
ida-pro-mcp Quick primer
ida-pro-mcp
文章来源 https://mp.weixin.qq.com/s/Czi_hc2ch5OcxQSopb8kCg
参考 decompiler Quick primer https://docs.hex-rays.com/user-guide/decompiler/primer
参考 IDC Reference Documentation https://idc.docs.hex-rays.com/
参考 IDAPython API Reference https://python.docs.hex-rays.com/
项目地址:https://github.com/mrexodia/ida-pro-mcp
之前就看到有通过mcp进行对话控制ida工具进行程序逆向相关的文章和视频,但自己一直没去实践,今天做了一下行动派给自己mac上的ida插上了梦想的🪽,从此逆向之路从从容容、游刃有余...
1.安装python3
ida和ida-pro-mcp需要较高的python版本 我这里使用的python3.11.9
Mac上最好使用pyenv对python版本进行管理
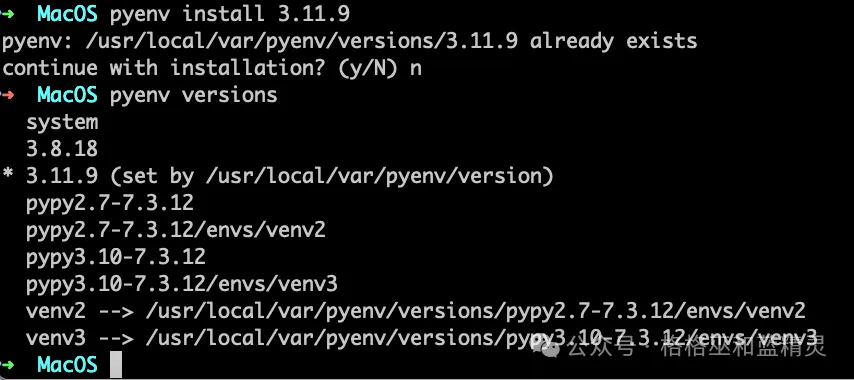
2.安装ida-pro
和其它mac上的安装软件方法一样进行下载安装(安装包已放到附件中),然后把keygen-v2.py 拷贝到这个目录下
/Applications/IDA Professional 9.2.app/Contents/MacOS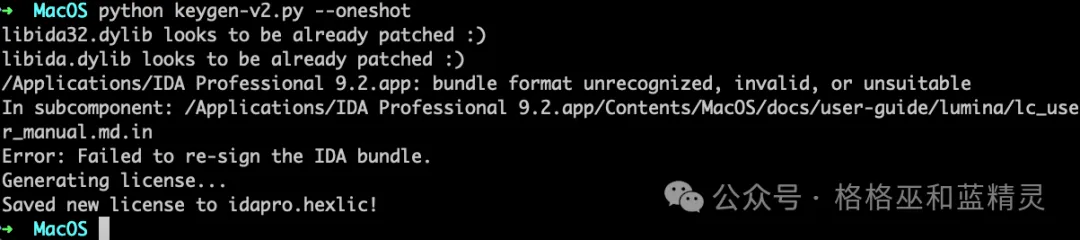
直接--oneshot参数 patch ida(部分报错信息可以无视)。这个时候你的ida就可以用了。
3.安装ida-pro-mcp
可以参考官方的安装方法 https://github.com/mrexodia/ida-pro-mcp
主要就两步
pip install https://github.com/mrexodia/ida-pro-mcp/archive/refs/heads/main.zip
pip install --upgrade git+https://github.com/mrexodia/ida-pro-mcp
ida-pro-mcp --install
model = "deepseek-chat"
model_provider = "deepseek"
[model_providers.deepseek]
name = "DeepSeek Chat Completions API"
base_url = "https://api.deepseek.com/v1"
