04【事务原理、MVCC】
第1章 事务基础
1.1 事务四大特性
| 事务特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是工作的最小单元,整个工作单元要么全部执行成功,要么全部执行失败 |
| 一致性(Consistency) | 事务执行前与执行后,数据库中数据应该保持相同的状态。如:转账前总金额与转账后总金额相同。 |
| 隔离性(Isolation) | 事务与事务之间不能互相影响,必须保持隔离性。 |
| 持久性(Durability) | 如果事务执行成功,对数据库的操作是持久的。 |
1.2 事务隔离级别
MySQL中可以有两种方式进行事务的操作:
- 1)手动提交事务
- 2)自动提交事务(MySQL默认)
查看当前MySQL是否是自动提交事务:
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
No(1):开启自动提交事务(默认值)
OFF(0):关闭自动提交事务
- 设置手动提交事务(关闭自动提交事务):
set autocommit=0; -- 本次会话有效
set global autocommit=0; -- 服务器只要不关闭一直有效(需要重启会话)
设置会话级别手动提交事务:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
并发访问下事务产生的问题:
当同时有多个用户在访问同一张表中的记录,每个用户在访问的时候都是一个单独的事务。
事务在操作时的理想状态是:事务之间不应该相互影响,实际应用的时候会引发下面三种问题。应该尽量避免这些问题的发生。通过数据库本身的功能去避免,设置不同的隔离级别。
- 脏读: 一个事务(用户)读取到了另一个事务没有提交的数据
- 不可重复读:一个事务多次读取同一条记录,出现读取数据不一致的情况。一般因为另一个事务更新了这条记录而引发的。
- 幻读:在一次事务中,多次读取到的条数不一致
四种隔离级别:
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
四种隔离级别起的作用:
Serializable(串行化): 可以避免所有事务产生的并发访问的问题 效率及其低下Repeatable read(可重复读):简称RR,会引发幻读的问题(InnoDB某些情况下已经解决)Read committed(读已提交):简称RC,会引发不可重复读和幻读的问题Read uncommitted(读未提交):简称RU,所有事务中的并发访问问题都会发生
- 查询全局事务隔离级别
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
mysql>
修改隔离级别:
set session transaction isolation level read uncommitted; -- 本次会话有效(重启客户端就失效)
set global transaction isolation level read uncommitted; -- 服务器只要不关闭一直有效(需要重启客户端才能生效)
修改隔离级别后需要重启会话
1.3 事务并发访问的问题
1.3.1 脏读
在并发情况下,一个事务读取到另一个事务没有提交的数据,这个数据称之为脏数据,此次读取也称为脏读。
我们知道,只有read uncommitted(读未提交)的隔离级别才会引发脏读。
- 将MySQL的事务隔离级别设置为
read committed(读已提交):
mysql> set session transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)
