

Towards spike-based machine intelligence with neuromorphic computing
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
参考知乎:Nature 长文综述:类脑智能与脉冲神经网络前沿 - 知乎 (zhihu.com)

Nature | Vol 575 | 28 November 2019 | 607
Abstract
在类脑"脉冲"计算框架的指导下,神经形态计算(用于机器智能的类脑计算)有望实现人工智能,同时降低计算平台的能源需求。这个跨学科领域始于生物神经程序的硅电路的实现,但已经发展到包含基于脉冲的编码和事件驱动表示的算法的硬件实现。在此,我们概述了算法和硬件的神经形态计算的发展,并强调了学习和硬件框架的基础知识。我们讨论了神经形态计算的主要挑战和未来前景,重点是算法-硬件协同设计。
Introduction
纵观历史,创造具有类脑能力的技术一直都是创新的源泉。从前,科学家们一直以为人脑中的信息是通过不同的通道和频率传递的,就像无线电一样。如今,科学家们认为人脑就像一台计算机。随着神经网络的发展,今天的计算机已在多个认知任务中展现出了非凡的能力,例如,AlphaGo在围棋战略游戏Go1中击败了人类选手。虽然这种表现的确令人印象深刻,但一个关键问题仍然存在:这些活动涉及的计算成本有多大?
人脑能够执行惊人的任务(例如,同时识别多个目标、推断、控制和移动),而能耗只有接近20瓦左右2。相比之下,标准计算机仅识别1000种不同的物体就需要消耗250瓦的能量3。尽管人脑尚未被探索穷尽,但从神经科学来看,人脑非凡的能力可归结于以下三个基本观察:广泛的连通性、结构和功能化的组织层次、以及时间依赖的神经元突触连接4,5(图1a)。神经元是人脑的计算原始元素,它通过离散动作电位或"脉冲"交换和传递信息。突触是记忆和学习的基本存储元素。人脑拥有数十亿个神经元网络,通过数万亿个突触相互连接。基于脉冲的时间处理机制使得稀疏且有效的信息在人脑中传递。研究还表明,灵长类动物的视觉系统由分层级的关联区域2组成,这些关联区域逐渐将视觉对象的映像转化为一种具有鲁棒性的格式,从而促进了感知能力。
目前,最先进的人工智能总体上使用的是这种受到人脑层次结构和神经突触框架启发的神经网络。实际上,现代深度学习网络(DLNs)本质上是层级结构的人造物,就像人脑一样用多个层级去表示潜在特征,由来自输入过程中多个图层的不同潜在特征的表征,经过转换形成的6(图1b)。硅晶体管硬件计算系统是这种神经网络的硬件基本。大规模计算平台的数字逻辑包含由集成在单个硅芯片上的数十亿个晶体管。这让人联想到了人脑的层级结构:各种硅基计算单元以层级方式排列,以实现高效的数据交换(图1c)。
尽管两者在表面上有相似之处,但人脑的计算原理和硅基计算机之间存在着鲜明区别。其中包括:(1) 计算机中计算(处理单元)和存储(存储单元)是分离的,不同于人脑中计算(神经元)和存储(突触)是一体的;(2) 受限于二维连接的计算机硬件,人脑中大量存在的三维连通性目前无法在硅基技术上进行模拟;(3) 晶体管主要为了构建确定性布尔(数字)电路开关,和人脑基于脉冲的事件驱动型随机计算不同。尽管如此,在当前的深度学习革命中,硅基计算平台(例如图像处理单元(GPU)云服务器)已成为一个重要的贡献因素。但是,使得"通用智能"(包括基于云服务器到边缘设备)无法实现的主要瓶颈是巨大的能耗和吞吐量需求。例如,在一个由典型的2.1Wh电池供能的嵌入式智能玻璃处理器(smart-glass processor)上运行深度网络,就会让处理器在25分钟内将电池消耗殆尽。
在人脑的指引下,通过脉冲驱动通信从而实现了神经元-突触计算的硬件系统将可以实现节能型机器智能。神经形态计算始于20世纪80年代晶体管仿照神经元和突触的功能运作(图2),之后其迅速演化到包括事件驱动的计算本质(离散的"脉冲"人造物)。最终,在21世纪初期,这种研究努力促进了大规模神经形态芯片的出现。今天,算法设计师们正在积极探索(特别是"学习")脉冲驱动型计算的优缺点,去推动有可扩展性、高能效的"脉冲神经网络"(spiking neural networks, SNN)。在这种情况下,我们可以将神经形态计算领域描述为一种协同工作,它在硬件和算法域两者中权重相同,以实现脉冲型人工智能。我们首先强调了"智能"(算法)方面,包括不同的学习机制(无监督以及基于脉冲的监督,或梯度下降方案),同时突出显示了要利用基于时空事件的表征。本文讨论的重点是视觉相关的应用任务,例如图像识别和检测。然后我们将探索"计算"(硬件)方面,包括模拟计算、数字神经运动系统,它们都超越了冯·诺依曼(数字计算系统的最新架构)和芯片技术(代表了基本的场效应晶体管设备,它们是当下计算平台的基础)。最后,我们将讨论算法的硬件协同设计前景,说明算法具有用于对抗硬件漏洞的鲁棒性,可以实现能耗和精度之间的最佳平衡。
