


8. SparkSQL综合作业
网盘下载sc.txt文件,分别创建RDD、DataFrame和临时表/视图;
分别用RDD操作、DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
一、DataFrame操作
创建RDD,转换DataFram
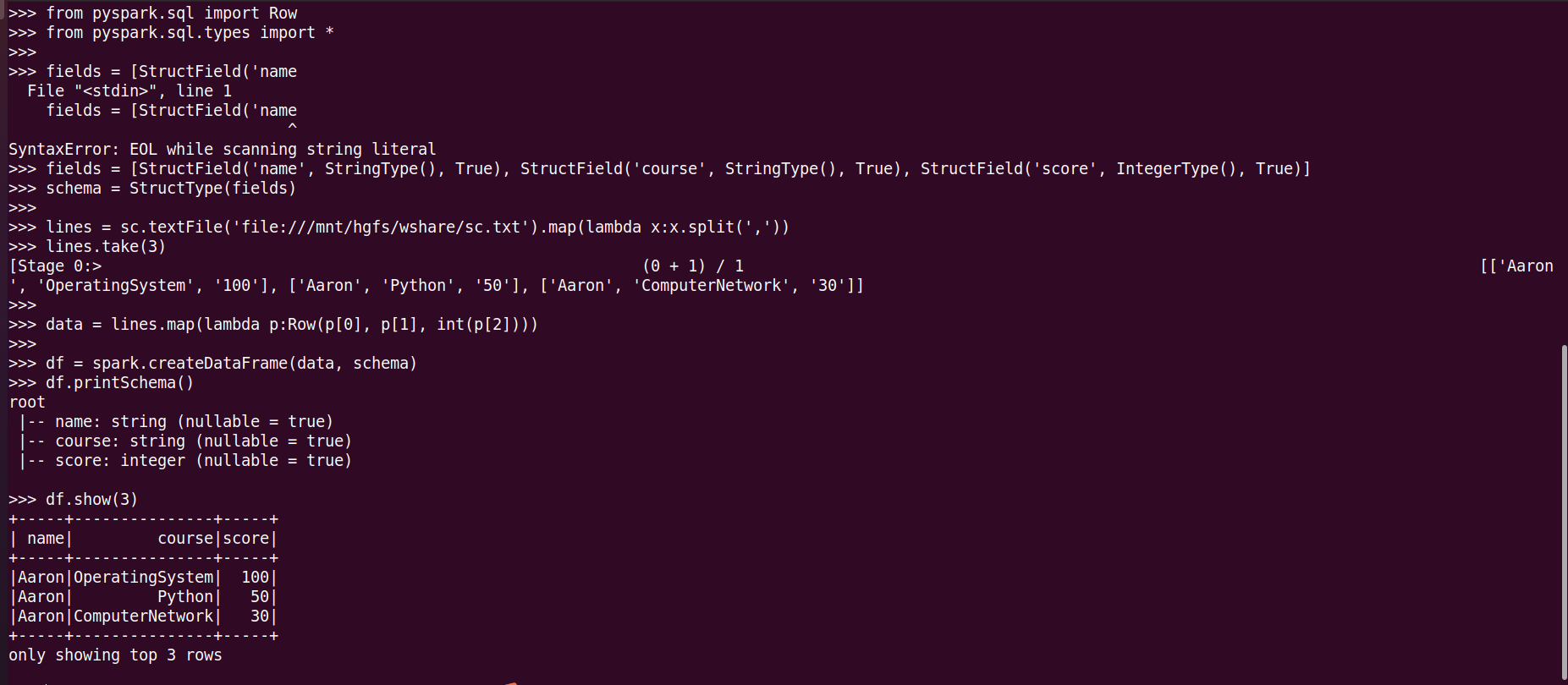
1、总共有多少学生?

2.总共开设了多少门课程?

3.每个学生选修了多少门课?
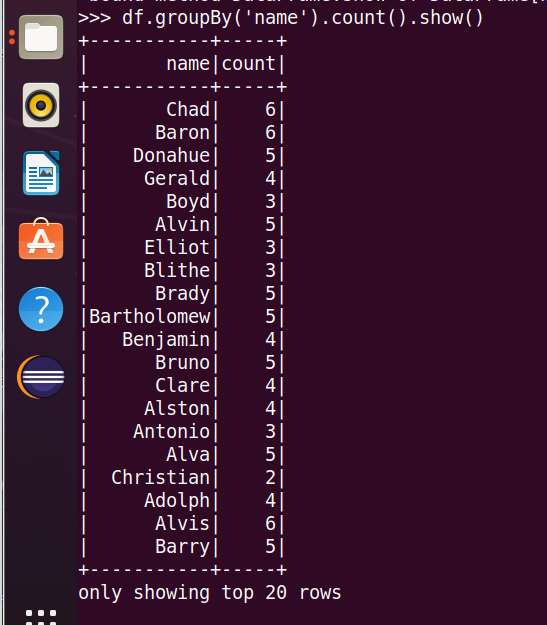
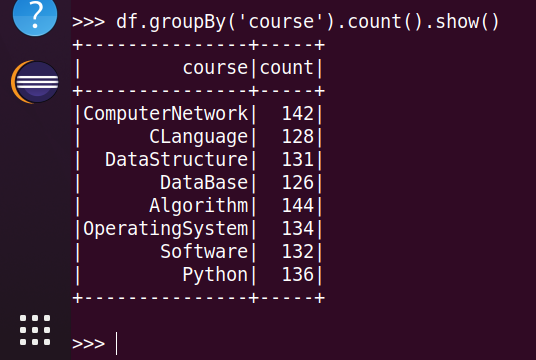
4.每门课程有多少个学生选?
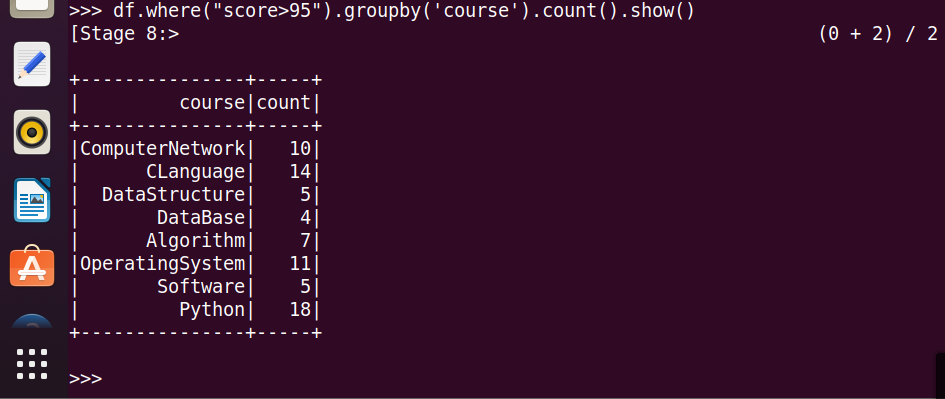
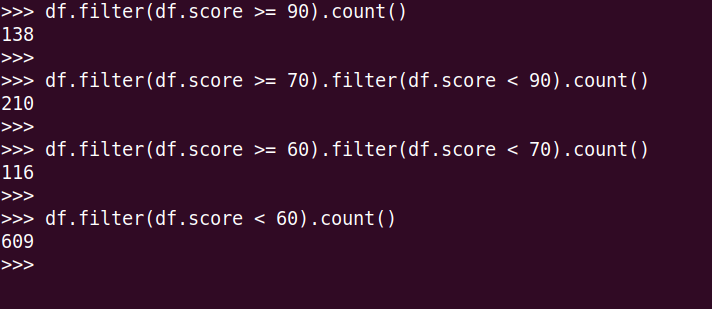
5.每门课程>95分的学生人数
6.课程'Python'有多少个100分?
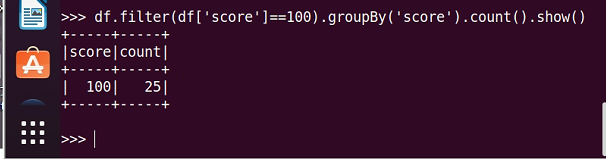
7.Tom选修了几门课?每门课多少分?
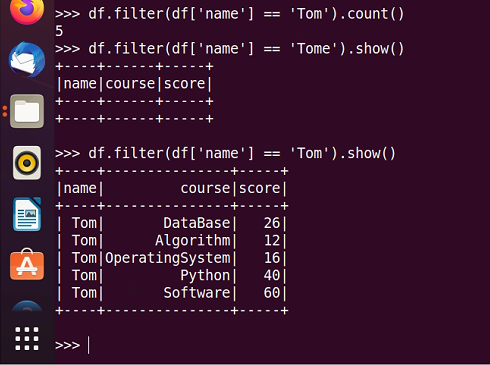
8.Tom的成绩按分数大小排序。
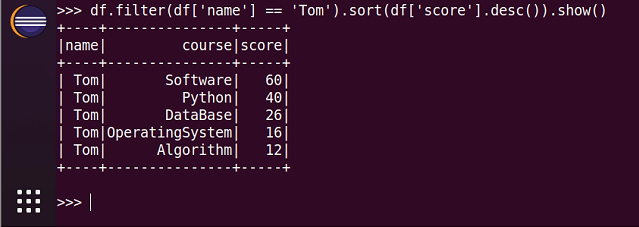
9.Tom选修了哪几门课?
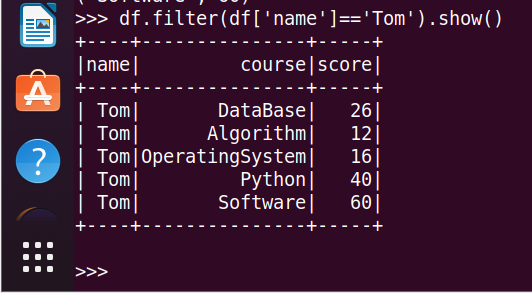
10.Tom的平均分。

