Redis(REmote DIctionary Server)基础
Redis(REmote DIctionary Server)基础
Redis是一个开放源代码(BSD许可)的内存数据结构存储,用作数据库、缓存和消息代理。它支持字符串、哈希、列表、集合、带范围查询的排序集合、位图、超日志、带半径查询和流的地理空间索引等数据结构。Redis具有内置的复制、Lua脚本、LRU收回、事务和不同级别的磁盘上持久性,并通过Redis Sentinel和Redis群集的自动分区提供高可用性。
在生产环境中Redis一般有三种用途,可以用作数据库(Database),缓存(Cache),消息队列(Message Queue)。因此不关你是开发还是运维人员,学习一下Redis还是很有必要的!
一.redis认识及部署
1.什么是Redis
- 缓存数据库
软件说明 Redis是一款开源的,ANSI C语言编写的,高级键值(key-value)缓存和支持永久存储NoSQL数据库产 品。 Redis采用内存(In-Memory)数据集(DataSet) 。 支持多种数据类型。
- 软件特性
1)透明性:分布式系统对用户来说是透明的,一个分布式系统在用户面前的表现就像一个传统的单处理机分时系统,可让用户不必了解内部结构就可以使用。
2)扩展性:分布式系统的最大特点就是可扩展性,他可以根据需求的增加而扩展,可以通过横向扩展使集群的整体性能得到线性提升,也可以通过纵向扩展单台服务器的性能使服务器集群的性能得到提升。
3)可靠性:分布式系统不允许单点失效的问题存在,它的基本思想是:如果一台服务器坏了,其他服务器接替它的工作,具有持续服务的特性。
4)高性能:高性能是人们设计分布式系统的一个初衷,如果建立了一个透明,灵活,可靠的分布式系统,但他运行起来像蜗牛一样慢,那这个系统就是失败的。
1)透明性
2)拓展型
单机 多实例
3)高性能
redis的主从复制
redis的高可用
4)可靠性
分布式的一个初衷
运行非常快速
Redis:
1)优点:高性能读写、多数据类型支持、数据持久化、高可用架构、支持自定义虚拟内存、支持分布式分片集群、单线程读写性能极高
2)缺点:多线程读写较Memcached慢
Memcached:
1)优点:高性能读写、单一数据类型、支持客户端式分布式集群、一致性hash多核结构、多线程读写性能高。
2)缺点:无持久化、节点故障可能出现缓存穿透、分布式需要客户端实现、跨机房数据同步困难、架构扩容复杂度高
Tair:
1)优点:高性能读写、支持三种存储引擎(ddb、rdb、ldb)、支持高可用、支持分布式分片集群、支撑了几乎所有淘宝业务的缓存。
2)缺点:单机情况下,读写性能较其他两种产品较慢
-
redis集群
- 哨兵模式sentinel
- cluster
官方网站:https://redis.io/下载网站:http://download.redis.io/releases/帮助网站:http://redisdoc.com/
2.本篇操作环境介绍
[root@web01 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@web01 ~]# uname -r
3.10.0-957.el7.x86_64
[root@web01 ~]# uname -m
x86_64
3.部署Redis
利用epel源安装Redis
[root@web01 ~]# yum -y install epel-release
[root@web01 ~]# ll /etc/yum.repos.d/ #安装epel源之后,会生成2个文件
-rw-r--r-- 1 root root 951 Oct 2 2017 epel.repo
-rw-r--r-- 1 root root 1050 Oct 2 2017 epel-testing.repo
[root@web01 ~]#
yum info redis #看软件包信息,包括软件包名称、适用架构、版本号、发行版、软件大小、仓库名称、概要、URL、许可证、描述。
[root@web01 ~]# yum info redis
Available Packages
Name : redis
Arch : x86_64
Version : 3.2.12
Release : 2.el7
Size : 544 k
Repo : epel/x86_64
Summary : A persistent key-value database
URL : http://redis.io
License : BSD
Description : Redis is an advanced key-value store. It is often referred to as a data
: structure server since keys can contain strings, hashes, lists, sets and
[root@web01 ~]#
#安装redis
[root@web01 ~]# yum -y install redis
rpm -ql redis #查看安装的Redis信息
[root@web01 ~]# rpm -ql redis
/etc/logrotate.d/redis
/etc/redis-sentinel.conf
/etc/redis.conf
/etc/systemd/system/redis-sentinel.service.d
/etc/systemd/system/redis-sentinel.service.d/limit.conf
/etc/systemd/system/redis.service.d
/etc/systemd/system/redis.service.d/limit.conf
/usr/bin/redis-benchmark
/usr/bin/redis-check-aof
/usr/bin/redis-check-rdb
/usr/bin/redis-cli
/usr/bin/redis-sentinel
/usr/bin/redis-server
/usr/lib/systemd/system/redis-sentinel.service
/usr/lib/systemd/system/redis.service
/usr/libexec/redis-shutdown
/usr/share/doc/redis-3.2.12
/usr/share/doc/redis-3.2.12/00-RELEASENOTES
/usr/share/doc/redis-3.2.12/BUGS
/usr/share/doc/redis-3.2.12/CONTRIBUTING
/usr/share/doc/redis-3.2.12/MANIFESTO
/usr/share/doc/redis-3.2.12/README.md
/usr/share/licenses/redis-3.2.12
/usr/share/licenses/redis-3.2.12/COPYING
/usr/share/man/man1/redis-benchmark.1.gz
/usr/share/man/man1/redis-check-aof.1.gz
/usr/share/man/man1/redis-check-rdb.1.gz
/usr/share/man/man1/redis-cli.1.gz
/usr/share/man/man1/redis-sentinel.1.gz
/usr/share/man/man1/redis-server.1.gz
/usr/share/man/man5/redis-sentinel.conf.5.gz
/usr/share/man/man5/redis.conf.5.gz
/var/lib/redis
/var/log/redis
/var/run/redis
使用源码编译部署redis
1.下载redis
wget https://download.redis.io/redis-stable.tar.gz
2.解压
tar xf redis-stable.tar.gz
3.编译之前安装依赖
yum -y install python3
yum -y install gcc
4. 编译 && 安装
cd redis-stable
make && make install
#如果编译失败,可以尝试清除之前编译结果,再次重新编译
清理之前的编译结果:
make distclean
重新编译所有依赖库和Redis:
cd deps
make hiredis lua jemalloc hdr_histogram fpconv linenoise
cd ..
