
Git 从来就不是为版本控制而生的
Git 从来就不是为版本控制而生的
来源 https://zhuanlan.zhihu.com/p/1920771131306149190
真相往往被忽略
很多人并不清楚:Git 起初并不是用来做版本控制的。
它是一个分布式文件系统,只不过具备了非常强的内容追踪能力。 这也解释了为何无数开发者苦苦挣扎——我们正在用一辆法拉利送外卖。
Git 的真实架构
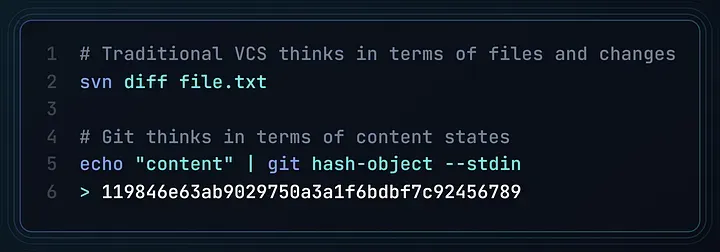
理解这一点之后,你对 Git 的认知将会改写。
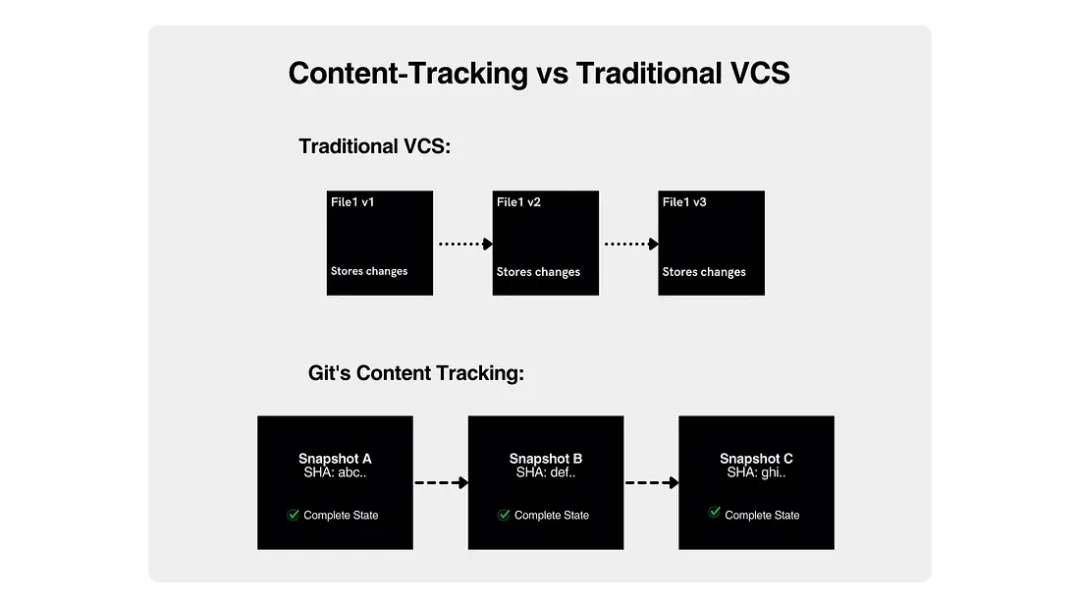
比如,那些神秘的 SHA-1 哈希,并不是“版本编号”,而是内容地址;.git 目录里并不是存储的“变更”,而是你文件系统的完整快照。
仓库的本质结构与核心对象类型
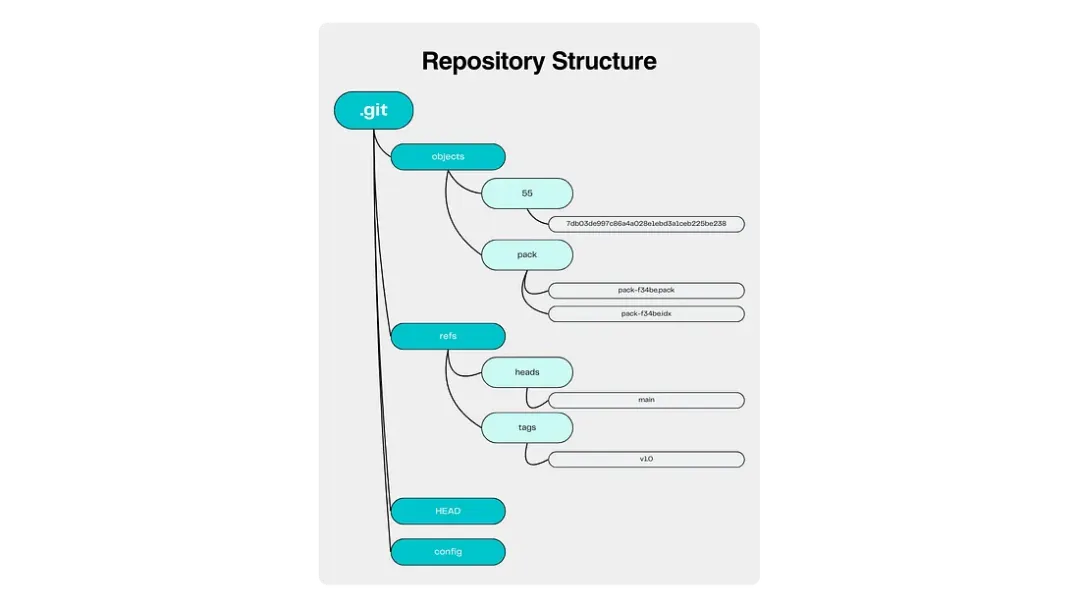