11.'OperatingSystem'不及格人数
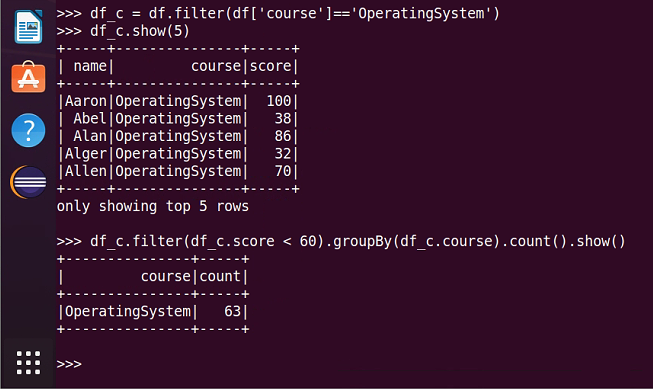
12.'OperatingSystem'平均分
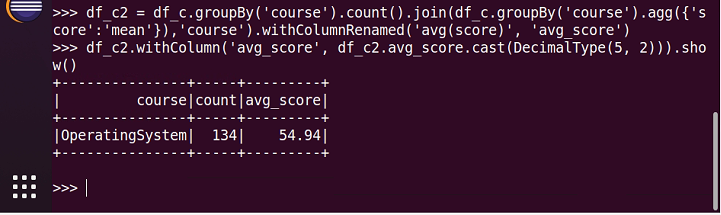
13.'OperatingSystem'90分以上人数

