今日总结
一 、生成器对象(自定义迭代器)
二 、yield关键字作用
三、自定义range方法
四 、生成器表达式
五 、模块简介
六 、导入模块的两种方式
七 、导入句式的补充说明
一、生成器对象
本质:和迭代器一样,只不过生成器是我们自己写的,里面也有__iter__和__next__方法
eg:
def index():
yield 111 # yield具有返回值和结束运行的功能,和return有点像
""" 生成器对象也可以节省存储空间,特性与迭代器对象一样,当函数体代码中含有yield关键字,第一次调用函数并不会执行函数体代码,而是将函数变成一个生成器 """
yield 222
yield 333
print(index) # <function index at 0x000002634B43D430> 没有被调用时,就是一个函数
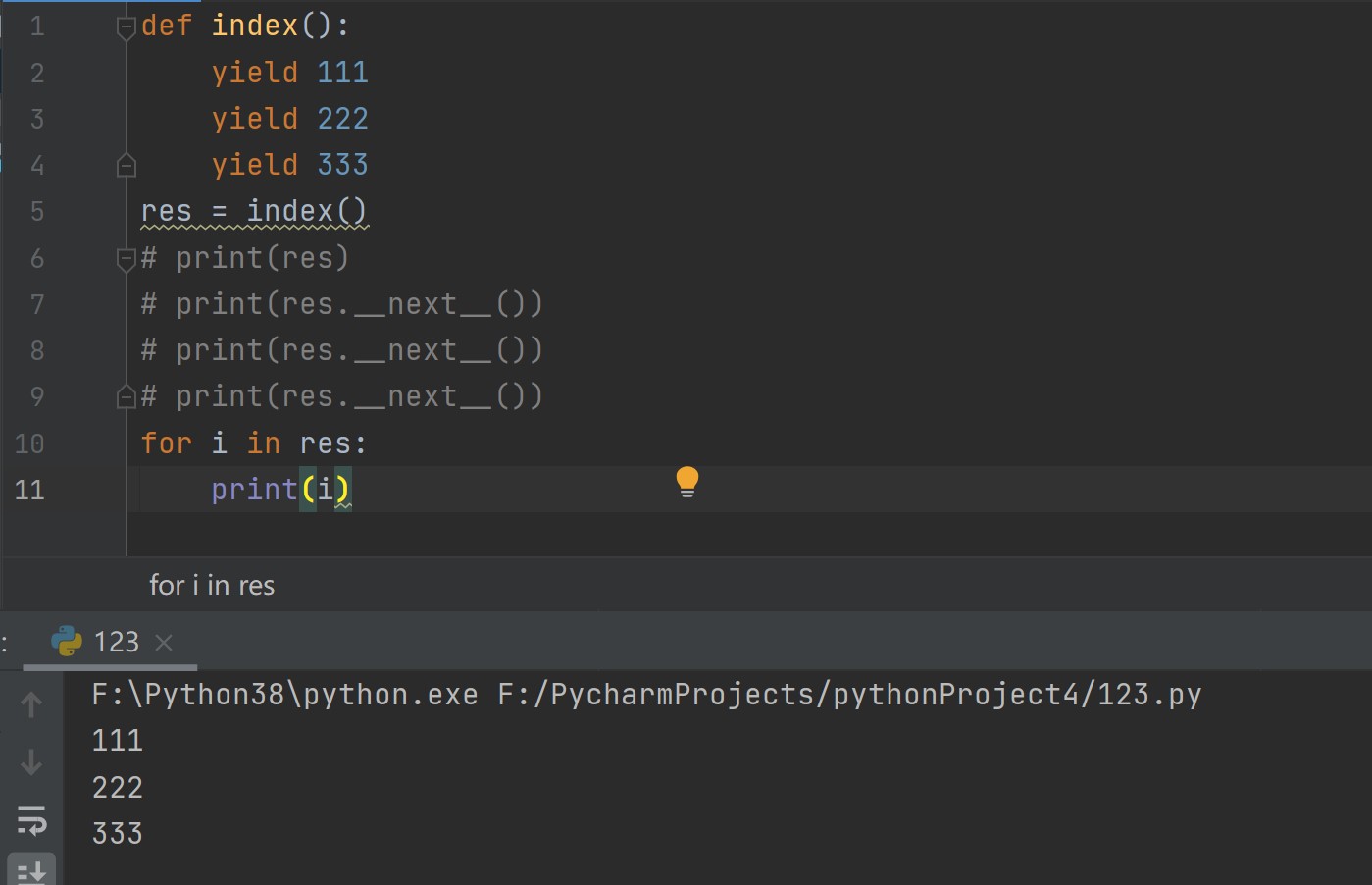
res = index()
print(res) # <generator object index at 0x000001BBCD32BB30> 变成了生成器,如果想要获取里面的值,通过__next__()调用
print(res.__next__()) # 111 yield 返回后面的值之后,结束运行
"""
如果函数体代码含有好几个yield关键字时,执行一次双下next返回后面的值,并且让代码停留再yield位置
再次执行就会从上次停留的位置,执行到下一个yield位置,当值被取完,再取的话就会报错
"""
for i in res:
print(i)
二、yield关键字作用
作用:
1、在函数体代码中,可以将函数变成生成器
2、执行时,将后面的值放回出去、类似return