make && make install
5.查看版本
redis-server --version
6.启动服务
redis-server &
7.检查端口
[root@db03 redis-stable]# netstat -lntup
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 13617/redis-server
8.连接redis
[root@db03 redis-stable]# redis-cli
127.0.0.1:6379>
9.退出redis
127.0.0.1:6379> quit
127.0.0.1:6379> exit
#修改配置文件的默认端口
vim /root/redis-stable/redis.conf
port 6380
#重启redis
127.0.0.1:6379> SHUTDOWN
#使用修改过的端口运行,引导redis读取配置启动
redis-server /root/redis-stable/redis.conf &
#连接新的端口6380 -p指定端口
redis-cli -p 6380
二.Redis数据类型
(注意:Redis所有的数据都是键值对的性质,只是其对应的值可能是字符串,也可能是列表,或者是集合等数据类型)
redis数据类型
- string 字符串类型
- hash 哈希类型
- list 列表型
- set 集合型
- sorted set 有序集合
通用类型
# 查看当前库下所有值
127.0.0.1:6381> keys *
1) "age"
# 判断keyname是否存在
127.0.0.1:6381> keys name
(empty array)
127.0.0.1:6381> keys age
1) "age"
# 给存在的key改名
rename key newkey
127.0.0.1:6381> keys *
1) "age"
2) "ages"
127.0.0.1:6381> rename age ageeeee
OK
127.0.0.1:6381> keys *
1) "ageeeee"
2) "ages"
# 查看key的数据类型
type key
127.0.0.1:6381> type ages
string
# 删除key
del key
127.0.0.1:6381> del ageeeee
(integer) 1
127.0.0.1:6381> keys *
1) "ages"
# 查看key的生存时间
ttl key
ttl ages
(integer) -1
# 以秒为单位设置时间
expire key seconds
127.0.0.1:6381> expire ages 10
(integer) 1
127.0.0.1:6381> ttl ages
(integer) 5
127.0.0.1:6381> ttl ages
(integer) 4
127.0.0.1:6381> ttl ages
(integer) -2 (消失结束)
127.0.0.1:6381> keys *
(empty array)
# 以毫秒为单位设置时间
127.0.0.1:6381> pexpire age 10000
(integer) 1
127.0.0.1:6381> ttl age
(integer) 7
127.0.0.1:6381> ttl age
(integer) 6
127.0.0.1:6381> ttl age
(integer) 5
127.0.0.1:6381> ttl age
(integer) -2
127.0.0.1:6381> keys *
(empty array)
# 取消生存时间
persist key
127.0.0.1:6381> persist age
(integer) 1
string字符串类型
增
# 应用场景
常规计算 微博数 粉丝数 直播平台
# 如何设置string类型的key
set key value
127.0.0.1:6381> set name xxx
OK
# 同时设置多个值
127.0.0.1:6381> mset age 18 name xxx
OK
127.0.0.1:6381> keys *
1) "age"
2) "name"
# 设置key的同时设置生存时间
## 设置key并以秒为单位设置生存时间
set age 18 ex 10
OK
## 设置key并以毫秒为单位设置生存时间
set age 18 px 10000
## 递归增加
## 模拟获得粉丝
127.0.0.1:6381> set fans 1
OK
# 收获新的粉丝 在原本粉丝的基础上做递增
127.0.0.1:6381> incr fans
(integer) 2
127.0.0.1:6381> incr fans
(integer) 3
127.0.0.1:6381> incr fans
(integer) 4
# 一次增长两个
127.0.0.1:6381> incrby fans 2
(integer) 12
127.0.0.1:6381> incrby fans 2
(integer) 14
# 递归减少 递减
127.0.0.1:6381> decr fans
(integer) 19
127.0.0.1:6381> decr fans
(integer) 18
# 指定减少次数
127.0.0.1:6381> decrby fans 3
(integer) 11
127.0.0.1:6381> decrby fans 2
(integer) 9
127.0.0.1:6381> decrby fans 3
(integer) 6
# 小数点增张
127.0.0.1:6381> incrbyfloat fans 0.1
"1.1"
127.0.0.1:6381> incrbyfloat fans 0.8
"1.9"
127.0.0.1:6381> incrbyfloat fans 0.1
"2"
删
del keyname
127.0.0.1:6381> keys *
1) "age"
2) "fans"
3) "num"
4) "name"
5) "fan"
127.0.0.1:6381> del fans
(integer) 1
127.0.0.1:6381> keys *
1) "age"
2) "num"
3) "name"
4) "fan"
改
# 追加 append
127.0.0.1:6381> get name
"xxx"
127.0.0.1:6381> append name 666
(integer) 6
127.0.0.1:6381> get name
"xxx666"
# 修改指定的位数额值 从0开始算
127.0.0.1:6381> setrange name 1 y
(integer) 6
127.0.0.1:6381> get name
"xyx666"
查
# 获取key的值
127.0.0.1:6381> get name
"yyx666"
# 获取多个值
127.0.0.1:6381> mget name age
1) "yyx666"
2) "18"
# 查看值的字符长度
1) "yyx666"
2) "18"
127.0.0.1:6381> strlen name
(integer) 6
127.0.0.1:6381> strlen age
(integer) 2
# 查看以秒为单位存活时间
ttl age
(integer) -1
# 查看毫秒为单位的存活时间
127.0.0.1:6381> set haha xixi px 100000
OK
127.0.0.1:6381> pttl haha
(integer) 80911
# 字符串的截取
getrange key start end
set name 123456
127.0.0.1:6381> getrange name 0 3
"1234"
hash类型 字典型
# 存储部分变更的数据
用户信息 商品信息
最接近表结构的数据类型
# 大部分的缓存都会做hash类型
# 学生表
student表
# 设置key
hset key field value [field value ...]
127.0.0.1:6379> hmset student name aaa age 18
# 查看key
127.0.0.1:6381> hget student name
"aaa"
127.0.0.1:6381> hget student age
"18"
# 获取整个key的所有的字段
hgetall student
1) "name"
2) "aaa"
3) "age"
4) "18"
增
# 创建key
hset key field value [field value ...]