wire_api = "chat"
requires_openai_auth = false
request_max_retries = 4
stream_max_retries = 10
stream_idle_timeout_ms = 300000
[model_providers.deepseek.http_headers]
Authorization = "Bearer sk-xxx"
[mcp_servers.ida-pro-mcp]
command = "C:\\Users\\Lenovo\\AppData\\Local\\Programs\\Python\\Python312\\python.exe"
args = [
"C:\\Users\\Lenovo\\AppData\\Local\\Programs\\Python\\Python312\\Lib\\site-packages\\ida_pro_mcp\\server.py",
"--ida-rpc",
"http://127.0.0.1:13337",
]
PS C:\Users\Lenovo\AppData\Roaming\Code\User\globalStorage\rooveterinaryinc.roo-cline> tree /a /f
文件夹 PATH 列表
| openrouter_models.json
| roo_models.json
| unbound_models.json
| vercel-ai-gateway_models.json
|
\---settings
custom_modes.yaml
mcp_settings.json
PS C:\Users\Lenovo\AppData\Roaming\Code\User\globalStorage\rooveterinaryinc.roo-cline>
PS C:\Users\Lenovo\AppData\Roaming\Code\User\globalStorage\rooveterinaryinc.roo-cline> type .\settings\mcp_settings.json
{
"mcpServers": {
"ida-pro-mcp": {
"command": "C:\\Users\\Lenovo\\AppData\\Local\\Programs\\Python\\Python312\\python.exe",
"args": [
"C:\\Users\\Lenovo\\AppData\\Local\\Programs\\Python\\Python312\\Lib\\site-packages\\ida_pro_mcp\\server.py",