3、还可以暂停代码运行
4、还能接收外面的传值
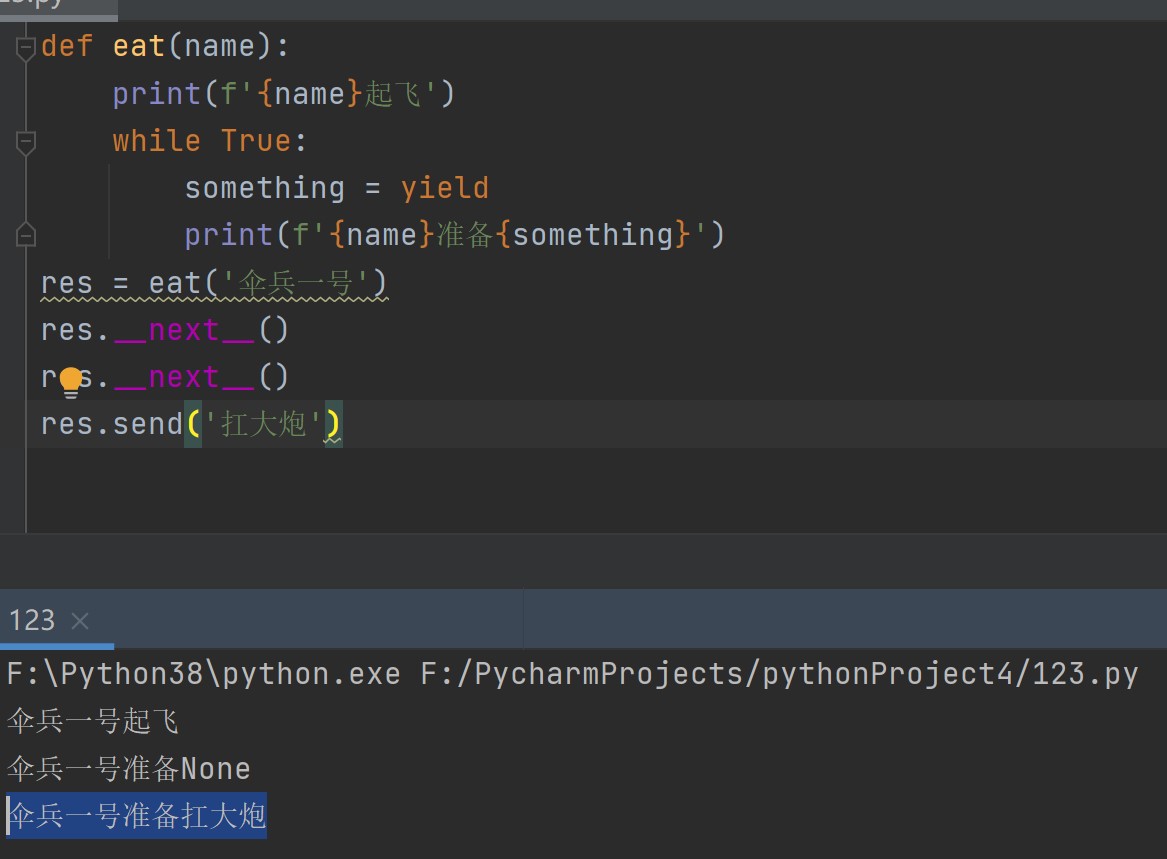
def eat(name):
print(f'{name}起飞')
while True:
something = yield
print(f'{name}准备{something}')
res = eat('伞兵一号')
res.__next__() # 伞兵一号起飞
res.__next__() # 伞兵一号准备None
res.send('扛大炮') # 伞兵一号准备扛大炮 使用send给yield传值,并且会自动调用__next__方法
三、自定义range方法
# range方法其实就是一个可迭代对象
使用公式:
def my_range():
pass
for i in my_range(0, 10):
print(i)
书写:
# start是起始位置,end为终点位置,step为步长默认为1
def my_range(start, end=None, step=1):
# 当没有给end传值
if not end:
end = start
start = 0
# 当第一个参数没有第二个大
while start < end:
# 返回第一个参数
yield start
# 每次循环增加一个步长数
start += step
for i in my_range(1, 10):
print(i) # 1 2 3 4 5 6 7 8 9
# 当只有一个列表时
end 可以不传值,应该设置成一个人默认函数,end=None
end = start
start = 0
# 当有两个数的时候,步长step默认1
四、生成器表达式