# 创建多个
hset studentid_2 name aaa age 20
删
127.0.0.1:6379> hgetall student
1) "name"
2) "zs"
3) "age"
4) "18"
5) "weight"
6) "66"
7) "high"
8) "172"
#删除hash类型中的一个值
127.0.0.1:6379> HDEL student name age
(integer) 1
127.0.0.1:6379> hgetall student
1) "weight"
2) "66"
3) "high"
4) "172"
#删除整个hash类型key
127.0.0.1:6379> DEL teacher
(integer) 1
127.0.0.1:6379> del student
(integer) 1
127.0.0.1:6379> keys *
1) "class_ji"
2) "class"
改
#修改hash类型值 增加1
127.0.0.1:6379> hincrby myhash num 1
(integer) 1
#hash类型值 减少1
127.0.0.1:6379> hincrby myhash num -1
(integer) 1
查
# 查询某一个字段
hget key field
hget student name
"111"
# 查询key中所有的字段
hgetall
hgetall student
1) "name"
2) "111"
3) "age"
4) "20"
# 查询key中特定字段
127.0.0.1:6379> hgetall studentid_2
1) "name"
2) "o"
3) "age"
4) "20"
127.0.0.1:6379> hmget studentid_2 name age
1) "o"
2) "20"
list列表型
增
lpush 从左变推入数据
rpush 从右边推入数据
#将一个值或者多个值插入列表的表头(若key不存在,则添加key并依次添加)
127.0.0.1:6379> lpush list zls
(integer) 1
127.0.0.1:6379> lpush list bgx
(integer) 2
127.0.0.1:6379> lpush list oldboy
(integer) 3
127.0.0.1:6379> lpush list alex
(integer) 4
#一行添加
127.0.0.1:6379> lpush teacher zls bgx oldboy alex
(integer) 4
#追加一个value值,若key不存在,则不创建
127.0.0.1:6379> LPUSHX teacher1 zls
(integer) 0
#在bgx前面添加zls
127.0.0.1:6379> linsert teacher before bgx zls
(integer) 6
#在尾部添加key
127.0.0.1:6379> rpush teacher wang5
(integer) 7
#将teacher的尾部元素弹出,再插入到teacher1的头部
127.0.0.1:6379> rpoplpush teacher teacher1
"wang5"
#查看一个列表内有多少行
127.0.0.1:6379> llen list
(integer) 4
#查看一个列表里所有元素
lrange teacher 0 -1
删
#删除key
127.0.0.1:6379> del teacher
(integer) 1
#从头部开始找,按先后顺序,值为a的元素,删除数量为2个,若存在第3个,则不删除
127.0.0.1:6379> lrem teacher 2 zls
(integer) 2
#从头开始,索引为0,1,2的3个元素,其余全部删除改
127.0.0.1:6379> ltrim teacher 0 2
OK
改
#从头开始, 将索引为1的元素值,设置为新值 e,若索引越界,则返回错误信息
127.0.0.1:6379> lset teacher 1 test
OK
#将 teacher 中的尾部元素移到其头部
127.0.0.1:6379> rpoplpush teacher teacher
"oldboy"
查
#列表头部弹出,弹一行少一行
127.0.0.1:6379> lpop teacher
"zls"
#列表尾部
127.0.0.1:6379> rpop teacher
"wang5"
#查询索引(头部开始)
127.0.0.1:6379> lindex teacher 0
"bgx"
#查询索引(尾部第一个)
127.0.0.1:6379> lindex teacher -1
"alex"
#范围查询索引
127.0.0.1:6379> lrange teacher 0 1
1) "bgx"
2) "oldboy"
set集合类型
集合型
# 应用场景
微博 社交平台 一个用户的所有关注者放到一个集合
一个用户的所有粉丝放到一个集合
实现共同关注 共同的爱好 二度好友
交集 并集 差集
1组 1 2 3 4 5
2组 1 3 5 7 9
# 交集
1 3 5
# 并集
1 2 3 4 5 7 9
# 差集
2 4 7 9
增
#若key不存在,创建该键及与其关联的set,依次插入bgx、lidao、xiaomimei若key存在,则插入value中,若bgx在zls_fans中已经存在,则插入了lidao和xiaomimei两个新成员。
127.0.0.1:6379> sadd zls_fans bgx lidao xiaomimei
(integer) 3
删
#尾部的b被移出,事实上b并不是之前插入的第一个或最后一个成员
127.0.0.1:6379> spop zls_fans
"bgx"
#若值不存在, 移出存在的值,并返回剩余值得数量
127.0.0.1:6379> SREM zls_fans lidao oldboy alex
(integer) 1
127.0.0.1:6379> smembers key1
1) "bb"
2) "dd"
3) "cc"
4) "aa"
#删除集合中指定的元素
127.0.0.1:6379> srem key1 aa
(integer) 1
127.0.0.1:6379> smembers key1
1) "bb"
2) "dd"
3) "cc"
改
key1 aa bb cc dd
key3 abcd aa
#将abcd从 key3 移到 key1
127.0.0.1:6379> smove key3 key1 abcd
(integer) 1
127.0.0.1:6379> smembers key1
1) "bb"
2) "dd"
3) "cc"
4) "aa"
5) "abcd"
查
#判断xiaomimei是否已经存在,返回值为 1 表示存在
127.0.0.1:6379> SISMEMBER zls_fans xiaomimei
(integer) 0
127.0.0.1:6379> SISMEMBER bgx_fans xiaomimei
(integer) 1
#查看set中的内容
