
数据集合详解
总结:
Connection接口:
1.List 有序,可重复
ArrayList:
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
LinkedList:
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
Vector:
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
2.Set 无序,唯一
(1)HashSet:
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
具体实现唯一性的比较过程:
1.存储元素时首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,肯定是不同的对象。
2.hashCode值相同,再比较equals方法。
3.equals相同,对象相同。(则无需储存)
(2)LinkedHashSet:
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
(3)TreeSet:
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
TreeSet底层数据结构采用红黑树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
红黑树:
在学习红黑树之前,咱们需要先来理解下二叉查找树(BST)。
二叉查找树
要想了解二叉查找树,我们首先看下二叉查找树有哪些特性呢?
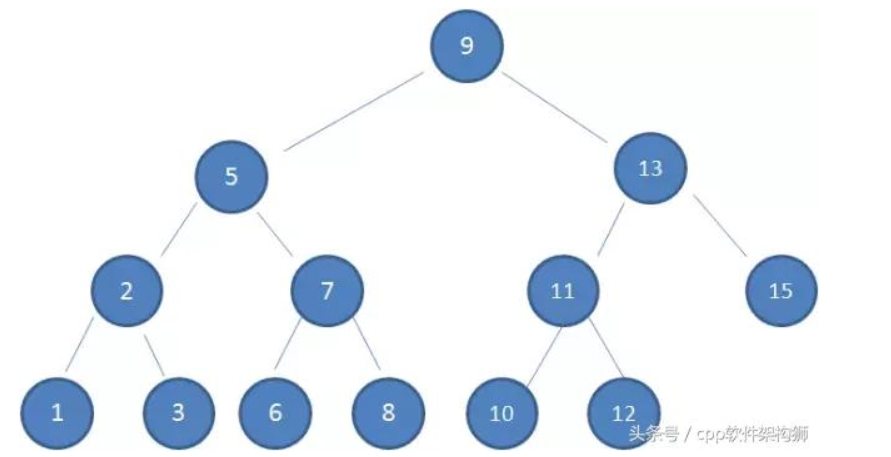
1, 左子树上所有的节点的值均小于或等于他的根节点的值
2, 右子数上所有的节点的值均大于或等于他的根节点的值
3, 左右子树也一定分别为二叉排序树
我们来看下图的这棵树,他就是典型的二叉查找树
红黑树
红黑树就是一种平衡的二叉查找树,说他平衡的意思是他不会变成“瘸子”,左腿特别长或者右腿特别长。除了符合二叉查找树的特性之外,还具体下列的特性:
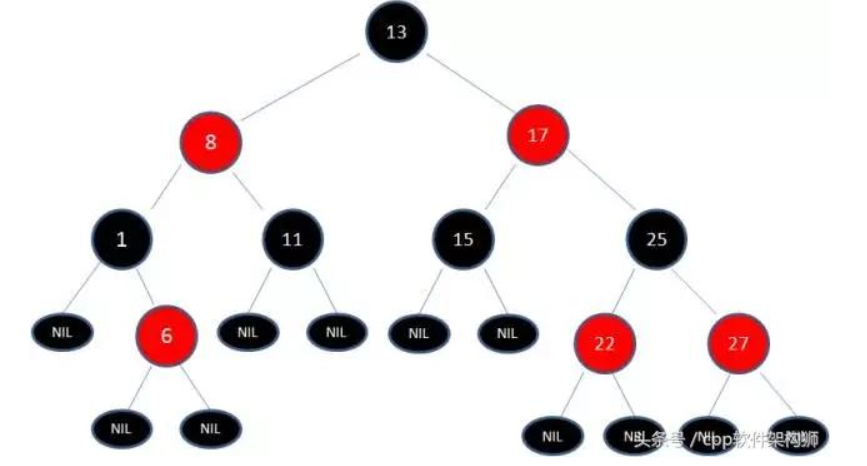
1. 节点是红色或者黑色
2. 根节点是黑色
3. 每个叶子的节点都是黑色的空节点(NULL)
4. 每个红色节点的两个子节点都是黑色的。
5. 从任意节点到其每个叶子的所有路径都包含相同的黑色节点。
看下图就是一个典型的红黑树:
红黑树详情:http://www.360doc.com/content/18/0904/19/25944647_783893127.shtml
TreeSet的两种排序方式比较
1.基本数据类型默认按升序排序
2.自定义排序
(1)自然排序:重写Comparable接口中的Compareto方法
(2)比较器排序:重写Comparator接口中的Compare方法
compare(T o1,T o2) 比较用来排序的两个参数。
o1:代表当前添加的数据
o2:代表集合中已经存在的数据
0: 表示 o1 == o2
-1(逆序输出): o1 < o2
1(正序输出): o1 > o2
1:o1 - o2(升序排列)
-1:o2 - o1 (降序排列)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号