

102302107_林诗樾_数据采集与融合技术实践作业1
作业①
1)、上海软科2020大学排名爬取实验(requests+BeautifulSoup)
import requests
from bs4 import BeautifulSoup
import warnings
warnings.filterwarnings("ignore") # 忽略SSL等无关警告
def crawl_university_ranking():
"""
爬取上海软科2020年中国大学排名(仅保留中文核心字段,优化对齐)
"""
# 1. 配置请求参数
target_url = "http://www.shanghairanking.cn/rankings/bcur/2020"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
try:
# 2. 发送请求并获取页面
response = requests.get(target_url, headers=headers, verify=False, timeout=10)
response.encoding = "utf-8" # 统一编码为UTF-8,避免中文乱码
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
return
# 3. 解析HTML
soup = BeautifulSoup(response.text, "lxml")
table_body = soup.find("tbody") # 定位表格数据区
if not table_body:
print("未找到排名表格,页面结构可能变更")
return
# 4. 打印表头(格式化字符串固定列宽)
print(f"{'排名':<4}{'学校名称':<8}{'省市':<6}{'学校类型':<6}{'总分':<8}")
print("-" * 32) # 分隔线(与列宽匹配)
# 5. 遍历行,提取并打印核心中文数据
for row in table_body.find_all("tr"):