"--ida-rpc",
"http://127.0.0.1:13337"
]
}
}
}
PS C:\Users\Lenovo\AppData\Roaming\Code\User\globalStorage\rooveterinaryinc.roo-cline>
资源是可浏览的IDB状态端点,提供对二进制元数据、函数、字符串和类型的只读访问。与执行作的工具不同,资源遵循类似REST的URI模式,以实现高效的数据探索。
IDB核心状态:
ida://idb/metadata- IDB 文件信息(路径、拱形、基、大小、哈希)ida://idb/segments- 带权限的内存段ida://idb/entrypoints- 入口点(主入口、TLS回调等)
代码浏览:
ida://functions- 列出所有功能(分页,可筛选)ida://function/{addr}- 按地址分类的功能详细信息ida://globals- 列表全局变量(分页,可过滤)ida://global/{name_or_addr}- 全局变量详细信息
数据探索:
ida://strings- 所有字符串(分页,可过滤)ida://string/{addr}- 地址处字符串详细信息ida://imports- 导入函数(分页)ida://import/{name}- 按名称导入详细信息ida://exports- 导出函数(分页)ida://export/{name}- 按名称导出详细信息
类型信息:
ida://types- 所有本地类型ida://structs- 所有结构/工会ida://struct/{name}- 带域的结构定义
分析上下文:
ida://xrefs/to/{addr}- 地址交叉引用ida://xrefs/from/{addr}- 地址交叉引用ida://stack/{func_addr}- 堆栈帧变量
UI状态:
ida://cursor- 当前光标位置与功能ida://selection- 当前选择范围
调试状态(调试器激活时):
ida://debug/breakpoints- 所有断点ida://debug/registers- 电流寄存器值ida://debug/callstack- 当前调用堆栈
idb_meta()获取IDB元数据(路径、模块、基址、大小、哈希值)。lookup_funcs(queries):通过地址或名称获取函数(自动检测,接受列表或逗号分隔字符串)。cursor_addr(): 获取当前光标地址。cursor_func():获取光标当前功能。int_convert(inputs):将数字转换为不同格式(十进制、十六进制、字节、ASCII、二进制)。