

使用Python+selenium+pytest+allure 编写ui自动化
一、
1.1背景:每次新发布功能后都需要手动跑冒烟用例,重复点击太多,消耗人力资源
1.2测试项目:飞书第三方isv应用
1.3技术栈:Python+Selenium+Pytest+Allure
1.4框架设计:使用Page Object设计模式,将页面的元素和元素之间的操作方法进行分离。它有三层架构,分别为:基础封装层BasePage,PO页面对象层,TestCase测试用例层
二、文件结构:
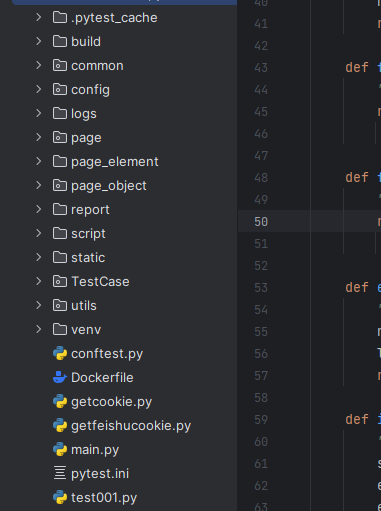
common文件夹:通用文件
config:配置文件
logs:日志
page:重新封装selenium基类
page_element:存放元素的yaml文件
page_object:定位元素对象
report:测试用例报告位置
script:验证定位元素是否正确
static:静态文件(本项目需要,可不需要)
TestCase:测试用例层
utils:工具层
conftest.py:pytest全局配置
main.py:程序入口文件
三、具体实现:
3.1、common:
readconfig.py:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import configparser
from config.conf import cm
HOST = 'HOST'
class ReadConfig(object):
"""配置文件"""
def __init__(self):
self.config = configparser.RawConfigParser() # 当有%的符号时请使用Raw读取
self.config.read(cm.ini_file, encoding='utf-8')
def _get(self, section, option):
"""获取"""
return self.config.get(section, option)
def _set(self, section, option, value):
"""更新"""
self.config.set(section, option, value)
with open(cm.ini_file, 'w') as f:
self.config.write(f)
@property
def url(self):
return self._get(HOST, HOST)
ini = ReadConfig()
if __name__ == '__main__':
print(ini.url)
readelement.py:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
import yaml
from config.conf import cm
class Element(object):
"""获取元素"""
def __init__(self, name):
self.file_name = '%s.yaml' % name
self.element_path = os.path.join(cm.ELEMENT_PATH, self.file_name)
if not os.path.exists(self.element_path):
raise FileNotFoundError("%s 文件不存在!" % self.element_path)
with open(self.element_path, encoding='utf-8') as f:
self.data = yaml.safe_load(f)
def __getitem__(self, item):
"""获取属性"""
data = self.data.get(item)
if data:
name, value = data.split('==')
return name, value
raise ArithmeticError("{}中不存在关键字:{}".format(self.file_name, item))
if __name__ == '__main__':
click = Element('click')
print(click['管理后台_选择人员'])
3.2、config:
conf.py:
# !/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
from selenium.webdriver.common.by import By
from utils.times import dt_strftime
class ConfigManager(object):
# 项目目录
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 页面元素目录
ELEMENT_PATH = os.path.join(BASE_DIR, 'page_element')
# 元素定位的类型
LOCATE_MODE = {
'css': By.CSS_SELECTOR,
'xpath': By.XPATH,
'name': By.NAME,
'id': By.ID,
'class': By.CLASS_NAME
}
# 邮件信息
EMAIL_INFO = {
'username': '1084502012@qq.com', # 切换成你自己的地址
'password': 'QQ邮箱授权码',
'smtp_host': 'smtp.qq.com',
