数据采集 实验三
1.作业①
1.1作业内容
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位) 输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1.2解题思路
爬取网站:http://www.weather.com.cn
获取网站下的所有图片,那就包含该网站和该网站下的子网站的图片,所有需要找寻网站下的所有a标签,获取网页下的所有链接和图片,再对获取的所有链接进行如上操作,也就是进行深度优先或广度优先搜索。
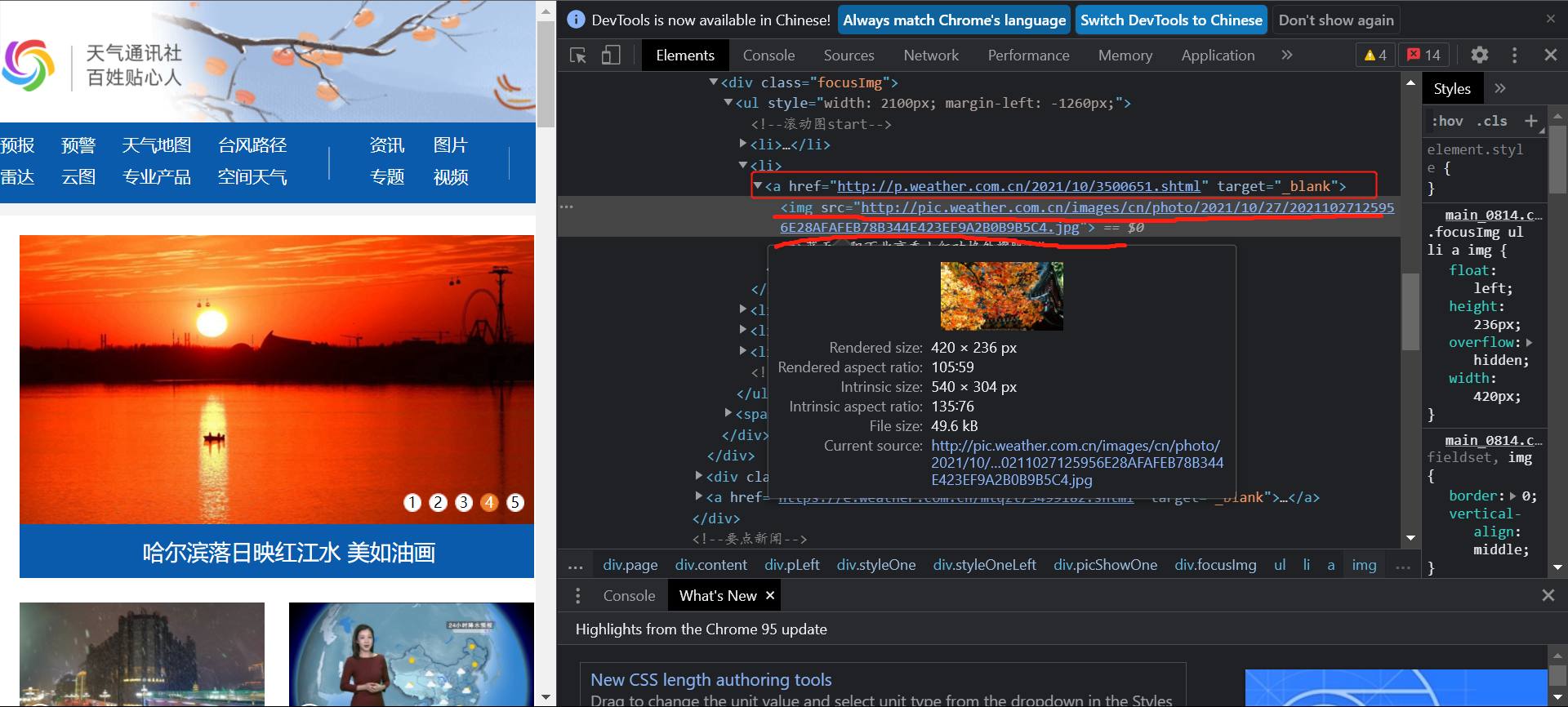
1.2.1获取链接
获取网页的源代码然后使用BeautifulSoup解析网页查找其中所有的a标签,存储所有链接正确的href属性值。
再使用requests对链接发起请求迭代。
首先从http://www.weather.com.cn网址进入。
reponse = requests.get(url=url, headers=header) # 发起get请求
reponse.encoding = 'utf-8' # 设置编码方式
bs4 = BeautifulSoup(reponse.text, 'lxml') #buautiful解析页面
alink = bs4.find_all('a') #找到全部a标签
然后获取标签的属性值
link = i.get('href')
if type(link)==str:
if link.startswith('http'): #判断以http开头的
alinks.append(link)
1.2.2获取图片