127.0.0.1:6379> SMEMBERS zls_fans
1) "xiaomimei"
2) "bgx"
3) "lidao"
#获取Set 集合中元素的数量
127.0.0.1:6379> scard zls_fans
(integer) 0
127.0.0.1:6379> scard bgx_fans
(integer) 1
#随机的返回某一成员
127.0.0.1:6379> srandmember bgx_fans
"xiaomimei"
差集sdiff
##sdiff取集合之中不同之处
#两个key值先后顺序不一样,结果也不一样,谁在前,就是谁为参照,在前的key值减去相同的key值在输出结果
#创建三个集合
127.0.0.1:6379> sadd key1 aa bb cc dd
(integer) 4
127.0.0.1:6379> sadd key2 aa bb cc
(integer) 3
127.0.0.1:6379> sadd key3 abcd aa
(integer) 2
127.0.0.1:6379> keys *
1) "key3"
2) "key2"
3) "key1"
key1 aa bb cc dd
key2 aa bb cc
key3 abcd aa
127.0.0.1:6379> sdiff key1 key3
1) "bb"
2) "cc"
3) "dd"
127.0.0.1:6379> sdiff key2 key1
(empty array)
127.0.0.1:6379> sdiff key2 key3
1) "bb"
2) "cc"
127.0.0.1:6379> sdiff key3 key2
1) "abcd"
#1和2结果再拿来和3比较
127.0.0.1:6379> sdiff key1 key2 key3
1) "dd"
#3个集和比较,获取独有的元素,并存入diffkey 关联的Set中
127.0.0.1:6379> sdiffstore key4 key1 key2 key3
(integer) 1
127.0.0.1:6379> smembers key4
1) "dd"
交集sinter
#获得多个key中共同拥有的元素
key1 aa bb cc dd
key2 aa bb cc
key3 abcd aa
key4 dd
127.0.0.1:6379> sinter key1 key2 key3
1) "aa"
127.0.0.1:6379> sinter key1 key2 key3 key4
(empty array) //因为这里没有交集,所以返回一个空集合
#将交集结果放入到新的集合
127.0.0.1:6379> sinterstore key5 key1 key2 key3
(integer) 1
127.0.0.1:6379> smembers key5
1) "aa"
并集sunion
#获取3个集合中的成员的并集 (共同多项并为一项)
key1 aa bb cc dd
key2 aa bb cc
key3 abcd aa
key4 dd
key5 aa
127.0.0.1:6379> sunion key1 key2 key3 key4 key5
1) "abcd"
2) "bb"
3) "dd"
4) "aa"
5) "cc"
#把并集存入unionkey 关联的Set中
127.0.0.1:6379> sunionstore key6 key1 key2 key3 key4 key5
(integer) 5
127.0.0.1:6379> keys *
1) "key4"
2) "key5"
3) "key6"
4) "key2"
5) "key3"
6) "key1"
127.0.0.1:6379> smembers key6
1) "abcd"
2) "bb"
3) "dd"
4) "aa"
5) "cc"
sorted-set类型
应用场景:
排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可
增
# 增
## 模拟一个考试成绩
zadd key score member [score member ...]
127.0.0.1:6379> zadd score 100 xxx 50 yyy 48 zzz
(integer) 3
删
#删除多个成员变量,返回删除的数量
127.0.0.1:6379> zrem score xxx yyy
(integer) 2
127.0.0.1:6379> zrange score 0 -1
1) "zzz"
#删除分数 50<= score <= 100 的成员,并返回实际删除的数量
127.0.0.1:6379> zremrangebyscore score 50 100
(integer) 2
#删除位置索引满足表达式 0 <= rank <= 1 的成员
127.0.0.1:6379> zrange score 0 -1
1) "zzz"
2) "yyy"
3) "xxx"
127.0.0.1:6379> zremrangebyrank score 0 1
(integer) 2
127.0.0.1:6379> zrange score 0 -1
1) "xxx"
改
#将成员 zzz 的分数增加 2,并返回该成员更新后的分数
127.0.0.1:6379> zincrby score 2 zzz
"50"
查
#返回所有成员和分数,不加WITHSCORES,只返回成员
127.0.0.1:6379> zrange score 0 -1
1) "zzz"
2) "yyy"
3) "xxx"
127.0.0.1:6379> zrange score 0 -1 withscores
1) "zzz"
2) "48"
3) "yyy"
4) "50"
5) "xxx"
6) "100"
127.0.0.1:6379> zrange score 0 1
1) "zzz"
2) "yyy"
#获取成员 xxx 在Sorted-Set中的位置索引值。0表示第一个位置
127.0.0.1:6379> zrank score xxx
(integer) 2
#获取 score 键中成员的数量
127.0.0.1:6379> zcard score
(integer) 3
#获取分数满足表达式 10 <= score <= 60 的成员的数量
zcount key min max
127.0.0.1:6379> zcount score 10 60
(integer) 2
#获取成员 zzz 的分数
zscore key member
127.0.0.1:6379> zscore score zzz
"48"
#获取分数满足表达式 50 <= score <= 100 的成员
127.0.0.1:6379> zrangebyscore score 50 100
1) "yyy"
2) "xxx"
#获取分数满足表达式 50 <= score <= 100 的成员和分数
127.0.0.1:6379> zrangebyscore score 50 100 withscores
1) "yyy"
2) "50"
3) "xxx"
4) "100"
根据限制查询