'smtp_port': 465
}
# 收件人
ADDRESSEE = [
'1084502012@qq.com',
]
@property
def log_file(self):
"""日志目录"""
log_dir = os.path.join(self.BASE_DIR, 'logs')
if not os.path.exists(log_dir):
os.makedirs(log_dir)
return os.path.join(log_dir, '{}.log'.format(dt_strftime()))
@property
def ini_file(self):
"""配置文件"""
ini_file = os.path.join(self.BASE_DIR, 'config', 'config.ini')
if not os.path.exists(ini_file):
raise FileNotFoundError("配置文件%s不存在!" % ini_file)
return ini_file
cm = ConfigManager()
if __name__ == '__main__':
print(cm.BASE_DIR)
config.ini:
[HOST]
HOST = www.baidu.com
3.3、page
webpage.py:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""
selenium基类
本文件存放了selenium基类的封装方法
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from config.conf import cm
from utils.times import sleep
from utils.logger import Logger
log = Logger(logger='TestMylog').getlog()
class WebPage(object):
"""selenium基类"""
def __init__(self, driver):
# self.driver = webdriver.Chrome()
self.driver = driver
# 设置等待时间
self.timeout = 20
self.wait = WebDriverWait(self.driver, self.timeout)
def get_url(self, url):
"""打开网址并验证"""
self.driver.maximize_window()
self.driver.set_page_load_timeout(60)
try:
self.driver.get(url)
self.driver.implicitly_wait(10)
log.info("打开网页:%s" % url)
except TimeoutException:
raise TimeoutException("打开%s超时请检查网络或网址服务器" % url)
@staticmethod
def element_locator(func, locator):
"""元素定位器"""
name, value = locator
return func(cm.LOCATE_MODE[name], value)
def find_element(self, locator):
"""寻找单个元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_element_located(args)), locator)
def find_elements(self, locator):
"""查找多个相同的元素"""
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_all_elements_located(args)), locator)
def elements_num(self, locator):
"""获取相同元素的个数"""
number = len(self.find_elements(locator))
log.info("相同元素:{}".format((locator, number)))
return number
def input_text(self, locator, txt):
"""输入(输入前先清空)"""
sleep(0.5)
ele = self.find_element(locator)
ele.clear()
ele.send_keys(txt)
log.info("输入文本:{}".format(txt))
def input_img(self, locator, img):
sleep(0.5)
ele = self.find_element(locator)
ele.send_keys(img)
def is_click(self, locator):
"""点击"""
self.find_element(locator).click()
sleep()
log.info("点击元素:{}".format(locator))
def element_text(self, locator):
"""获取当前的text"""
_text = self.find_element(locator).text
log.info("获取文本:{}".format(_text))
return _text
@property
def get_source(self):