list_funcs(queries): 列表函数(分页,过滤)。list_globals(queries): 列出全局变量(分页、过滤)。imports(offset, count): 列出所有带模块名的导入符号(分页)。strings(queries):数据库中的字符串列表(分页、过滤)。segments(): 列出所有带权限的内存段。local_types(): 列出数据库中定义的所有本地类型。decompile(addrs): 在给定地址处反编译函数。disasm(addrs): 反汇编函数,包含完整细节(参数、栈框架等)。xrefs_to(addrs)获取所有地址交叉引用。xrefs_to_field(queries): 获取对特定结构字段的交叉引用。callees(addrs): 获得由函数在地址调用的函数。callers(addrs):获得调用地址处函数的函数。entrypoints():获取所有程序入口。
set_comments(items): 在反汇编和反编译视图中,在地址处设置注释。patch_asm(items): 地址处的配线组装说明。declare_type(decls):在本地类型库中声明C类型。
get_bytes(addrs):在地址处读取原始字节。get_u8(addrs): 读8位无符号整数。get_u16(addrs): 读16位无符号整数。get_u32(addrs): 读取32位无符号整数。get_u64(addrs): 读64位无符号整数。get_string(addrs):读取空端字符串。get_global_value(queries):通过地址或名称读取全局变量值(自动检测,编译时值)。
stack_frame(addrs):获取函数的堆栈框架变量。declare_stack(items):在指定的偏移量处创建栈变量。delete_stack(items): 按名称删除栈变量。
structs(): 列出所有已定义的结构及其成员。struct_info(names):获取关于结构的详细信息。read_struct(queries):读取特定地址的结构字段值。search_structs(filter):按名称模式搜索结构。
dbg_regs():获取所有线程的所有寄存器。dbg_regs_thread(tids): 获取特定线程的所有寄存器。dbg_regs_cur(): 获取当前线程的所有寄存器。dbg_gpregs_thread(tids): 获取线程的通用寄存器。dbg_current_gpregs():获取当前线程的通用寄存器。dbg_regs_for_thread(thread_id, register_names): 为线程获取特定的寄存器。