Unsupervised learning of digit recognition using spike-timing-dependent plasticity
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Front. Comput. Neurosci., (2015)
Abstract
为了了解哺乳动物新皮层如何进行计算,需要做两件事。我们需要对可用的神经元处理单元和机制有一个很好的了解,并且我们需要对这些机制如何组合以构建功能性系统有一个更好的了解。因此,近年来,人们越来越关注如何将SNN用于执行复杂的计算或解决模式识别任务。但是,设计使用生物学合理的机制(特别是学习新模式)的SNN仍然是一项艰巨的任务,因为大多数此类SNN架构都依赖于基于发放率的网络中的训练并随后转换为SNN。我们提出了一种用于数字识别的SNN,其基于具有更高生物合理性的机制,即基于电导的突触而不是基于电流的突触,具有时间依赖的权重变化的脉冲时序依赖可塑性,横向抑制和自适应脉冲阈值。与大多数其他系统不同,我们不使用教学信号,也不向网络显示任何类别标签。使用这种无监督的学习方案,我们的结构在MNIST基准上达到了95%的精度,这比以前没有监督的SNN实现要好。我们没有使用任何特定领域的知识这一事实表明我们网络设计的普遍适用性。而且,我们的网络的性能随所用神经元的数量而很好地扩展,并且在四个不同的学习规则下表现出相似的性能,表明机制完全组合的鲁棒性,这表明其在异构生物神经网络中的适用性。
Keywords: spiking neural network, STDP, unsupervised learning, classification, digit recognition
1. Introduction
哺乳动物新皮层仅提供10至20瓦的功耗即可提供无与伦比的模式识别性能(Javed et al., 2010)。因此,不足为奇的是,目前在机器学习,人工神经网络(ANN)或深度神经网络(Hinton and Salakhutdinov, 2006)中最受欢迎的模型受到生物学特性的启发。但是,应该将这种比较打个折扣,因为尽管有生物学启发,但这些模型使用的学习和推断机制与生物学中实际观察到的根本不同。虽然ANN依赖于在单元之间发送的32位甚至64位消息,但新皮质使用的脉冲类似于1位精度(如果忽略了脉冲时间对所传输消息的可能影响)。另外,ANN单元通常是完美的积分器,积分后会应用非线性,这对于真实的神经元而言并非如此。相反,新皮层神经元是相当泄漏的积分器,它们使用基于电导的突触,这意味着由于脉冲引起的膜电压变化取决于当前的膜电压。