Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
arXiv:1702.07464v3 [cs.CR] 14 Sep 2017

以下是对本文关键部分的摘抄翻译,详情请参见原文。
ABSTRACT
不幸的是,我们发现任何隐私保护的协作深度学习都容易受到我们在本文中设计的强大攻击。特别是,我们表明分布式、联邦或分散的深度学习方法从根本上将会被打破,并且不再能保护诚实参与者的训练集。我们开发的攻击利用了学习过程的实时性,使对手能够训练一个生成对抗网络(GAN)。该网络生成目标训练集的原型样本,而目标训练集是私有的(由GAN生成的样本旨在产生自与训练数据相同的分布)。有趣的是,我们表明,如前面的工作中所提出的,应用于模型共享参数的记录级别差异隐私是无效的(即记录级别差异隐私DP不是为解决我们的攻击而设计的)。
1 INTRODUCTION
深度学习社区最近提出了生成对抗网络(GANs),目前仍在大力发展。GANs的目标不是将图像分为不同的类别,而是生成与训练集中的图像相似的样本(理想情况下具有相同的分布)。更重要的是,GANs在没有原始样本的情况下生成这些样本。GAN只与有区分力的深度神经网络相互作用,以了解数据的分布。
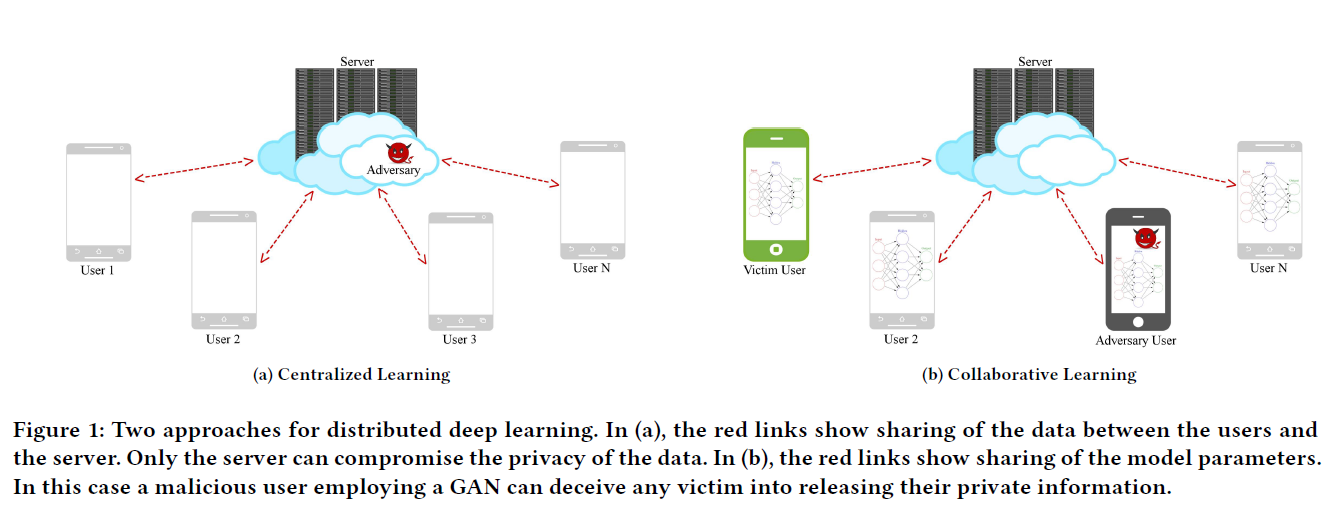
在本文中,我们使用GANs设计了一种针对协同深度学习的强大攻击。攻击的结果是,任何作为内部人员的用户都可以从受害者的设备中推断出敏感信息。攻击者只需运行协同学习算法并重建存储在受害者设备上的敏感信息。攻击者还能够影响学习过程并欺骗受害者发布更详细的信息。这种攻击在不影响服务操作者的情况下工作,甚至当模型参数通过差异隐私被模糊时也是如此。如图1(a)所示,集中式服务器是唯一危害数据隐私的地方。在图1(b)中,我们展示了任何用户都可以故意危害任何其他用户,使得分布式设置更加不受欢迎。
我们的主要贡献是提出和实现一种新的主动推断攻击,在深度神经网络的协同设置。我们的方法比现有的黑盒或白盒信息提取机制更有效。
也就是说,我们的贡献是:
- 我们设计了一个新的攻击 —— 基于GANs的分布式深度学习。GANs通常用于隐式密度估计,据我们所知,这是第一个恶意使用GANs的应用程序。
- 我们的攻击比当前的信息提取机制更通用、更有效。特别是,我们的方法可以用来对付卷积神经网络(CNN),这是众所周知的模型反演攻击的困难。
- 我们引入了协同学习中的欺骗概念,即对手欺骗受害者,使其在敏感数据上发布更准确的信息。
- 我们设计的攻击在通过差异隐私模糊参数时也是有效的。我们强调,这不是针对差异隐私的攻击,而是针对协同深度学习的攻击。在实践中,我们证明了在[77]和[1]中应用的差异私人训练(样例/记录级差异隐私)在我们的隐私概念下的协同学习环境中是无效的。
2 REMARKS
