数据采集 实验五
作业①
1.1作业内容
作业①: 要求: 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
关键词:学生自由选择
输出信息:MYSQL的输出信息如下

1.2解题过程
1.2.1网页的获取
先进入京东主页面,通过搜索框输入查找的关键词,然后店家查找:
搜索输入框的获取:
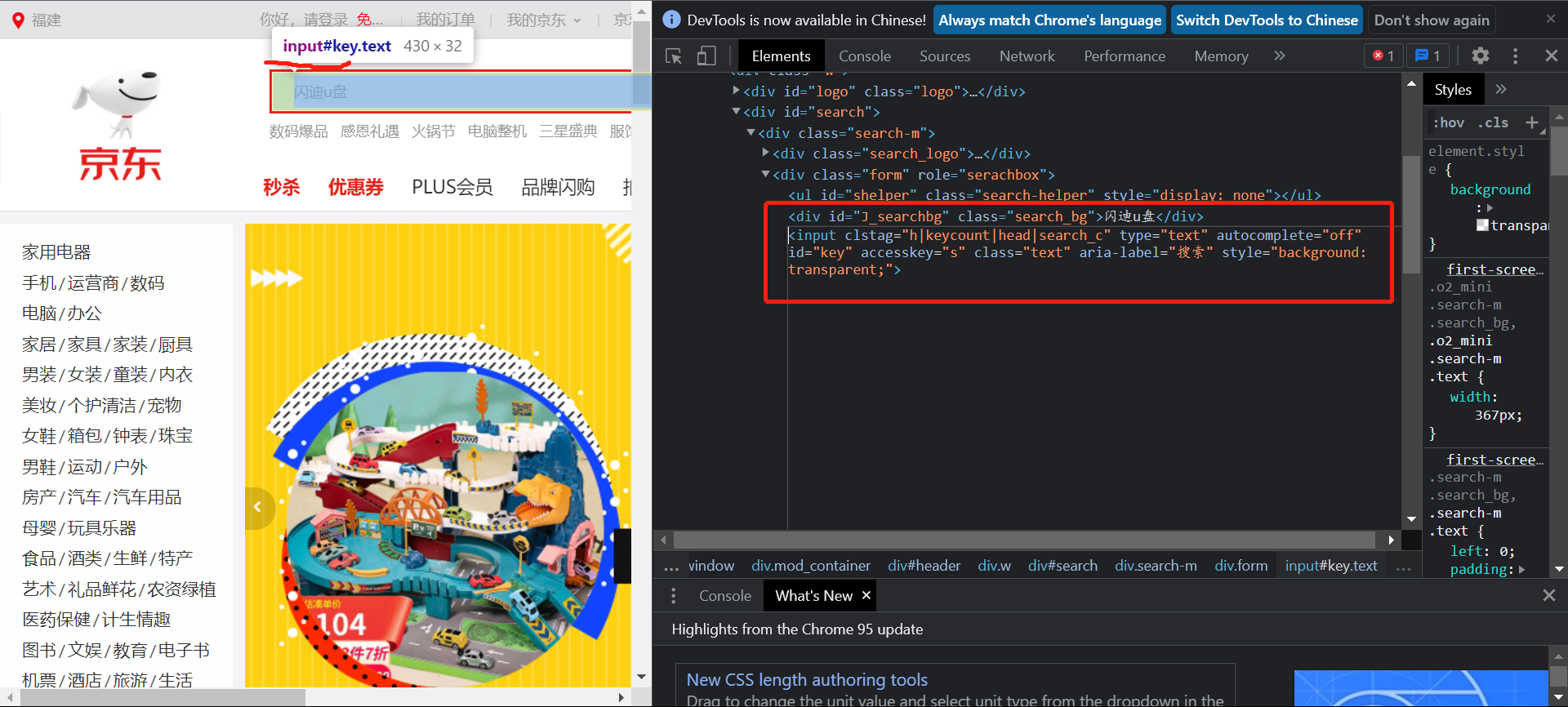
查找id="key"的input组件即可。
查找按钮:
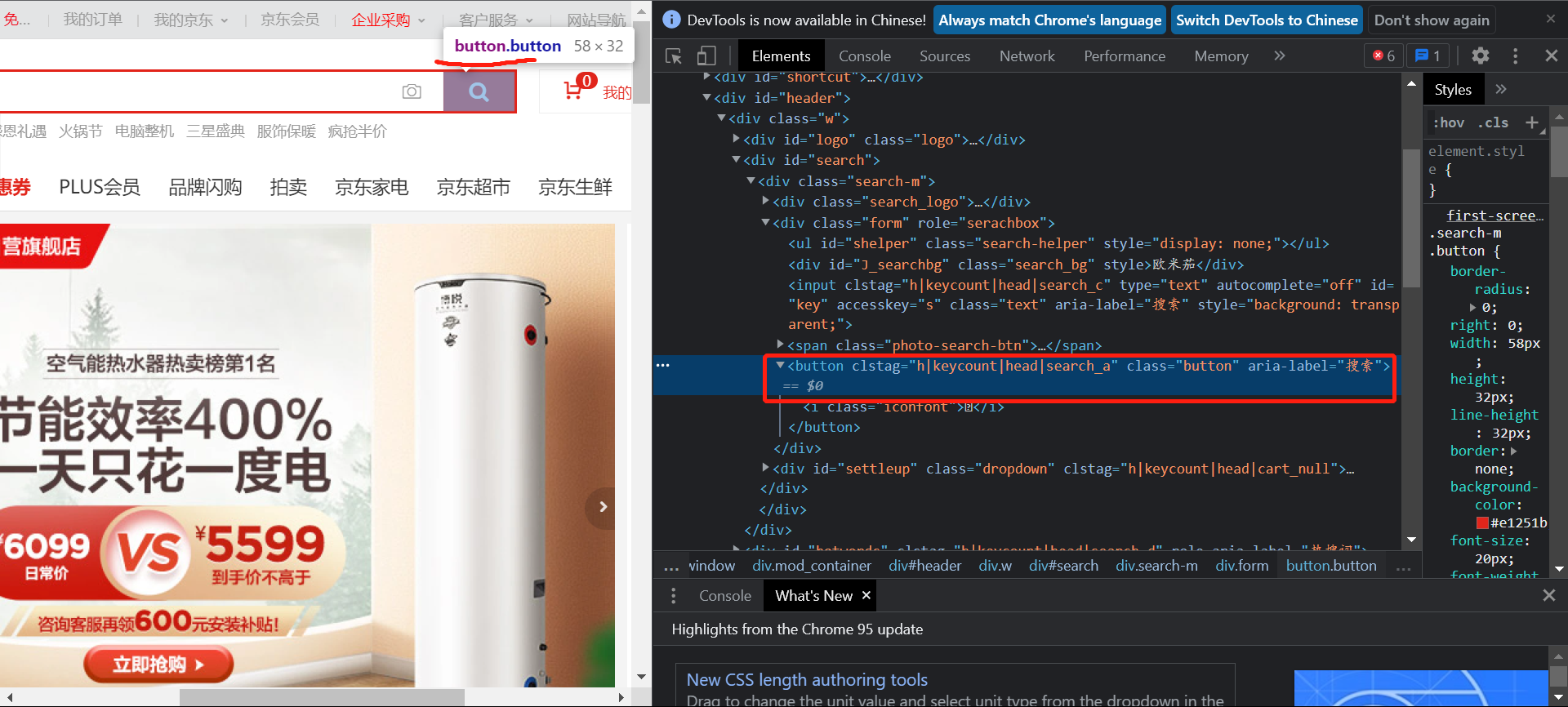
id=“search"的标签下的第一个div标签下的第二个div标签下的button。
代码部分:
driver.get(url) # 访问首页
inputit = driver.find_element_by_xpath('//*[@id="key"]')
inputit.send_keys(keyWord)
findbutton = driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button')
