Implementing Spiking Neural Networks on Neuromorphic Architectures: A Review
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Arxiv 2022
Abstract
最近,工业界和学术界都提出了几种不同的神经形态系统来执行使用脉冲神经网络(SNN)设计的机器学习应用。随着设计和技术领域日益复杂,编程此类系统以接纳和执行机器学习应用程序变得越来越具有挑战性。此外,神经形态系统需要保证实时性能,消耗较低的能量,并提供对逻辑和记忆故障的容忍度。因此,显然需要能够在当前和新兴的神经形态系统上实现机器学习应用的系统软件框架,同时解决性能、能量和可靠性问题。在此,我们全面概述了为基于平台的设计和硬件软件协同设计提出的框架。我们强调了神经形态计算系统软件技术领域的未来挑战和机遇。
1. Introduction
神经形态系统是设计用于模拟哺乳动物大脑中事件驱动计算的集成电路[1]。它们能够执行脉冲神经网络(SNN),这是一种使用脉冲神经元和生物启发学习算法设计的计算模型[2]。SNN由于其时空信息编码能力而实现了强大的计算[3]。SNN可以实现不同的机器学习方法,如监督学习[4]、无监督学习[5]、强化学习[6]和终身学习[7]。
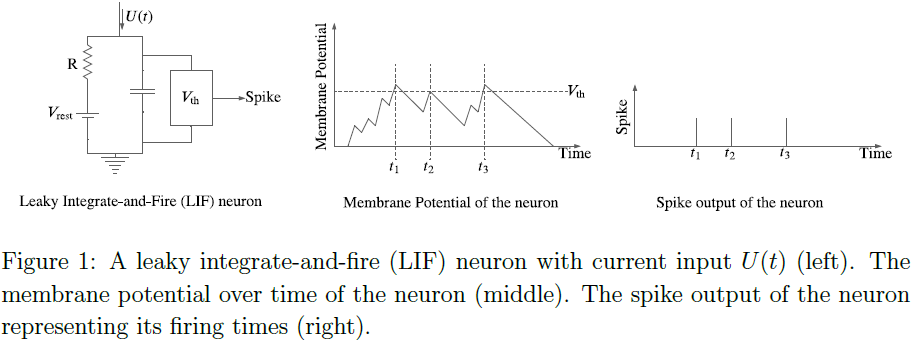
在SNN中,神经元通过突触连接。神经元可以被实现为IF逻辑[8],如图1(左)所示。这里,来自突触前神经元的输入当前脉冲U(t)提高了突触后神经元的膜电压。当该电压超过阈值Vth时,IF逻辑发出一个脉冲,该脉冲传播到突触后神经元。图1(中)说明了输入脉冲序列引起的膜电压。图1(右)显示了超过阈值的时刻,即发放时间。
SNN可以在CPU或GPU上实现。然而,由于其有限的内存带宽,SNN在此类设备上的性能通常很慢,并且功率开销很高。在SNN中,神经计算和突触存储紧密结合。它们提供了CPU和GPU设备无法利用的高度分布式计算范式。神经形态硬件可以消除CPU和GPU的性能和能量瓶颈,这得益于它们的低功耗模拟和数字神经元设计、分布式就地(in-place)神经计算和突触存储架构,以及非易失性存储器(NVM)用于高密度突触存储[9, 10, 11, 12, 13, 14, 15]。由于其低能量开销,神经形态硬件可以在能量受限的嵌入式系统和物联网(IoT)边缘设备上执行机器学习任务[16]。
神经形态硬件被实现为基于瓦片(tiled-based)的架构[17],其中瓦片(tile)共享互连。瓦片可以包括 1)神经形态核心,其实现神经元和突触电路,2)外围逻辑,用于将脉冲编码和解码为地址事件表示(AER),以及3)网络接口,用于从互连发送和接收AER分组。交换机放置在互连上,以将AER数据包路由到其目标区块。表1说明了最近一些神经形态硬件核心的性能。