cells = row.find_all("td")
if len(cells) < 5:
continue # 跳过无效行
# 精准提取每个字段(只保留第一个换行前的中文内容)
rank = cells[0].text.strip() # 排名
school_name = cells[1].text.strip().split("\n")[0].strip() # 学校名称(分割后取第一部分)
province = cells[2].text.strip().split("\n")[0].strip() # 省市(分割后取第一部分)
school_type = cells[3].text.strip().split("\n")[0].strip() # 学校类型(分割后取第一部分)
total_score = cells[4].text.strip().split("\n")[0].strip() # 总分(分割后取第一部分)
# 6. 格式化打印(左对齐+固定列宽)
print(f"{rank:<4}{school_name:<8}{province:<6}{school_type:<6}{total_score:<8}")
except Exception as e:
print(f"爬取出错:{str(e)}")
if __name__ == "__main__":
crawl_university_ranking()
运行结果:

2)、心得体会
最初爬取时未找到表格数据,原因是直接用soup.find_all("table")获取所有表格,导致匹配到无关表格。后来通过浏览器 “检查” 工具查看页面源码,发现排名表格的class="rk-table",用find("table", class_="rk-table")精准定位后解决问题,这让我意识到 “先分析页面结构,再写解析逻辑” 的重要性。
作业②
1)、商城书包比价爬取实验(requests+re)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import re