findbutton.click()
1.2.2目标数据的获取
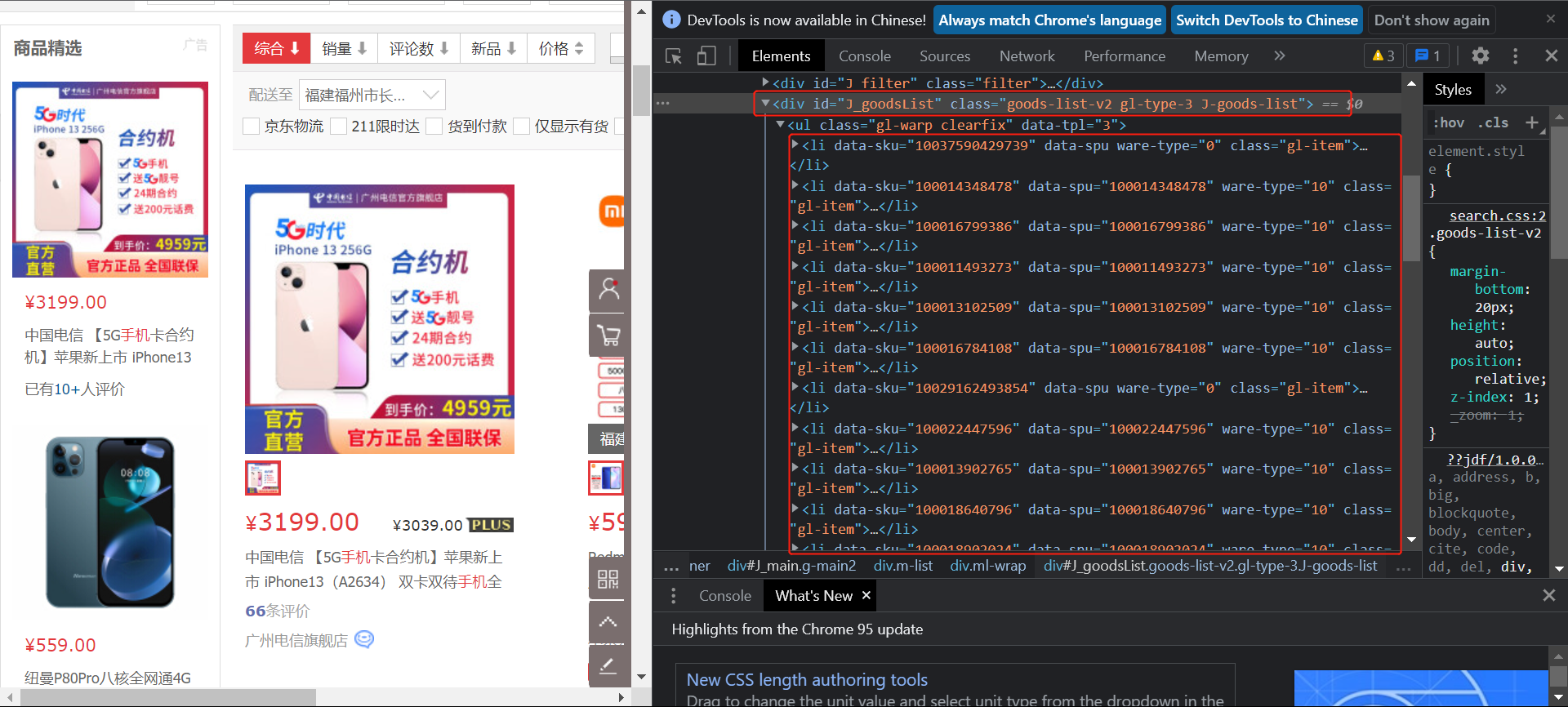
可以看到商品数据都 存在一个class="gl-warp clearfix"的div标签下的列表中。
所以先获取商品列表:
shoplist = driver.find_element_by_xpath('//*[@class="gl-warp clearfix"]')
然后是对应内容的查找,以价格为例:
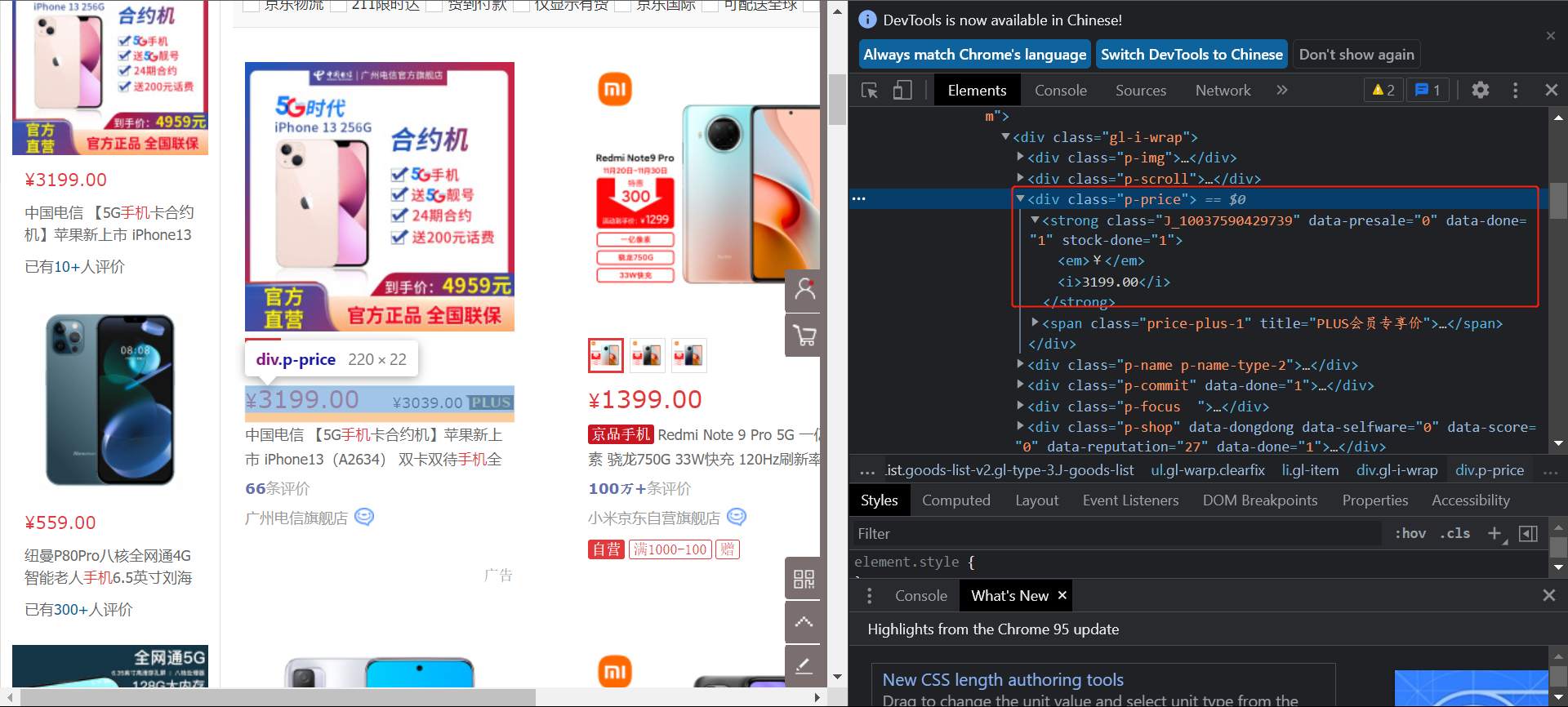
可以看到价格信息存在商品列表下的class=”p-price"的div标签下的/strong/i路径下的文本内,所以查找:
price = shoplist.find_elements_by_xpath('.//div[@class="p-price"]/strong/i')
1.2.3翻页和下拉
翻页处理就是找到下一页的按钮:

class=“pn-next”的a标签。点击即可。
def loadNext(): #用于转到下一页
time.sleep(1)
try:
