Python实训day08am【网络爬虫selenium、图像处理入门】
网络爬虫-selenium
练习1-下载歌曲
课后作业:根据今日所学,在网易云上,找到一名自己喜欢的歌手,将该歌手的歌曲或歌词下载到本地。
例如,毛不易:https://music.163.com/#/artist?id=12138269

'''
课后作业:根据今日所学,在网易云上,找到一名自己喜欢的歌手,将该歌手的歌曲或歌词下载到本地。
例如,毛不易:https://music.163.com/#/artist?id=12138269
'''
import requests as req
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
def wydown(songname, songid):
common_url = 'http://music.163.com/song/media/outer/url?id={}';
resp = req.get(common_url.format(songid), headers=hds);
ct = resp.content;
print(len(ct))
print(resp.status_code); # 200正常;302重定向,需要继续获取重定向后的路径
if resp.status_code == 200:
f = open(r'C:\Users\lwx\Desktop\网易云\毛不易\{}.mp3'.format(songname), 'wb')
f.write(ct);
f.close();
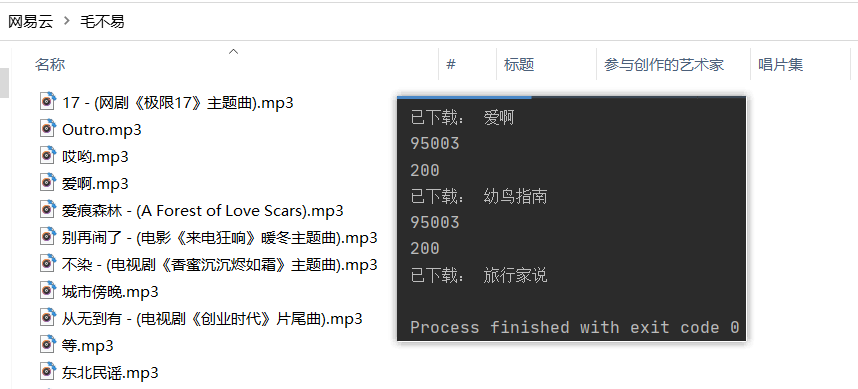
print('已下载:', songname);
# 无头模式:隐身的启动浏览器,但是并没有窗口展现。
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
url = 'https://music.163.com/#/artist?id=12138269'
bw.get(url);
bw.switch_to.frame('g_iframe');
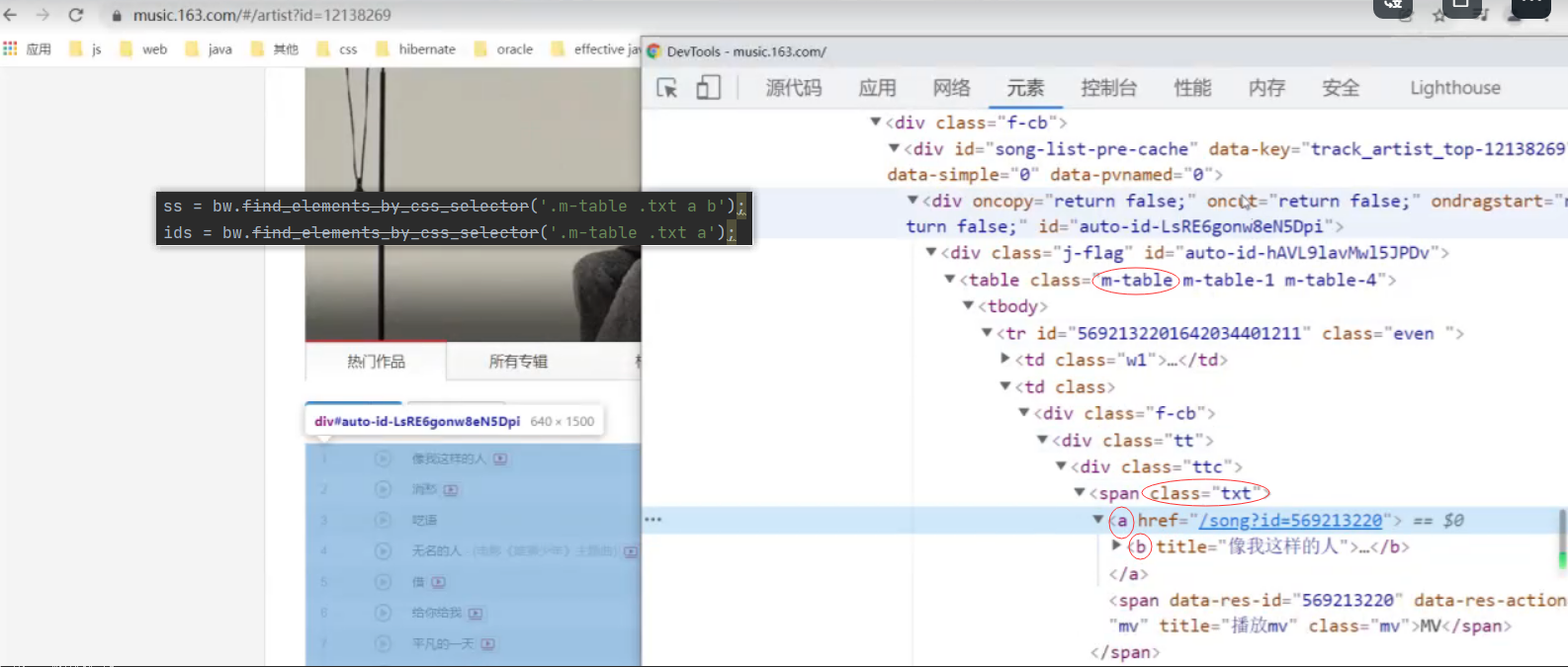