和上面获取a标签的href属性值相同的方法,获取img标签的src属性值。
img = bs4.find_all('img') #找到全部img标签
num=0 #判断当前页面读取的图片数量
for i in img:
src =i.get('src')
获取了图片的源地址后可以对图片进行下载的操作:
with open("./images/" + imgname + '.jpg', 'wb') as imgs: # 将图片写进图片文件
pic2 = requests.get(url).content # 获取图片链接的二进制
imgs.write(pic2)
1.2.3进行迭代搜索
这里编写了一个函数进行搜索:
def getalink(url,deep): #url就是遍历页面的url,deep是深度优先搜索的层数
url是搜索的网址,deep是迭代层数,开始时对http://www.weather.com.cn发起请求
getalink('http://www.weather.com.cn/',5)
这里的5是我设置的最大迭代次数。
找到链接之后对每个链接进行如上操作
for i in alinks:
if i not in global_link:
getalink(i,deep-1)
这里的links是存放链接的列表。每次迭代次数减一。
网址在迭代的时候可能会回到原来已经搜索过的网址,所以这里设置了两个列表用于存放已经搜索的网站和已经下载的图片:
global_link=[] #存储已经搜索的页面的url,防止回溯
global_img=[] #存储已经下载的图片的url
下载图片的时候同理:
1.2.4多线程实现
使用threading创建和启动进程:
T = threading.Thread(target=writetofilebylty, args=(src, count)) # 创建进程
T.start()
threads.append(T)
args里存储的是函数的参数
在主函数创建一个列表存储创建的进程:
threads = []
for i in range(len(threads)):
threads[i].join()
1.3输出
输出设置要求爬取116张图片,可以通过global_img列表的长度来判断。
if deep<=0 or len(global_img)>=116: #判断116张
return
控制台输出:

保存的图片,名称为图片链接最后一个字段
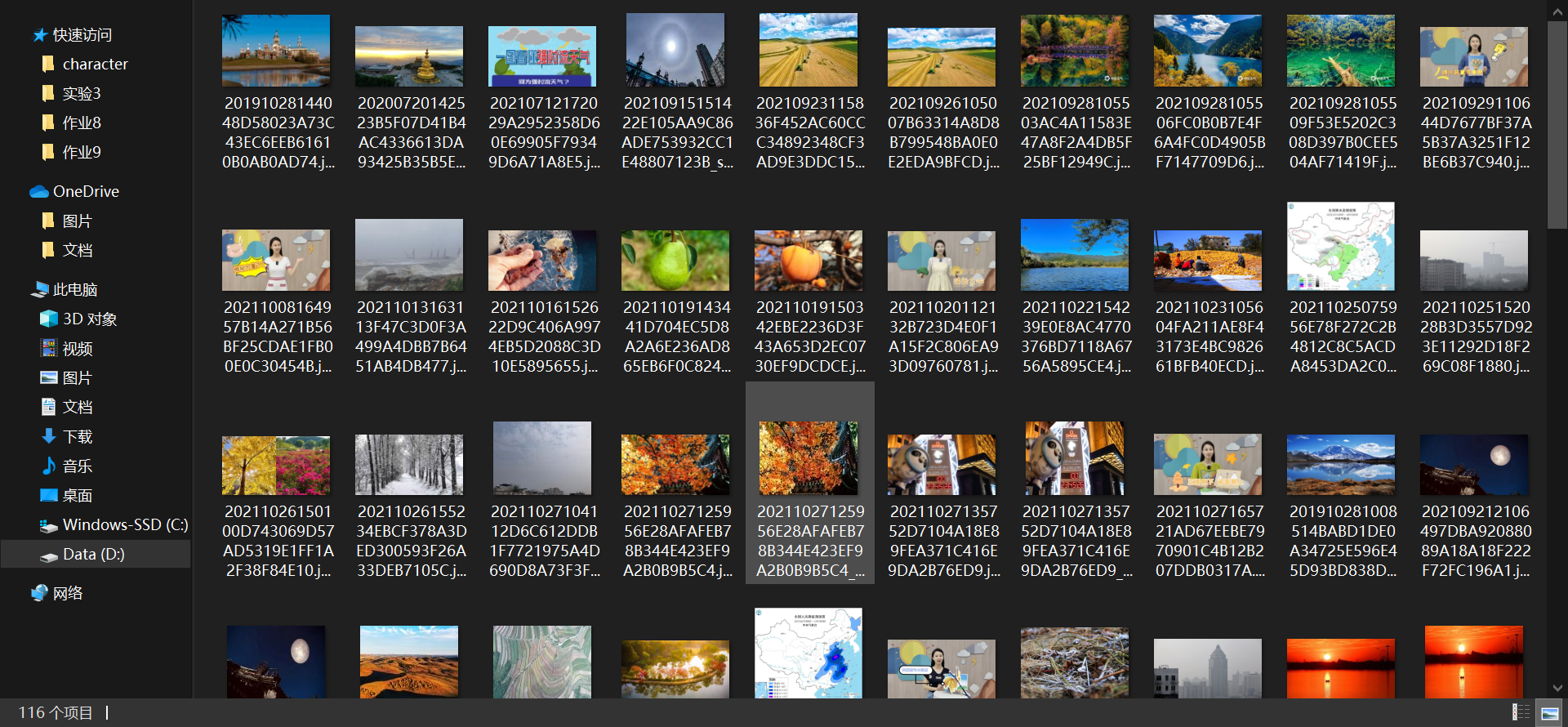
1.4心得体会
熟悉了对网站的遍历,巩固了对多线程爬虫的理解,requests和BeautifulSoup和threading的使用
2.作业②
2.1作业内容
求:使用scrapy框架复现作业①。 输出信息: 同作业①
2.2解题思路
基本同作业一,爬取一个网站下的所有图片和子网站链接,迭代进行搜索。不同之处在于使用scrapy架构。
2.2.1链接获取
scrapy中发起请求使用的是 scrapy.Request或者 scrapy.FormRequest。
发起第一个请求写在继承scrapy.Spider类的start_requests方法中:
def start_requests(self):
url = "http://www.weather.com.cn/" #开始的网址
yield scrapy.Request(url=url, callback=self.parse, meta={'deep': 5}) #发起请求,mate中带参数deep是计算迭代次数