NextPage = driver.find_element_by_xpath('//a[@class="pn-next"]')
NextPage.click()
except:
print("最后一页")
京东的网页下拉到底会加载出下一页的内容,一页的内容是30个商品,下拉到底加载出全部60个商品,如果不下拉可能会有数据(如图片)未加载出来,而出现null的情况。
def loadAll():
for i in range(100): #没有下拉到底,差不多全部加载完成就行
js = 'window.scrollTo(0,%s)' % (i * 100) #js脚本
driver.execute_script(js) #提交js脚本
time.sleep(0.07)
每拉一点停一下,以确保数据全部加载。
1.3输出
保存的图片:
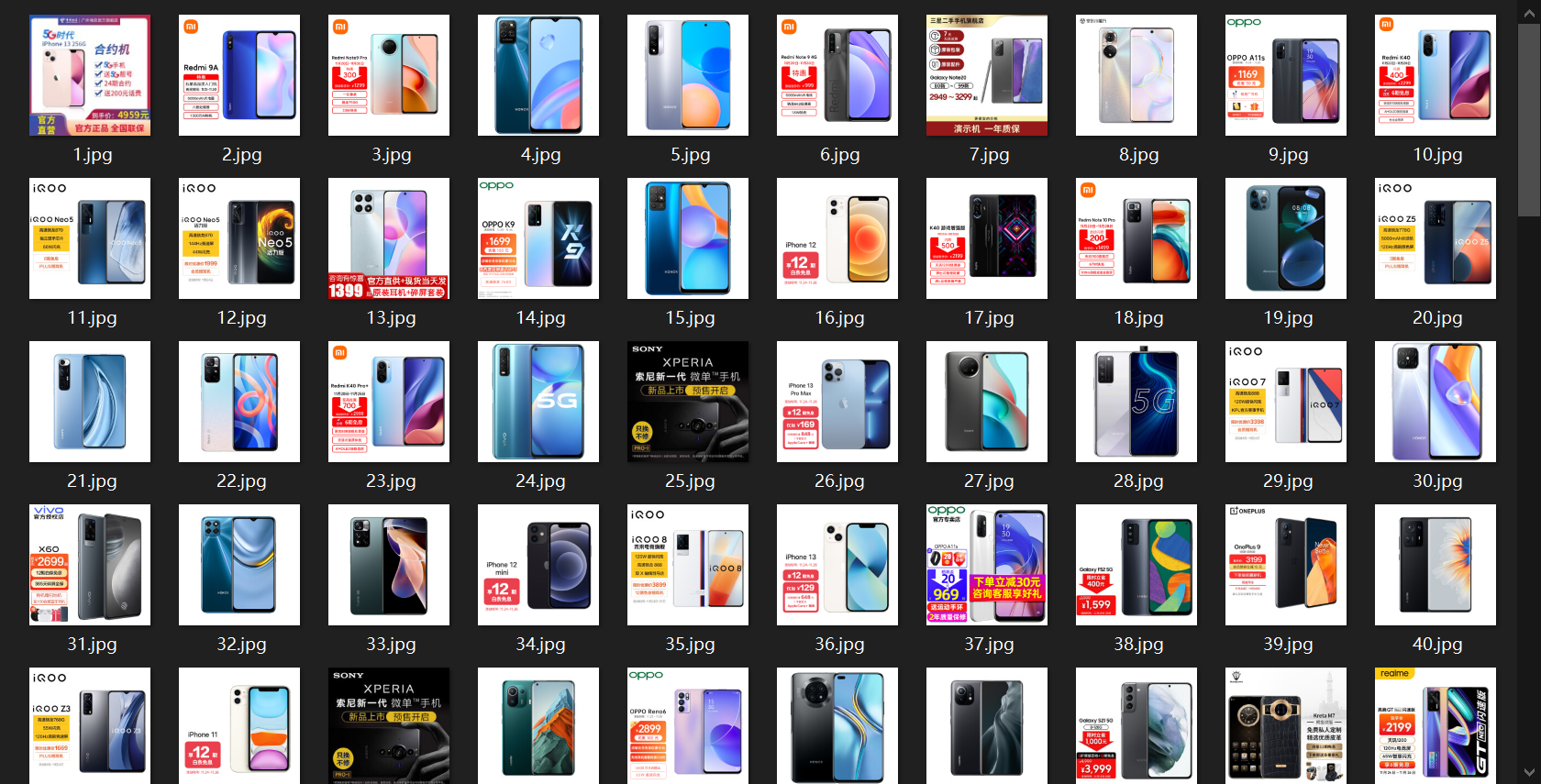
数据库:

1.4心得体会
selenium的基本使用,网页内容查找,输入,点击等事件。
selenium提交js脚本的使用
作业②
2.1作业内容