class SchoolbagComparator:
def __init__(self):
self.driver = webdriver.Edge(service=Service(r"F:\数据采集作业\msedgedriver.exe"))
self.keyword = "书包"
self.pages = 2
self.total_items = 0
self.products = []
def crawl_page(self, page_num):
url = f"https://search.dangdang.com/?key={self.keyword}&page={page_num}"
self.driver.get(url)
# 匹配正确的商品名称选择器(示例:a.pic)
WebDriverWait(self.driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "a.pic"))
)
time.sleep(2)
name_elements = self.driver.find_elements(By.CSS_SELECTOR, "a.pic")
price_elements = self.driver.find_elements(By.CSS_SELECTOR, "span.price_n")
for name, price in zip(name_elements, price_elements):
if self.total_items >= 40:
return
clean_name = re.sub(r'\s+', ' ', name.get_attribute("title")).strip()[:50]
clean_price = price.text
self.products.append({
"index": self.total_items + 1,
"name": clean_name,
"price": clean_price,
"price_num": float(clean_price.replace("¥", ""))
})
self.total_items += 1
print(f"[{self.total_items}] 名称:{clean_name} | 价格:{clean_price}")
time.sleep(2)
def compare_prices(self):
if not self.products:
print("\n❌ 未爬取到有效商品数据")
return
sorted_products = sorted(self.products, key=lambda x: x["price_num"])
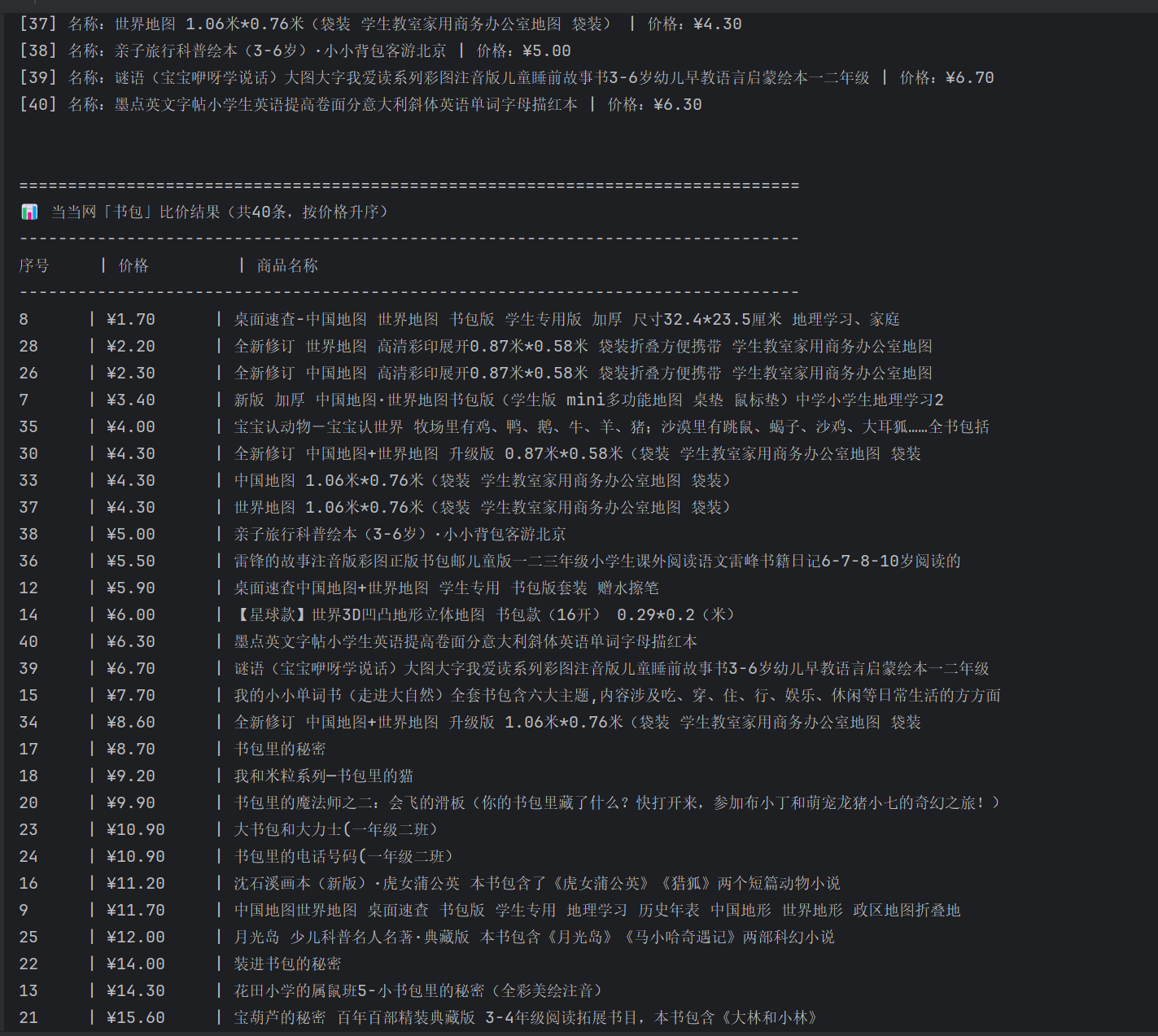
print("\n\n" + "="*80)
print(f"📊 当当网「{self.keyword}」比价结果(共{self.total_items}条,按价格升序)")
print("-"*80)
print(f"{'序号':<6} | {'价格':<10} | 商品名称")
print("-"*80)
for p in sorted_products:
print(f"{p['index']:<6} | {p['price']:<10} | {p['name']}")
prices = [p["price_num"] for p in sorted_products]
print("-"*80)
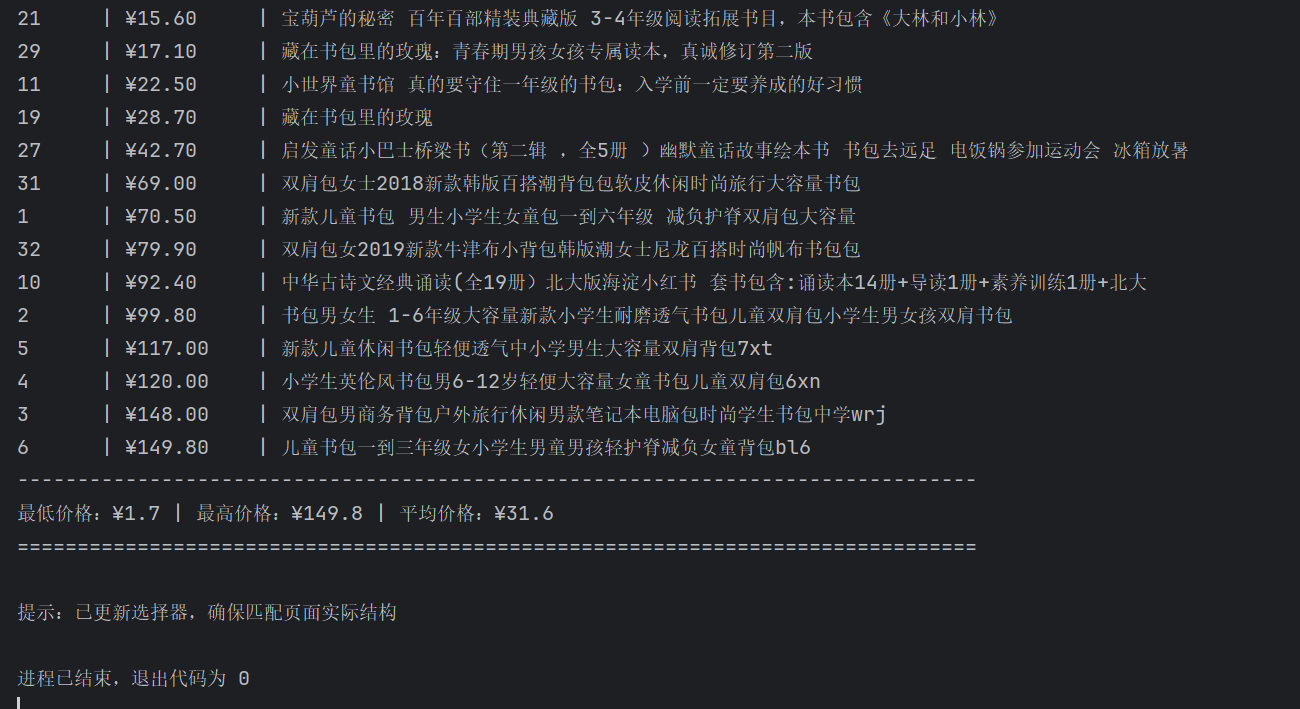
print(f"最低价格:¥{min(prices)} | 最高价格:¥{max(prices)} | 平均价格:¥{round(sum(prices)/len(prices), 2)}")
print("="*80)
def run(self):
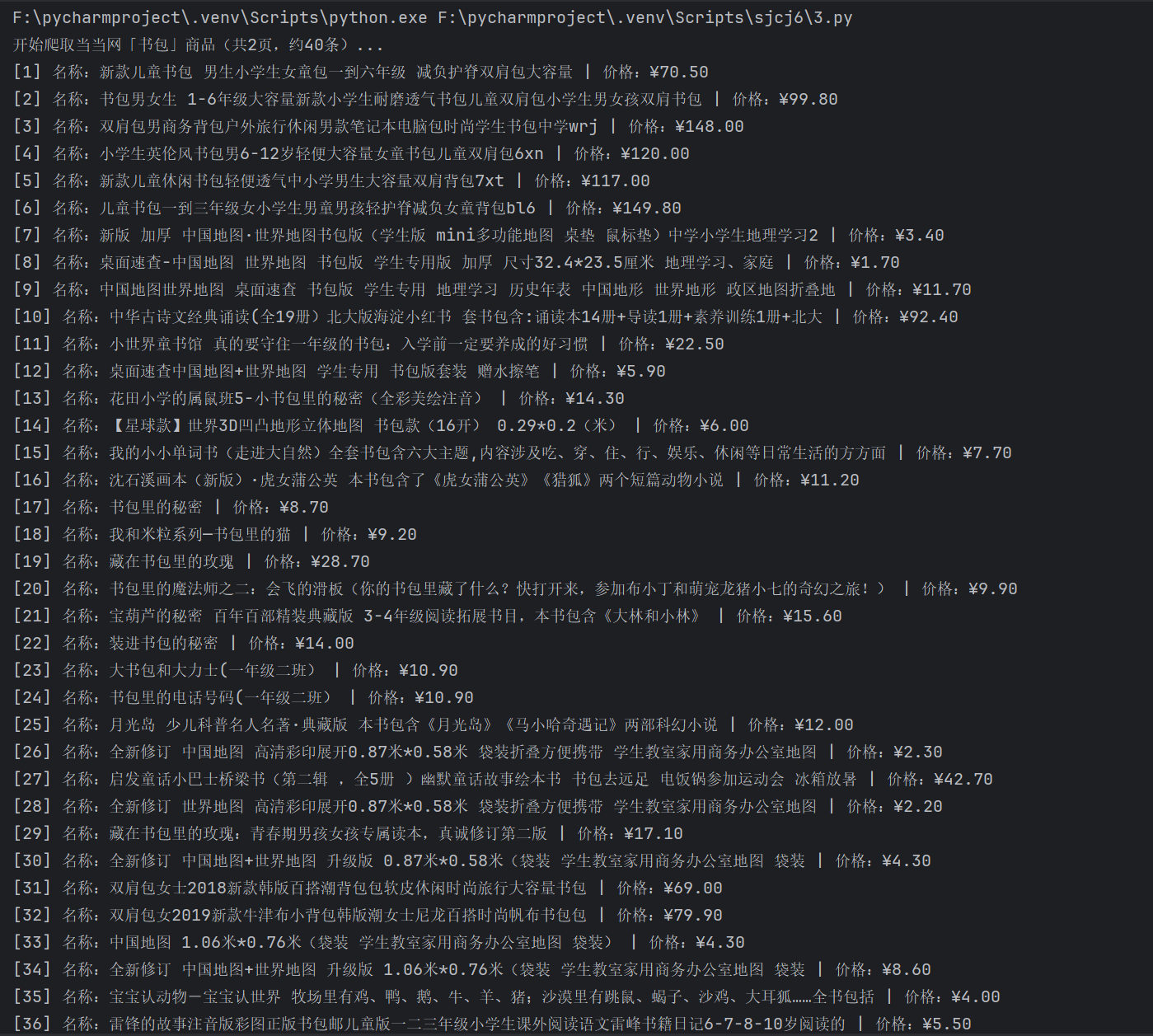
print(f"开始爬取当当网「{self.keyword}」商品(共{self.pages}页,约40条)...")
