数据采集 第二次实验
1.作业①
1.1作业内容
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在 数据库。

1.2解题过程
1.2.1解析网页和获取数据
对应城市的网页:
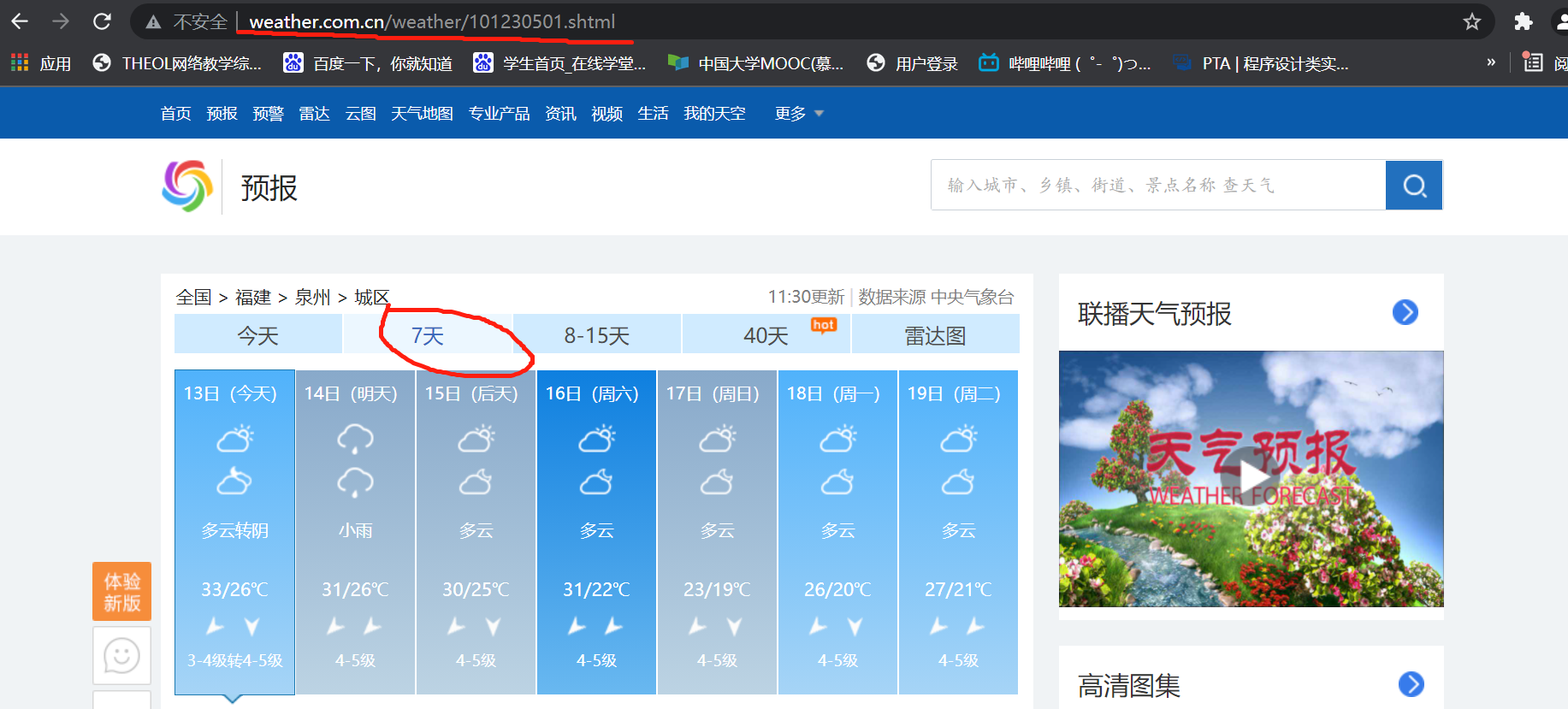
使用requests获取网页内容并使用BeautifulSoup解析网页:
import requests
from bs4 import BeautifulSoup
reponse = requests.get(url=url)
reponse.encoding="utf-8"
bs4 = BeautifulSoup(reponse.text, 'lxml')
