

python机器学习——点评评论分析
(一)选题背景:
随着广大用户“即需要、即外卖、即使用”的方便快捷的“外卖生活方式”的形成和普及,如今外卖行业不仅可以满足用户餐饮商品的在线即时购物需求,还可以满足饮食、水果、酒水饮料、家居日用、母婴用品、数码家电、服饰鞋包、美妆护肤、医药等各种品类商品。对于服务行业来说,好评、差评有什么作用呢?最直观的影响,就是后续客户的购买意愿或商家的名誉会受到影响。所以预测好差评对人们进行购物有着重要的意义。于是通过机器学习设计了一套程序用于判断好评、差评。
(二)机器学习设计案例:从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件打上标签,对数据进行预处理,并运用split分割数据,用贝叶斯模型建立训练模型,最后模型评估并验证。
(三)机器学习的实现步骤
数据来源:大众点评3W条评论数据(带标签)_数据集-阿里云天池 (aliyun.com)
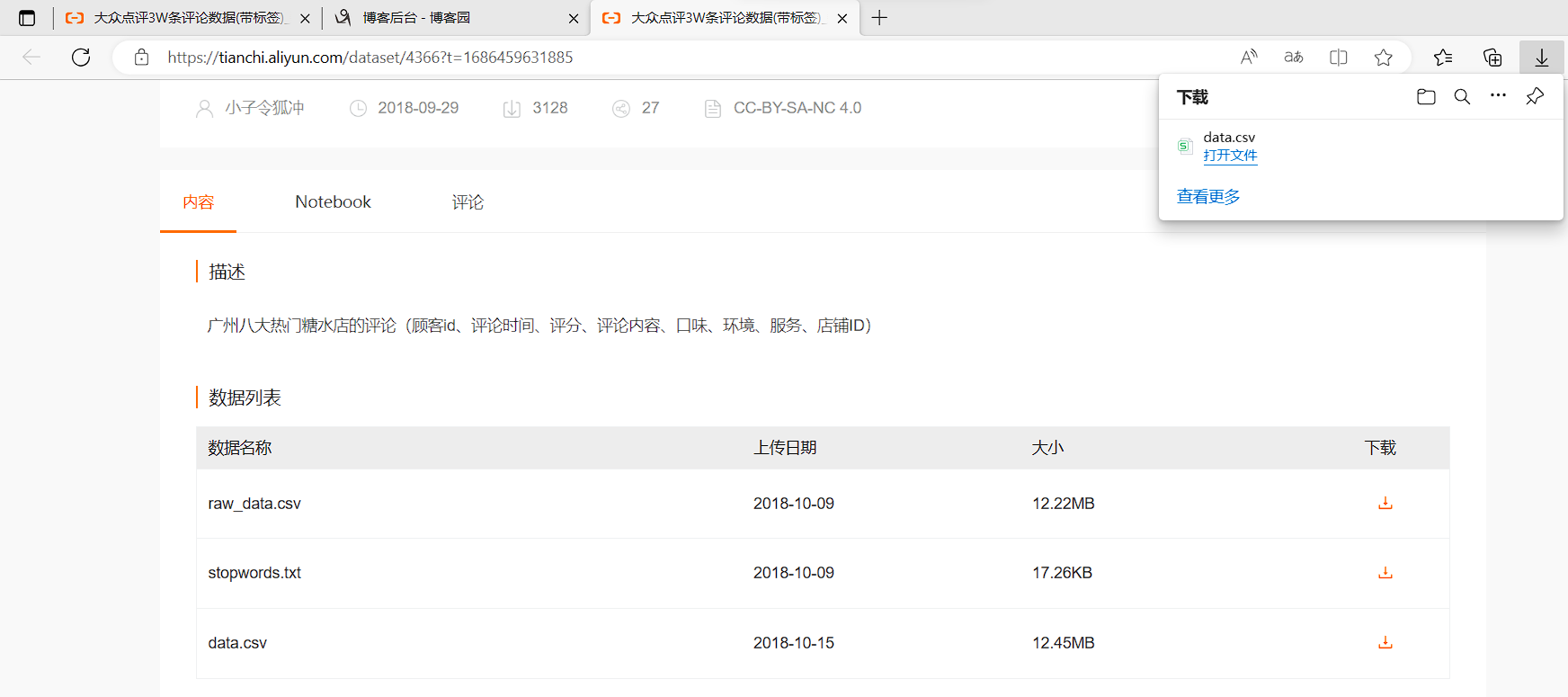