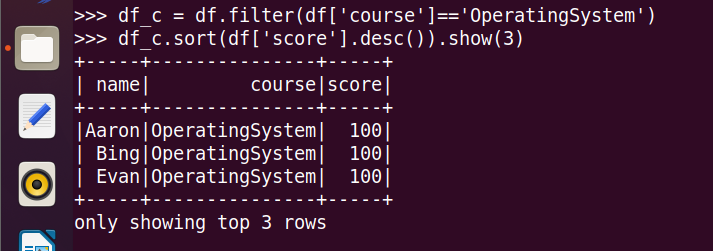
14.'OperatingSystem'前3名
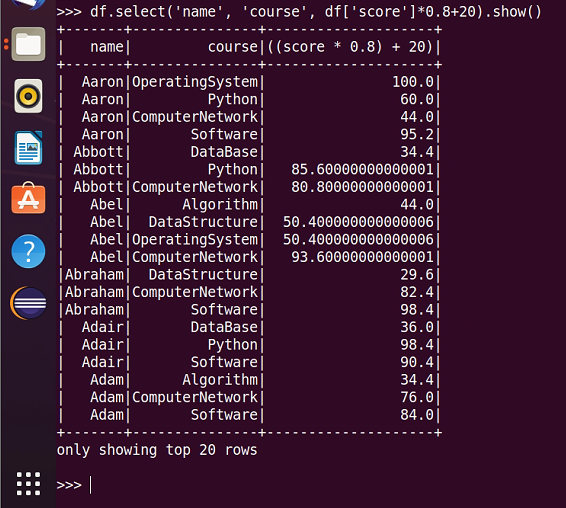
15.每个分数按比例+20平时分。
16.求每门课的平均分
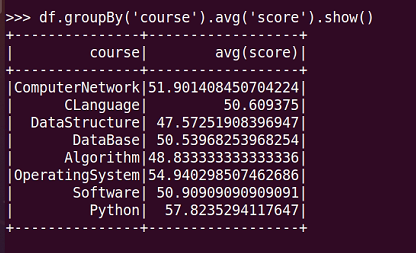
17.选修了7门课的有多少个学生?
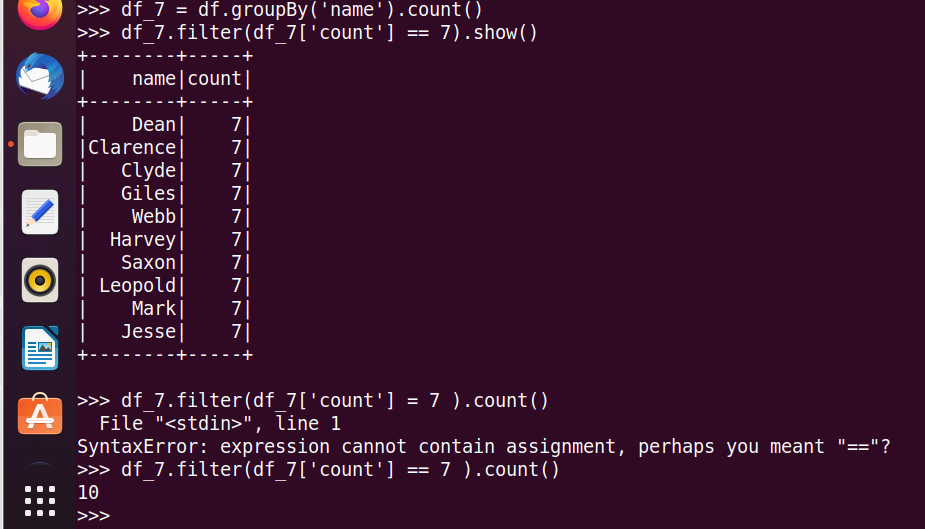
18.每门课大于95分的学生数
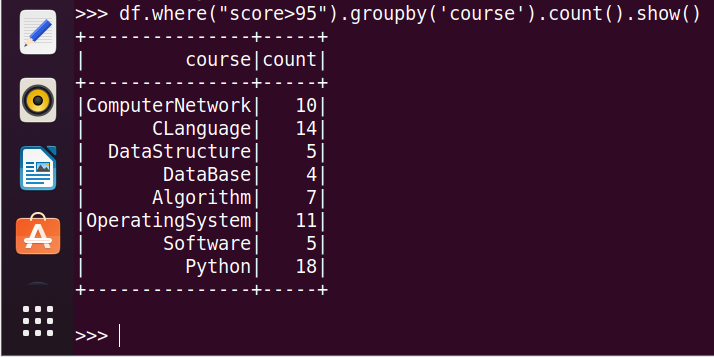
19.每门课的选修人数、平均分、不及格人数、通过率
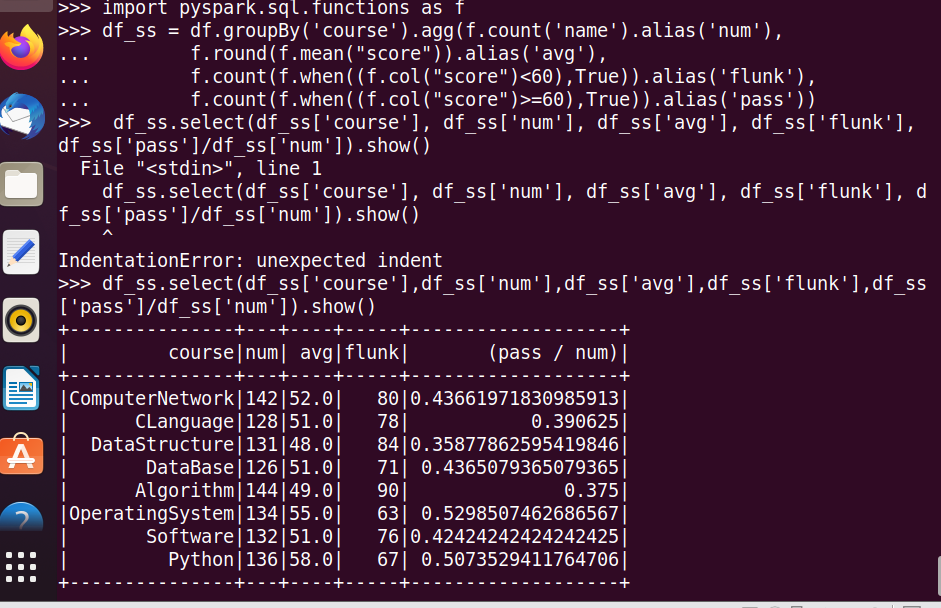
20.优秀、良好、通过和不合格各有多少人?
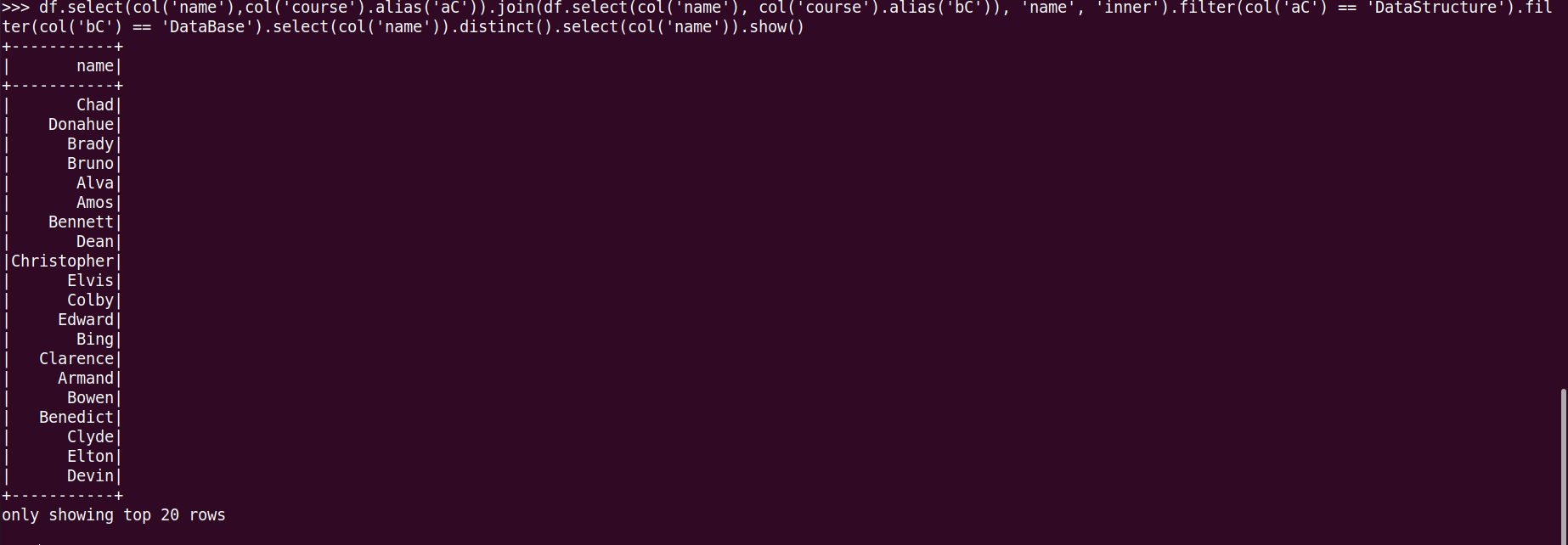
21.同时选修了DataStructure和 DataBase 的学生
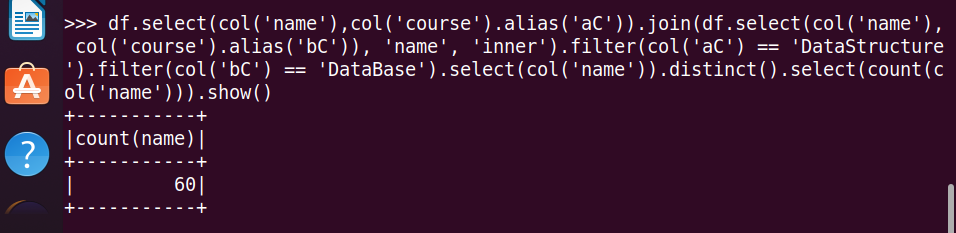
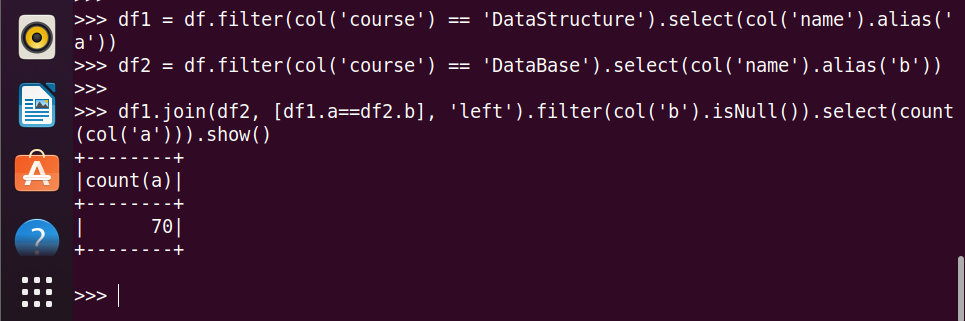
22.选修了DataStructure 但没有选修 DataBase 的学生
23.选修课程数少于3门的同学
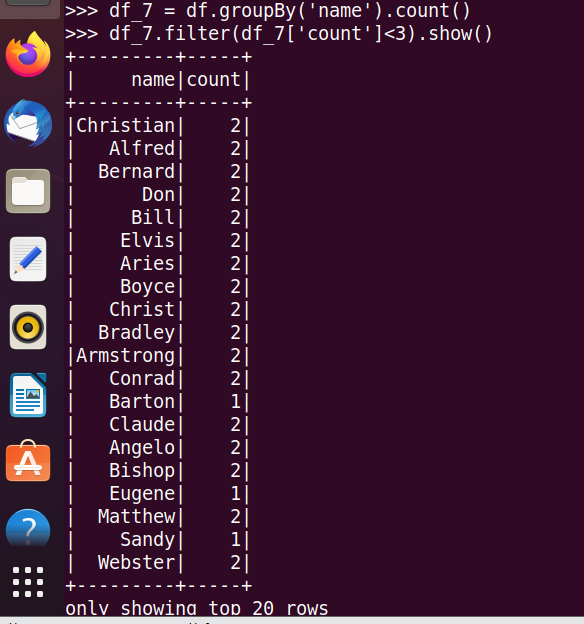