图1:生物和硅基计算的关键属性构架。a,大脑的组织原理示意图。神经元和突触与时间脉冲处理交织在一起的网络使得不同区域之间的信息能够快速高效地流动。b,一个深度卷积神经网络物体执行目标检测的图片。这些网络是多层的,并使用突触存储和神经元非线性学习广泛的数据表示。使用反向传播训练后,每层学习的特征都显示有趣的模式。第一层学习一般特征,如边缘和颜色斑点。随着我们深入网络,学习到的功能变得更具体,用目标的部分(如狗的眼睛或鼻子)代表完整的目标(如狗的脸)。这种从一般到特殊的过渡代表了视觉皮层的层次结构。c,最先进的硅计算生态系统。广义上讲,计算层次分为处理单元和内存存储。处理单元和内存层次结构的物理分离导致众所周知“内存墙瓶颈(memory well bottleneck)” 。当今的深度神经网络在强大的云服务器上训练,尽管会产生巨大的能耗,但仍可提供令人惊叹的精度。

图2:智能计算的重大发现和进展时间表(从1940年代到现在)6,10,14,73,78,84,93,105,115,136,150,151。硬件方面,我们有从两个角度展示发现:一是对神经形态计算的启迪,或通过硬件创新实现类人脑的计算和“智能”;另一方面是对计算效率的启发,或者实现更快、更节能的布尔计算。从算法的角度来看,我们已指出这些发现是出于理解人脑的动机,受到神经科学和生物科学的驱动,并同时致力于实现人工智能,它由工程和应用科学所驱动。请注意,这张图并不是完整或全面的清单。“当前研究”并不一定意味着过去没有对这些努力进行探索;相反,我们强调了该领域正在进行和有希望研究的关键方面。
Algorithmic outlook
Spiking neural networks
按照神经元功能,Maass开创性的论文将神经网络分为三个代际。首先,第一代被称为McCulloch–Pitt感知机,它执行阈值运算并输出数字(1, 0)10。基于sigmoid单元或整流线性单元11(ReLU),第二代神经元单元增加了连续非线性,使其能够计算一组连续的输出值。第一代和第二代网络之间的非线性升级在扩展神经网络向复杂应用和更深度的实现方面起着关键作用。当前的DLNs在输入和输出之间具有多个隐藏层,都是基于第二代神经元。实际上,由于它们连续的神经元功能,这些模型可以支持基于梯度下降的反向传播学习,这也是目前训练深度神经网络的标准算法。第三代神经网络主要使用"整合发放"(integrate-and-fire)型脉冲神经元,通过脉冲交换信息(图3)。
第二代和第三代神经网络之间最大的区别在于信息处理性质。第二代神经网络使用了实值计算(例如,信号振幅),而SNN则使用信号的时间(脉冲)处理信息。脉冲本质上是二值事件,它是0或1。如图3a所示,SNN中的神经元单元只有在接收或发出脉冲信号时才处于活跃状态,因此它是事件驱动型的,因此可以使其节省能耗。若无事件发生SNN单元则保持闲置状态,这与DLN相反。无论实值输入和输出,DLN所有单位都处于活跃状态。此外,SNN中的输入值为1或0,这也减少了数学上的点积运算Σi Vi × wi (图3a),减小了求和的计算量。
针对不同的生物合理性水平下产生的脉冲代际,相关的脉冲神经元模型已被提出。例如泄漏整合发放型(LIF)(图3b)和Hodgkin–Huxley型13。同样,针对于突触可塑性,已有例如Hebbian14和non-Hebbian方案被提出15。突触可塑性即突触权重的调节(在SNN中转化为学习)取决于突触前和突触后脉冲的相对时间(图3c)。神经形态工程师的一个主要目标是:在利用基于事件(使用基于事件的传感器)及数据驱动更新的同时,建立一个具有适当突触可塑性的脉冲神经元模型,从而实现高效的识别、推断等智能应用。
Exploiting event-based data with SNNs
