
2021年1月26日 String类、StringBuffer类、正则表达式
StringBuffer类与StringBuilder类,所有方法是一样的。
StringBuilder sb = new StringBuilder("I Love "); //将字符串追加到此字符序列 sb.append("You");//I Love You //移除此序列的子字符串中的字符 sb.delete(6, 10);//I Love //将字符串插入此字符序列中 sb.insert(2, "don't ");//I don't Love //用给定字符串替换此序列的子字符串中的字符 sb.replace(8, 12, "Hate");//I don't Hate //将此字符序列反转 sb.reverse();//etaH t'nod I
正则表达式中需要加强记忆的:
|
除了 a、b 或 c以外的任何字符 |
[^abc] |
|
匹配的是一个大写或者小写字母 |
[A-Za-z] (注意在ascii码表中,Z与a之间还有别的字符,所以用A-z表示所有字母是错的!) |
|
X出现一次或一次也没有 |
X? |
|
换行符 |
\n |
|
回车符 |
\r |
|
X出现一次或多次 |
X+ |
|
X出现零次或多次 |
X* |
|
边界匹配器 |
\b |
|
\w |
[0-9a-zA-Z_] |
|
\d |
[0-9] |
==========================================
每个字符串都是String类的对象。所以可以直接用点调用String类的方法:
"ABC".split("");
====================
只要成员变量是final修饰的,就会进常量池(堆里面的一个区域),每个字符串都是这样
字符串的值实际上是:private final byte[] value;
================
String类的indexOf和contains 方法结合起来使用,可以计算出子串在字符串中出现的次数和位置:
算法如下:
String target = "This is a String,a very normal String!"; //定义被查找的字符串 String search = "String"; //定义需要查找的子字符串 int index = 0; //下标变量 int count = 0; //计数器 while(target.indexOf(search, index)>=0) { //循环条件为:从上一个找到的子串结尾开始,往后找是否还有下一个子串 System.out.println(count+1+":"+target.indexOf("String", index)); //输出找到的是第几个,以及下标 index = target.indexOf("String", index)+search.length(); //将刚找到的字符串末尾下标赋值给下标变量 count++; //计数器+1 }
=====================
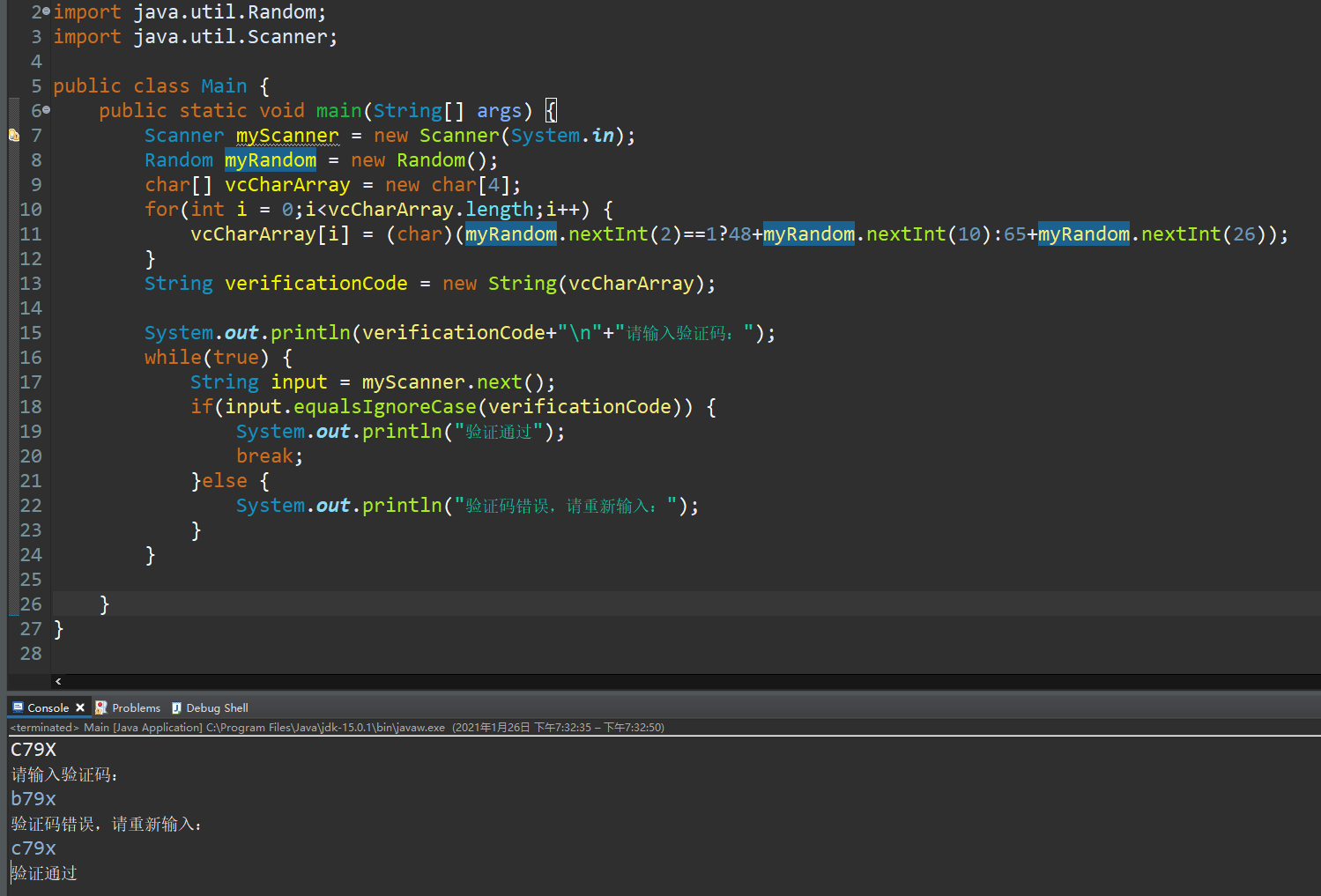
equalsIgnoreCase方法将来可用于验证码功能:
需求:设计一个小程序,产生随机的四位验证码(包含大写字母和数字),让用户输入验证码,验证用户输入是否正确(忽略字母大小写)
实现:
================
char类型和int类型可以相互转换
int a = '0'; System.out.println(a);//48 char b = 65; System.out.println(b);//A
=====================
StringBuffer的append可以传入任意类型的引用变量,会将该对象的toString方法返回值加在结尾
StringBuffer sb = new StringBuffer("Cat"); sb.append(new Object().toString()); System.out.println(sb);//Catjava.lang.Object@2f92e0f4
=====================
Java API 1.6 pattern类里可以看所有正则表达式规则