# -inf 表示第一个成员,+inf最后一个成员
#limit限制关键字
127.0.0.1:6379> zadd chengji 100 xxx 50 yyy 48 zzz 38 aaa 28 bbb 18 ccc 8 ddd
(integer) 7
127.0.0.1:6379> zrange chengji 0 -1
1) "ddd"
2) "ccc"
3) "bbb"
4) "aaa"
5) "zzz"
6) "yyy"
7) "xxx"
# limit 0 3 0表示索引号,第一个成员,3表示限制成员三个
127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 0 3
1) "ddd"
2) "ccc"
3) "bbb"
127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 2 3
1) "bbb"
2) "aaa"
3) "zzz"
#所有元素
127.0.0.1:6379> zrange chengji 0 -1 WITHSCORES
1) "ddd"
2) "8"
3) "ccc"
4) "18"
5) "bbb"
6) "28"
7) "aaa"
8) "38"
9) "zzz"
10) "48"
11) "yyy"
12) "50"
13) "xxx"
14) "100"
#按位置索引从高到低,获取所有成员和分数
127.0.0.1:6379> zrevrange chengji 0 -1 WITHSCORES
1) "xxx"
2) "100"
3) "yyy"
4) "50"
5) "zzz"
6) "48"
7) "aaa"
8) "38"
9) "bbb"
10) "28"
11) "ccc"
12) "18"
13) "ddd"
14) "8"
#根据索引查询
#查找索引为0 1 2 的成员
127.0.0.1:6379> zrange chengji 0 2
1) "ddd"
2) "ccc"
3) "bbb"
#查找索引为0 1 2 的成员,反向输出(可以理解为从反方向查询)
127.0.0.1:6379> zrevrange chengji 0 2
1) "xxx"
2) "yyy"
3) "zzz"
#相反的顺序:从高到低的顺序
zrevrangebyscore chengji max min [WITHSCORES]
#获取分数 50>=score>=100的成员并以相反的顺序输出
127.0.0.1:6379> zrevrangebyscore chengji 100 50
1) "xxx"
2) "yyy"
#获取索引是1和2的成员,并反转位置索引
zrevrangebyscore chengji max min [WITHSCORES]
127.0.0.1:6379> zrevrangebyscore chengji 100 50 limit 1 2
1) "yyy"
redis消息队列(了解)
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息生产者只管把消息发布到MQ中而不管谁来取,消息消费者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
消息队列产品
- 1)rabbit-MQ(最初起源于金融系统,用于分布式系统中存储转发消息。OpenStack)
- 2)Zero-MQ(SaltStack)
- 3)Kafka(JAVA)
- 4)redis(key:value数据库,缓存,消息队列)
生产消费模型

任务队列模式(queuing)
任务队列:顾名思义,就是“传递消息的队列”。与任务队列进行交互的实体有两类,一类是生产者(producer),另一类则是消费者(consumer)。生产者将需要处理的任务放入任务队列中,而消费者则不断地从任务独立中读入任务信息并执行。
任务队列好处
-
1)松耦合。
生产者和消费者只需按照约定的任务描述格式,进行编写代码。 -
2)易于扩展。
多消费者模式下,消费者可以分布在多个不同的服务器中,由此降低单台服务器的负载。
发布 订阅模式
订阅
127.0.0.1:6379> subscribe aaa频道
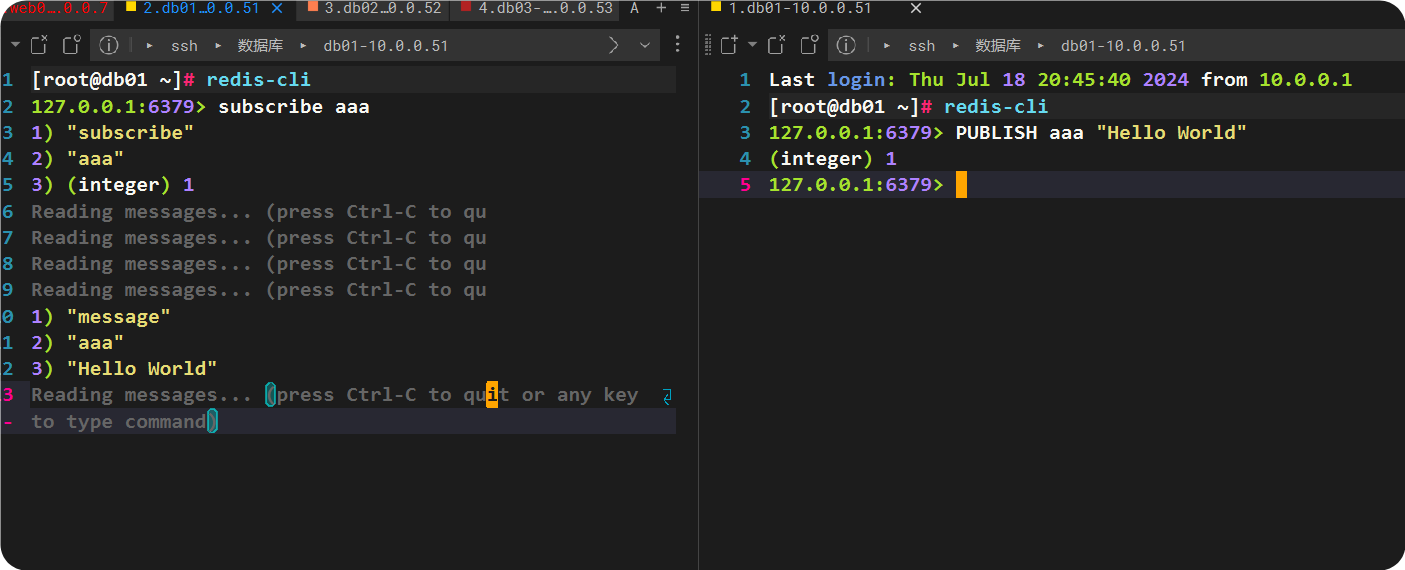
发布(另开一个窗口)
127.0.0.1:6379> PUBLISH aaa "Hello World"
订阅频道显示如下
127.0.0.1:6379> subscribe aaa
1) "subscribe"
2) "aaa"
3) (integer) 1
1) "message"
2) "aaa"
3) "Hello World"
订阅所有频道
PSUBSCRIBE *
subscribe 订阅单个
psubscribe 订阅多个
unsubscribe 取消订阅单个
punsubscribe 取消订阅多个
三.Redis服务常用配置介绍
redis基操
redis守护进程
# 修改配置文件 守护进程模式,放到后台运行
vim /root/redis-stable/redis.conf
daemonize yes
# 启动redis让他读取配置文件
[root@db01 ~]# redis-server /root/redis-stable/redis.conf
######报错解决
8470:C 15 Jul 2024 19:08:08.478 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
vim /etc/sysctl.conf #编辑文件添加如下内容
vm.overcommit_memory = 1
命令行执行
sysctl vm.overcommit_memory=1
# 再次启动redis
[root@db01 ~]# redis-server /root/redis-stable/redis.conf
检查端口查看是否启动OK
redis的基本操作
高级键值(key-value)
key
value
# redis一共有16个库
0-15
# redis切换库
SELECT index(0-15)
# 只能切换0-15数字
127.0.0.1:6379[1]> SELECT 16
(error) ERR DB index is out of range
# 创建数据语句
set key value
127.0.0.1:6379> set name xxx
OK
127.0.0.1:6379> set age 20
OK
# 查看数据
127.0.0.1:6379> keys *
1) "name"
2) "age"
# 注意点 企业中不要随便使用keys *, 使用keys *会将redis数据全部加载到内存里,数据过大会将内存占满
127.0.0.1:6379> keys name
1) "name"
#如果key值不存在?
127.0.0.1:6379> keys names
(empty array)
#查看key的值
get key
127.0.0.1:6379> get name
"xxx"
127.0.0.1:6379> get age
"20"
#清空当前库的数据 慎用!!!!