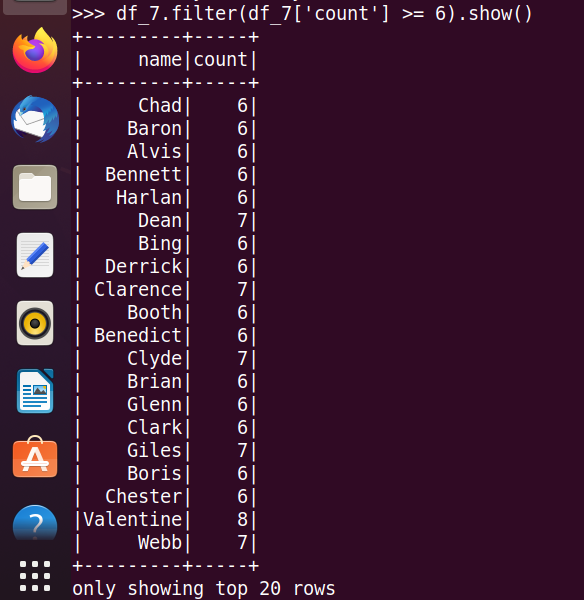
24.选修6门及以上课程数的同学
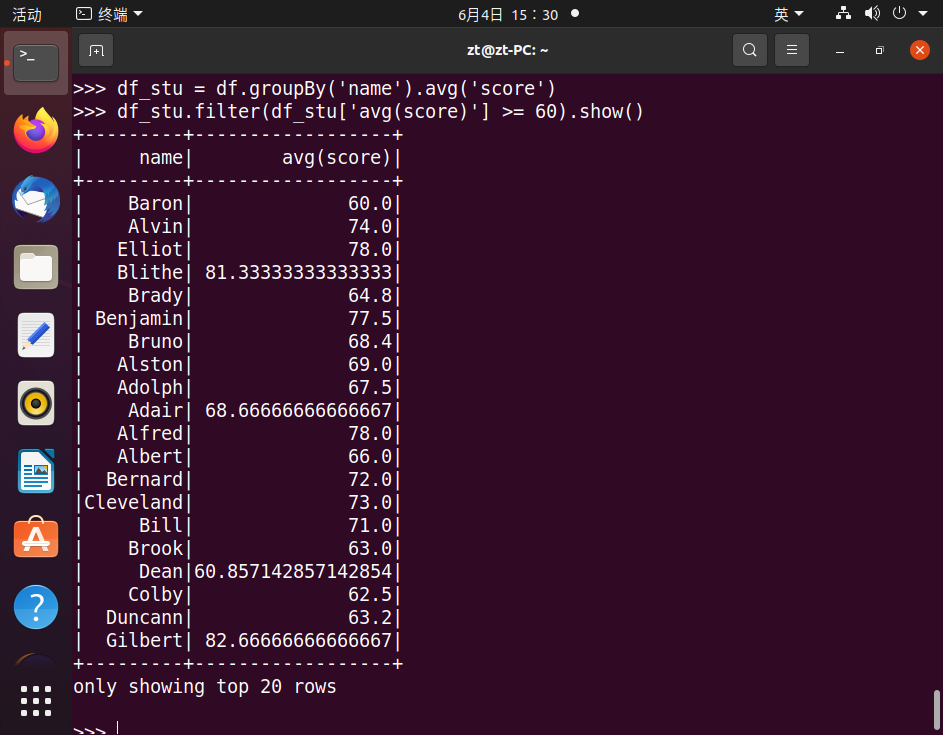
25.查询平均成绩大于等于60分的姓名和平均成绩
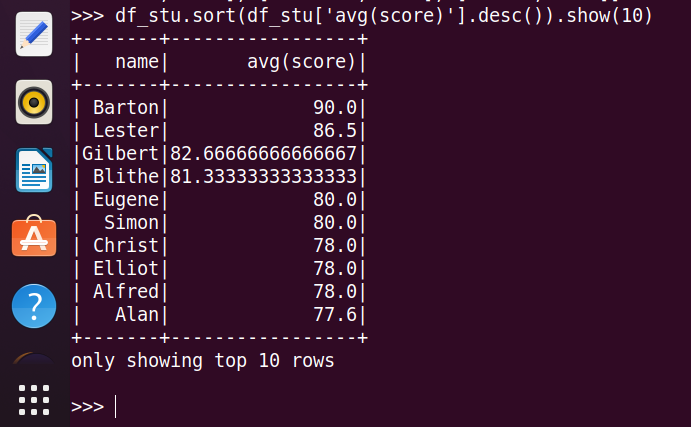
26.找出平均分最高的10位同学
二、Spark.sql操作
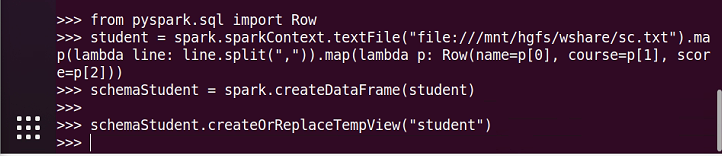
1、总共有多少学生?
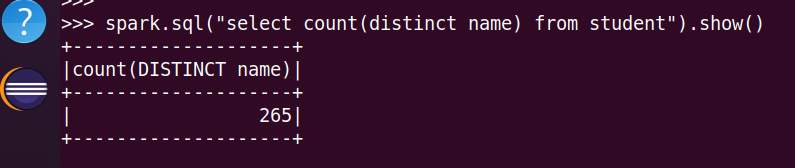
2.总共开设了多少门课程?
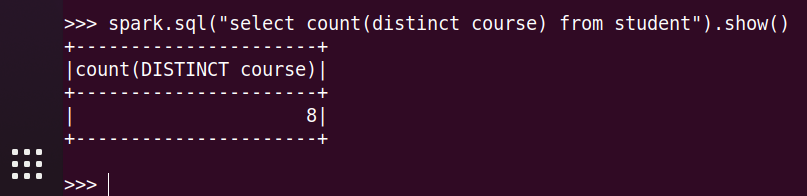
3.每个学生选修了多少门课?
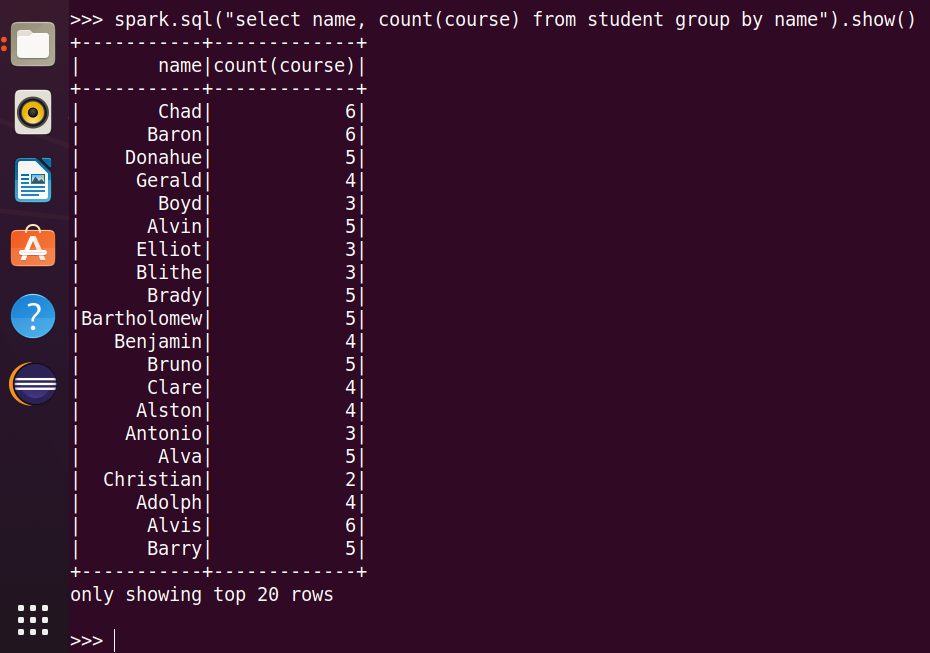
4.每门课程有多少个学生选?
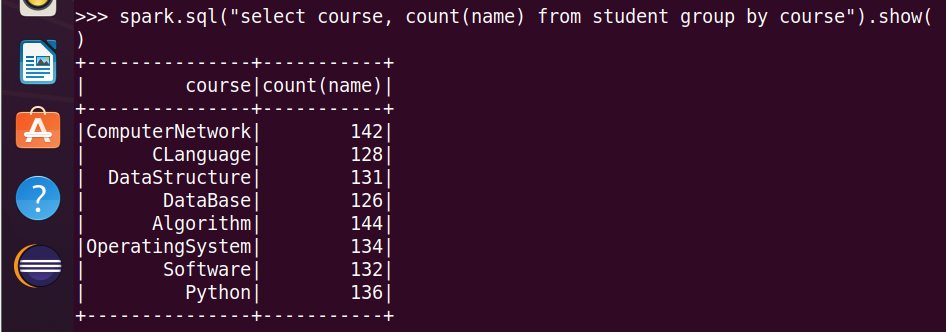
5.每门课程>95分的学生人数
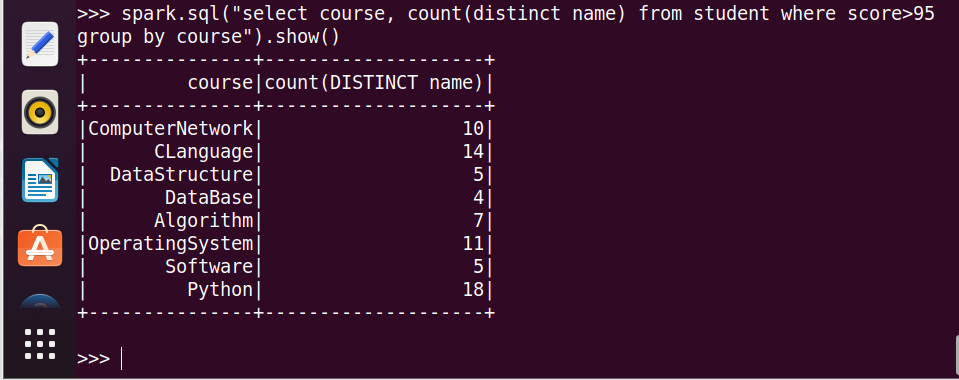
6.课程'Python'有多少个100分?
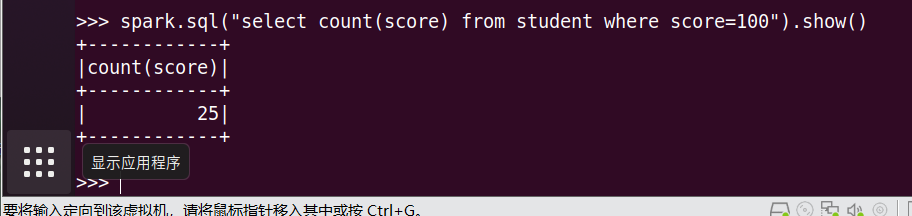
7.Tom选修了几门课?每门课多少分?
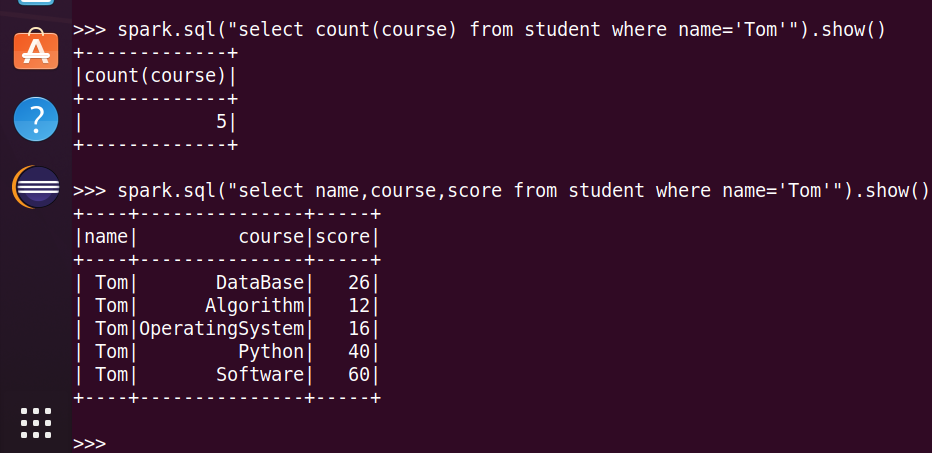