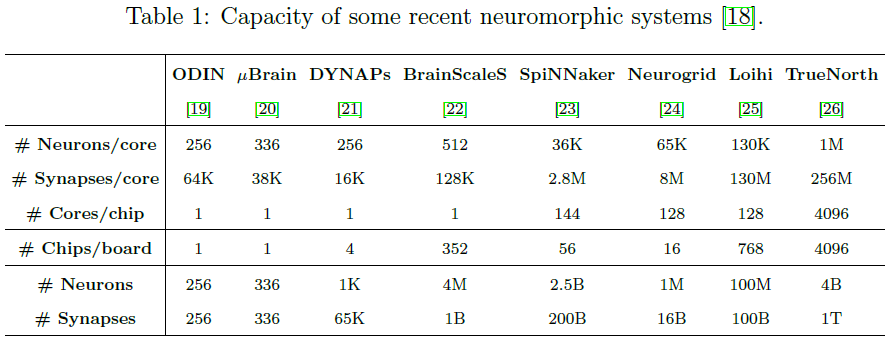
NVM设备由于其在低功耗多级操作和高集成密度方面的潜力,为实现突触存储提供了一个有吸引力的选择[27, 28, 29, 30]。最近,正在为神经形态计算探索几种NVM:基于氧化物的电阻随机存取存储器(ReRAM)[31]、相变存储器(PCM)[32]、铁电RAM[33]和自旋转移扭矩磁性或自旋轨道扭矩RAM(STT和SoT MRAM)[34]。表2显示了最近集成NVM的一些神经形态硬件演示(除神经形态计算外,NVM还用作常规计算的主存储器[35, 36, 37, 38, 39, 40, 41, 42])。

图2显示了具有瓦片(C)和开关(S)的神经形态硬件。为了说明的目的,我们将每个瓦片显示为交叉(crossbar),其中NVM单元组织在使用水平字线和垂直位线形成的二维网格中。
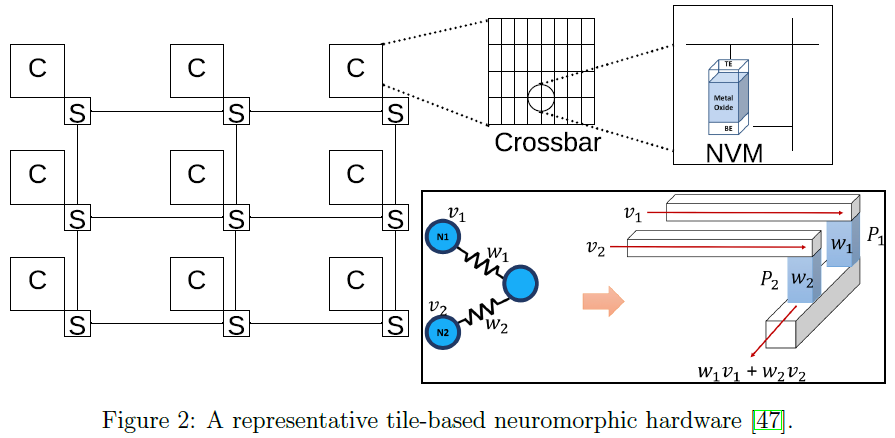
该图还说明了在交叉开关上实现SNN的一个小示例。突触权重w1和w2分别被编程为NVM细胞P1和P2的电导。N1的输出脉冲电压v1和N2的输出脉冲电压v2将电流注入交叉,通过将突触前神经元的输出脉冲信号电压与NVM细胞的电导相乘而获得(欧姆定律)。沿列的电流求和是并行进行的(基尔霍电流定律),它们实现了和![]() (即神经元激励)。
(即神经元激励)。
为了应对日益复杂的神经形态系统、集成新兴NVM技术的挑战以及更快的上市压力,需要采用科学的设计方法。我们强调了以下两个可能解决上述设计问题的关键概念。
- Platform-based Design: 在这种设计方法中,从其系统软件中抽象出一个硬件平台,使硬件和软件开发正交,以便更有效地探索替代解决方案[48]。基于平台的设计方法促进了系统软件在许多不同硬件平台上的重用。
- Hardware-Software Co-design: 在该设计方法中,同时设计了硬件平台及其系统软件,以利用它们的协同作用,从而实现系统级设计目标[49]。在这种情况下,系统软件是为硬件平台定制的。
在本文中,我们对神经形态计算的这些设计方法进行了综述,主要关注软件技术前沿的最新进展。
2. Platform-based Design
基于平台的设计已成为电子行业的一种重要设计风格[48, 50, 51, 52, 53, 54]。基于平台的设计将系统设计过程的各个部分分开,以便可以针对不同的指标(如性能、功率、成本和可靠性)对它们进行独立优化。基于平台的设计方法也可用于神经形态系统设计[55],其中软件可独立于底层神经形态硬件平台进行优化。
与传统计算系统一样,神经形态系统的抽象包括 1)应用软件、2)系统软件和 3)硬件[56, 57, 58]。在神经形态计算的背景下,应用软件包括使用不同SNN拓扑设计的应用,如多层感知器(MLP)[59]、卷积神经网络(CNN)[60]和循环神经网络(RNN)[61],以及生物启发学习算法,如脉冲时序依赖可塑性(STDP)[62]、长期可塑性(LTP)[63]和FORCE[64]。系统软件包括编译器和运行时管理器,用于在硬件上执行SNN应用程序。最后,硬件抽象包括由神经形态硬件组成的平台。
