Python实训day06pm【网络爬虫(爬取接口)-爬取图片、音频、数据;查找视频下载地址_1/3】
下午的任务:爬取各种各样的接口数据(2-3个课堂练习)
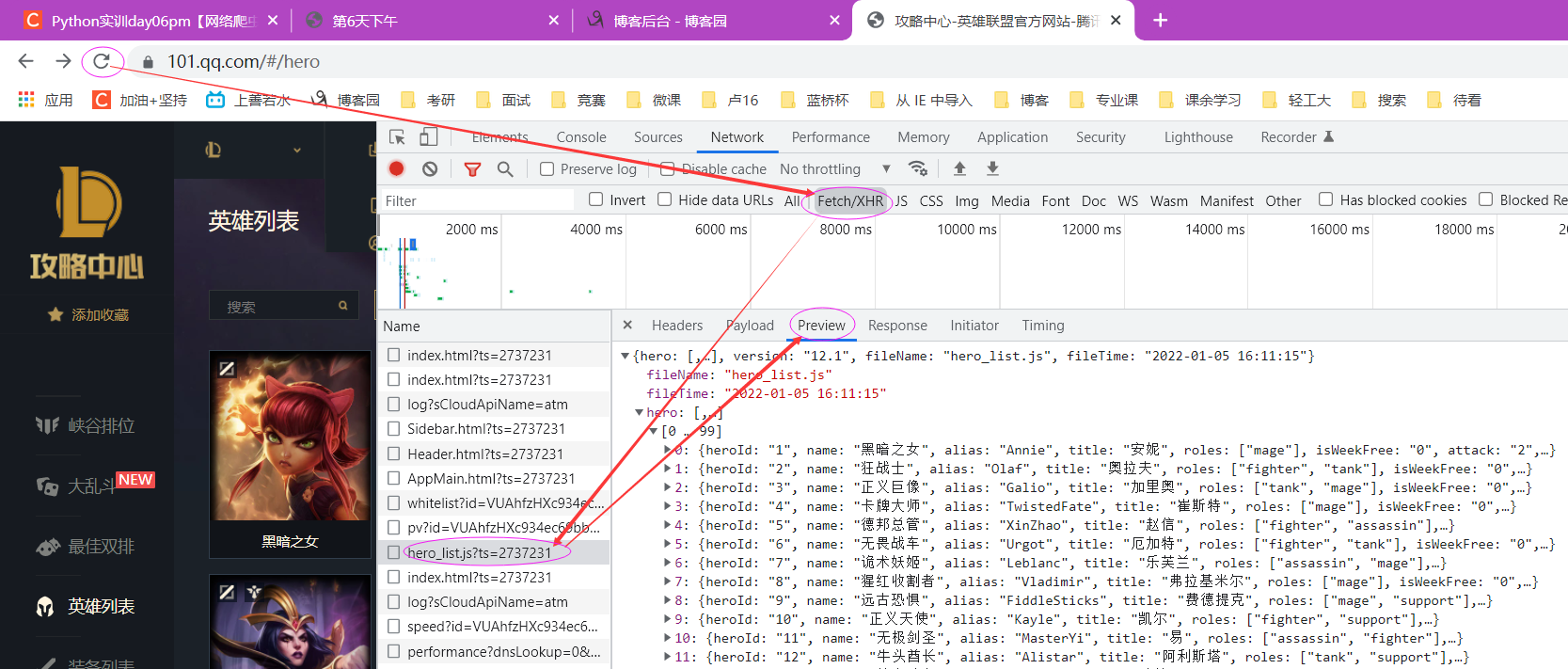
1、练习——LOL英雄头像与英雄语音

'''
下午的任务:爬取各种各样的接口数据(2-3个课堂练习)
课堂练习:#爬取LOL的内容-爬取lol英雄的头像、BP的音乐。
需要找数据接口:https://101.qq.com/#/hero
'''
import requests
# from bs4 import BeautifulSoup as BS
import json
hds = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
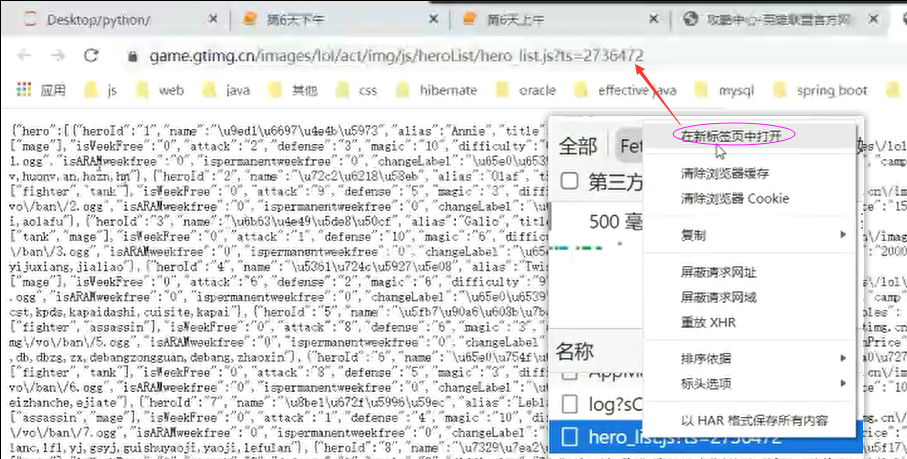
resp = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2736472', headers=hds)
ct = resp.content.decode('utf-8') # 文本需要解码
# print(ct)
info = json.loads(ct); # 对爬取到的内容进行解析
hs = info['hero'];
print(hs)
# 下载二进制(非文本)文件信息
def binary_down(url, path):
resp = requests.get(url, headers=hds)