ANN的另一个非生物学方面是学习的类型。在ANN中,标准的训练方法是反向传播(Rumelhart et al., 1985),在提出输入示例之后,每个神经元都会接收其特定的误差信号,该误差信号用于更新权重矩阵。这样的特定于神经元的误差信号似乎不可能在大脑中实现(O'Reilly and Munakata, 2000),相反,证据更多地指向了无监督学习方法,如脉冲时间依赖可塑性(STDP)(Bi and Poo, 1998),可以通过全局奖励信号进行调节,因此也可以用于强化学习。
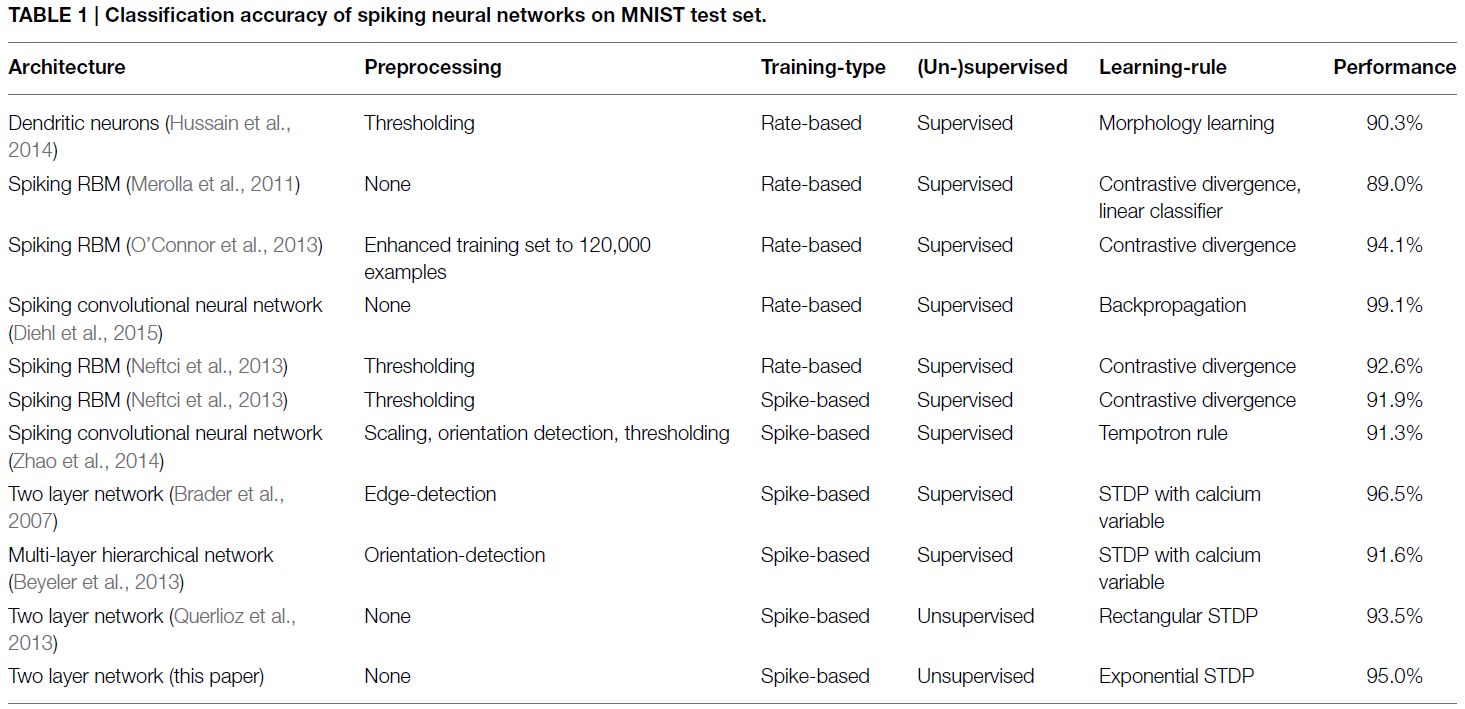
另一方面,计算神经科学中的许多模型都很好地仿真生物学特性,但通常不是大规模的功能系统。但是,了解新皮层的计算原理需要两个方面,即生物学合理性和在模式识别任务上的良好性能。如果我们只关注生物学合理性,即使我们能够开发功能系统,也很难知道计算所需的机制,即能够复制系统并不一定会导致理解。同样地,如果我们只专注于良好的性能,我们将创建一个运行良好的系统,但是由于它们过于抽象而无法将它们与真实大脑的计算基元进行比较,因此也不会导致更好的理解。近年来,针对模式识别任务开发了许多模型,这些模型使用了生物学上更合理的机制,并结合了两种理解方法。一种流行的方法是仍然依靠反向传播训练,但是之后将ANN转换为SNN,我们将其称为"基于发放率的学习"(Merolla et al., 2011; O'Connor et al., 2013; Hussain et al., 2014; Neil and Liu, 2014; Diehl et al., 2015)。尽管它们在诸如经典机器学习基准MNIST (LeCun et al., 1998)之类的任务上显示出非常好的性能,但是这种基于发放率的学习在生物学上不是很合理,或者至少从生物学机制中非常抽象。其他基于脉冲的学习方法通常依赖于STDP模型的不同变体(Brader et al., 2007; Habenschuss et al., 2012; Beyeler et al., 2013; Querlioz et al., 2013; Zhao et al., 2014),为学习过程提供与生物学的更紧密匹配。但是,大多数模型都依赖于教学信号,该教学信号为用于分类的每个单个神经元提供指示正确响应的反馈,从而将问题转移到已经需要知道解决方案的“主管神经元”。同样,它们通常使用神经元/突触模型中的特征,这些特征使学习变得更容易,但不一定具有生物学合理性。示例包括具有高度特定于应用程序的参数调整或基于电流的突触的STDP模型,这两种模型通常都不使用通过实验观察到的梯度权重变化或梯度电流。
