
Python3+mitmproxy安装使用教程(Windows)
一、安装
1.1 安装mitmproxy
直接使用pip安装即可
pip install mitmproxy
pip本质上会一是安装mitmproxy库的相关代码,二是安装mitmproxy.exe/mitmdump.exe/mitmdump.exe三个可执行程序。
可执行程序被安装在$PYTHON_HOME/Scripts文件夹下,如果是conda版本的python那可以用以下命令来查看当前使用的是哪个环境。
conda env list

1.2 安装证书
和burpsuite类似mitmproxy默认只能拦截http,想要拦截https那就需要安装证书。
首先到$PYTHON_HOME/Scripts目录下运行一下mitmdump,完成之后在用户家目录下的.mitmproxy文件夹下即会生成证书,传到手机点击安装即可。

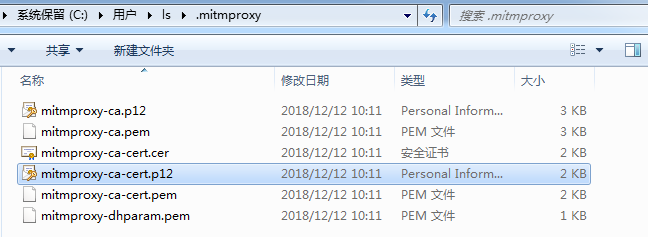
mitmproxy-ca.p12----PKCS12格式证书私钥
mitmproxy-ca.pem----PEM格式证书私钥
mitmproxy-ca-cert.cer----PEM格式证书,与mitmproxy-ca-cert.pem相同只是改变了后辍,适用于部分Android
mitmproxy-ca-cert.p12----PKCS12格式证书,适用于Windows
mitmproxy-ca-cert.pem----PEM格式证书,适用于大多数非Windows平台
mitmproxy-dhparam.pem----PEM格式秘钥文件,用于增强SSL安全性
Windows安装证书:双击mitmproxy-ca-cert.p12----全部默认直接点“下一步”直到安装完成。
Android安装证书:把mitmproxy-ca-cert.cer通过usb复制到手机上----点击使用证书安装器安装证书(通过qq发送到手机上时提示无法读取证书不懂什么原因)
二、网络代理配置
2.1 确保手机和电脑处于同一局域网
运行mitmproxy的电脑和运行目标app的手机要同处一个局域网才能进行代理。
如果是有笔记本那么笔记本和手机同连到一个路由器上,或者在笔记本上开启一个wifi然后用手机连上去,或者用Genymotion等模拟器运行app在模拟器设置代理,这三个方法都可以。