"""获取页面源代码"""
return self.driver.page_source
def refresh(self):
"""刷新页面F5"""
self.driver.refresh()
self.driver.implicitly_wait(30)
3.4、page_element
click.yaml:
[名称]: 'xpath== '
百度一下: 'xpath==//*[@id="su"]'
3.5、page_object
clickpage.py:
from page.webpage import WebPage, sleep
from common.readelement import Element
click = Element('click')
class ClickPage(WebPage):
# 点击百度一下
def click_search(self):
self.is_click(click['百度一下'])
3.6、script
inspect.py:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
import yaml
from config.conf import cm
from utils.times import running_time
@running_time
def inspect_element():
"""检查所有的元素是否正确
只能做一个简单的检查
"""
for files in os.listdir(cm.ELEMENT_PATH):
_path = os.path.join(cm.ELEMENT_PATH, files)
with open(_path, encoding='utf-8') as f:
data = yaml.safe_load(f)
for k in data.values():
try:
pattern, value = k.split('==')
except ValueError:
raise Exception("元素表达式中没有`==`")
if pattern not in cm.LOCATE_MODE:
raise Exception('%s中元素【%s】没有指定类型' % (_path, k))
elif pattern == 'xpath':
assert '//' in value, \
'%s中元素【%s】xpath类型与值不配' % (_path, k)
elif pattern == 'css':
assert '//' not in value, \
'%s中元素【%s]css类型与值不配' % (_path, k)
else:
assert value, '%s中元素【%s】类型与值不匹配' % (_path, k)
if __name__ == '__main__':
inspect_element()
3.7、TestCase
test_click.py:
import re
import time
import allure
import pytest
from TestCase import skip
from utils.logger import Logger
from common.readconfig import ini
from page_object.clickpage import ClickPage
from utils.times import dt_strftime
Logger(logger='TestMylog').getlog()
class TestClick:
def test_clickSearch(self, drivers):
click = ClickPage(drivers)
click.click_search()
3.8、utils
logger.py:
import logging
import os.path
import time
class Logger(object):
def __init__(self, logger):
"""
指定保存日志的文件路径,日志级别,以及调用文件
将日志存入到指定的文件中
:param logger:
"""
# 拼接日志文件夹,如果不存在则自动创建
cur_path = os.path.dirname(os.path.realpath(__file__))
log_path = os.path.join(os.path.dirname(cur_path), 'logs')
if not os.path.exists(log_path): os.mkdir(log_path)
# 创建一个logger
self.logger = logging.getLogger(logger)
self.logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
# log_path = os.path.dirname(os.getcwd()) + '/Logs/'
# log_name = log_path + rq + '.log'
log_name = os.path.join(log_path, '%s.log ' % rq)
fh = logging.FileHandler(log_name)
fh.setLevel(logging.INFO)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def getlog(self):
return self.logger
if __name__ == '__main__':