在此,我们介绍了一个SNN,该网络依赖于生物学合理的机制的组合,并使用无监督学习,即网络的权重无需输入标签即可学习输入示例的结构。它使用的架构类似于Querlioz et al. (2013)提出的架构,即它使用了LIF神经元,STDP,横向抑制和固有可塑性。但是,这里我们使用更多的生物学合理的成分,例如基于电导的突触和不同的STDP规则,所有这些都与权重变化呈指数时间依赖性。改变学习规则设计的可能性表明了所用机制组合的鲁棒性。我们正在MNIST数据集上训练网络,而无需对数据进行任何预处理(除了将强度图像转换为脉冲序列的必要转换)。该方法的性能与网络中神经元的数量很好地缩放,并使用6400个学习神经元达到95%的精度。改变学习规则但保持其他机制不变,不仅显示了框架的鲁棒性,而且还有助于更好地理解不同观察到的机制类型之间的关系。具体而言,我们观察到侧向抑制会在神经元之间产生竞争,内平衡有助于使每个神经元都有公平的竞争机会,并且在这种设置下,兴奋性学习导致学习原型输入作为感受野(很大程度上独立于所使用的学习规则)。
在下一节中,我们将说明包含神经元和突触模型的结构,以及训练和评估过程。第3节包含仿真结果,在第4节中,我们将我们的结果与其他架构的结果进行比较,并直观地了解我们的网络如何工作。
2. Methods
要仿真使用Python和BRIAN仿真器(Goodman and Brette, 2008)1的SNN。在此,我们描述了神经元在单个突触中的动态,然后描述了网络架构和所使用的机制,最后我们对MNIST的训练和分类过程进行了说明。
2.1. Neuron and Synapse Model
为了对神经元动态进行建模,我们选择了LIF模型。膜电压V用下式进行描述:
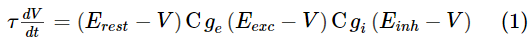
其中Erest是静息膜电位,Eexc和Einh分别是兴奋性和抑制性突触的平衡电位,ge和gi分别是兴奋性和抑制性突触的电导。正如在生物学中观察到的,我们使用时间常数τ,对于兴奋性神经元而言,其时间要长于抑制性神经元。当神经元的膜电位超过其膜阈值vthres时,神经元发放,其膜电位被重置为vreset。在重置后的几毫秒内,神经元处于其不应期,无法再次发放脉冲。
突触通过电导变化建模,即,当突触前脉冲到达突触时,突触会立即通过突触权重w增大其电导,否则电导将呈指数衰减。如果突触前神经元是兴奋性的,则电导ge的动态为:
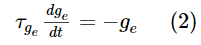