for page in range(1, self.pages + 1):
if self.total_items >= 40:
break
self.crawl_page(page)
self.compare_prices()
self.driver.quit()
print("\n提示:已更新选择器,确保匹配页面实际结构")
if __name__ == "__main__":
comparator = SchoolbagComparator()
comparator.run()
运行结果:
2)、心得体会
在完成商城书包比价爬虫开发的过程中,我明确了技术选型的边界——动态页面适配Selenium、静态页面适用requests+re;掌握了“浏览器F12调试+选择器验证”的页面元素精准定位方法;通过将商品数据结构化存储为含序号、名称、价格及数字价格的字典列表,实现了价格排序与统计分析;借助显式等待和请求间隔控制,有效应对反爬并保障了爬虫稳定性;以类封装爬取、分析等模块化功能的设计,为复杂爬虫系统开发奠定了工程化架构基础,这一系列实践让我从工具使用层面进阶到场景化解决方案的设计思维,对爬虫开发全流程逻辑有了更深刻的理解。
作业③
1)、网页图片爬取与保存实验
import requests
from bs4 import BeautifulSoup
import os
import warnings
warnings.filterwarnings("ignore") # 忽略SSLSSL证书警告
def crawl_fzu_news_images():
"""
爬取福州大学新闻页图片(处理相对路径URL,确保完整有效)
目标网页:https://news.fzu.edu.cn/yxfd.htm
图片保存路径:当前目录下的fzu_news_images文件夹
"""
# 基础配置
base_url = "https://news.fzu.edu.cn" # 网站基础域名(用于补全相对路径)
target_url = "https://news.fzu.edu.cn/yxfd.htm" # 目标网页
save_dir = "fzu_news_images" # 图片保存文件夹
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 创建保存文件夹(若不存在)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print(f"已创建图片保存文件夹:{save_dir}(路径:{os.path.abspath(save_dir)})")
try:
# 1. 获取网页内容
response = requests.get(target_url, headers=headers, verify=False, timeout=10)
response.encoding = "utf-8" # 福州大学网页使用UTF-8编码
if response.status_code != 200:
print(f"请求网页失败,状态码:{response.status_code}")
return
# 2. 解析HTML提取所有图片标签
soup = BeautifulSoup(response.text, "lxml")