测试表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB ;
INSERT INTO `user`(`id`, `name`, `age`) VALUES (1, 'zs', 20);
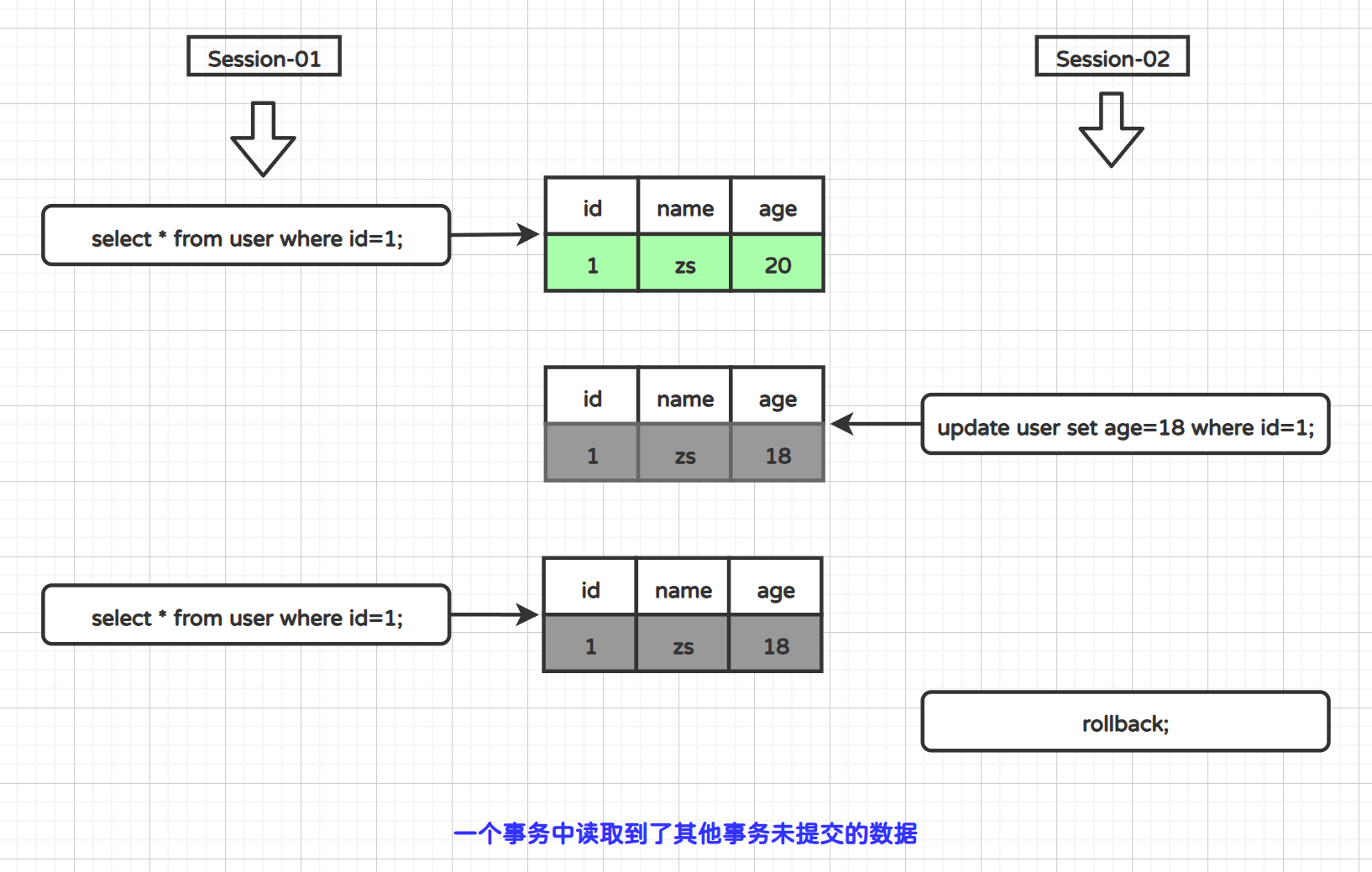
为了解决脏读,我们可以将隔离级别设置高级一点(read committed)
1.3.2 不可重复读
在一次事务中,多次读取到数据信息不一致;
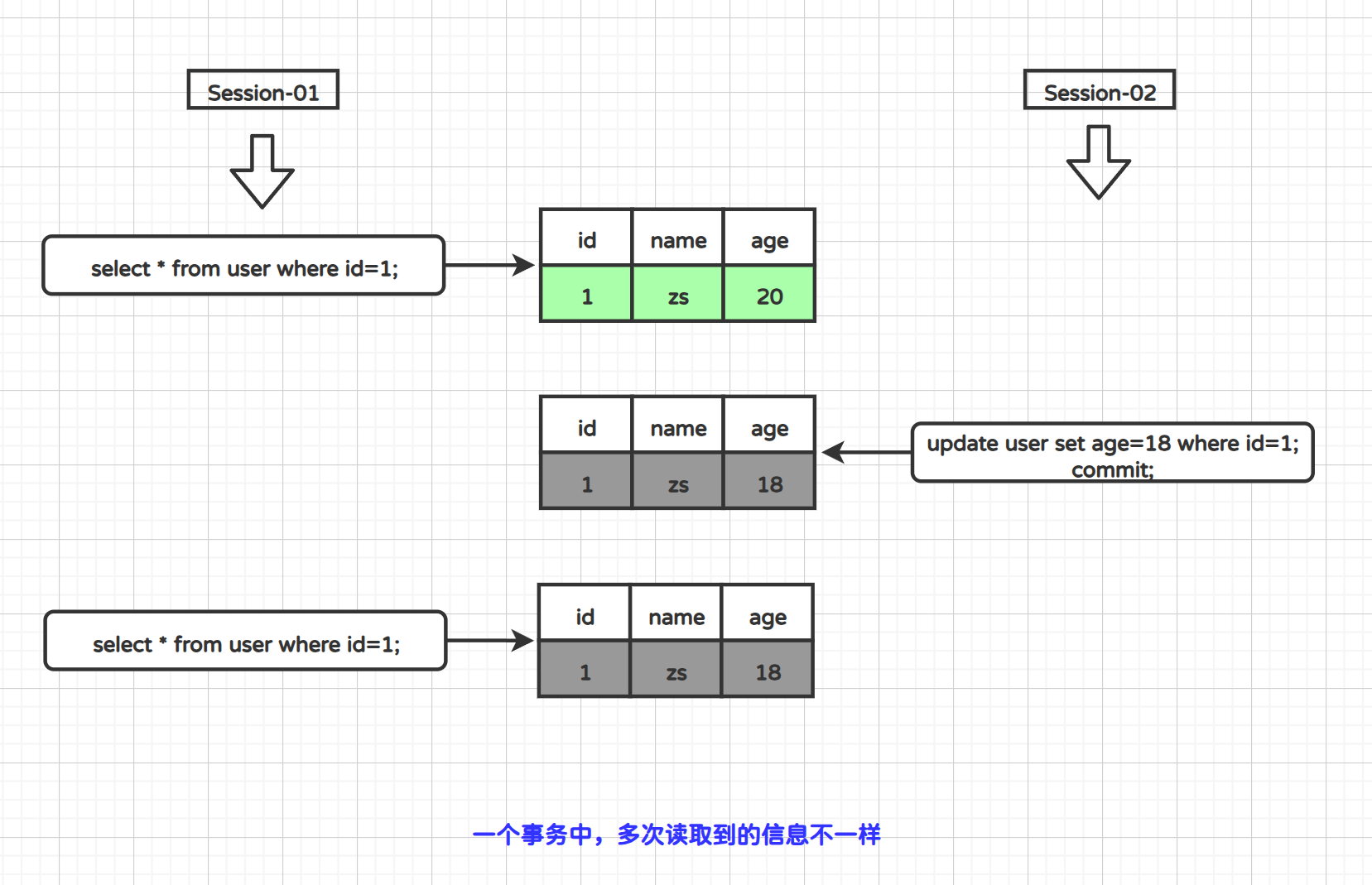
在上面案例中,session-01窗口两次查询id=1的数据都不一致。
Tips:解决不可重复读的方法就是将隔离级别再设置高级一点(
repeatable read)
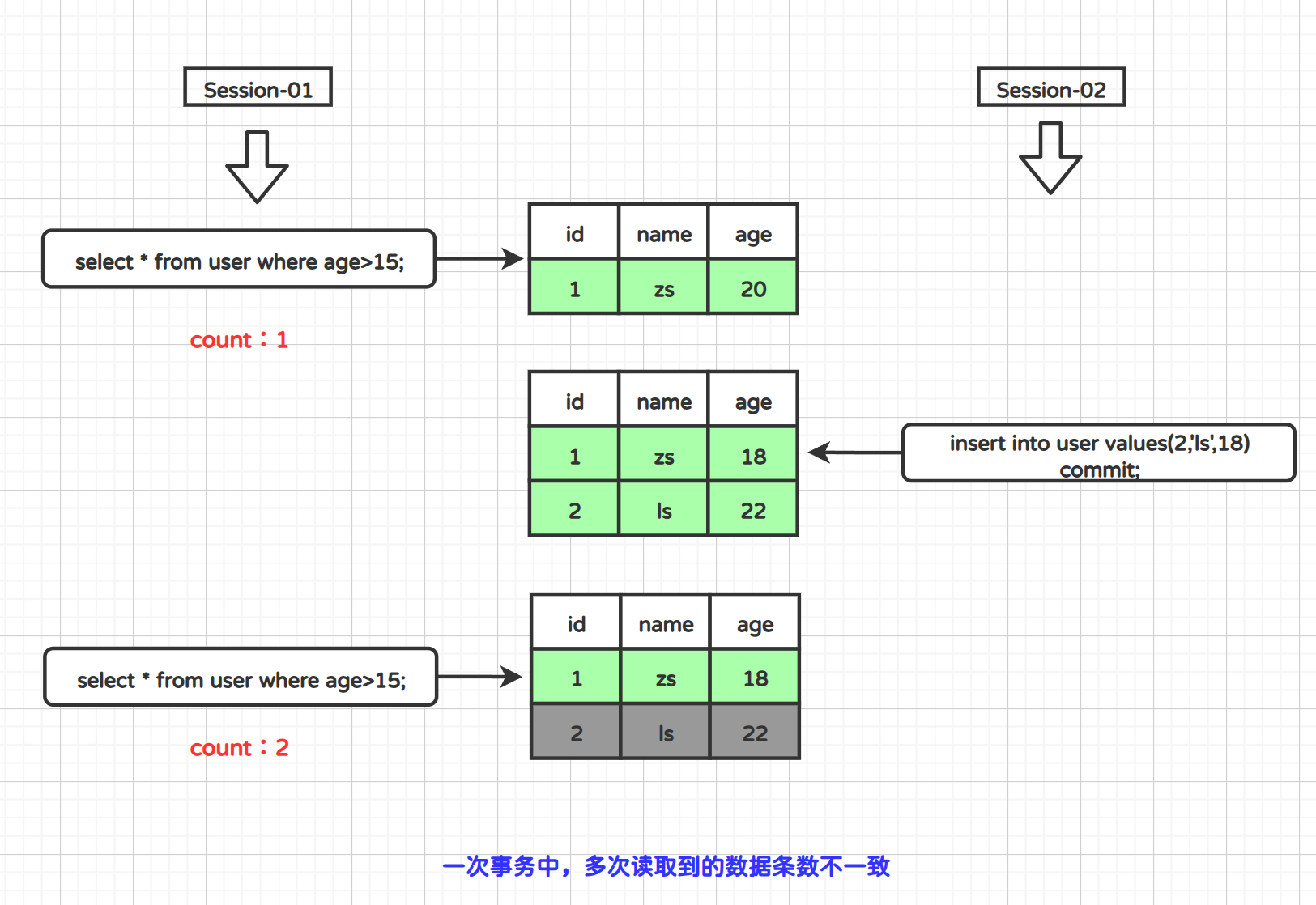
1.3.3 幻读
在一次事务中,多次读取到的条数不一致,但是在InnoDB中,幻读问题已经被解决了。
我们来看看幻读的现象:
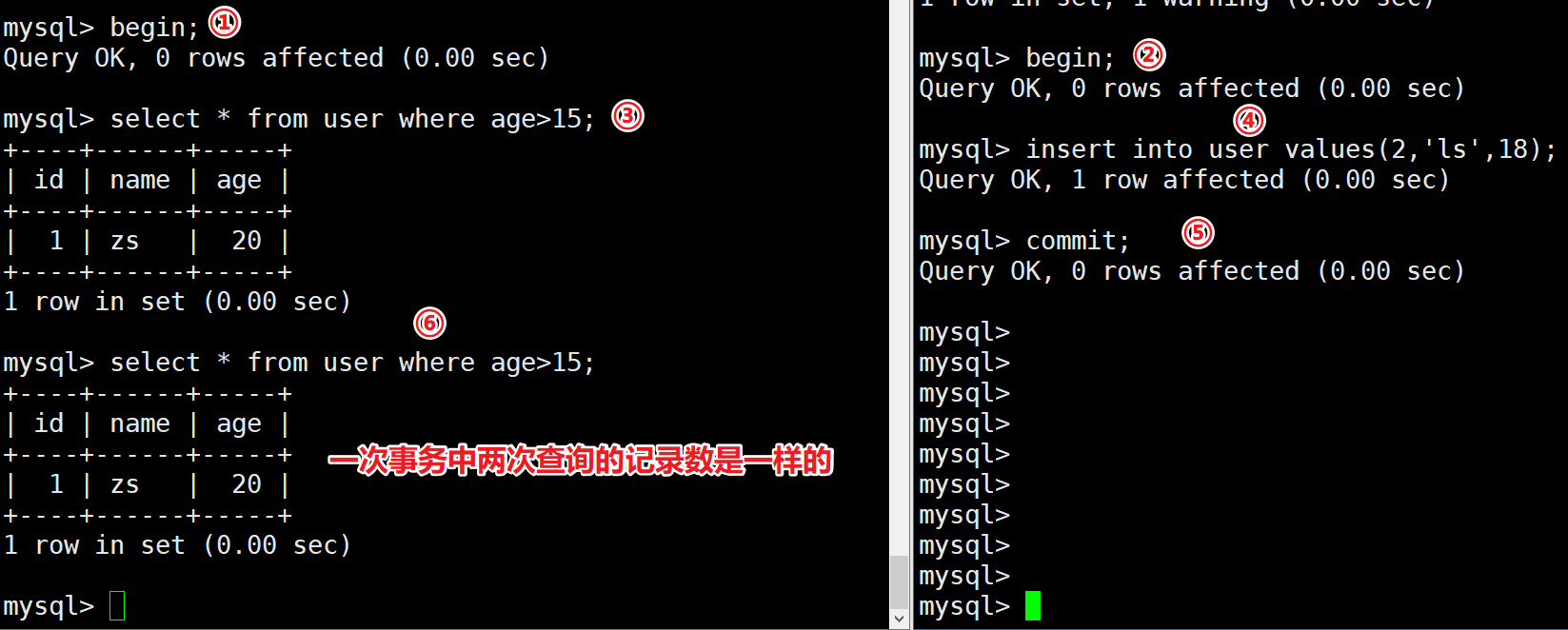
在InnoDB中,RR隔离级别可以解决幻读的问题:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from user where age>15; | |
| insert into user values(2,'ls',18); | |
| commit; | |
| select * from user where age>15; |
1.4 SQL标准
SQL标准是由国际标准化组织(ISO)和美国国家标准协会(ANSI)制定的一系列规范,用于定义结构化查询语言(SQL)的语法、功能和行为。SQL是用于管理和操作关系型数据库的标准语言,而SQL标准则确保不同数据库系统在实现SQL时具有一致性和兼容性。
SQL标准从1986年首次发布(SQL86)开始,经历了多个版本的更新(如SQL92、SQL99、SQL2003等),每个版本都在前一版本的基础上扩展功能,以适应不断变化的数据库需求。
SQL标准的核心特性包括:
- 数据定义语言(DDL):用于定义和管理数据库对象(如表、视图、索引等)。
- 数据操作语言(DML):用于查询和操作数据(如
SELECT、INSERT、UPDATE、DELETE)。 - 数据控制语言(DCL):用于管理数据库访问权限(如
GRANT、REVOKE)。 - 事务控制:用于确保数据的一致性和完整性(如
COMMIT、ROLLBACK)。 - 完整性约束:用于确保数据的正确性(如主键、外键、唯一约束等)。
- 复杂查询支持:包括连接操作、子查询、集合操作、窗口函数等。
1.4.1 SQL92标准
SQL92(也称为SQL2)是结构化查询语言(SQL)的第二个主要版本,它增强了SQL功能,并奠定了现代SQL的基础。通过引入完整性约束、事务控制、连接操作等特性,SQL92极大地提高了SQL的表达能力和实用性。尽管后续的SQL标准(如SQL99、SQL2003)进一步扩展了SQL的功能,但SQL92仍然是SQL语言的核心标准,对数据库技术的发展产生了深远的影响。
SQL92标准引入了大量新特性,包括:
- 连接操作(如
INNER JOIN、LEFT JOIN、RIGHT JOIN)。 - 子查询。
- 集合操作(如
UNION、INTERSECT、EXCEPT)。 - 视图(
CREATE VIEW)。 - 完整性约束(如
UNIQUE、CHECK)。 - 事务控制(如
BEGIN TRANSACTION)。
