WordCount-拓展功能
申明
- 合作者:201631062407,201631062306
- 代码地址:https://gitee.com/hhhhhhh2/WordCount
- 本次作业的链接地址:https://edu.cnblogs.com/campus/xnsy/2018Systemanalysisanddesign/homework/2188
正文
1. PSP表格
| **PSP2.1 ** | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 1 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 1 |
| Development | 开发 | 152 | 243 |
| · Analysis | · 需求分析 (包括学习新技术) | 2 | 10 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding | · 代码规范 (为目前的开发制定合适的规范) | 10 | 3 |
| · Code Review | · 具体设计 | 20 | 20 |
| · Test | · 具体编码 | 120 | 210 |
| Reporting | · 代码复审 | 65 | 30 |
| · Test Report | 报告 | 30 | 40 |
| · Size Measurement | · 测试报告 | 30 | 10 |
| · Postmortem & Process | · 计算工作量 | 5 | 10 |
| Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 120 |
| 合计 | 232 | 394 |
-
小总结:
这次由于已经做过PSP评估,有了一定经验,估计值相较于上一次有了进步。这次的主要时间出入任然是具体编码时间上的估计错误。当我一开始看题目要求的时候,认为实现扩展功能并不复杂,能够很快实现。但是当我真正敲代码的时候,我发现我在实现迭代文件夹目录、用正则表达式来实现具体功能存在问题,所以查找资料花了较长的时间。
2. 互审代码情况
我审查的模块分别有:图形化界面展示、停用词表、通配符的实现。
以下是审查这些方法的测试结果:
2.1 图形化界面
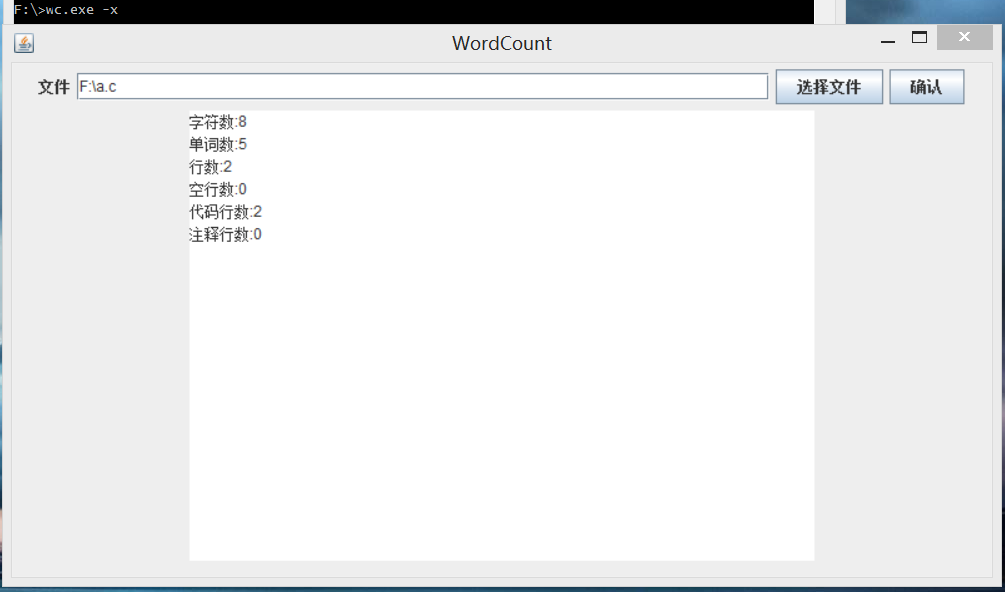
2.2 停用词表
@Test
public void testInStop() throws Exception{
WordCount wordCount = new WordCount();
String[] bufferL = null;
File dirr = new File("f:/stopList.txt");
String[] bufferS = null;
String Sline = null;
BufferedReader bff = new BufferedReader(new FileReader(dirr));
while((Sline = bff.readLine()) != null){
//System.out.println("停用词表中的单词:" + Sline);
bufferS = Sline.split(",| ");
}//of while