img_tags = soup.find_all("img") # 提取所有<img>标签
if not img_tags:
print("未找到任何图片标签,可能页面结构已变更")
return
# 3. 遍历图片标签,处理URL并下载
img_count = 0 # 统计成功下载的图片数量
for img in img_tags:
img_src = img.get("src") # 获取图片原始URL(src属性)
if not img_src:
continue # 跳过无URL的图片
# 关键:补全相对路径URL(处理3种常见情况)
if img_src.startswith("//"):
# 情况1:URL以//开头(如//news.fzu.edu.cn/xxx.jpg)
img_full_url = f"http:{img_src}"
elif img_src.startswith("/"):
# 情况2:URL以/开头(相对根路径,如/xxx/xxx.png)
img_full_url = f"{base_url}{img_src}"
elif not img_src.startswith(("http://", "https://")):
# 情况3:URL为相对路径(如images/xxx.jpg)
img_full_url = f"{base_url}/{img_src}"
else:
# 情况4:完整URL(直接使用)
img_full_url = img_src
# 过滤非目标格式图片(仅保留jpg/jpeg/png)
if not img_full_url.lower().endswith((".jpg", ".jpeg", ".png")):
continue
# 4. 下载图片并保存
try:
img_response = requests.get(img_full_url, headers=headers, verify=False, timeout=10)
if img_response.status_code != 200:
print(f" 图片下载失败(状态码:{img_response.status_code}):{img_full_url}")
continue
# 生成保存文件名(序号+原后缀,避免重名)
img_suffix = img_full_url.split(".")[-1].lower()
# 限制后缀长度(防止异常后缀)
if len(img_suffix) > 5:
img_suffix = "jpg"
img_filename = f"fzu_img_{img_count + 1}.{img_suffix}"
save_path = os.path.join(save_dir, img_filename)
# 写入图片文件(二进制模式)
with open(save_path, "wb") as f:
f.write(img_response.content)
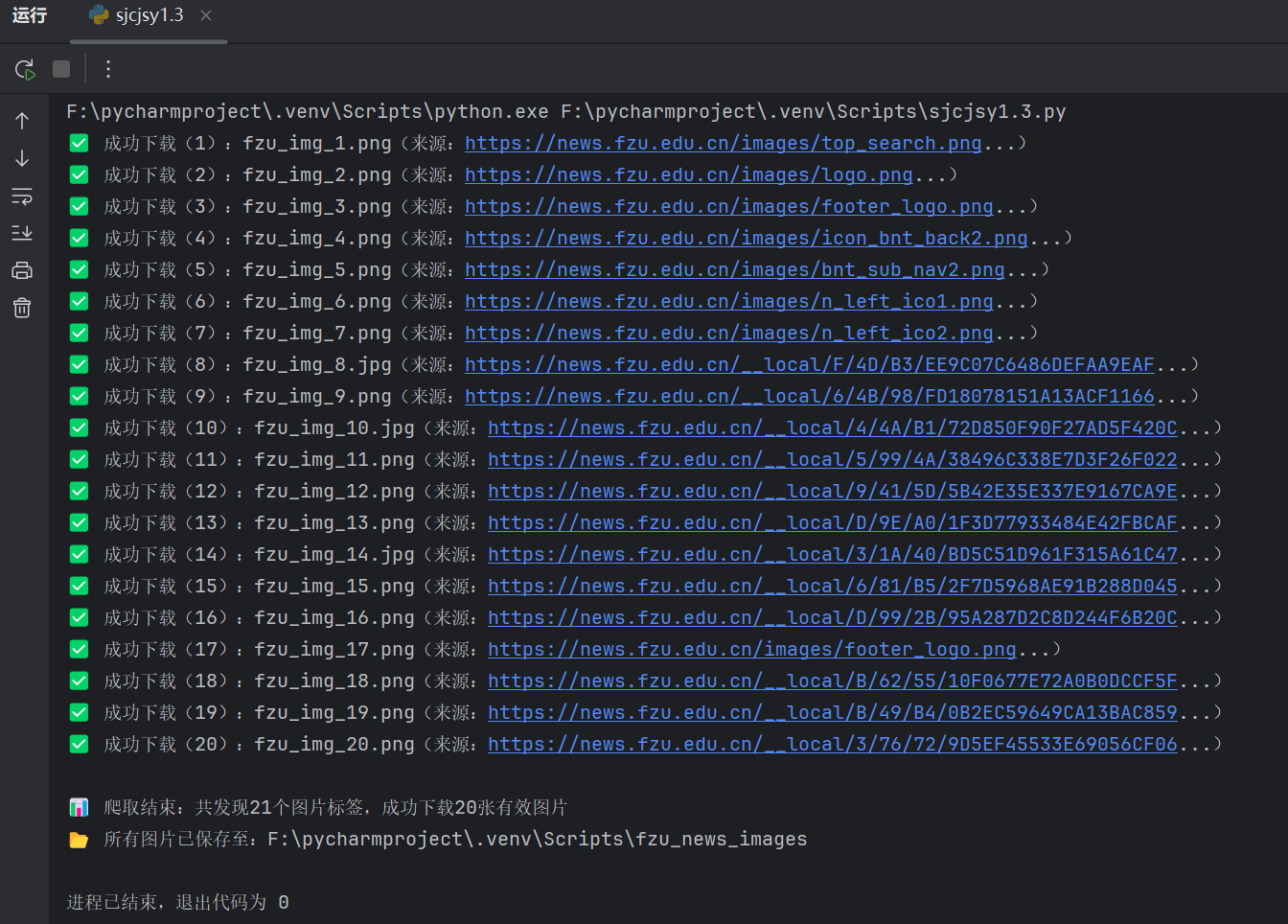
img_count += 1
print(f" 成功下载({img_count}):{img_filename}(来源:{img_full_url[:60]}...)")