8.Tom的成绩按分数大小排序。
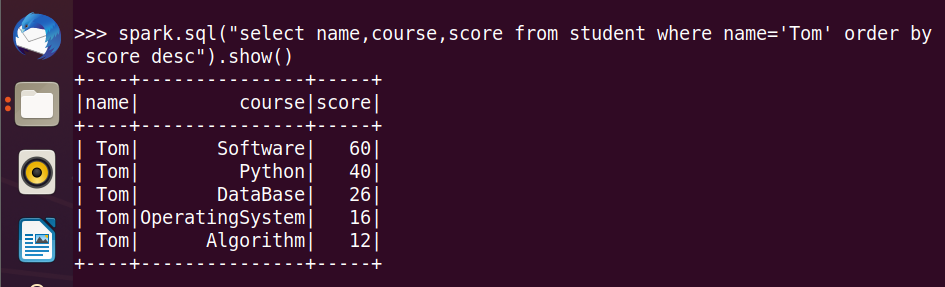
9.Tom选修了哪几门课?
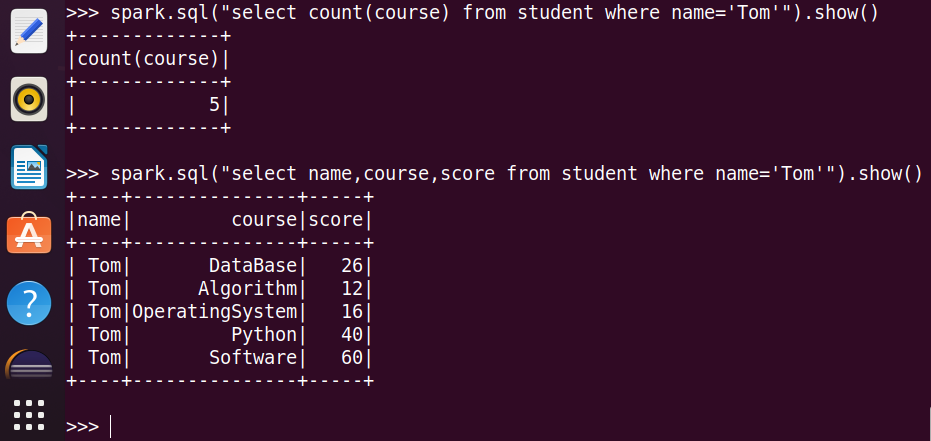
10.Tom的平均分。
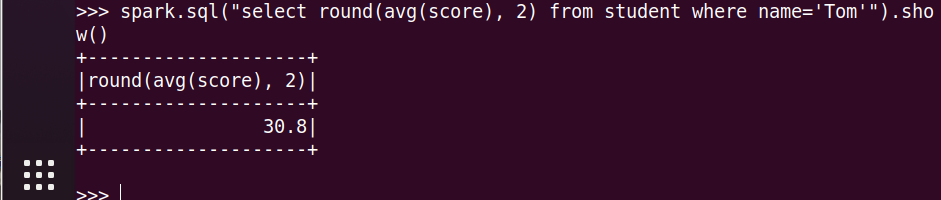
11.'OperatingSystem'不及格人数
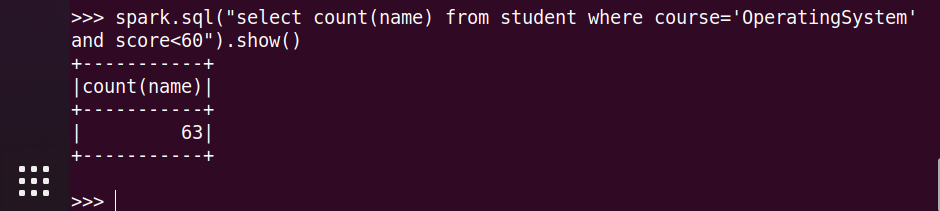
12.'OperatingSystem'平均分
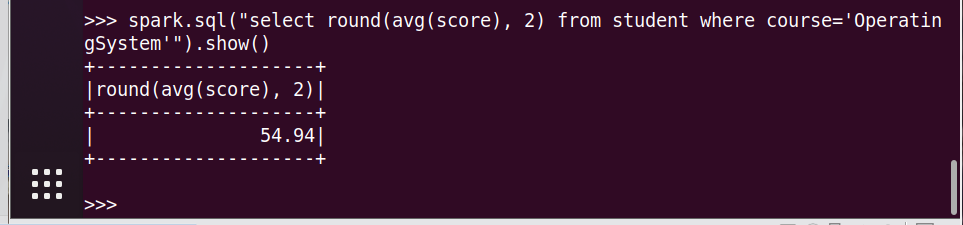
13.'OperatingSystem'90分以上人数
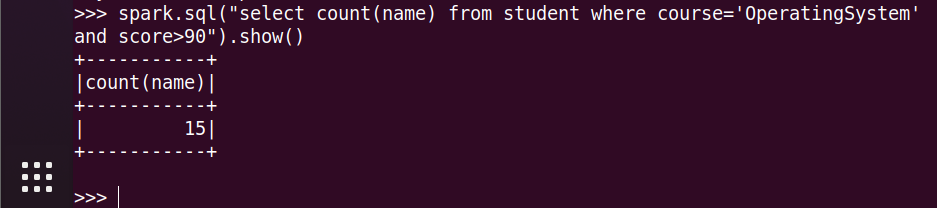
14.'OperatingSystem'前3名
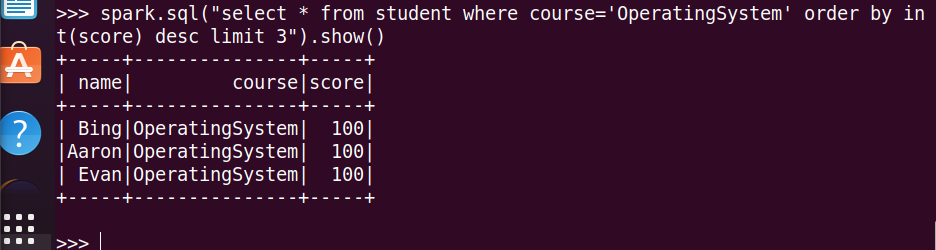
15.每个分数按比例+20平时分。
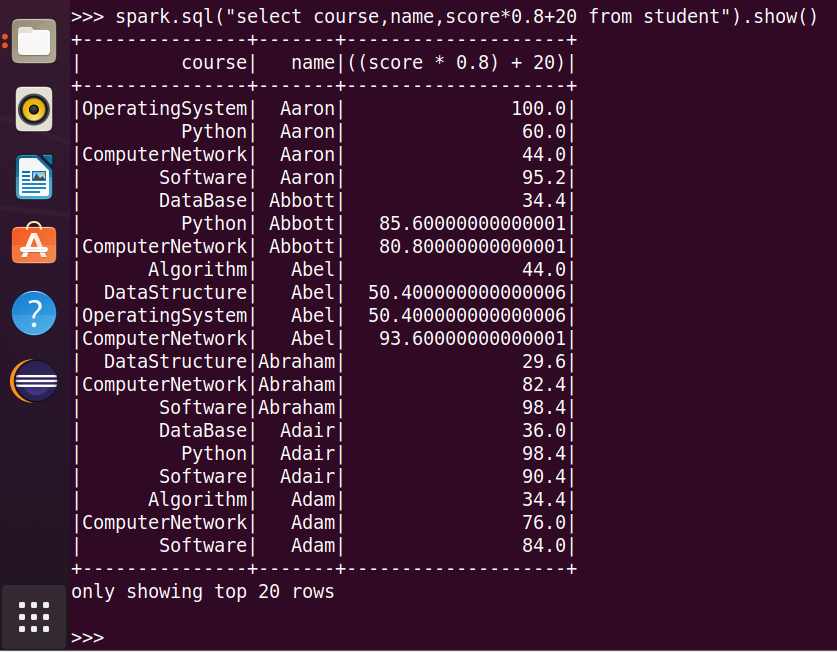
16.求每门课的平均分
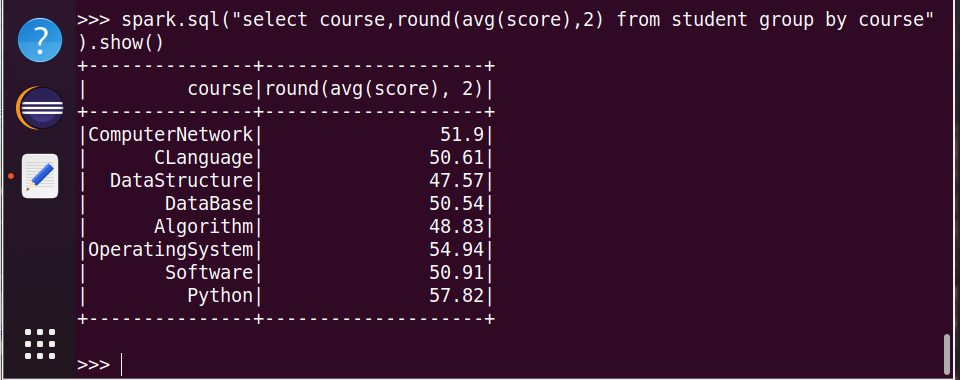
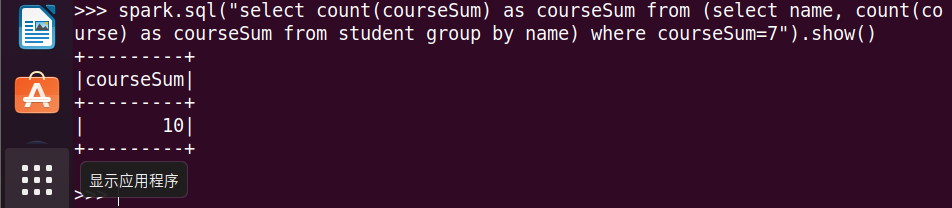
17.选修了7门课的有多少个学生?
