TCP系列13—重传—3、协议中RTO计算和RTO定时器维护
从上一篇示例中我们可以看到在TCP中有一个重要的过程就是决定何时进行超时重传,也就是RTO的计算更新。由于网络状况可能会受到路由变化、网络负载等因素的影响,因此RTO也必须跟随网络状况动态更新。如果TCP过早重传,则可能会向网络中注入很多重复报文,如果过晚重传,则在丢包时候则会影响滑窗前行可能会降低网络利用率。因为TCP在接收到数据后会发送累计的ACK number,因此TCP发送某个系列号的报文后,在接收到覆盖此系列号的ACK报文的时候,测量发送和接收之间的时间,这个测量就叫做RTT采样(RTT sample)。TCP对于每个连接都会根据RTT采样来维护跟新RTO,同时还会维护一个RTO超时的定时器。注意是对每个连接维护一个超时定时器,而不是对每个发出去的TCP报文。当TCP发出数据报文(或者SYN、FIN报文)的时候,如果之前没有等待ACK的报文则会设置这个连接的RTO定时器,如果之前有等待ACK的报文,则并不会重启RTO定时器。当TCP同时有多个报文发出且没有等到ACK的时候,则会先重传第一个报文,第一个报文重传成功收到ACK后,再设置RTO定时器然后重传第二个报文。
本篇先来介绍一下协议中更新计算RTO的方法。协议中主要有两种方法来计算RTO一种是RFC793的经典方法(classic method),另一种是RFC6298的标准方法(standard method)。
一、经典方法
在原始的RFC793中关于RTO更新的介绍只有半页文字的样子,它首先让TCP使用下面的公式更新一个平滑RTT估计(smoothed RTT estimator、简称SRTT):
SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT)
其中RTT是之前介绍的一个RTT采样值,ALPHA则是一个平滑因子(smoothing factor),协议给出的示例范围是0.8--0.9之间。这个过程也叫做指数加权移动平均(exponentially weighted moving average、简称EWMA)。可以看到这个计算过程只需要保留一个RTT采样值就行了,而不需要保留过多的历史RTT采样。
接着在按照下面公式计算出RTO:
RTO = min[UBOUND,max[LBOUND,(BETA*SRTT)]]
其中BETA是一个延迟因子,协议给出的示例范围是1.3--2.0。UBOUND是一个RTO上限,LBOUND是一个RTO下限,UBOUND和LBOUND协议给出的示例范围分别是1分钟和1秒,显然这两个值对于现代TCP网络可能并不合适。
二、标准方法
RFC1122指出上面介绍的计算RTT的经典方法中存在两个问题,一个是在发生TCP重传的时候,RTT采样的精确测量非常困难,第二个问题是经典方法认为RTT是比较平稳的状态,变化比较小,因此SRTT的计算是不合适的。实际上比如在低速网络中,TCP的数据包的不同大小会导致不同的传输耗时,进而可能就会导致RTT采样值差距比较大。对于上面两个问题第一个问题由karn算法解决,karn算法我们后续进行介绍。第二个问题由Jacobson算法解决,该算法在RTO估计中添加了一个用于反映RTT波动的RTTVAR变量。而RFC6298就是一个基于Jacobson算法的RTO计算文档,我们把这种RTO计算方法称为标准方法。
1、RTO计算及更新
为了计算当前的RTO,TCP发送端维护两个状态变量一个是SRTT(smoothed round-trip time)一个是RTTVAR (round-trip time variation),另外还有一个TCP时钟粒度G。
-
1)、在没有测量到有效的RTT采样之前,设置RTO=1s;
-
2)、在第一个有效的RTT采样测量出来后,假设采样值为R,则进行如下初始化过程
SRTT = R
RTTVAR = R/2
RTO = SRTT + max(G,K*RTTVAR)
其中K = 4;
-
3)、当随后的RTT采样R’测量到以后,按照如下更新:
RTTVAR = (1 - beta) * RTTVAR + beta * |SRTT - R'|
SRTT = (1 - alpha) * SRTT + alpha * R'
注意用于计算RTTVAR的公式中的SRTT是本次更新前的值,也就是说这两个公式的计算顺序不能颠倒。其中alpha=1/8、 beta=1/4,alpha和beta的选值允许计算机通过移位做除法的快速运算。