同时设置编码方式,
再通过BeautifulSoup找到要找到内容,如找气温的数据:
tem = bs4.find_all(attrs={"class" :"tem"})
寻找class为”tem“的所有内容。
1.2.2存入数据库
使用pymysql存入mysql数据库
import pymysql
conn = pymysql.connect(host="localhost", user="root", password="root", database="spider", charset='utf8') #配置数据库信息
cs1 = conn.cursor()
这里存入名为spider的数据库
然后提交sql指令来进行数据表的创建和写入操作如:
sqlcreat = '''
create table if not exists exp2_1(
序号 char(100) not null,
日期 char(30) not null,
地区 char(50) not null,
天气信息 char(50) not null,
温度 char(50) not null)
''' #创建对应的表exp2_1
cs1.execute(sqlcreat)
1.2.3输出
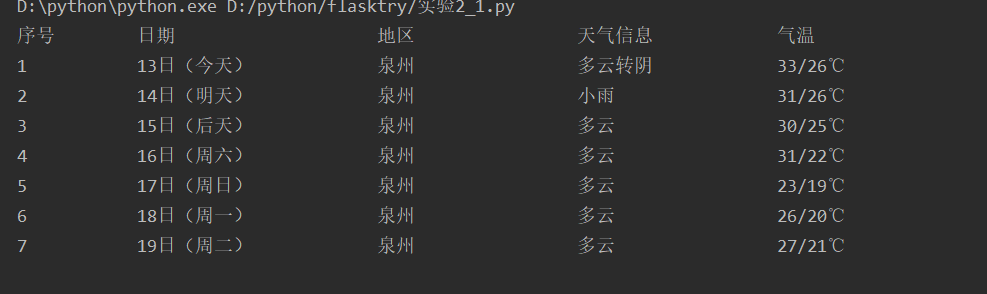
数据库:
)
1.3心得体会
在页面内容中要获取的内容分类很明确时,如class设置明确,BeautifulSoup较正则匹配的方式简便且高效。使用python将数据写入mysql数据库时应注意sql语句是否正确。
