
2021年1月31日 单列集合
为什么List集合存取顺序是一样的?
List是顺序存储的,即元素的存储结构是有顺序性的,第一个存入的元素会第一个被遍历到。
ArrayList与LinkedList的相同之处就是在于:
他们之中的元素都是按照存入顺序存储的

ArrayList是连续存储的,所以查找快,增删慢
LinkedList是不连续存储的。所以查找慢,增删快
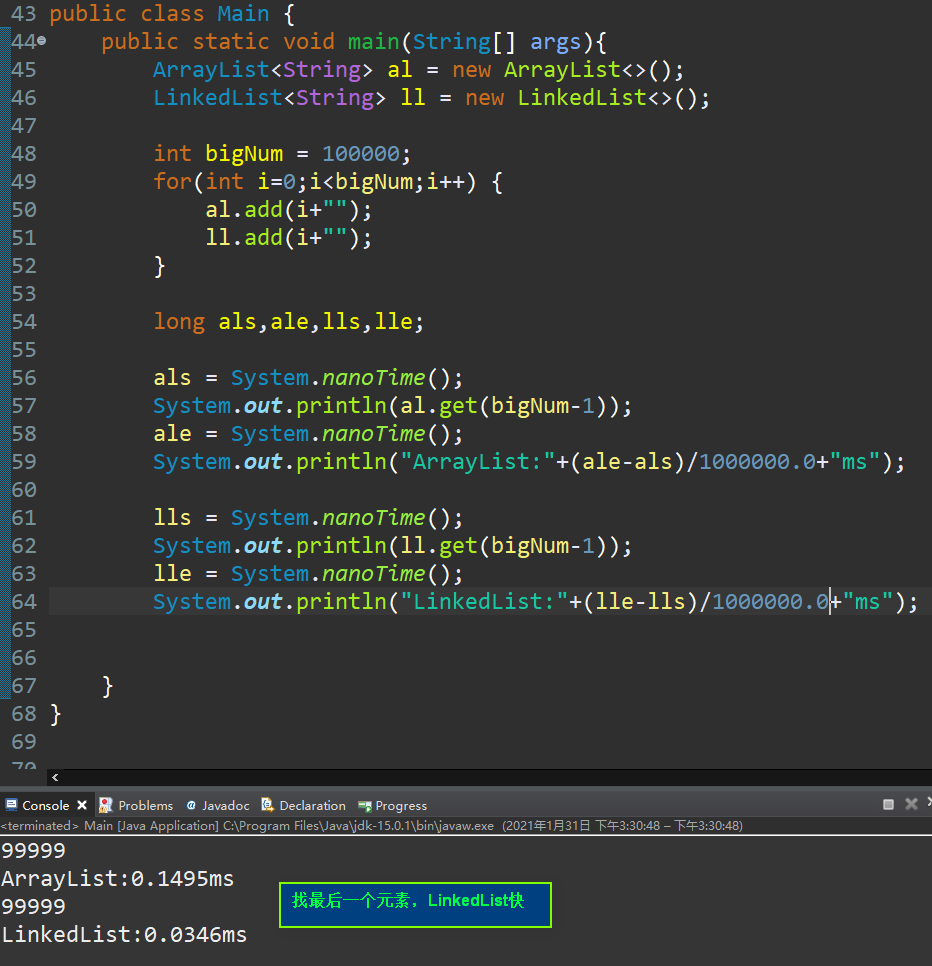
对比ArrayList与LinkedList的查找速度:
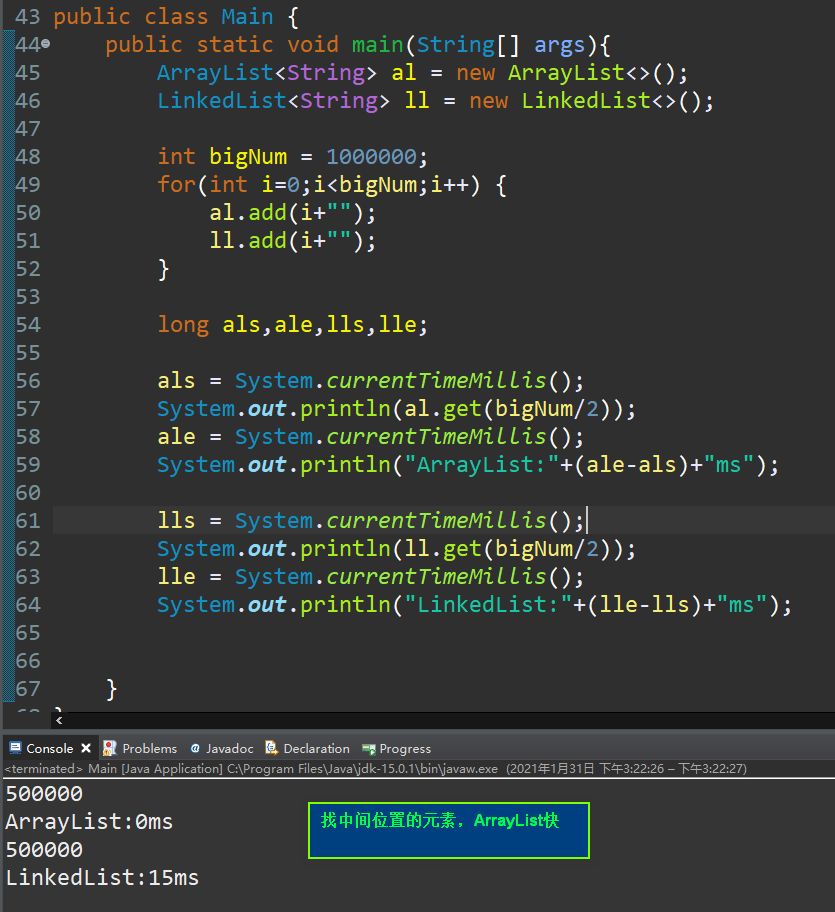
上面说的查找快慢不是绝对的,由于LinkedList可以从尾端开始找,有时候会比ArrayList快
为什么Set集合存取顺序不一样?
因为不管是HashSet还是TreeSet,都有自己独特的存储结构,存入时的规则、遍历的顺序与存储结构有关,与存入的先后顺序无关。
比如元素是学生,Set是校园
张三7点到校,去4班上课
李四7点半到校,去3班上课
王五8点到校,去1班上课
级部主任按照班级序号进行点名,
那么这三位学生被点到的次序就是:王五,李四,张三
但是早上上学他们到的先后顺序是:张三、李四、王五
为什么Set集合不能有重复元素?
Set的实现类
TreeSet集合,内部存储结构是二叉树
HashSet集合,内部存储元素的结构是哈希表
HashSet依靠hashCode()和equals()方法约束内部元素的唯一性。
HashSet的基本结构是:数组(存放hashcode)+链表(或二叉树),每个数组指向一个链表