要求: 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待 HTML元素等内容。 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学 进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹 中,图片的名称用课程名来存储。
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
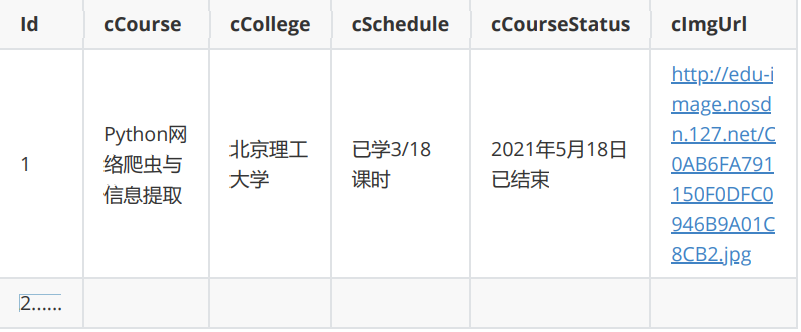
2.2解题过程
2.2.1模拟登录的实现
首先找到输入账号密码的窗口
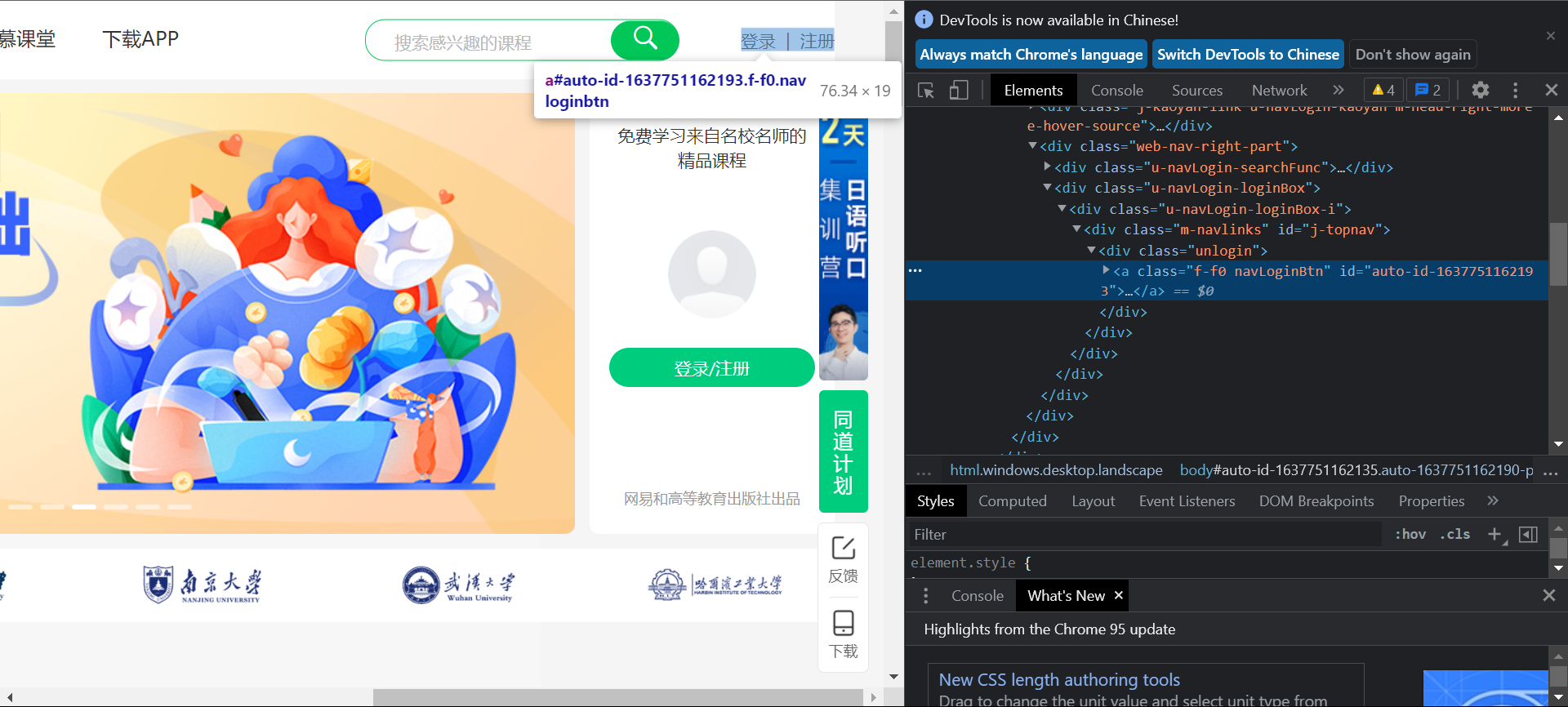
点击右上方的登录|注册可以弹出登录窗口,直接通过点击Copy Xpath获取的地址是
//*[@id="auto-id-1637751328911"]
通过的是id来查找,但是这里的id每次进入这个网页的时候都会发生变化,所以无法通过id来查找,
所以通过class-"unlogin"标签来查找。
同样问题也适用在这个网站的其他内容的查找中,
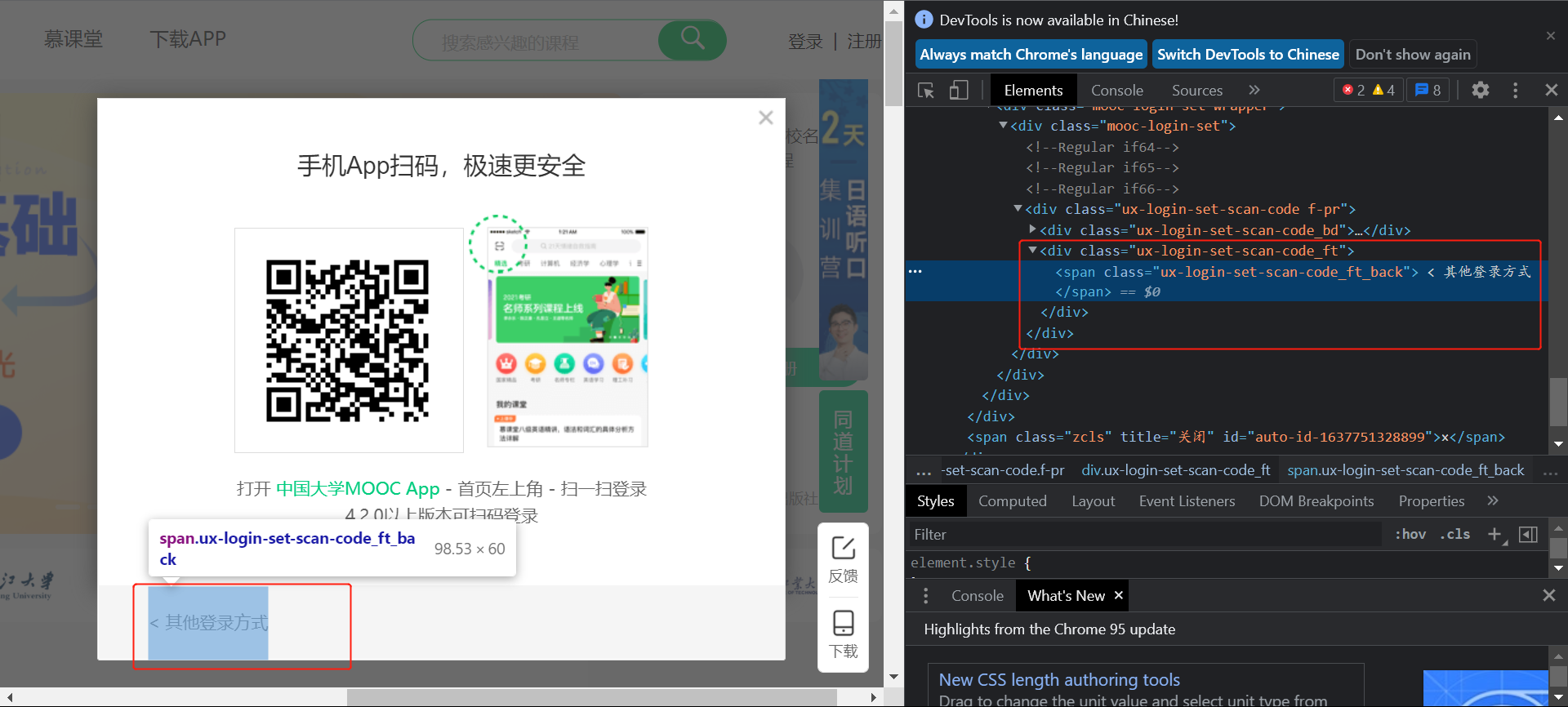