127.0.0.1:6379> flushdb
OK
#清空所有库的数据 !!!!慎用!!!!
127.0.0.1:6379> flushall
OK
redis的安全设置
- bind 指定ip去监听
- protected-mode 保护模式
- requirepass 输入密码保护
bind配置
vim /root/redis-stable/redis.conf
bind 10.0.0.51 172.16.1.51 127.0.0.1
#使用另外一台机器连接51机器的redis 使用 -h 指定要连接的ip
[root@lb01 redis-stable]# redis-cli -h 10.0.0.51
10.0.0.51:6379>
[root@lb01 redis-stable]# redis-cli -h 172.16.1.51
172.16.1.51:6379>
#此时仅仅连接,但是不能对对端的redis库进行修改,
#因为对端的redis 保护模式 是开启的所以连接是可以连接 但是读写的操作都是禁止的,需要把保护模式关掉
保护模式
# 关闭保护模式
vim /root/redis-stable/redis.conf
protected-mode yes ------ > no
# 测试对端redis连接并操作
[root@lb01 redis-stable]# redis-cli -h 172.16.1.51
172.16.1.51:6379> keys *
(empty array)
172.16.1.51:6379> set age 18
OK
172.16.1.51:6379> keys *
1) "age"
# 查看本地
127.0.0.1:6379> keys *
1) "age"
设置redis密码
# 添加redis密码(自行添加)
vim /root/redis-stable/redis.conf
requirepass 123
# 重启redis
# 对端测试密码
[root@lb01 redis-stable]# redis-cli -h 172.16.1.51
172.16.1.51:6379>
# 只有输入正确密码才可以在对端进行操作
172.16.1.51:6379> auth 123
OK
172.16.1.51:6379> keys *
1) "age"
172.16.1.51:6379> keys *
1) "age"
# 第二种输入密码的方式
redis-cli -h 172.16.1.51 -a 123
# 警告 会暴露密码不安全
Warning: Using a password with '-a' or '-u' option on the command line interface
may not be safe.
使用redis
开启redis日志
# 需要通过修改配置文件 (手动输入路径)
vim /root/redis-stable/redis.conf
logfile "/var/log/redis/redis.log"
# 创建存放日志的上一级目录
mkdir /var/log/redis
# 重启redis
[root@db01 redis-stable]# redis-server redis.conf
[root@db01 redis-stable]# ll /var/log/redis/
total 4
-rw-r--r-- 1 root root 770 Jul 15 16:21 redis.log
库内查看redis配置
# 查看所有的配置 (配置文件的配置)
127.0.0.1:6379> CONFIG GET *
# 查看特定的某个配置
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "10.0.0.51 172.16.1.51 127.0.0.1"
127.0.0.1:6379> CONFIG GET protected-mode
1) "protected-mode"
2) "no"
# 在库内临时修改某个配置
127.0.0.1:6379> CONFIG set requirepass 123
OK
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) "123"
127.0.0.1:6379> keys *
1) "age"
# 如果配置文件有requirepass 456
# CONFIG set requirepass 123
# CONFIG set 是临时修改 会替换掉配置文件里面的配置
# 一旦重启 还是会以配置文件的配置为准
redis多实例
# 编辑多个不同的配置文件 启动不同的redis
#准备多个配置文件
mkdir -p /data/638{0,1,2}/redis
port
日志
守护进程
bind
保护模式 关闭
# 准备6380的配置文件
vim /data/6380/redis/redis.conf
port 6380
logfile "/data/6380/redis/redis.log"
daemonize yes
bind 10.0.0.51 172.16.1.51 127.0.0.1
protected-mode no
# 准备6381的配置文件
vim /data/6381/redis/redis.conf
port 6381
logfile "/data/6381/redis/redis.log"
daemonize yes
bind 10.0.0.51 172.16.1.51 127.0.0.1
protected-mode no
# 准备6382的配置文件
vim /data/6382/redis/redis.conf
port 6500
logfile "/data/6500/redis/redis.log"
daemonize yes
bind 10.0.0.51 172.16.1.51 127.0.0.1
protected-mode no
# 启动redis的多实例
[root@db01 redis-stable]# redis-server /data/6380/redis/redis.conf
[root@db01 redis-stable]# redis-server /data/6381/redis/redis.conf
[root@db01 redis-stable]# redis-server /data/6382/redis/redis.conf
# 测试多实例连接
[root@db01 redis-stable]# redis-cli -p 6380
127.0.0.1:6380>
[root@db01 redis-stable]# redis-cli -p 6381
127.0.0.1:6381>
[root@db01 redis-stable]# redis-cli -p 6382
127.0.0.1:6500>
配置文件详解
[root@web01 ~]# grep "^##" /etc/redis.conf
###### INCLUDES ###### ------> 基本配置,用来模块化配置文件,和nginx很相似通过include关键字加载配置文件
###### NETWORK ###### -----> 网络配置项
###### GENERAL ###### -----> 一般行选项
###### SNAPSHOTTING ###### -----> 快照持久化相关配置项
###### REPLICATION ###### -----> 复制相关配置项
###### SECURITY ###### -----> 安全相关配置项
###### LIMITS ###### -----> Limit相关的配置
###### APPEND ONLY MODE ###### -----> 简称AOM持久化
###### LUA SCRIPTING ###### -----> LUA脚本先关
###### REDIS CLUSTER ###### ----> Redis集群相关
###### SLOW LOG ###### -----> 慢日志SlowLog相关的配置
###### LATENCY MONITOR ###### -----> 延迟监控
###### EVENT NOTIFICATION ###### -----> 事件通知
###### ADVANCED CONFIG ###### -----> 高级配置
INClUDES配置端文件说明
用来把整个配置文件模块化的,大家知道把配置文件模块化也是一个趋势。把一个大配置文件切割成很多段,我们找一个中心配置文件,然后使用include的方式把其他以“*.conf”的文件通通包含进来。比如nginx和http都是这样干的!这样的方式的好处就是将来我们可以使用脚本或者运维工具来生成或者删除配置文件达到去配置应用程序的目的
因此我们可以说INCLUDES是便于我们达到标准化,工具化一种有效的支撑机制。
NETWORK 配置端文件说明
bind参数:
顾名思义,用来指定绑定的地址,类似于Kafka服务中的LISTEN,即指定监听的地址,我们通常使用"0.0.0.0"来通配当前主机的所有地址
protected-mode参数:
默认是启用保护模式的(即默认值为yes),启动保护默认需要两个必要条件:
第一:没有使用 bind 参数
第二:没有使用 pasword 配置
port参数:
设置监听的端口,Redis默认监听的端口为6379。
tcp-backlog参数:
和Tomcat类似,它是设置后援队列长度的,即当并发量达到上限时,我们打算在后端启用承载多长的队列。
unixsocket参数:
如果Redis只是本地连接,建议使用更高性能的连接方式。也就是说本地连接时建议启用该参数,因为它会更高效,我们知道MySQL也支持类型的功能。
unixsocketperm参数:
设置本地连接文件的权限。
timeout参数:
表示我们关闭连接时,客户端运行空闲多长时间。如果设置为0表示禁用该功能,默认就是禁用状态!也就是说只要客户端连接进来,不管他是否做增删改查,服务端都不会主动去端口连接的。如果高并发连接的生产环境,建议开启该功能,比如可以设置为5分钟(300s)!