=====================
探讨:为什么java中的正则表达式反斜杠总是成对出现?
回忆JS中的正则表达式:
JS中的正则表达式不是字符串形式定义的,是用斜杠括起来的
反斜杠也用于转义,正则表达式中两个反斜杠表示匹配字符串中的一个反斜杠
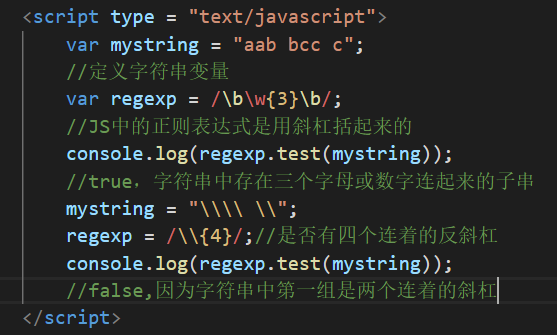
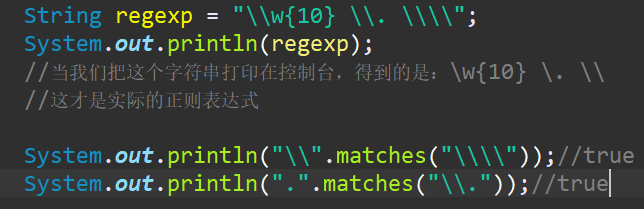
而Java中的正则表达式本身就是一个字符串,是用引号括起来的。
所以变量中的四个反斜杠,实际上表示匹配字符串中一个反斜杠
==================
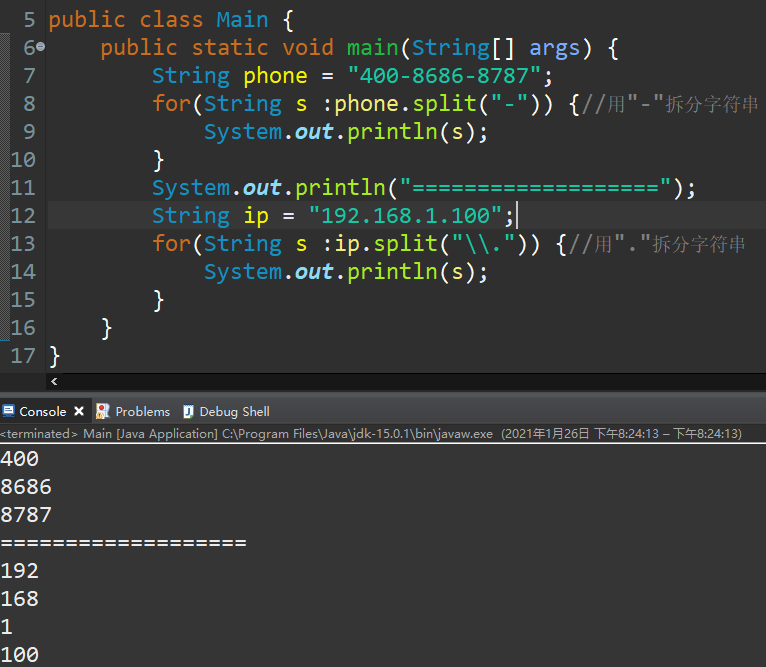
用split可以拆分ip地址,400电话等,非常有用
==========================================
匹配中文字符[\u4e00-\u9fa5](根据unicode编码表)

==================================
\u3000是中文空格

 浙公网安备 33010602011771号
浙公网安备 33010602011771号