构成请求携带了参数deep,作用如作业一中函数的deep。
发起请求后会将请求的结果发送到parse方法中,在parse方法中使用response.body.decode()可以获取页面的内容。
这里是复现作业①,所以同样使用了BeautifulSoup来解析页面的内容。
bs4 = BeautifulSoup(data, 'lxml') #解析网页
self.global_link.append(response.url) #将网页添加进global_link
alink = bs4.find_all('a') #找a标签
alinks = [] #存储找到的链接
for i in alink:
link = i.get('href')
if type(link) == str and link.startswith('http'):
alinks.append(link)
2.2.2获取图片
获取图片也基本同作业①
img = bs4.find_all('img')
count = 0
for i in img:
src = i.get('src')
if src.startswith('http') and src not in self.global_img: #判断图片是否已经爬取
# downimg(src)
item = Demo1Item()
item['src'] = src #添加图片的源地址
self.global_img.append(src)
count += 1
if count >= 10: #每个网页最多爬十张图片
break
yield item
global_img是在主类中创建的作用和作业①的一样的列表。
在items.py中设置了
src = scrapy.Field()
用于存储图片的源地址。
获取地址后yield启动进程,然后在ppelines进行图片的下载:
try:
if item['src'] not in self.imglist:
with open("./images/" + str(self.cunt) + '.jpg', 'wb') as imgs: # 将图片写进图片文件
pic2 = requests.get(item['src']).content # 获取图片链接的二进制
imgs.write(pic2)
print(item['src'])
self.imglist.append(item['src'])
self.cunt += 1
except:
print(item['src'])
2.2.3进行迭代搜索
在parse方法中找到链接后,存入links列表中,然后通过和start_requests方法相同的方式构成新的请求并进行迭代。
count = 0
for i in alinks:
count += 1
if count >= 20: #每个网页最多取20个链接
break
if i not in self.global_link and len(self.global_img) < 116:
# getalink(i, deep)
yield scrapy.Request(url=i, callback=self.parse, meta={'deep': deep - 1}) #发起新的请求(深搜)
global_img是在主类中创建的存储以搜索页面的列表。