File dir = new File("f:/a.c");
BufferedReader br = new BufferedReader(new FileReader(dir));
while((Sline = br.readLine()) != null)
{
//System.out.println("目标文件中读取每一行内容:" + Sline);
bufferL = Sline.split(",| ");
for(int i = 0; i < bufferL.length; i++){
boolean s = wordCount.inStop(bufferL[i], bufferS);
System.out.println(s);
}
}
}
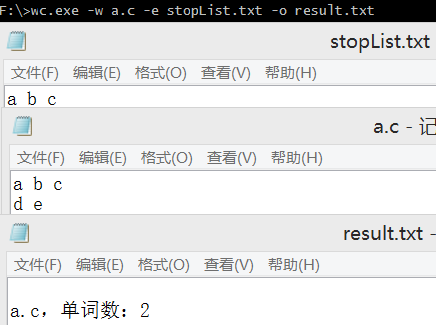
2.3 通配符
@Test
public void testGetFiles() {
ArrayList<String> filenames = ExtendFunc.getFiles("F:/simulate");
System.out.println(filenames);
String[] test = "F:\\simulate\\*.c".split(", ");
assertEquals(test, filenames.toArray());
}
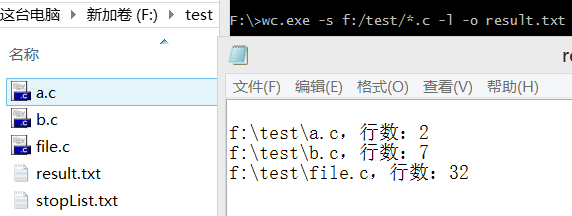
发现的问题:合作伙伴的代码写得很好,条理清晰,需求所要求的功能基本能够实现。只是,
- 在写入文件时,是在文件的尾部添加内容,不能够在每次执行程序后,将文件原有的内容覆盖。经过修改,每次执行后先将文件原有的内容清空,再添加程序执行后需要的内容。
- 通配符实现部分,当能够实现通配符时,输入的路径为文件时报错。
- 在程序运行时,把输出的文件也当做读取文件计算。
3. 设计过程
我们设计了一共有5个类,22个方法。他们的关系如图所示:
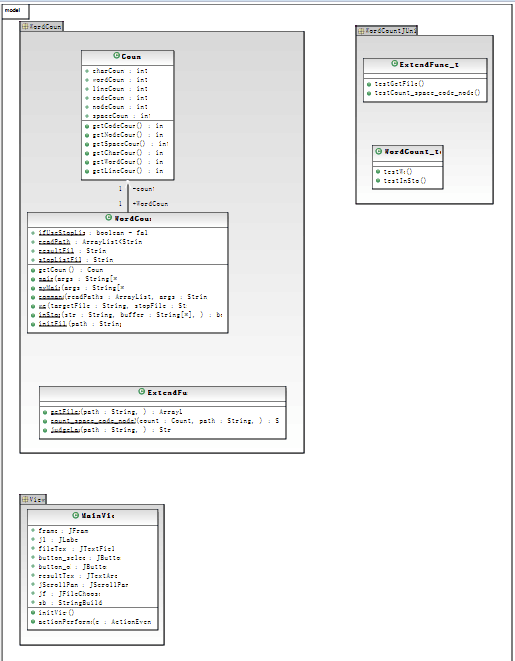
关键函数的算法设计(流程图),如图所示:
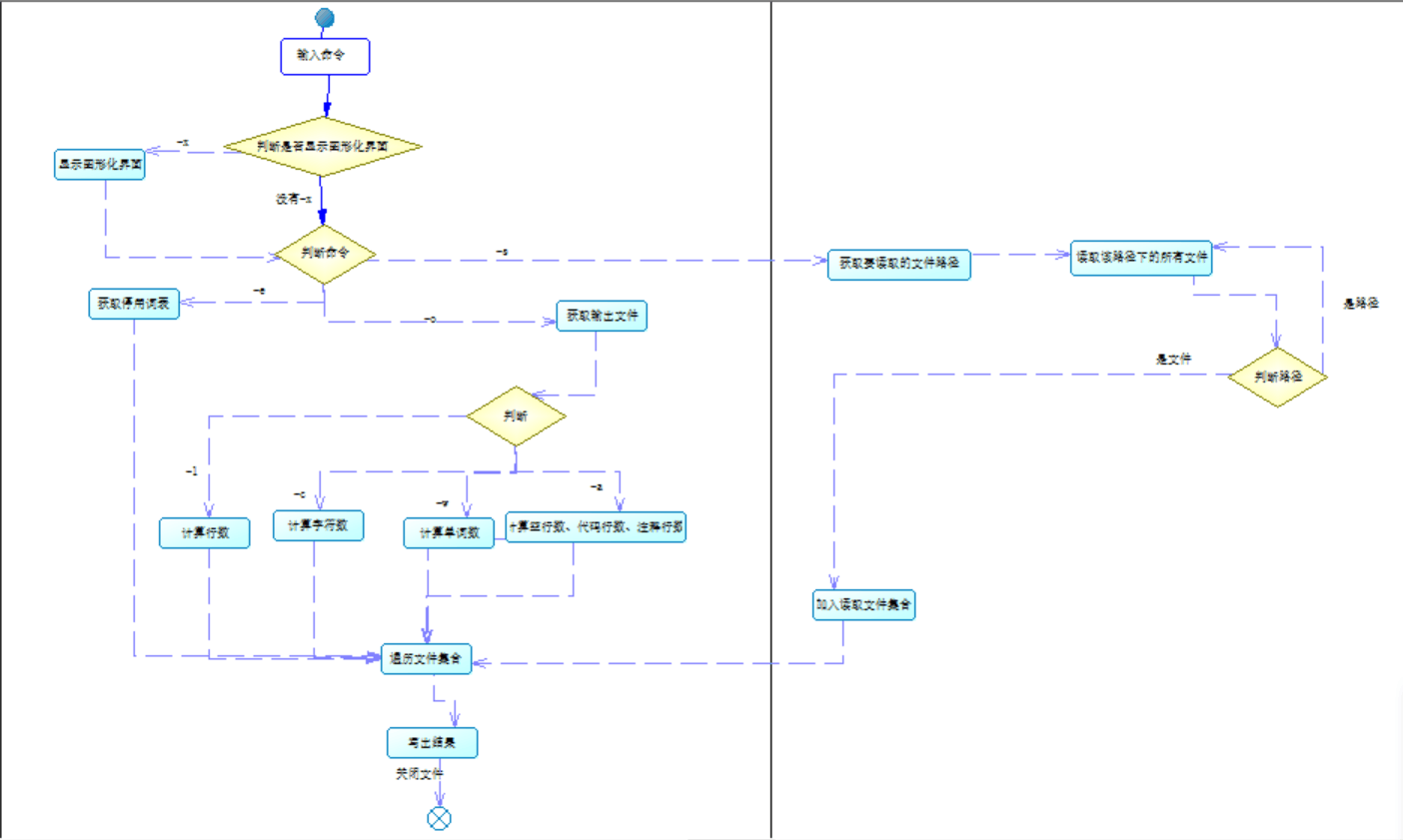
4. 代码说明
在结对项目中,我主要负责递归处理目录下符合条件的文件、返回更复杂的数据(代码行 / 空行 / 注释行)和处理一般通配符的效果。代码如下:
4.1 递归处理目录下符合条件的文件、处理一般通配符
/**
* 递归获取某路径下的所有文件、文件夹,并返回包含该路径下所有文件的数组
*/
public static ArrayList<String> getFiles(String path) {
ArrayList<String> fileNames = new ArrayList<String>();
String[] paths = path.split("/");
String filePath = ""; //该路径下文件夹名
for(int i=0; i<paths.length-1; i++){
filePath += paths[i];
filePath += "/";
}
File file = null;
System.out.println(paths[paths.length-1].split("\\.").length);