但如果是没有无线网卡的台式机那似乎只能使用模拟器,要用其他两种方法那得外接一个usb式无线网卡。
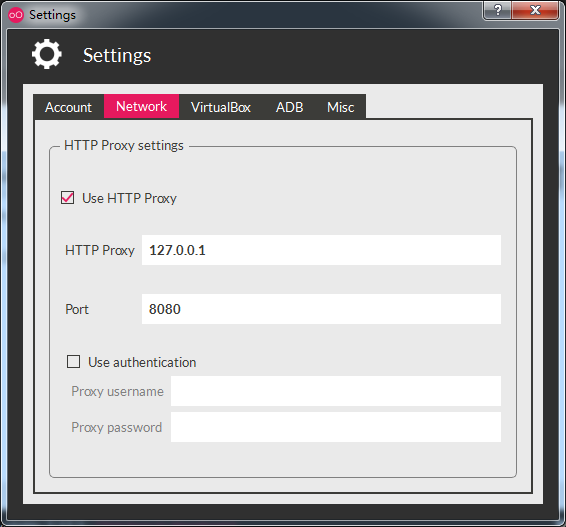
我这里用的方法是台式机外接无线网卡使用360开启一个wifi手机连上去,台式机ip为172.30.195.1手机ip为172.30.195.2。
2.2 电脑启动代理
我这里是windows,mitmproxy.exe并不支持windows,但这并没有很大关系,mitmproxy.exe本质就是一个窗口式的burpsuite的proxy+repeater。
如果要拦包改包我们用burpsuite更加好,用mitmproxy的意义在于代码能获取数据包,而这个功能是由mitmdump实现只要mitmdump.exe可运行即可。

和1.2一样启动mitmdump.exe
mitmdump.exe
2.3 手机配置代理
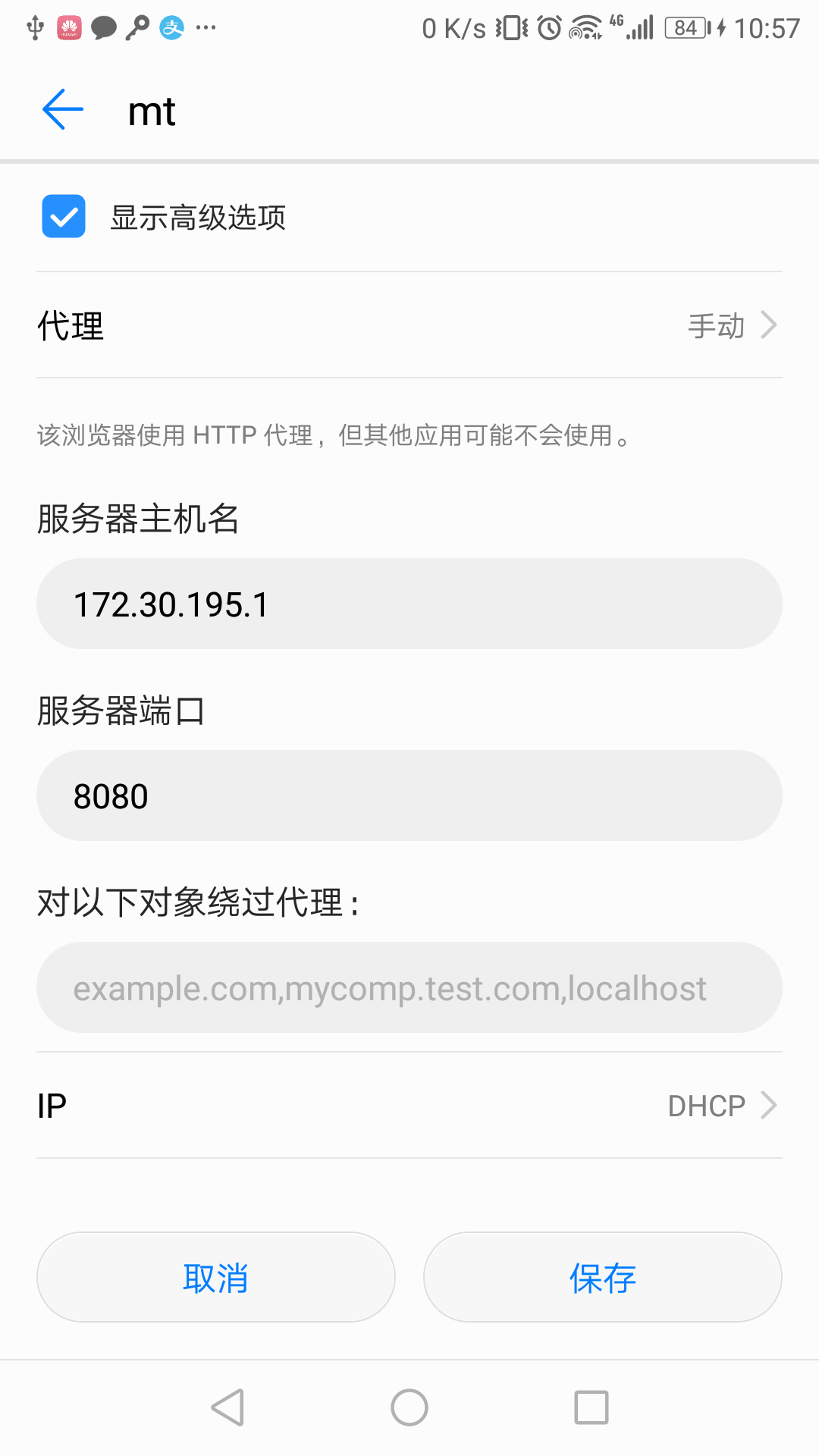
手机配置代理大同小异都在设置之中进行配置。比如我这里的路径是:
设置----无线和网络WLAN----长按wifi名----修改网络----显示高级选项----代理----手动---服务器主机名输入172.30.195.1(根据自己电脑ip修改)服务器端口输入8080----保存
2.4 代理效果查看
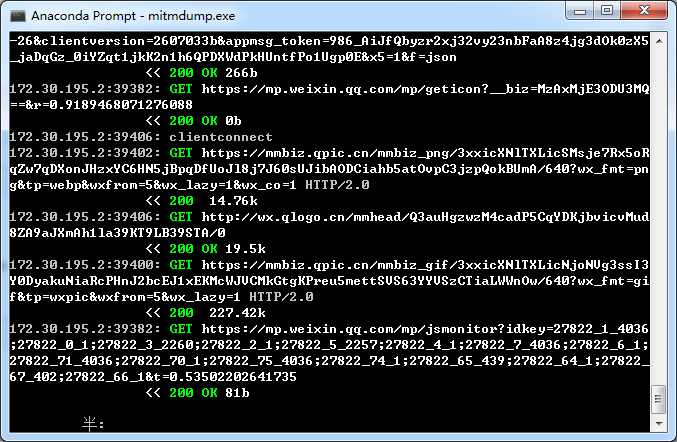
完成后在启动mitmdump.exe的代理窗口上即可看到手机发送的所有数据包。
三、Python3使用mitmproxy
我们前边2.2也提到使用mitmproxy的根本目的是想要python能修改发送的数据包,及截获服务端返回的数据包。只是像2.4那样打印出所有发送的请求对我们的目的而言是没有什么用的。
python接触发送数据包的途径是在启动mitmdump启动时使用-s选项指定处理脚本,其中通过重写request方法处理请求数据包,通过重写response方法处理响应数据包。示例如下。
启动命令:
mitmdump.exe -s example_script.py
exampl_script.py内容:
from mitmproxy import ctx # 所有发出的请求数据包都会被这个方法所处理 # 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可 def request(flow): # 获取请求对象 request = flow.request # 实例化输出类 info = ctx.log.info # 打印请求的url info(request.url) # 打印请求方法 info(request.method) # 打印host头 info(request.host) # 打印请求端口 info(str(request.port)) # 打印所有请求头部 info(str(request.headers)) # 打印cookie头 info(str(request.cookies)) # 所有服务器响应的数据包都会被这个方法处理 # 所谓的处理,我们这里只是打印一下一些项 def response(flow): # 获取响应对象 response = flow.response # 实例化输出类 info = ctx.log.info # 打印响应码 info(str(response.status_code)) # 打印所有头部 info(str(response.headers)) # 打印cookie头部 info(str(response.cookies)) # 打印响应报文内容 info(str(response.text))

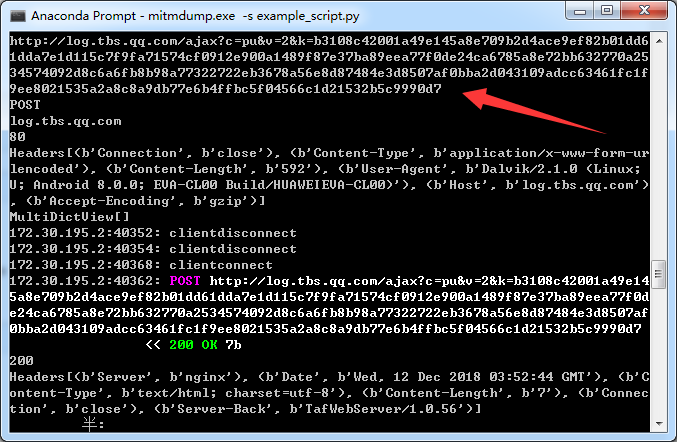
如图箭头所指处正是经request方法处理,依次输出请求url、请求方法、host头、请求端口、所有头部及cookies
四、评述
我们在电脑上写爬虫,关键操作是找到请求url、制定请求数据包、解析返回结果。
从这个角度出发对app我们根本需要的似乎其实只是拦截请求数据包和响应数据包、分析他们的格式,没必要从app发出和接收数据包。
也就是似乎用burpsuite代理并进行数据包分析就完了,mitmproxy没什么用(?)。
参考:
崔庆才----《Python3网络爬虫开发实战》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号