我们关注系统软件抽象,并强调文献中提出的关键优化技术。在第2.1节中,我们概述了神经形态计算系统软件概念的独特性。
对于神经形态系统,性能、能量和可靠性是系统软件优化的驱动指标。因此,我们将最先进的方法分为 1)面向性能/能源的软件方法(见第2.2节)和 2)面向热/可靠性的软件方法。最后,我们强调了在平台设计阶段早期使用高级数据流表示来估计SNN性能的最新方法(见第2.4节)。
2.1. System Software Considerations for Neuromorphic Computing
在SNN中,信息被编码在神经元之间传递的脉冲中[65]。我们以SNN中的脉冲间隔(ISI)编码为例。设{t1, t2, ... , tK}表示神经元在时间间隔[0, T]内的发放时间,该脉冲序列的平均ISI为:

ISI的变化,称为ISI失真,影响SNN性能。为了说明这一点,我们使用了一个小的SNN,其中三个输入神经元连接到一个输出神经元。图3说明了ISI失真对输出脉冲的影响。在顶端子图中,由于输入神经元的脉冲,输出神经元在22μs时产生脉冲。在底部子图中,来自输入3的第二个脉冲被延迟,即它具有ISI失真。由于这种失真,没有产生输出脉冲。缺少脉冲会影响推理质量,因为脉冲会在SNN中编码信息。
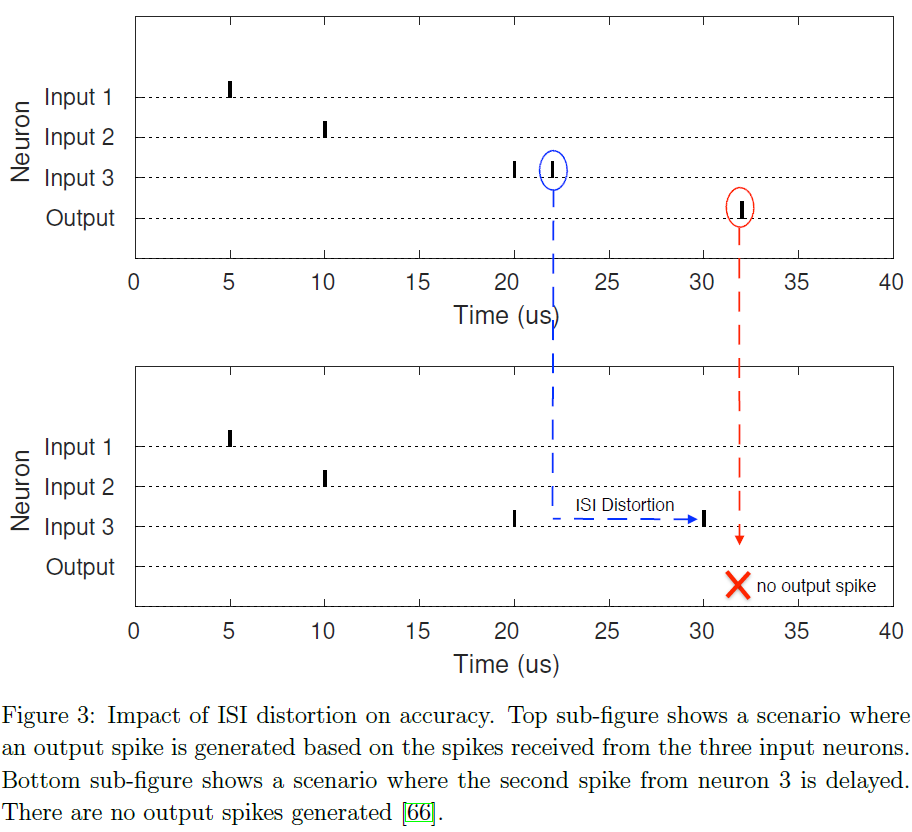
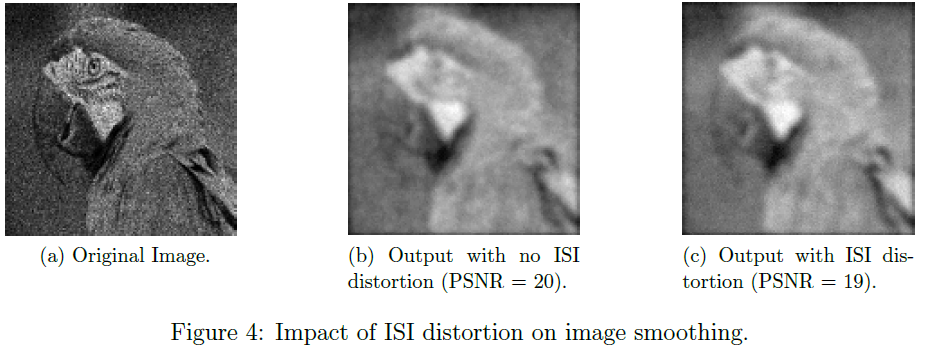
图4显示了ISI失真在应用程序级别的影响。我们考虑使用CARLsim模拟器使用SNN模型实现的图像平滑应用[67]。图4a显示了输入图像,该图像被馈送到SNN。图4b显示了无ISI失真的图像平滑应用程序的输出。输出相对于输入的峰值信噪比(PSNR)为20。图4c显示了ISI失真的输出。该输出的PSNR为19。PSNR的降低表明具有ISI失真的输出图像质量更低。
这一背景激发了以下动机。神经形态硬件的系统软件需要考虑应用特性,特别是脉冲时序及其失真,以确保在硬件实现上获得的SNN性能与应用级模拟器(如CARLsim[67]、NEST[68]、Brian[69]和NEURON[70])中模拟的性能紧密匹配。
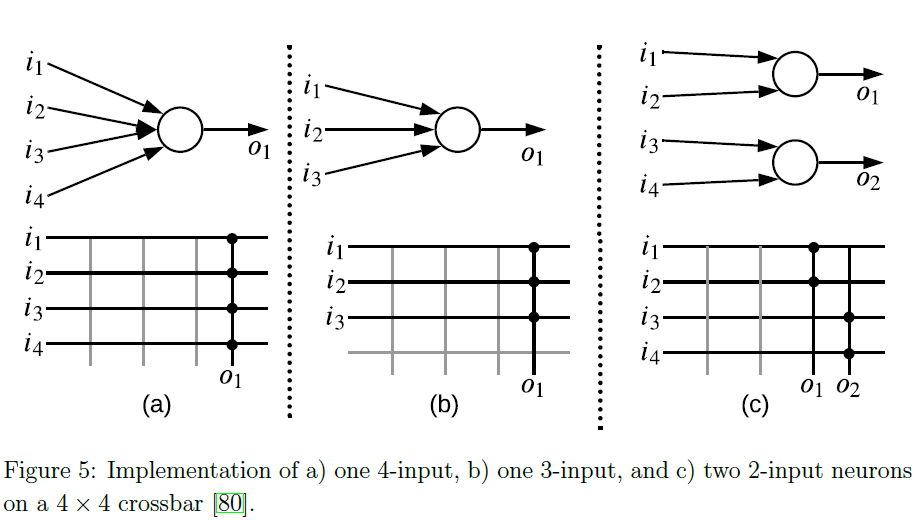
在实现方面,用于神经形态硬件的系统软件还必须包含硬件约束,例如受限的神经结构、有限的神经元和突触容量以及每个神经元的有限扇入。我们采用交叉的架构[71, 72, 73, 74, 75, 76, 77, 78, 79],这通常用于实现神经形态硬件平台。在交叉中,位线和字线被组织成网格,存储单元在其交叉点连接以存储突触权重。神经元电路沿着位线和字线实现。每个突触后神经元的交叉只能容纳有限数量的突触前连接。为了说明这一点,图5显示了在4×4交叉上实现神经元的三个示例。左子图显示了在交叉上实现四输入神经元的情况。神经元占据了所有四个输入端口和一个输出端口。中间的子图显示了一个三输入神经元的实现,占据了三个输入端口,一个输出端口。最后,右侧的子图展示了两个两输入神经元的实施,占据了四个输入端口和两个输出端口。