事务控制是在SQL89标准中首次引入,增加了对事务的基本支持,包括提交(Commit)、回滚(Rollback)等。虽然事务控制是在SQL89中引入的,但SQL92标准进一步扩展和规范了事务的功能,包括使用begin transaction显示的开启一个事务(SQL89中事务通常是隐式开启),事务的隔离级别、保存点等功能。
SQL92标准官网:http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
1.4.2 SQL92标准事务
SQL92标准中关于隔离级别处理的问题:

可以看到SQL92标准中,RR隔离级别是会引发幻读问题的;
搜索isolation关键字,找到关于幻读的定义

幻读: 事务T1读取满足搜索条件的N行数据,事务T2执行SQL语句生成一条或多条SQL语句满足事务T1的搜索条件,如果事务T1使用相同搜索条件的SQL语句读取,那么他会返回一个不同行的集合
Tips:SQL92只是一个标准,他提出了事务并发引起的问题有哪几种方案(隔离级别)可以解决,不同的事务隔离级别应该处理哪些问题,但是具体实现落实在了不同的数据库厂商,比如在Oracle中的事务默认隔离级别就是RC(Read Committed),并且Oracle只支持三种事务隔离级别(读已提交、串行化、只读),但MySQL支持四种隔离级别,而且MySQL默认的存储引擎(InnoDB)在RR隔离级别下不会引发幻读;(部分情况)
第2章 事务日志
事务的隔离性是通过锁实现,而事务的原子性、和持久性则是通过事务日志实现。
事务日志是 MySQL 中用于确保事务的持久性(Durability)和原子性(Atomicity)的重要机制。它记录了所有对数据库的修改操作,以便在系统崩溃或故障时能够恢复数据。MySQL 的事务日志主要包括两种:
- 重做日志(Redo Log):记录事务对数据页的物理修改,用于崩溃恢复,保障事务的持久性。
- 回滚日志(Undo Log):记录事务修改前的数据状态,用于回滚事务和多版本并发控制(MVCC),保障事务的原子性。
MySQL 的事务日志是确保事务持久性和原子性的核心机制。重做日志用于崩溃恢复,确保已提交事务的修改不会丢失;回滚日志用于事务回滚和多版本并发控制(MVCC),确保数据的一致性和隔离性。事务日志的存在使得 MySQL 能够在高并发和系统故障的情况下,依然保证数据的完整性和可靠性。
2.1 Redo Log
2.1.1 Redo Log与持久性
事务开启后,执行的所有的操作都是记录在事务日志中,这部分数据并没有写入磁盘表,需要把当前事务提交,才会将事务日志记录的数据写入到磁盘表中。Redo Log是用于保证事务的ACID中的持久性的,关于什么是持久性我们必须弄清楚这一点。
- 事务的持久性:事务提交成功后,数据被保存到磁盘表中,即使发生系统崩溃、断电或其他故障,只要表、磁盘等软硬件设备不被损坏,那么数据将永久保持在磁盘中。
这里存在一个疑问,事务都提交成功了,系统发生崩溃、断电或其他故障不是本就不会影响到磁盘表中的数据吗?当然前提是磁盘表中的数据没有损坏,那这个持久性到底保障的是什么呢?
需要注意:事务的持久性指的是事务一旦提交成功,才能保障后续的流程(崩溃、宕机等问题的处理)。可不是保证事务一定能提交成功。如果事务在提交过程中出现问题,这个问题包括事务运行过程中的问题(一般是客户端的代码问题),也包括MySQL服务器自身的问题(一般是执行commit命令时宕机、系统奔溃等)。但不管是客户端或者是MySQL服务器本身的问题导致的提交失败,MySQL都会将其标记为提交失败,客户端接收到MySQL响应的提交失败请求后可以做其他的补偿处理。
