Imminent Collision Mitigation with Reinforcement Learning and Vision
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
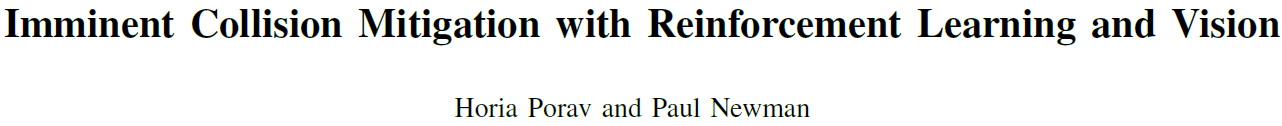
2018 21st International Conference on Intelligent Transportation Systems (ITSC)
Maui, Hawaii, USA, November 4-7, 2018
Abstract
这项工作通过在即将发生接触的情况下控制速度和转向,研究了强化学习在降低道路碰撞严重程度方面的作用。我们构建了一个模型,将摄像机图像作为输入,该模型能够学习和预测障碍物、汽车和行人的动态,并使用该模型训练我们的策略。将控制制动和转向的两种策略与基准进行比较,基准中采取的唯一动作是(常规)直线制动。这两种策略使用两种不同的奖励结构进行训练,一种是任何和所有碰撞都会产生固定的惩罚,另一种是根据已经建立的损伤严重程度delta-v模型计算惩罚。结果表明,两种策略都超过了基准的表现,使用伤害模型训练的策略表现最高。
I. INTRODUCTION
无论是人类驾驶的车辆还是自动驾驶的车辆,确保所有交通参与者的安全都是最重要的,也是自动驾驶车辆研究的主要动力。这项努力的一部分是考虑如果发生某种冲突不可避免的情况该怎么办。在此,我们不必详尽地考虑造成这种情况的许多可能的原因——这可能完全是由于无法控制的第三方决定或“天灾”事件。然而,我们应该考虑在碰撞很可能或不可避免之后以及碰撞发生之前,可以采取什么适当的动作。有可能减少碰撞场景中遭受的总伤害和伤害,特别是在紧急制动系统本身无法防止碰撞的情况下[1]。
目前的方法可分为两大类:
- 仅制动且无任何转向输入的紧急系统[1][2]
- 能够制动和转向的紧急系统,通常以变道的形式[3][4]
仅制动系统的主要缺点是,它们无法避免与障碍物的距离小于总停车距离的碰撞。如果系统检测到直线制动不足,制动和转向系统将通过触发变道或转向来改善这种情况。然而,迄今为止,据我们所知,这些系统要么使用简单的启发式(有或没有路径规划[4]),要么在简化的模拟中使用强化学习[1]学习策略。
在这项工作中,我们建立了一个循环模型,以[5]和[1]的方式预测障碍物、行人和车辆的移动。在这种情况下,我们的模型具有以下关键组件:一个变分自编码器(VAE),它降低了数据的维数,并将输入的观察结果压缩为潜在的表示,RNN学习预测给定当前潜在表示的下一个潜在表示,以及控制器。我们扩展了[7]的模拟系统,以包括行人和汽车碰撞,以及人行道上的随机行人和碰撞现场周围道路上的车辆交通,并关注1.5秒及以下的碰撞时间(TTC)[1]。