- 下载数据集
2.导入所需要的库
1 import numpy as np 2 import pandas as pd 3 from sklearn.model_selection import train_test_split 4 from sklearn.feature_extraction.text import TfidfVectorizer 5 from sklearn.naive_bayes import MultinomialNB 6 from sklearn.model_selection import cross_val_score 7 import jieba
1 """ 2 文本预测 3 4 得出信息: 5 - 行:32483条数据 缺失值:stars 跟cus_comment 6 - 列:14列 7 - 目标:stars 星级评分 8 - 特征:cus_comment:评价内容 ->> 词汇决定好评/差评 9 """ 10 dz_data = pd.read_csv("./data.csv") 11 dz_data.info() 12 dz_data.head()
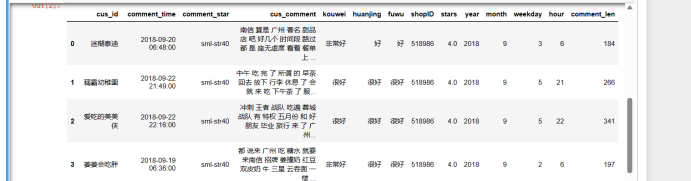
1
"""
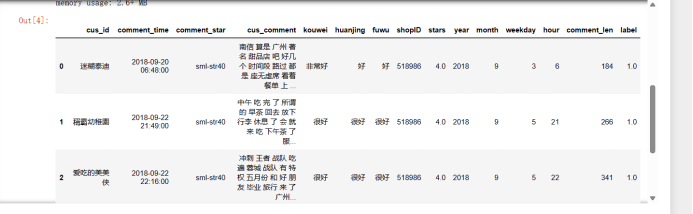
1-2:差评 --- >0 2 3 4-5:好评 --- >1 4 5 3:中评 --- >干扰干扰项! ---> np.nan
""" 6 7 rpl_data = {1.0:0, 2.0:0, 3.0:np.nan, 4.0:1, 5.0:1} #对目标值进行替换取代 8 9 dz_data["label"] = dz_data["stars"].map(rpl_data) 10 11 dz_data.info() 12 13 dz_data.head()

1 # 注意:删除缺失值 2 3 dz_data_2 = dz_data.dropna() 4 5 dz_data_2.info() 6 7 dz_data.head()
3.数据分割
1 from sklearn.model_selection import train_test_split 2# 特征 目标 3 4 x_train, x_test, y_train, y_test = train_test_split(dz_data_2["cus_comment"], dz_data_2["label"], random_state=3, test_size=0.25) 5 print(len(y_train)) 6 print(len(y_test)) 7 print(len(x_train)) 8 print(len(x_test))

1 x_train
1 #去除停用词 把没作用的词去除 2 3 f = open("stopwords.txt", encoding="utf-8") #使用停用词表 4 5 stop_words = f.readlines() 6 7 stop_words = [word.strip() for word in stop_words] 8 9 stop_words


1 #使用 tf-idf 进行文本处理用于信息检索与数据挖掘 2 3 from sklearn.feature_extraction.text import TfidfVectorizer 4 5 # ngram_range=(1,2) ->> 表示选取1-2个词作为组合方式 6 7 tf_idf = TfidfVectorizer(stop_words=stop_words, max_features=4000, ngram_range=(1,2)) 8 9 tf_idf.fit(x_train)

4.建立模型
1 #贝叶斯模型 2 3 from sklearn.naive_bayes import MultinomialNB 4 5 mt_cls = MultinomialNB() #实义化 6 7 mt_cls.fit(tf_idf.transform(x_train), y_train) #训练