交叉不是神经形态结构的唯一类型。大脑架构由三层神经元组成,它们以全连接的拓扑结构相互连接[20]。交叉和μBrain都受到限制的扇入和扇出。其他硬件架构包括解耦设计,其中处理逻辑与突触存储器分离[81, 82, 83, 84]。
当SNN需要在硬件中实现时,系统软件需要结合底层平台的硬件约束。
2.2. System Software for Performance and Energy Optimization
我们讨论了解决在神经形态硬件上执行SNN应用程序的性能和能量方面的关键系统软件优化方法。
在[85]中,Varshika等人提出了一种具有完全可合成无时钟μBrain核心的多核硬件[20]。在所提出的架构中,核心使用分段总线互连互连[86]。在内部,μBrain核心由三层全连接的神经元组成,这些神经元可以编程实现卷积、池化、级联和加法等操作,以及不规则的网络拓扑结构,这在许多新兴的脉冲深度卷积神经网络(SDCNN)模型中常见。为了在提出的多核设计上实现SDCNN,作者提出了SentryOS,这是一个系统软件框架,由编译器(SentryC)和运行时管理器(SentryRT)组成。SentryC是SDCNN生成子网络的群集方法,这些子网络可以在硬件的不同核心上实现。子网络生成工作如下。它根据SDCNN模型中所有神经元与输出神经元的距离对其进行分类。考虑到神经形态核心的资源限制,它将距离小于或等于2的所有神经元分组成簇。2的限制是由于μBrain核心的三层架构。在下一次迭代中,它从模型中移除已经聚集的神经元,重新计算神经元距离,并将剩余的神经元分组以生成下一组簇。重复这个过程,直到所有神经元都聚集到子网络中。通过结合硬件约束,SentryC确保子网络无法到达目标核心架构。运行时管理器(SentryRT)将这些子网络调度到核心上。为此,它使用实时演算来计算不同子网络的执行结束时间。接下来,它丢弃执行时间,只保留子网络的执行顺序。最后,它将子网络的执行流水线化到核心上,并将多个输入图像的执行重叠到硬件核心上。SentryOS通过改善流水线和利用数据级并行性的机会,显著提高了硬件吞吐量。
在[87]中,Amir等人提出了corelet,一种TrueNorth神经形态硬件的编程范式[26]。这是为了解决与设计与TrueNorth架构一致的神经形态算法以及在硬件上编程相关的复杂性而开发的。Corelet范式是使用corelet设计的,这是一个神经突触核心网络的抽象,它封装了生物学细节和神经元连接,只向程序员暴露网络的外部输入和输出。接下来,作者提出了一种面向对象的Corelet语言,用于创建、组合和分解Corelet。