我们所做的主要假设是,其他交通参与者自己无法通过制动或改变方向来主动避免碰撞。我们在V中展示了我们的结果,并表明与直线制动基准相比,在复杂模拟中训练制动和转向策略可以减少行人和汽车乘员的伤害,尤其是在0.5到1.5秒之间的碰撞时间(TTC)[9]值。在我们的测试中,使用作为车辆乘员delta-v函数和行人碰撞速度函数的标准伤害模型,我们看到行人和汽车乘员的碰撞率降低了60%。
II. RELATED WORK
在本节中,我们回顾了相关工作和碰撞缓解以及受伤风险评估。
A. Related Work
在[2]中,作者提出了一种评估算法,通过考虑检测到的所有车辆及其约束条件,并仅在碰撞不可避免时触发紧急制动,来确定碰撞是否可以避免。与我们的工作类似,他们的方法不依赖于关于车辆路径或道路基础设施的假设,而仅依赖于车辆约束和其他检测到的交通参与者,并且他们的方法可以应用于各种碰撞场景,而不像其他仅对追尾碰撞进行建模的方法。在早期的研究中,[3]提出了一种用于确定防撞场景中最佳机动的工具。针对不同的速度生成间隙曲线,沿着该曲线,只有通过最佳机动才能避免危险状态。他们的结果表明,在高速行驶时,变道比完全停车更有优势,这突出了更多样化的动作空间的重要性。[8]提出了一种巡航控制系统,其目的是每当从传感器获取新数据时,使用涉及紧急制动或防撞动作的防撞模式来减少车队内的碰撞。[9]提出一种基于模型的碰撞避免算法,以近似驾驶员可以采取的一组动作(刹车、加速或转向),并确定是否需要立即协助。与我们的工作类似,该模型可用于所有交通场景和各种交通参与者。[4]提出了一种非线性模型预测控制,其目的是降低由于车辆试图避免碰撞而导致的其他危险情况的风险。该模型通过实现两级架构来考虑车辆动力学(最小和最大方向盘角度和加速度):一个控制器提供避免碰撞的路径/状态,另一个控制器帮助车辆遵循所提出的路径。
[10]中介绍了一种系统,该系统能够早期检测行人横穿道路的意图,并在无法通过制动进行避让时执行避让动作。然而,他们依赖于在危险的道路位置设置路边装置,以检测行人意图,并将该信息发送给车上的车载装置。
与大多数先前的研究相反,[1]提出了一种使用深度强化学习(DRL)的无模型碰撞避免系统。他们推导出基于DRL的自动制动系统的平衡奖励函数,其中动作空间允许4种选择:无制动、弱制动、中等和强制动。奖励函数由一个组件组成,该组件惩罚制动过早的智能体,而第二个组件是对与行人碰撞的惩罚,并考虑车辆速度,以反映损坏程度。由于学习性能不稳定(冲突很少发生),无论当前的策略如何,作者都使用记忆回放[11]来提醒智能体发生冲突。结果表明,当碰撞时间大于或等于1.5秒时,碰撞率为0。这促使我们研究低于1.5秒的TTC值。
B. Injury risk literature
研究中采用了各种度量标准来衡量碰撞严重程度,尽管这让人难以理解,但它们确实提供了广泛采用的定量、数据驱动的事故结果模型。它们包括加速度严重度指数(ASI)、乘员碰撞速度(OIV)和Delta-V。然而,[12]表明,与后者相比,前两者没有提供显著的预测优势。自1970年代出现以来,Delta-V一直是碰撞严重程度的传统度量标准,并被定义为碰撞前速度和碰撞后速度之间的绝对变化,假设速度的较大差异与更严重的伤害相关[13]:
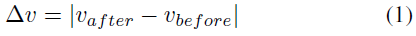
在[14]中,使用GIDAS数据集(德国深度事故研究)研究了由车辆碰撞速度给出的行人死亡风险。该数据集包括1999年至2007年间2127名行人的数据。他们提供了目前广泛采用的死亡风险近似值:
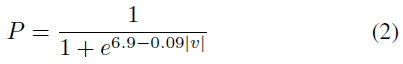
其中v是碰撞行人时的速度(km/h)。
[15]的作者介绍了一种广泛使用的模型,用于计算正面碰撞过程中汽车乘员严重受伤的概率,该模型后来在一项更大的研究中得到了证实和扩展[16]。这两篇论文都分析了美国国家公路交通安全管理局(National Highway Traffic Safety Administration,USA)发布的碰撞测试,以确定正面碰撞时碰撞速度如何影响乘用车前排乘员的严重伤害风险。他们估计致命伤害风险如下:

其中Δv以英里/小时表示,P值的上限为1.0。向前看,毫无偏见,我们将使用公式2和3作为事故严重程度的定量模型。在接下来的章节中,没有任何内容需要这些特定的模型,读者可以自行决定替换它们。我们在这里提出的是一个框架,而不是一个固定的实现方案,或是一个关于衡量事故严重程度的正确方法的判断呼吁。
III. LEARNING TO AVOID AND MITIGATE COLLISIONS
在此,我们研究机器学习在管理和减轻冲突中的作用。我们的目标是降低碰撞成本,尤其是在碰撞时间值较低的情况下。我们的“智能体”是我们可以执行转向和制动控制的车辆。在运行时,我们的智能体仅提供道路场景的一系列图像。鉴于此,我们需要学习从图像到2通道控制序列的映射,这比传统的基准直线制动提高了结果。这样,系统可以根据瞬时速度和碰撞时间选择制动和转向的方式和时间。我们将考虑并比较两种损失/回报策略,这将在第III-B节中解释。在剩下的小节中,我们假设对最近的强化学习文献有一定的了解,为了完整起见,我们给出了学习过程的细节。然而,第四节和第五节中的实验和结果可以独立于本节进行消费/阅读。
A. Reinforcement learning using DDPG
我们使用深度确定性策略梯度(DDPG)[6],因为它是异策的,通过使用随机策略来改进探索,使其适合于在模拟中快速发现最优策略,同时解决学习确定性策略这一更容易的任务。DDPG使用两个网络,一个策略网络(行动器)和一个Q值估计网络(评判器)。使用当前状态作为两个网络的输入,行动器将从连续动作空间输出动作,而评判器根据行动器的输出估计Q值。然后使用确定性策略梯度[17]更新行动器网络权重,使用时序差分信号的梯度更新评判器权重,类似于[17]。