模型评估
1 pred_proba = mt_cls.predict_proba(tf_idf.transform(x_test))[:,1] 2 pred_proba 3 mt_cls.score(tf_idf.transform(x_test), y_test)

看多次评分结果 ->> 交叉验证

5.测试模型
- 首先导入 jieba 库:
import jieba - 对需要分词的文本(test_s)进行分词处理,将分词结果用空格隔开并存储到列表中:
s_fenci = " ".join(list(jieba.cut(test_s))) - 将分词结果转换为 pandas.Series 格式:
s_fenci = pd.Series(s_fenci) - 将处理后的文本输入到模型中进行预测,并获取其概率值:
proba = model.predict_proba(tf_idf.transform(s_fenci))[:,1][0] jieba 的分词操作主要体现在第 2 行代码中的list(jieba.cut(test_s))这个部分。其中,jieba.cut(test_s)会将字符串 test_s 进行分词处理,并返回一个可迭代的生成器对象。list()函数则将其转换为列表格式,方便进行 join 操作
1 test1 = "感觉这边环境不是很好,但是,挺好吃的!好评!!!" 2 3 test2 = "这是我在长沙吃的最好的一顿,第一个上来的毛豆,配上灵魂酱汁YYDS。第二个豆花,也太好吃了把!花甲的汤汁也是无敌了" 4 5 test3 = "朋友说很好吃,抱有非常大的期望,但结果很失望!!一点都不好吃" 6 7 test4 = "差评!!。" 8 9 import jieba #用jieba进行分词 10 11 def pred(model, test_s): 12 13 s_fenci = " ".join(list(jieba.cut(test_s))) 14 15 s_fenci = pd.Series(s_fenci) 16 17 # print(s_fenci) 18 19 proba = model.predict_proba(tf_idf.transform(s_fenci))[:,1][0] 20 21 # print(proba) 22 23 return proba 24 25 print(f"test1预测为好评的概率是:{pred(mt_cls, test1)}") 26 27 print(f" 差评的概率是:{1-pred(mt_cls, test1)}") 28 29 print(f"test2预测为好评的概率是:{pred(mt_cls, test2)}") 30 31 print(f" 差评的概率是:{1-pred(mt_cls, test2)}") 32 33 print(f"test3预测为好评的概率是:{pred(mt_cls, test3)}") 34 35 print(f" 差评的概率是:{1-pred(mt_cls, test3)}") 36 37 print(f"test4预测为好评的概率是:{pred(mt_cls, test4)}") 38 39 print(f" 差评的概率是:{1-pred(mt_cls, test4)}")

差评测试中由于数据样本少,导致预测不准确
1 test5 = "感觉很一般吧,东西没听说的那么好吃,有点些东西是冷的,不太新鲜" 2 3 test6 = "一直网上看人说不错,但是我吃了没说的那么好吃,可能有点虚化了" 4 5 test7 = "垃圾垃圾垃圾别去" 6 7 test8 = "东西不新鲜是冷的" 8 9 print(f"test5预测为好评的概率是:{pred(mt_cls, test5)}") #结果极其不准确 10 11 print(f" 差评的概率是:{1-pred(mt_cls, test5)}") 12 13 print(f"test6预测为好评的概率是:{pred(mt_cls, test6)}") 14 15 print(f" 差评的概率是:{1-pred(mt_cls, test6)}") 16 17 print(f"test7预测为好评的概率是:{pred(mt_cls, test7)}") 18 19 print(f" 差评的概率是:{1-pred(mt_cls, test7)}") 20 21 print(f"test8预测为好评的概率是:{pred(mt_cls, test8)}") 22 23 print(f" 差评的概率是:{1-pred(mt_cls, test8)}")