而从Object类中继承过来的hashCode()和equals()方法是这样的:
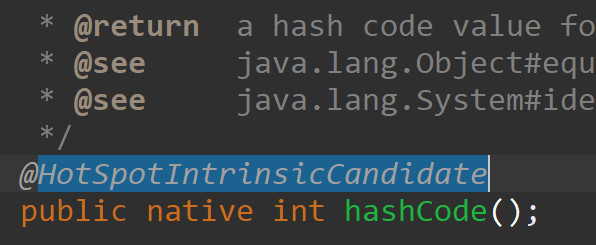
发现没有方法体, native表示该方法是外部定义的,C语言写的
但是我们能确定他肯定和内存地址有关
equals比较的就是内存地址。
所以如果想用HashSet集合存储自定义类型的元素,就需要重写该类的hashcode和equals方法,规定值相同的元素是重复的
比如下例中定义了一个Circle类,并规定只要半径相同就是重复的圆,如果我们不重写equals或hashcode中任意一个方法,都会输出四个圆
class Circle{ double radius; Circle(double radius){ this.radius = radius; } public String toString() { return "A Circle : "+radius; } public int hashCode() { final int prime = 31; int result = 1; long temp; temp = Double.doubleToLongBits(radius); result = prime * result + (int) (temp ^ (temp >>> 32)); return result; } public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Circle other = (Circle) obj; if (Double.doubleToLongBits(radius) != Double.doubleToLongBits(other.radius)) return false; return true; } } public class Main { public static void main(String[] args){ HashSet<Circle> hs = new HashSet<>(); hs.add(new Circle(5.5)); hs.add(new Circle(5.5)); hs.add(new Circle(5.5)); hs.add(new Circle(5.5)); System.out.println(hs); for(Circle c:hs) { System.out.println(c.hashCode()); } } }
LinkedHashSet与HashSet
查看源码发现:LinkedHashSet是HashSet的子类

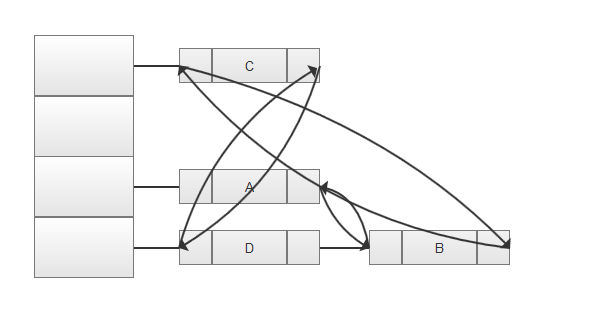
LinkedHashSet在内部存储时,在哈希表的基础上,每个元素还保存了前一个和后一个元素的内存地址,以达到存入顺序与遍历顺序一致:
对比LinkedHashSet与HashSet的区别(还是使用上面的圆类):
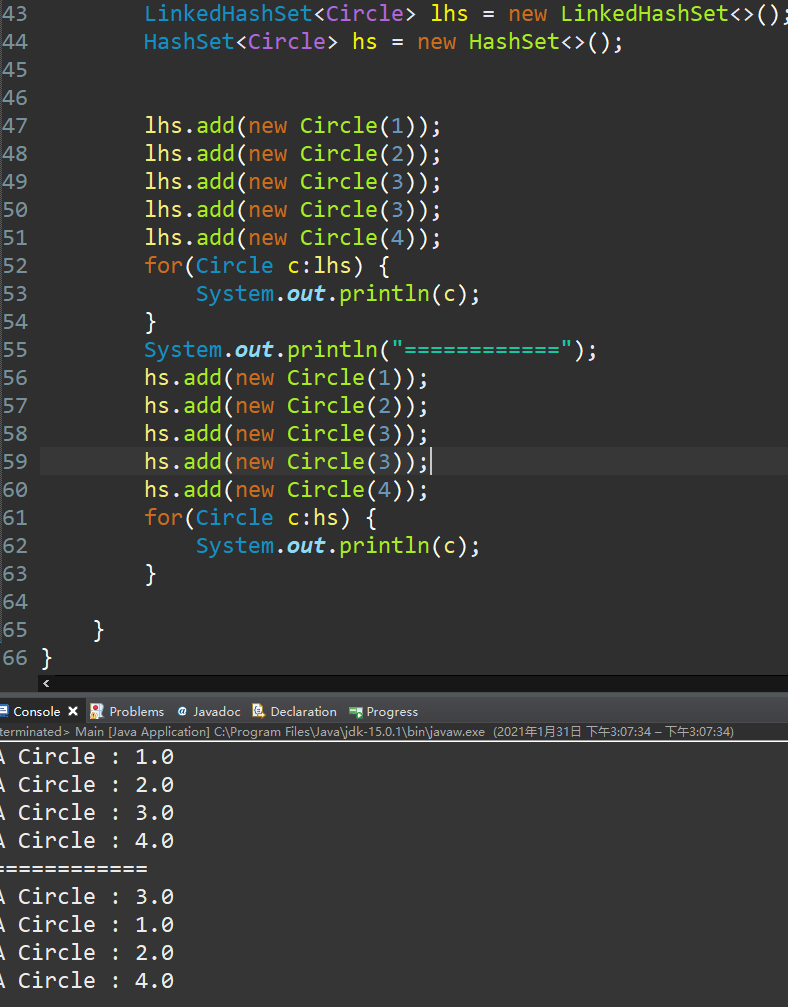
可见LinkedHashSet即能保证元素不重复,又可以按照存入顺序遍历出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号