我们认为,SNN最大的优势在于其能够充分利用基于时空事件的信息。今天,我们有相当成熟的神经形态传感器16,18,来记录环境实时的动态改变。这些动态感官数据可以与SNN的时间处理能力相结合,以实现超低能耗的计算。实际上,与传统上DLN使用的帧驱动的方法相比,SNN将时间作为附加的输入维度,以稀疏的方式记录了有价值的信息(图3),从而实现高效的SNN框架,并通过计算视觉光流19,20或立体视觉来实现深度感知21,22。结合基于脉冲的学习规则,它可以产生有效的训练。机器人界的研究者已经证明使用基于事件的传感器进行跟踪和手势识别以及其他应用的优势19,21,22。但是,这些应用程序大多数都使用了DLN来执行识别。
在此类传感器中使用SNN主要受限于缺乏适当的训练算法,从而可以有效地利用脉冲神经元的时间信息。实际上就精度而言,在大多数学习任务中SNN的效果仍落后于第二代深度学习。很明显,脉冲神经元可以实现非连续的信息传递,并发出不可微分的离散脉冲(见图3),因此它们不能使用基于梯度下降型的反向传播技术,而这是传统神经网络训练的基础。
另外,SNN还受限于基于脉冲的数据可用性。虽然理想情况要求SNN的输入是带有时间信息的序列,但SNN训练算法的识别性能是在现有静态图像的数据集上进行评估的,例如CIFAR或ImageNet24。然后,此类基于静态帧的数据将通过适当的编码技术(例如发放率编码或秩序编码,见图3d)转换为脉冲序列。虽然编码技术使我们能够评估SNN在传统基准数据集上的性能,但我们要超越静态图像分类的任务。SNN的最终能力应当来自于它们处理和感知瞬息万变的现实世界中的连续输入流,就像人脑轻而易举所做的那样。目前,我们既没有良好的基准数据集,也没有评估SNN实际性能的指标。收集更多适当的基准数据集的研究,例如动态视觉传感器数据或驾驶和导航实例,便显得至关重要。
(这里我们指的是作为DLN的第二代连续神经网络,以区别于基于脉冲的计算。我们注意到SNN可以在具有卷积层次结构的深度架构上实现,并同时执行脉冲神经元功能。)
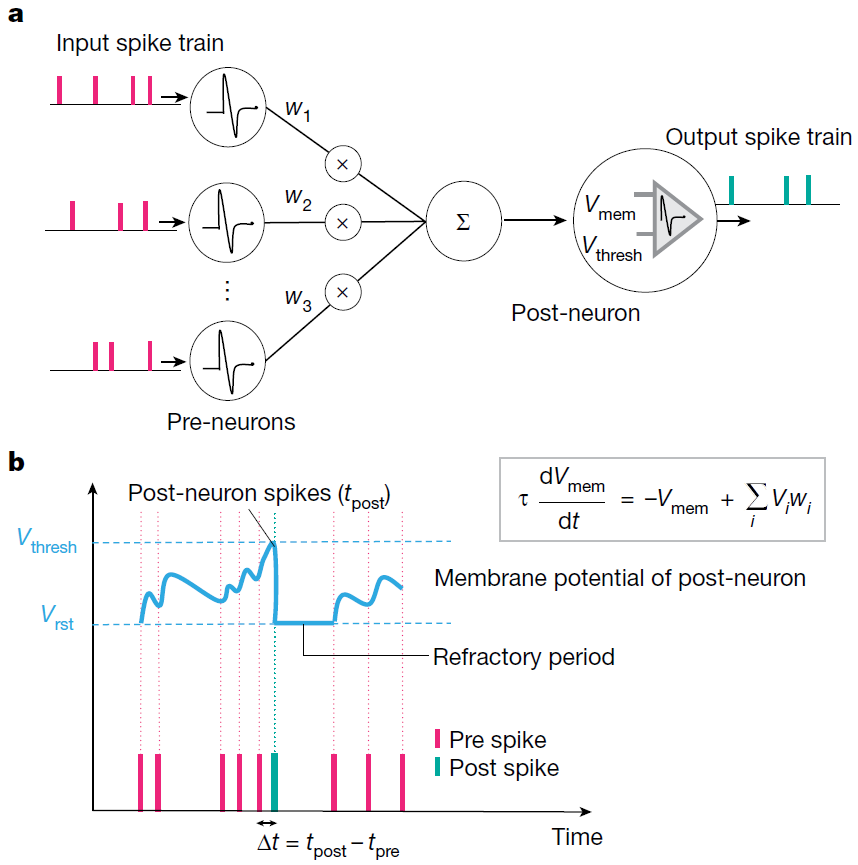
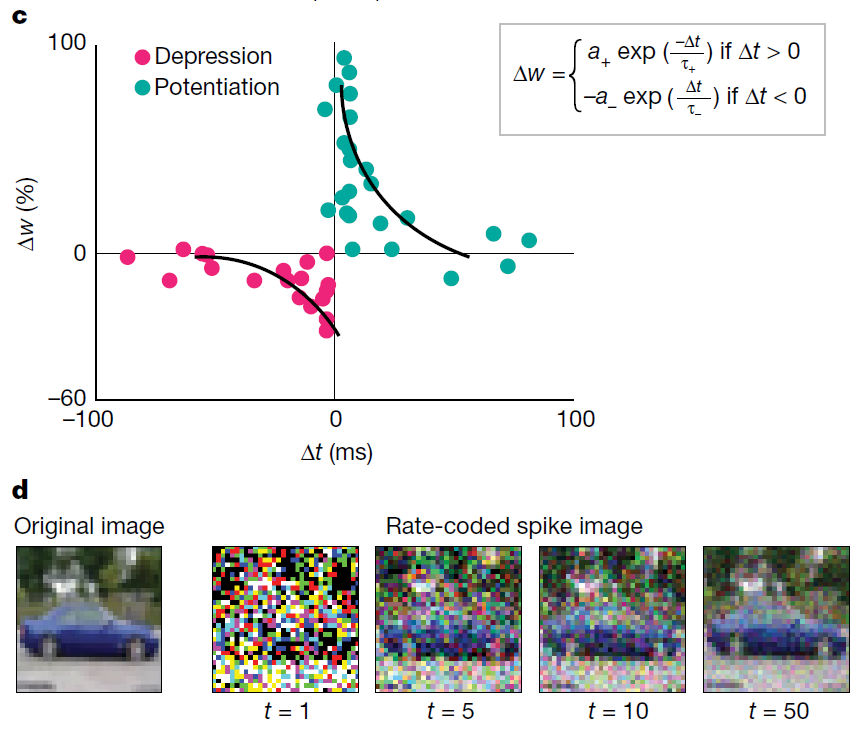
图3:SNN计算模型。a,由输入上游神经元驱动的下游神经元组成的神经网络。上游神经脉冲Vi通过突触权重wi调节,在给点时间内产生合成电流Σi Vi × wi (相当于点积运算)。产生的合成电流会影响下游神经元的膜电位。b,LIF脉冲神经元的动力学显示。在没有脉冲的情况下,膜电位Vmem在时间常数 τ 中集成了传入脉冲和泄漏。当Vmem超过阈值Vthresh时,下游神经元输出脉冲。随之产生不应期,在此期间后神经元的Vmem不再受到影响。c,显示了基于实验数据的脉冲时序依赖可塑性(STDP)公式,其中a+,a-,τ+和τ-是控制权重变化Δw的学习率和时间常数。突触权重wi根据上游神经元与下游神经元脉冲的时间差(Δt = tpost − tpre)更新。d,使用发放率编码将输入图像(静态帧数据)转换为脉冲在各个时间步长上的映射。每个像素产生一个泊松脉冲序列,其发放率与像素强度成正比。当几个时间步求和得出脉冲映射时(标记为t = 5的脉冲映射是从t = 1到t = 5的映射总和),它们开始类似于输入。因此,基于脉冲的编码既保留了输入图像的完整性,并且在时域中对数据进行了二值化。结果显示,LIF行为和随机输入脉冲的产生使SNN的内部动力学具有随机性。注意,秩序编码也可以用来生成脉冲数据25。
Learning in SNNs
Conversion-based approaches
基于转换的方法的思路是获得一个SNN,对给定的任务,该SNN将产生与DLN相同的输入-输出映射。本质上,使用权重缩放和归一化方法将一个训练好的DLN转换为SNN,将非线性连续输出神经元的特征和脉冲神经元的泄漏时间常数,不应期、膜阈值以及其他功能相匹配29-34。迄今为止,在图像分类的大型脉冲网络中(包括ImageNet数据集),这种方法能够产生有竞争力的精确度。在基于转换的方法中,其优点是免除了时域中的训练负担。DLN使用了已有的深度学习框架例如Tensorflow35对基于帧的数据进行训练,这些工具提供了训练中的灵活性。这种转换首先需要在基于事件的数据(通过对静态图像数据集进行发放率编码获得)上解析训练后的DLN,之后再进行简单的转换。但是,这种方法有其内在的局限性。例如在使用双曲线正切(tanh)或归一化指数函数(softmax)后,非线性神经元的输出值可以得正也可以得负,而脉冲神经元的发放率只能是正值。因此,负值总被丢弃,导致转换后的SNN的精度下降。转换的另一个问题是在不造成严重的性能损失的前提下获得每一层最佳。最近的研究29-31提出了确定最佳发放率的实用解决方案,以及在DLN的训练过程中引入其他约束(例如噪声或leaky ReLU)以更好地匹配脉冲神经元的发放率36。当前,转换方法可为图像识别任务提供最先进的精度,并与DLN的分类性能相当。值得注意的是,从DLN转换的SNN的推理时间变得很长(约几千个时间步骤),导致延迟以及能耗增加。