dbg_current_regs(register_names): 获取当前线程的专用寄存器。dbg_callstack()获取包含模块和符号信息的调用栈。dbg_list_bps(): 列出所有断点及其状态。dbg_start(): 启动调试进程。dbg_exit(): 退出调试器进程。dbg_continue(): 继续调试器执行。dbg_run_to(addr): 将调试器运行到特定地址。dbg_add_bp(addrs): 在地址处添加断点。dbg_step_into():请上课。dbg_step_over():越过指令。dbg_delete_bp(addrs): 删除地址处的断点。dbg_enable_bp(items): 启用或禁用断点。dbg_read_mem(regions):从调试进程读取内存。dbg_write_mem(regions):将内存写入调试进程。
py_eval(code):在IDA上下文中执行任意Python代码(返回dict,带result/stdout/stderr,支持Jupyter风格的评估)。analyze_funcs(addrs):全面的函数分析(反编译、汇编、xref、callee、调用者、字符串、常数、基本块)。
find_bytes(patterns, limit=1000, offset=0):查找二进制字节模式(例如,“48 8B ?? ??”)。最大上限:10000。退货或 。cursor: {next: N}{done: true}find_insns(sequences, limit=1000, offset=0):在代码中查找指令序列。最大上限:10000。退货或 。cursor: {next: N}{done: true}find_insn_operands(patterns, limit=1000, offset=0):找到具有特定作数值的指令。最大上限:10000。退货或 。cursor: {next: N}{done: true}search(type, targets, limit=1000, offset=0):高级搜索(即时值、字符串、数据/代码引用)。最大上限:10000。退货或 。cursor: {next: N}{done: true}
basic_blocks(addrs):获取带有继任和前任的基础方块。find_paths(queries): 查找源地址与目标地址之间的执行路径。
apply_types(applications):将类型应用于函数、全局变量、局部变量或栈变量。infer_types(addrs):在地址处使用六角射线或启发式推断类型。
