公交车路线查询系统后台数据库设计--换乘算法改进与优化
在《查询算法》一文中已经实现了换乘算法,但是,使用存储过程InquiryT2查询从“东圃镇”到“车陂路口”的乘车路线时,发现居然用了5分钟才查找出结果,这样的效率显然不适合实际应用。因此,有必要对原有的换乘算法进行优化和改进。在本文中,将给出一种改进的换乘算法,相比原有的算法,改进后的算法功能更强,效率更优。
1. “压缩”RouteT0
假设RouteT0有以下几行

如下图所示,当查询S1到S4的二次换乘路线时,将会产生3×2×4=24个结果

从图中可以看出,第1段路线中的3条线路的起点和站点都相同(第2、3段路线也是如此),事实上,换乘查询中关心的是两个站点之间有无线路可通,而不关心是乘坐什么路线,因此,可以将RouteT0压缩为:

如下图所示,压缩后,查询结果有原来的24条合并1组

查询结果为:
![]()
那么,为什么要对视图RouteT0进行压缩呢,原因如下:
(1)RouteT0是原有换乘算法频繁使用的视图,因此,RouteT0的数据量直接影响到查询的效率,压缩RouteT0可以减少RouteT0的数据量,加速查询效率。
(2)压缩RouteT0后,将中转站点相同的路线合并为1组,加速了对结果集排序的速度。
2.视图GRouteT0
在数据库中,将使用GRouteT0来描述压缩的RouteT0,由于本文使用的数据库的关系图与《查询算法》中有所不同,在给出GRouteT0的代码前,先说明一下:

主要的改变是Stop_Route使用了整数型的RouteKey和StopKey引用Route和Stop,而不是用路线名和站点名。
GRouteT0定义如下:
create view GRouteT0 as select StartStopKey, EndStopKey, min(StopCount) as MinStopCount, max(StopCount) as MaxStopCount from RouteT0 group by StartStopKey,EndStopKey
注意,视图GRouteT0不仅有StartStopKey和EndStopKey列,还有MinStopCount列,MinStopCount是指从StartStop到EndStop的最短线路的站点数。例如:上述RouteT0对应的GRouteT0为:

3.二次查询算法
以下是二次换乘查询的存储过程GInquiryT2的代码,该存储过程使用了临时表来提高查询效率:
GInquiryT2 /* 查询站点@StartStops到站点@EndStops之间的二次换乘乘车路线,多个站点用'/'分开,结果以分组方式给出,如: exec InquiryT2 '站点1/站点2','站点3/站点4' */ CREATE proc GInquiryT2( @StartStops varchar(2048), @EndStops varchar(2048) ) as begin declare @ss_tab table(StopKey int) declare @es_tab table(StopKey int) insert @ss_tab select distinct Stop.StopKey from dbo.SplitString(@StartStops,'/') sn,Stop where sn.Value=Stop.StopName insert @es_tab select distinct Stop.StopKey from dbo.SplitString(@EndStops,'/') sn,Stop where sn.Value=Stop.StopName if(exists(select top 1 * from @ss_tab sst,@es_tab est where sst.StopKey=est.StopKey)) begin raiserror ('起点集和终点集中含有相同的站点',16,1) return end declare @stops table(StopKey int) insert @stops select StopKey from @ss_tab insert @stops select StopKey from @es_tab print '====================================================' print '筛选出第1段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第1段乘车路线,保存到临时表#R1中 select * into #R1 from GRouteT0 where StartStopKey in (select StopKey from @ss_tab) and EndStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表#R1上创建索引 create index index1 on #R1(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '筛选出第3段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第3段乘车路线,保存到临时表#R3中 select * into #R3 from GRouteT0 where EndStopKey in (select StopKey from @es_tab) and StartStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表上创建索引 create index index1 on #R3(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '筛选出第2段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第2段乘车路线,保存到临时表#R2中 select * into #R2 from GRouteT0 where StartStopKey in (select EndStopKey from #R1) and EndStopKey in (Select StartStopKey from #R3) --在临时表上创建索引 create clustered index index1 on #R2(StartStopKey,EndStopKey) create index index2 on #R2(EndStopKey,StartStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '二次换乘查询' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --二次换乘查询 select ss.StopName as 起点, dbo.JoinRoute(res.StartStopKey,res.TransStopKey1) as 路线1, ts1.StopName as 中转站1, dbo.JoinRoute(res.TransStopKey1,res.TransStopKey2) as 路线2, ts2.StopName as 中转站2, dbo.JoinRoute(res.TransStopKey2,res.EndStopKey) as 路线3, es.StopName as 终点, MinStopCount from( --查询出站点数最少的10组路线 select top 10 r1.StartStopKey as StartStopKey, r2.StartStopKey as TransStopKey1, r2.EndStopKey as TransStopKey2, r3.EndStopKey as EndStopKey, (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) as MinStopCount from #R1 r1,#R2 r2,#R3 r3 where r1.EndStopKey=r2.StartStopKey and r2.EndStopKey=r3.StartStopKey order by (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) asc )res, Stop ss, Stop es, Stop ts1, Stop ts2 where res.StartStopKey=ss.StopKey and res.EndStopKey=es.StopKey and res.TransStopKey1=ts1.StopKey and res.TransStopKey2=ts2.StopKey ------------------------------------------------------------ set statistics time off print '====================================================' end
4.测试
(1) 测试环境
测试数据:广州市350条公交车路线
操作系统:Window XP SP2
数据库:SQL Server 2000 SP4 个人版
CPU:AMD Athlon(tm) 64 X2 Dual 2.4GHz
内存:2G
(2)选择用于测试的的站点
二次换乘查询的select语句使用的三张表#R1,#R2,#R3,因此,这三张表的数据量直接影响到二次换乘查询使用的时间:
显然,R1的数据量由起点决定,查询起始站点对应的#R1的数据量的SQL语句如下:
select Stop.StopName as '站点',count(StartStopKey) '#R1的数据量' from RouteT0 full join Stop on RouteT0.StartStopKey=Stop.StopKey group by Stop.StopName order by count(StartStopKey) desc
运行结果如下:

显然,但起点为“东圃镇”时,#R1的数据量最大,同理可得终点和#R3数据量关系如下:

因此,在仅考虑数据量的情况下,查询“东圃镇”到“车陂路口”所用的时间是最长的。在下文中,将使用“东圃镇”作为起点,“车陂路口”为终点对二次查询算法进行效率测试
(3)效率测试
测试语句如下:
exec GInquiryT2 '东圃镇','车陂路口'
测试结果:
查询结果如下:
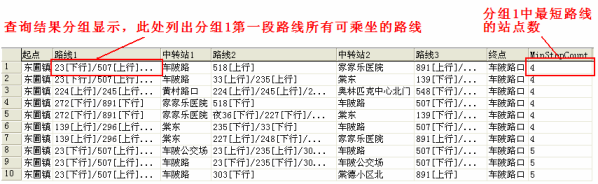
输出如下:
==================================================== 筛选出第1段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 458 行) SQL Server 执行时间: CPU 时间 = 10 毫秒,耗费时间 = 10 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 ==================================================== 筛选出第3段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 449 行) SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 9 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 1 毫秒,耗费时间 = 1 毫秒。 SQL Server 执行时间: CPU 时间 = 15 毫秒,耗费时间 = 1 毫秒。 ==================================================== 筛选出第2段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 41644 行) SQL Server 执行时间: CPU 时间 = 825 毫秒,耗费时间 = 825 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 93 毫秒,耗费时间 = 98 毫秒。 SQL Server 执行时间: CPU 时间 = 93 毫秒,耗费时间 = 98 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 SQL Server 执行时间: CPU 时间 = 73 毫秒,耗费时间 = 73 毫秒。 SQL Server 执行时间: CPU 时间 = 79 毫秒,耗费时间 = 73 毫秒。 ==================================================== 二次换乘查询 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 10 行) SQL Server 执行时间: CPU 时间 = 140 毫秒,耗费时间 = 141 毫秒。
从消息窗口的信息可以看出,查询大概用了1秒
5.效率优化
用GInquiryT2查询“东圃镇”到“车陂路口”仅用了1秒钟,那么,还能不能再优化呢?仔细分析输出的结果,可发现查询时最耗时的并不是换乘查询语句(140ms),而是筛选出第2段查询路线的语句(825ms),如图所示:

那么有没有方法可以提高筛选第2段路线的效率呢?答案是肯定的。只需把GRouteT0改成实表,并创建索引就行了。修改成实表后,就不需要把第2段路线缓存到临时表#R2中,修改后的GInquiryT2(重命名为GInquiryT2_1)如下:
/* 查询站点@StartStops到站点@EndStops之间的二次换乘乘车路线,多个站点用'/'分开,结果以分组方式给出,如: exec GInquiryT2_1 '站点1/站点2','站点3/站点4' */ CREATE proc GInquiryT2_1( @StartStops varchar(2048), @EndStops varchar(2048) ) as begin declare @ss_tab table(StopKey int) declare @es_tab table(StopKey int) insert @ss_tab select distinct Stop.StopKey from dbo.SplitString(@StartStops,'/') sn,Stop where sn.Value=Stop.StopName insert @es_tab select distinct Stop.StopKey from dbo.SplitString(@EndStops,'/') sn,Stop where sn.Value=Stop.StopName if(exists(select top 1 * from @ss_tab sst,@es_tab est where sst.StopKey=est.StopKey)) begin raiserror ('起点集和终点集中含有相同的站点',16,1) return end declare @stops table(StopKey int) insert @stops select StopKey from @ss_tab insert @stops select StopKey from @es_tab print '====================================================' print '筛选出第1段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第1段乘车路线,保存到临时表#R1中 select * into #R1 from GRouteT0 where StartStopKey in (select StopKey from @ss_tab) and EndStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表#R1上创建索引 create index index1 on #R1(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '筛选出第3段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第3段乘车路线,保存到临时表#R3中 select * into #R3 from GRouteT0 where EndStopKey in (select StopKey from @es_tab) and StartStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表上创建索引 create index index1 on #R3(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '二次换乘查询' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --二次换乘查询 select ss.StopName as 起点, dbo.JoinRoute(res.StartStopKey,res.TransStopKey1) as 路线1, ts1.StopName as 中转站1, dbo.JoinRoute(res.TransStopKey1,res.TransStopKey2) as 路线2, ts2.StopName as 中转站2, dbo.JoinRoute(res.TransStopKey2,res.EndStopKey) as 路线3, es.StopName as 终点, MinStopCount from( --查询出站点数最少的10组路线 select top 10 r1.StartStopKey as StartStopKey, r2.StartStopKey as TransStopKey1, r2.EndStopKey as TransStopKey2, r3.EndStopKey as EndStopKey, (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) as MinStopCount from #R1 r1,GRouteT0 r2,#R3 r3 where r1.EndStopKey=r2.StartStopKey and r2.EndStopKey=r3.StartStopKey order by (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) asc )res, Stop ss, Stop es, Stop ts1, Stop ts2 where res.StartStopKey=ss.StopKey and res.EndStopKey=es.StopKey and res.TransStopKey1=ts1.StopKey and res.TransStopKey2=ts2.StopKey ------------------------------------------------------------ set statistics time off print '====================================================' end
下面,仍然用查询“东圃镇”到“车陂路口”为例测试改成实表后GInquiryT2的效率,测试语句如下:
exec GInquiryT2_1 '东圃镇','车陂路口'
消息窗口输出如下:
==================================================== 筛选出第1段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 458 行) SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 3 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 ==================================================== 筛选出第3段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 449 行) SQL Server 执行时间: CPU 时间 = 6 毫秒,耗费时间 = 6 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 ==================================================== 二次换乘查询 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 10 行) SQL Server 执行时间: CPU 时间 = 250 毫秒,耗费时间 = 253 毫秒。 ====================================================
从输出可以看出,大概用了250ms
6.展开路线组
GInquiryT2查询给出的结果是10组最短路线,那么,怎样才能得到最短的10条路线,显然,只需将这10组路线展开即可(展开后的路线数>=10),而最短的10条路线必然在展开的结果中。查询10条最短路线的存储过程GInquiryT2_Expand如下:
CREATE proc GInquiryT2_Expand( @StartStops varchar(2048), @EndStops varchar(2048) ) as begin declare @ss_tab table(StopKey int) declare @es_tab table(StopKey int) insert @ss_tab select distinct Stop.StopKey from dbo.SplitString(@StartStops,'/') sn,Stop where sn.Value=Stop.StopName insert @es_tab select distinct Stop.StopKey from dbo.SplitString(@EndStops,'/') sn,Stop where sn.Value=Stop.StopName if(exists(select top 1 * from @ss_tab sst,@es_tab est where sst.StopKey=est.StopKey)) begin raiserror ('起点集和终点集中含有相同的站点',16,1) return end declare @stops table(StopKey int) insert @stops select StopKey from @ss_tab insert @stops select StopKey from @es_tab print '====================================================' print '筛选出第1段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第1段乘车路线,保存到临时表#R1中 select * into #R1 from GRouteT0 where StartStopKey in (select StopKey from @ss_tab) and EndStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表#R1上创建索引 create index index1 on #R1(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '筛选出第3段乘车路线' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --筛选出第3段乘车路线,保存到临时表#R3中 select * into #R3 from GRouteT0 where EndStopKey in (select StopKey from @es_tab) and StartStopKey not in (Select StopKey from @stops) order by StartStopKey,EndStopKey --在临时表上创建索引 create index index1 on #R3(StartStopKey,EndStopKey) ------------------------------------------------------------ set statistics time off print '====================================================' print '二次换乘查询' print '----------------------------------------------------' set statistics time on ------------------------------------------------------------ --二次换乘查询 select ss.StopName as 起点, r1.RouteName as '路线 1', ts1.StopName as 中转站1, r2.RouteName as '路线 2', ts2.StopName as 中转站2, r3.RouteName as '路线 3', es.StopName as 终点, res.StopCount as 总站点数 from( --展开最优 10 组路线 得到最短 10 条路线 select top 10 res.StartStopKey as StartStopKey, rt1.RouteKey as RouteKey_SS_TS1, res.TransStopKey1 as TransStopKey1, rt2.RouteKey as RouteKey_TS1_TS2, res.TransStopKey2 as TransStopKey2, rt3.RouteKey as RouteKey_TS2_ES, res.EndStopKey as EndStopkey, (rt1.StopCount+rt2.StopCount+rt3.StopCount) as StopCount from( --查询出站点数最少的 10 组路线 select top 10 r1.StartStopKey as StartStopKey, r2.StartStopKey as TransStopKey1, r2.EndStopKey as TransStopKey2, r3.EndStopKey as EndStopKey, (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) as MinStopCount from #R1 r1,GRouteT0 r2,#R3 r3 where r1.EndStopKey=r2.StartStopKey and r2.EndStopKey=r3.StartStopKey order by (r1.MinStopCount+r2.MinStopCount+r3.MinStopCount) asc )res, RouteT0 rt1, RouteT0 rt2, RouteT0 rt3 where rt1.StartStopKey=res.StartStopKey and rt1.EndStopKey=res.TransStopKey1 and rt2.StartStopKey=res.TransStopKey1 and rt2.EndStopKey=res.TransStopKey2 and rt3.StartStopKey=res.TransStopKey2 and rt3.EndStopKey=res.EndStopKey order by (rt1.StopCount+rt2.StopCount+rt3.StopCount) asc )res left join Stop ss on res.StartStopKey=ss.StopKey left join Stop es on res.EndStopKey=es.StopKey left join Stop ts1 on res.TransStopKey1=ts1.StopKey left join Stop ts2 on res.TransStopKey2=ts2.StopKey left join Route r1 on res.RouteKey_SS_TS1=r1.RouteKey left join Route r2 on res.RouteKey_TS1_TS2=r2.RouteKey left join Route r3 on res.RouteKey_TS2_ES=r3.RouteKey ------------------------------------------------------------ set statistics time off print '====================================================' end
下面,仍然以查询“东圃镇”到“车陂路口”为例测试GInquiryT2_Expand,代码如下:
exec GInquiryT2_Expand '东圃镇','车陂路口'
查询结果如下:
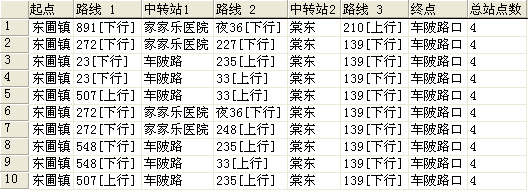
消息窗口输出如下:
==================================================== 筛选出第1段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 458 行) SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 3 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 ==================================================== 筛选出第3段乘车路线 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 449 行) SQL Server 执行时间: CPU 时间 = 6 毫秒,耗费时间 = 6 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 1 毫秒。 ==================================================== 二次换乘查询 ---------------------------------------------------- SQL Server 执行时间: CPU 时间 = 0 毫秒,耗费时间 = 0 毫秒。 (所影响的行数为 10 行) SQL Server 执行时间: CPU 时间 = 282 毫秒,耗费时间 = 301 毫秒。 ====================================================
由输出结果可看出,大约用了300ms
7.总结
下面,对本文使用的优化策略做一下总结:
(1)使用临时表;
(2)将频繁使用的视图改为表;
(3)从实际出发,合并RouteT0中类似的行,从而“压缩”RouteT0的数据量,减少查询生成的结果,提高查询和排序效率。
E-mail:mrlucc@126.com
出处:http://lucc.cnblogs.com/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号