

Geo-localization论文阅读list1
Geo-localization论文阅读list1
从Week16开始,博主主要工作转为阅读Geo-localization专业论文,鉴于专业论文和深度学习基础论文的特点差异,专业论文总结将会以一个一个的list呈现。
文章目录
1. Learning Deep Representations for Ground-to-Aerial Geolocalization
1.1 Thinkings
论文的motivation是从大量geo-tagged images的利用开始,催生了许多ground-to-ground的geolocalization方法。但即使是ground-level reference photos再多,受到其视角范围的限制,还是难以做到地球全覆盖,所以短期之内利用ground-level photos作为geo-reference难以做到大范围的图像定位。所以,本论文利用航空影像作为geo-reference,采用匹配的方式来实现对ground-level photos的定位。受到了深度学习在人脸验证上面所取得成功的启发,作者提出了一个叫Where-CNN的网络框架,将ground-to-aerial geolocalization这个问题看作一个图像检索的问题进行解决。
作者在这里也提出了匹配这些disparate visual domains主要存在两大难点:
- 几何上面,每种视角都会有着大量的遮挡。例如,对于同一个房子来说,街景视角会有树木遮挡,而鸟瞰视角又只能看见这个房子的房顶。
- 同一地点的不同视角图片在不同的光照、气候、季节下面拍摄。
总体来说,这篇论文的contributions主要由以下三个方面:
- 本论文的方法利用航空图片作为geo-reference,而无需利用ground-level photos作为geo-reference,克服了ground-level photos难以做到大面积覆盖的缺点。
- 论文介绍了一个从公开数据源中创建大尺度cross-view数据集的方法。
- 论文还做了传统计算机视觉features和几个不同深度学习策略的对比。
1.2 Principle Analysis
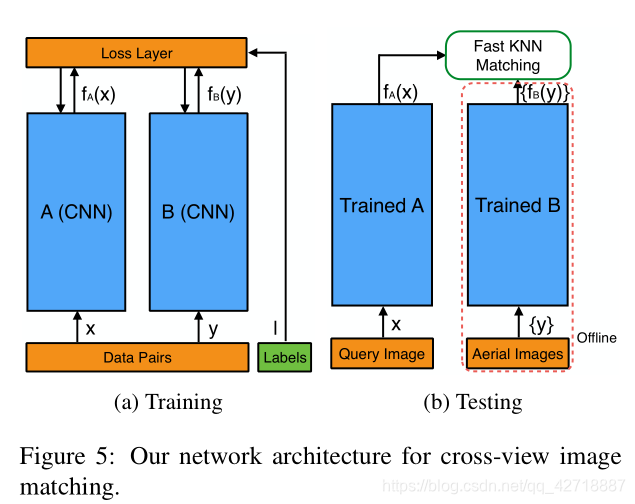
如上图所示,作者的Where-CNN就是利用了Siamese network的结构,将cross-view匹配问题转换为一个图像检索的问题(人脸验证)。这里作者使用的backbone是pre-trained AlexNet。
1.3 Weakness
- 在测试的时候需要对没有metadata的ground-level query images进行尺度和深度的估计。
- ground-level query images的绝对方位可能会不知道,所以需要挨个试一下。
2. PlaNet - Photo Geolocation with Convolutional Neural Networks
2.1 Thinkings
在计算机视觉领域之中一般都是把geo-localization作为一个image retrieval的问题,通过匹配的方式用匹配好的geo-tagged images坐标去计算query images的坐标。而作者创造性地利用地球格网剖分将geo-localization转换为一个classification问题。通过classification输出概率分布,而不像以前一样直接推断出query images的坐标,能够充分表达推理的不确定性。当然,这种方法定位的精度取决于地球网格剖分的精度了,而往往网格剖分很难做到在整个地球划分小尺度(比如街道)的均匀网格。
值得注意的事情是,作者的图片数据集有一部分是从Flickr里面收集的,和传统geo-localization使用的数据集不同的是,传统数据集一般是包含landmarks, weather patterns, vegetation, road markings and architectural details,而作者这里的数据集有可能是一张食物、动物或者汽车等任意图像。所以,作者为了解决这些图像可能没有informative cues的问题,引入了photo albums的概念,即一个photo album里面的图片一般是在同一个地点拍摄的。作者在此利用一个photo album在时序特征上面相似的特点,在原网络的基础之上引入了LSTM网络提取时序特征,使得PlaNet性能有了明显的提升。
总体来说作者的contributions主要在以下两方面:
- 创造性地将geo-localization问题转化为classification。
- 利用Squence model扩展了模型的泛化能力。
2.2 Principle Analyse
总体来说本论文的原理主要在三个方面:
- Adaptive partitioning using S2 Cells:作者利用了谷歌的s2-geometry-library剖分地球网格。
- CNN model:本论文的backbone是Inception网络,最后加入了SoftMax将问题转化为预测该图片属于哪一个网格。
- Sequence model:如下图所示,作者选择了LSTM网络,利用photo albums的时序特征,设计了四个时序PlaNet的四个变体:
![在这里插入图片描述]()

2.3 Weakness
总体来说,虽然利用地球网格剖分创新地将geo-localization转换为分类问题,能够很好地表示定位中的不确定性,但是也带来了精度和计算上面的缺陷。如果想要获得更加精准的图像坐标,就需要划分更加细致的网格,这会导致网格的数量直线上升,使得最后的SoftMax层输出变得十分巨大。
3. CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization
CVPR2018
3.1 Thinkings
目前很多人都将geo-localization问题当做一个cross-view matching问题。作者的motivation就是传统的descriptor在面对cross-view matching问题时,由于巨大的视角变化,很难起到好的效果。作者在此首先利用了Siamese architecture提取local image features,然后又使用NetVLAD将local image features编码成global image descriptors。作者又为了提升模型收敛速度和精度,提出了weighted soft margin ranking loss function。
总体来说,作者的contibutions,主要在以下两点:
- 网络结构的组合创新,即将Siamese Network和NetVLAD组合起来,共同解决cross-view matching问题。
- 引入了weighted soft margin ranking loss function加速模型收敛,提高模型精度。
3.2 Principle Analyse

如上图所示,作者提出了两种CVM-Net的变体,左边那个是不共享NetVLAD参数,右边那个共享NetVLAD参数和输入NetVLAD前第二全连接层的参数。实验结果证明不共享参数稍微好一点。

如上图所示,作者的weighted soft margin ranking loss function就是在soft margin ranking loss function之上加入了一个
α
\alpha
α参数(实验中取10),将d的效果进行了放大。当然,这个weight也可以扩展到其他的loss上面。
3.3 Trash Talk
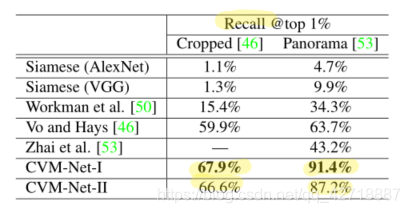
虽然博主感觉作者没有什么实质性的创新:cross-view问题很早就被提出来了;NetVLAD也是一个几年前的网络,并且别人提出的时候本身就是作为一个plugin module被提出的,所以很容易加入到其他网络结构;Siamese Network也是geo-localization领域中常用的一个网络结构;weighted soft margin ranking loss function只是加入了一个
α
\alpha
α参数去放大d的效果。但是,如上图所示,这个网络在全景图片的那个数据集上面Recall @ top 1%已经刷到了91.4%,属实厉害,所以博主感觉模型性能和精度也是发顶会很重要的一个参考指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号