如果一个事务被标记为提交成功,那么数据能够正常写入磁盘表,并且不怕MySQL宕机、服务器崩溃等,如果一个事务被标记为失败,那么该出现的问题还是会出现的。那么也可以这么理解:如何让事务能够快速被标记为成功,或许才是事务日志真正所要考虑的问题,毕竟能够快速标记为成功,那就少一份执行commit时MySQL宕机、服务器崩溃的风险。
2.1.2 Redo Log的工作原理
Redo日志也叫重做日志,在InnoDB存储引擎中使用。它记录了数据在内存中更改之后但还未持久化到磁盘表之前的信息。它的主要作用是在系统崩溃后能够重新执行(redo)那些已经提交但尚未写入磁盘的数据更改。如果在事务提交时,此时数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据Redo Log中记录的日志,把数据库恢复到崩溃前的一个状态。因此Redo Log 是InnoDB实现事务持久性的强力保证。
Tips:Redo Log主要保障的是事务的持久性,即只要事务提交成功,那么数据就能够永久保存到数据库中,否则就属于提交失败,就应该进行事务回滚(根据Undo 日志回滚),客户端也可以做一些事务提交失败的代码流程。
- Redo的运行流程:
首先在操作表时,会将表数据从磁盘(.idb)加载到内存缓冲池中(Buffer Pool),对表所有的操作都会记录一份到Redo Buffer日志(内存中的Redo日志)中,其根据一定的策略将数据刷新到Redo Log中(磁盘中的Redo日志)。在事务最终要提交时(执行了commit),如果数据库或系统突然宕机,那么当数据库或系统重启时,就可以根据Redo Log日志中的记录进行数据的恢复。
Redo Log的工作原理如图所示:
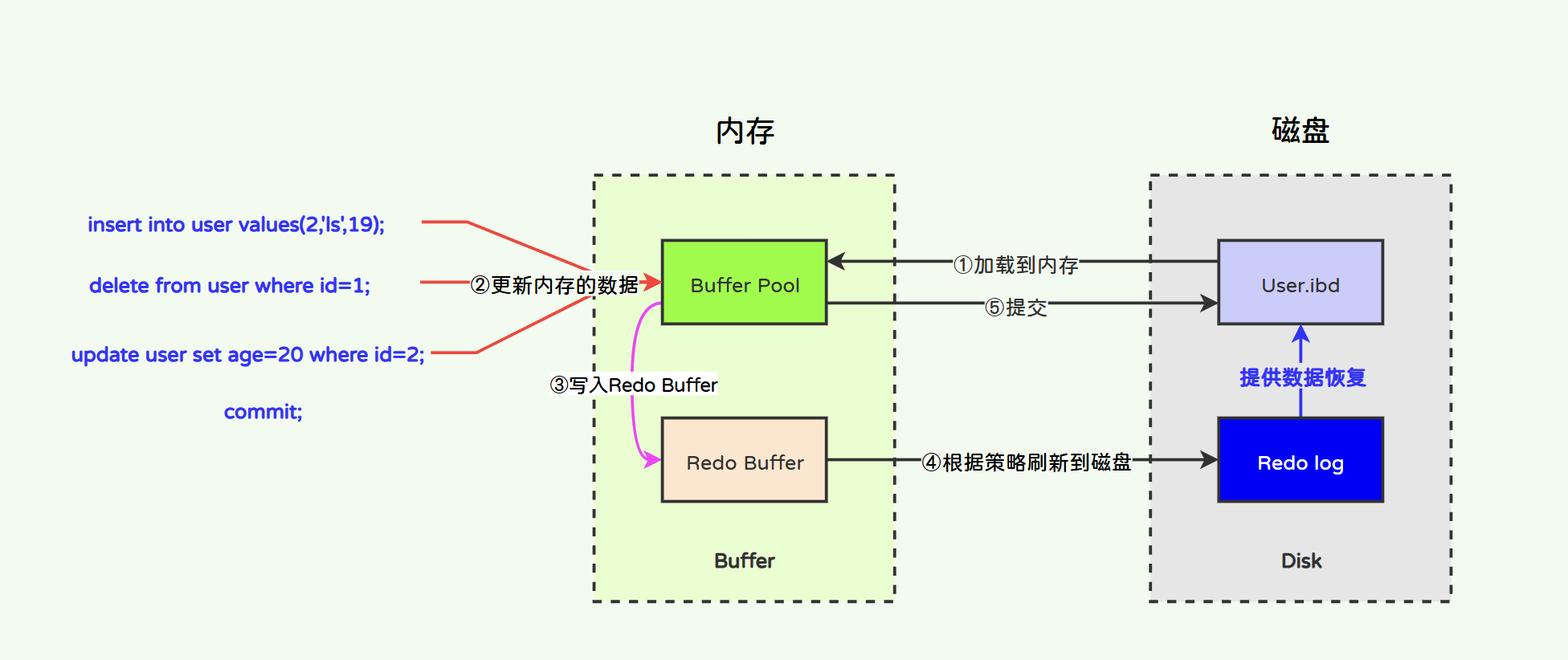
在提交事务时,为什么不直接将数据写入数据库表呢?而是要先写入Redo Log中呢?看似好像“多此一举”?其实不然。写入Redo Log的好处如下:
- 原因一:Redo Log的结构简单。
Redo Log 记录的是物理层面上的数据修改,因此Redo也叫物理日志。这些修改记录包含了数据页的物理地址(Page Number)和修改的具体内容(如页内数据的前后变化)。在系统重启时,InnoDB 会读取 Redo Log 文件,并根据其中的记录重做对数据页的修改。
Redo Log的日志格式:
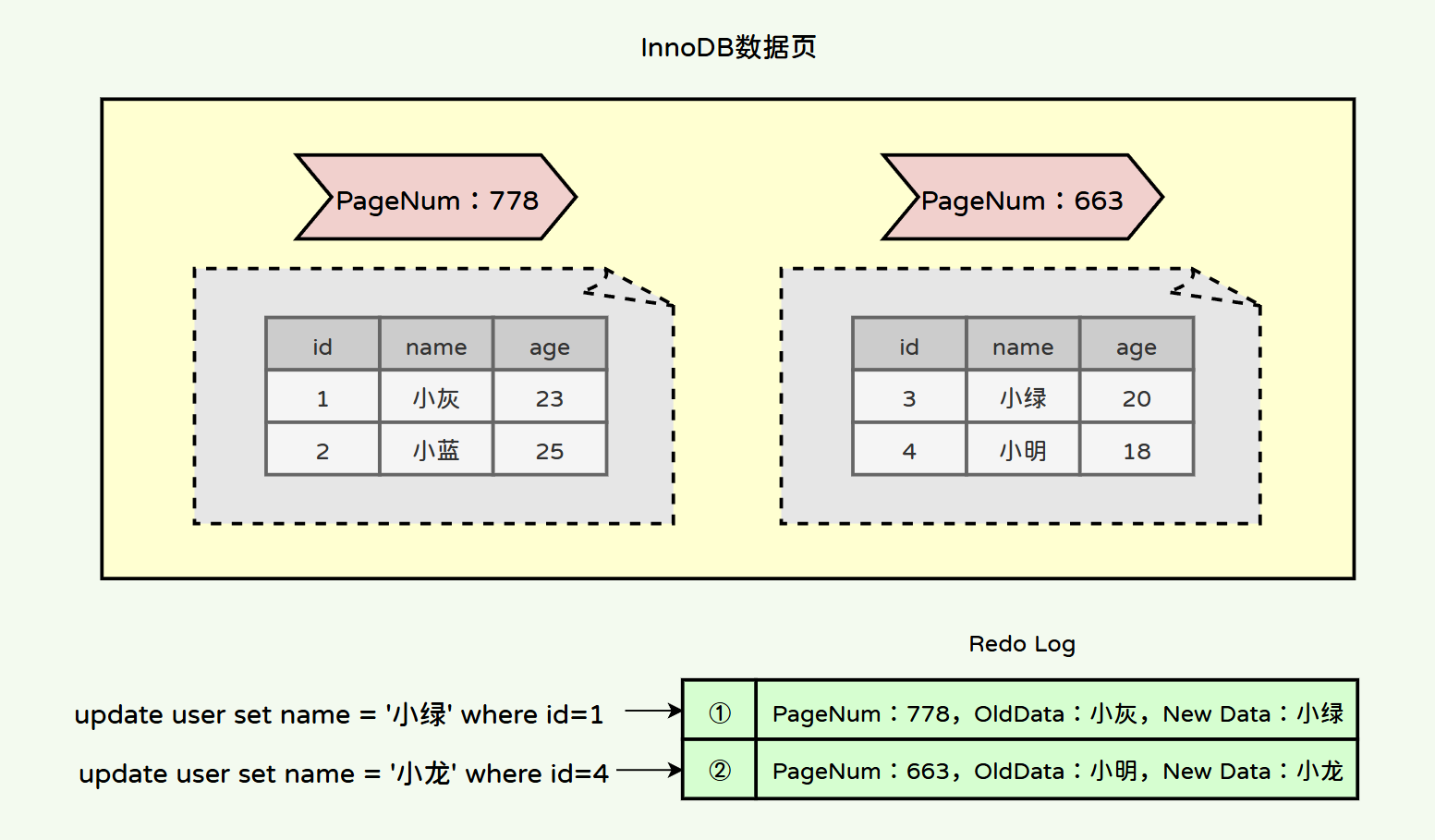
正因为Redo Log中记录的数据结构简单,只记录一些物理地址以及一些变更状态等信息。因此数据先写入Redo Log要比直接写入到表快多了。其次,Redo Log作为“临时存储的数据区域”,当Redo Buffer中的数据已经到达一定大小后,Redo Buffer也会将这部分数据写入到Redo Log中,此时数据还未提交,但是已经写入到磁盘中了。
Tips:上面流程中这种先写日志,再写磁盘,只有日志写入成功,才算事务提交成功的技术思想在MySQL也叫做
WAL技术 (Write-Ahead Logging日志先行)。
- 原因二:顺序IO性能远高于随机IO。
数据在MySQL中存储是以页为单位,事务中操作的数据可能遍布在不同的页中,如果直接写入到磁盘中对应的页中,是随机IO写入,效率低。
而Redo Log是通过往Redo Log日志中追加数据的方式,属于顺序IO,效率高。这样可能会影响Redo Log恢复数据时的性能,但可以保证在提交时期能够快速写入Redo Log日志记录本次事务的更改。
2.1.3 Redo Log的落盘策略
事务的日志是先写入到redo log buffer 中的,并且这个过程是非常快的,那redo log buffer在什么时候会写入磁盘呢?