ss = bw.find_elements_by_css_selector('.m-table .txt a b');
ids = bw.find_elements_by_css_selector('.m-table .txt a');
songinfo = {}; # 歌曲名:歌曲id
for i, s in enumerate(ss):
songinfo[s.get_attribute('title')] = ids[i].get_attribute('href').split("=")[1];
bw.close();
print(songinfo);
# 遍历字典,下载所有歌曲
for k, v in songinfo.items():
wydown(k, v);练习2-下载歌词
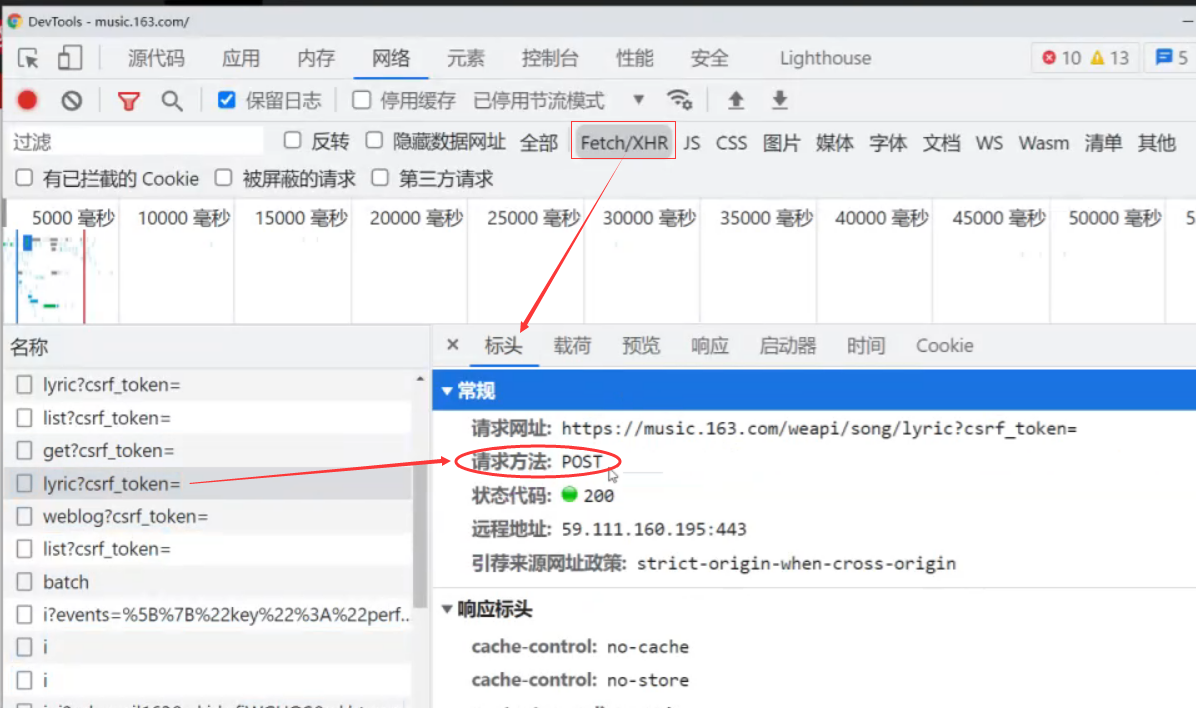
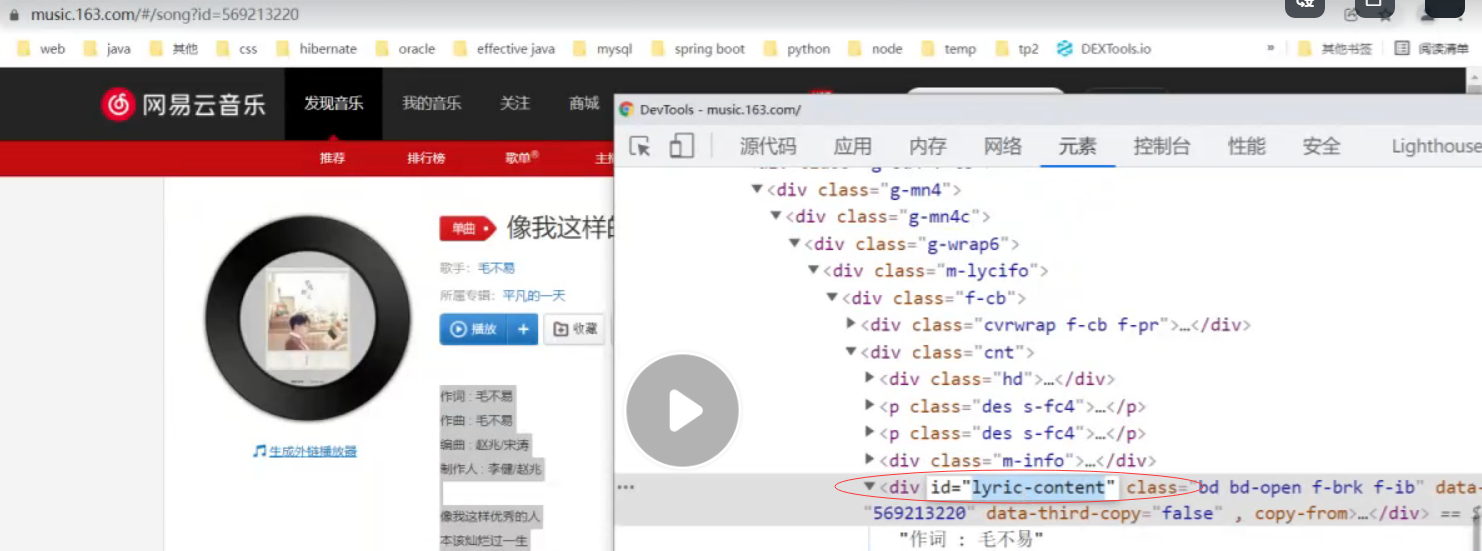
歌词路径:https://music.163.com/#/song?id=569213220
'''