其中![]() 为兴奋性突触后电位的时间常数。类似地,如果突触前神经元具有抑制作用,则使用相同的公式更新电导gi,但使用抑制性突触后电位的时间常数
为兴奋性突触后电位的时间常数。类似地,如果突触前神经元具有抑制作用,则使用相同的公式更新电导gi,但使用抑制性突触后电位的时间常数![]() 。
。
我们对仿真中的几乎所有参数都使用生物学合理的范围,包括膜,突触和学习窗口的时间常数(Jug, 2012)。例外是兴奋性神经元的膜电压的时间常数。将兴奋性神经元膜电位的时间常数增加到100毫秒(对于生物神经元通常观察到的10到20毫秒),大大提高了分类精度。原因是使用发放率编码来表示输入,请参见第2.5节,因此较长的神经元膜常数可以更好地估计输入发放率。例如,如果识别神经元只能以最大输入发放率63.75 Hz对20 ms以上的输入进行积分,则神经元平均只会对1.275个以上的脉冲进行积分,这意味着单个噪声脉冲会产生较大的影响。通过将膜时间常数增加到100 ms,神经元平均可以积分超过6.375个脉冲,从而减少了噪声的影响。输入脉冲太少的问题仅存在,因为该结构使用的输入神经元的数量比生物学观察到的要少得多,从而提高了仿真速度。输入神经元数量的增加将允许相同的平均效果。
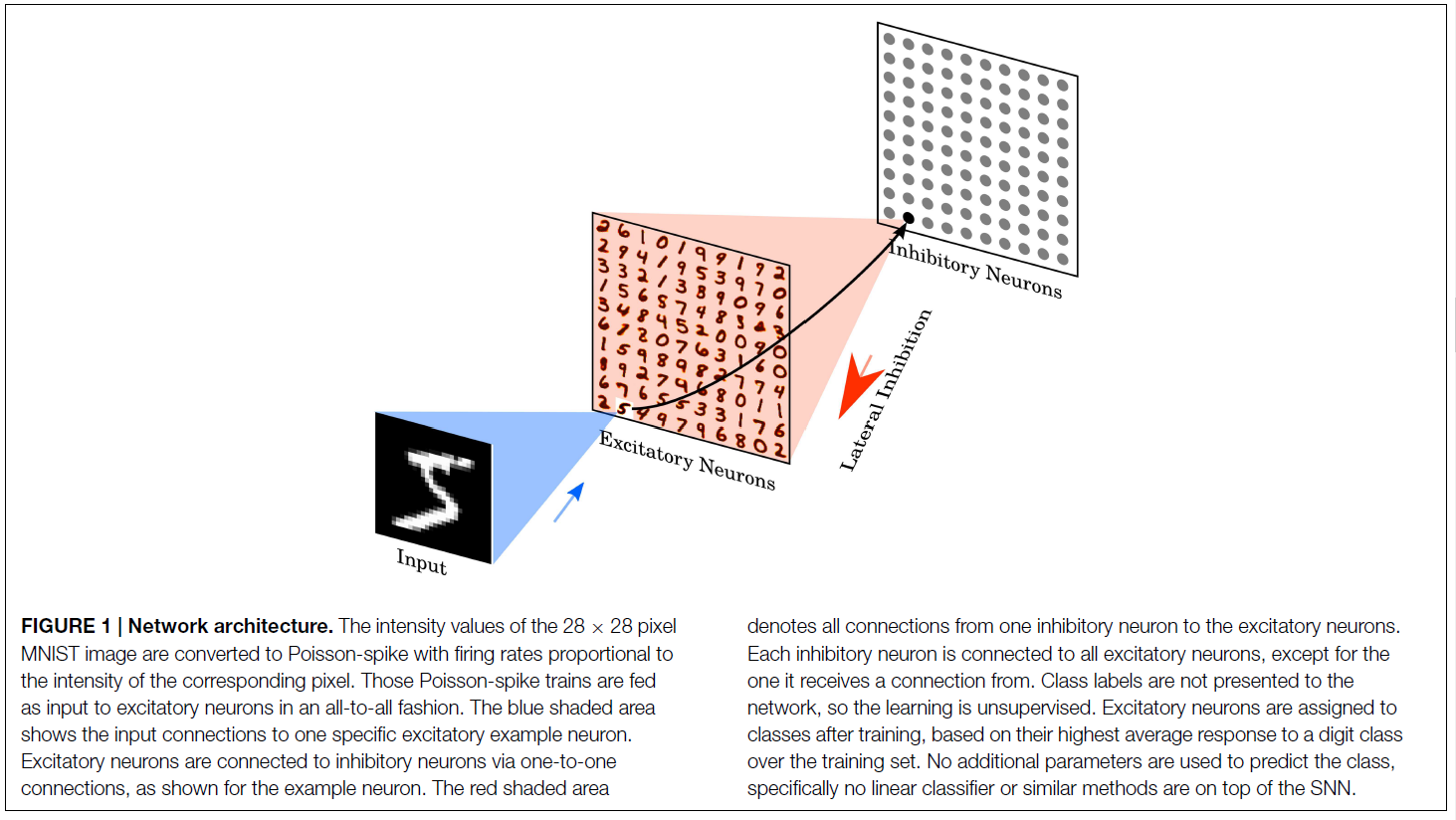
2.2. Network Architecture
该网络由两层组成,请参见图1。第一层是输入层,包含28×28个神经元(每个图像像素一个神经元),第二层是处理层,包含可变数量的兴奋性神经元以及尽可能多的抑制性神经元。每个输入都是一个Poisson脉冲序列,它被馈送到第二层的兴奋性神经元。每个神经元的发放率与示例图像中相应像素的强度成正比,请参见第2.5节。
第二层的兴奋性神经元以一对一的方式连接到抑制性神经元,即,兴奋性神经元中的每个脉冲将触发其相应的抑制性神经元中的脉冲。每个抑制性神经元都与所有兴奋性神经元相连,但与之相连的神经元除外。这种连通性提供了横向抑制,并导致兴奋性神经元之间的竞争。抑制兴奋性突触的最大电导固定为10 nS。但是,精确值对仿真结果的影响不大,相反,必须平衡抑制性突触传导与兴奋性突触传导之间的比率,以确保横向抑制作用不会太弱(这意味着它没有任何影响力),也不过分强大(这意味着一旦选择了获胜者,获胜者就会阻止其他神经元发放)。
2.3. Learning
使用STDP学习从输入神经元到兴奋性神经元的所有突触。为了提高仿真速度,使用突触轨迹计算权重动态(Morrison et al., 2007)。这意味着,除了突触权重之外,每个突触都跟踪另一个值,即突触前迹xpre,该值建模最近的突触前脉冲历史。每次突触前脉冲到达突触时,迹增加1,否则xpre呈指数衰减。当突触后脉冲到达突触时,根据突触前轨迹计算权重变化Δw:

其中η是学习率,wmax是最大权重,μ决定更新对先前权重的依赖性。xtar是突触后脉冲时刻的突触前迹的目标值。目标值越高,突触权重就越低。该偏移量确保很少导致突触后神经元发放的突触前神经元将变得越来越疏远,如果突触后神经元仅很少活跃,则特别有用。通过向输入添加一些噪声并为学习规则添加权重降低机制(如在经典的STDP,Bi and Poo, 1998)以断开无关的输入,可以达到类似的效果。但是,在我们的仿真中,这是以增加仿真时间为代价的。学习规则类似于Querlioz et al. (2013)使用的规则,但在此我们使用指数时间依赖性,这在生物学上似乎比时间相关的权重变化更合理(Abbott and Song, 1999)。
为了将所选架构的鲁棒性与学习规则的确切形式进行比较,我们测试了其他三种STDP学习规则。第二条STDP规则使用指数权重依赖性(Nessler et al., 2013; Querlioz et al., 2013)计算权重变化:

其中β决定权重依赖性的强度。
第三个规则不仅使用突触前迹,还使用突触后迹,其工作方式与突触前迹相同,但其增加是由突触后脉冲触发的。此外,对于该学习规则,突触前和突触后脉冲的权重发生变化。突触前脉冲的权重变化Δw为:
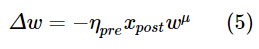
其中ηpre是突触前脉冲的学习率,而μ决定权重依赖性。突触后脉冲的权重变化为:
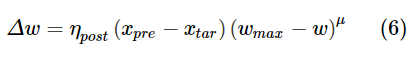
其中ηpost是学习率,wmax是最大权重,xtar是突触后脉冲时刻的突触前迹的目标均值。
此外,我们使用三元STDP规则了解了网络的权重(Pfister and Gerstner, 2006)。由于此规则不使用任何权重依赖性进行学习,因此我们要么将其纳入规则中,要么需要以其他形式限制权重。在此,我们使用除法权重归一化(Goodhill and Barrow, 1994),这确保神经元的平等使用。
请注意,幂律和指数权重相关性STDP规则的优点是,仅当突触后兴奋性神经元发放脉冲时才触发权重更新。由于突触后神经元的发放率非常低,因此用于突触后发放的更复杂的STDP更新不需要很多计算资源。对称学习规则和三元组规则在计算上使用软件仿真(特别是对于较大的网络)进行仿真比较昂贵,因为对于每个突触前事件,必须为每个单独突触后神经元计算权重变化。
2.4. Homoeostasis