export_funcs(addrs, format): 导出指定格式(json、c_header或原型)的函数。
callgraph(roots, max_depth):从根函数构建调用图,并可配置深度。
rename(batch):功能、全局变量、本地变量和栈变量的统一批次重命名作(接受带有可选键的dict)。funcdatalocalstackpatch(patches):一次修补多个字节序列。
xref_matrix(entities):构建多个地址之间的交叉参考矩阵。
analyze_strings(filters, limit=1000, offset=0):分析字符串,进行模式匹配、长度过滤和xref信息。最大上限:10000。退货或 。cursor: {next: N}{done: true}
主要特色:
- 类型安全API:所有函数都使用强类型参数和TypedDict模式,以更好地支持IDE和LLM结构化输出
- 批处理优先设计:大多数作既接受单个项目,也接受列表
- 错误处理一致:所有批处理返回
[{..., error: null|string}, ...] - 基于光标的分页:搜索功能返回或(默认限制:1000,强制最大10000以防止代币溢出)
cursor: {next: offset}{done: true} - 性能:字符串通过基于MD5的失效缓存,以避免在大型项目中重复调用
build_strlist
之后打开ida ,注意需要打开任意一个程序。在edit->plugins 就能看到MCP了
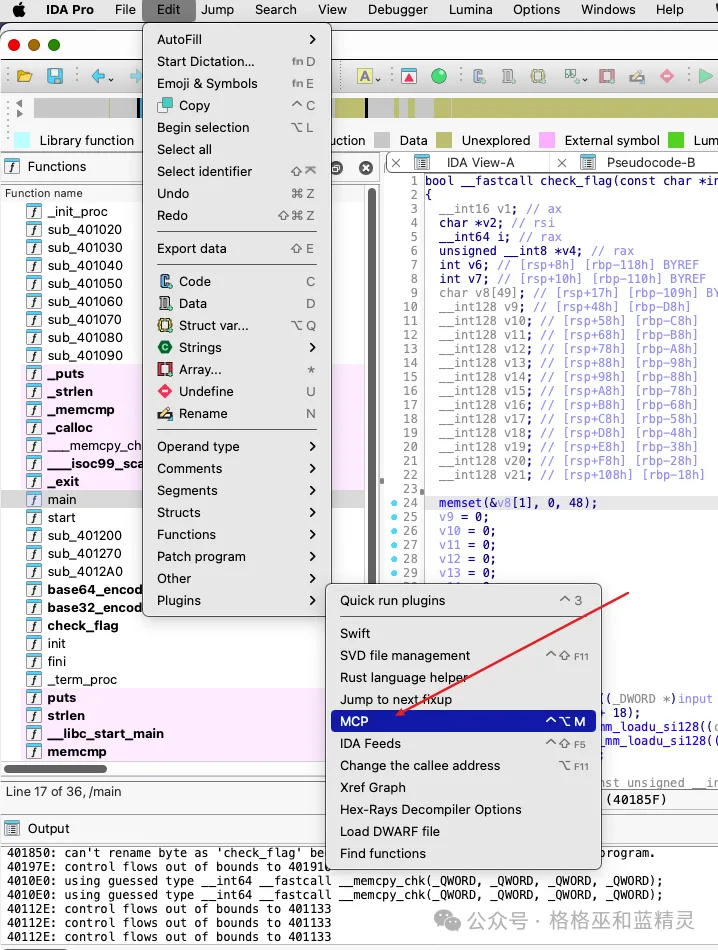
点击一下 会开启如下的server

4.安装MCP Client
ida-pro-mcp支持的client 有很多,比如VScode、claude、Cline、Cursor、Trae、CodeX等。
因为氪金了chatgpt,所以这里就首选chatgpt来作为我的大语言模型( Large Language Model ),准确来说应该叫做 代码导向大语言模型(Code-optimized LLM)。
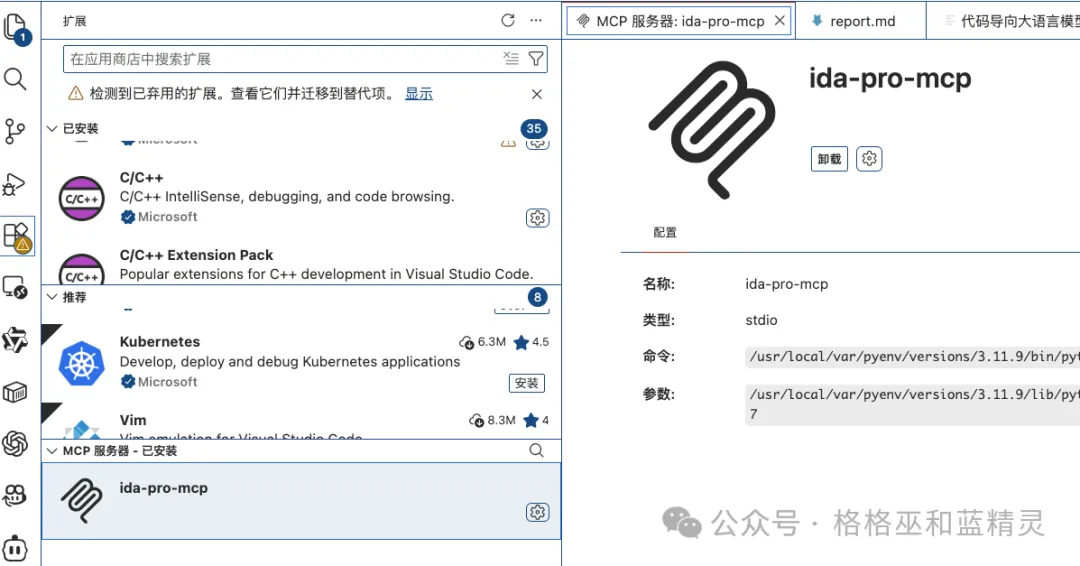
在vscode中安装Codex插件
登录自己的OpenAI账号。就可以使用了(安装ida-pro-mcp的时候已经自动写入到一些常见工具配置文件中了),也可以通过 ida-pro-mcp --config查看配置文件,在客户端中配置相应的mcp server
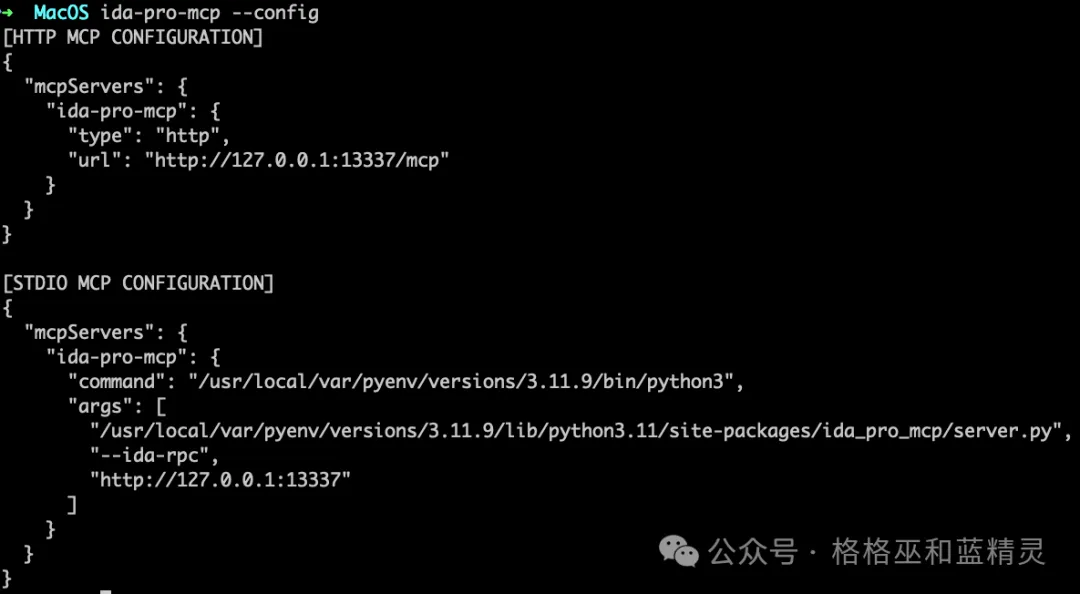
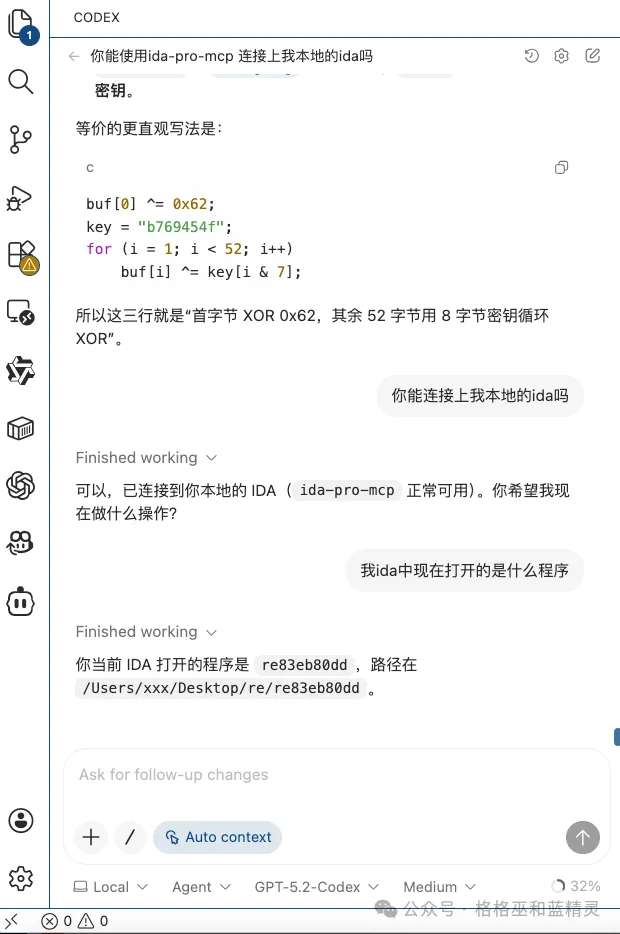
可以在对话中输入相关进行测试是否已经正常配置。