tcp-keepalive参数:
和timeout的功能类似,只不过该参数控制的是tcp的连接超时时间,默认时间为300s。
GENERAL 配置端文件说明
daemonize参数:
表示是否设置为守护进程,默认值为no。由于CenOS5,CentOS6以及CentOS7管理服务的方式是不同的。在CentOS7操作系统时,所有的服务都交给systemd服务去管理的,所有的服务都得在systemd总线中注册。在CentOS6可以设置为yes,但是在CentOS7的话建议使用默认值,即设置为no。
supervised参数:
可以通过upstart和systemd管理Redis守护进程,选项如下:
supervised no - 没有监督互动
supervised upstart - 通过将Redis置于SIGSTOP模式来启动信号
supervised systemd - signal systemd将READY = 1写入$ NOTIFY_SOCKET
supervised auto - 检测upstart或systemd方法基于 UPSTART_JOB或NOTIFY_SOCKET环境变量
pidfile参数:
配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面。
loglevel参数:
定义日志级别。可以是下面的这些值:
debug(记录大量日志信息,适用于开发、测试阶段)
verbose(较多日志信息)
notice(适量日志信息,使用于生产环境)
warning(仅有部分重要、关键信息才会被记录)
logfile 参数:
日志文件的位置,当指定为空字符串时,为标准输出,如果redis已守护进程模式运行,那么日志将会输出到/dev/null
syslog-enabled参数:
默认值为yes,要想把日志记录到系统日志,就把它改成 yes,也可以可选择性的更新其他的syslog 参数以达到你的要求。
syslog-ident参数:
设置系统日志的ID
syslog-facility参数:
指定系统日志设置,必须是 USER 或者是 LOCAL[0-7] 之间的值
databases 参数:
设置数据库的数目。默认的数据库是DB 0 ,可以在每个连接上使用select <dbid> 命令选择一个不同的数据库。我们知道Redis默认的数据库只有16个,如果你想不想限制Redis的数据库数量的话,可以将其的值设置为-1。
SECURITY 配置端文件说明
requirepass 参数:
表示客户端连接时必须输入密码才能连接,Redis默认是禁用该功能的。我们可以指定连接时的密码,比如我们设置连接密码为 yinzhengjie,那么我们配置时就可以设置为:“requirepass yinzhengjie”rename-command参数: 表示命令重命名,Redis有几个非常危险的命令,执行后可以瞬间把Redis中的数据删除掉,因此我们可以设置成一个复杂的字符串,当执行一些危险的命令时需要使用我们自定义的字符串去操作!从而达到运维人员手抖误操作做的尴尬场景,但改参数我们在生产环境中也很少使用!
LIMITS 配置端文件说明
maxclients参数:
设置客户端最大并发连接数,默认是1万,这个默认值是比较合理的,我们基本上可以不用去修改,毕竟Redis一般情况下并不是面向互联网客户端的,而是面临应用系统内的各种应用程序服务器的。
maxmemeory参数:
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key。生产环境中建议设置为物理机的一半内存。因为设置过大有可能会出现OOM(Out Of Memory)。 注意,内存泄露是导致OOM发生的可能性因素之一,当发生OOM时,内核为了自救(因为内核的运行也是需要内存空间的),内核将自动杀死最“吃”内存资源的进程,从而保证操作系统运行正常。它内部有一个oom_score用来记录每个进程占用内存的分数,我们可以通过oom_adj来调整内核去杀死进程的机制!