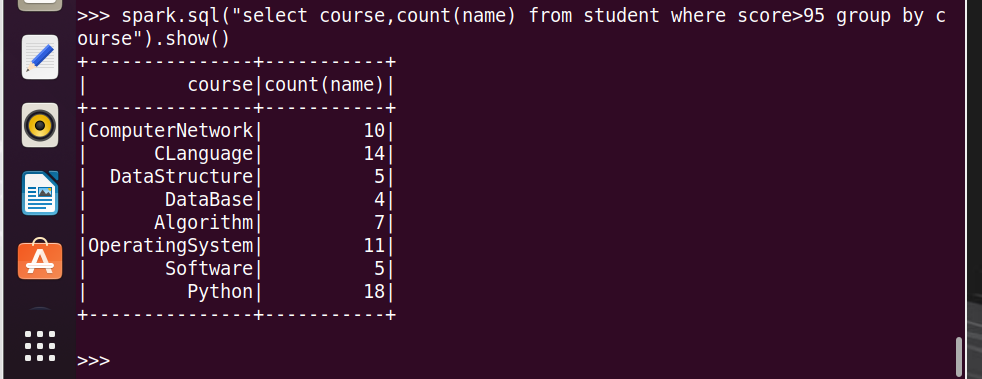
18.每门课大于95分的学生数
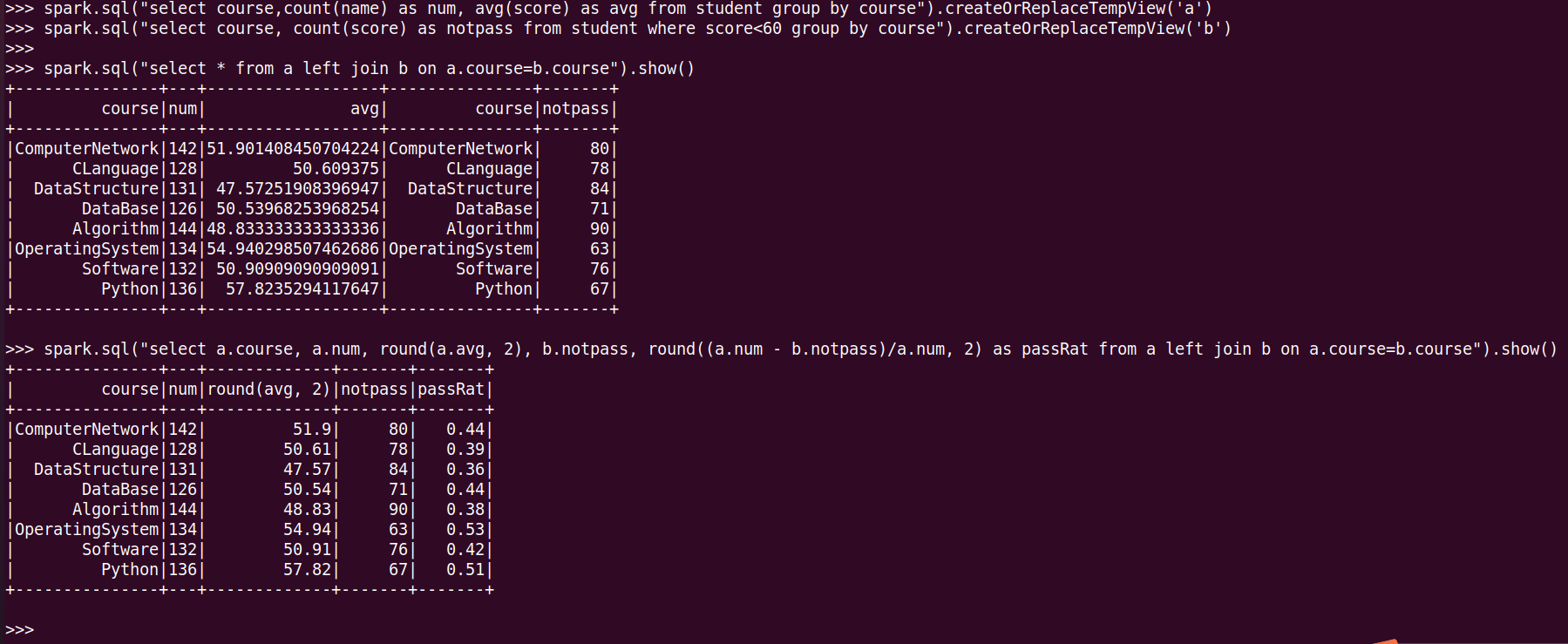
19.每门课的选修人数、平均分、不及格人数、通过率
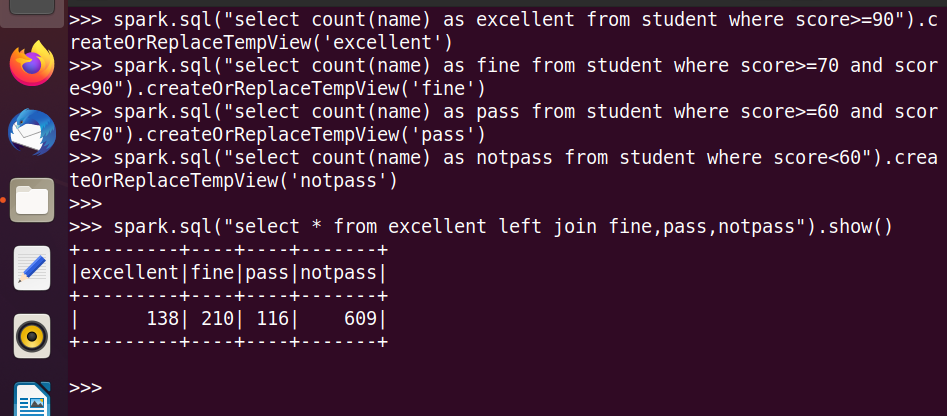
20.优秀、良好、通过和不合格各有多少人?
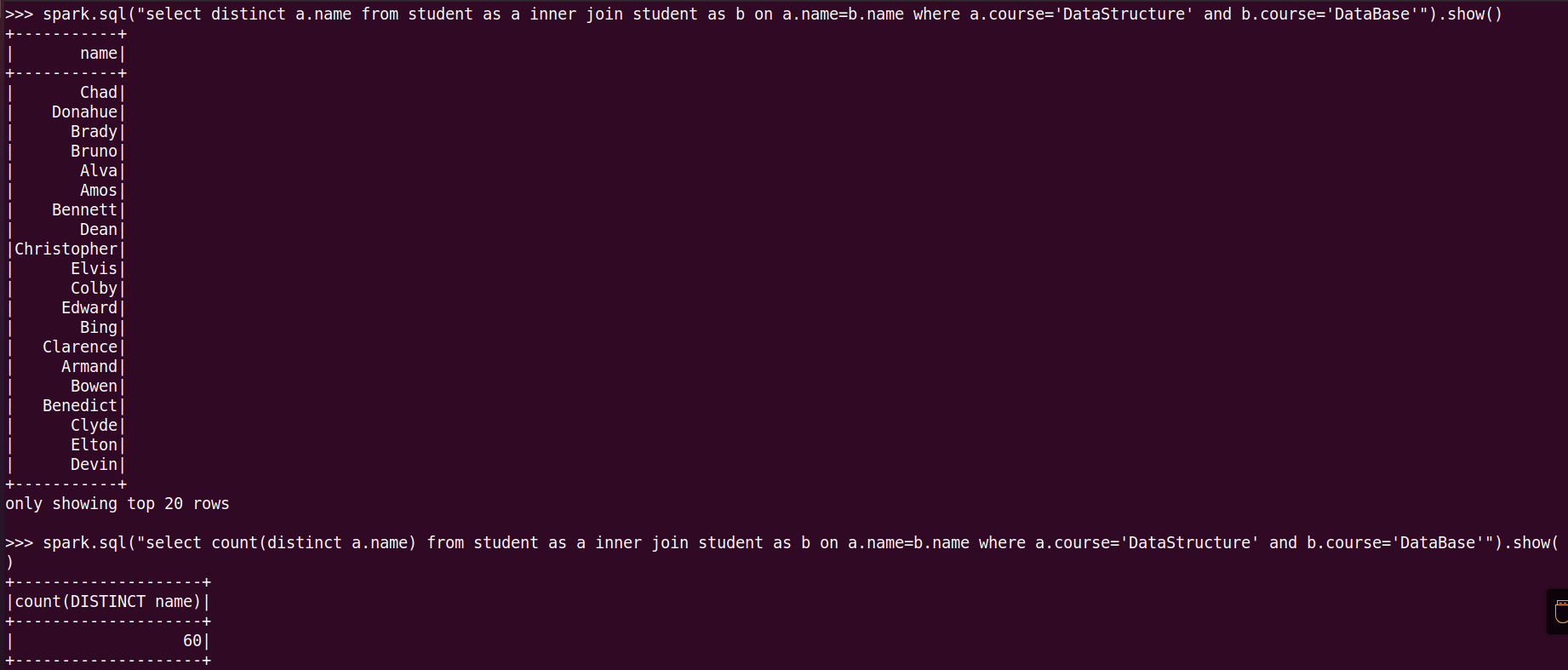
21.同时选修了DataStructure和 DataBase 的学生
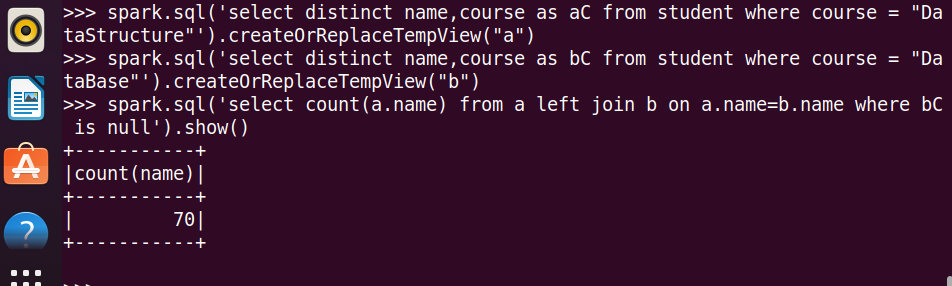
22.选修了DataStructure 但没有选修 DataBase 的学生
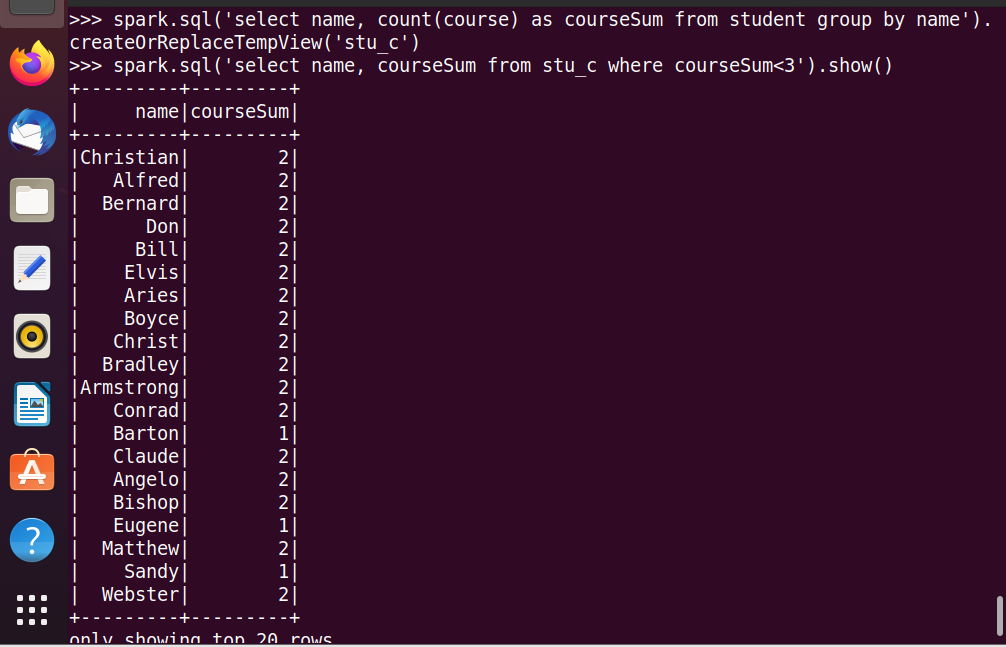
23.选修课程数少于3门的同学
24.选修6门及以上课程数的同学
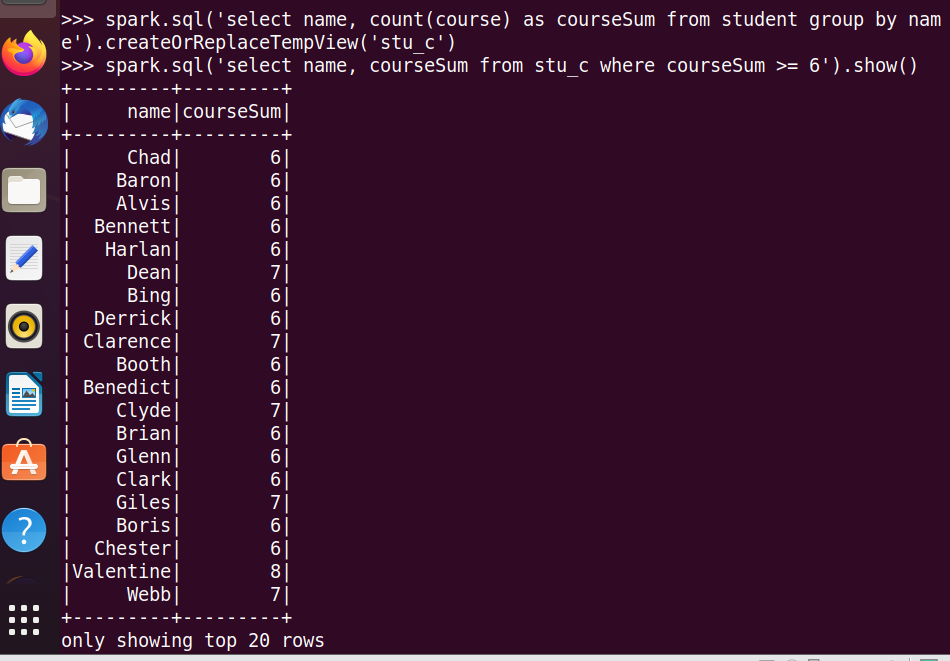
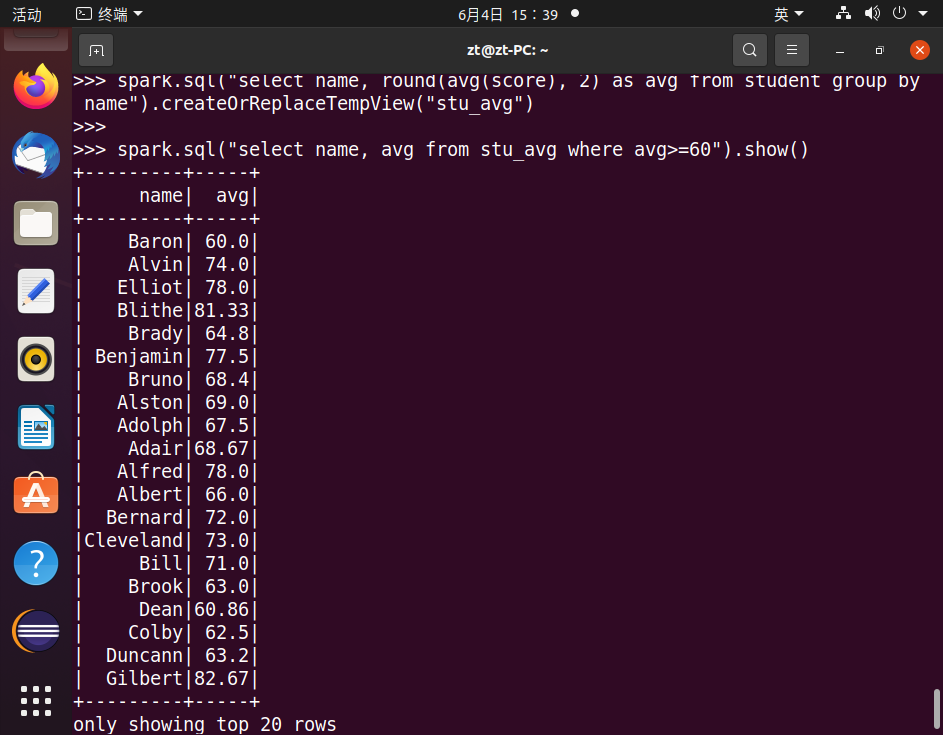
25.查询平均成绩大于等于60分的姓名和平均成绩
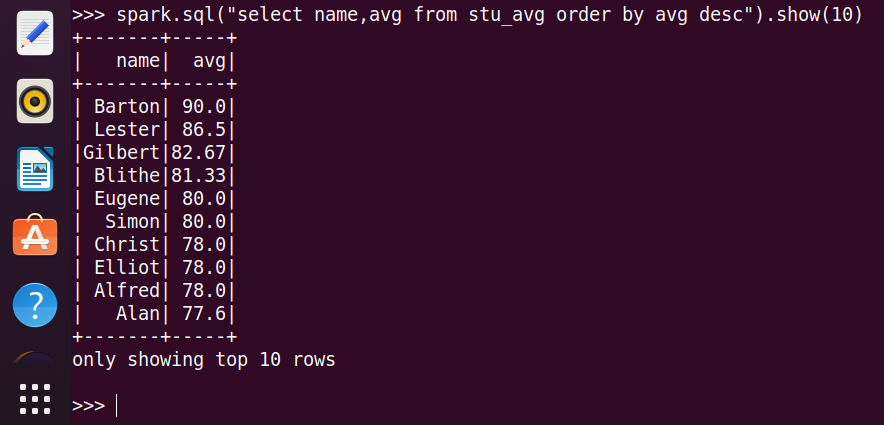
26.找出平均分最高的10位同学
三、RDD操作
1.总共有多少学生?
scm.map(lambda line: line[0]).distinct().count()

