论文查重
| 这个作业属于哪个课程 | 计科国际班软工 |
|---|---|
| 这个作业要求在哪里 | 要求 |
| 这个作业的目标 | 论文查重程序 |
| 1.GitHub地址: https://github.com/a-sk768/3119009435 | |
| 2.PSP表格 | |
| PSP2.1 | Personal Software Process Stages |
| --------------------------------------- | -------------------------------- |
| Planning | 计划 |
| · Estimate | · 估计这个任务需要多少时间 |
| Development | 开发 |
| · Analysis | · 需求分析 (包括学习新技术) |
| · Design Spec | · 生成设计文档 |
| · Design Review | · 设计复审 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) |
| · Design | · 具体设计 |
| · Coding | · 具体编码 |
| · Code Review | · 代码复审 |
| · Test | · 测试(自我测试,修改代码,提交修改) |
| Reporting | 报告 |
| · Test Repor | · 测试报告 |
| · Size Measurement | · 计算工作量 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 |
| Sum up | 合计 |
| 3.计算模块接口的设计与实现过程: | |
| 此次论文查重我以余弦相似度实现。 | |
| 我使用hanlp进行分词及关键字提取,kmp算法计算关键词数量,并以快速排序和链表数据结构进行辅助计算。 | |
| 故至少需要以下模块: | |
| 1.输入输出模块 | |
| 2.分词及关键词提取模块 | |
| 3.计算关键词数量模块 | |
| 4.计算余弦值模块 | |
| 程序的函数嵌套顺序以模块标号按从小到大进行 | |
| 其中,3、4模块在最后被我合并为一个计算模块,此外加入了一些用以辅助计算的类,类中有且只有一个静态方法。 | |
| (注:关键词提取部分的函数目前正在构建,故先调用工具辅助进行,以后有时间commit) | |
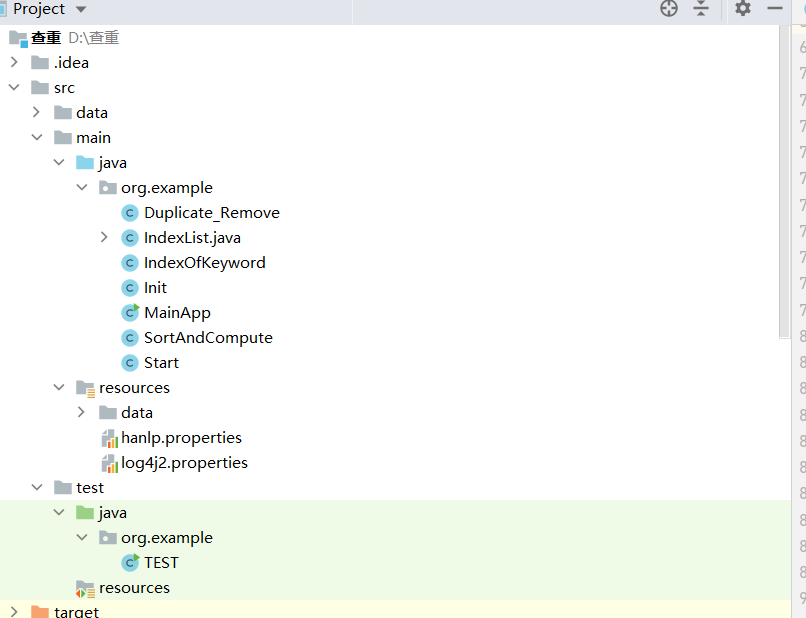
| 我的工程结构示意图: | |
 |
Libraries:

4 性能测试
JProfiler运行时截图:
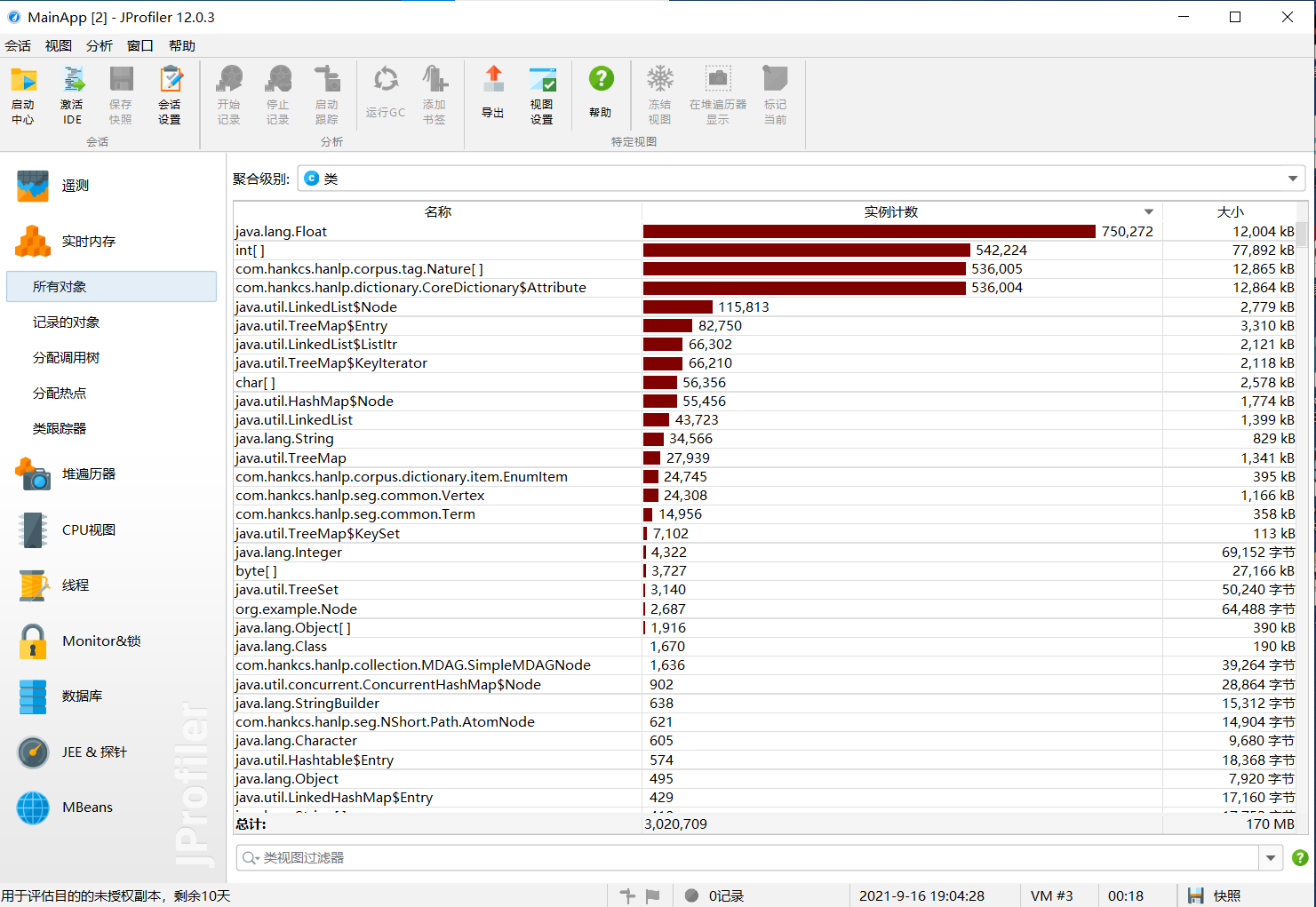