2.作业②
2.1作业内容
要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/ 新浪股票:http://finance.sina.com.cn/stock/
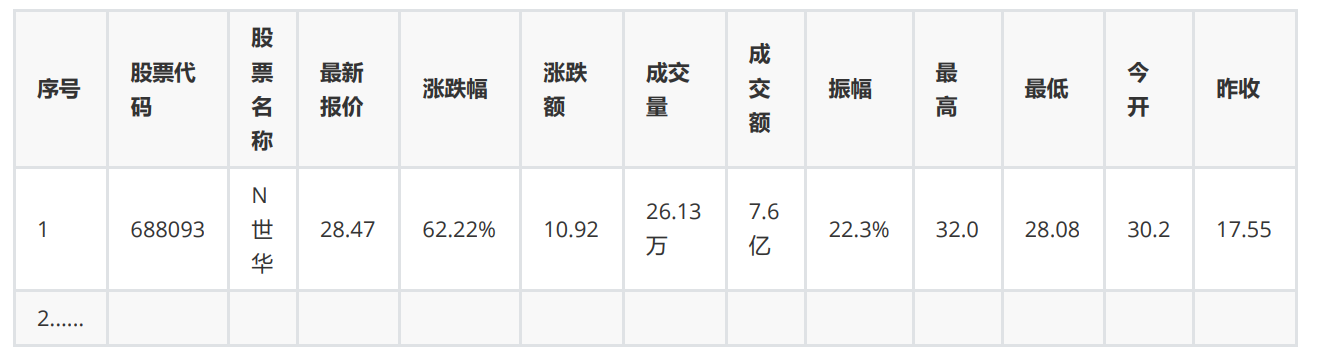
2.2解题过程
2.2.1获取目标内容
打开此网页:
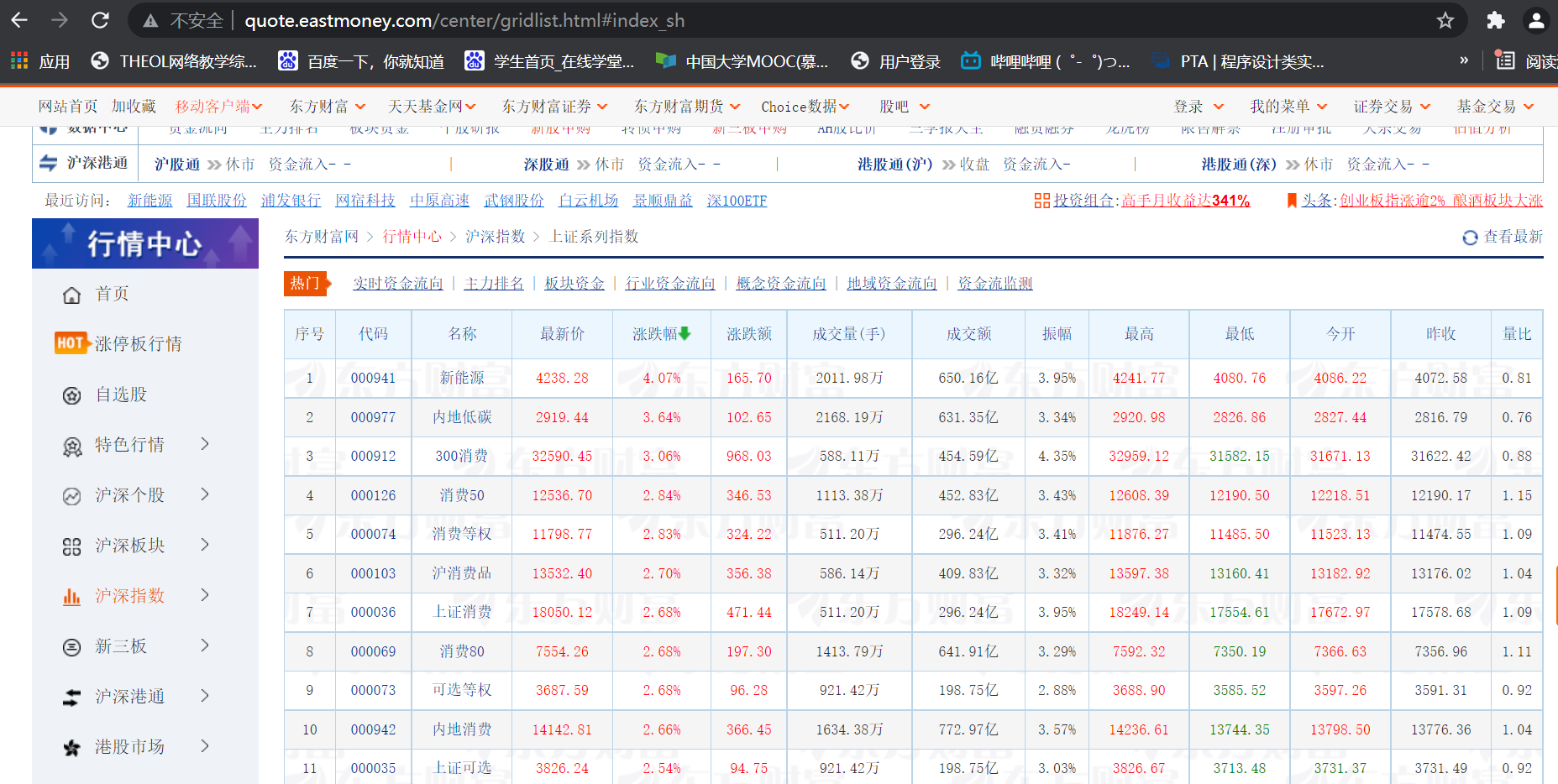
然后按F12进行抓包:
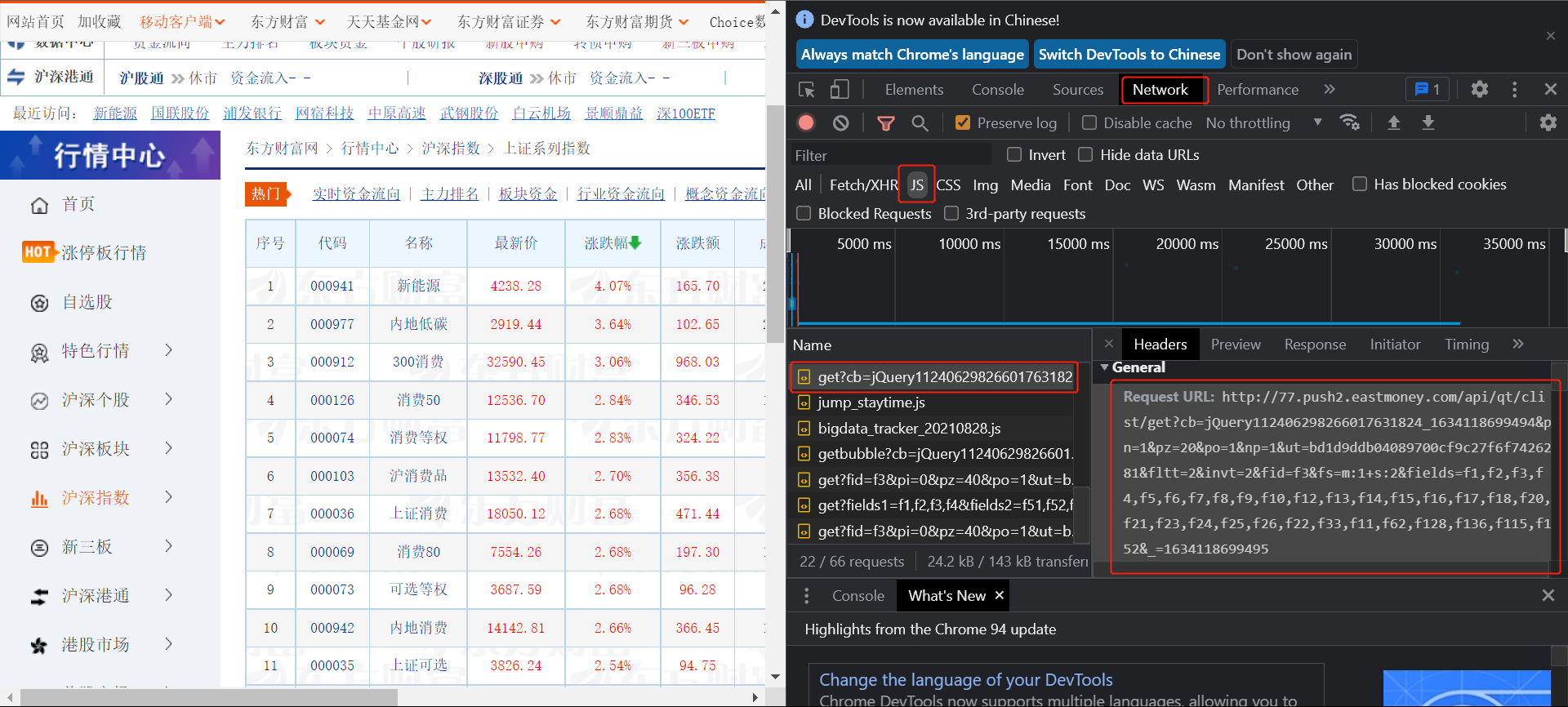
找到对应的url进入页面查看:

都是json的格式进行存储数据。
2.2.2提取目标内容
将上述的url复制到代码中进行爬取