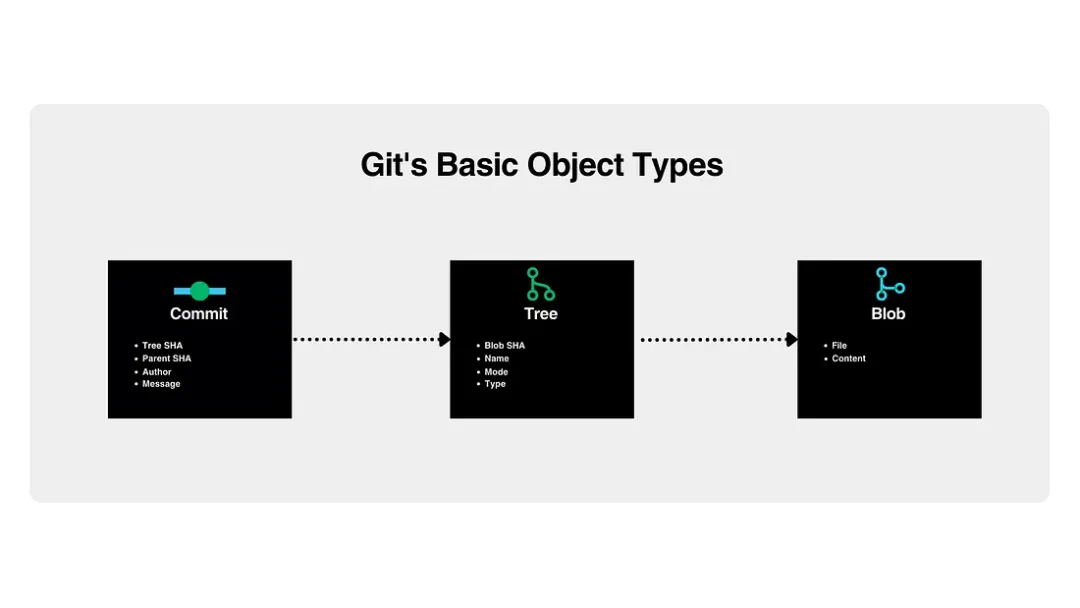
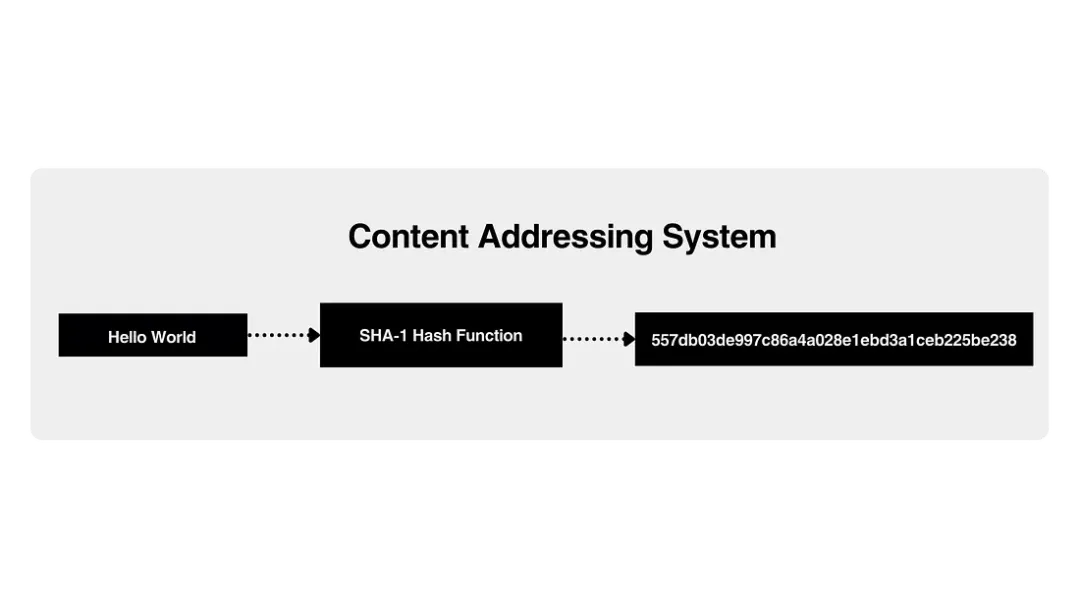
Git 实际上就是一个有内容地址索引机制的高级文件系统,只是它附带了部分版本控制的特性。
那些看不见的代价
前不久,看到大佬为一家世界500强企业做 Git 性能咨询。他们的 mono-repo 已经膨胀至 50GB,一次 git pull 需要 15 分钟。
问题出在哪?他们在用 Git 做版本控制,而不是内容跟踪器。
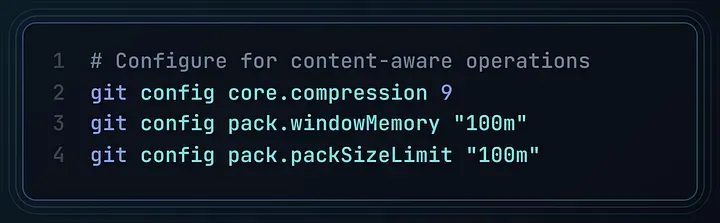
他们做了以下优化前后的对比:
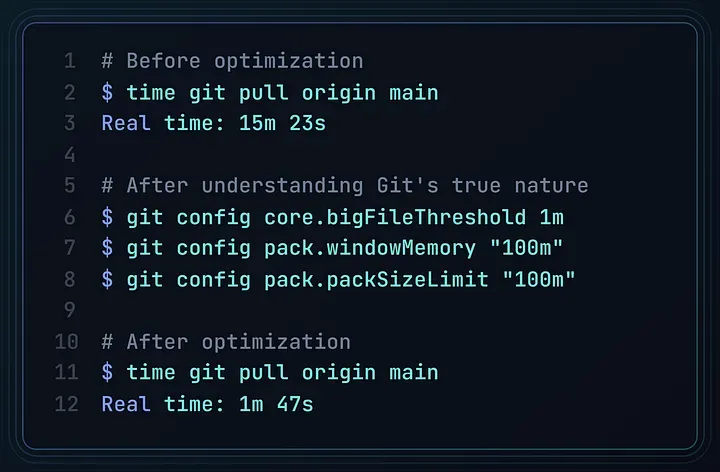
结果?仅仅是顺着 Git 的“天性”来使用它,性能就提升了 **88%**。
Git 是文件系统,不是传统意义的版本控制
深入理解其内部机制,你会发现:
Git 把所有东西都视作对象来存储。 这不是在做版本管理,而是在构建一个可寻址的快照系统。
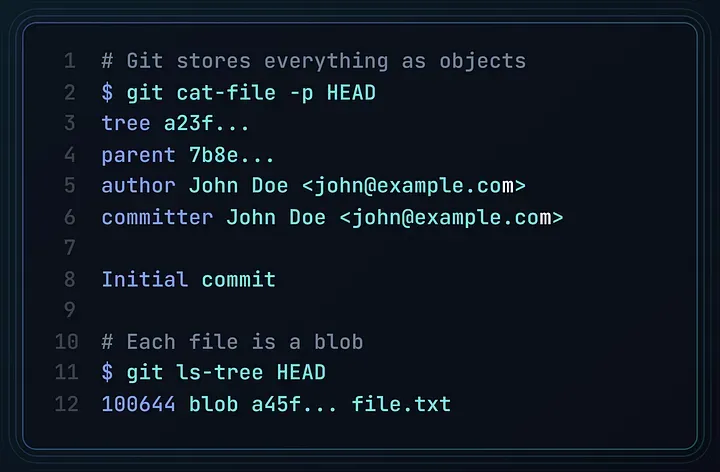
现实中会发生什么?
最近,大佬为一家初创公司提供技术协助。他们试图用 Git 来管理大型机器学习模型。但结果是:
- 提交卡顿
- 仓库越来越庞大
- 团队协作困难
我们换了个思路,把 Git 当作内容追踪工具,而非传统版本库。
错误方式:
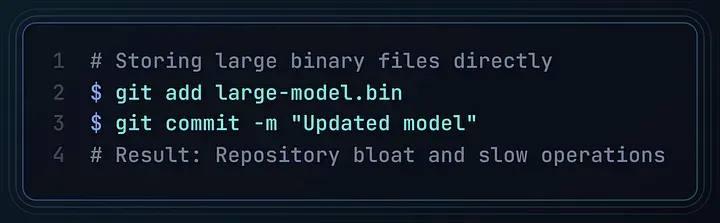
直接将大型二进制文件加入版本库
正确方式:
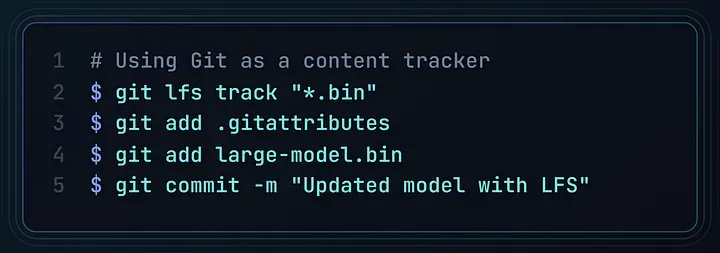
借助 Git 的内容地址管理特性,配合 Git LFS 存储大文件
最终,他们的仓库大小下降了 **70%**,克隆时间从 45 分钟缩短至 3 分钟。
Git 的隐藏能力,很多人从未使用