可以看到,Java.lang.Float的实例次数最多,这是因为在函数实现的过程中大量调用toString方法。
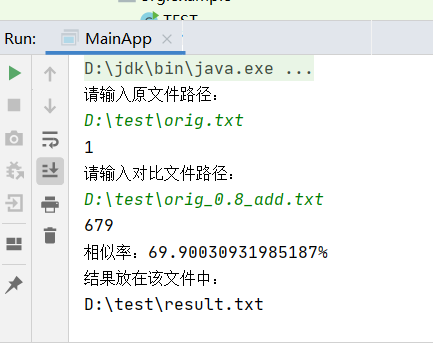
从这个上面所展示的截图可以看出,在处理文本容量为一万字左右的文件时,该项目计算结果所需时间为679ms,读取数据用了1ms,
为了检查程序在不同性能设备上运行效率 我将电脑置为省电模式,结果为763ms以及2ms。
至于如何改进,思路如下:
将原文分词并去除停用词后放入Map中,之后根据关键词数组遍历Map,遇到相同的,关键词的数量数组对应位置加一(具体实现靠hash算法),直到遍历完成,最终得到表示关键词数量的数组。从时间复杂度来看,假设关键词数量为m,文本容量为n,若用原来的方法,对每一个关键词,均需要遍历一次文本所以最终时间复杂度为O(mn),改进后的算法,只需要遍历一遍文本,所以时间复杂度仅为O(m),最终得到一个线性时间复杂度的算法。
改进后的算法相当于重写一遍这个作业,所以我暂时放弃将其实现,但之前想复杂了,这次以后,我会着重考虑性能分析,在构建代码前仔细思考。(所以说这次算法的设计真的辣鸡)
5 部分代码展示:
1.
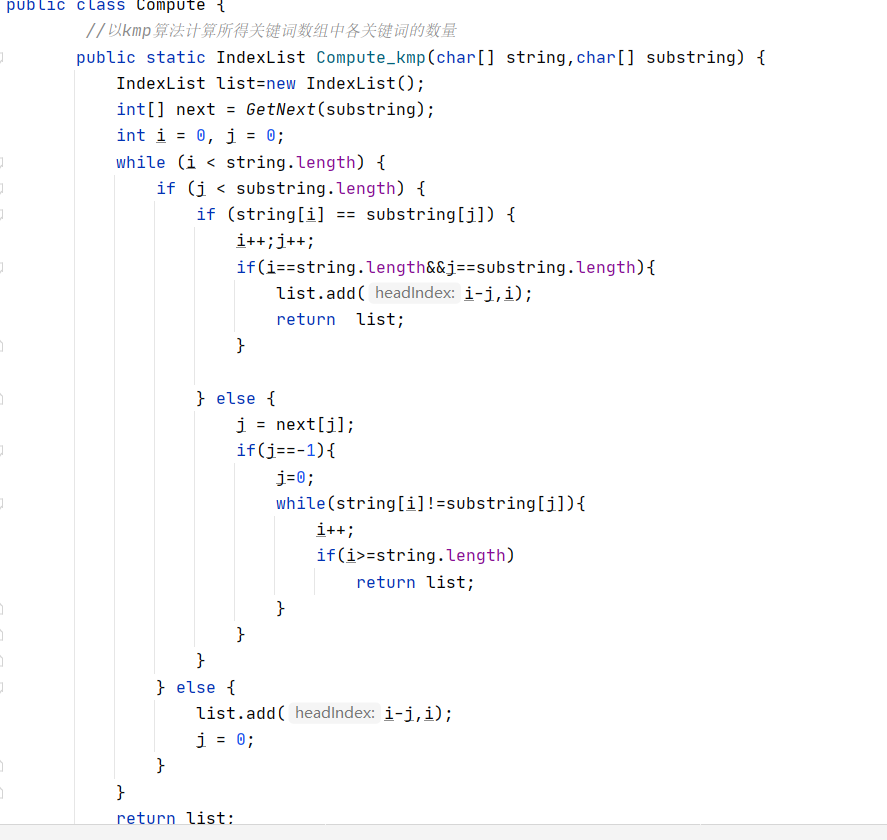
这里我直接构建一个String,将其转换为char数组,然后传参,通过人工校验确认无误后,测试结束。
2.