我们以一种新的方式使用GAN,因为它们被用于在一个协同深度学习框架中从诚实的受害者那里提取信息。GAN创建了一个应该是私有类的实例。我们基于GAN的方法只在协同深度学习的训练阶段起作用。我们的攻击甚至对卷积神经网络,即使卷积神经网络众所周知很难反转[78],或者参数利用记录级别粒度设置的差异隐私进行模糊时(如[77]和[1]中所述)也是有效的。它在白盒访问模型中工作,攻击者在该模型中看到并使用模型的内部参数。黑盒访问与之相反,攻击者只看到每个特定输入的模型输出。这并不是我们程序的限制,因为协同学习的目的是共享参数,即使只有很小的百分比。
一旦分布式学习过程结束,参与者总是可以对训练过的模型应用模型反转或类似的攻击。这并不奇怪。我们在本文中展示的是,恶意参与者可以看到模型是如何建立和影响其他诚实参与者的,并迫使他们发布有关其私有数据集的相关信息。这种欺骗诚实用户的能力对于我们的攻击是独一无二的。此外,截断或模糊共享参数将没有帮助,因为只要本地模型的准确性足够高,我们的攻击都是有效的。
然而,我们强调,我们的攻击不会违反为保护数据库而定义的差异隐私(DP)。问题是,在协同深度学习中,DP被应用于模型的参数,并且粒度设置在记录/示例级别。一旦模型变得准确,添加到学习参数中的噪声最终将被抑制。只要模型能够准确地进行分类,我们的攻击就会起作用,并将生成该类的代表。DP在[77]和[1]中的应用方式最多可以防止与学习阶段使用的标签相关的特定元素的恢复。我们的攻击结果可能被视为或不被视为侵犯隐私。请考虑以下示例:
- 受害者的设备包含规范的病历。GAN将生成类似于通用病历的元素,即来自训练集中相同分布的条目。在这种情况下,攻击者可能了解不到任何感兴趣的内容,也不会侵犯隐私。但是,如果受害者的设备包含的都是癌症患者的记录,那么攻击者可能会看到不存在的患者,但都是癌症患者。根据上下文,这可能被视为侵犯隐私。
- 受害者的设备包含淫秽图片。GAN将生成类似的场景。虽然它们看起来像是假的,但泄露给对手的信息是重要的。在其他情况下,我们的攻击可能对充当对手的执法官员有用。例如,当受害者的设备包含恋童癖色情图片或恐怖分子的训练材料时。
- 受害者的设备包含录音。GAN会产生胡言乱语,有很多类似于虚假单词的声音(当网络在没有文本序列的情况下进行训练时,与WaveNet[64]进行比较),因此不会有侵犯隐私的行为。但是,可以推断所使用的语言(如英语或中文)或说话者是男性还是女性,而泄露的信息可能构成侵犯隐私。
- 受害者的设备包含Alice的图像。GAN将生成与Alice相似的脸,就像合成艺术家生成目击证人对Alice记忆的草图一样。在我们的攻击框架中,对手还将收集所有这些Alice的图片,并错误地声称它们是Eve的。这将迫使受害者设备内的本地模型发布关于Alice脸的更相关和独特的细节,加剧泄露。然而,虽然许多人认为这是侵犯隐私,但其他人可能不同意,因为对手可能无法恢复Alice的准确面容,而只能进行重建(见图2)。另一方面,如果Alice戴眼镜或有棕色头发,那么这些信息将被泄露,并可能根据上下文构成侵犯隐私的行为。图3中给出了另一个示例,其中DCGAN在CIFAR-10数据集[41]上运行,针对一个由大约6000个包含各种马的图像组成的类。请注意,该类可以标记为“jj3h221f”,并且不明显地涉及马。GAN产生的图像将告诉对手‘jj3h221f’不包含汽车或飞机,而是动物(可能是马)。