Git 有很多被忽略的强大功能,原因是我们一直用它来“控制版本”,却忽略了它的“内容追踪能力”:
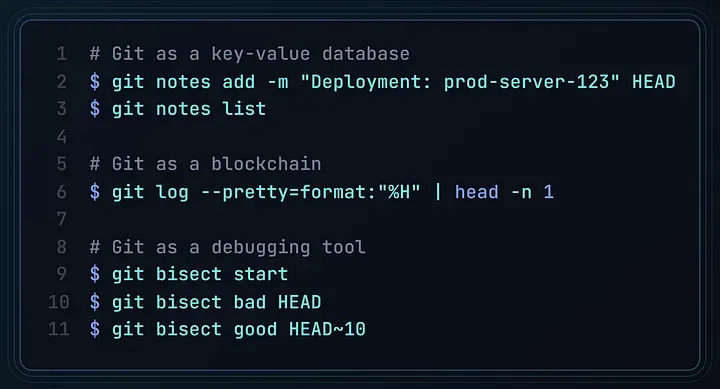
现代开发中的误区
我们当前的一些开发习惯,其实正好违背了 Git 的核心理念:
- CI 流程:每次提交都触发构建,默认 Git 是版本线性管理器
- 微服务架构:把仓库拆分,而 Git 其实天生适合追踪大型仓库
- 二进制资产:让 Git 处理它不擅长的东西
真正该做的:顺势而为
与其反抗,不如顺应 Git 的设计哲学:
用“状态”思维取代“变更”思维
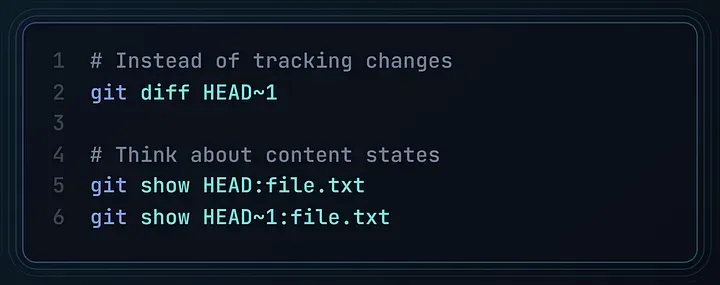
充分利用内容追踪能力
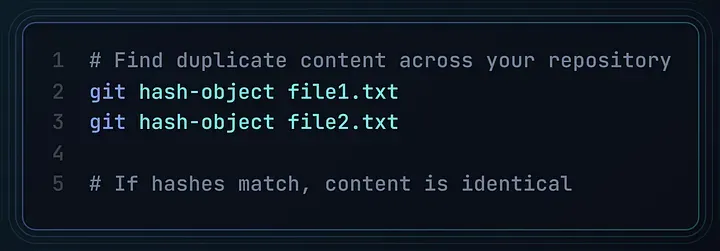
发挥文件系统级特性
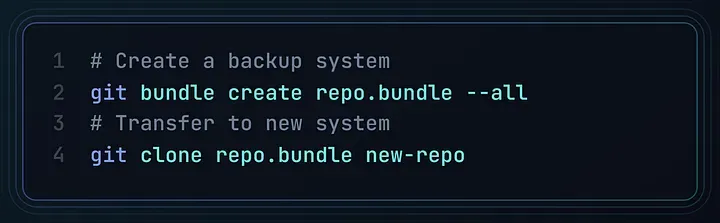
这些理解,不只是写法的改变,更是认知的转变。
未来的可能性
理解 Git 的真正架构后,我们可以预见一系列发展方向:
- 基于内容的开发流程
- 区块链式的完整性校验
- 分布式内容管理系统
- 全新代码存储与协作模型
实用落地建议
审视你当前的 Git 使用方式

- 是否把它当成了 SVN 替代品?
- 是否用它去追踪不该追踪的东西?
- 是否频繁使用 rebase 只是为了“整洁”?
实施改进方案:
- 每次提交都思考“状态是否合理”
- 用 SHA 校验内容完整性
- 使用 Git LFS 管理大文件
- 使用
git notes存储元数据,避免污染 commit 历史
最后
Git 本质是一个内容追踪器,恰好也具备版本控制能力。 但如果你错把它当成纯粹的版本管理工具,就等于浪费了它最强大的那一部分。
理解这个真相后,Git 将不再是那个“难懂的工具”,而是你真正的开发助手。
============== End

 浙公网安备 33010602011771号
浙公网安备 33010602011771号