今日总结
一、正则表达式前戏
二、正则表达式字符串
三、正则表达式特殊符号
四、正则表达式量词
五、复杂正则编写
六、正则表达式取消转义
七、贪婪匹配与非贪婪匹配
八、python内置模块之re模块
一、正则表达式前戏
模拟京东注册页面获取手机号
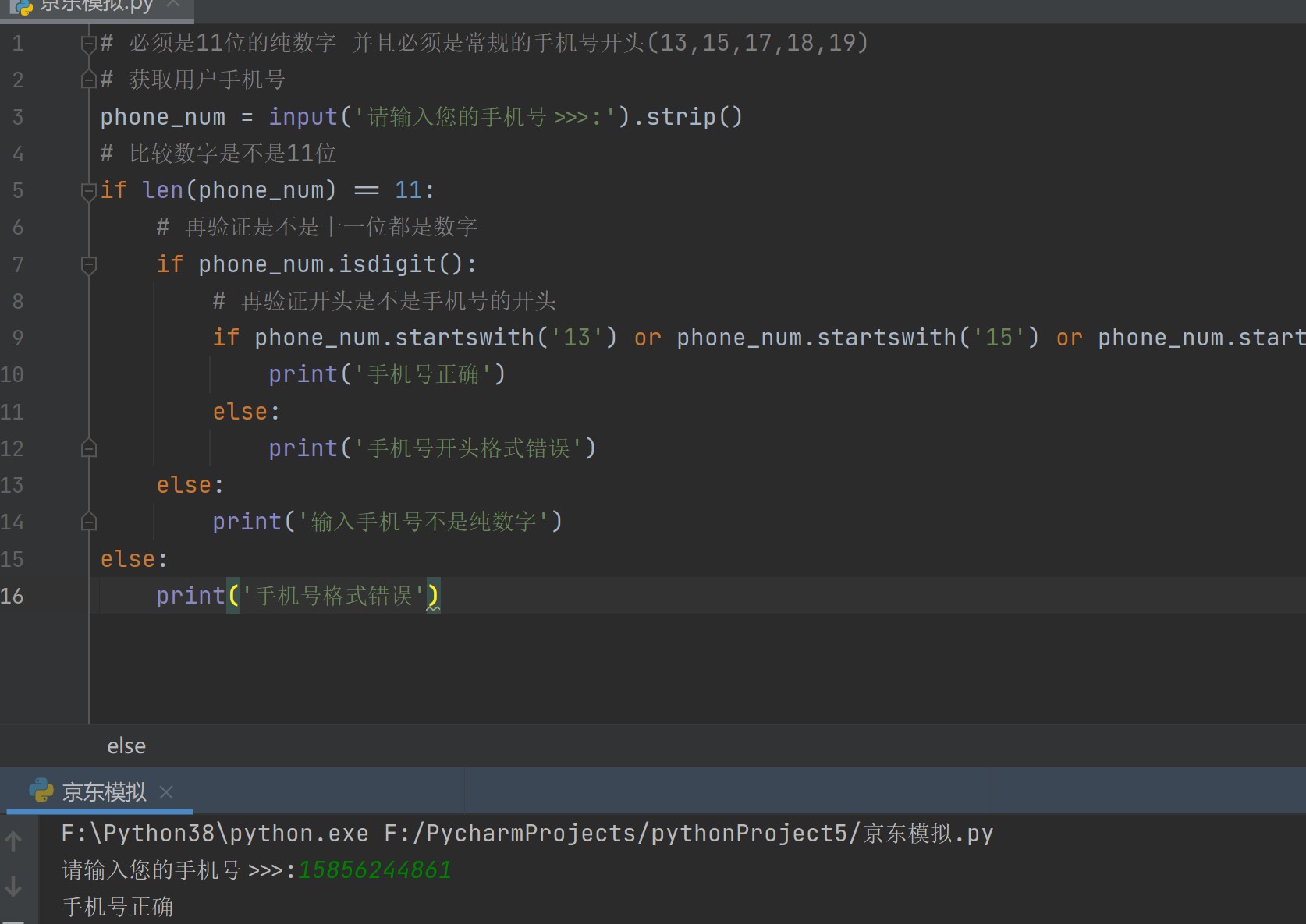
# 手机号必须为11位纯数字,并且常规手机号开头位(13, 14, 15, 17, 18, 19)
# 上面条件使用python代码书写
# 获取用户手机号
phone_num = input('please input your phone number>>>:').strip()
# 比较数字是不是11位
if len(phone_num) == 11:
# 再验证是不是十一位都是数字
if phone_num.isdigit():
# 再验证开头是不是手机号的开头
if phone_num.startswith('13') or phone_num.startswith('15') or phone_num.startswith('17') or phone_num.startswith('18')or phone_num.startswith('19'):
print('手机号正确')
else:
print('手机号开头格式错误')
else:
print('输入手机号不是纯数字')
else:
print('手机号格式错误')
# 使用正则表达式
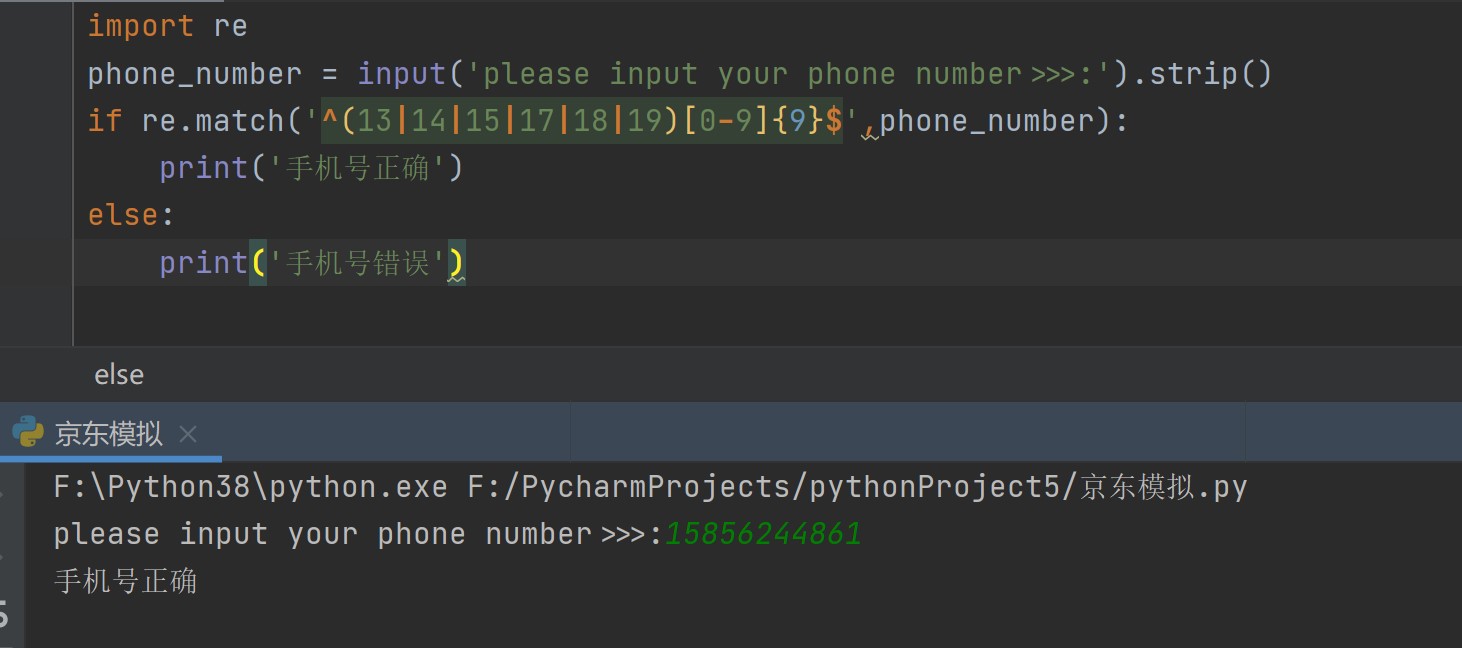
import re
phone_number = input('please input your phone number>>>:').strip()