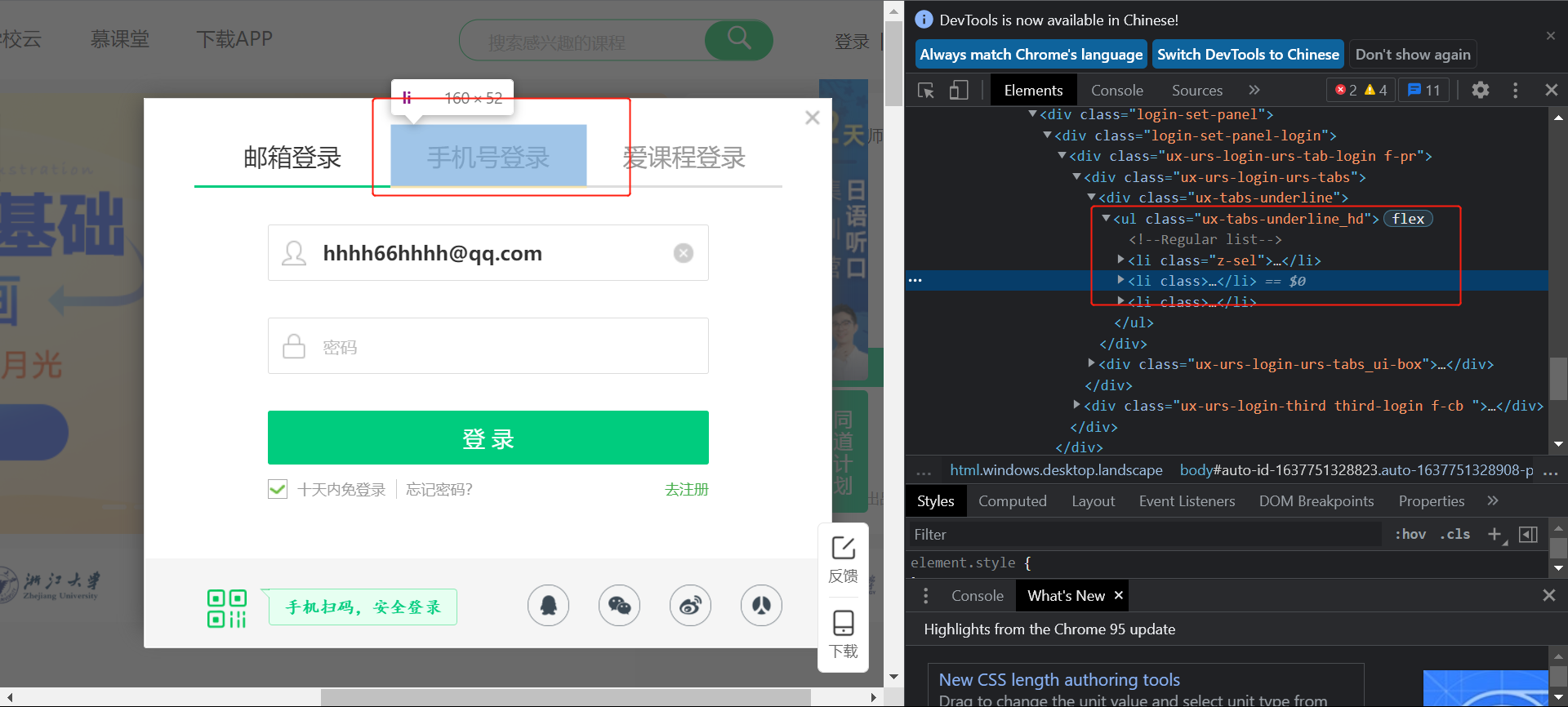
在显示了上面这个输入手机号和密码的输入框之后,无法找到输入的组件
这是因为网页加载了一个新的frame:
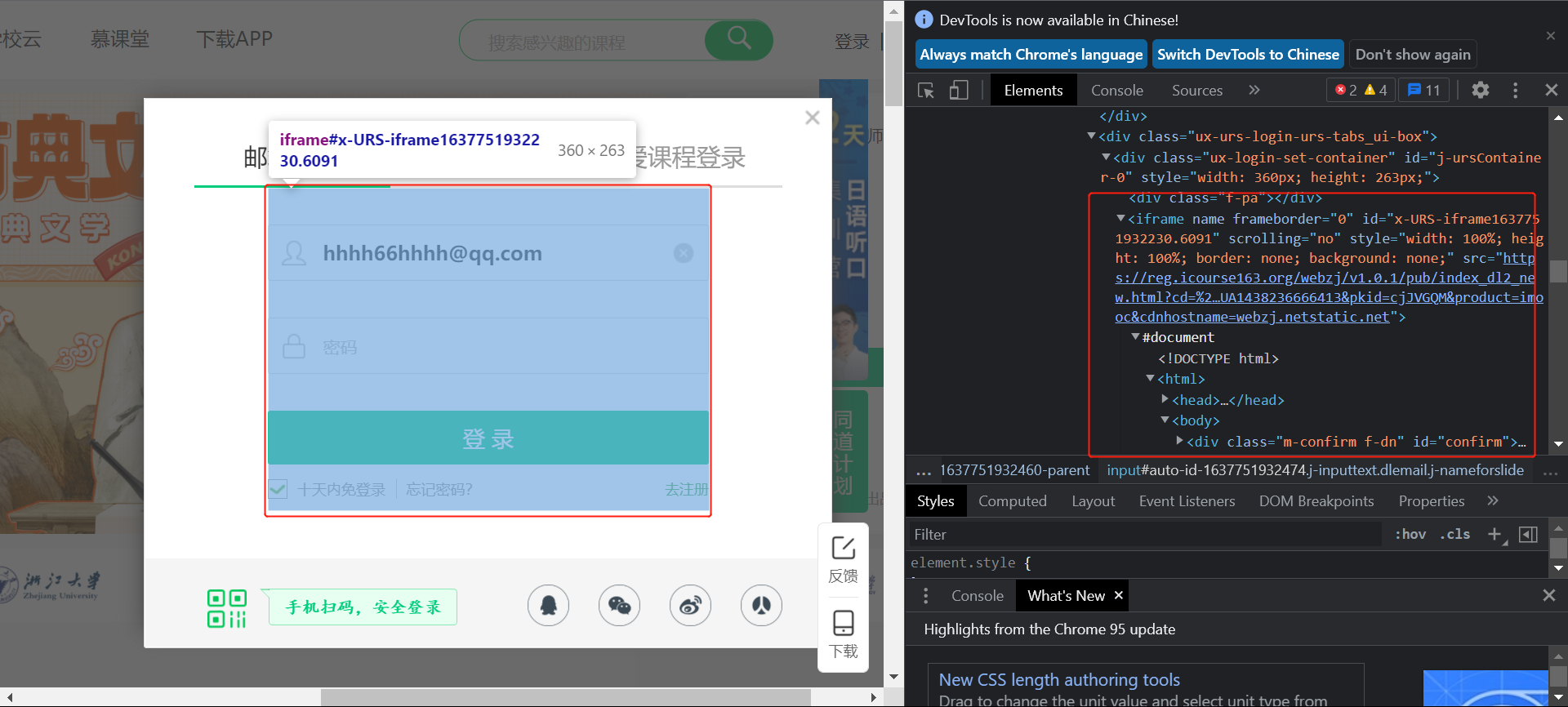
此时需要切换到这个新的:
frame = driver.find_element_by_xpath('//div[@class="ux-login-set-container"]/iframe')
driver.switch_to.frame(frame)
然后才能继续执行
然后查找输入账号密码点击登录:

账号密码的输入框都放在class="u-input box"的标签下,可以通过这个来查找:
登录按钮id="submitBtn"可以直接查找不会变化。
inputUserName =driver.find_element_by_xpath('//div[@class="u-input box"][1]/input')
inputUserName.send_keys("")
inputPasswd = driver.find_element_by_xpath('//div[@class="inputbox"]/div[2]/input[2]')