redo log buffer不是直接将日志内容刷盘到redo log file中,而是先刷入到操作系统的文件系统缓存 (page cache)中去。最后,日志内容会从操作系统的文件系统缓存中刷到磁盘的日志文件中,至于什么时候触发这个动作,MySQL的innoDB引擎提供了3种策略可选。
Tips:Redo Log Buffer 刷新到 page cache 后,如果是MySQL宕机则问题不大,但是如果整个系统宕机数据将会丢失,因为数据都保存在操作系统的
page cache中。不过这个过程很快,而且整个系统宕机概率相对MySQL会小很多。
InnoDB引擎提供了 innodb_flush_log_at_trx_commit 参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 的3种策略,取值有0、1、2;默认为1。
mysql> select @@innodb_flush_log_at_trx_commit;
+----------------------------------+
| @@innodb_flush_log_at_trx_commit |
+----------------------------------+
| 1 |
+----------------------------------+
1 row in set (0.00 sec)
- 0:代表每秒将
Redo Buffer中的数据刷到OS buffer然后立即从OS buffer刷到Redo Log磁盘文件中。
为0时,后台线程每隔1秒进行一次重做日志的刷盘操作。在这种情况下,MySQL或操作系统宕机最多丢失1s内的事务数据,这种方式效率最高,但是安全性最低。
- 1:代表每次提交事务都将
Redo Buffer同步到OS Buffer然后立即从OS Buffer刷到Redo Log磁盘文件中(默认值)。
为1时,每次事务提交时都将进行同步, 执行主动刷盘操作。在这种情况下,MySQL或操作系统宕机最多丢失1次事务的数据,安全性最高,效率偏低。
- 2:代表每次提交都将
Redo Buffer中的数据刷到OS Buffer,然后再隔一秒从OS Buffer刷到Redo Log磁盘文件中。
为2时,只要事务提交成功,redo log buffer中的内容只写入文件系统缓存(pagecache)。在这种情况下,如果是MySQL宕机,最多丢失1次事务的数据,但是如果是操作系统宕机,则可能会丢失1s内的数据。安全性和效率折中。
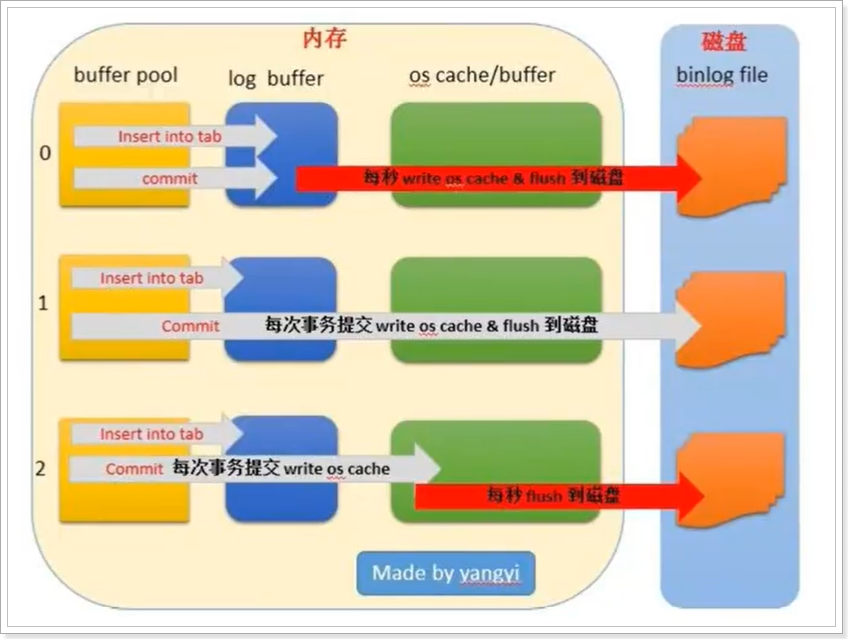
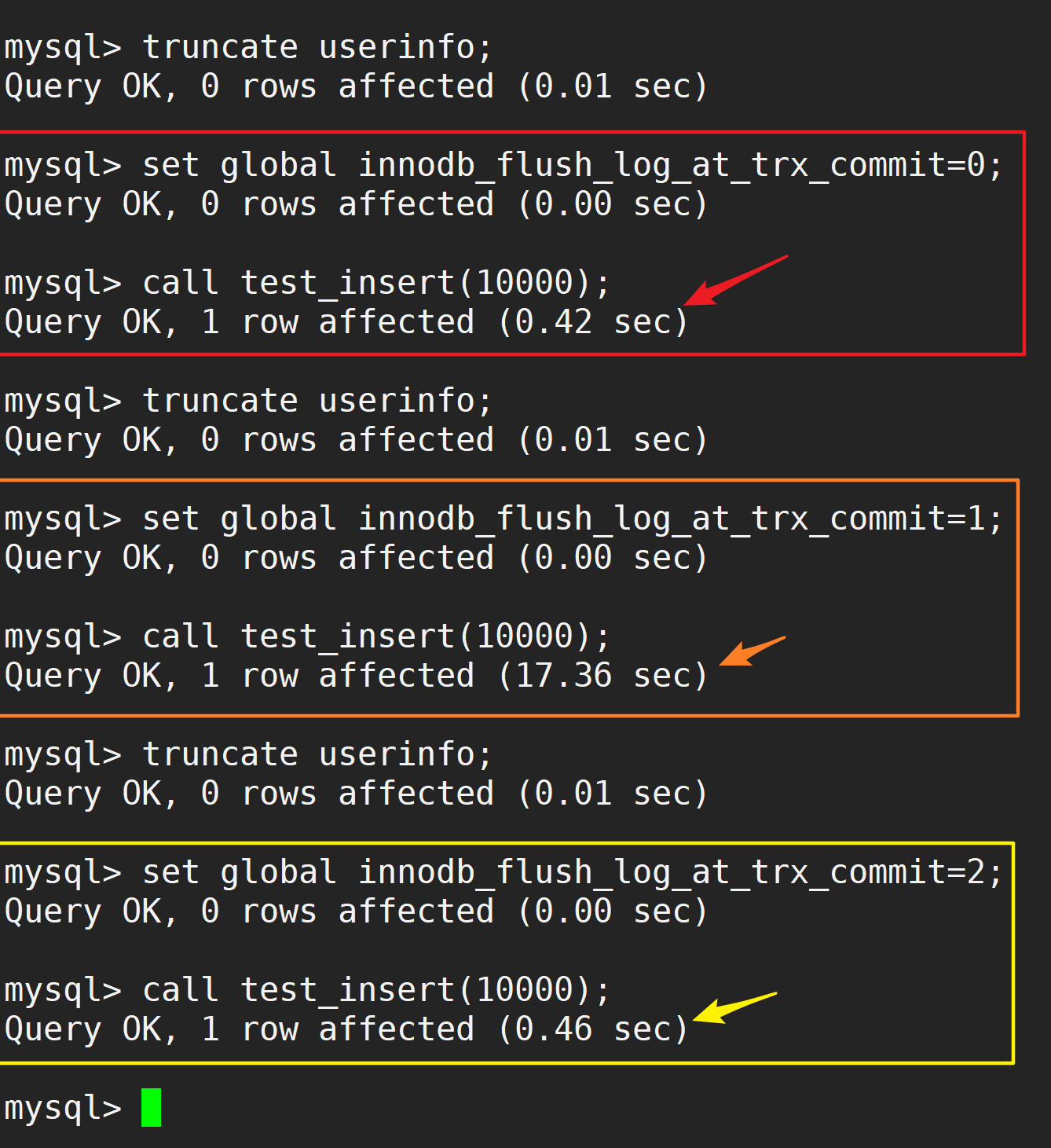
- 测试不同的redo刷盘策略对性能的影响:
mysql> truncate userinfo;
Query OK, 0 rows affected (0.01 sec)
mysql> set global innodb_flush_log_at_trx_commit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> call test_insert(10000);
Query OK, 1 row affected (0.42 sec)
mysql> truncate userinfo;
Query OK, 0 rows affected (0.01 sec)
mysql> set global innodb_flush_log_at_trx_commit=1;
Query OK, 0 rows affected (0.00 sec)
mysql> call test_insert(10000);
Query OK, 1 row affected (17.36 sec)
mysql> truncate userinfo;
Query OK, 0 rows affected (0.01 sec)
mysql> set global innodb_flush_log_at_trx_commit=2;
Query OK, 0 rows affected (0.00 sec)
mysql> call test_insert(10000);
Query OK, 1 row affected (0.46 sec)
mysql>
Redo Buffer 除了上面3种策略进行刷盘以外,还有另外一种特殊的场景:当redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写盘。
2.1.4 Redo Log的系统参数
innodb_log_buffer_size:Redo Buffer的大小,默认16Minnodb_log_file_size:单个Redo Log事务日志文件的最大大小,默认48Minnodb_log_files_group:Redo Log日志文件的个数,默认2个innodb_log_group_home_dir:Redo Log的存放路径;默认值为./代表当前MySQL的数据目录(Linux默认是/var/lib/mysql)innodb_log_checksums:启用或禁用Relo log数据页的校验,默认开启。innodb_log_compressed_pages:指定是否将重新压缩的页写入Redo Log,默认是开启状态