图4:脉冲网络中的全局和局部学习原理。a,在已知目标标签指导下进行全局监督学习,T用于分类任务。给定一个前馈网络,网络通过隐藏层单位A向前传播输入值X,并输出神经元激活值Y。结合非线性变换ƒ(Z1),使用输入的加权求和可以计算隐藏层的A,用矩阵符号表示为![]() 。输出以类似的方式进行计算。然后,用误差E相对于权重(W1, W2)的导数求出随后的权重更新。前向和反向传播的迭代导致学习。误差求导需要ƒ',这要求ƒ'是连续的。因此,基于脉冲的反向传播的规则近似LIF函数的可微方案。基于时间信息的处理细节没有显示在这里。b,局部STDP数字分类无监督学习。给定一个两层拓扑结构,输入层与输出层的所有神经元完全连接,通过STDP学习突触连接。根据输入层和输出层神经元的脉冲时间差异进行权重调整。输入神经元在输出之前(或之后)发放,权重值将增加(或减小)。随着迭代在多个时间步骤上进行训练,权重在初始化时随机赋值,通过训练它将学习对一类输入所示的样式进行通用表示的编码(在这种情况下为'0', '1'和'2')。这里,为了进行识别,目标标签是不需要的。
。输出以类似的方式进行计算。然后,用误差E相对于权重(W1, W2)的导数求出随后的权重更新。前向和反向传播的迭代导致学习。误差求导需要ƒ',这要求ƒ'是连续的。因此,基于脉冲的反向传播的规则近似LIF函数的可微方案。基于时间信息的处理细节没有显示在这里。b,局部STDP数字分类无监督学习。给定一个两层拓扑结构,输入层与输出层的所有神经元完全连接,通过STDP学习突触连接。根据输入层和输出层神经元的脉冲时间差异进行权重调整。输入神经元在输出之前(或之后)发放,权重值将增加(或减小)。随着迭代在多个时间步骤上进行训练,权重在初始化时随机赋值,通过训练它将学习对一类输入所示的样式进行通用表示的编码(在这种情况下为'0', '1'和'2')。这里,为了进行识别,目标标签是不需要的。
Spike-based approaches
在基于脉冲的方法中,SNN使用时间信息进行训练,因此在整体脉冲动态中具备明显的稀疏性和高效率优势。研究人员采用了两种主要方向37:无监督学习(没有标记数据的训练),以及监督学习(有标记数据的训练)。早期监督学习成果是ReSuMe38和tempotron39,它们证明了在单层的SNN中,可以使用脉冲时序依赖可塑性(STDP)的变体去进行分类。从那时起,研究工作一直致力于整合基于脉冲且类似于全局反向传播的误差梯度下降法,以便在多层SNN中实现监督学习。大多数依赖反向传播的成果为脉冲神经元功能估计了一个可微的近似函数,从而使其能够执行梯度下降法(图4a)。SpikeProp40及其相关变体41,42已派生出通过在输出层固定一个目标脉冲序列来实现SNN的反向传播规则。最近的成果43-46对实值膜电位使用随机梯度下降法,是为了让正确输出神经元随机发放更多的脉冲(而不是具有精确目标的脉冲序列)。这些方法在深度卷积SNN的小规模图像识别任务上取得了最新进展,例如MNIST(美国国家标准与技术研究所)手写数字数据库的数字分类。然而,尽管计算效率更高,监督学习在大型任务的精度上无法超过基于转换的方法。
另一方面,受到神经科学和硬件效率为主要目标的启发,基于局部STDP学习规则的无监督SNN训练48也很有意思。通过局部学习(我们将在后面的硬件讨论中看到),有机会使记忆(突触存储)和计算(神经元输出)更紧密地相结合。这种架构更像人脑,也适合节能芯片上实现。Diehl等人49率先证明了完全无监督的SNN学习,其精度可与MNIST数据库深度学习相媲美(图4b)。
但是,将局部学习方法扩展到多层复杂任务是一个挑战。随着网络的深入,神经元的脉冲概率(或发放率)会降低,我们称之为"消失的前向脉冲传播"。为了避免这种情况,多数工作46,48,50-53首先用逐层的方式训练多层SNN(包括卷积SNN),进行基于脉冲的局部学习,然后进行全局反向传播学习,以去进行分类。这样局部-全局结合的方法尽管很有成效,但在分类精度方面仍落后于转换方法。此外,最近的成果54,55显示了概念验证,即通过深度SNN中反馈连接误差信号的随机投影确实有助于改善学习。这种基于反馈的学习方法需要进一步研究,以评估其在大规模任务上的效果。
Implications for learning in the binary regime