它由三个基本符号组成——神经元、神经突触核和corelet。连接符构成了将符号组合到TrueNorth程序中的语法。作者表明,使用符号和语法,可以表达任何TrueNorth程序。接下来,作者介绍了Corelet库,这是一个包含100多个corelet的存储库,有助于TrueNorth程序的设计。最后,作者提出了一个Corelet实验室在TrueNorth硬件上使用corelet设计的实现程序。
在[88]中,Lin等人提出了LCompiler,一种将SNN映射到Loihi神经形态硬件上的编译器框架[25]。作者表明,Loihi的能耗主要是由于更新了本地学习规则使用的数据结构。作者报告称,由于芯片上学习而消耗的能量比Loihi的脉冲路由所消耗的能量高一个数量级。作者表明,学习更新中相关的能量成本与分配给SNN实例的数据结构数量成正比,这取决于SNN如何划分为核心。在内部,LCompiler创建由逻辑实体组成的数据流图来描述SNN实例。这些逻辑实体包括隔室(神经元的主要构造块)、突触、输入图、输出轴突、突触迹和树突蓄积器。总体而言,LCompiler分三步操作。在预处理步骤中,它验证SNN参数,分解学习规则,将其转换为微码,并将SNN拓扑(即逻辑实体)转换为连接矩阵。在映射步骤中,它使用贪婪算法将逻辑实体映射到Loihi内核的硬件组件,对内核上的共享资源进行时间复用。最后,在代码生成步骤中,它为每个Loihi内核生成二进制比特流。
在[89]中,Gallupi等人提出了分区与配置管理器(PArtitioning and Configuration MANager, PACMAN),这是一种将SNN映射到SpiNNaker系统上计算节点的框架[23]。PACMAN的关键思想是将SNN的高级表示转换为物理片上实现。PACMAN持有SNN的三种不同表示。在模型级别,SNN使用高级语言(如PyNN[90]和Nengo[91])指定。在系统级,SNN被分成多个组,其中每个组不能连接到SpiNNaker计算节点。在设备级,从组到SpiNNaker系统的节点形成映射。为了生成这些表示,PACMAN执行四个操作{1)拆分,将SNN划分为更小的子网络;2)分组,将子网络组合为无法连接到硬件节点的组;3)映射,将组分配给不同的节点;4)二值文件生成,从分区和映射的网络创建实际的数据二值。
在[92]中,Sugiarto等人提出了一种框架,将作为任务图运行的通用应用程序映射到SpiNNaker硬件上,目的是减少不同SpiNNake芯片之间的数据传输。所提出的框架使用XL Stage程序[93]给出的任务图描述。在将任务图映射到硬件时,每个任务都映射到SpiNNaker芯片。为了提供容错性,在不同的SpiNNaker芯片上生成并执行任务的多个副本。作者提出使用进化算法来执行映射,以平衡系统上的负载,同时最小化芯片间的数据通信。