mysql> show variables like '%innodb_log%';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
+-----------------------------+----------+
7 rows in set (0.00 sec)
2.1 Undo Log
2.1.1 Undo Log与原子性
事务的持久性是交由Redo Log来保证,原子性则是交由Undo Log来保证。如果事务中的SQL执行到一半出现错误,需要把前面已经执行过的SQL撤销以达到原子性的目的,这个过程也叫做"回滚",所以Undo Log也叫回滚日志。
Undo Log记录了数据在每个操作前的状态,这些记录包括旧的数据值和事务的 ID。如果事务执行过程中需要回滚,就可以根据Undo Log进行回滚操作。
每当我们要对一条记录做改动时(这里的改动可以指INSERT、DELETE、UPDATE),把回滚时所需的东西记下来。比如:
- 当执行了一条insert语句时:至少要把这条记录的主键值记下来,之后回滚的时候只需要把这个主键值对应的记录删掉就好了。对于事务中的每个insert语句,在事务回滚时InnoDB都会完成一个delete操作。
- 当执行了一条delete语句时:至少要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入。对于事务中的每个delete语句,在事务回滚时InnoDB都会完成一个insert操作。
- 当执行了一条update语句时:至少要把修改这条记录前的旧值都记录下来,这样之后回滚时再把这条记录更新为旧值。对于事务中的每个update语句,在事务回滚时InnoDB都会完成一个反向的update操作。
另外,Undo Log 也是实现多版本并发控制的基础,通过保存旧版本的数据,InnoDB 可以在并发事务中提供隔离级别,如读已提交(Read Committed)、可重复读(Repeatable Read)等。
Tips:Undo Log主要保证事务的原子性,即通过记录修改前的状态,以提供回滚功能,其次Undo Log用于提供MVCC的快照读。
2.1.2 Undo的存储格式
Redo属于物理日志,即记录了数据库页的物理修改操作,比如页上的哪些字节被更改,具体到物理结构上。Undo属于逻辑日志,即记录了从逻辑角度如何撤销已经发生的变更的信息,第一步第二步该如何做等,通常包括了反向操作所需要的数据。
“Redo属于物理日志”意味着它详细记录了物理层面的数据页是如何被改变的;而“Undo属于逻辑日志”则表示它更多是从逻辑角度出发,记录了为实现某种目的(如回滚或访问历史版本)所需执行的操作步骤。这两者共同保障了MySQL数据库中事务处理的ACID特性。
在InnoDB中,所有表中都会有三个隐藏的列,分别为:DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR。
- DB_TRX_ID:数据行版本号,也叫事务ID。当有新的数据修改或插入时的事务ID号,用于记录修改这条记录的事务ID和创建这条记录的事务ID。(记录这条数据是哪个事务修改的,哪个事务创建的)
- DB_ROLL_PTR:删除行版本号,也叫回滚指针。指向Undo Log中这条记录的上一个版本,删除记录,记录当前事务ID。(记录这条数据是哪个事务删除的)
- DB_ROW_ID:聚集索引。如果数据表没有主键,InnoDB会创建一个DB_ROW_ID作为聚集索引。
其中事务ID与回滚指针和Undo Log日志密切相关,另外在InnoDB中,Undo Log分为Insert Undo Log和update Undo Log两种类型,其中删除操作也是借助update Undo Log来完成的。
1)insert类型Undo Log
执行如下insert语句:
insert into user values(1,"小灰",20);
insert into user values(2,"小绿",25);
当事务开启后,执行的insert语句都会以“insert类型的undo log”记录在undo log日志中,本次事务插入的所有的数据行的版本号字段都为当前事务的ID。
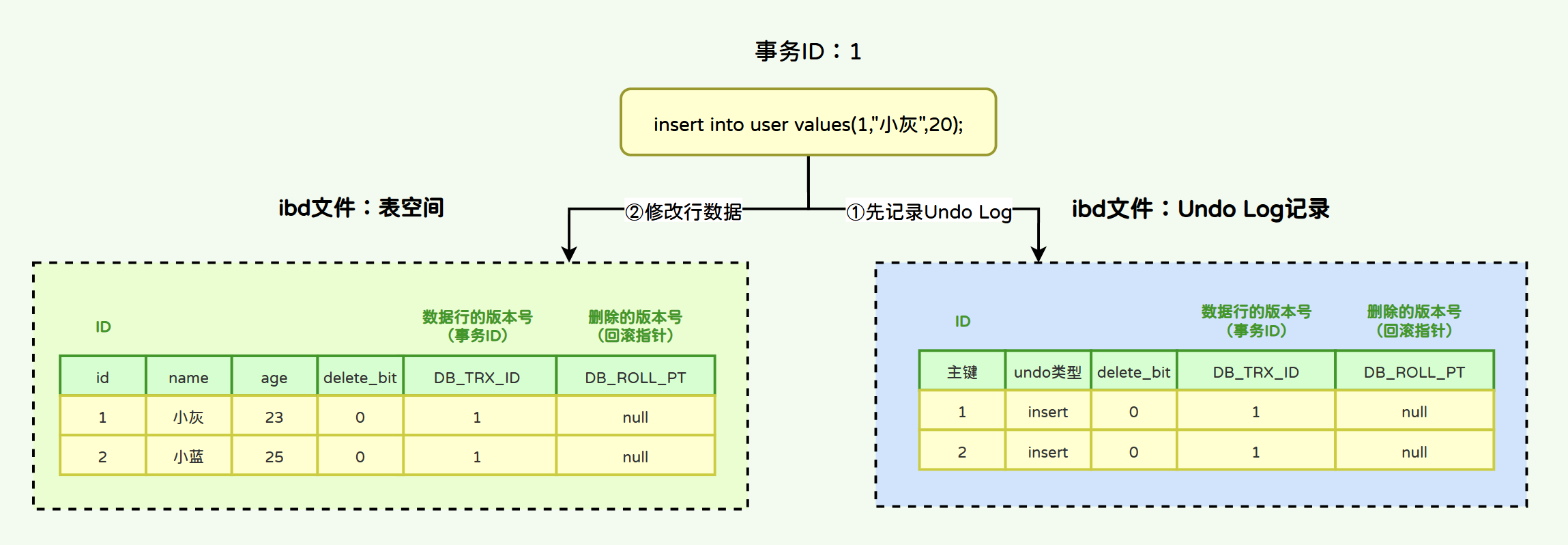
如果需要进行事务回滚,根据undo log中记录的主键进行delete操作即可。
2)delete类型Undo Log
执行如下delete语句:
delete from user where id=1;
delete from user where id=2;