计算出SRTT和RTTVAR后,RTO仍旧按照如下更新:
RTO = SRTT + max (G, K*RTTVAR)
-
4)、当RTO计算出来后,如果RTO小于1s,RTO则应该设置为1s。虽然给出的是1s的下限,但是协议允许使用更低的下限。
-
5)、也可以对RTO设置一个上限,协议建议上限至少为60s。
关于上面的RTT采样,协议要求使用karn算法进行采样,同时要求至少在一个RTT里面采样一次(除非因为karn算法导致不可能在一个RTT里面采样一次)。协议指出对于每个TCP报文进行RTT采样测量不一定会得到更好的RTT估计值。
2、RTO定时器的管理
协议对于RTO定时器的建议管理方法如下:
-
1)、每次一个包含数据的TCP报文发送出去的时候(包括重传),如果RTO定时器没有运行,则重启RTO定时器,并设置定时时间为RTO。
-
2)、当所有发出的数据报文都被ACK后,关闭这个RTO定时器。
-
3)、当一个新的ack number到达的时候(新的ack number是指ack了新数据),如果还有未被ACK的数据,则重启RTO定时器,并设置定时时间为当前RTO。
当RTO定时器触发的时候(即所设置的定时时间到达的时候)
-
4)、在还没有ACK的报文里面重传最早发出去的报文。
-
5)、设置RTO = RTO * 2,这也就是我们经常说的指数回退。也可以和上面RTO更新过程一样添加一个同样的上限来限制RTO大小。
-
6)、重启RTO定时器,设置定时时间为RTO(这里的RTO是已经回退过的RTO)。
-
7)、如果RTO定时器是因为等待SYN报文的ACK而超时,如果实现上使用的RTO值小于3s,这个RTO定时器必须被重新初始化为3s。
在重传完成后,新的RTT采样可能会将RTO设置为与原来比较接近的值,从而消除指数回退对于RTO的影响。另外在多次指数回退过程中,TCP实现可能会清空SRTT和RTTVAR的值,一旦这两个被清空,则需要使用上面RTO计算及更新中的第2)步来初始化SRTT和RTTVAR。
三、RTO定时器管理示例
下面的测试示例关闭了TLP功能,相关介绍见后面文章
1、RTO超时重传成功恢复后发送的新数据又RTO超时。对于这种场景我们从下图可以看到新发送的数据在RTO超时后,超时时间大约为1.5s,也就是说RTO定时器在之前指数回退后现在已经恢复。

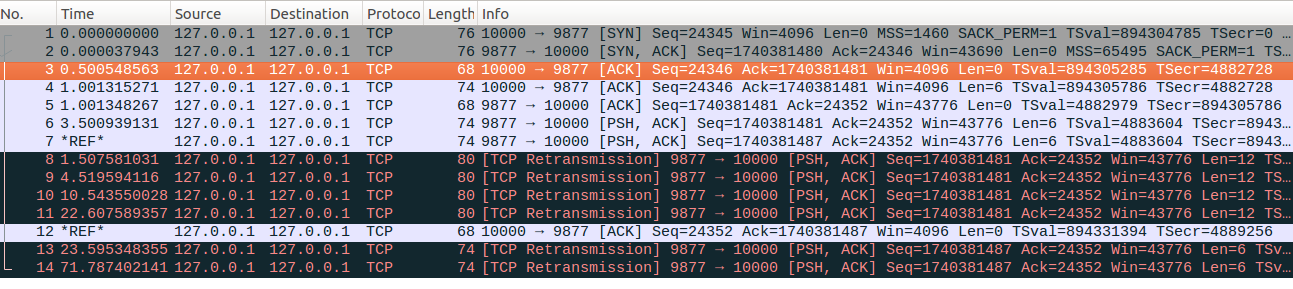
2、RTO超时重传collapse后,只回复部分ACK确认包。如下图所示,在数据包No6超时重传的时候,把No7数据包collapse在一起了,也就是说No8重传包同时包含了No6和No7数据包的内容,从图中的len字段也可以看出来,如果这时候client只是ACK确认了No6报文的内容(No12确认包Ack=1740381487正好是No7数据包的Seq),No11重传包只有收到Ack>=1740381493时候才会取消RTO定时器,这时候部分ACK并不能取消server在发送No11时候的定时器,最终RTO超时超时重传No13数据包,重传的时候被部分ACK确认的数据不会在重传,因为No13只是重传了No7数据包。(关于重传collapse的内容我们后面内容在进行介绍)。
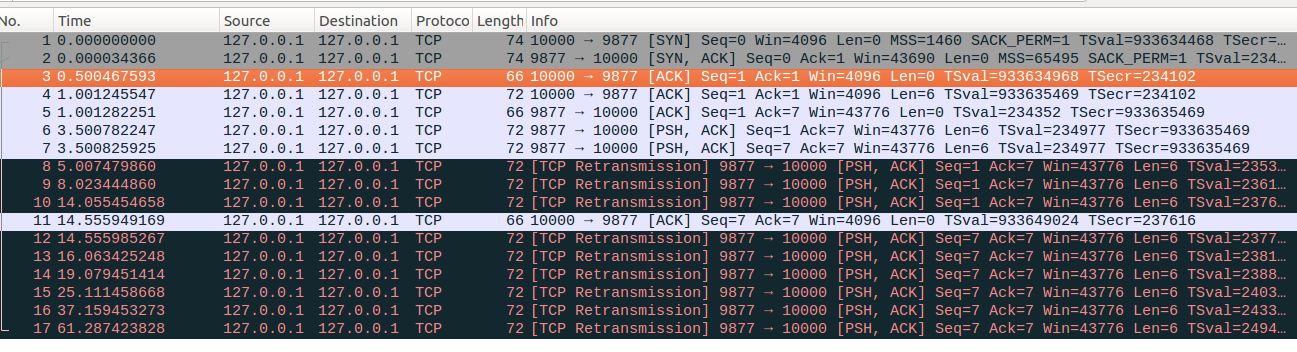
3、RTO超时重传成功后还有待重传数据。如下图所示,server端发出了No6和No7两个数据包,RTO超时后重传No6报文,No6重传成功后server端发现还有一个No7报文等待重传,接着在收到No11确认包后立即进行了一个快速重传。(严格的说应该叫做慢启动重传SlowStartRetrans,但是实际上走的是快速重传的流程,快速重传请参考后面的内容)。快速重传的同时会初始化一个RTO定时器,如果快速重传失败,接着进行RTO超时重传(No13-No17)。这里可以看到server端在发出No12报文时候初始化的RTO定时器定时时间为1.5s。也就是之前RTO指数回退的作用已经消除了,可以看到这里与协议是存在一些差异的。
4、SACK reneging下RTO超时重传的示例请参考后面SACK和FACK相关的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号