if re.match('^(13|14|15|17|18|19)[0-9]{9}$',phone_number):
print('手机号正确')
else:
print('手机号错误')
"""
正则表达式是一门独立的语言,用来匹配、校验、筛查、所需要的数据,
任何编程语言都可以使用正则,在python中直接使用内置模块re
"""
二、正则表达式之字符串
在线测试正则测试网站:
http://tool.chinaz.com/regex/
''' 单个字符串组默认一次匹配一个字符 '''
[0123456789]——匹配0到9之间的任意一个数字
[0-9]——匹配0到9之间的任意一个数字(简写)
[a-z]——匹配a到z之间的任意一个小写字母
[A-Z]——匹配A到Z之间的任意一个大写字母
[0-9a-zA-Z]——匹配任意一个数字或者大小写字母(没有顺序)
三、正则表达式之特殊符号
# 特殊符号默认一次匹配一个字符
. —— 匹配除换行符以外的任意字符
\w(小写w) —— 匹配数字、字母、下划线(筛选变量名)
\d —— 匹配任意的数字
\t —— 匹配一个制表符(tab键)
^(上尖号) —— 匹配字符串的开始位置,像startswith
$(dollar) —— 匹配字符串的结尾像endswith
\W(大写W) —— 匹配非字母或数字或下划线
\D —— 匹配非数字
a|b —— 匹配a或b,管道符就是or的意思
() —— 给正则表达式分组 不影响正则匹配
[] —— 字符组的概念(里面所有的数据都是或的关系)
[^] —— 上箭号出现在了中括号的里面意思是取反操作
四、正则表达式之量词
""" 量词必须在表达式后面,不能单独使用,用来增加匹配的字符数"""
* —— 重复零次或者多次(默认就是多次:越多越好)
+ —— 重复一次或者多次(默认就是多次:越多越好)
? —— 重复零次或者一次(默认就是一次:越多越好)