使用requests进行页面的获取和re库获取想要的数据
import requests
import re
reponse = requests.get(url=url)
reponse.encoding="utf-8" #设置编码方式,否则有乱码
paper = reponse.text
获取对应的内容只要使用正则匹配如匹配股票名称:
regname = '"f14":"(.*?)"' #股票名称
names = re.findall(regname,paper)
对应的是文件中的:
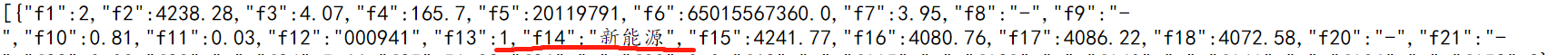
爬取其他的数据同理。
2.2.3输出
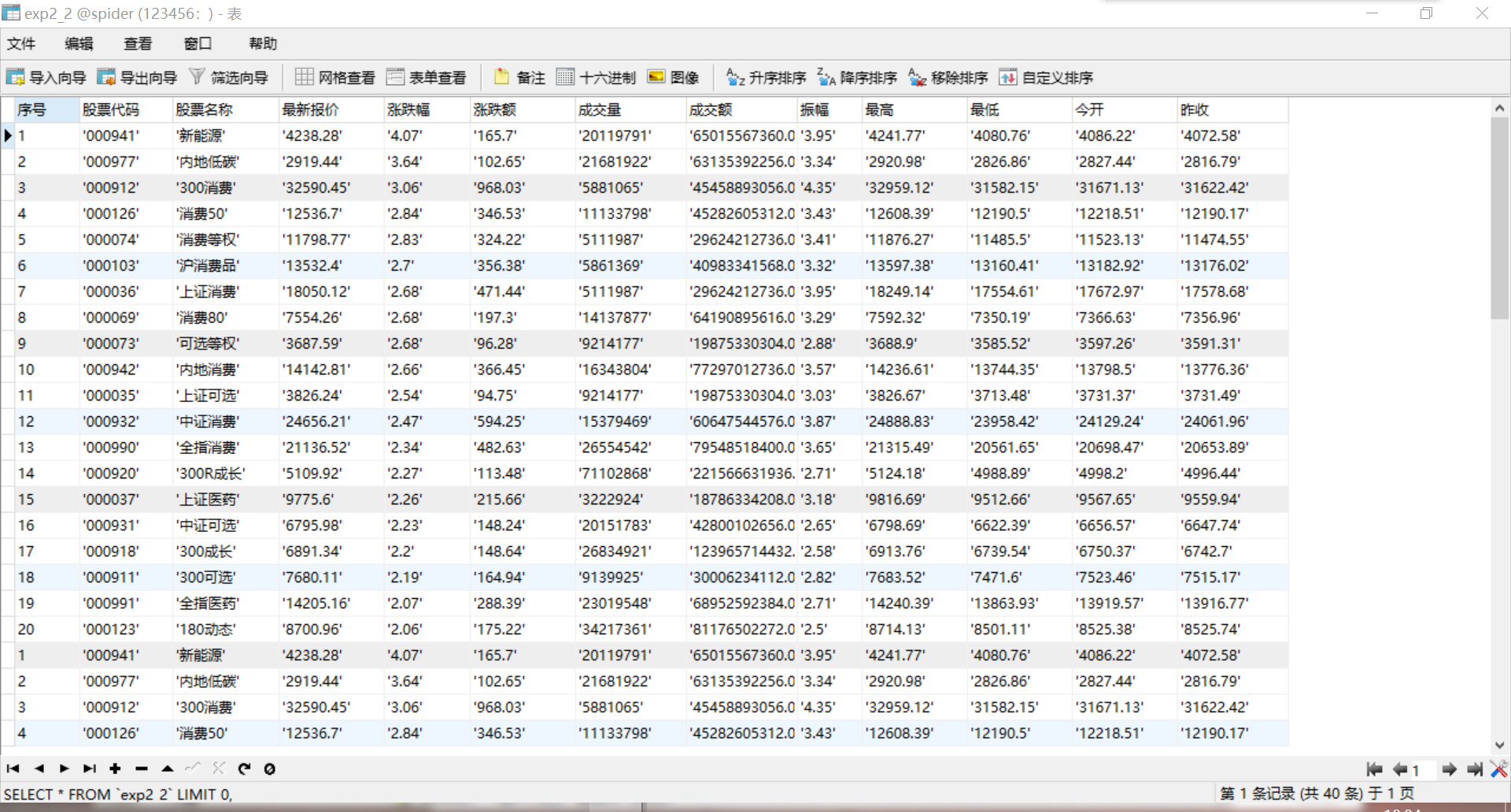
2.3新的体会