当事务开启后,InnoDB对于delete语句的流程是:
- 1)将被删除的行以“update类型的undo log”记录到undo log日志中。
- 2)将该行的事务ID设置为当前事务ID,回滚指针设置为被删除前那条记录的事务ID。
- 3)将删除标记设置为1,表示该记录是被删除掉的记录。
- 4)更改表空间。
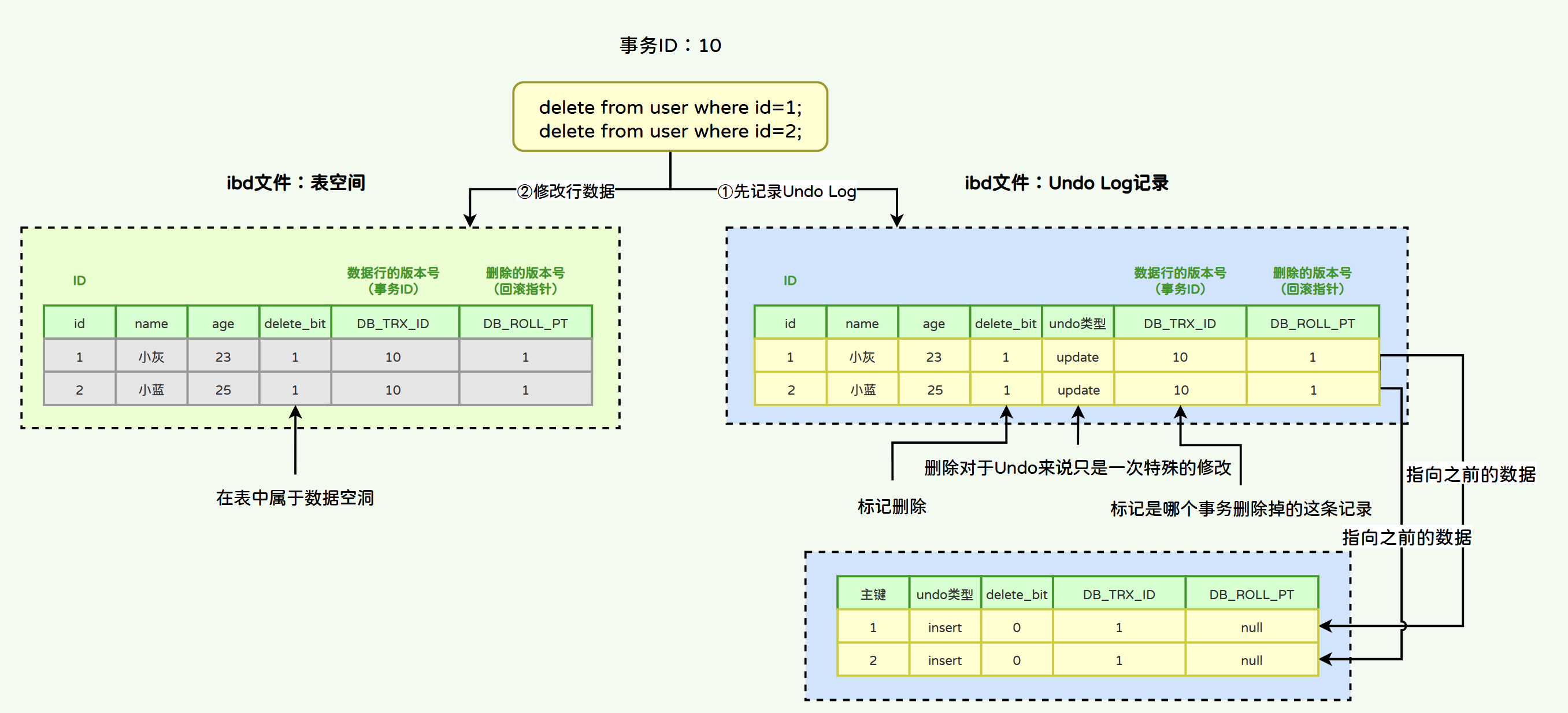
3)update类型Undo Log
执行如下update语句:
update user set name="小绿" where id=1;
当事务开启后,InnoDB对于update语句的流程是:
- 1)将被修改的行以“update类型的undo log”记录到undo log日志中。
- 2)将该行的事务ID设置为当前事务ID,回滚指针设置为被删除前那条记录的事务ID。
- 3)更改表空间。
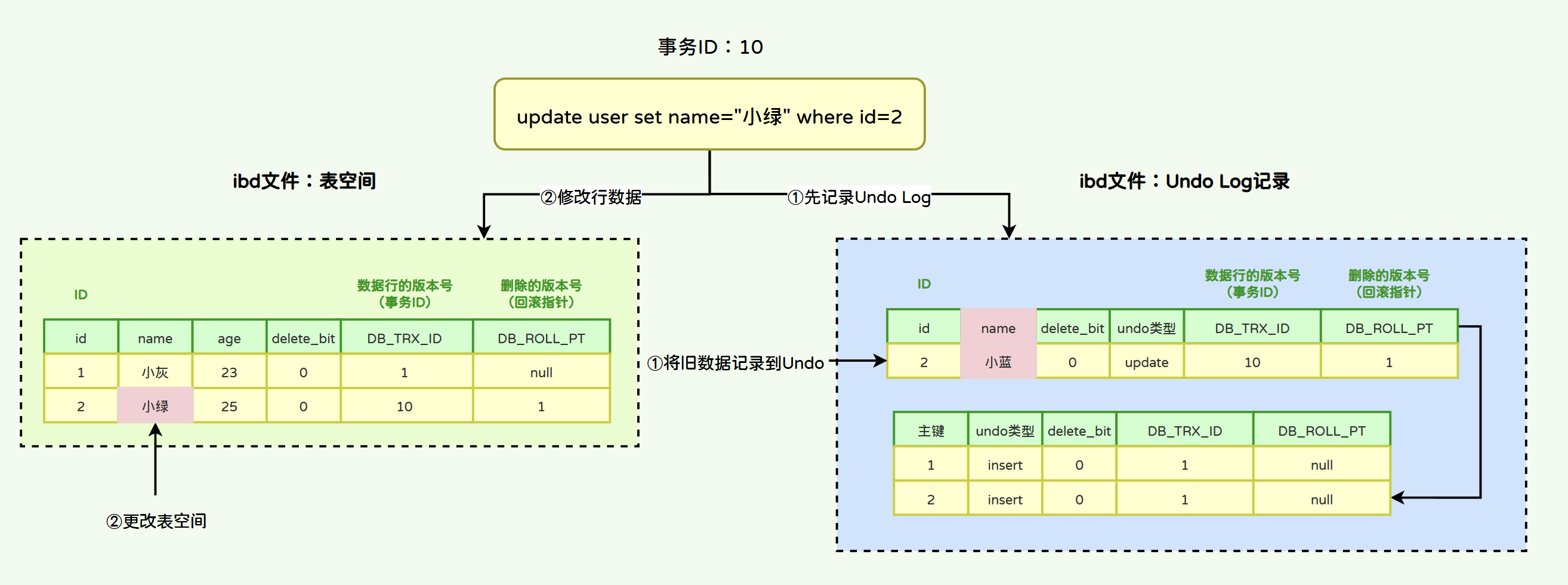
当同一条数据被修改多次,那么Undo Log将通过数据的事务ID和回滚指针能够形成一个非常好的修改链路:
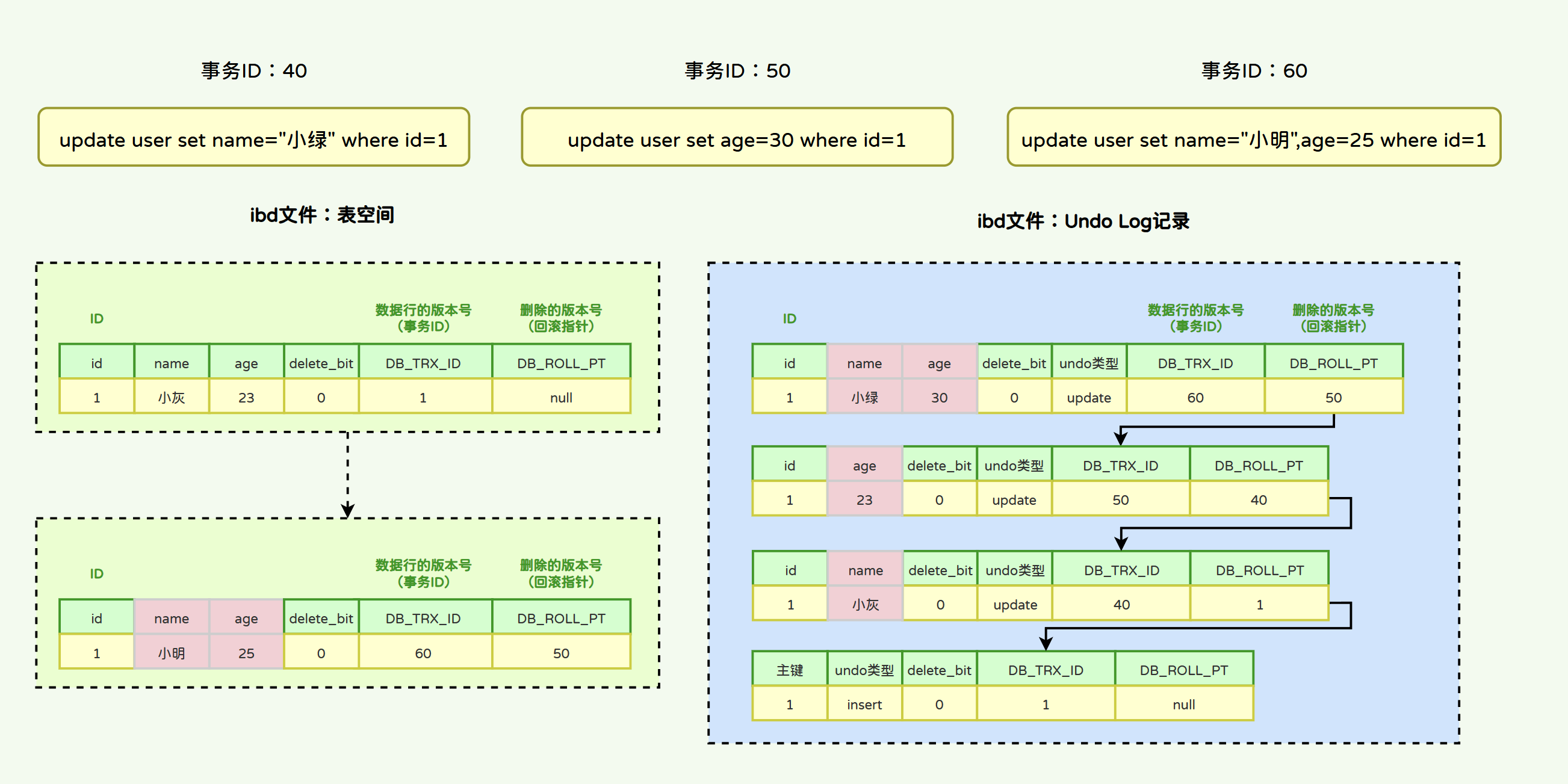
2.1.3 Undo Log的工作原理
InnoDB在MySQL启动时,会在内存中构建一个BufferPool,而这个缓冲池主要存放两类东西,一类是数据相关的缓冲,如索引、锁、表数据等,另一类则是各种日志的缓冲,如Undo、Redo....等日志。当一条写SQL执行时,MySQL并不会直接去往磁盘中的ibd文件写数据,而是先修改内存中的Buffer Pool,这样性能就能得到极大的提升。
与Redo Log一样,Undo Log也存在内存缓冲区,即Undo Log Buffer。当一条写SQL执行时,不会直接去往磁盘中的xx.ibdata文件中的Undo Log写数据,而是会写在undo_log_buffer缓冲区中,因为工作线程直接去写磁盘太影响效率了,写进缓冲区后会由后台线程去刷写磁盘。
- Undo Log完整的工作原理如下:
首先在操作表时,会将表数据从磁盘(.idb)加载到内存中(Buffer),对表的update/delete等操作InnoDB都会事先将修改前的数据备份到Undo Buffer中,这样当事务进行回滚时可以根据Undo Buffer中的内容进行事务的回滚操作,除此之外,Undo Buffer提供了数据的快照读取,在事务未提交之前,Undo 日志可以作为并发读写时的读快照,来保证事务的可重复读;
事务做到一半了,失败了,那就要将数据还原到未提交之前的状态,undo 就是记录这些事务步骤的。当然了redo 也记录了,但是redo里面东西太繁杂,不可能什么事都找它(主要是Redo和Undo的格式不一样,应用场景也不一样),于是就将事务步骤写入另外一个地方:undo,以后遇到回滚了就去查找因此在每一步操作时都会写入磁盘中的Undo Log;
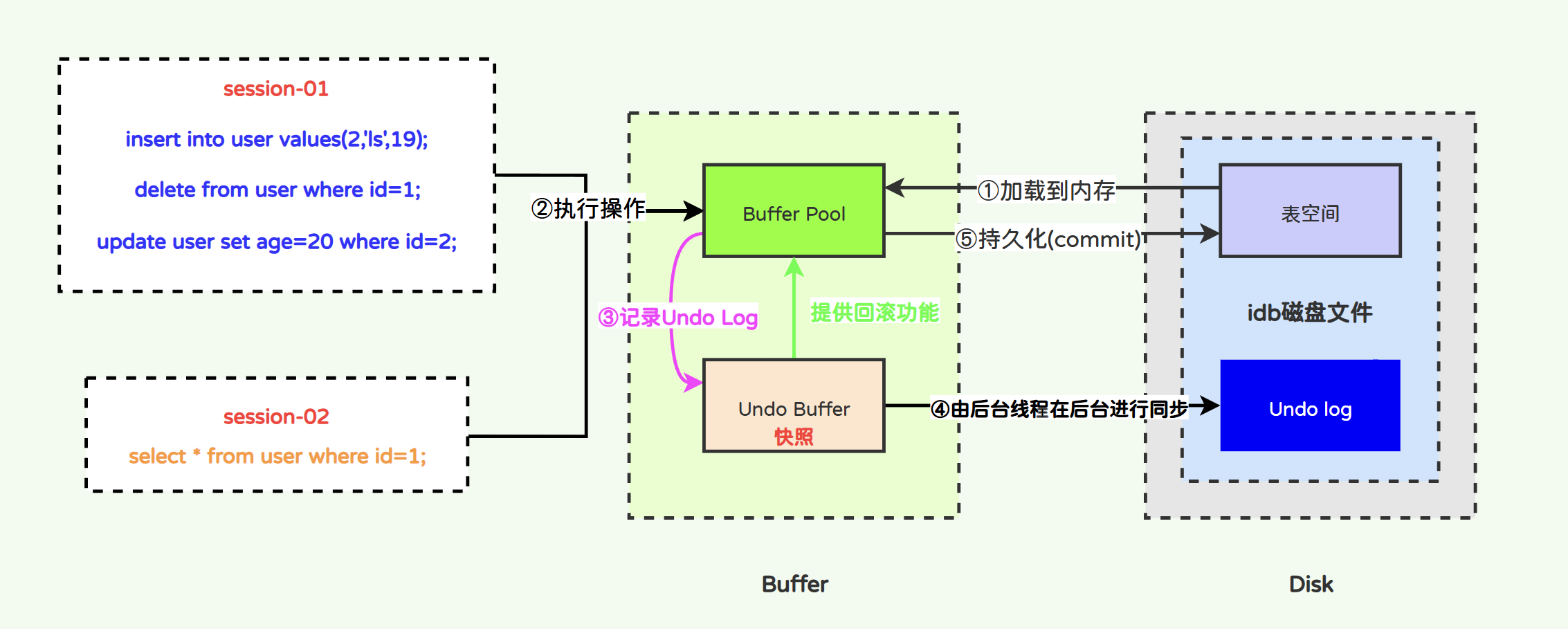
引入Undo Log Buffer是来提升Undo Log的性能的,比较操作内存要比操作磁盘快多了,但由此也引入了另外一个问题,那就是既然内存中记录了Undo Log的值,为什么还要在磁盘中也记录Undo Log的值呢?难道Undo Log也要保证持久性?
并不是,在InnoDB中持久性由Redo保证。Undo之所以要写人磁盘是因为InnoDB对数据进行了多版本的控制(MVCC)。
观察如下案例:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from user; | |
| update user set name='小蓝' where id=1; | |
| commit; | |
| select * from user; -- 能否查询到修改的数据? |
如果当前的事务隔离级别为RR(可重复读),那么在session-02事务中修改的数据是不能被查询出来。那数据库表中id=1的这一行数据的name值有没有被改为"小蓝"呢?答案是肯定的,因为事务都已经提交了,磁盘表中的name已经修改为了"小蓝"。这就引入了一个问题,并不是提交的数据就一定能被查询出来的,有时候需要查询旧数据。Undo Log正是保存那些旧版本的数据,让其在其他事务中可见。
2.1.4 Undo Log的系统参数
InnoDB对undo log的管理采用段的方式,也就是回滚段(rollback segment) 。每个回滚段记录了 1024 个 undo log segment ,每个事务只会使用一个undo log segment,当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
在MySQL5.5的时候,只有一个回滚段,那么最大同时支持的事务数量为1024个。在MySQL 5.6开始,InnoDB支持最大 128个回滚段,故其支持同时在线的事务限制提高到了 128*1024 。