在[90]中,Davidson等人提出了一个名为PyNN的Python接口,以促进不同研究机构之间更快的应用程序开发和可移植性。PyNN提供了SNN模型的高级抽象,促进了代码共享和重用,并为模拟器不可知的分析、可视化和数据管理工具提供了基础。除了作为不同后端SNN模拟器的Python前端外,PyNN还支持在SpiNNaker[23]、BrainScaleS[22]和Loihi[25]神经形态硬件上映射SNN模型。为了实现这种映射,PyNN首先将SNN模型划分为集群,然后在不同的硬件核心上执行它们。为了进行分区,PyNN任意分配SNN模型的神经元和突触,同时结合神经形态核心的资源约束。
在[91]中,Bekolay等人提出了Nengo,一种Python框架,用于构建、测试和部署SNN到神经形态硬件。Nengo基于神经工程框架(NEF)[94]。NEF使用三个基本原理来构建大规模神经模型。这些原则是 1)表示、2)转换和 3)动力学。NEF的表示原理提出信息由神经元群体编码。它将信息表示为实数的时变向量。为了对信息进行编码,电流根据被编码的向量注入神经元。可以使用解码过程来估计原始编码向量,该过程包括使用指数衰减滤波器来过滤脉冲序列。滤波脉冲序列与通过求解最小二乘最小化问题确定的权重相加。NEF的变换原理提出,两个神经群体之间的权重矩阵可以被分解为两个在计算上非常小的矩阵。最后,动力学原理指出,通过循环连接,对应于神经群体的向量相当于动态系统中的状态变量。这样的系统可以使用控制理论进行分析,并使用表示和转换原理将其转换为神经电路。Nengo使用NEF不仅模拟大规模神经模型,还将SNN映射到定制FPGA(nengoFPGA)和Loihi[25]和SpiNNaker[23]等神经形态硬件上。
在[95]中,Ji等人提出了一种编译器,将经过训练的SNN应用程序转换为满足硬件约束的等效网络。该编译器针对TianJi[96]和PRIME[97]神经形态硬件平台。执行编译有四个步骤。在步骤1中,编译器基于给定的SNN信息构建数据流图,该SNN信息包括训练参数、网络拓扑、顶点信息和训练数据集。在步骤2中,它将数据流图转换为由硬件友好操作组成的中间表示(IR)。在步骤3中,它执行图形调整,包括数据重新编码(以解决硬件精度问题)、扩展(其中IR被转换为目标硬件中支持的操作)和权重调整(即,微调参数以最小化转换误差)。最后,在步骤4中,它利用平台的互连约束将调整后的图映射到硬件。映射步骤将硬件操作分配给硬件的物理核心。
在[98]中,Gao等人提出了一种利用动态系统理论将神经元模型映射到神经形态硬件的方法。作者采用模型引导的方法将神经元模型映射到神经形态硬件上。总体方法如下。它从控制模型状态变量的常微分方程(ODE)开始。接下来,它将这些状态变量表示为电流。接下来,直接从这些ODE合成电流模式亚阈值CMOS电路。该方法通过一组硬件特定映射参数产生与神经模型参数相关的电路偏置组合。最后,将这些映射参数转换为电路参数。使用 1)使用模型的数值模拟作为参考的非线性优化,以及 2)调整电路的操作电流以与数值模拟的状态变量收敛的迭代方法来提取映射参数。作者使用二次和三次IF神经元在多核神经网格神经形态硬件中演示了他们的映射策略[24]。