2.总共开设了多少门课程?
scm.map(lambda line: line[1]).distinct().count()

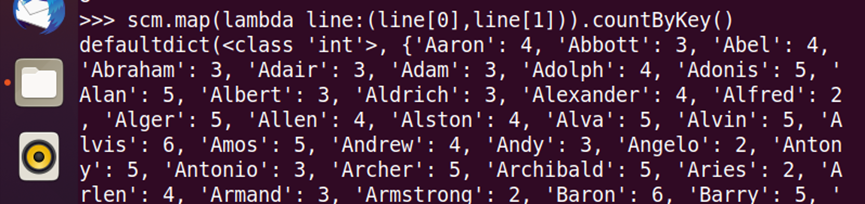
3.每个学生选修了多少门课?
scm.map(lambda line:(line[0],(line[1],line[2]))).countByKey()
4.每门课程有多少个学生选?
scm.map(lambda line:(line[0],(line[1],line[2]))).values().countByKey()

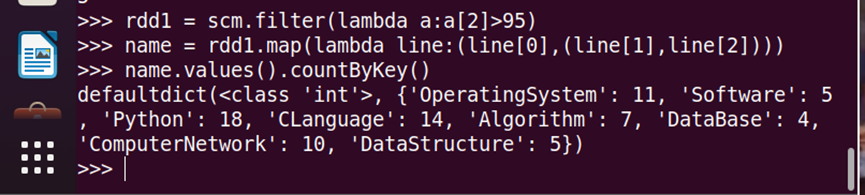
5.每门课程>95分的学生人数
rdd1=scm.filter(lambda a:a[2]>95)
name=rdd1.map(lambda line:(line[0],(line[1],line[2])))
name.values().countByKey()
6.课程'Python'有多少个100分?
scm.filter(lambda a:a[1]=='Python').filter(lambda a:a[2]=='100').count()