inputPasswd.send_keys("")
LoginButton = driver.find_element_by_xpath('//*[@id="submitBtn"]')
LoginButton.click()
2.2.2数据的获取
登录之后页面变为登录后的页面:
通过webdriver执行的会出现:
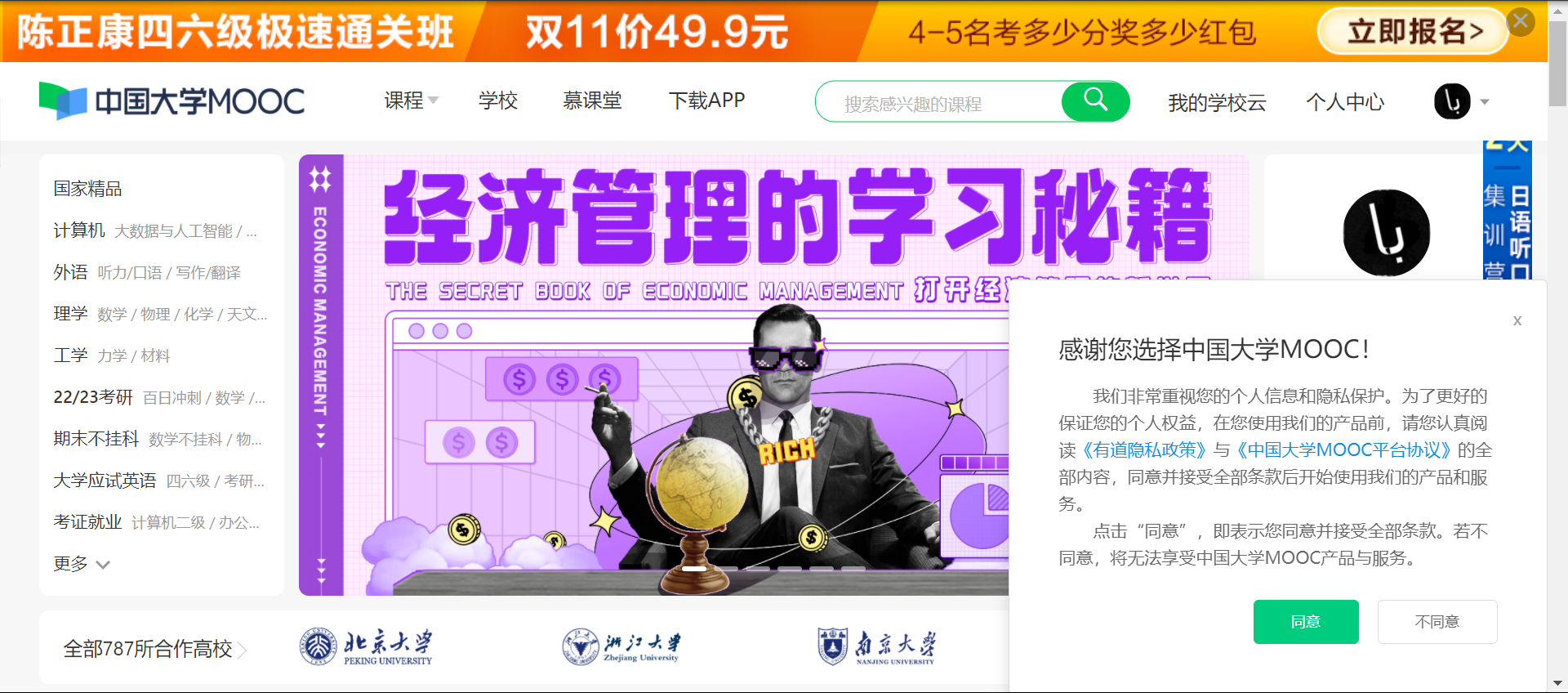
右下角的窗口会遮挡住我的课程按钮,使按钮无法点击:

此时需要关闭这个窗口:
agree=driver.find_element_by_xpath('//button[@class="btn ok"]')
agree.click()
然后才可以进入我的课程页面:
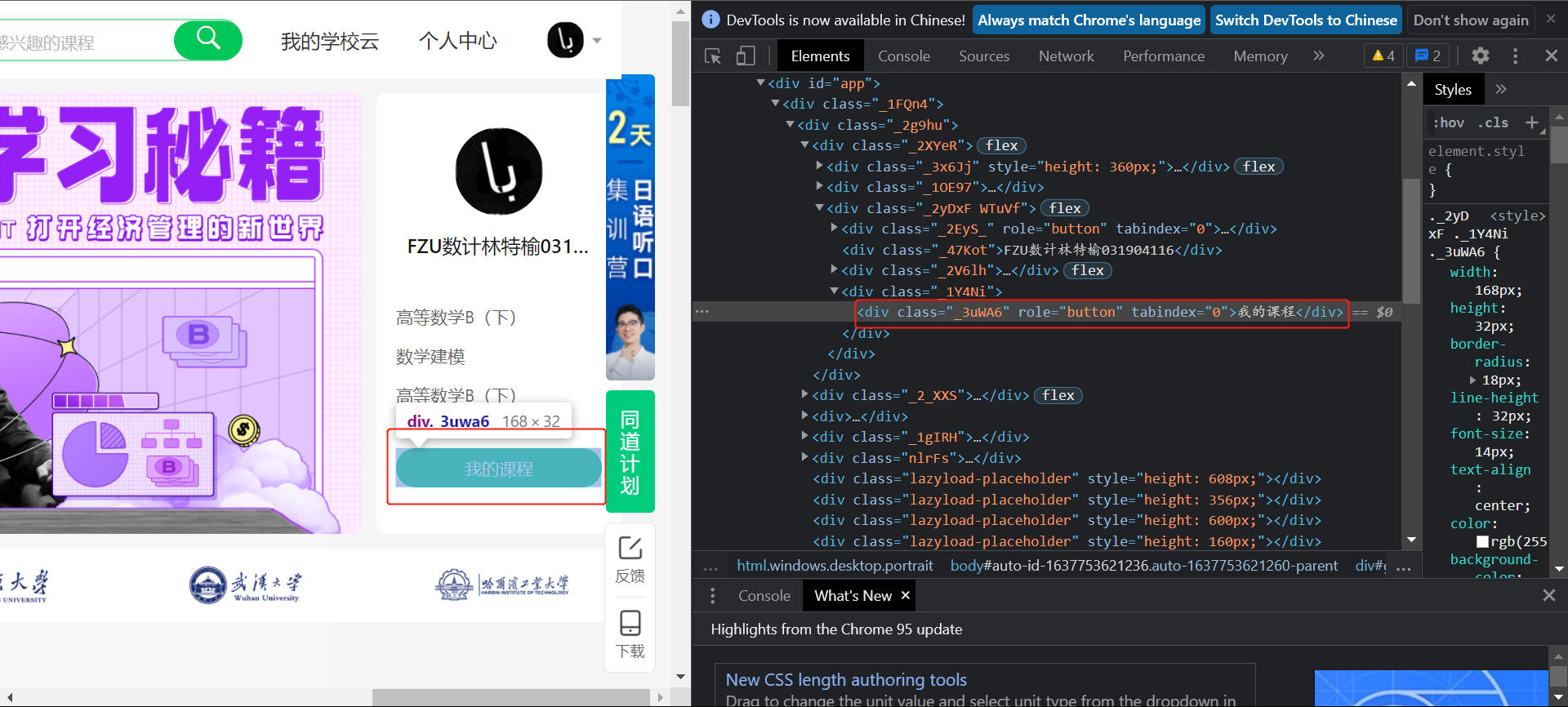
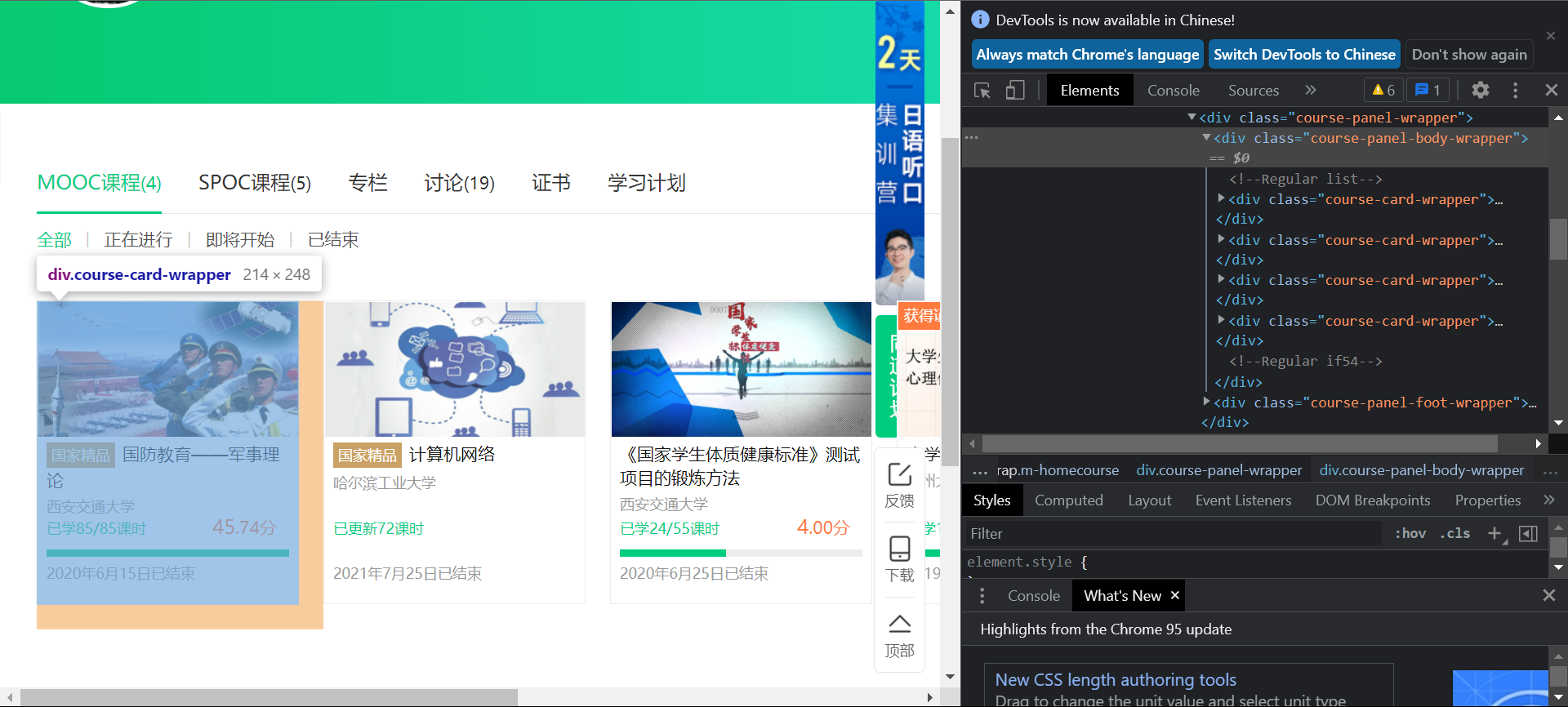
可以看到需要的信息都存在class="course-panel-body-wrapper"下的div标签中然后