DDPG使用经验回放[11]作为方差减少技术,并使用目标网络[17]来稳定训练。与DPG[17]的不同之处在于,DDPG不是每N步将本地网络θL的权重直接复制到目标网络θT,而是使用0和1之间的更新率τ对其目标网络权重θT进行软更新:
![]()
通过最小化损失函数来更新本地评论器网络:
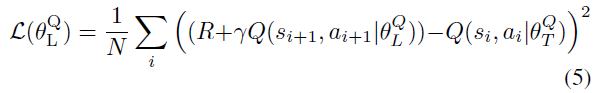
这里,R是奖励,Q是Q值逼近函数,本地评判器网络由![]() 参数化,目标评判器网络由
参数化,目标评判器网络由![]() 参数化,γ是时间范围折扣因子,N是从经验回放缓存采样的小批量的大小。当前状态和动作由si和ai表示,未来状态和动作则由si+1和ai+1表示。使用本地评判器网络相对于动作ai的梯度,乘以本地行动器网络相对于
参数化,γ是时间范围折扣因子,N是从经验回放缓存采样的小批量的大小。当前状态和动作由si和ai表示,未来状态和动作则由si+1和ai+1表示。使用本地评判器网络相对于动作ai的梯度,乘以本地行动器网络相对于![]() 的梯度(链式规则)[17],更新本地行动器网络:
的梯度(链式规则)[17],更新本地行动器网络:
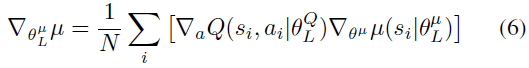
这里,μ是策略函数,本地行动器网络由![]() 参数化,目标参与者网络由
参数化,目标参与者网络由![]() 参数化。奖励R、动作a和状态s的参数化、来源和形式现在将在以下小节中解释。
参数化。奖励R、动作a和状态s的参数化、来源和形式现在将在以下小节中解释。
B. Reward structure
由于这项研究旨在客观比较学习策略导致的智能体行为,我们为强化学习智能体提出了两种奖励结构:一种是惩罚统一(任何类型的碰撞均为-1),另一种是遵循严重风险伤害和行人死亡风险的文献。
虽然[1]的工作只关注行人,但我们提出的奖励结构还将考虑另一类交通参与者:汽车乘客。其次,由于伤害风险在先前的研究中已经接近,我们希望第二个奖励结构将更紧密地遵循真实的碰撞场景,因为汽车的能量吸收特性,汽车乘员比行人受到更好的保护。此外,这种经验方法允许我们避免奖励函数中的任何超参数或权重。
Reward Strategy 1 第一个奖励函数定义为:
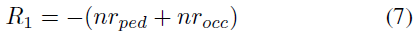
这里nrped表示行人数量,nrocc表示事故中涉及的汽车乘客数量。这一策略只计算碰撞中涉及的人数。
Reward Strategy 2 第二个奖励函数结合了“伤害”公式(2)和(3)的经验模型,因此明确说明了伤害程度,定义如下:
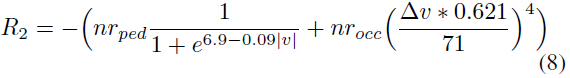
在乘员伤害部分,0.621用于将速度从km/h转换为英里/小时,以符合Joksch[15]的原始模型。
注意,当使用策略1或策略2比较结果时,我们将在两种情况下使用经验推导的公式2和3,以连续数字表示总伤害。
C. Action space