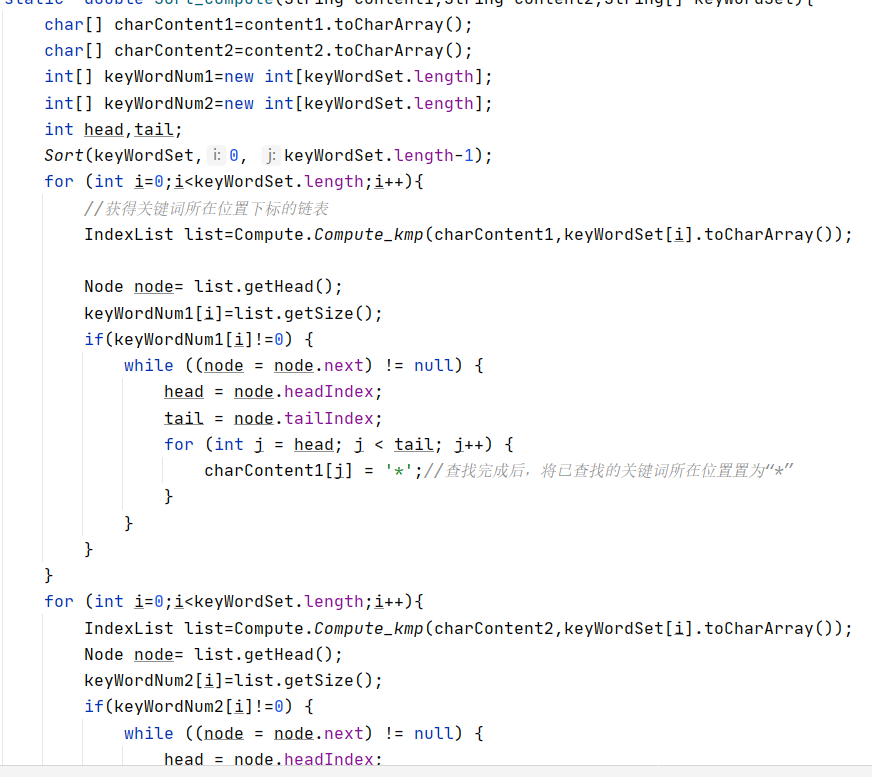
这里我还是直接构建一个String,将其转换为char数组,然后传参,通过人工校验确认无误后,啪,测试结束。
6.计算模块部分异常处理说明
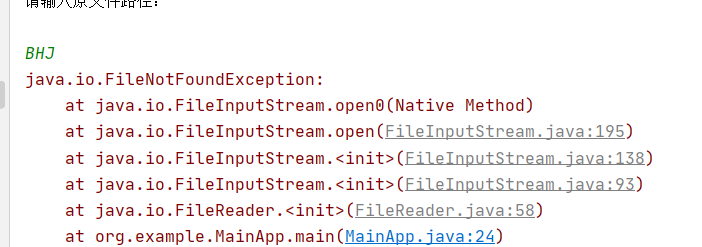
在输入输出部分的异常处理我是直接使用了Java语言的异常抛出机制,如果遇到文件路径非法或者路径不存在,则会抛出如下
异常:
非法路径:
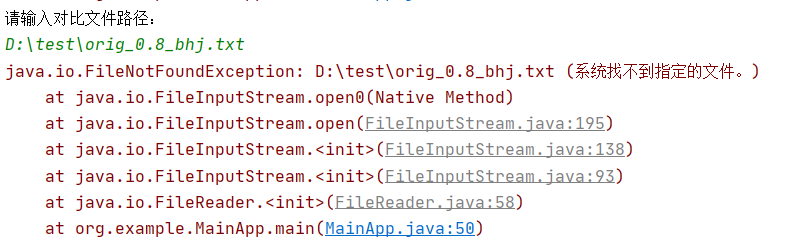
文件不存在:
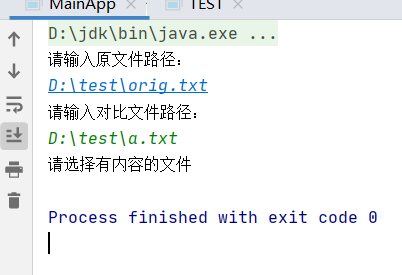
文件为空:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号