网络的输入基于MNIST数据集,其中包含60000个训练示例和10000个测试示例,这些示例包含数字0–9的28×28像素图像(LeCun et al., 1998)。输入以Poisson分布脉冲序列的形式在350毫秒内呈现给网络,发放率与MNIST图像像素的强度成比例。具体来说,最大像素强度255除以4,导致输入发放率介于0到63.75 Hz之间。此外,如果第二层中的兴奋神经元在350毫秒内发放少于五个脉冲,则最大输入发放率将增加32 Hz,并且该示例将再次出现350毫秒。重复该过程,直到在提出特定示例的整个过程中至少发放五个脉冲为止。
2.5. Input Encoding
网络的输入基于MNIST数据集,其中包含60000个训练示例和10000个测试示例,这些示例包含数字0–9的28×28像素图像(LeCun et al., 1998)。输入以Poisson分布脉冲序列的形式在350毫秒内呈现给网络,发放率与MNIST图像像素的强度成比例。具体来说,最大像素强度255除以4,导致输入发放率介于0到63.75 Hz之间。此外,如果第二层中的兴奋神经元在350毫秒内发放少于五个脉冲,则最大输入发放率将增加32 Hz,并且该示例将再次出现350毫秒。重复该过程,直到在提出特定示例的整个过程中至少发放五个脉冲为止。
2.6. Training and Classification
为了训练网络,我们将MNIST训练集中的数字(60000个示例)呈现给网络。呈现新图像之前,要有150 ms的相位,没有任何输入,以使所有变量都能下降到其静止值(自适应阈值除外)。训练完成后,将学习率设定为零,固定每个神经元的脉冲阈值,并基于训练集表示形式的十个数字类别的最高响应,给每个神经元分配一个类别。
类别分配的神经元的响应用于测量MNIST测试集上网络的分类精度(10000个示例)。预测的数字由每个神经元的每个响应的均值确定,然后选择具有最高平均发放率的类别。

3. Results
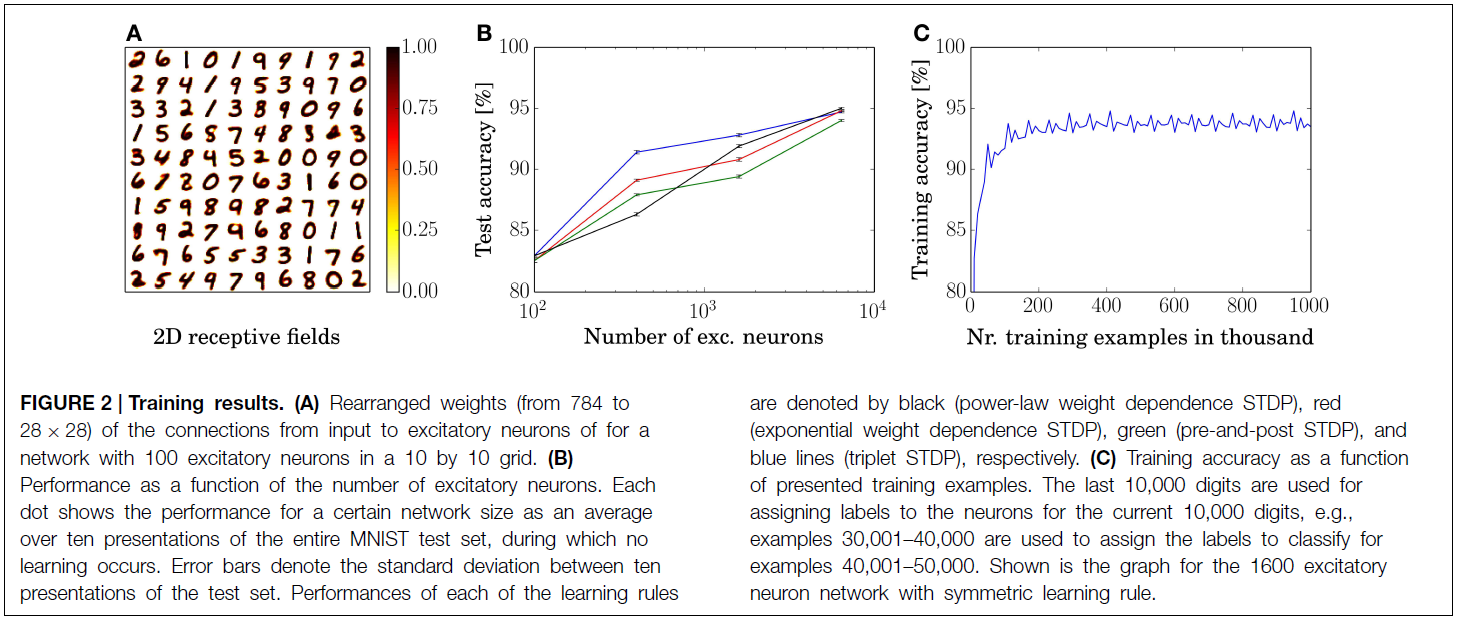
通过展示40,000个示例性的MNIST训练集,对具有100个兴奋神经元的网络进行了训练和测试。兴奋性神经元权重的重新排列输入如图2A所示。 对于每个神经元,其784维输入向量的排列顺序为28×28矩阵,以可视化表示神经元学习了原型输入。