System.out.println(paths[paths.length-1]);
//含通配符时
if(paths[paths.length-1].contains("+") || paths[paths.length-1].contains("?")){
file = new File(filePath);
System.out.println("filePath:" + filePath);
if(paths[paths.length-1].split("\\.").length<1){
// 如果这个路径是文件夹
if (file.isDirectory())
{
// 获取路径下的所有文件
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++)
{
// 如果还是文件夹 递归获取里面的文件 文件夹
if (files[i].isDirectory())
{
getFiles(files[i].getPath());
}
else
{
fileNames.add(files[i].getPath());
}
}
}
else
{
fileNames.add(file.getPath());
}
}else{
String match_fileName = paths[paths.length-1];
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++)
{
//判断是否符合含通配符的文件
if(files[i].getPath().matches(match_fileName)){
fileNames.add(files[i].getPath());
}
}
}
}else{ //不含通配符时
file = new File(path);
// 如果这个路径是文件夹
if (file.isDirectory())
{
// 获取路径下的所有文件
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++)
{
// 如果还是文件夹 递归获取里面的文件 文件夹
if (files[i].isDirectory())
{
getFiles(files[i].getPath());
}
else
{
fileNames.add(files[i].getPath());
}
}
}
else
{
fileNames.add(file.getPath());
}
}
return fileNames;
}
4.2 返回更复杂的数据(代码行 / 空行 / 注释行)
public static String count_space_code_nodeNum(Count count, String path){
BufferedReader fileReader = null;
String str = "";
int codeCount = 0;
int spaceCount = 0;
int nodeCount = 0;
count.spaceCount = 0;
count.nodeCount = 0;
count.codeCount = 0;
try {
fileReader = new BufferedReader(new FileReader(path));
String line = null;