解决办法:添加差评样本的数据,复制差评信息使得与好评信息量基本一致
1 dz_data_2["label"].value_counts() 2 3 # 获取目标为0的目标数据 4 5 y_lower = y_train[y_train==0] 6 7 # 获取目标为0的特征数据 8 9 x_lower = x_train[y_train==0] 10 11 x_lower 12 13 y_lower
1 y_train_2 = y_train 2 3 x_train_2 = x_train 4 5 #追加十次 6 7 for count in range(10): 8 9 y_train_2 = y_train_2.append(y_lower) 10 11 x_train_2 = x_train_2.append(x_lower) 12 13 y_train_2.value_counts() #好评与差评数量一致

采用重构训练集训练
1 mt_cls_2 = MultinomialNB() 2 mt_cls_2.fit(tf_idf.transform(x_train_2), y_train_2)

#模型预测
1 pred_proba_2 = mt_cls_2.predict_proba(tf_idf.transform(x_test))[:,1] 2 pred_proba_2

#模型评分
1 mt_cls_2.score(tf_idf.transform(x_test), y_test)

多次验证
1 print(f"test5预测为好评的概率是:{pred(mt_cls_2, test1)}") 2 3 print(f" 差评的概率是:{1-pred(mt_cls_2, test1)}") 4 5 print(f"test6预测为好评的概率是:{pred(mt_cls_2, test2)}") 6 7 print(f" 差评的概率是:{1-pred(mt_cls_2, test2)}") 8 9 print(f"test7预测为好评的概率是:{pred(mt_cls_2, test3)}") 10 11 print(f" 差评的概率是:{1-pred(mt_cls_2, test3)}") 12 13 print(f"test8预测为好评的概率是:{pred(mt_cls_2, test4)}") 14 15 print(f" 差评的概率是:{1-pred(mt_cls_2, test4)}")
#结果准确

1 test5 = "感觉很一般吧,东西没听说的那么好吃,有点些东西是冷的,不太新鲜" 2 test6 = "一直网上看人说不错,但是我吃了没说的那么好吃,可能有点虚化了" 3 test7 = "垃圾垃圾垃圾别去" 4 test8 = "东西不新鲜是冷的" 5 print(f"test5预测为好评的概率是:{pred(mt_cls_2, test5)}") #结果准确 6 print(f" 差评的概率是:{1-pred(mt_cls_2, test5)}") 7 print(f"test6预测为好评的概率是:{pred(mt_cls_2, test6)}") 8 print(f" 差评的概率是:{1-pred(mt_cls_2, test6)}") 9 print(f"test7预测为好评的概率是:{pred(mt_cls_2, test7)}") 10 print(f" 差评的概率是:{1-pred(mt_cls_2, test7)}") 11 print(f"test8预测为好评的概率是:{pred(mt_cls_2, test8)}") 12 print(f" 差评的概率是:{1-pred(mt_cls_2, test8)}")

