
爬虫学习随笔:爬取百度翻译指定内容
str=input('Please enter:') url='https://fanyi.baidu.com/sug' header={ 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36' } data={ 'kw':str } response=requests.post(url=url,header=header,data=data) json_data=response.json() print(json_data['data'][0]['v'])
url是发送请求的地址
header的内容是将代码伪装成浏览器,因为网站会识别浏览器和代码,如果不是浏览器会封掉。header内的信息可以在如图找到(演示浏览器为chorme)
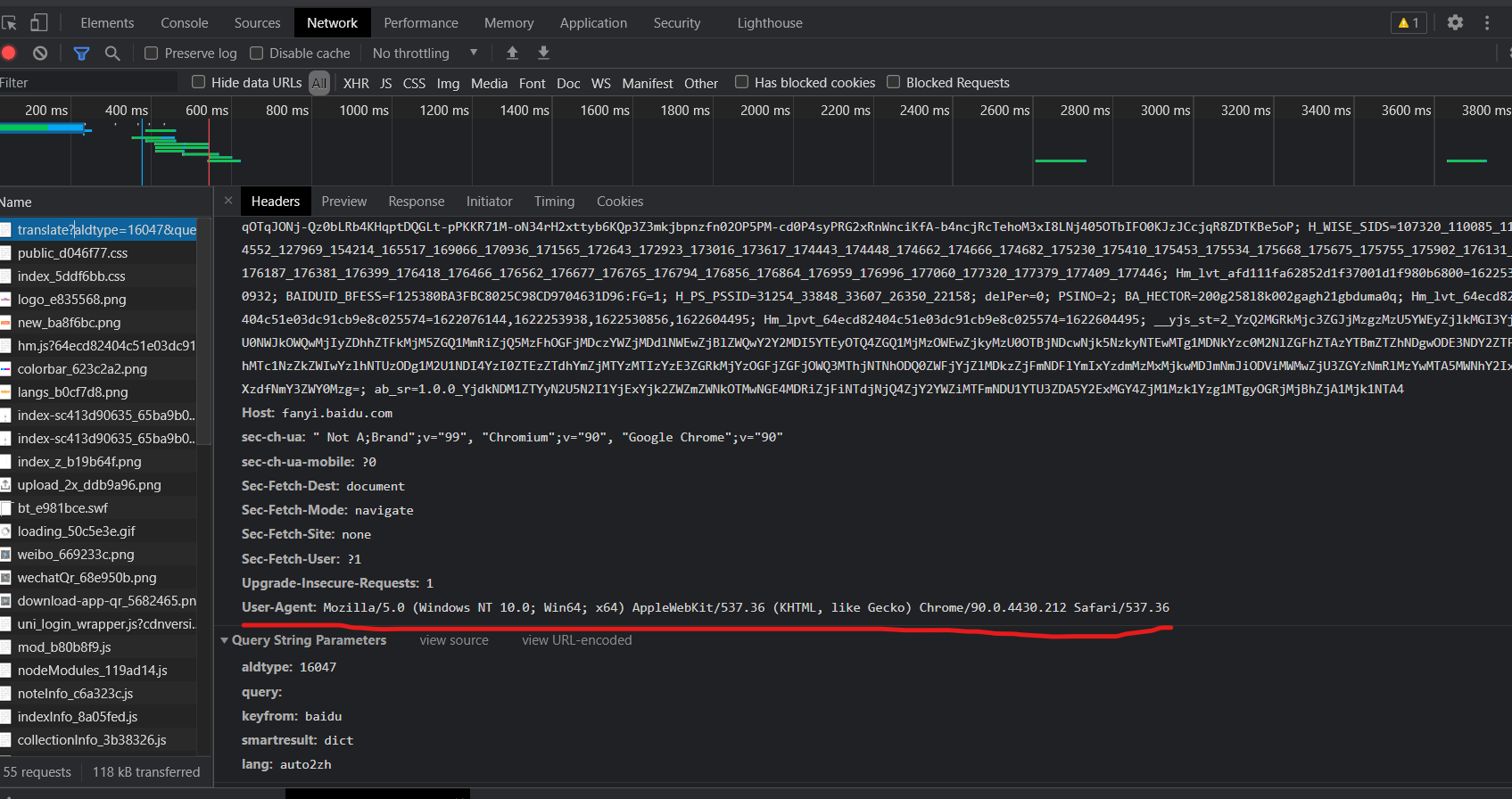 里面也有向cookie等需要的信息。
里面也有向cookie等需要的信息。
data保存的数据是需要翻译的单词、语句。str是要查的词句,‘kw’是通过浏览器抓包获得的(如下图 )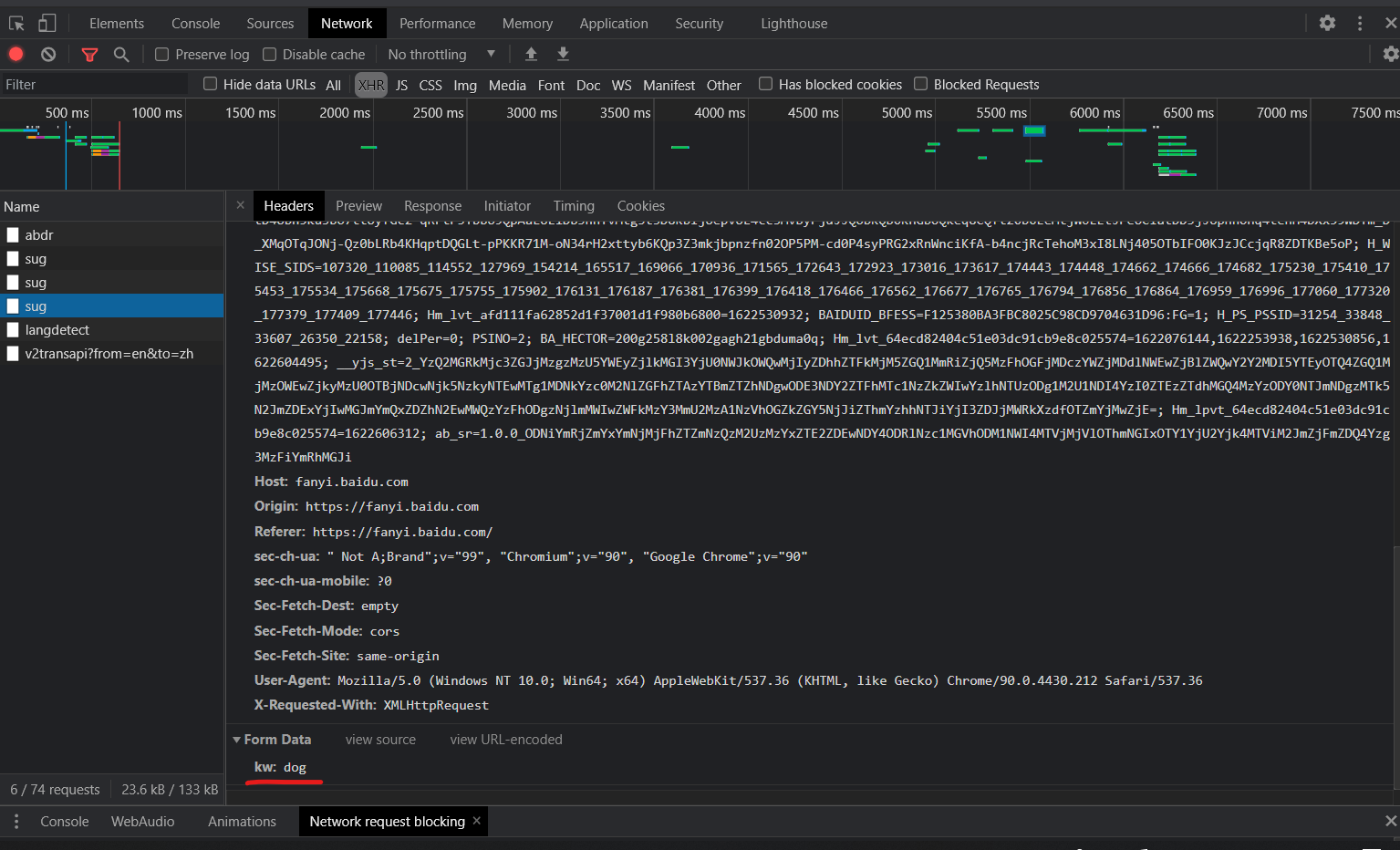
requests.post获得网页信息。
response.json()是将数据变成json格式,也可以通过response.text变成字符格式。需注意如果要将数据变成json,数据要是json的形式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号