boolean flagNode = false;
while( (line = fileReader.readLine()) != null)
{
String regxNodeBegin = "\\s*/\\*.*";//空白字符任意多个、字符“/*”、任意字符、多个
String regxNodeEnd = ".*\\*/\\s*";//任意字符、 零次或者多次、 出现字符“*/”、空白任意多个
String regx = ".*//.*";//单行注释
String regxSpace = "\\s*";//空行
//多行的单行注释
if( line.matches(regxNodeBegin) && line.matches(regxNodeEnd))
{
nodeCount++;
}
else
{
if(line.matches(regxNodeBegin))
{
nodeCount++;
flagNode = true;
}
else if(line.matches(regxNodeEnd))
{
nodeCount++;
flagNode = false;
}
else if(line.matches(regxSpace))
{
spaceCount++;
}
else if(line.matches(regx)){
nodeCount++;//单行注释
}
else if(!flagNode)
{
codeCount++;
}else{
nodeCount++;
}
}
}
count.spaceCount = spaceCount;
count.codeCount = codeCount;
count.nodeCount = nodeCount;
str += "空行:" + spaceCount + "\r\n";
str += "代码行:" + codeCount + "\r\n";
str += "注释行:" + nodeCount + "\r\n";
} catch (FileNotFoundException e) {
str = "文件读取有误!";
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return str;
}
5. 总结
在构建之法的结对项目的实践经历中,我感受颇多。通过结对编程我认识到了结对编程的好处:
-
促进参与项目的程序员自身的提高:一对程序员工作的时候,水平较低的一方会潜移默化地受水平略高的程序员影响,学到一些新的东西。而水平高的一方同样因为不断地把自己的想法说出来而整理了自己的思路。
-
促进大家对项目的热爱:我们在编程中各自都会遇到问题,并相互改正。两个人不断的互换角色,以至于最后谁也记不清哪行代码是谁敲的;整个项目的代码是团队共有,而不再是个人作品。
-
帮助加快项目的完成进度:一个人编程时,遇到问题可能想很久都不能够解决,而队友却能很快的找出我们代码中的错误并更正。
-
增加大家对编码的积极性:如果单独工作,在遇到困难的时候,并不是所有人都立刻积极地去解决问题,这时或许会上网和网友聊聊天,看看无关的网站等等,大半天的时间都浪费了。而结对编程有一种相互督促的作用,在一边工作疲惫状态不好使,另一边会起一个鼓励和激发斗志的作用。大家一起解决问题,完成工作,具有很高的效率和积极性。
在这次结对编程中,我要感谢我队友辛勤付出;我也通过这次的结对编程,感受到了1+1>2。