course = driver.find_element_by_xpath('.//div[@class="course-panel-body-wrapper"]')
names = course.find_elements_by_xpath('.//span[@class="text"]')
schools= course.find_elements_by_xpath('.//div[@class="school"]')
courset = course.find_elements_by_xpath('.//span[@class="course-progress-text-span"]')
time = course.find_elements_by_xpath('.//div[@class="course-status"]')
hrefs = course.find_elements_by_xpath('.//div[@class="img"]/img')
2.3输出
mysql里数据
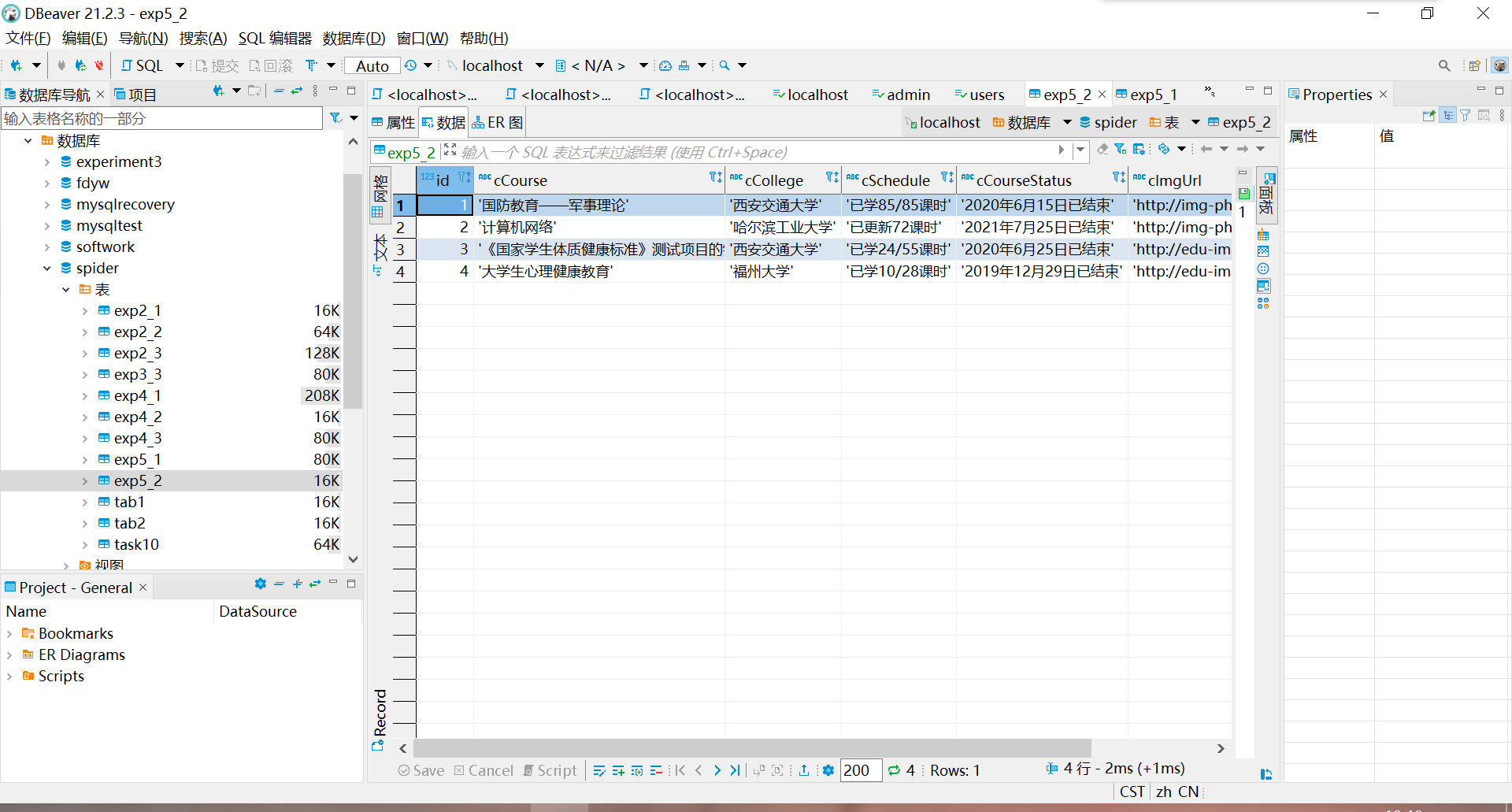
2.4心得体会
selenium实现模拟登录,窗口(frame)的转换。
selenium等待机制。
作业③:
要求:
理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。
完成Flume日志采集实验,包含以下步骤:
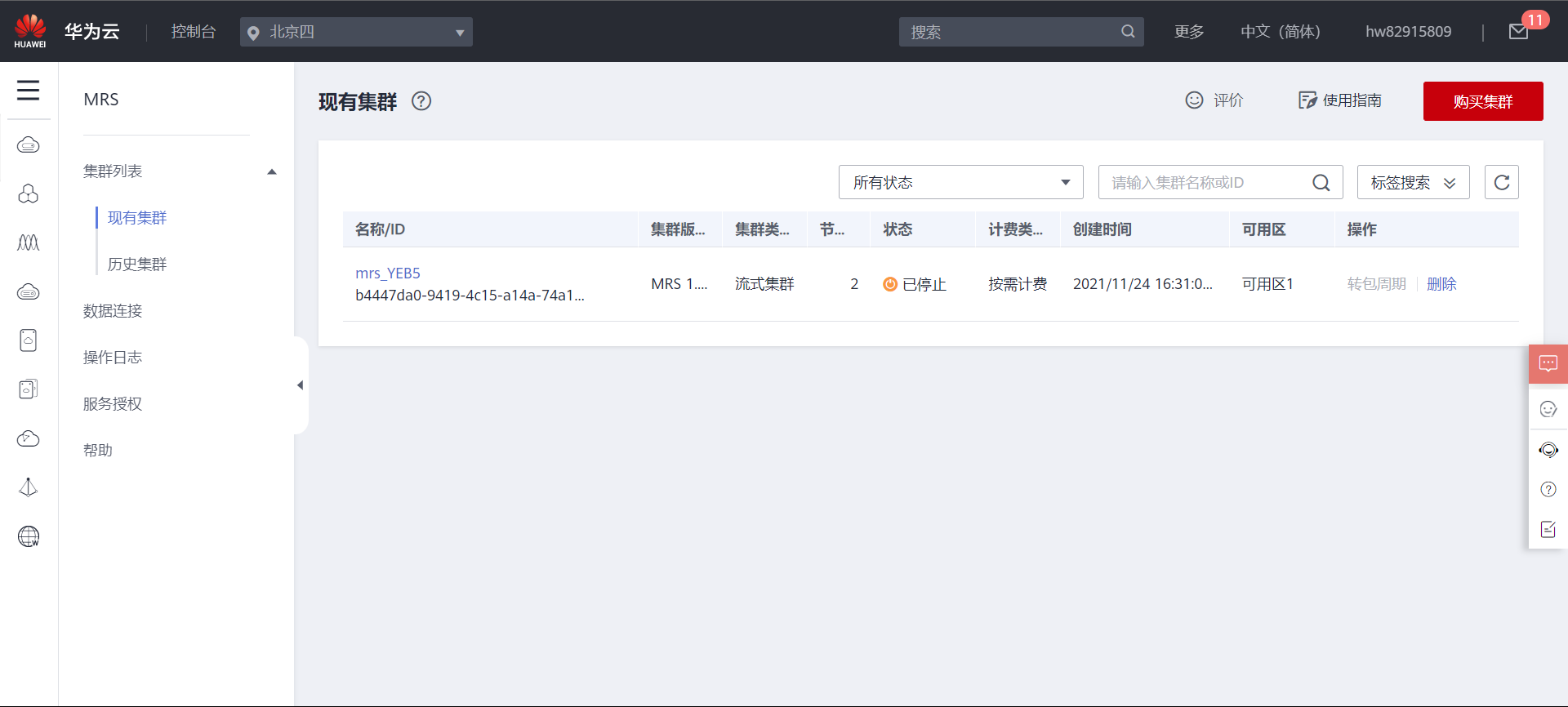
任务一:开通MapReduce服务
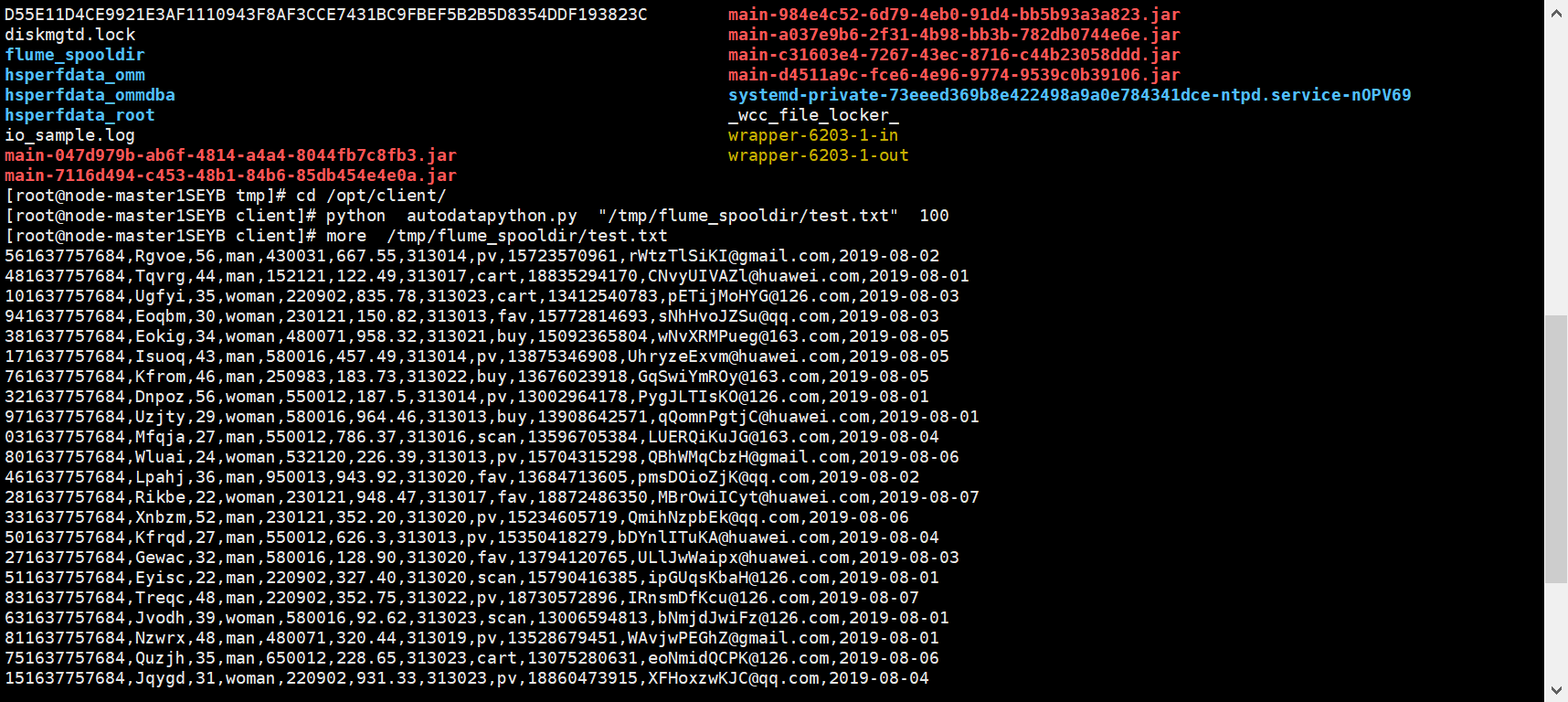
任务二:Python脚本生成测试数据
连接服务器
输出:
任务三:配置Kafka
查看zookeeper ip:
配置完成

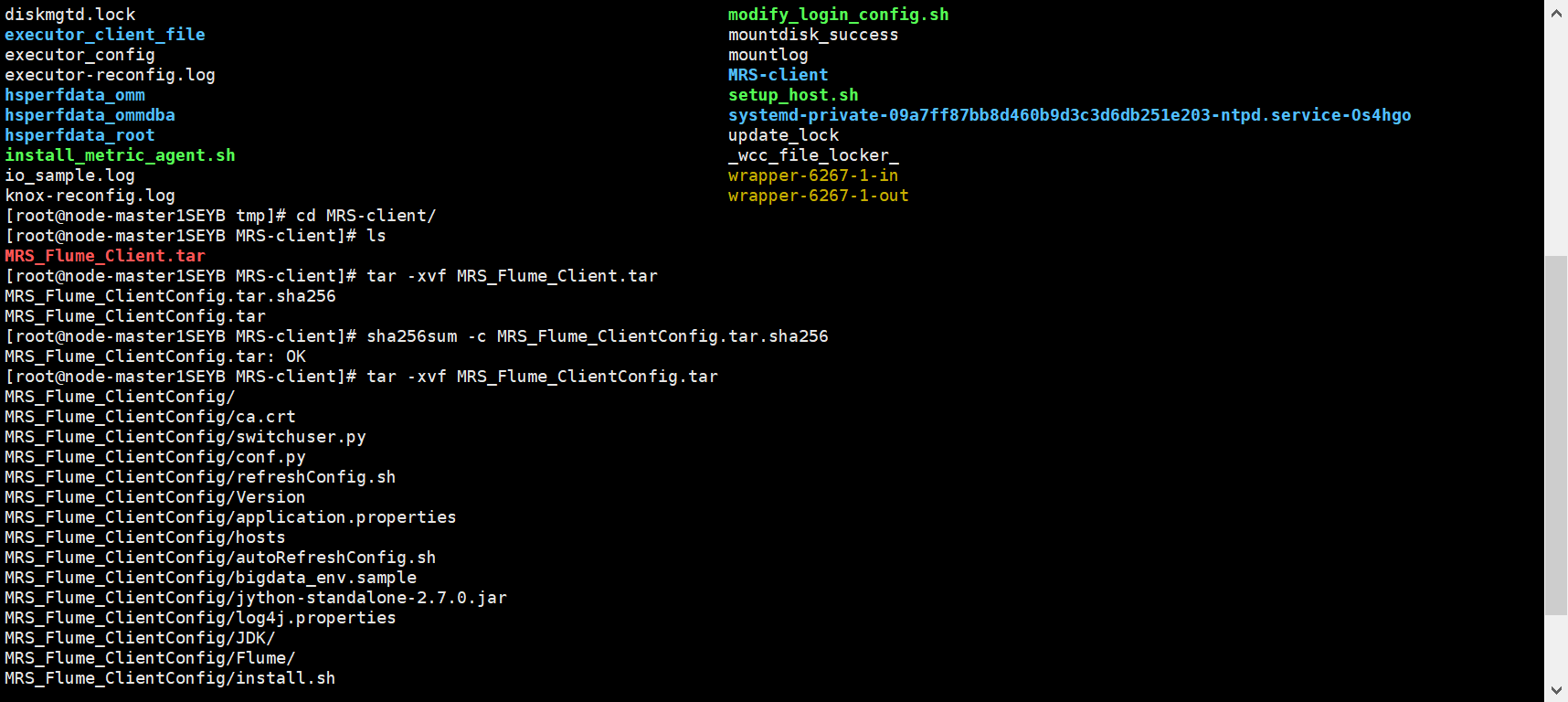
任务四:安装Flume客户端
解压:
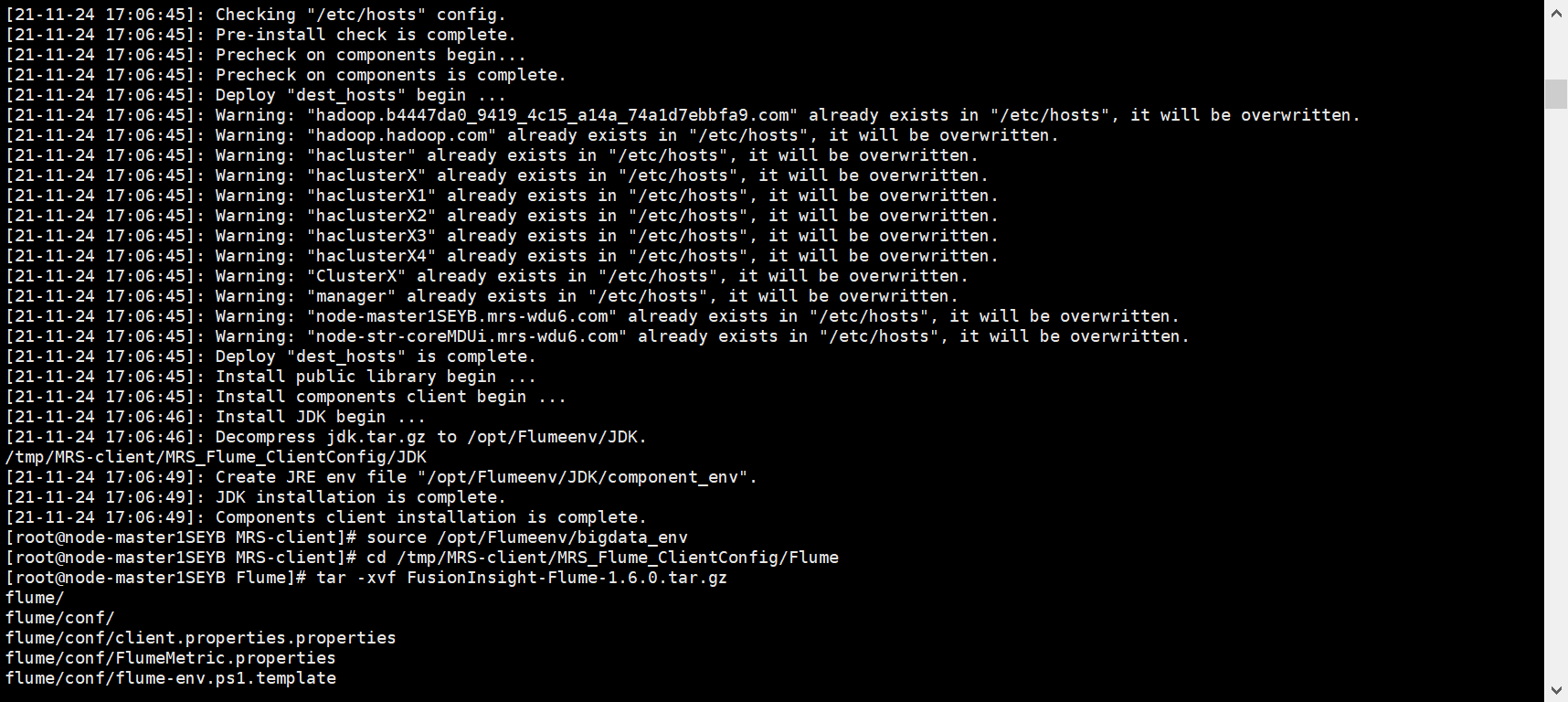
安装完成:

重启服务安装结束:

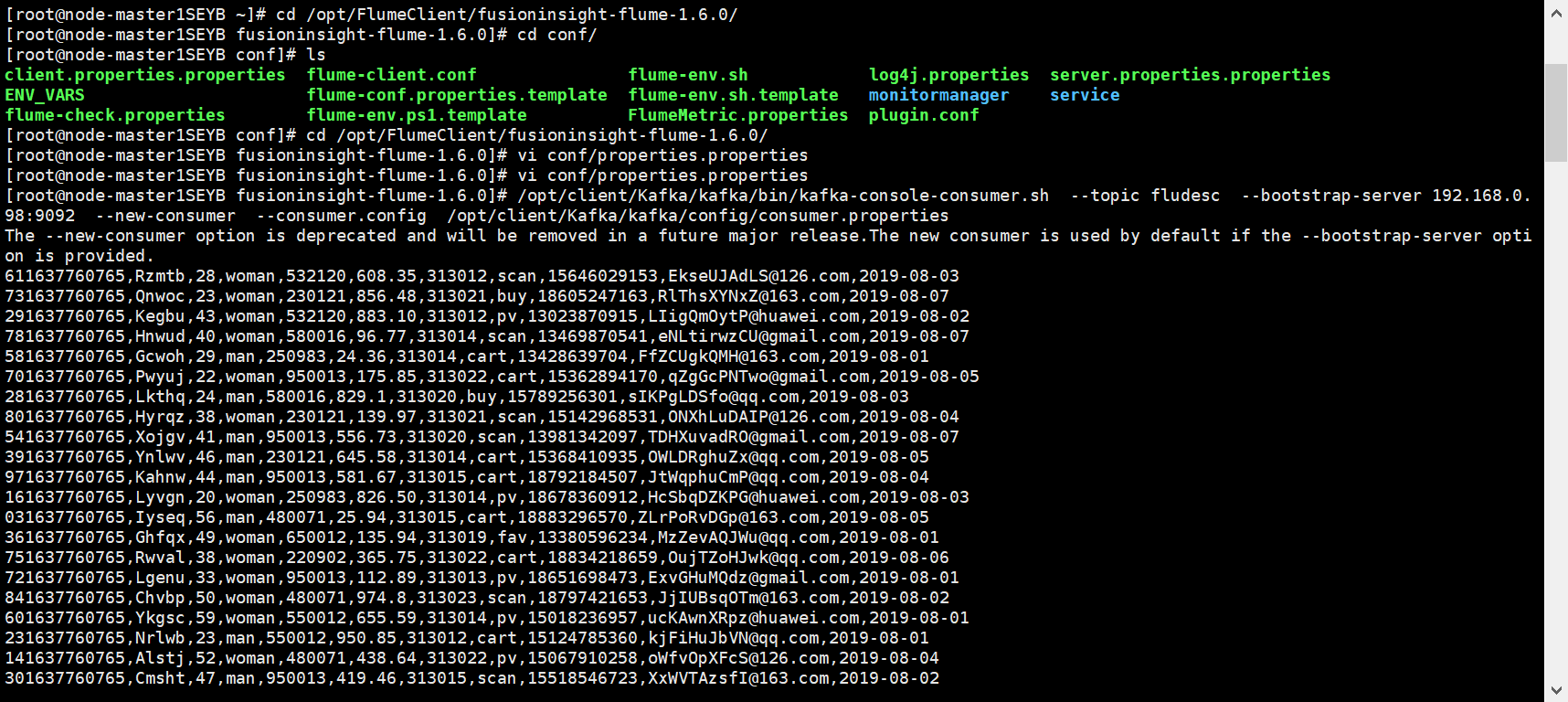
任务五:配置Flume采集数据
运行结果:
心得体会
了解并学习了Flume架构,学会了使用华为云平台,完成使用Flume日志采集任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号