logger = Logger(logger='TestMylog').getlog()
times.py:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import time
import datetime
from functools import wraps
def timestamp():
"""时间戳"""
return time.time()
def dt_strftime(fmt="%Y%m%d%H%M%S"):
"""
datetime格式化时间
:param fmt "%Y%m%d %H%M%S
"""
return datetime.datetime.now().strftime(fmt)
def sleep(seconds=1.0):
"""
睡眠时间
"""
time.sleep(seconds)
def running_time(func):
"""函数运行时间"""
@wraps(func)
def wrapper(*args, **kwargs):
start = timestamp()
res = func(*args, **kwargs)
print("校验元素done!用时%.3f秒!" % (timestamp() - start))
return res
return wrapper
if __name__ == '__main__':
print(dt_strftime("%Y%m%d%H%M%S"))
3.9、conftest.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import json
import os
import pytest
from selenium import webdriver
driver = None
@pytest.fixture(scope='session', autouse=True)
def drivers(request):
global driver
if driver is None:
driver = browser_initial()
with open(r'D:\python\fmselenium\static\feishu_cookie.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.feishu.cn',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'sameSite': 'None',
'Secure': True
}
driver.add_cookie(cookie_dict)
driver.get("https://140lslchw.feishu.cn/admin/index")
# 窗口变大
# driver.maximize_window()
print("调用drivers ***************************************************")
def fn():
driver.quit()
request.addfinalizer(fn)
return driver
#刷新网页
def browser_initial():
os.chdir(r'/')
driver = webdriver.Chrome()
driver.get("https://140lslchw.feishu.cn/admin/index")
return driver
3.10 、main.py:
import os
import pytest
if __name__ == '__main__':
current_dir = os.getcwd()
pytest.main(["-s", f"{current_dir}/TestCase/", "--alluredir", f"{current_dir}/report/allure-result"],)
# 清理上一次测试数据
# pytest.main(["-s","TestCase/test_02_backend.py","--alluredir", f"{current_dir}/report/allure-result",'--clean-alluredir'],)
os.system(f"allure generate {current_dir}/report/allure-result/ -o {current_dir}/report/allure-report --clean")
# print(current_dir)
os.system(rf"xcopy {current_dir}\report\allure-report\history {current_dir}\report\allure-result\history /E /Y /I")
4.问题
飞书登录
1.写好一个测试用例脚本后,开始调试,验证框架是否完整,发现webdriver打开的浏览器需要重新进行飞书 登录验证,且进行授权登录
ps:飞书isv应用只能通过飞书授权进行登录,获取企业信息,导致必须先登录飞书,在进行点击授权获取 code码
解决思路:
1.查看飞书登录方法,一共3种,扫码登录、手机号验证码登录、邮箱登录。(sso登录企业未配置,忽略)
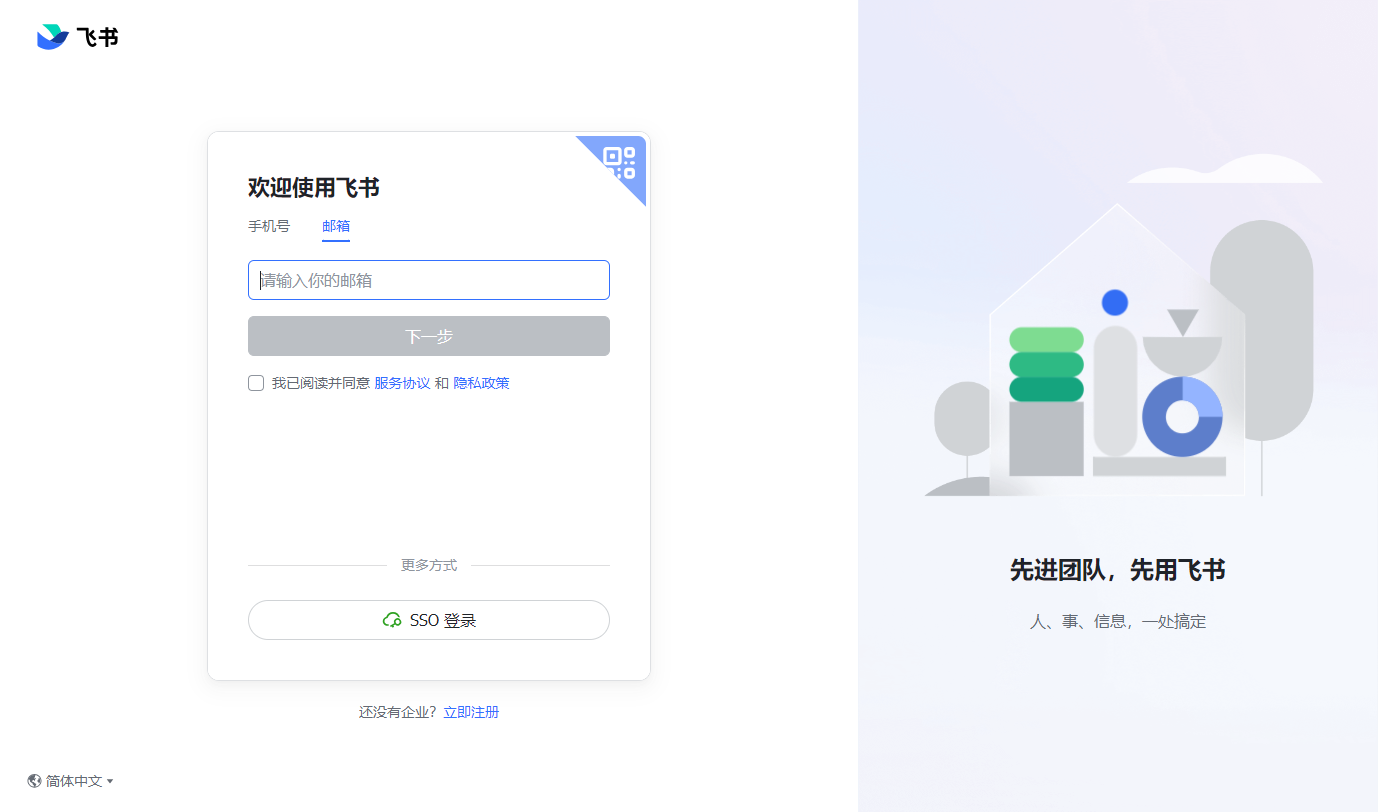
2.首先排除扫码登录,跑一下扫一次码不现实
3.手机号登录,需要接收验证码,也排除
4.邮箱登录,验证码发送到邮箱,似乎能做?