除了100个神经元网络外,我们通过展示整个MNIST训练集的3, 7和15次来训练和测试其他三个具有400, 1600和6400兴奋性神经元的网络。对于幂律权重相关性STDP规则,这四个网络的平均分类精度分别为82.9, 87.0, 91.9和95.0%。对于所有仿真,我们使用相同的神经元,突触和STDP参数(除了需要适应自适应阈值和抑制强度的参数,以保持一个常数响应率)。精度是MNIST测试集的10000个示例的平均表示形式,请参见图2B。由于MNIST测试集的强度图像已转换为Poisson分布式脉冲序列,因此精度可能会因不同的脉冲时间而有所不同。但是,如图2B的误差条所示,性能的标准差在整个测试集的十个表示形式(使用相同的训练过的网络)很小(≈0.1%)。
图2B中还显示了其余三种学习规则的性能,其中指数权重相关性显示为红色,使用pre-and-post STDP的性能显示为绿色,使用三重态STDP规则的性能显示为蓝色。图2C中显示了具有对称规则的1600神经元网络的训练精度。在大约200000个示例的性能接近于收敛之后,甚至有100万个示例的性能也没有下降,而是保持稳定。请注意,此周期性结构是MNIST训练集的重复形式。对于所有的网络大小和学习规则,这个趋势是相同的。但是,更大的网络需要更长的训练时间,直到达到峰值性能。
使用标准STDP规则对6400个神经元的网络进行误差分析,如图3所示。图3A显示了MNIST测试集的十个表示形式上的平均混淆矩阵,即,测试示例的每个分类都属于10×10 tiles之一,并且其位置由实际数字和推断数字确定。毫不奇怪,在分类率为95%的情况下,大多数示例都在对应于正确分类的标识上;更有趣的是错误分类的示例。最常见的混淆是4被标识为9 (57次),而7被标识为9 (40次),而7被标识为2 (26次)。虽然很容易混淆4和9以及7和2,但看起来7明显并不太可能被误认为是9。可能的解释可以在图3B中看到。错误分类的7和典型的9之间的唯一区别通常是7中的中间水平笔画不与上笔画相连,这意味着具有9接受力的神经元也可能会触发。
由于每个神经元仅对输入数字的很小子集做出响应,因此响应非常稀疏,每个示例只有很少的脉冲被触发。即使在具有6400个兴奋性神经元的最大网络中,也只有≈17个脉冲会响应一位数的表示而发放。具体而言,对于正确识别的示例,相同类别的神经元发放≈16个脉冲,而分配给不同类别的神经元发出≈1个脉冲,而对于错误识别的示例,正确类别的神经元发放≈3个脉冲,而其他类别的神经元发放≈12个脉冲。
4. Discussion
4.1. Comparison
4.2. Inhibition
4.3. Spike-based Learning for Machine Learning
4.4. Competitive Learning
4.5. Robustness of Learning


 浙公网安备 33010602011771号
浙公网安备 33010602011771号