maxmemory-policy参数:
当内存使用达到最大值时,redis使用的清楚策略。有以下几种可以选择:
1.volatile-lru
利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
2.allkeys-lru
利用LRU算法移除任何key
3.volatile-random
移除设置过过期时间的随机key
4.allkeys-random
移除随机ke
5.volatile-ttl
移除即将过期的key(minor TTL)
6.noeviction noeviction
不移除任何key,只是返回一个写错误 ,默认选项
maxmemory-samples参数:
LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法(为了节省内存)。随意你可以选择样本大小进行检,redis默认选择5个样本进行检测,你可以通过maxmemory-samples进行设置样本数
SLOW LOG 配置端文件说明
slowlog-log-slower-than参数:
slog log是用来记录redis运行中执行比较慢的命令耗时。当命令的执行超过了指定时间,就记录在slow log中,slog log保存在内存中,所以没有IO操作。执行时间比slowlog-log-slower-than大的请求记录到slowlog里面,单位是微秒,默认是10毫秒。
注意,负数时间会禁用慢查询日志,而0则会强制记录所有命令。
slowlog-max-len参数:
慢查询日志长度。当一个新的命令被写进日志的时候,最老的那个记录会被删掉,这个长度没有限制。只要有足够的内存就行,你可以通过 SLOWLOG RESET 来释放内存。
ADVANCED CONFIG 配置端文件说明
hash-max-ziplist-entries参数:
hash类型的数据结构在编码上可以使用ziplist和hashtable。ziplist的特点就是文件存储(以及内存存储)所需的空间较小,在内容较小时,性能和hashtable几乎一样。因此redis对hash类型默认采取ziplist。如果hash中条目的条目个数或者value长度达到阀值,将会被重构为hashtable。这个参数指的是ziplist中允许存储的最大条目个数,,默认为512,建议为128
hash-max-ziplist-value参数:
ziplist中允许条目value值最大字节数,默认为64,建议为1024。
list-max-ziplist-size参数:
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
list-compress-depth参数:
这个参数表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。参数list-compress-depth的取值含义如下:
0: 是个特殊值,表示都不压缩。这是Redis的默认值。
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
依此类推…
由于0是个特殊值,很容易看出quicklist的头节点和尾节点总是不被压缩的,以便于在表的两端进行快速存取。
set-max-intset-entries参数:
数据量小于等于set-max-intset-entries用intset,大于set-max-intset-entries用set。
zset-max-ziplist-entries和zset-max-ziplist-value参数:
数据量小于等于zset-max-ziplist-entries用ziplist,大于zset-max-ziplist-entries用zset
hll-sparse-max-bytes参数:
value大小小于等于hll-sparse-max-bytes使用稀疏数据结构(sparse)大于hll-sparse-max-bytes使用稠密的数据结构(dense),一个比16000大的value是几乎没用的,建议的value大概为3000。如果对CPU要求不高,对空间要求较高的,建议设置到10000左右
activerehashing参数:
Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置为no。如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存
client-output-buffer-limit normal 0 0 0参数:
(一般指正常客户端)对客户端输出缓冲进行限制可以强迫那些不从服务器读取数据的客户端断开连接,用来强制关闭传输缓慢的客户端。对于normal client,第一个0表示取消hard limit,第二个0和第三个0表示取消soft limit,normal client默认取消限制,因为如果没有寻问,他们是不会接收数据的。
client-output-buffer-limit slave 256mb 64mb 60参数:
(一般指主从复制的客户端)对于slave client和MONITER client,如果client-output-buffer一旦超过256mb,又或者超过64mb持续60秒,那么服务器就会立即断开客户端连接。
client-output-buffer-limit pubsub 32mb 8mb 60参数:
(订阅发布模式)对于pubsub client,如果client-output-buffer一旦超过32mb,又或者超过8mb持续60秒,那么服务器就会立即断开客户端连接。
hz参数:
redis执行任务的频率为1s除以hz。aof-rewrite-incremental-fsync参数:
在aof重写的时候,如果打开了aof-rewrite-incremental-fsync开关,系统会每32MB执行一次fsync。这对于把文件写入磁盘是有帮助的,可以避免过大的延迟峰值
参考链接:https://www.cnblogs.com/pqchao/p/6558688.html。
四.Redis持久化
我们之前说过,Redis不仅可以当缓存(Cache)使用,还可以当数据库(Database)使用,而任何数据库系统就必须能持久存储数据的,这样就意味着数据库崩溃了,在重启起来,数据依然是有效的(除非硬盘坏了,否则我们要确保数据盘是依然可用的)。Redis是支持两种持久化的,两种持久化机制各有优点,一般而言,我们只需要启用一种即可,不建议同时使用!(如果你非要启用两种方式的话,建议存储在不同的文件系统中,恢复数据时首推AOF)
RDB:(延迟较大,且存在丢失数据的风险)
snapshotting,二进制格式;按事先定制的策略,周期性地将数据从内存同步至磁盘;数据文件默认为dump.rdb;客户端显示使用SAVE或BGSAVE命令来手动启动快照保护机制。 SAVE:同步,即正在主线程中保护快照,此时会阻塞所有客户端请求(这种方式不推荐使用,因为会影响到客户端写入操作); BGSAVE:异步,background(这种方式相对来时比较推荐使用)。AOF:(IO量较大,启动时较慢,数据完整性更强!) Append Only File,fsync,记录每次写操作至指定的文件尾部实现的持久化;当Redis重启时,可通过重新执行文件中的命令在内存中重建出数据库; BGREWRITEAOF,AOF文件重写:不会读取正在使用的AOF文件,而是通过将内存中的数据以命令的方式保存至临时文件中,完成之后替换原来的AOF文件。
save 900 1
save 300 10
save 60 10000
存 DB 到磁盘:
格式:save <间隔时间(秒)> <写入次数>
根据给定的时间间隔和写入次数将数据保存到磁盘
下面的例子的意思是:
900 秒内如果至少有 1 个 key 的值变化,则保存
300 秒内如果至少有 10 个 key 的值变化,则保存
60 秒内如果至少有 10000 个 key 的值变化,则保存
注意:你可以注释掉所有的 save 行来停用保存功能。
也可以直接一个空字符串来实现停用:
save ""
stop-writes-on-bgsave-error yes
如果用户开启了RDB快照功能,那么在redis持久化数据到磁盘时如果出现失败,默认情况下,redis会停止接受所有的写请求。
这样做的好处在于可以让用户很明确的知道内存中的数据和磁盘上的数据已经存在不一致了。
如果redis不顾这种不一致,一意孤行的继续接收写请求,就可能会引起一些灾难性的后果。
如果下一次RDB持久化成功,redis会自动恢复接受写请求。
如果不在乎这种数据不一致或者有其他的手段发现和控制这种不一致的话,可以关闭这个功能,
以便在快照写入失败时,也能确保redis继续接受新的写请求。
rdbcompression yes
对于存储到磁盘中的快照,可以设置是否进行压缩存储。
如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,
可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbchecksum yes
在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,
如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename dump.rdb
设置快照的文件名
dir /home/yinzhengjie/softwares/redis/data
设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。建议生成环境系统盘和数据盘要分开,当操作系统出现故障时,不会影响到数据的存储!
appendonly no
默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,
会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,
可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件,
每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。
appendfilename "appendonly.aof"
aof文件名
appendfsync always
appendfsync everysec
appendfsync no
aof持久化策略的配置
no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
always表示每次写入都执行fsync,以保证数据同步到磁盘。
everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
no-appendfsync-on-rewrite no
在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,
执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。
如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。
设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。
Linux的默认fsync策略是30秒。可能丢失30秒数据。
auto-aof-rewrite-percentage 100
aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,
即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。
当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite-min-size 64mb
设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写
aof-load-truncated yes
aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。
重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,出现这种现象
redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。
如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。
如果是no,用户必须手动redis-check-aof修复AOF文件才可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号