# 在做代码优化时,可以使用
表达式为:
res = (i for i in 'owen') # 里面的值自定义
print(res) # <generator object <genexpr> at 0x0000021DEF13BB30> 生成器模式
#使用双下next调用
print(res.__next__()) # o
1 、生成器练习题
def add(n, i):
return n + i
def test():
for i in range(4):
yield i
# 把nest函数变成生成器对象
g = test()
for n in [1, 10]:
g = (add(n, i) for i in g)
""" 当第一次for循环时
g = (add(n, i) for i in g)
当第二次for循环时
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g) # list 底层就是for循环,相当于对g迭代取值操作
print(res)
A. res=[10,11,12,13]
B. res=[11,12,13,14]
C. res=[20,21,22,23]
D. res=[21,22,23,24]
选 c
五、模块简介
eg:
import time 导入模块
time.time() 调用方法
1、模块的含义
模块就是已经封装好了的功能体,可以直接使用
2、用模块的好处
提升开发效率
3、模块的三种来源
3.1 内置的模块
不需要下载,解释器里面自带,直接导入使用即可
3.2 自定义模块
自己动手写的代码,封装成模块,自己用或者分享大家一起用
3.3 第三方模块
别人发到网上的,直接下载使用的模块
4、模块的四种表达形式
# 4.1 使用python代码编写的的py文件
# 4.2 多个py文件组成的文件夹(包)
4.3 已被编译为共享库或者DLL的c或C++扩展
4.4 使用C编写并链接到python解释器的内置模块
六、模块的两种导入方式
1、import...句式
eg:
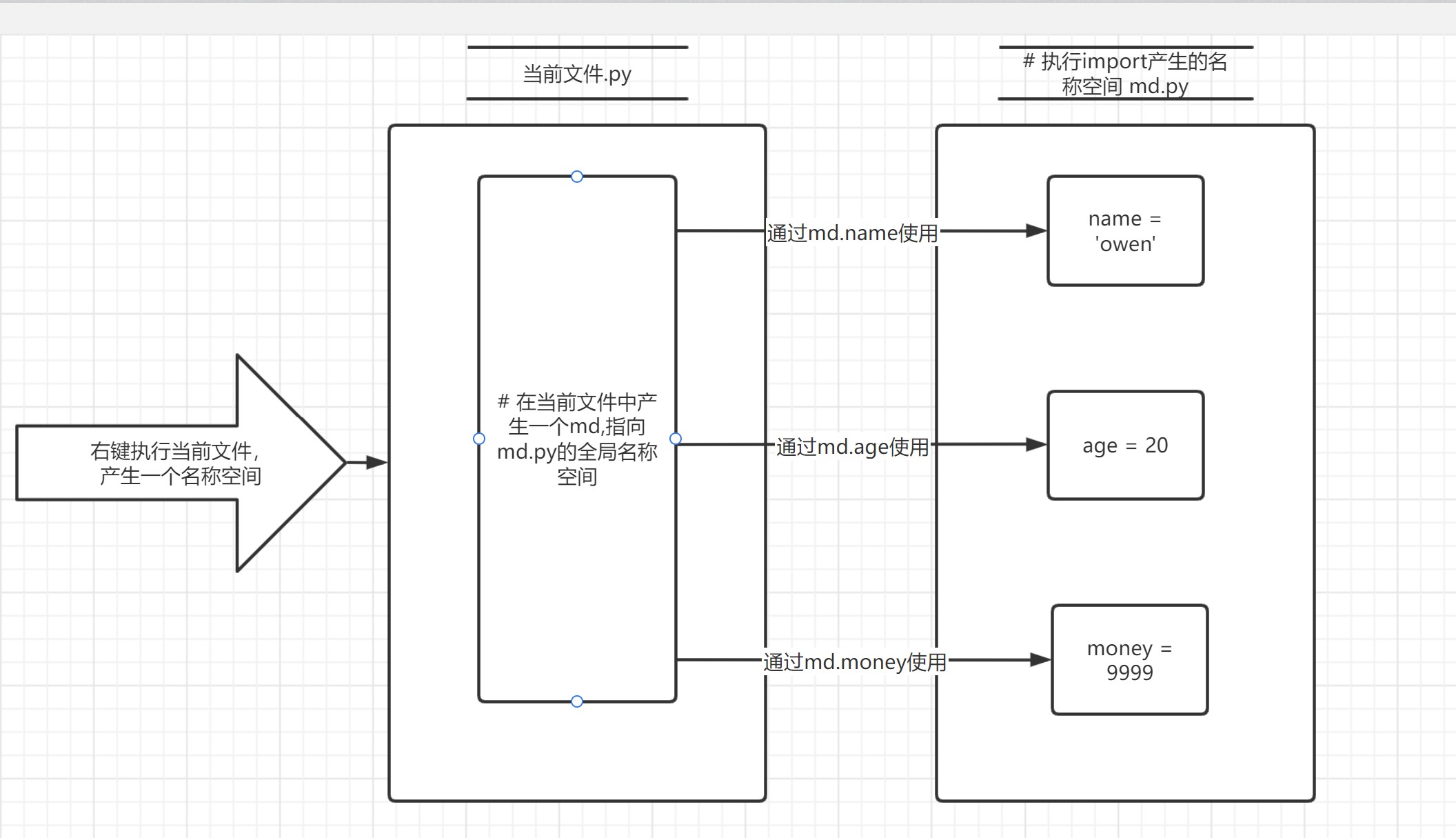
import md
print(md.name)
一定要分清楚那个执行文件,那个是被导入文件(模块)
模块简介.py是执行文件 md.py是被导入文件(模块)
导入模块内部发生了什么
1、执行当前文件,产生一个当前文件的名称空间
2、执行import句式,导入模块文件(就是执行模块文件代码产生模块文件的名称空间)
3、在当前文件的名称空间中产生一个模块的名字,指向模块的名称空间
4、通过这个名字就能够使用这个模块空间中所有数据
import md # 可以执行
import md # 不能执行了
# 所以相同的模块反复被导入只会执行一次
import句式的特点:
可以通过import后面的模块名+点的方式,使用模块所有的名字,并且不会与当前名称空间中的名字发生冲突
import md
money = 9999999
md.change()
print(money) # 9999999
2 、from...import...句式
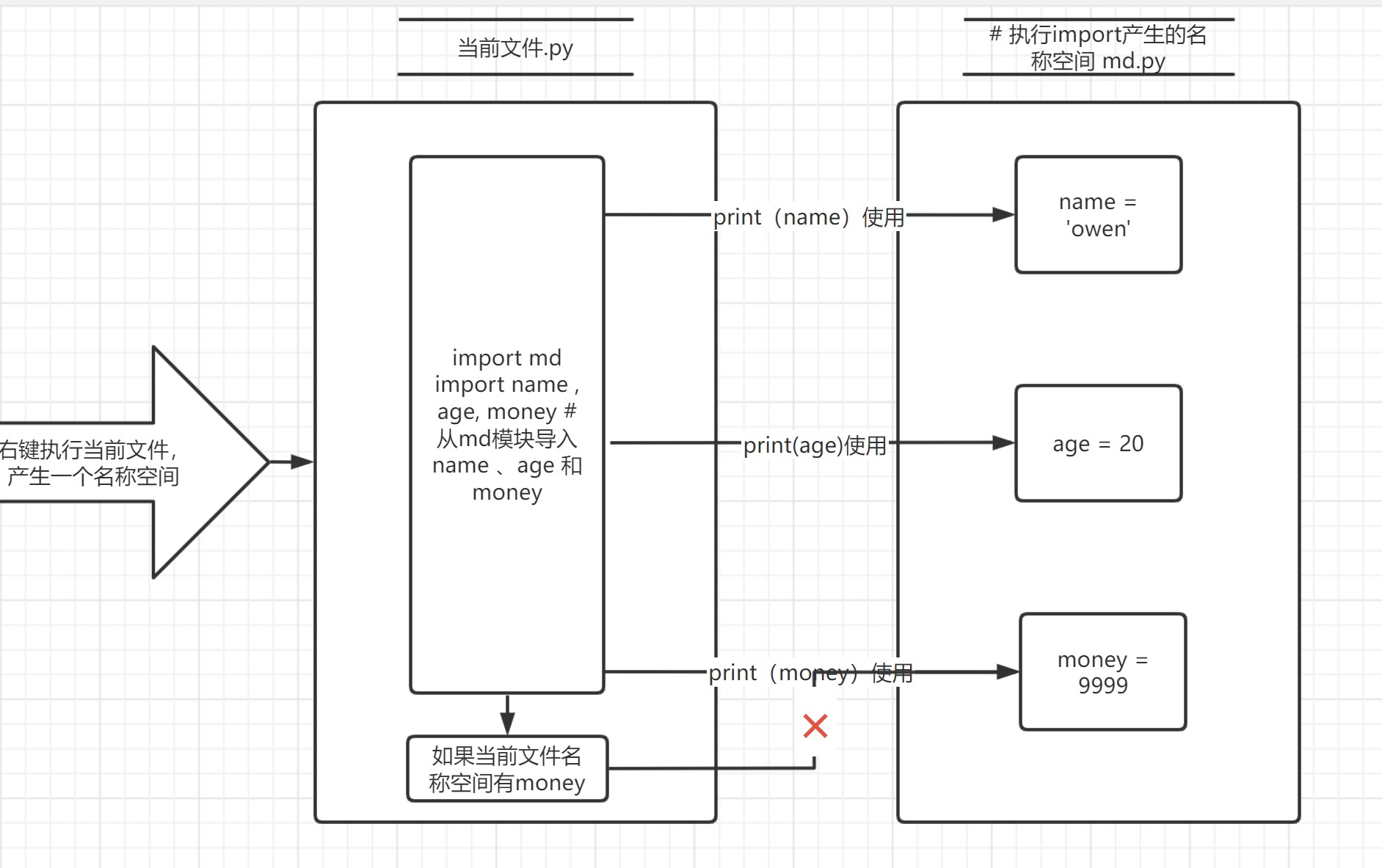
from md import name
print(name) # owen
name = 'mary'
print(name) # mary
#当导入列表只有name,你使用money时
from md import name