我们可以通过仅用二值(1/0)位值,而不是需要额外内存的16位或32位浮点值来获得超低能耗和高效计算。实际上在算法层级,目前正在研究以概率方式学习(其中神经元随机脉冲,权重低精度转换)获得参数较少的网络和计算操作56-58。二元和三元的DLN也被提出,其神经元输出和权重只取低精度值-1、0和+1,而且在大规模分类任务中表现良好59,60。基于二值脉冲处理,SNN已具有计算优势。此外,LIF神经元的神经元动态中的随机性可以提高网络对外部噪声(例如,带噪输入或硬件的带噪权重参数)的鲁棒性61。那么,我们是否可以用结合此SNN时间处理架构使用适当的学习方法,并将权重训练压缩为二值机制,使精度损失最小,还有待研究。
Other underexplored directions
Beyond vision tasks
到目前为止,我们已经给出了大多数分类任务处理的办法,那么如何处理在静态图像上识别和推断以外的任务呢?SNN也可以处理序列数据,但是仅有很少的研究34论证SNN在处理NLP的能力。使用SNN做因果推断的能力又如何呢?深度学习研究人员在强化学习算法上投入了大量资金,这些算法使模型通过与环境实时交互来学习。不过使用SNN进行强化学习研究的却很少62,63。在SNN这一领域——特别是在训练学习算法中——SNN所面临的最大挑战就是否能表现出和深度学习相当的性能。尽管深度学习已经设下了很高的竞争门槛,但是我们相信SNN会在机器人、自主控制等领域表现的更好。
Lifelong learning and learning with fewer data
深度学习模型在长期学习时会出现灾难性遗忘现象。比如,学习过任务A的神经网络在学习任务B时,它会忘记学过的任务A,只记得B。如何在动态的环境中像人一样具备长期学习的能力成为了学术界关注的热点。这固然是深度学习研究的一个新的方向,但我们应该探究SNN中额外的时间维度是否有助于实现持续性学习型任务64。另一个类似的任务就是,利用少量数据进行学习,这也是SNN能超过深度学习的领域。SNN中的无监督学习可以与提供少量数据的监督学习相结合,只使用一小部分标记的训练数据得到高效的训练结果46,50,65。
Forging links with neuroscience
我们可以和神经科学的研究成果相结合,把这些抽象的结果应用到学习规则中,以此提高学习效率。例如,Masquelier等人65利用STDP和时间编码模拟视觉神经皮层,他们发现不同的神经元能学习到不同的特征,这一点类似于卷积层学到不同的特征。研究者把树突学习66和结构可塑性67结合起来,把树突的连接数做为一个超参数,以此为学习提供更多的可能。SNN领域的一项互补研究是LSM (liquid state machines)68。LSM利用的是未经训练、随机链接的循环网络框架,该网络对序列识别任务表现卓著69–71,但是在复杂的大规模任务上的表现能力仍然有待提高。
Hardware outlook
从前文对信息处理能力和脉冲通信的描述中,旨在形成SNN基础计算框架的硬件系统的一些特征很容易假设。其中包括底层硬件的稀疏事件驱动性质,作为基于脉冲的信息交换的直接表现;受到在生物大脑中无处不在的神经元和突触的启发,对紧密交织的计算和内存结构的要求;以及需要实现复杂的动态函数——例如,使用最小电路原语的神经元和突触动态。
The emergence of neuromorphic computing
在20世纪80年代,晶体管发明了40年后,在生物神经系统领域,Carver Mead设想了"更智能"、"更高效"的硅基计算机结构72,73。他也表示过自己最初试图建立神经系统的尝试是"简单而愚蠢的"74。但是他的工作代表了硬件计算的一种新的范式。Mead并不在意基于基本AND、OR门的布尔运算74,相反他利用金属氧化物硅(MOS)晶体管在亚阈值区的电气物理特性(电压-电流指数相关)来模拟指数神经元的动力学特征72。这样的设备-通路协同设计是神经形态计算中最有趣的领域之一,由新型材料和相关设备驱动。
The advent of parallel-processing GPUs
与由一个(或几个)与片上存储器集成的复杂计算核心组成的CPU(中央处理单元)相反,GPU75由许多并行运行的简单计算核心组成,从而实现高吞吐量处理。在传统意义上GPU是加速图形应用程序的硬件加速器。在受益于GPU的高吞吐量计算的众多非图形应用程序中,深度学习是最引人注目的6。事实上,GPU服务器不仅是运行DLN的首选硬件平台,也是探索SNN推理和训练的首选硬件平台76,77。虽然GPU在高扩展性上具备明显优势,但无法很好的用来进行基于事件驱动的脉冲计算。因此,事件驱动的"超级大脑"神经芯片就可以提供高效的解决方案78,79。