ct = resp.content;
f = open(path, 'wb');
f.write(ct);
f.close();
dr = r'C:\Users\lwx\Desktop\LOL\{}.{}'; # 本地目录
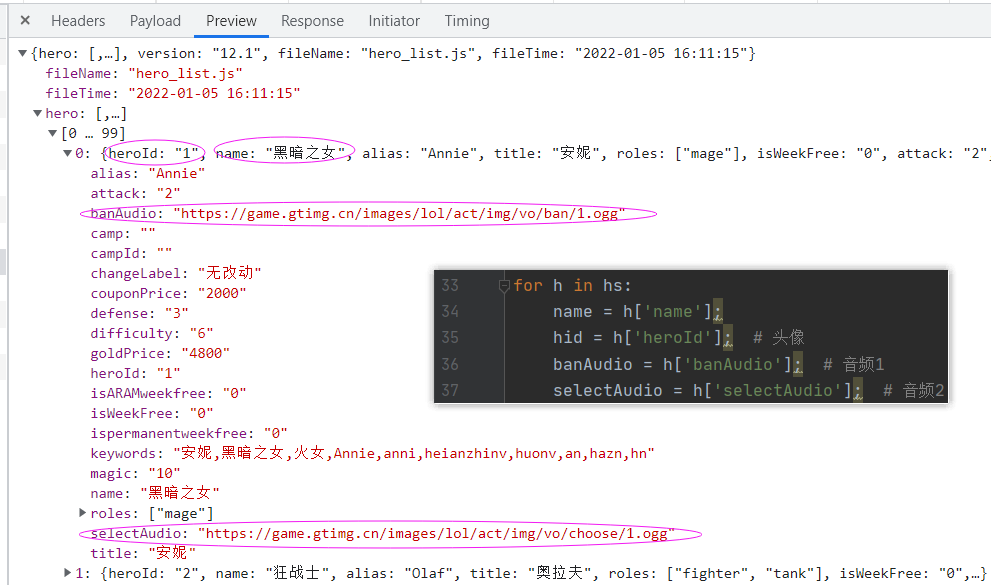
for h in hs:
name = h['name'];
hid = h['heroId']; # 头像
banAudio = h['banAudio']; # 音频1
selectAudio = h['selectAudio']; # 音频2
# 调用binary_down(url, path)函数下载文件
binary_down('https://game.gtimg.cn/images/lol/act/img/skinloading/{}000.jpg'.format(hid), dr.format(name, 'jpg'));
binary_down(banAudio, dr.format(name + "_ban", 'ogg'));
binary_down(selectAudio, dr.format(name + "_select", 'ogg'));
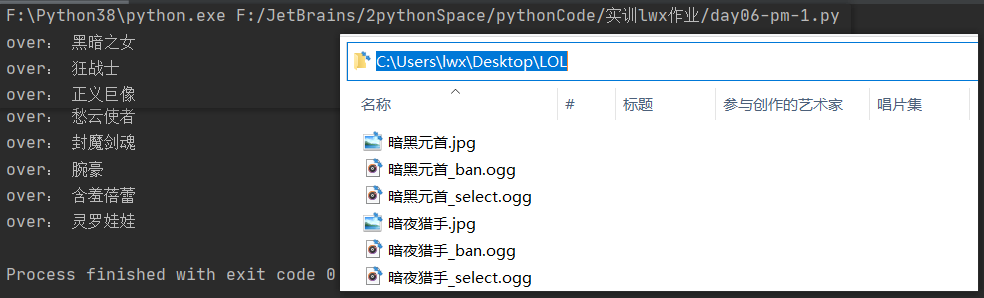
print("over:", name)
print("下载完毕!")
 浙公网安备 33010602011771号
浙公网安备 33010602011771号