正则表达式在处理如json格式的文本内容时,可以较轻易的去除想要的内容。
某些网页的内容不是直接写进页面的html中的,而是通过js文件,要通过抓包才能找到要爬取的内容。
3.作业③
3.1作业内容
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所 有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。

3.2解题过程
3.2.1获取目标内容
直接打开题目的连接只有前20的学校排名
按F12进行抓包:
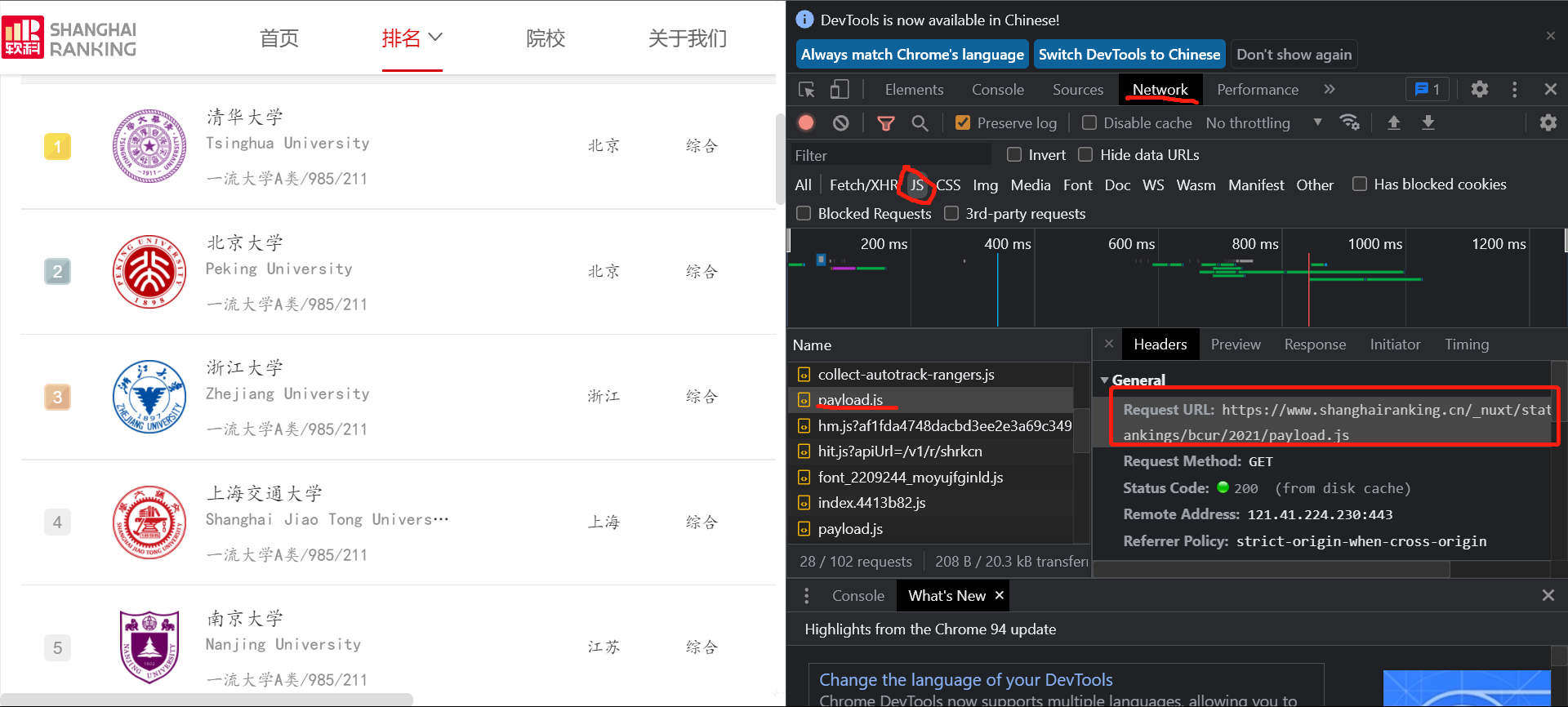