2.3输出
控制台输出:
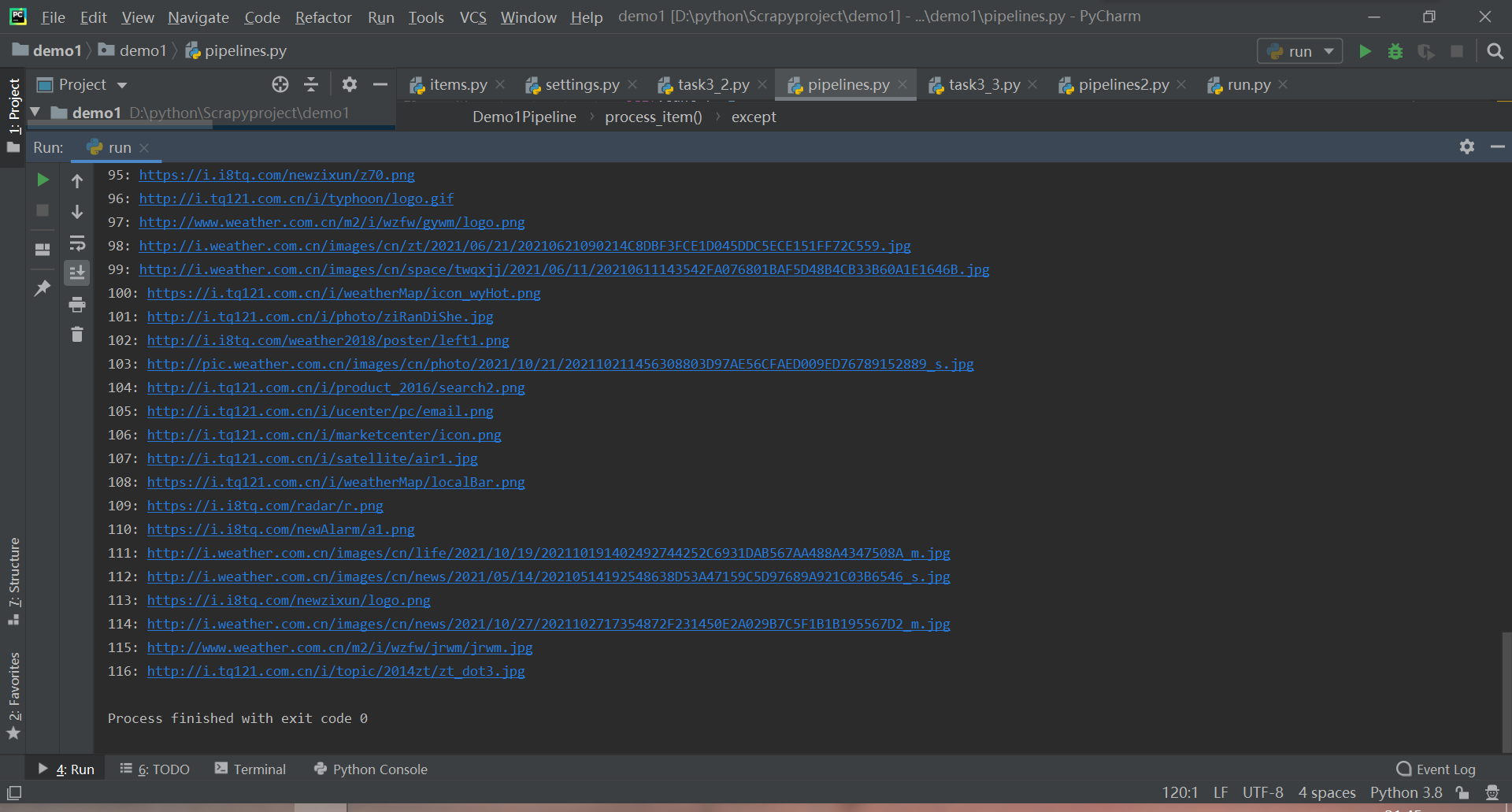
保存图片:
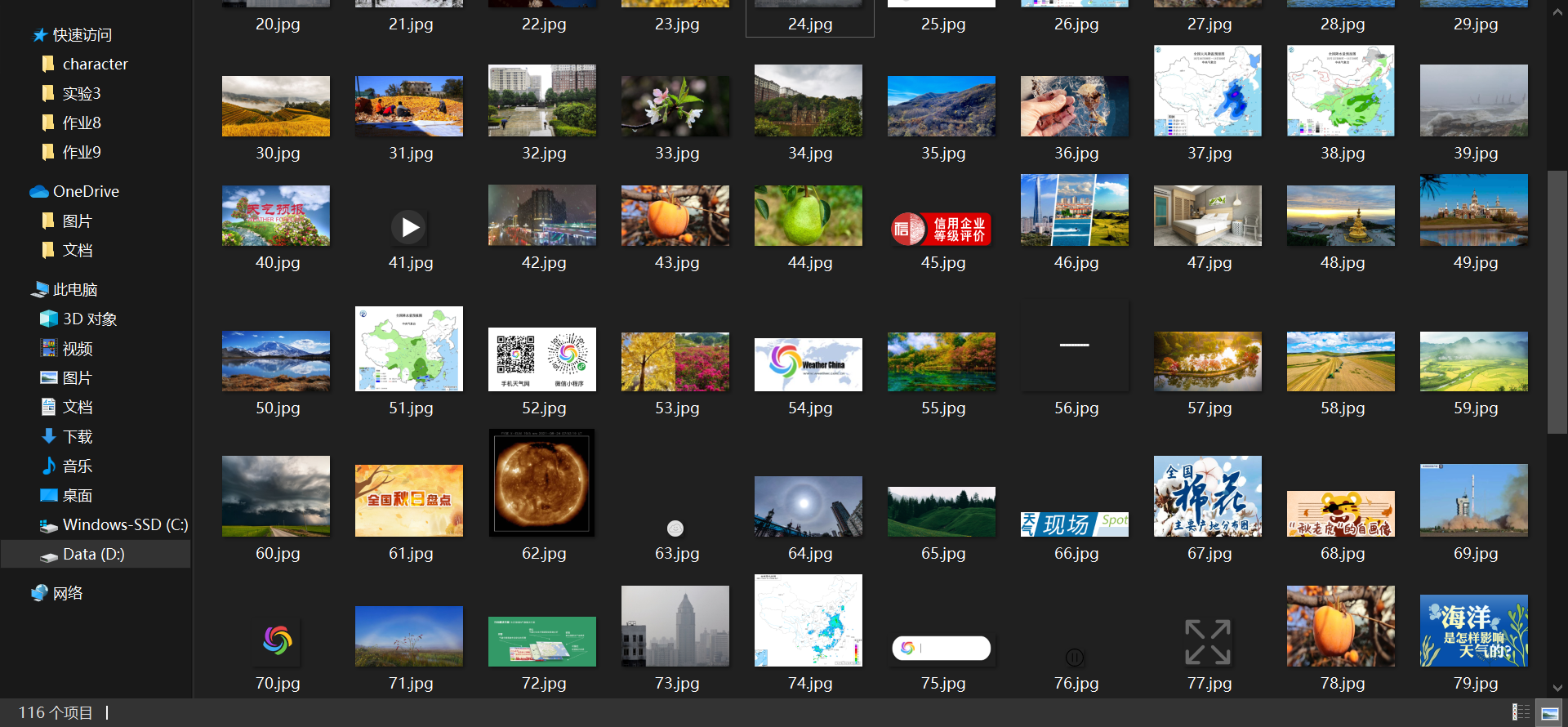
2.4心得体会
复习了scrapy爬虫框架。
了解了scrapy中parse的传参机制,(meta={'deep': 5},作业中迭代次数的参数)
3.作业③
3.1作业内容
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在 imgs路径下。
候选网站: https://movie.douban.com/top250
输出:
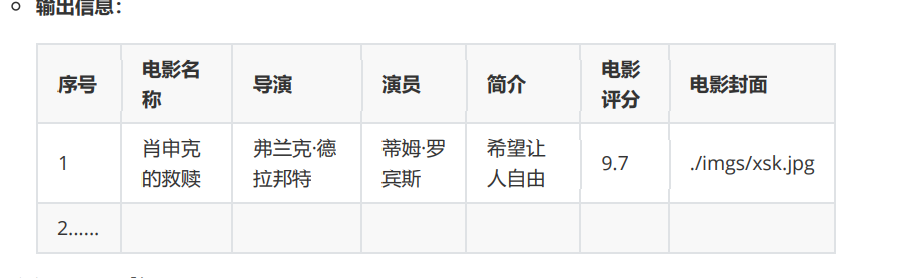
3.2解题思路
3.2.1网页内容的解析
要爬取的内容有序号,名称,导演,主演,简介,评分,电影封面(图片)在网页中查找需要爬取的元素的位置
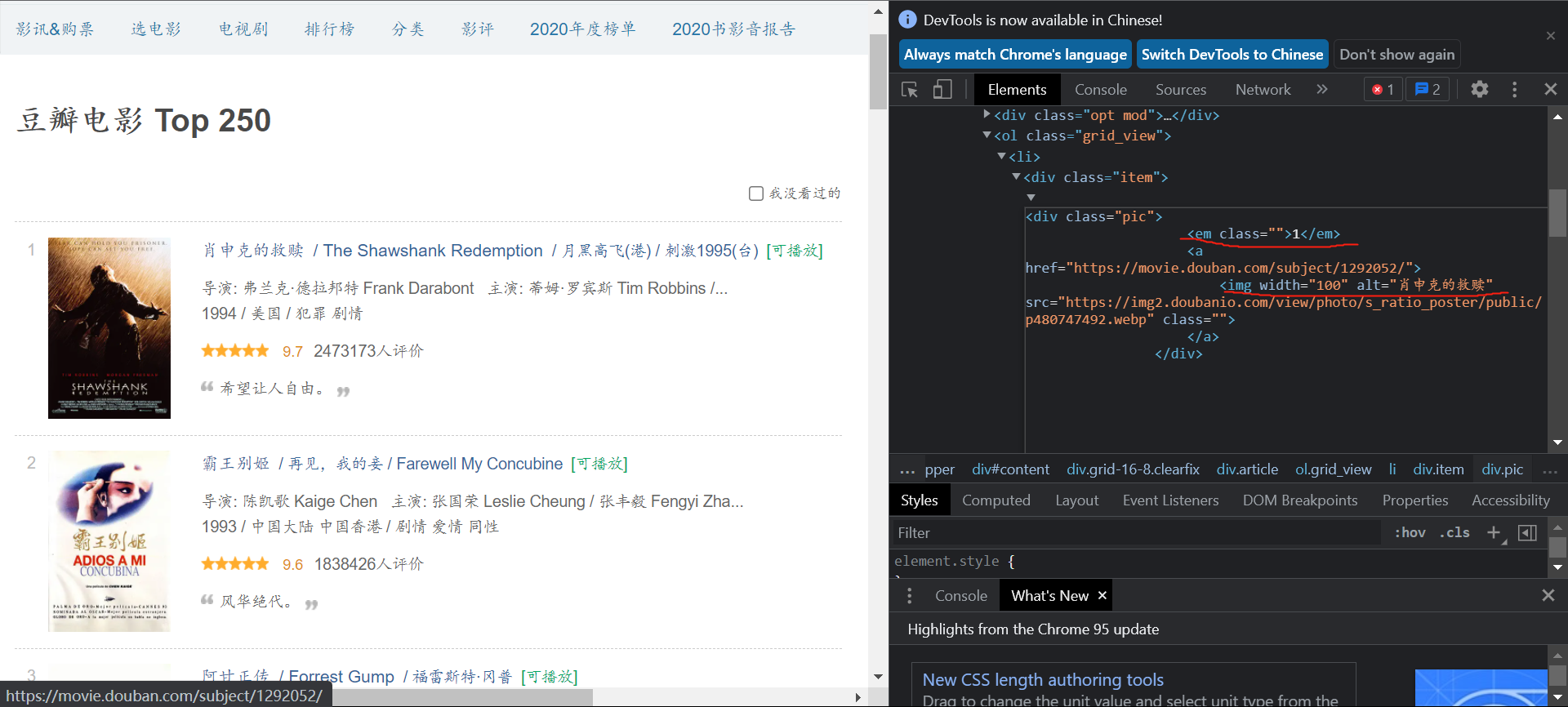
可以看到序号,名称,电影封面图片的源地址在class="pic"的标签的子节点中都有

导演和主演信息在class="bd"中有,但是接在一起且有很多转义符,需要处理
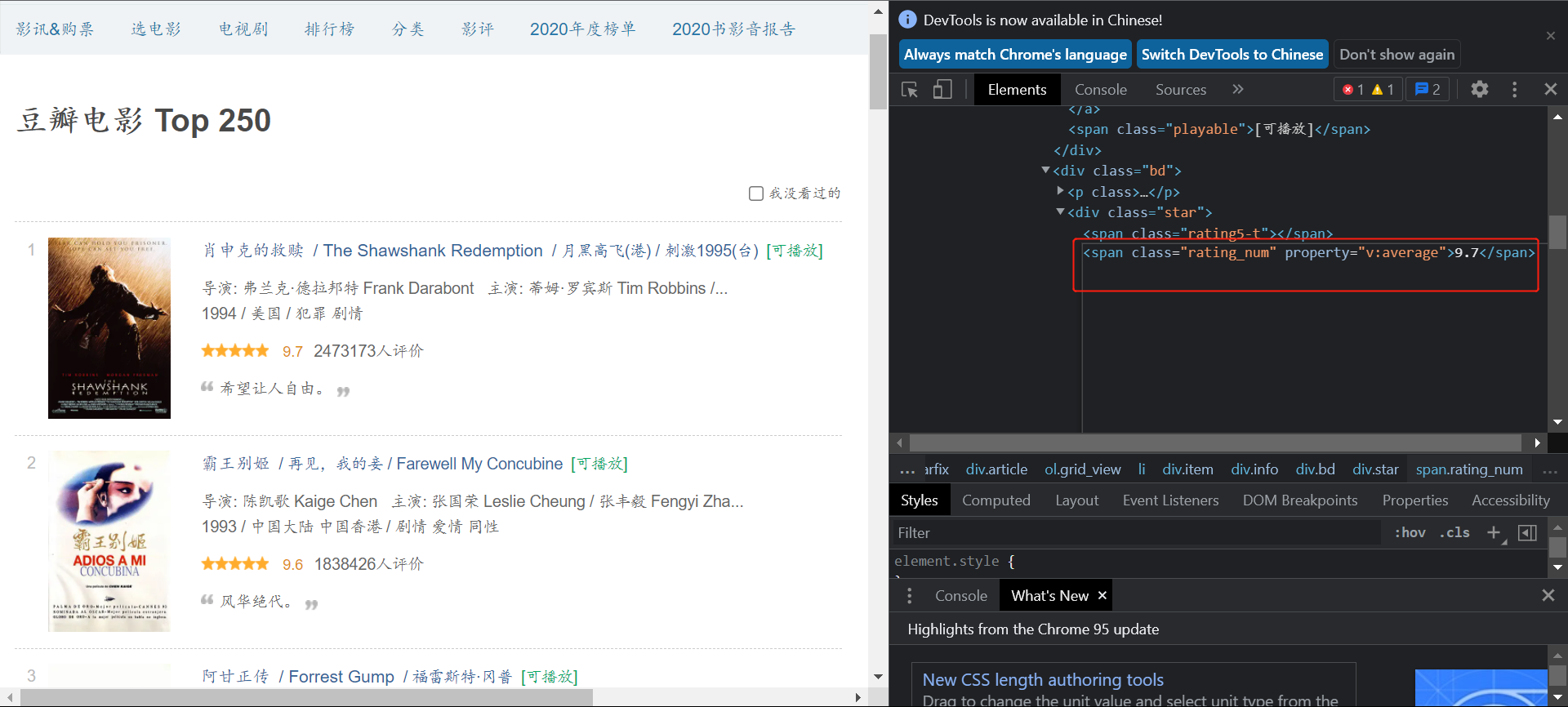
评分信息存储在span class="rating_num"标签中。
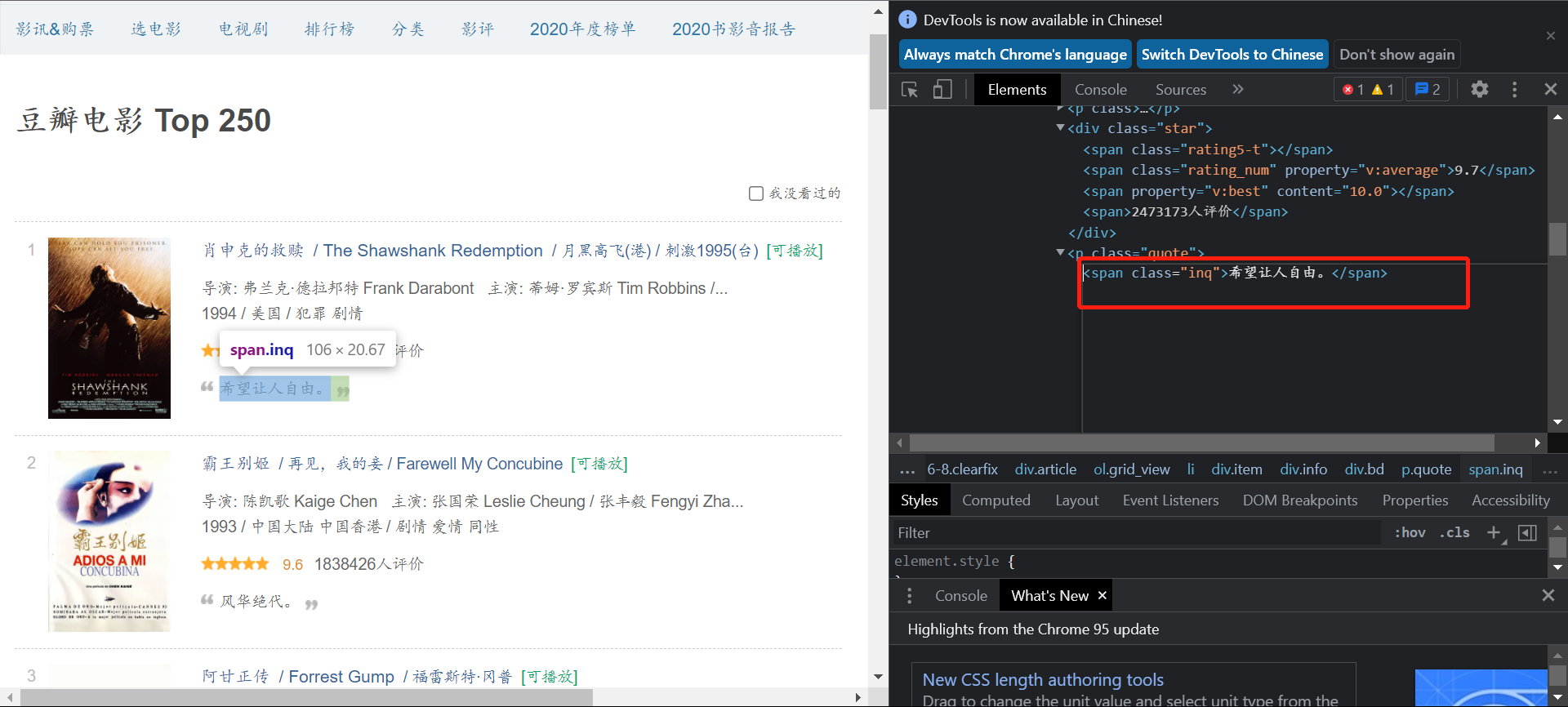
电影简介存储在span class="inq"标签中
3.2.2发起请求及信息获取
发起请求:
def start_requests(self):
for i in range(5):