4.1、思路:使用imaplib邮件服务器,再进行检索邮件,找到最新邮件进行解析数据,找到验证码,再进行填 入飞书登录

4.2、太麻烦了,排除此方法
5.直接获取到飞书租户的cookie,再添加到webdriver里,以此实现模拟已飞书已登录的浏览器状态
5.1、思路:人工手动从浏览器获取到飞书登录的cookie,再使用此cookie存到webdriver里
5.2、实现方法:
5.2.1 手动获取cookie,使用的是谷歌浏览器,所以直接下载插件,登录飞书(任意一个界面)直接右键进行复制cookie
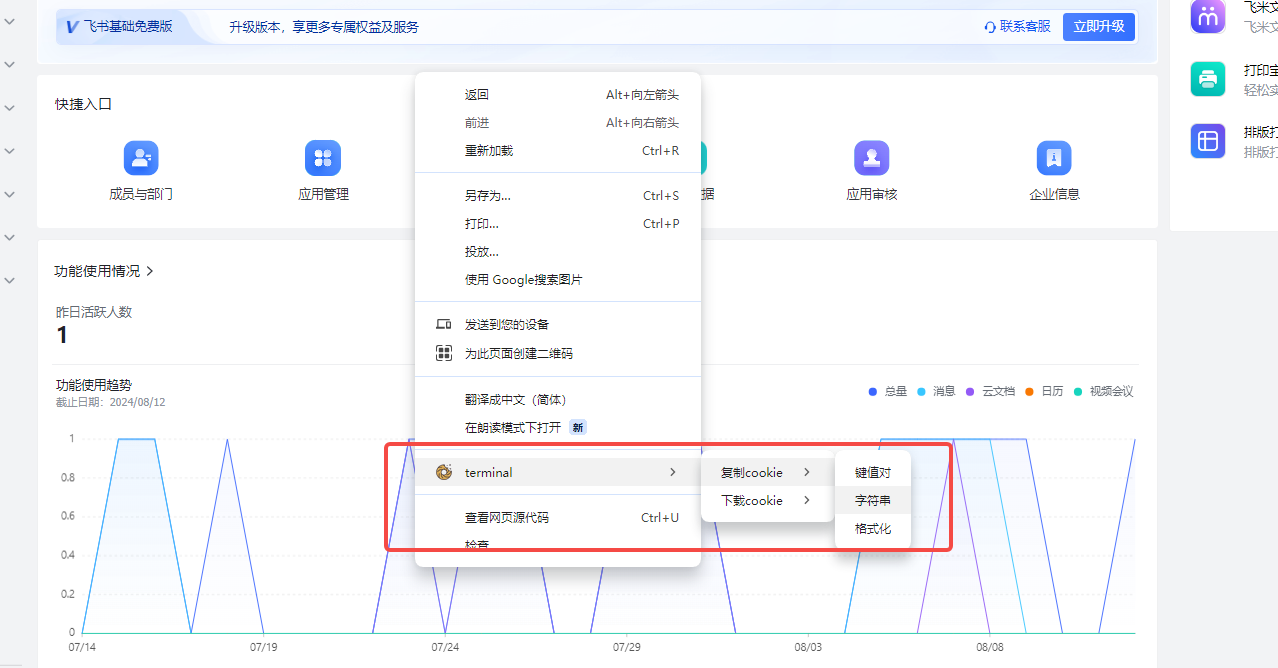
5.2.2 存放到文件中
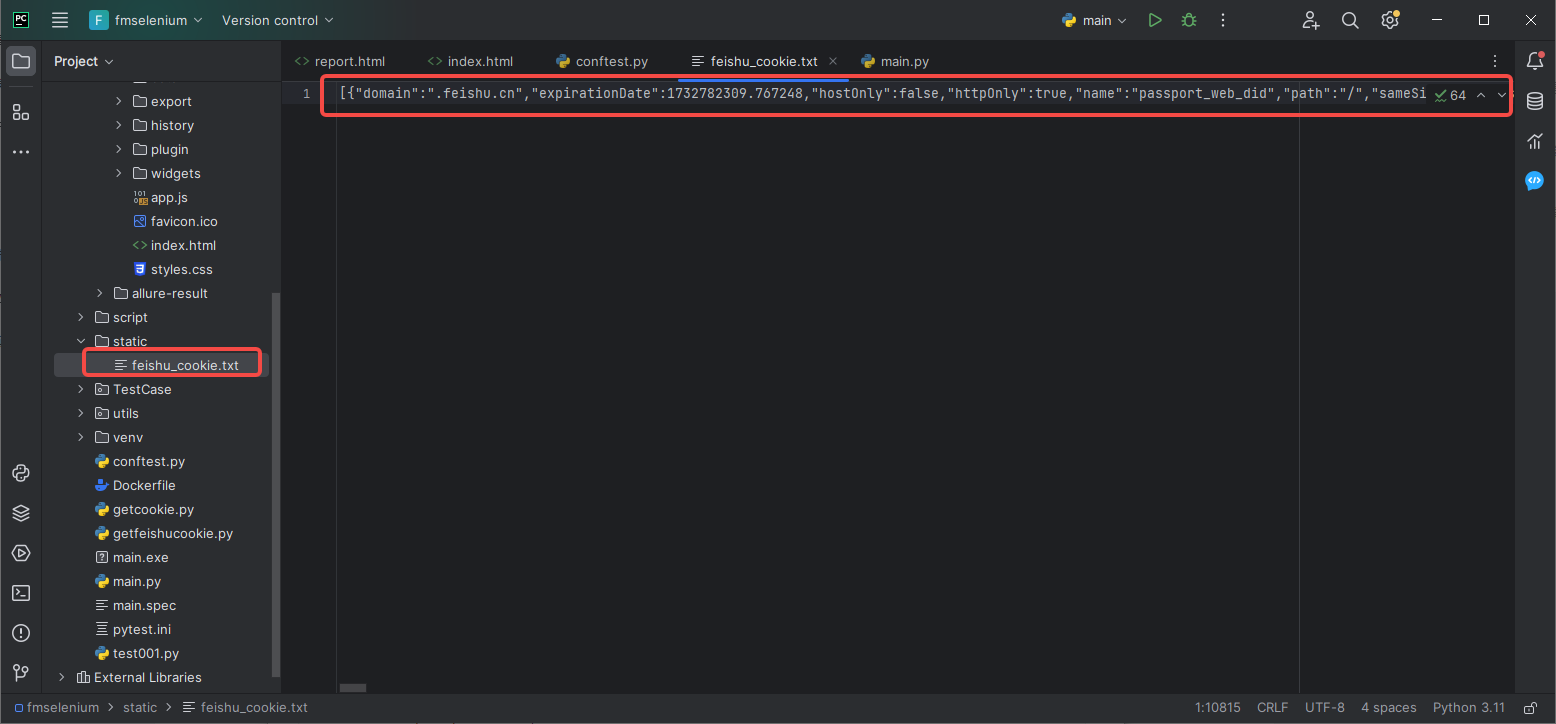
5.2.2 在conftest.py文件中,进行编写全局的配置
``
@pytest.fixture(scope='session', autouse=True)
def drivers(request):
global driver
if driver is None:
driver = browser_initial()
# 获取手动拿到的cookie
with open(r'D:\python\fmselenium\static\feishu_cookie.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.feishu.cn',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'sameSite': 'None',
'Secure': True
}
driver.add_cookie(cookie_dict)
driver.get("https://140lslchw.feishu.cn/admin/index")
# 窗口变大
# driver.maximize_window()
print("调用drivers ***************************************************")
def fn():
driver.quit()
request.addfinalizer(fn)
return driver
#刷新网页
def browser_initial():
os.chdir(r'/')
driver = webdriver.Chrome()
driver.get("飞书登录的网页地址")
return driver
-
3 解决飞书登录问题
结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号