
乐观锁/悲观锁
什么是乐观锁/悲观锁?
无论是悲观锁还是乐观锁,都是人们定义出来的概念,可以认为是一种思想。其实不仅仅是关系型数据库系统中有乐观锁和悲观锁的概念,其实在java中也有广泛的应用。
悲观锁
概念
当我要对一条数据进行修改的时候,为了避免同时被其他人修改,于是我对该数据进行加锁操作,当其他人修改时,必须等我修改完数据并释放锁之后,其他人才能对数据进行修改。说白了就是我在修改数据时,其他线程想要操作数据,都需要阻塞挂起。悲观锁适用于写多读少的场景。
实现方式
- 传统的关系型数据库使用这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。
- Java 里面的同步 synchronized 关键字的实现。
乐观锁
概念
乐观锁它不会真正的去加锁,它是在数据进行提交更新的时候,对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景
实现方式
- 版本号控制。
- CAS操作(Compare and Swap)。
悲观锁具体实现
select … for update 加锁
以MySQL InnoDB为例
用户user表中有余额字段 price=0,现在要对用户表的余额进行操作。
如果不采用 for update 加锁
@Transactional
public void A() {
int price = userMapper.getPriceById(1); // select price from user where id = #{id}
price = price + 50;
Thread.sleep(3000); // 停止3秒钟
userMapper.updatePriceById(price, 1);// update user set price = #{price} where id = #{id}
}
@Transactional
public void B() {
int price = userMapper.getPriceById(1); // select price from user where id = #{id}
price = price + 100;
userMapper.updatePriceById(price, 1);// update user set price = #{price} where id = #{id}
}
上面代码在A和B同时被访问的情况下会出现问题,如下:
1、A 查询 price = 0,并对 price + 50,计算 price 结果为 50
2、A 暂停了 3 秒
3、此时 B 方法执行了,先查询 price = 0,并计算 price 结果为 100,写入数据库中
4、A 方法 3 秒之后继续执行,把 price = 50 写入数据库
上边最终 price 的结果是 50,和我们预想的 150 是不同的。为了解决上边的问题,可以使用 for update 加锁的方式去解决。
使用悲观锁来实现
@Transactional
public void A() {
int price = userMapper.getPriceByIdLock(1); // select price from user where id = #{id} for update
price = price + 50;
Thread.sleep(3000); // 停止3秒钟
userMapper.updatePriceById(price, 1);// update user set price = #{price} where id = #{id}
}
@Transactional
public void B() {
int price = userMapper.getPriceByIdLock(1); // select price from user where id = #{id} for update
price = price + 100;
userMapper.updatePriceById(price, 1);// update user set price = #{price} where id = #{id}
}
将 sql 改为上边的方式,使用 for update 加锁,执行流程如下:
1、A 查询 price = 0,并对 price + 50,计算 price 结果为 50
2、A 暂停了 3 秒
3、此时 B 方法执行了,在执行 getPriceByIdLock(1) 方法时,由于 A 已经对数据加锁了, B 方法阻塞
4、A 方法 3 秒之后继续执行,把 price = 50 写入数据库,并提交了事务(释放锁)
5、B 查询 price = 50,并对 price + 100,计算 price 结果为 150
6、B 把 price = 150 写入数据库
使用select ... for update注意事项
注意注意注意:for update 仅适用于InnoDB,并且必须开启事务,在begin与commit之间才生效。或者在代码中使用@Transactional才能生效
行锁:访问数据库的时候,锁定整个行数据,防止并发错误。 如InnoDB存储引擎使用行锁
表锁:访问数据库的时候,锁定整个表数据,防止并发错误。 如MyISAM存储引擎使用表锁
例1:明确指定主键,并且数据真实存在,行锁
select status from t_goods where id = 1 for update;
例2:明确指定主键,但数据不存在,无锁
select status from t_goods where id = 0 for update;
例3:主键不明确,表锁
select status from t_goods where id <= 3 for update;
例4:无主键,表锁
select status from t_goods for update;
乐观锁具体实现
1.版本号控制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会 +1。
举个版本号控制的例子
假设 userid = 1 的用户现有余额 price = 30, version默认为0.