self.url = "https://movie.douban.com/top250?start=" + str(i * 25) + "&filter=" #构造url进行翻页
yield scrapy.FormRequest(url=self.url, callback=self.parse, headers=self.header) #发起请求
发起请求并进行翻页处理
由于豆瓣每页只显示25部电影,所以按25为步长。
获取相关信息:
items.py中设置:
name = scrapy.Field()
piece = scrapy.Field()
dir = scrapy.Field()
character=scrapy.Field()
text =scrapy.Field()
score=scrapy.Field()
src = scrapy.Field()
id = scrapy.Field()
写在parse方法中:
如查找评分:
scores = selector.xpath('//span[@class="rating_num"]')
for i in range(len(scores)):
item['score'] = scores[i].xpath('./text()').extract_first()
对于导演和主演的处理:
dirandcharacter=others[i].xpath('.//p/text()').extract_first().split("主演:")
item['dir'] = dirandcharacter[0].replace(" ","").replace("导演:","").replace("\n","")
if len(dirandcharacter)>1:
item['character'] = dirandcharacter[1]
else:
item['character'] = "..."
由于在封面有些个别无法显示主演信息,先使用...代替
3.2.3写入数据库
使用pymysql实现数据库的存储,写在pipalines中。
conn = pymysql.connect(host="localhost", user="root", password="root", database="spider",
charset='utf8') # 配置数据库信息
cs1 = conn.cursor() # 连接数据库
sql1 = """ """ #创建表的语句
cs1.execute(sqlcreat)
sql2=''' ''' #插入数据的语句
arg = (item['id'], item['name'], item['dir'],item['character'],item['score'],item['text'],item['src'])
cs1.execute(sql2, arg)
conn.commit()
3.3输出
保存的图片:
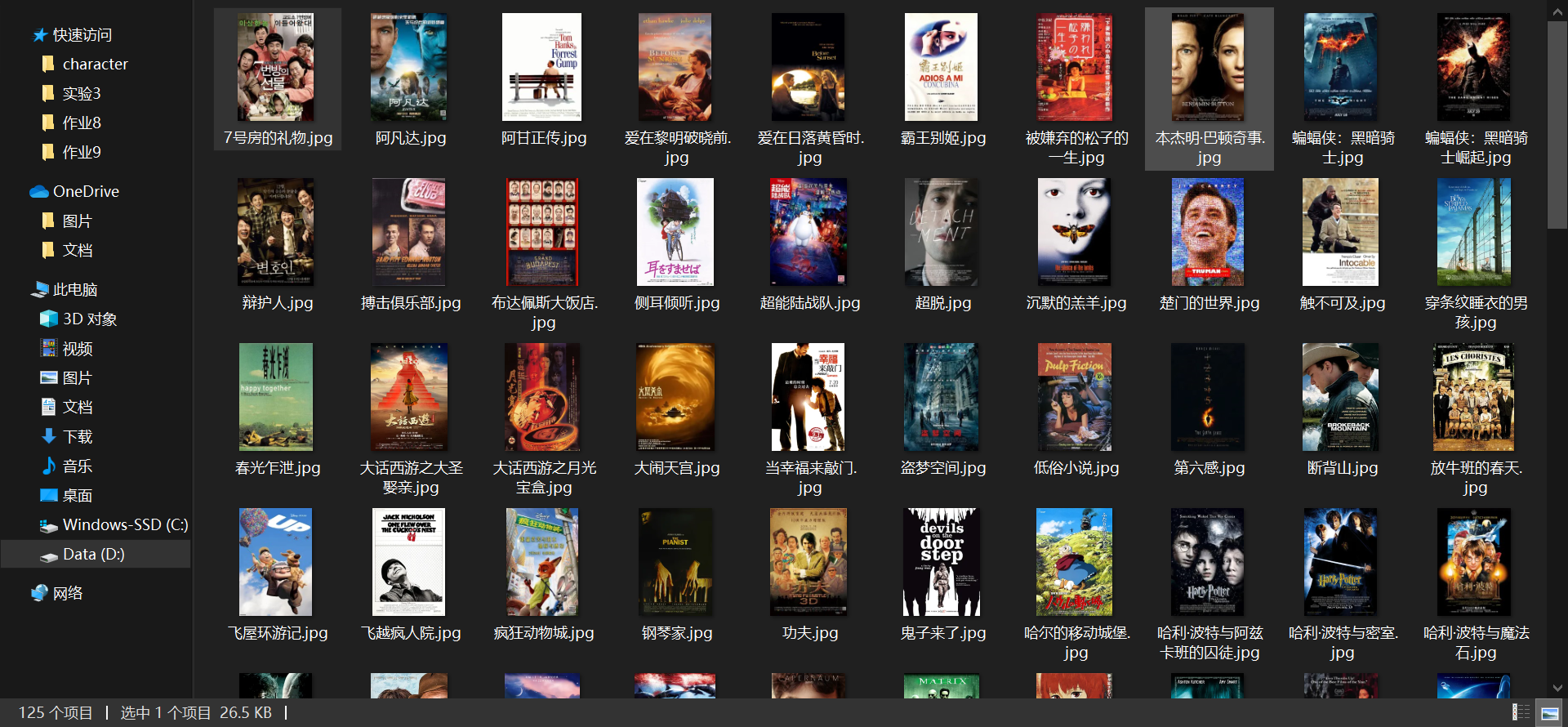
爬取了五页125部电影
数据库:
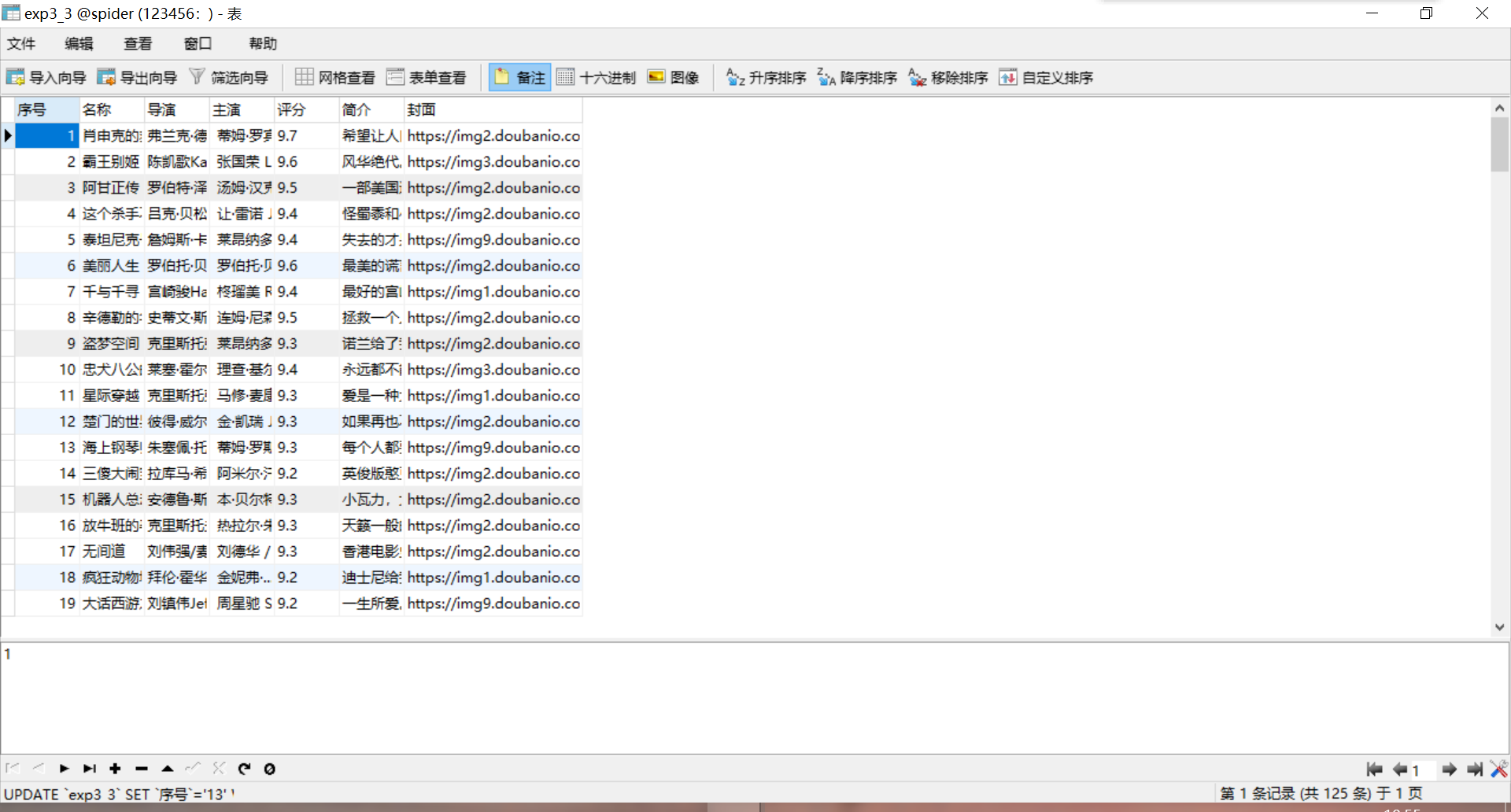
3.4心得体会
巩固了使用pymysql对数据库的操作和scrapy爬虫框架,了解了一下机器人协议(ROBOTSTXT_OBEY = False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号