根据先前基于模型的研究,将转向和制动作为防撞选项,我们提出了[1]智能体的动作空间的扩展,以包括制动和转向。此外,我们让动作是连续的而不是离散的,以允许更大程度的控制。
动作at被编码为-1和1之间的一对整数值,第一个值编码转向角,第二个值编码油门(正值)或制动器(负值)。对于转向-1到1映射最大左转向角和最大右转向角之间的范围。对于制动-1到0映射了导致减速-9. 8m/s2至0m/s2的制动力。
D. General Simulation Architecture
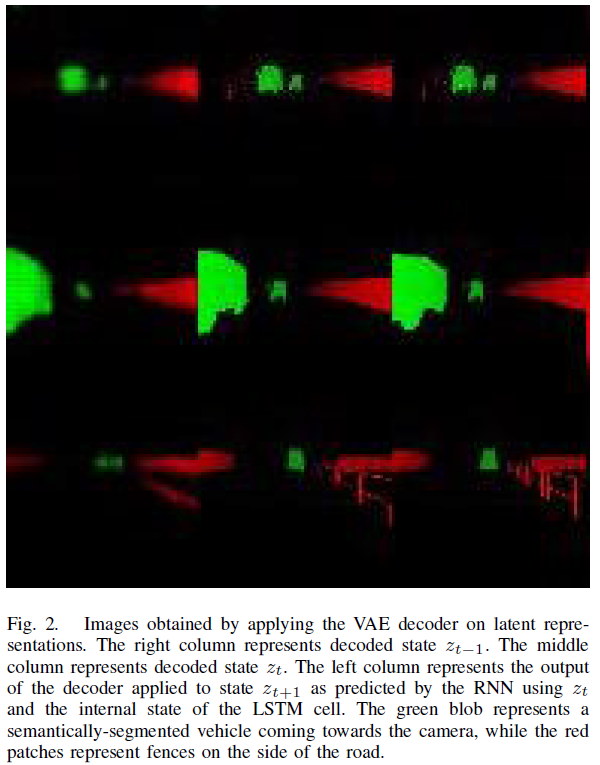
显然,在这种情况下,需要使用模拟。在现实生活中,人们无法轻易或合乎道德地探索事故与动作的空间。因此,我们这里介绍的系统是与CARLA基于Citiscape[18]类的语义分割输出结合使用的后端,该输出以64×64的单通道图像形式提供给我们的系统,13个对应的类别(无、建筑物、围栏、其他、行人、电杆、道路线、道路、人行道、植被、车辆、墙壁、交通标志)被编码为0-12之间的整数值。我们的选择基于实时语义分割方法的最新性能[19][20],我们假设这样的系统现在可以作为输入预处理器。与[5]类似,我们在多个阶段开发和训练我们的系统,因为这允许我们在可能的情况下使用监督学习并测试单个组件。我们首先记录一个智能体使用内置的基于航路点的自动驾驶仪[7]探索CARLA环境时产生的观察obst和动作at,并将高斯噪声添加到控制中。在每个时间 t,我们收集的观察obst由环境的语义分割(使用Citiscapes类)图像It(如图4所示)和车辆前进速度vt的元组表示。在第一阶段,变分自编码器(VAE)[21]学习将来自环境的输入观测obst压缩为具有高斯分布的潜在表示zt。在第二阶段,给定当前潜在表示zt和当前动作at,我们训练循环神经网络(RNN)来预测下一个潜在表示zt+1。最后,在第三阶段中,我们通过使用VAE编码当前传入帧、使用循环网络预测下一状态以及使用潜在表示zt和预测状态zt+1作为控制器的输入来使用DDPG训练智能体,从而使智能体能够访问环境的当前状态和对未来状态的预测。然后,智能体在模拟的CARLA环境中采取动作。系统架构概述如图3所示。
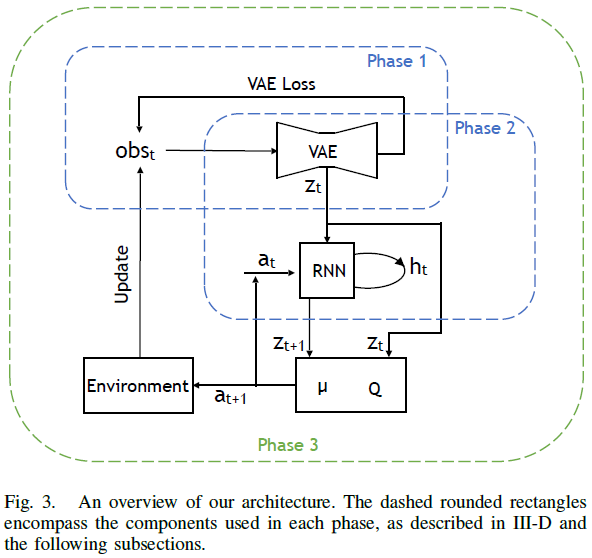

E. Phase 1
在[5]之后,在阶段1中,我们训练变分自编码器(VAE)[21],以将传入的2D观测(图像)obst压缩为具有高斯分布且长度为128的潜在表示zt。关于VAE的文献非常丰富,例如,请读者研究[22]和[21],以更深入地了解VAE。使用VAE的主要原因有两方面:1)我们希望降低数据的维数,以便更容易训练RNN和控制器;2)我们希望只保留与编码传入语义分割图像中发现的目标的位置和类型相关的特征。
F. Phase 2