6 THREAT MODEL
我们的威胁模型遵循[77],但依赖于活跃的内部人士。
对手假装是协同深度学习协议中的诚实参与者,但试图提取他不拥有的一类数据的信息。对手还将秘密地影响学习过程,以欺骗受害者,从而发布有关目标类别的更多详细信息。这种对抗性的影响使我们的攻击比仅仅对最终训练的模型应用模型反转攻击[27]更有效。此外,我们的攻击适用于更通用的学习模型(那些可以实现GAN的模型),包括那些模型反转攻击无效的模型(例如卷积神经网络)。
具体来说,我们考虑以下场景:
- 对手是隐私保护协同深度学习协议的内部人士。
- 对手的目标是推断关于一个他不拥有的标签的有意义的信息。
- 对手不会破坏中央参数服务器(PS),该服务器收集参数并将其分发给参与者。也就是说,在我们的示例中,参数服务器或服务提供者不受对手的控制。在我们的现实世界中,对手是一个成熟的内部人士,不必为服务提供商工作。
- 对手是活跃的,因为他直接操纵值并在本地建立了一个GAN。同时,他遵循受害者所看到的协议规范。尤其是,对手轮流执行参数选择程序,按照事先约定上传和下载正确数量的梯度,并根据协同学习过程的要求模糊上传的参数。
- 如[77]所述,假设所有参与者事先就共同的学习目标达成一致。这意味着对手掌握了模型结构的知识,尤其是其他参与者的数据标签。
- 与模型反演[27]中的静态对手不同,我们的对手可以在学习过程中自适应并实时工作。对手能够通过分享精心设计的梯度来影响其他参与者,并诱使参与者泄漏更多关于其本地数据的信息。这是可能的,因为分布式学习过程需要运行几轮才能成功。
7 PROPOSED ATTACK
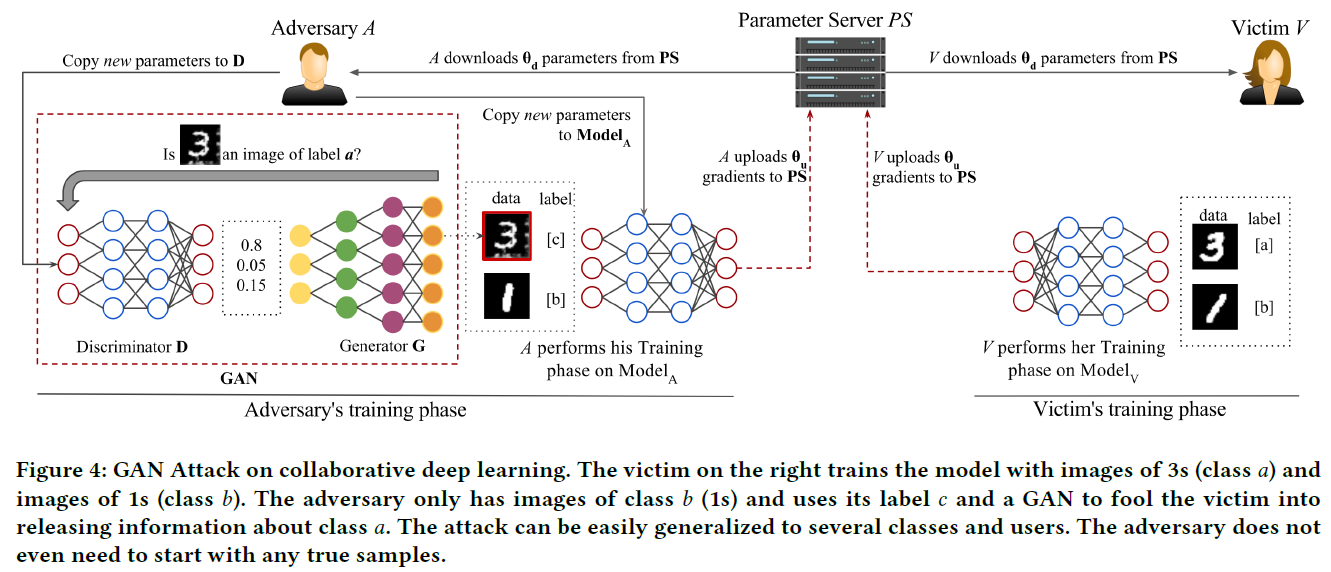
对手A参与了协同深度学习协议。所有的参与者都提前确定了一个共同的学习目标[77],这意味着他们了解神经网络架构的类型以及训练标签。
V为另一个声明标签[a,b]的参与者(受害者)。对手A声明标签[b,c]。因此,虽然b是共同的,但是A没有关于a类的信息。对手的目标是尽可能推断出关于a中元素的有用信息。
我们的内部人员利用了一个GAN来生成类似于受害者的a类样本的样例。内部人员将这些来自a的假样本作为c类注入分布式学习过程中。通过这种方式,受害者需要更加努力地区分a和c类,因此会比最初预期更多地揭示关于a类的信息。因此,内部人员模仿来自a的样本,并利用受害者来提高他在训练前忽略的类的知识。GANs最初是为密度估计而设计的,因此我们可以从分类器的输出中了解数据的分布,而不必直接看到数据。在这种情况下,我们利用这个属性欺骗受害者,让他们提供更多关于内部人士不知道的类的信息。
为了简单起见,我们考虑前两个参与者(对手和受害者),然后将攻击策略扩展到多个用户。每个参与者可以声明任意数量的标签,并且不需要类重叠。
(1)假设两个参与者A和V。建立并确定共同的学习结构和目标。