现有 A 和 B 两个人同时给 userid = 1 的用户增加 100 块钱
1、A 查询用户现有余额 price = 30,version = 0
2、B 同时也查询用户现有余额 price = 30,version = 0
3、A 给用户加 100 块钱 price = 130
4、A 更新用户余额到数据库 update t_user set price=130,version=version+1 where userid=1 and version = 0
5、B 并不知道 A 已经把余额改为 130,B 只知道之前查询出来的用户余额为 30
6、B 给用户加 100 块钱 price = 130(这个结果是错误的,实际应该是230才对)
7、B 更新用户余额到数据库 update t_user set price=130,version=version+1 where userid=1 and version = 0
8、这时B的更新操作是失败的,因为A已经执行了version+1,所以 B 最终没有给用户加钱成功。
2.CAS操作(Compare and Swap)
CAS 是一种逻辑(比较并交换)。操作包含三个操作数。
- 内存值 V
- 旧的预期值 A
- 要修改的新值 B
当且仅当预期值A和内存值V相同时,将内存值V修改为B。否则什么都不做,或者执行自旋操作。
举个例子来说明CAS,有一个数 n = 0,现在要执行 n++ 操作。
可以把 n++ 拆分为以下三个步骤
1、读取主内存 n = 0 到工作内存
2、在工作内存中,对 n = n + 1
3、把工作内存中的 n 写入主内存
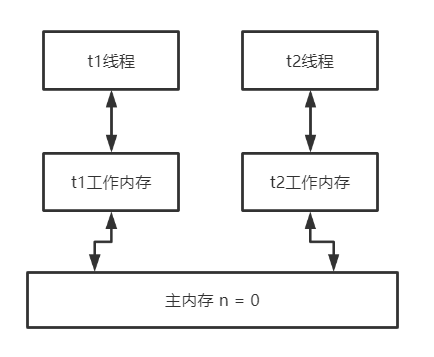
假设有 t1、t2 两个线程,同时执行 n++。
1、t1 线程执行 n++ 的第一步,读取主内存 n=0 到 t1 工作内存
2、t2 线程执行完成 n++ 的三个步骤,并把 n 写入主内存中,此时主内存中 n=1 (内存值V)
3、t1 线程执行 n++ 的第二步之前,先判断 t1 工作内存中的 n=0(预期值A)是否等于主内存中的 n=1(内存值V)
4、t1 线程发现预期值(A)不等于内存值(V),可以选择放弃后续操作,也可以执行自旋操作。
5、假设 t1 执行自旋操作
6、t1 线程重新读取主内存中 n=1 到 t1 工作内存,此时 t1 工作内存 n=1(预期值A)
7、t1 线程判断 t1 工作内存中的 n=1(预期值A)是否等于主内存中的 n=1(内存值V)
8、预期值A == 内存值V,t1 线程执行 n++ 的第二步和第三步,将计算结果 n = 2 写入主内存
2.1 JAVA中的CAS操作
public class TestVolatele {
private static volatile long n = 0;
public static void main(String[] args) throws Exception {
List<Thread> tList = new ArrayList<>();
for (int i = 0; i < 5; i++) {
tList.add(new Thread(() -> {
for (int j = 0; j < 2000; j++) {
n++;
}
}));
}
for (Thread thread : tList) {
thread.start();
}
for (Thread thread : tList) {
thread.join();
}
System.out.println(n);
}
}
上边的代码可以知道结果中n总是 <= 10000的。因为volatile关键字只保证可见性和有序性,但是不保证原子性,具体参考volatile。
为了解决上边的原子性问题,可以使用JAVA提供的院子操作类包java.util.concurrent.atomic,一系列以Atomic开头的包装类。例如AtomicBoolean,AtomicInteger,AtomicLong。它们分别用于Boolean,Integer,Long类型的原子性操作。
public class TestVolatele {
private static AtomicLong n = new AtomicLong(0);
public static void main(String[] args) throws Exception {
List<Thread> tList = new ArrayList<>();
for (int i = 0; i < 5; i++) {
tList.add(new Thread(() -> {
for (int j = 0; j < 2000; j++) {