下载歌词:https://music.163.com/#/song?id=569213220
毛不易《像我这样的人》
'''
import requests as req
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time;
hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
# 无头模式:隐身的启动浏览器,但是并没有窗口展现。
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
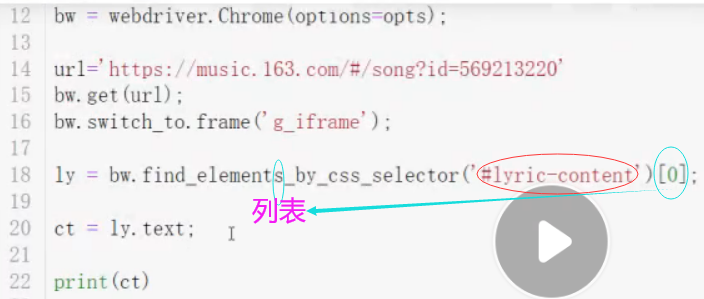
url = 'https://music.163.com/#/song?id=569213220' # 歌词路径
bw.get(url);
bw.switch_to.frame('g_iframe');
# bw.implicitly_wait(10) #设置等待,最多等10秒,如果有元素会立即返回
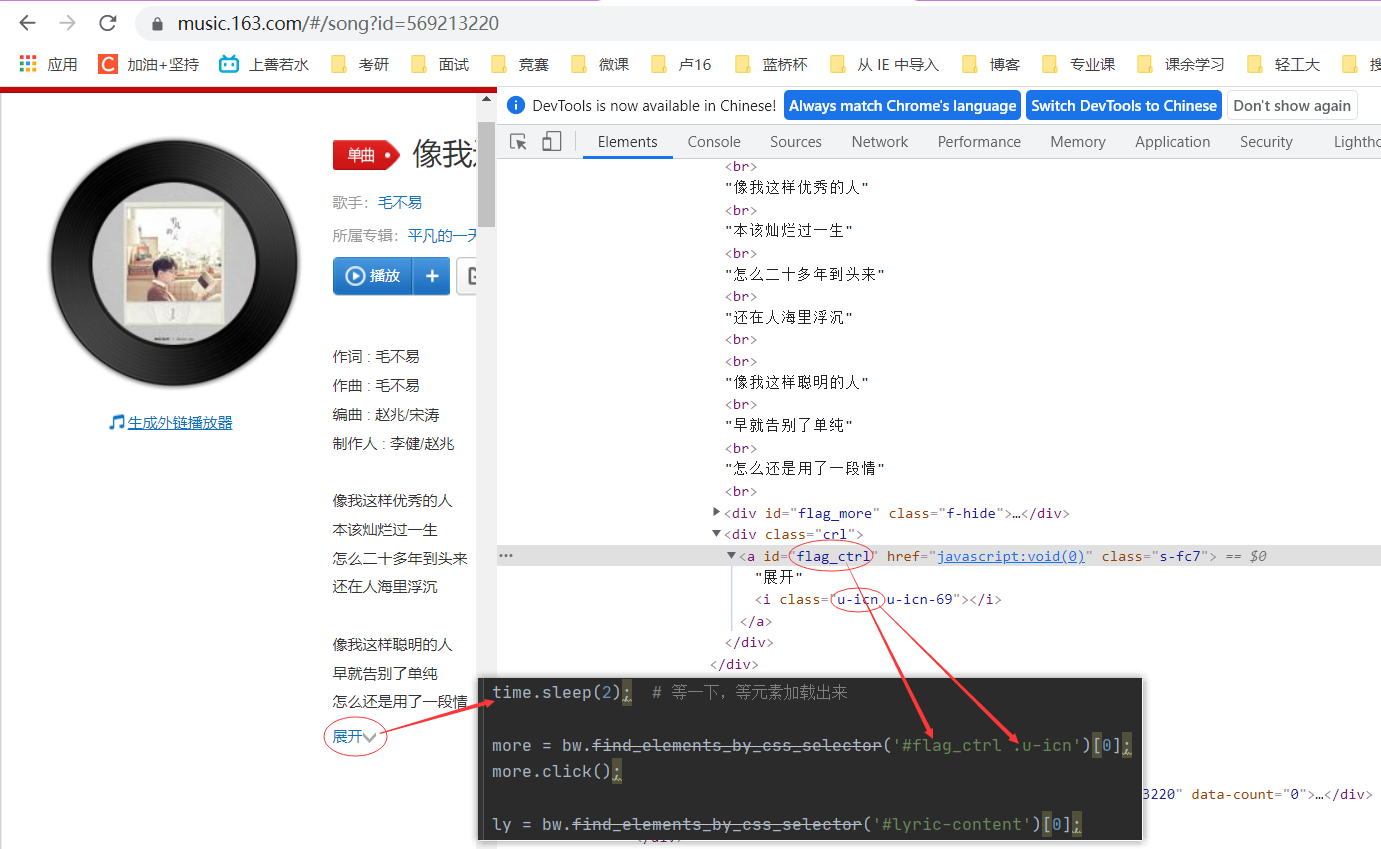