(四)总结
收获:机器学习就是从数据中挖掘出有价值的信息,数据本身是无意识的,它不能自动呈现出有用的信息。要给数据一个抽象的表示,接着基于表示进行建模,然后估计模型的参数,也就是计算;了应对大规模的数据所带来的问题,我们还需要设计一些高效的实现手段,包括硬件层面和算法层面。
改进建议:可以进行多次训练和添加更多的数据集来提高机器的判断正确率
全代码:
1 import numpy as np 2 3 import pandas as pd 4 5 from sklearn.model_selection import train_test_split 6 7 from sklearn.feature_extraction.text import TfidfVectorizer 8 9 from sklearn.naive_bayes import MultinomialNB 10 11 from sklearn.model_selection import cross_val_score 12 13 import jieba 14 15 16 """ 17 文本预测 18 19 得出信息: 20 - 行:32483条数据 缺失值:stars 跟cus_comment 21 - 列:14列 22 - 目标:stars 星级评分 23 - 特征:cus_comment:评价内容 ->> 词汇决定好评/差评 24 """ 25 26 dz_data = pd.read_csv("./某点评评论.csv") #使用 pd.read_csv() 方法读取文件中的数据 27 28 dz_data.info() 29 30 dz_data.head() 31 #使用 dz_data.info() 和 dz_data.head() 等方法查看数据信息和前面几行数据 32 33 """ 34 1-2:差评 --- >0 35 4-5:好评 --- >1 36 3:中评 --- >干扰干扰项! ---> np.nan 37 """ 38 39 rpl_data = {1.0:0, 2.0:0, 3.0:np.nan, 4.0:1, 5.0:1} #对目标值进行替换取代 40 41 dz_data["label"] = dz_data["stars"].map(rpl_data) 42 43 dz_data.info() 44 45 dz_data.head() 46 47 # 注意:删除缺失值 48 49 dz_data_2 = dz_data.dropna() 50 51 dz_data_2.info() 52 53 dz_data.head() 54 55 from sklearn.model_selection import train_test_split #使用 train_test_split() 方法将数据划分成训练集和测试集 56 57 # 特征 目标 58 59 x_train, x_test, y_train, y_test = train_test_split(dz_data_2["cus_comment"], dz_data_2["label"], random_state=3, test_size=0.25) 60 61 print(len(y_train)) 62 63 print(len(y_test)) 64 65 print(len(x_train)) 66 67 print(len(x_test)) 68 69 f = open("stopwords.txt", encoding="utf-8") #使用停用词表 70 71 stop_words = f.readlines() 72 73 stop_words = [word.strip() for word in stop_words] 74 75 stop_words 76 77 print(len(stop_words)) 78 79 #使用 tf-idf 进行文本处理 80 81 from sklearn.feature_extraction.text import TfidfVectorizer 82 83 # ngram_range=(1,2) ->> 表示选取1-2个词作为组合方式 84 85 tf_idf = TfidfVectorizer(stop_words=stop_words, max_features=4000, ngram_range=(1,2)) #使用 TfidfVectorizer() 方法实现文本特征提取 86 87 # fit ->> 训练 88 89 # transform ->> 转换数据 90 91 # fit_transform ->> 训练&转换数据 92 93 tf_idf.fit(x_train) 94 95 from sklearn.naive_bayes import MultinomialNB #采用贝叶斯模型 96 97 mt_cls = MultinomialNB() #实例化 98 99 mt_cls.fit(tf_idf.transform(x_train), y_train) #训练 100 101 # 好评差评的概率 102 103 pred_proba = mt_cls.predict_proba(tf_idf.transform(x_test))[:,1] 104 105 pred_proba 106 107 #模型评分 108 109 mt_cls.score(tf_idf.transform(x_test), y_test) 110 111 from sklearn.model_selection import cross_val_score 112 113 scores = cross_val_score(mt_cls, tf_idf.transform(x_test), y_test, cv=10) 114 115 np.mean(scores) #多测预测取平均值 116 117 test1 = "感觉这边环境不是很好,但是,挺好吃的!好评!!!" 118 119 test2 = "这是我在长沙吃的最好的一顿,第一个上来的毛豆,配上灵魂酱汁YYDS。第二个豆花,也太好吃了把!花甲的汤汁也是无敌了" 120 121 test3 = "朋友说很好吃,抱有非常大的期望,但结果很失望!!一点都不好吃" 122 123 test4 = "差评!!。" 