图5:一些有代表性的“超级大脑”芯片和AER方法。a,在许多旨在构建大规模神经形态芯片的工作78,81-84中,我们重点介绍了两个具有代表性的系统——Neurogrid和TrueNorth。Neurogrid拥有65000多个神经元和5亿个突触,而TrueNorth拥有100万神经元和2.56亿个突触。Neurogrid和TrueNorth分别使用树和网格路由拓扑两种结构。Neurogrid使用模拟混合信号设计,TrueNorth依赖数字基元。一般来说,像TrueNorth这样的数字神经形态系统将神经元的膜电位表示为n位二进制格式。通过适当增加或减少n位字来实现神经元动态,比如LIF行为。相比之下,模拟系统将膜电位表示为存储在电容中的电荷。通过电流从电容进出,模拟所需的神经元动态。尽管存在电路差异,但一般来说,模拟系统和数字系统都使用事件驱动AER进行脉冲通信。事件驱动通信是实现低能耗大规模集成系统的关键。b,基本的AER通信系统。每当发射端送出一个事件(一个脉冲),相应的地址就通过数据总线发送到接收端。接收端解码输入地址,并重新构造脉冲的序列。因此,每个脉冲由其位置(地址)显式编码,并在其地址发送到数据总线时隐式编码。
The 'Big Brain' chips
"超级大脑"芯片80的特点是整合了百万计的神经元和突触,这提供了脉冲计算的能力78,81–86(参见图5a)。Neurogrid82和TrueNorth84分别是基于混合信号模拟电路和数字电路的两种模型芯片。TrueNorth使用数字电路是因为模拟电路容易累积误差,并且更容易受到芯片制造过程中由工艺引起的变化的影响。Neurogrid被设计出来以帮助计算神经科学模拟大脑活动,通过复杂的神经元运作机制,例如多种离子通道的开启和关闭,以及生物突触的特有行为82,87。相比而言,TrueNorth作为一款神经芯片,目的是用于重要商业任务,例如使用SNN进行分类与识别,而且这基于简化的神经和突触原型。
以TrueNorth为例,可以突出显示跨越神经形态芯片78,88不同实现的两个特性,如下所示。
Asynchronous address event representation. 首先,异步地址事件表示不同于传统的芯片设计,在传统的芯片设计中,所有的计算都按照全局时钟进行,但是因为SNN是稀疏的,仅当脉冲产生时才要进行计算,所以异步事件驱动的计算模式更加适合进行脉冲计算[89,90]。
Network-on-chip. 其次,片上网络(NOC)用于脉冲通信。NOC是片上路由器网络,通过时分复用共享总线接收和传输数字信息包。将NOC用于大规模芯片势在必行,因为典型硅制造过程中的连接主要是二维的,而三维的灵活性有限。我们注意到,尽管使用了NOC,但片上连接仍然无法与大脑中的3D连接相媲美。TrueNorth以及随后的大规模数字神经形态芯片(如Loihi78)已经展示了基于SNN的应用程序的能源效率,使我们更接近生物学合理的实现。然而,有限的连接性、有限的NOC总线带宽和全数字方法仍然是需要进一步研究的关键领域。
Beyond-von-Neumann computing
晶体管的持续尺寸缩放(称为摩尔定律91)推动了CPU和GPU以及"超级大脑"芯片的计算能力不断提高。近年来,随着硅基晶体管接近其物理极限92,这种增长已经放缓。为了跟上计算能力飙升的需求,研究人员最近开始探索一种双管齐下的方法,以实现"超越冯诺依曼"和"超越硅"的计算模型。冯诺依曼模型的一个主要缺点93是处理单元与存储单元物理分离的清晰划分,通过总线连接以进行数据传输(见图1c)。通过这种带宽受限的总线在较快的处理单元和较慢的内存单元之间频繁移动数据会导致众所周知的"内存墙瓶颈",从而限制计算吞吐量和能源效率94。
减轻内存墙瓶颈影响的最有希望的方法之一是启用"near-memory"和"in-memory"计算95,96。Near-memory计算通过在内存单元附近嵌入专用处理引擎来实现内存和计算的协同定位。事实上,具有紧密放置的神经元和突触阵列的各种"超级大脑芯片"(参见图5)的"分布式计算架构"是near-memory处理的代表。相比之下,in-memory计算通过在内存位单元或外围电路中启用计算,将计算操作的某些方面嵌入到内存阵列中(参见图6示例)。