{n} —— 重复n次
{n,} —— 重复最少n次最多多次(越多越好)
{n,m} —— 重复n到m次(越多越好)
五、复杂正则的编写
# 校验用户身份证号码
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x
^[1-9][0-9]{14}
^[1-9][0-9]{16}[0-9x]
我们可上网查找别人写好的,就是要知道什么意思
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
六、正则表达式取消转义
\n \n False
\\n \n True
\\\\n \\n True
在python中在字符串前面加r直接取消转义
七、贪婪匹配与非贪婪匹配
# 正则 # 待匹配的数 # 结果
<.*> —— <script>alert(123)<script> —— 1条
贪婪匹配就是取到最后一个括号结束
<.*?> —— <script>alert(123)<script> —— 2条
非贪婪匹配就是第一个括号结束为结尾
量词默认都是贪婪匹配 如果想修改为非贪婪匹配 只需要在量词的后面加?即可
贪婪非贪婪通常都是利用左右两边的条件作为筛选依据
八、python内置模块之re模块
在python里面无法直接使用正则,所以需要借助于模块来使用
1、内置的re模块
2、第三方的其他模块
# 调用re模块
import re
# findall
res = re.findall('a', 'abababa') # findall(正则表达式,待匹配的文本)
print(res) # ['a', 'a', 'a', 'a'] 结果符合条件的数据,组织成列表
# search
res = re.search('a', 'oboboba') # search(正则,待匹配文本)