n.getAndIncrement();
}
}));
}
for (Thread thread : tList) {
thread.start();
}
for (Thread thread : tList) {
thread.join();
}
System.out.println(n);
}
}
上边的代码,无论执行多少次,结果最终都是 10000,可以在并发情况下使用 Atomic 包来保证原子性,那为什么Atomic能保证原子性?因为 Atomic 底层使用的是CAS操作。
我们以AtomicInteger为例,找一个其中自增的方法分析一下:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
该方法主要为了自增,它调用了getAndAddInt方法。这个是方法是我们的Unsafe类下面。
//var1 是this指针
//var2 是地址偏移量
//var4 是自增的数值,是自增1还是自增N
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
//获取我们的的期望值赋值给var5
var5 = this.getIntVolatile(var1, var2);
//调用了Unsafe下面的另一个方法,是一个native方法
//如果期望值var5与内存值var2相等的话,更新内存值为var5+var4,否则更新期望值为内存值
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
compareAndSwapInt方法是底层c代码写的,里边涉及到cpu啥啥的,反正大概就是比较并替换的意思。
// 第一和第二个参数代表对象的实例以及地址,第三个参数代表期望值,第四个参数代表更新值
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
说白了就是 期望值(A)和内存值(V)做比较,如果期望值(A)不等于内存值(V),则更新期望值为内存值。一直重试到期望值(A)等于内存值(V),则更新内存值,并退出循环返回结果。
2.2 SQL中的CAS操作
// 查询出商品库存,num = 100
select num from items where id = 1
// 修改商品库存减1
update items set num = num - 1 where id = 1 and num = 100
sql中的cas比较简单,先查询一下库存表中当前库存数 num,在做更新的时候以查询出来的库存数作为条件去更新。
以上 SQL 其实还是有一定的问题的,就是一旦遇上高并发的时候,就只有一个线程可以修改成功,那么就会存在大量的失败,总让用户感知到失败显然是不合理的。
为了解决这个问题,一个比较好的建议,就是减小乐观锁粒度,最大程度的提升吞吐率,提高并发能力!如下:
// 修改商品库存减1
update items set num = num - 1 where id = 1 and num > 0
由于库存数不管怎么样都不可能为负数,所以可以把锁条件改为 num > 0,这样做可比 num = {num} 的吞吐率高了太多。
所以,在高并发环境下锁粒度把控是一门重要的学问。选择一个好的锁,在保证数据安全的情况下,可以大大提升吞吐率,进而提升性能。
2.3 CAS中的ABA问题
什么是ABA问题?比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。
举个例子
假设一个栈中,只有一个元素A
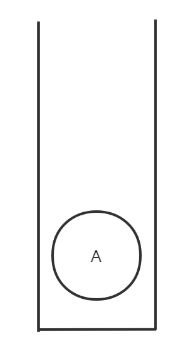
线程one查询栈中的第一个元素为 A。这时线程two往栈中放入了 B 元素,然后线程two再重新放入一个 A 元素
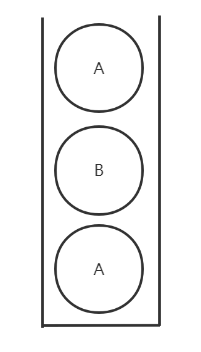
线程one一看,第一个元素还是 A,觉得没有问题,然后 one 进行了后续的业务操作。其实线程one看似没问题,但其实整个栈已经改变了。
如何解决ABA问题?
可以使用版本号的方式来解决。每次往栈中添加元素时,每个元素都带上一个version字段。例如上边的例子。
1、one 从栈中取出 A,并且取出 A 的 version = 1
2、two 往栈中放入 B ,同时设置 B 的 version = 2。再放入 A ,设置 A 的 version = 3
3、one 再比较 A 的时候,发现 version 不同,那么 A 就可以停止后续的业务操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号