图6:使用非易失性存储设备作为突触存储。a,各种非易失性技术的示意图:PCM、RRAM、STT-MRAM和浮栅晶体管。这种非易失性设备已被用作突触存储和原位神经突触计算56,112–114,135,139-144,并用作各种通用非神经形态应用的in-memory加速器128,145-149。b,使用忆阻技术实现突触功效和可塑性。我们展示了一系列以交叉方式连接的忆阻器。根据欧姆定律,水平线(绿色)上的输入脉冲会产生与忆阻元件的电导成正比的电流。通过多个脉冲前神经元的电流沿垂直线(黑色)相加,这是基尔霍夫电流定律的结果。这导致了代表突触功效的内存中点积操作。根据特定的学习规则(如在STDP中),每当前神经元和后神经元分别在水平和垂直线上出现脉冲时,通常通过适当地施加电压脉冲来原位实现突触可塑性。组成忆阻器的电阻值基于在相应水平和垂直线上产生的电压差进行编程。用于编程的电压脉冲的形状和时序根据具体的器件技术进行选择。请注意,浮栅晶体管,因为它们是三端器件,需要额外的水平和/或垂直线来启用交叉开关功能115。该图还显示了忆阻阵列以平铺方式与NOC连接,从而实现高通量原位计算97。
Non-volatile technologies
非易失性技术97-103通常被比作生物突触。事实上,它们表现出生物突触的两个最重要的特征:突触功效和突触可塑性。突触可塑性是基于特定学习规则调节突触权重的能力。突触功效是指基于传入脉冲生成输出的现象。在最简单的形式中,这意味着传入的脉冲乘以存储的突触权重,这通常表示为可编程的、模拟的、非易失性电阻。将所有前神经元(特定层中接收输入脉冲的神经元)相乘的信号相加,并作为输入信号应用于后神经元(特定层中产生输出脉冲的神经元)(见图3)。图6说明了如何使用以交叉方式排列的新兴非易失性忆阻技术实现原位突触功效和突触可塑性103,104。此外,可以使用NOC以事件驱动的方式连接此类交叉开关,以构建具有原位内存计算的密集、大规模神经形态处理器。
基于忆阻技术105,106的各种工作,例如电阻随机存取存储器(RRAM)107、相变存储器(PCM)108和自旋转移矩磁随机存取存储器(STT-MRAM)109已经探索了基于STDP规则的原位点积计算和突触学习。RRAM(基于氧化物和基于导电桥的107)是电场驱动的器件,依靠灯丝形成来实现模拟可编程电阻。RRAM容易出现器件到器件和周期到周期的变化110,111,这是目前的主要技术障碍。PCM包含夹在两个电极之间的硫属化物材料,可以在非晶态(高电阻)和结晶态(低电阻)之间切换其内部状态。PCM器件具有与RRAM相当的编程电压和写入速度,尽管它们会随着时间的推移而受到高写入电流和电阻漂移的影响108。自旋电子器件由两个由垫片隔开的磁铁组成;它们表现出两种电阻状态,具体取决于两层的磁化方向是平行还是反平行。与RRAM和PCM相比,自旋器件具有几乎无限的耐用性、更低的写入能量和更快的反转速度109。然而,自旋器件中两个极端电阻状态(ON和OFF)的比率比PCM和RRAM小得多。
另一类允许可调非易失性电阻的非易失性器件是浮栅晶体管。正在积极探索此类设备用于突触存储112-114。事实上,浮栅设备是第一个被提出作为非易失性突触存储的设备115,116。因为他们与MOS制造工艺的兼容性,它们比其他新兴器件技术更成熟。然而,与所有其他非易失性技术相比,浮栅器件的主要限制是其耐用性降低和编程电压高。
尽管原位计算和突触学习为大规模超越冯诺依曼分布式计算提供了诱人的前景,但仍有许多挑战有待克服。考虑到设备到设备、周期到周期和过程引起的变化,计算的近似性质容易出现误差,从而降低整体计算效率以及最终应用程序的准确性。此外,交叉开关操作的稳健性受到电流潜行路径、线路电阻、驱动电路的源极电阻和感应电阻117,118的影响。选择器设备(晶体管或两端非线性设备)的非理想性、对模数转换器的要求和有限的位精度也增加了使用非传统突触设备设计稳健计算的整体复杂性。此外,写入非易失性设备通常是能源密集型的。此外,此类设备固有的随机性可能导致不可靠的写入操作,这需要昂贵且迭代的写入验证方案119。
Silicon (in-memory) computing
除了非易失性技术,使用标准硅存储器(包括静态和动态随机存取存储器)进行内存计算的各种提议正在广泛研究中。这些工作中的大多数都集中在将布尔逐位向量计算嵌入到内存阵列120-122中。 此外,最近已经证明了混合信号模拟内存计算操作和二值卷积123,124。事实上,目前几乎所有主要的内存技术都在探索各种形式的内存计算,包括静态125和动态硅内存126、RRAMs127、PCMs128和STT-MRAMs129。尽管这些工作中的大多数都专注于加密和DLN等通用计算应用,但它们可以很容易地在SNN中找到应用。