except Exception as img_err:
print(f" 图片下载出错:{img_full_url},错误:{str(img_err)}")
# 5. 下载完成提示
print(f"\n 爬取结束:共发现{len(img_tags)}个图片标签,成功下载{img_count}张有效图片")
print(f" 所有图片已保存至:{os.path.abspath(save_dir)}")
except Exception as e:
print(f" 爬取过程出错:{str(e)}")
# 执行爬取
if __name__ == "__main__":
crawl_fzu_news_images()
运行结果:
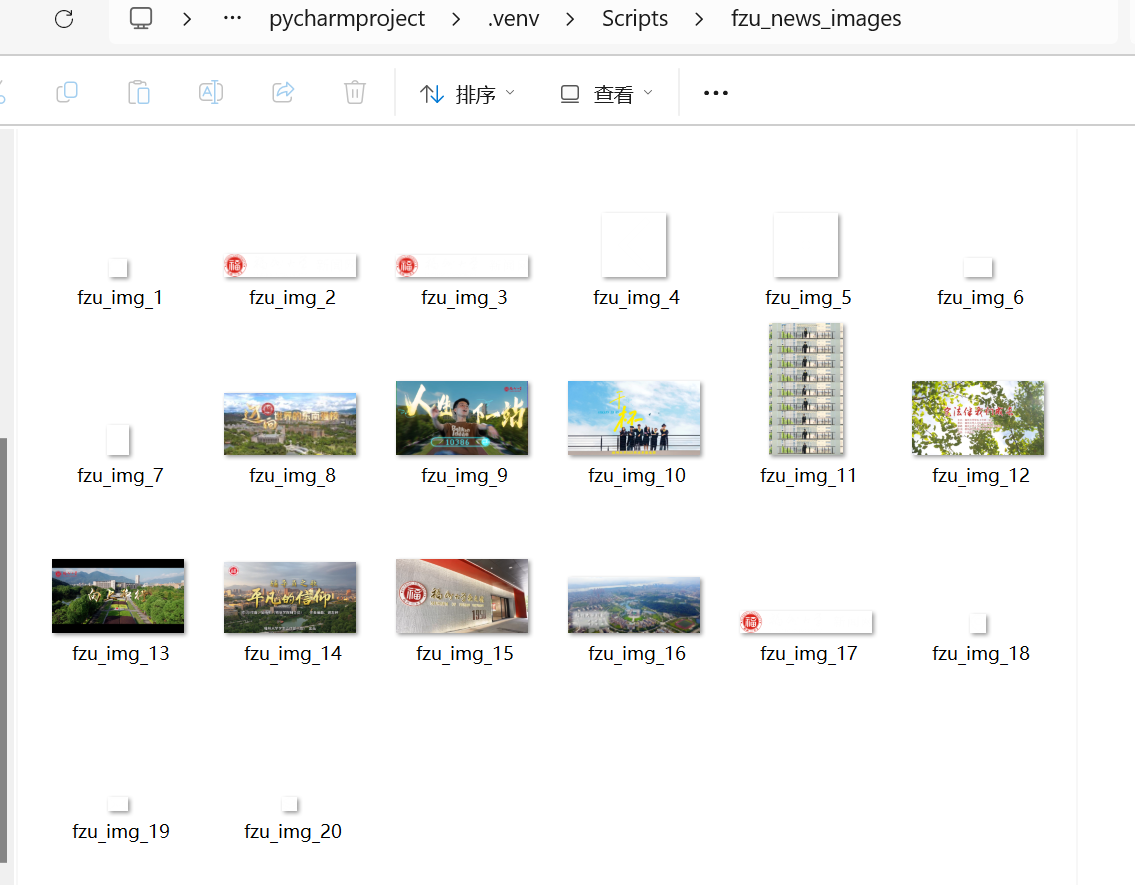
2)、心得体会
为避免文件名重复(如不同图片的原始文件名相同),代码用 “序号 + 原始文件名” 命名(如 img_1_xxx.jpg),确保每个文件唯一;同时将所有图片集中保存到指定文件夹,避免杂乱。这培养了我 “代码不仅要实现功能,还要注重输出的规范性和可维护性” 的意识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号