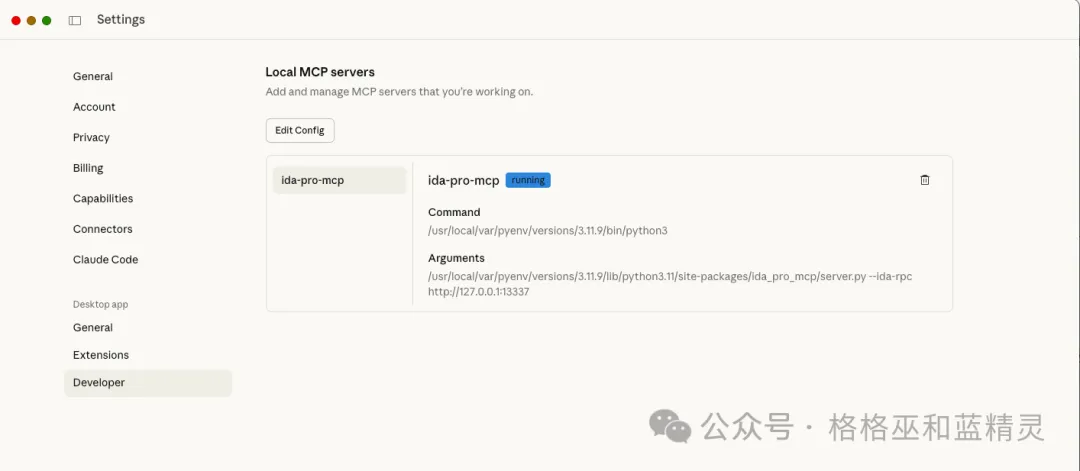
当然这里也可以使用claude,打开设置 就能看到默认已经添加了ida-pro-mcp,如果没有添加话就手动添加一下。
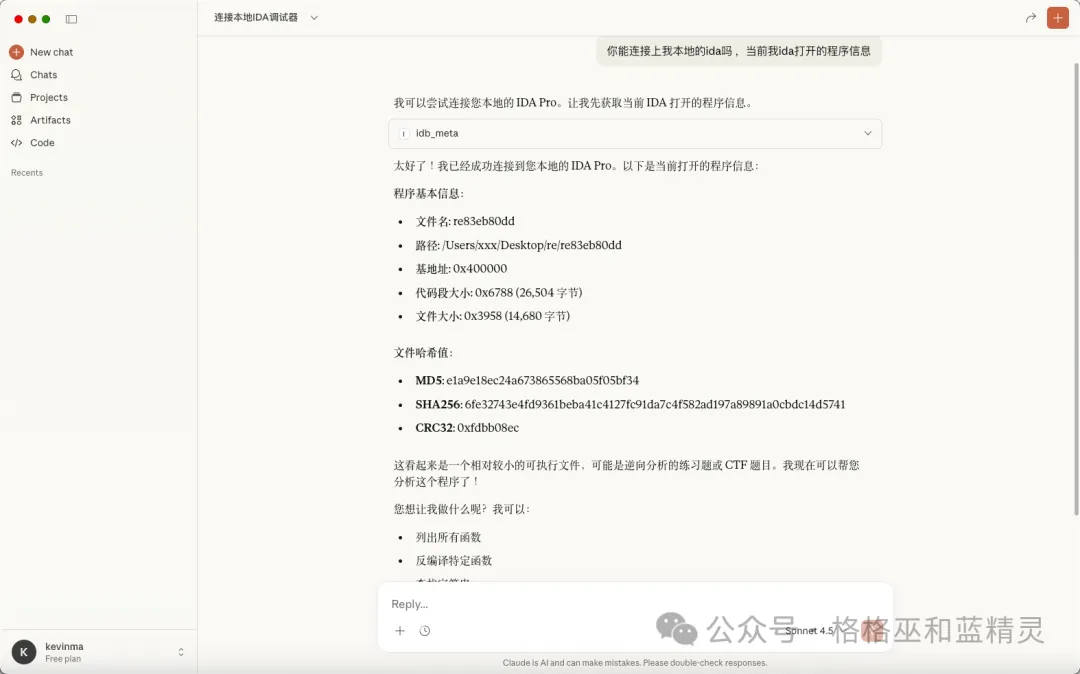
5.实战(愉快😀的玩耍)
拿一道稍复杂点儿ctf逆向题来测试一下效果如何。关于提示词promot的话可以参考官方给的 ,也可以把官方的做一下翻译
你的任务是在 IDA Pro 中分析打开程序。你可以使用 MCP 工具(如 ida-pro-mcp)来获取反编译、反汇编和程序结构信息。请严格按照以下逆向分析策略执行:1. 首先检查 IDA 的反编译结果(F5 输出),结合语义理解代码逻辑,并在关键位置添加注释。2. 将无意义的变量名(如 v1、v3、a1 等)重命名为具有实际语义的名称。3. 如有必要,修改变量和函数参数的类型,尤其是指针、数组和结构体类型,以提高代码可读性。4. 将函数重命名为能够准确描述其行为的名称(例如校验函数、解密函数、初始化函数等)。5. 当反编译信息不足或存在歧义时,请查看对应的反汇编代码,并基于汇编指令补充注释和分析结论。6. 绝对不要自行进行任何数字进制转换(例如十六进制转十进制),如有需要,必须使用 int_convert MCP 工具。7. 禁止尝试任何形式的暴力破解,所有结论必须通过反汇编逻辑分析和必要的简单 Python 推导脚本得出。8. 分析过程中请始终关注:- 输入数据的来源与长度- 校验逻辑与失败分支- 字符串处理、循环结构、状态机或加密/混淆逻辑9. 在分析完成后,请生成一个 report.md 文件,内容包括:- 程序整体结构概览- 关键函数说明(含重命名理由)- 校验/解密流程的完整逻辑说明- 得出最终结论的推导过程10. 当你推导出最终密码或 flag 后,请将结果提交给用户,并询问用户是否确认该结果正确。请以“逆向工程师”的视角进行分析,避免臆测、过度抽象或脱离汇编语义的解释。
如果是恶意样本逆向分析的话,也可以让ai帮你生成一段或者网上搜索一下
一分钟左右就把正确的flag获取到了并输出了相应的文档。


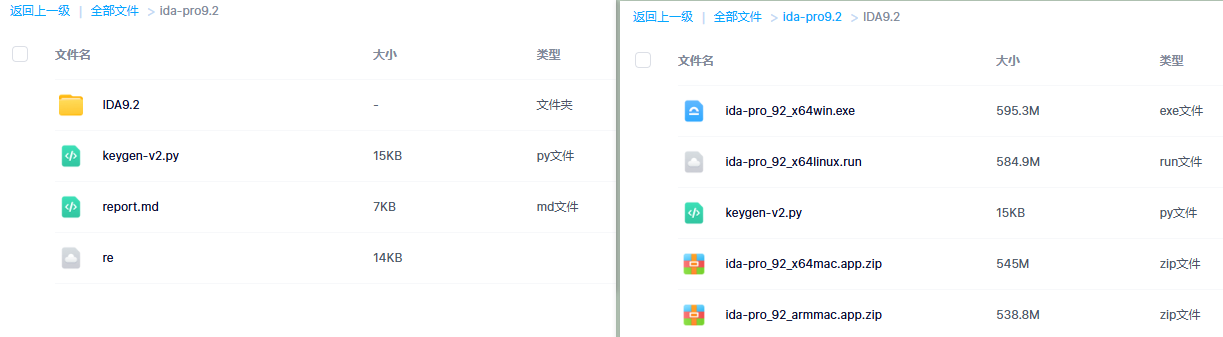
逆向源程序和完整报告见附件。
可能是因为没有氪金的原因,在对claude使用Sonnet4.5模型做了测试没跑出正确的flag。
其它
本文分享了在Mac操作系统下关于ida-pro-mcp的安装和使用,关于在windows平台下的安装和使用也是类似,大家可以自行探索。
========= End

 浙公网安备 33010602011771号
浙公网安备 33010602011771号