Algorithm–hardware codesign
Mixed-signal analog computing
模拟计算非常容易受到过程引起的变化和噪声的影响,并且在面积和能耗方面受到模拟和数字转换器的复杂性和精度的很大限制。将片上学习与紧密耦合的模拟计算框架结合使用将使此类系统能够从本质上适应过程引起的变化,从而减轻它们对准确性的影响。过去130,131以及最近的生物学合理算法工作54研究了强调片上和设备上学习解决方案的局部学习。本质上,无论是以局部学习的形式还是使用树突学习等范式,我们认为一类更好的容错局部学习算法——即使以额外的学习参数为代价——将是推进模拟神经形态计算的关键。此外,片上学习的弹性可用于开发低成本的近似模数转换器,而不会降低目标应用的准确性。
Memristive dot products
作为模拟计算的一个具体例子,忆阻点积是实现原位神经形态计算的一种很有前途的方法。不幸的是,代表点积的忆阻阵列中产生的电流同时具有空间和数据依赖性,使得交叉开关电路分析成为一个不平凡的复杂问题。很少有工作研究过横杆非理想的影响117,132,133,并探索了减轻点积不准确影响的训练方法118,134。请注意,这些工作中的大多数都侧重于DLN,而不是SNN。然而,有理由假设在这些工作中开发的基本设备和电路见解也与SNN实现相关。现有工作需要详细的设备电路仿真运行,必须与训练算法紧密结合以减少精度损失。我们相信,基于最先进设备的交叉开关阵列模型的抽象版本,以及在点积不准确性中建立理论界限的努力,具有直接的兴趣。这将使算法设计人员能够探索新的训练算法,同时考虑硬件的不一致性,而无需耗时和迭代的设备-电路-算法模拟。
Stochasticity
由于具有固有随机性的新兴设备的可用性,随机SNN引起了极大的兴趣135,136。最近关于实现随机二值SNN的大部分工作都集中在小规模任务上,例如MNIST数字识别56。这些工作的共同主题是使用类似STDP的随机局部学习规则来生成权重更新。我们认为STDP学习中的时间维度为权重更新提供了额外的带宽,以便朝着正确的方向(朝着实现整体准确度)前进,即使受限于二值机制也是如此。这种二值局部学习方案与基于梯度下降的大规模任务学习规则相结合,同时利用硬件中的随机性,为节能神经形态系统提供了有趣的机会。
Hybrid design approaches
我们认为,基于混合方法的硬件解决方案——即在单个平台上结合各种技术的优势——是另一个需要深入研究的重要领域。这种方法可以在最近的文献中找到,其中低精度忆阻器与高精度数字处理器结合使用。这种混合方法有许多可能的变体,包括计算数据的重要性驱动隔离、混合精度计算137、将传统硅存储器重新配置为按需in-memory中近似加速器125、局部同步和全局异步设计138、局部模拟和全局数字系统;其中新兴技术和基于硅的技术可以同时使用,以提高准确性和能源效率。此外,这种混合硬件可以与混合脉冲学习方法结合使用,例如局部无监督学习,然后是全局监督反向传播53。我们相信这种结合的局部-全局学习方案可以用来降低硬件复杂性,同时也可以最大限度地减少终端应用程序的性能下降。
Conclusion
如今,"智能化"已经成为了我们周围所有学科的主题。在这方面,本文阐述了神经形态计算作为一种高效方式,通过硬件(计算)和算法(智能)的协同演化的方式来实现机器智能。我们首先讨论了脉冲神经范式的算法含义,这种范式使用事件驱动计算,而不是传统深度学习范式中的数值计算。我们描述了实现标准分类任务的学习规则(例如基于脉冲的梯度下降、无监督STDP和从深度学习到脉冲模型的转换方法)的优点和局限性。未来的算法研究应该利用基于脉冲信号的信息处理的稀疏和时间动态特性;以及可以产生实时识别的互补神经形态学数据集;硬件开发应该侧重于事件驱动的计算、内存和计算单元的协调,以及模拟神经突触的动态特征。特别引人关注的是新兴的非易失性技术,这项技术支持了原位混合信号的模拟计算。我们也讨论了包含算法-硬件协同设计的跨层优化的前景。例如,利用算法适应性(局部学习)和硬件可行性(实现随机脉冲)。最后,我们谈到,基于传统和新兴设备构建的基于脉冲的节能智能系统与当前无处不在的人工智能相比,二者的前景其实是相吻合的。现在是我们该交换理念的时候了,通过设备、通路、架构和算法等多学科的努力,通力合作打造一台真正节能且智能的机器。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号