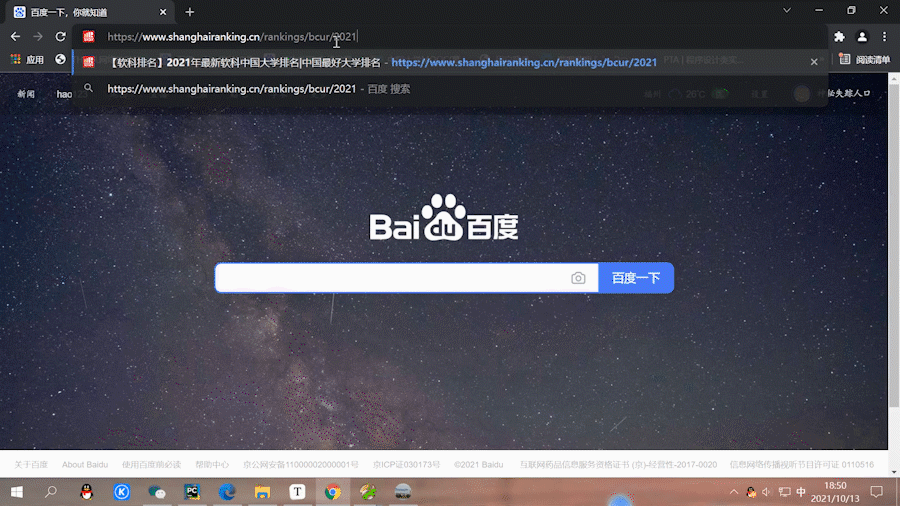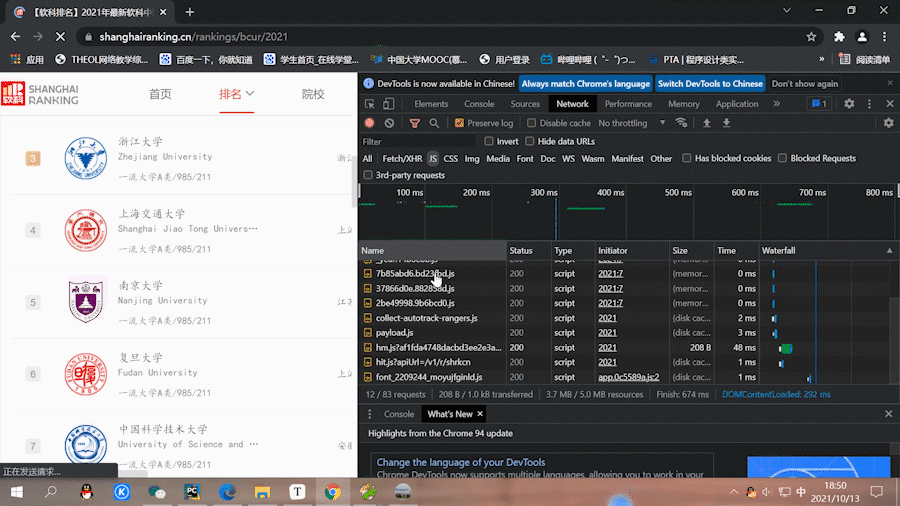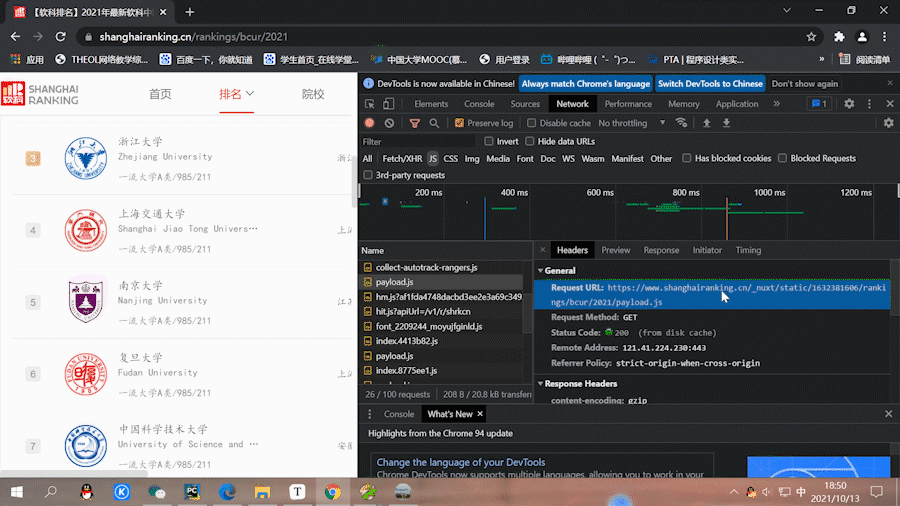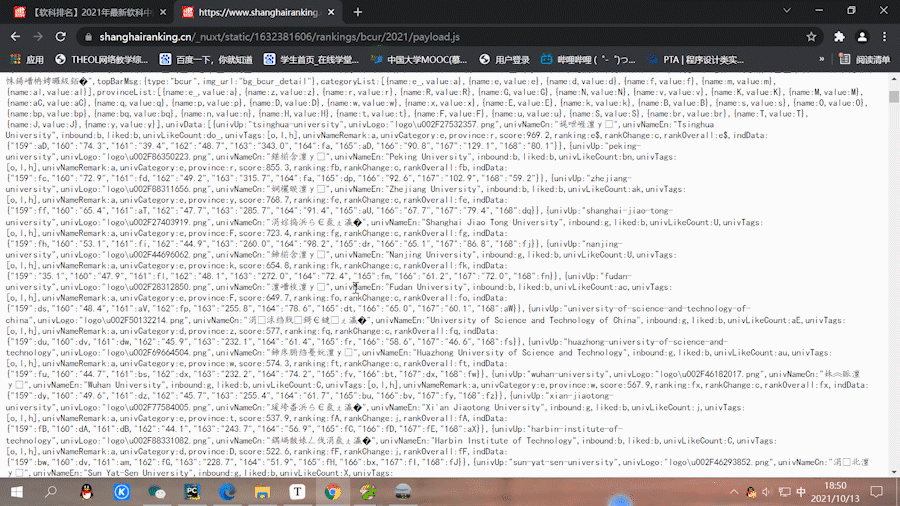
在network选择js文件,找到第一个payload.js,里面的url就是要找的,
在网页打开:

可以看到都是乱码,所有在代码中要设置编码方式
3.2.2提取目标内容
由于文件内容也是使用json的格式,所以使用requests获取页面信息和re进行正则匹配
import requests
import re
正则匹配如匹配学校名称时:
regname='univNameCn:"(.+?)"' #匹配学校名称的正则表达式