time.sleep(2); # 等一下,等元素加载出来
more = bw.find_elements_by_css_selector('#flag_ctrl .u-icn')[0];
more.click();
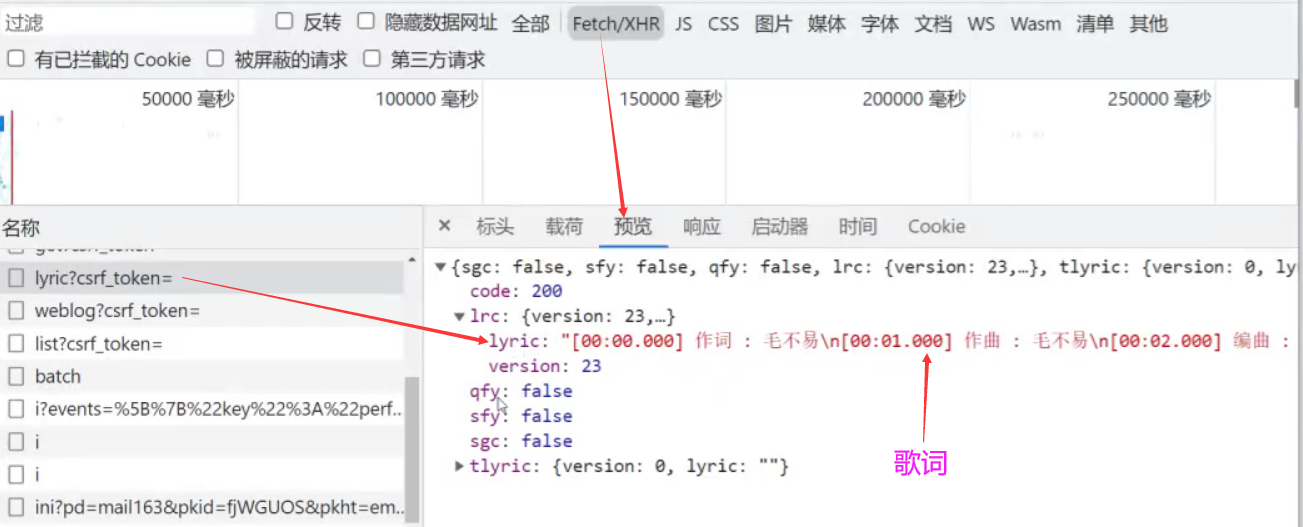
ly = bw.find_elements_by_css_selector('#lyric-content')[0];
ct = ly.text;
print(ct)
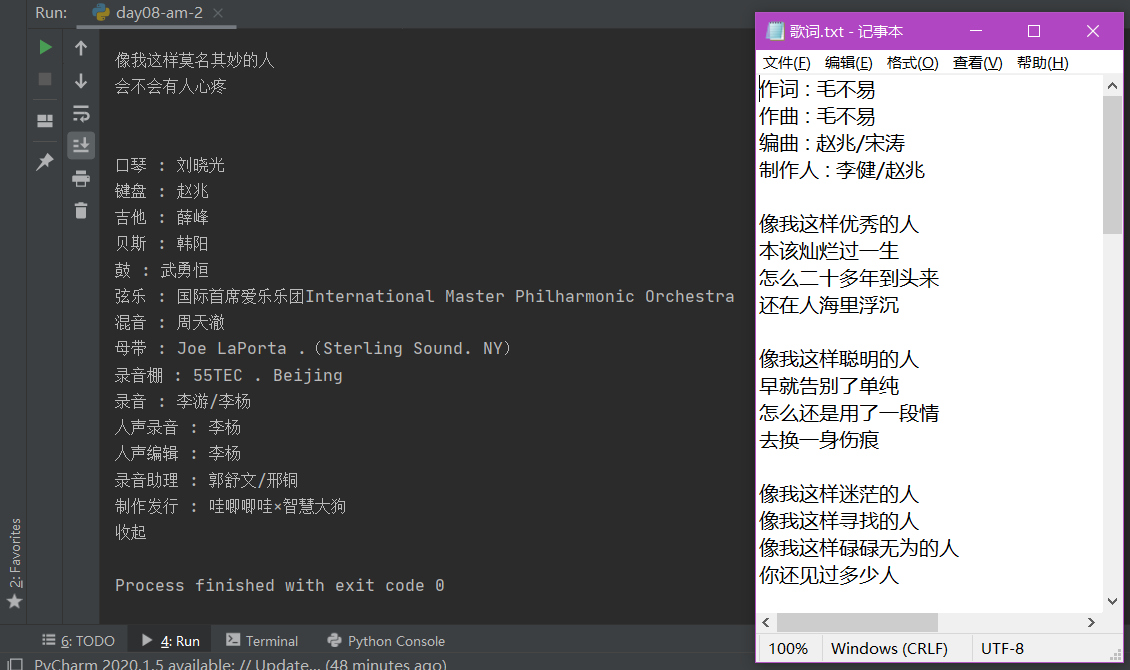
# 将ct的内容下载到.txt中
# 1.打开文件(默认是gbk编码)
f1 = open(r'C:\Users\lwx\Desktop\歌词.txt', 'a', encoding="utf-8"); # w就表示write
# 2.写文件
f1.write(ct)
# 3.关闭文件
f1.close();
 浙公网安备 33010602011771号
浙公网安备 33010602011771号