在[99]中,Neftci等人提出了一种在神经形态硬件上用不精确和有噪声的神经元映射SNN的方法。为了解决这一问题,作者提出首先将硅神经元的不可靠硬件层转换为由可靠神经元组成的抽象计算层,然后将目标动力学建模为在该计算层上运行的软状态机。映射思路如下。SNN是通过将神经元的电路偏置电压映射到模型参数并使用一系列群体活动测量对其进行校准而在硬件上实现的。抽象计算层是通过将神经网络配置为通用的软赢者通吃子网络而形成的。最后,通过仅在各个子网络的一些神经元之间引入稀疏连接,将期望的高级行为的状态和转变嵌入到计算层中。
(未完待续)
2.3. System Software for Thermal and Reliability Optimization
我们讨论了在神经形态硬件上执行SNN应用程序时解决热和可靠性问题的关键系统软件优化方法。
2.4. Application and Hardware Modeling for Predictable Performance Analysis
神经形态平台的设计越来越复杂。为了管理设计复杂性,需要一个可预测的设计流程。结果应该是一个确保SNN应用程序能够在严格的时间期限内执行其操作的系统。这要求可以预测硬件、软件及其交互的时序行为。我们讨论这些设计。
3. Hardware-Software Co-Design
大多数电子系统由执行软件程序的硬件平台组成。硬件-软件协同设计是一种系统设计范式,通过并行设计和优化,利用硬件和软件的协同作用,实现成本、性能、功率和可靠性等系统级目标[195, 49, 196, 197]。类似于许多电子系统设计[198, 151, 199, 200, 58],硬件-软件联合设计也用于神经形态系统的设计[201]。在此,我们回顾了用于软硬件协同设计的软件技术。
4. Outlook
在过去十年中,神经形态计算在硅技术、硬件和软件方面取得了重大进展。这主要是由于摩尔定律的未来值得怀疑,以及对视觉和听觉场景分析和推理等类脑功能的需求日益增长。然而,今天的神经形态硬件节点可以执行几种不同类型的科学计算,而不仅仅限于机器学习。目前尚不清楚如何使用现有软件技术将此类科学计算有效地映射到神经形态硬件上支持的事件驱动操作。如果神经形态计算要集成到涉及CPU和GPU的现有计算工作中,这一点尤为重要。
未来,神经形态系统有望聚合多个异构神经形态硬件节点,以生成一个大规模并行系统,该系统可以解决单节点神经形态硬件过于复杂的科学计算。然而,尽管在软件方面取得了重大的技术进步,但现有的软件技术在如此大规模的系统中的可移植性仍有待观察。最后,神经形态系统的虚拟化为软件技术的研究开辟了一条新的途径。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号