7.Tom选修了几门课?每门课多少分?
scm.filter(lambda line:line[0]='Tom').map(lambda line:(line[1],line[2])).collect()

8.Tom的成绩按分数大小排序。
scm.filter(lambda line:line[0]='Tom').sortBy(lambda a:a[2],False).collect()

9.Tom选修了哪几门课?
scm.filter(lambda line:line[0]='Tom').map(lambda line:line[1]).collect()

10.Tom的平均分。
import numpy as np
np.mean(scm.filter(lambda line:line[0]=='Tom').map(lambda line:line[2]).collect())

11.'OperatingSystem'不及格人数
scm.filter(lambda a:a[1]=='OperatingSystem').filter(lambda a:a[2]<60).count()

12.'OperatingSystem'平均分
import numpy as np
np.mean(scm.filter(lambda line:line[1]=='OperatingSystem').map(lambda line:line[2]).collect())

13.'OperatingSystem'90分以上人数
scm.filter(lambda a:a[1]=='OperatingSystem').filter(lambda a:a[2]>90).count()

14.'OperatingSystem'前3名
scm.filter(lambda line:line[1]='OperatingSystem').sortBy(lambda a:a[2],False).take(3)

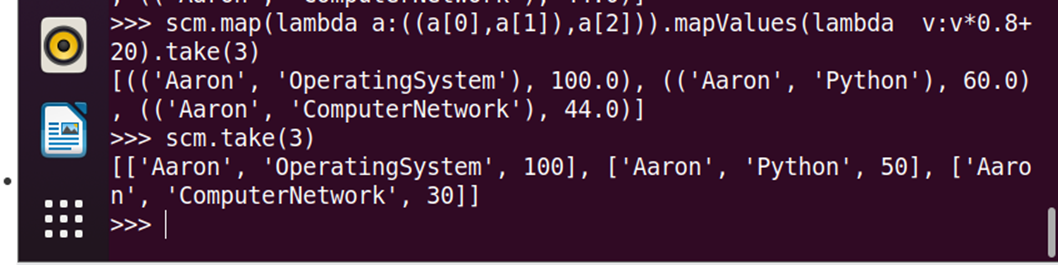
15.每个分数按比例+20平时分。
scm.take(3)
adjust=scm.map(lambda a:((a[0],a[1]),a[2])).mapValues(lambda v:v*0.8+20)
adjust.take(3)
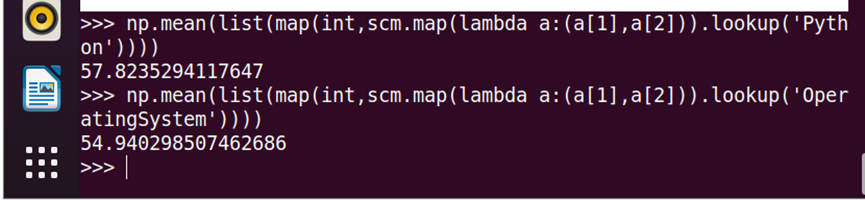
16.求每门课的平均分
np.mean(list(map(int,scm.map(lambda line:(line[1],line[2])).lookup(''))))
17.选修了7门课的有多少个学生?

18.每门课大于95分的学生数

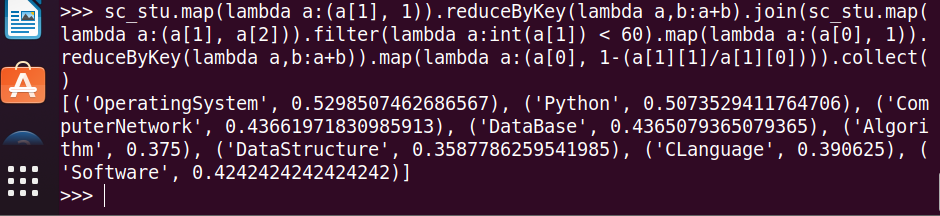
19.每门课的选修人数、平均分、不及格人数、通过率



20.优秀、良好、通过和不合格各有多少人?
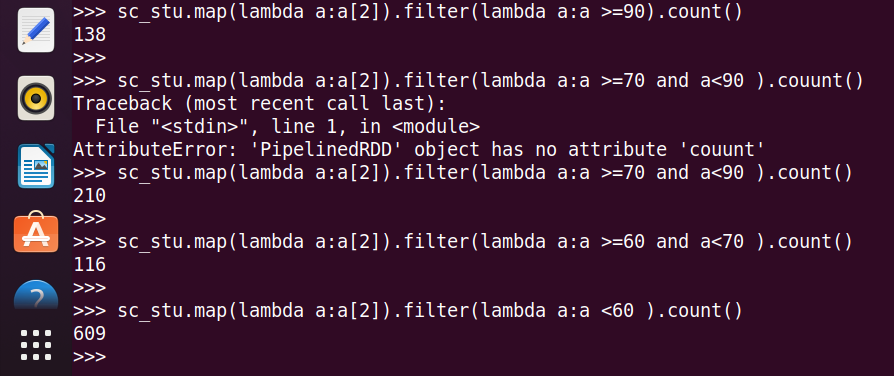
21.同时选修了DataStructure和 DataBase 的学生

22.选修了DataStructure 但没有选修 DataBase 的学生

23.选修课程数少于3门的同学

24.选修6门及以上课程数的同学

25.查询平均成绩大于等于60分的姓名和平均成绩
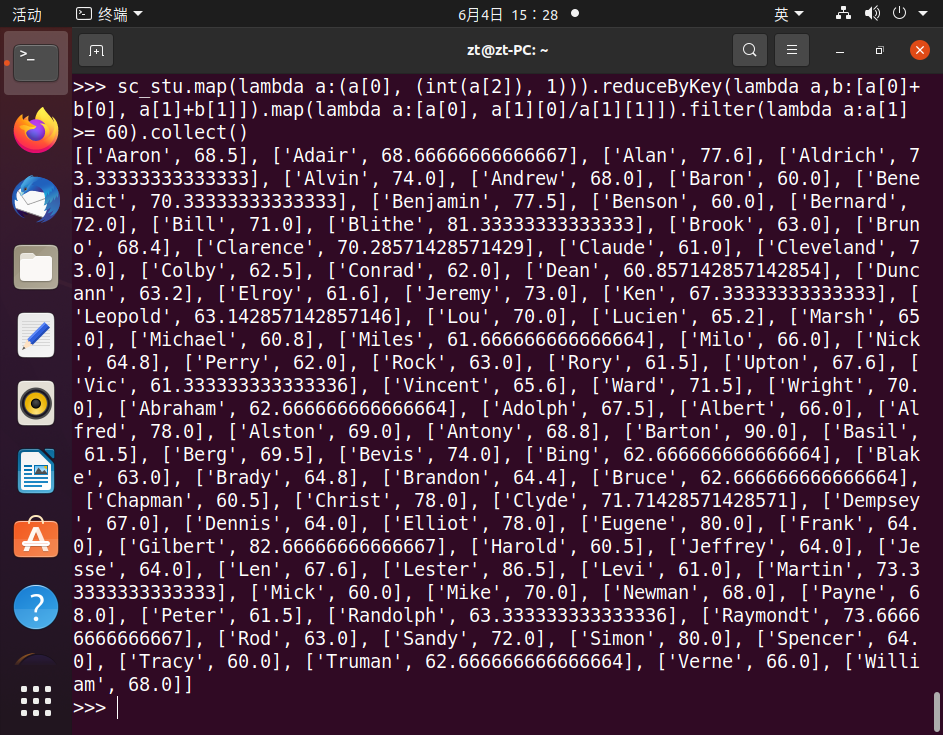
26.找出平均分最高的10位同学


 浙公网安备 33010602011771号
浙公网安备 33010602011771号