(2)V声明标签[a,b],A声明标签[b,c]。
(3)运行多个epoch的协同深度学习协议,只有当参数服务器(PS)上的模型和两个本地模型的精度高于某个阈值时才停止。
(4)首先,受害者训练网络:
(a)V从PS下载一定比例的参数并更新其本地模型。
(b)V的本地模型在[a,b]上进行训练。
(c)V将本地模型的参数选择上载到PS。
(5)其次,对手训练网络:
(a)A从PS下载一定比例的参数并更新其本地模型。
(b)A训练其本地生成对抗网络(受害者不知道)模仿受害者的a类。
(c)A从GAN生成样本并将其标记为c类。
(d)A的本地模型在[b,c]上进行训练。
(e)A将其本地模型的参数选择上载到PS。
(6)在4)和5)之间迭代,直到收敛。
以上5b)和5c)中强调的步骤代表对手为了尽可能多地学习目标标签a的元素而进行的额外工作。该过程如图4所示。算法1报告了攻击对多个用户的泛化。
只要A的本地模型随着时间的推移提高其精度,GAN攻击就可以工作。另一个重要的观点是,即使在使用差异隐私或其他模糊技术时,GAN攻击仍然有效。这不是针对差异隐私的攻击,而是针对协同深度学习的攻击。虽然实验结果的质量可能会下降,但实验表明,只要模型是可学习的,GAN也可以改进和学习。当然,可能总是有一个设置,在那里攻击可能会被阻止。这可以通过设置更强的隐私保证、释放更少的参数或建立更严格的阈值来实现。然而,正如[77]中的结果所示,这些措施导致无法学习的模型或比集中数据训练性能差的模型。最后,即使在部署差异隐私的情况下,攻击也是有效的,因为生成-判别-协同学习的成功只依赖于判别模型的准确性,而不依赖于其实际的梯度值。

9 EXPERIMENTS



在我们的实验中,我们注意到,一旦模型的精度达到80%,G就开始产生良好的结果。



10 CONCLUSIONS
在这项工作中,我们提出并实现了一类在深度神经网络的协同设置中新的主动推断攻击。我们的方法依赖于生成对抗网络(GANs),比现有的信息提取机制更有效和通用。我们相信我们的工作将在现实世界中产生重大影响,因为主流公司正在考虑采用分布式、联邦或分散的深度学习方法来保护用户的隐私。
我们研究的重点是,协同学习比它应该取代的集中式学习方法更不可取。在协同学习中,任何用户都可能在不涉及服务提供商的情况下侵犯系统中其他用户的隐私。
最后,我们无法针对我们的攻击制定有效的对策。解决方案可能依赖于安全多方计算或(完全)同态加密。但是:(1)为了避免这些代价高昂的加密基元,引入了隐私保护协同学习[77],并且(2)我们基于它们探索的解决方案仍然容易受到某些形式的攻击。另一种方法是考虑不同粒度的差异隐私。用户级或设备级的DP可以抵御本文设计的攻击。但是,目前还不清楚如何构建一个真正的系统,以便与设备、类或用户级的DP(例如,用户以不可预知的方式运转和共享数据)进行协同学习。因此,我们将这个问题留给以后的工作。
A SYSTEM ARCHITECTURE




 浙公网安备 33010602011771号
浙公网安备 33010602011771号