在阶段2中,我们首先将所有记录的2D图像观测值obst转换为潜在空间表示zt。接下来,我们通过为 t 创建一个元组序列(zt, zt+1, at)来生成训练数据,其中 t 在1和N之间,即序列中记录的帧总数。然后,我们训练LSTM-RNN[23]来预测给定当前潜在表示zt和使用元组序列的当前动作的下一个潜在表示zt+1。在预测的潜在表示上应用VAE解码器的示例如图2所示。RNN布局使用具有512个隐藏单元的LSTM单元。有关实现的详细信息可参考[5]。
G. Phase 3
在阶段3中,我们使用DDPG在CARLA环境中训练我们的智能体,如III-A所述。对于每个传入的观测obst,我们使用VAE将其转换为潜在表示zt并预测未来状态zt+1。策略和Q值函数的输入都是zt和zt+1的级联,使智能体能够访问环境的当前状态和未来状态的预测。
IV. EXPERIMENTAL SETUP
A. Generating and Simulating Collision Scenarios
为了生成一组不同的即将发生的碰撞场景,我们从以下分布中随机采样碰撞参数:
![]()
- 碰撞速度
![]()
-
行人速度
![]()
- 车辆数目 nc ~ [0 ... 10]
- 其他行人数目 np ~ [0 ... 10]
- 行人违规概率
![]()
- 车辆违规概率
![]()
对于每个场景,如果行人碰撞的概率高于0.5,我们生成一个随机轨迹,该轨迹与行人和车辆相交,如果保持车辆的速度,该轨迹将在TTC秒后到达。类似地,如果车辆碰撞的概率高于0.5,那么如果速度保持恒定,我们将产生一辆与车辆在TTC秒后相交的车辆。
B. Training
我们在包含200000帧的数据集上训练VAE 2个回合。我们在850个序列上训练RNN 10个回合,每个序列约230帧,在CARLA环境中以15FPS捕获,每个序列的时间限制为15秒。我们将Adam作为所有训练的求解器,初始学习率为0.0001,批大小为32。未设置或使用其他超参数。
C. Testing
为了测试我们的策略的有效性,我们通过扫描TTC、碰撞速度和交通参与者设置创建了一组测试场景,并为任何随机生成的组件设置了固定种子,以允许重复性。然后,我们使用相同的测试场景测试两个策略和基准策略,并为每个冲突场景以及场景设置记录以下度量:
- 是否与行人发生碰撞
- 是否与车辆发生碰撞
- 是否与静止物体发生碰撞
- 每个参与者每次碰撞的伤害严重程度
- 碰撞开始时汽车的速度
- 汽车是否已离开车道
通过这些度量,我们可以研究每种策略类型和每种冲突时间间隔:
- 避免的行人碰撞百分比
- 避免的汽车碰撞百分比
- 与静态障碍物的碰撞百分比(例如电杆、墙壁等)
- 严重伤害的百分比
D. Performance
对于Intel I7处理器上分辨率为64×64的图像,智能体网络大约需要100毫秒,对于NVIDIA Tesla GPU上分辨率相同的图像,则需要30毫秒。
V. RESULTS
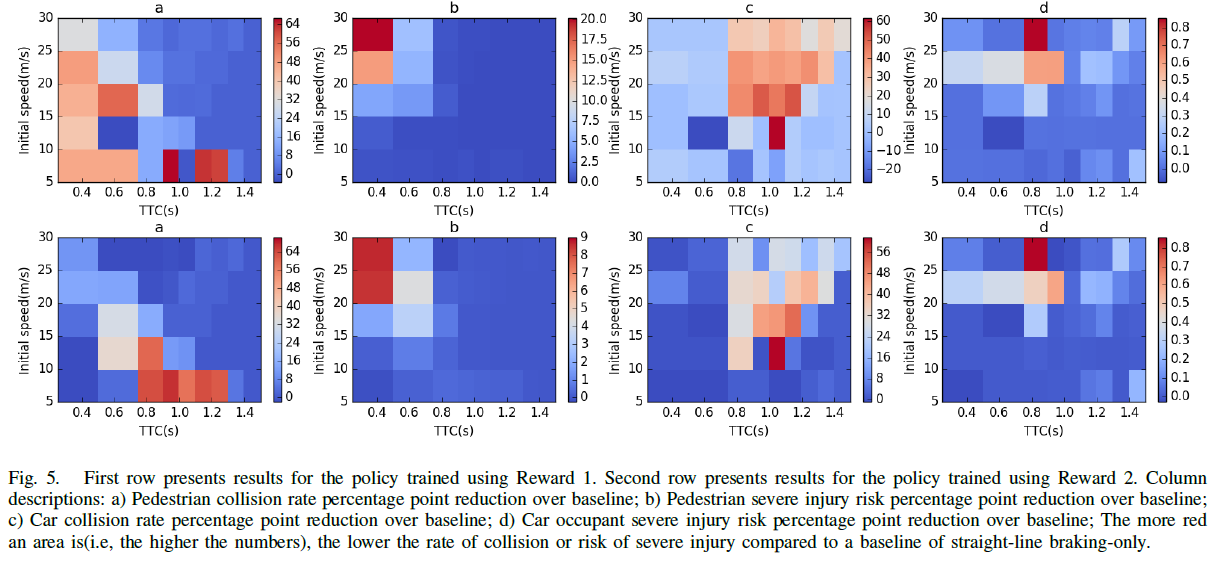