print(money) # 报错 因为from只导入name
"""
1.执行当前文件产生一个名称空间
2.执行导入语句 运行模块文件产生名称空间存放运行过程中的所有名字
3.将import后面的名字直接拿到当前执行文件中
4.重复导入也只会导入一次
5.使用模块名称空间中的名字不需要加模块名前缀 直接使用即可
6.但是from...import的句式会产生名字冲突的问题
在使用的时候 一定要避免名字冲突
7.使用from...import的句式 只能使用import后面出现的名字
from...import...可以简单的翻译成中文
从...里面拿...来用 没有提到的都不能用
"""
七 、导入句式的补充说明
1.可以给模块起别名(使用频率很高)
模块名或者变量名太长或者太复杂的时候, 可以简写
import md as m
print(m.name)
from md import name as n
print(n)
2.连续导入多个模块或者变量名
import time, sys, md
from md import name, age, pwd
"""
1.连续导入多个模块 这多个模块最好有相似的功能部分 如果没有建议分开导入
2.如果是同一个模块下的多个变量名无所谓
3.使用逗号隔开的方式
"""
3.通用导入
from md import *
'''
*表示md里面所有的名字,from...import的句式也可以导入所有的名字
如果模块文件中使用了__all__限制可以使用的名字 那么*号就会失效 依据__all__后面列举的名字
'''
print(name)
print(age)

散会~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号