124 125 import jieba 126 # 注意1:test系列没有做分词处理 ->> 以空格连接词语为一整个字符串 127 128 # 注意2:处理完后,进行tf-idf处理 129 130 # 注意3:预测得到概率 131 132 def pred(model, test_s): 133 134 s_fenci = " ".join(list(jieba.cut(test_s))) 135 136 s_fenci = pd.Series(s_fenci) 137 138 # print(s_fenci) 139 140 proba = model.predict_proba(tf_idf.transform(s_fenci))[:,1][0] 141 142 # print(proba) 143 144 return proba 145 146 print(f"test1预测为好评的概率是:{pred(mt_cls, test1)}") 147 148 print(f" 差评的概率是:{1-pred(mt_cls, test1)}") 149 150 print(f"test2预测为好评的概率是:{pred(mt_cls, test2)}") 151 152 print(f" 差评的概率是:{1-pred(mt_cls, test2)}") 153 154 print(f"test3预测为好评的概率是:{pred(mt_cls, test3)}") 155 156 print(f" 差评的概率是:{1-pred(mt_cls, test3)}") 157 158 print(f"test4预测为好评的概率是:{pred(mt_cls, test4)}") 159 160 print(f" 差评的概率是:{1-pred(mt_cls, test4)}") 161 162 #差评测试 163 164 test5 = "感觉很一般吧,东西没听说的那么好吃,有点些东西是冷的,不太新鲜" 165 166 test6 = "一直网上看人说不错,但是我吃了没说的那么好吃,可能有点虚化了" 167 168 test7 = "垃圾垃圾垃圾别去" 169 170 test8 = "东西不新鲜是冷的" 171 172 dz_data_2["label"].value_counts() 173 174 # 获取目标为0的目标数据 175 176 y_lower = y_train[y_train==0] 177 178 # 获取目标为0的特征数据 179 180 x_lower = x_train[y_train==0] 181 182 x_lower 183 184 y_lower 185 186 y_train_2 = y_train 187 188 x_train_2 = x_train 189 190 #追加十次 191 192 for count in range(10): 193 194 y_train_2 = y_train_2.append(y_lower) 195 196 x_train_2 = x_train_2.append(x_lower) 197 198 y_train_2.value_counts() #好评与差评数量一致 199 200 mt_cls_2 = MultinomialNB() #采用重构训练集训练 201 202 mt_cls_2.fit(tf_idf.transform(x_train_2), y_train_2) 203 204 #模型预测 205 206 pred_proba_2 = mt_cls_2.predict_proba(tf_idf.transform(x_test))[:,1] 207 208 pred_proba_2 209 210 #模型评分 211 212 mt_cls_2.score(tf_idf.transform(x_test), y_test) 213 214 from sklearn.model_selection import cross_val_score 215 216 scores = cross_val_score(mt_cls_2, tf_idf.transform(x_test), y_test, cv=10) #使用新的训练集重新构建模型 mt_cls_2,进行预测并展示模型评分和预测结果 217 218 np.mean(scores) #多测预测取平均值 219 220 print(f"test5预测为好评的概率是:{pred(mt_cls_2, test1)}") #结果准确 221 222 print(f" 差评的概率是:{1-pred(mt_cls_2, test1)}") 223 224 print(f"test6预测为好评的概率是:{pred(mt_cls_2, test2)}") 225 226 print(f" 差评的概率是:{1-pred(mt_cls_2, test2)}") 227 228 print(f"test7预测为好评的概率是:{pred(mt_cls_2, test3)}") 229 230 print(f" 差评的概率是:{1-pred(mt_cls_2, test3)}") 231 232 print(f"test8预测为好评的概率是:{pred(mt_cls_2, test4)}") 233 234 print(f" 差评的概率是:{1-pred(mt_cls_2, test4)}") 235 236 test5 = "感觉很一般吧,东西没听说的那么好吃,有点些东西是冷的,不太新鲜" 237 238 test6 = "一直网上看人说不错,但是我吃了没说的那么好吃,可能有点虚化了" 239 240 test7 = "垃圾垃圾垃圾别去" 241 242 test8 = "东西不新鲜是冷的" 243 244 #再次预测 245 246 print(f"test5预测为好评的概率是:{pred(mt_cls_2, test5)}") #结果准确 247 248 print(f" 差评的概率是:{1-pred(mt_cls_2, test5)}") 249 250 print(f"test6预测为好评的概率是:{pred(mt_cls_2, test6)}") 251 252 print(f" 差评的概率是:{1-pred(mt_cls_2, test6)}") 253 254 print(f"test7预测为好评的概率是:{pred(mt_cls_2, test7)}") 255 256 print(f" 差评的概率是:{1-pred(mt_cls_2, test7)}") 257 258 print(f"test8预测为好评的概率是:{pred(mt_cls_2, test8)}") 259 260 print(f" 差评的概率是:{1-pred(mt_cls_2, test8)}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号