names = re.findall(regname, paper)
对应文件中的:

其他内容同理。
如果有总分相同的学校,只显示第一个学校的分数,所以需要处理:
for i in range(len(score)):
try:
float(score[i])
num=score[i]
except ValueError:
score[i]=num
这里将第一个的分数填入
存入数据库同第一题。
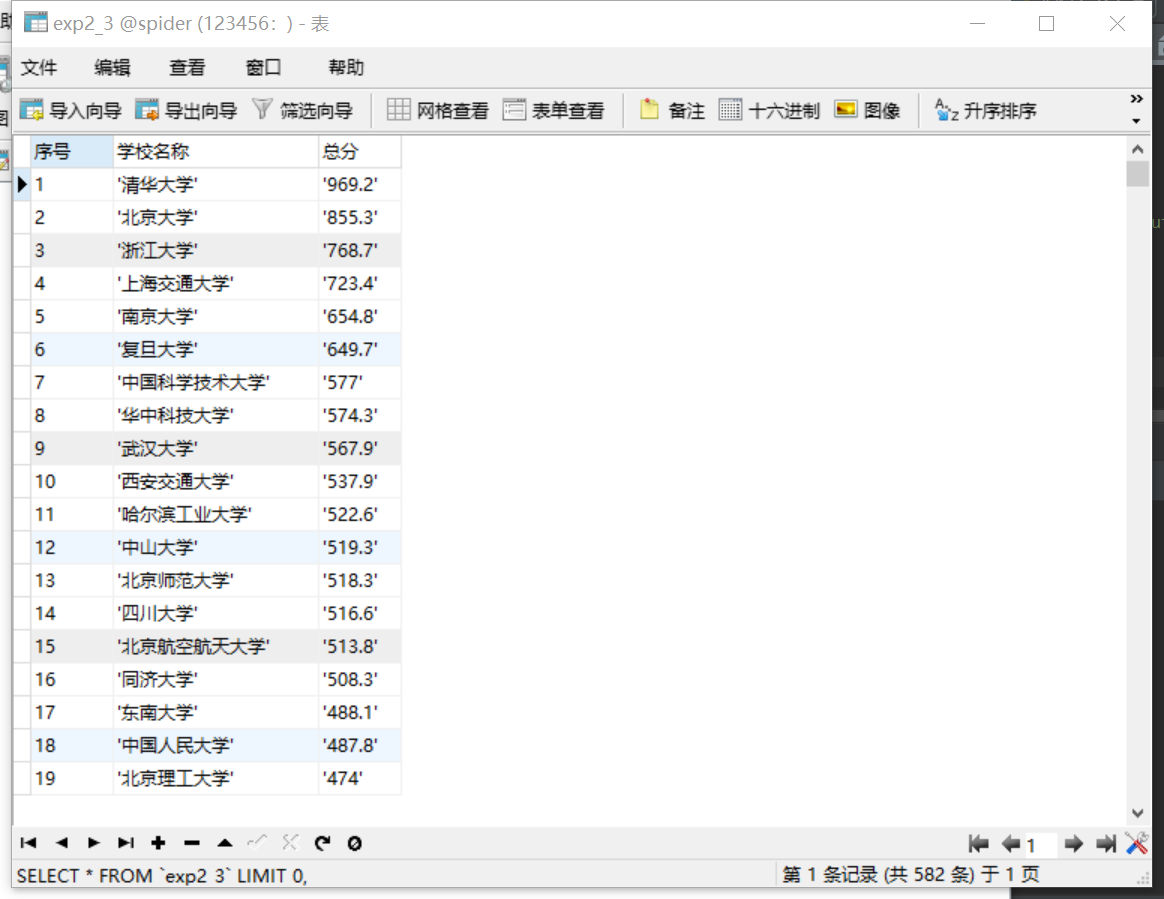
3.2.3输出

数据库:
3.3心得体会
熟悉Python对mysql的操作,要注意存入mysql的数据是否有缺少的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号