图5显示,在每列上,按以下顺序排列:a)行人碰撞率比基准提高的百分比;b) 行人严重伤害风险比基准提高的百分比;c) 汽车碰撞率比基准提高的百分比;d) 汽车乘员严重伤害风险比基准提高的百分比;所有这些都表示为TTC和初始速度的函数。第一行显示了使用奖励R1训练的策略的结果,而第二行显示了利用奖励R2训练的策略结果。我们注意到,与仅制动的基准相比,两种策略都提供了非常有利的结果。
我们观察到,与基准相比,避免的碰撞次数显著增加,尤其是行人的TTC值在0.25秒到1.0秒之间,汽车碰撞的TTC数值在0.75秒到1.3秒之间。与仅制动的基准相比,我们没有观察到性能的总体下降,这表明控制器已经学会了有效地判断简单制动何时足够,以及何时需要转向输入来减轻碰撞的影响。
我们还观察到行人严重受伤的风险显著提高,特别是在TTC的问题[1]区域,0.9秒以下并且速度超过15m/s。
表I比较了经过训练的智能体的性能与行人严重受伤风险的仅制动基准。与直线制动相比,这两项策略都导致了较低的严重伤害发生率,使用R2训练的策略在所有方面都有明显改善,但TTC 0.75s在30m/s时除外。
表II比较了经过训练的智能体的性能与汽车乘员受伤的仅制动基准。我们观察到,使用R2训练的策略在所有方面都有明显的改善。
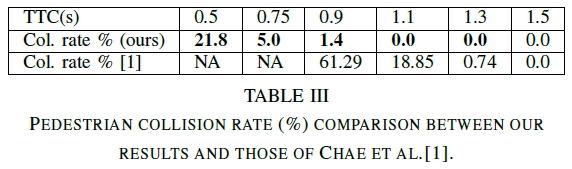
表III将使用我们的R2策略获得的行人碰撞结果与[1]发布的结果进行了比较。我们发现,在整个TTC范围内,0.9s和1.5s之间的严重伤害率有所降低,并且在TTC为0.75s和0.5s时的碰撞率比[1]中报告的0.9s的碰撞率低得多。
VI. CONCLUSIONS
这篇论文提出了一个不寻常的问题:“自动驾驶汽车在事故中可能会做什么,包括碰撞不可避免的情况?”。当然,没有明显正确的答案,我们也不打算在这里就应该发生的事情提出看法。相反,我们问,如果我们利用现有的损伤严重程度模型,同时利用自动驾驶车辆控制其完整轨迹的能力,从而区别于传统ADAS系统,我们会学到什么控制行为。
我们的结构对使用模拟和机器学习研究碰撞缓解的主题做出了一些贡献。VAE的训练从CARLA模拟中提取相关信息,使得RNN和控制器变得更容易训练。当然,在控制器中使用强化学习允许系统自由学习复杂的控制曲线。
我们将考虑转向和制动控制的结果与直线紧急制动系统的结果进行了比较。我们使用两种奖励结构来训练我们的系统——一种是简单地计算碰撞参与者,另一种是考虑到根据经验得出的严重程度。在所有三种情况下(我们的两种策略和基准),我们使用相同的损伤经验测量方法(公式(2)和公式(3))的测量结果。
我们提出了一种基于视觉的紧急碰撞缓解系统,该系统在模拟下可降低人身伤害的总严重程度。我们的经验结果表明,当与我们所学的策略一起使用时,允许车辆制动和转向会产生更好的结果。在某些情况下,收益率为60%。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号