print(res.group()) # a
res = re.search('a', 'obobob') # search(正则,待匹配文本)
print(res) # None 没有符合条件的数据返回None
# match
res = re.match('a', 'oabaonm') # match(正则表达式,待匹配的文本)
print(res) # None 从字符串的开头匹配 如果没有则直接返回None 类似于给正则自动加了^ 如果符合也只获取一个就结束
res = re.match('a', 'aoabaonm')
print(res.group()) # a 没有则无法调用group() 直接报错
# finditer
res = re.finditer('a', 'jhasgafadsda') # finditer(正则表达式,待匹配的文本)
print(res) # 结果是一个迭代器对象 为了节省空间
print([obj.group() for obj in res]) # ['a', 'a', 'a', 'a']
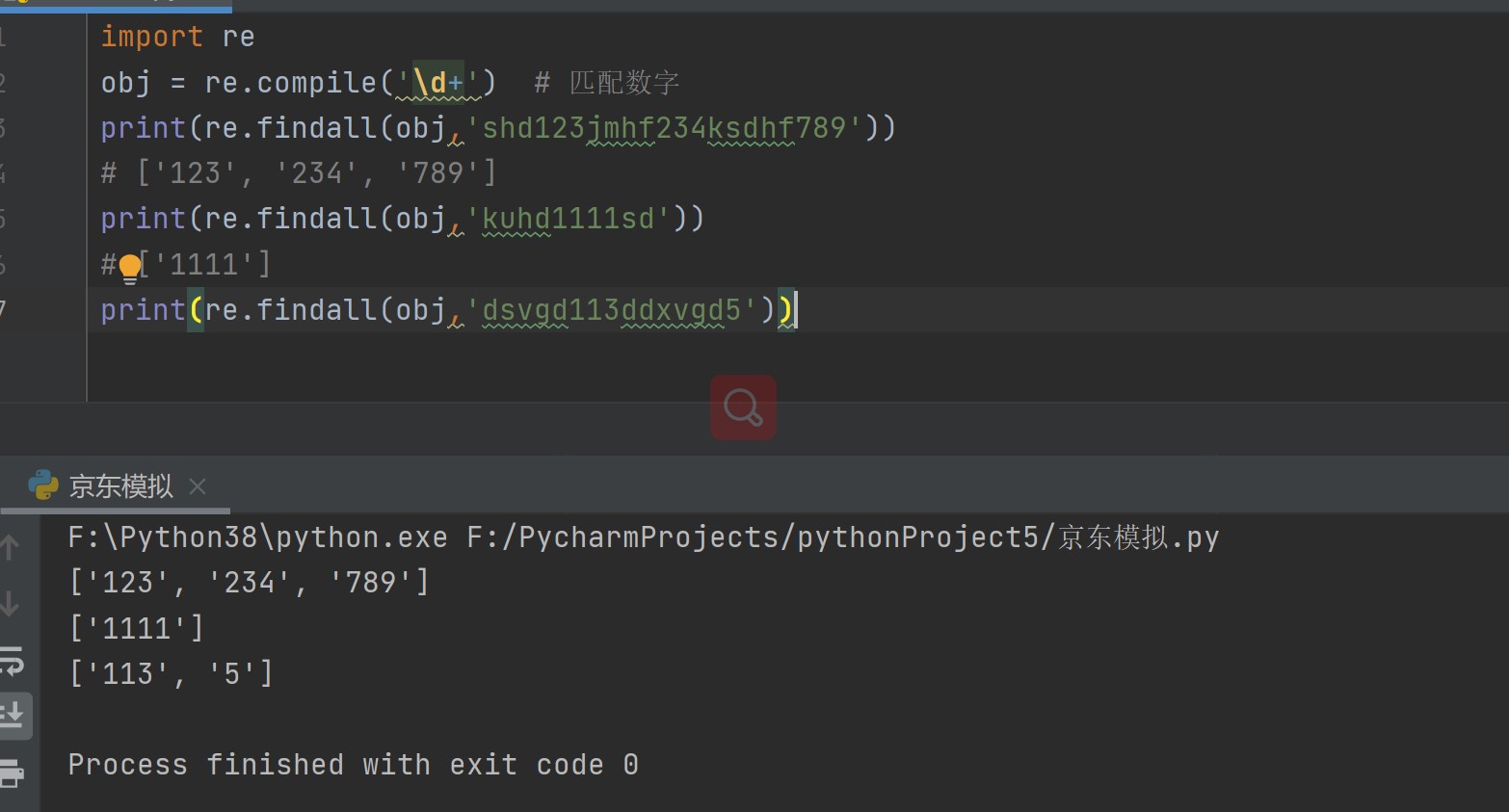
obj = re.compile('\d+') # 匹配数字
print(re.findall(obj,'shd123jmhf234ksdhf789'))
# ['123', '234', '789']
print(re.findall(obj,'kuhd1111sd'))
# ['1111']
print(re.findall(obj,'dsvgd113ddxvgd5'))
# ['113', '5']
# 反复调用即可


 浙公网安备 33010602011771号
浙公网安备 33010602011771号