我们可以查看InnoDB中Undo Log的有关系统参数,在MySQL5.5之前没有太多参数,如下:
mysql> show variables like 'innodb_max_undo_log_size';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
+--------------------------+------------+
1 row in set (0.00 sec)
mysql> show variables like 'innodb_rollback_segments';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_rollback_segments | 128 |
+--------------------------+-------+
1 row in set (0.00 sec)
innodb_max_undo_log_size:本地磁盘文件中,Undo-log的最大值,默认1GB。innodb_rollback_segments:指定回滚段的数量,默认为1个。
除开上述两个参数外,其他参数基本上是在MySQL5.6才有的,如下:
mysql> show variables like '%innodb_undo%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+-------+
4 rows in set (0.00 sec)
innodb_undo_directory: 设置rollback segment文件所在的路径。这意味着rollback segment可以存放在共享表空间以外的位置,即可以设置为独立表空间。该参数的默认值为“/”,即MySQL的数据文件夹。innodb_undo_logs: 设置rollback segment的个数,默认值为128,也就是之前的innodb_rollback_segments。innodb_undo_tablespaces: 设置构成rollback segment文件的数量,这样rollback segment可以较为平均地分布在多个文件中。设置该参数后,会在路径innodb_undo_directory看到undo为前缀的文件,该文件就代表rollback segment文件。innodb_undo_log_truncate:是否开启Undo-log的在线压缩功能,即日志文件超过大小一半时自动压缩,默认OFF关闭。
在MySQL5.5版本以后,Undo-log日志支持单独存放,并且多出了几个参数可以调整Undo-log的区域。
2.1.5 Undo Log与Purge线程
前面提到,事务提交后Undo Log日志并不会马上删除,因为其他事务很可能需要用到该数据。直接移除可能会导致其他事务读不到数据。那么对于废弃的undo log日志在什么时候删除呢?另外磁盘表中的被标记为删除的记录(数据空洞),也需要进行空间释放。这些数据都是由MySQL内部的线程——Purge线程来执行后台删除。
- 针对于
insert undo log,因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log在事务提交后就没有用,就会直接删除。 - 针对于
update undo log,该undo log需要支持MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,有专门的purge线程进行删除。
有关于Purge线程的参数:
mysql> show variables like '%purge%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| gtid_purged | |
| innodb_max_purge_lag | 0 |
| innodb_max_purge_lag_delay | 0 |
| innodb_purge_batch_size | 300 |
| innodb_purge_rseg_truncate_frequency | 128 |
| innodb_purge_threads | 4 |
| relay_log_purge | ON |
+--------------------------------------+-------+
7 rows in set (0.01 sec)
innodb_max_purge_lag:当InnoDB存储引擎压力非常大时,Purge线程可能并不会工作,此时是否要延缓DML的操作,innodb_max_purge_lag控制Undo Log的数量,如果数量大于该值,就延缓DML的操作,默认为0,代表不延缓;innodb_max_purge_lag_delay:表示当上面innodb_max_purge_lag的delay超时时间太大,超过这个参数时,将delay设置为该参数值,防止purge线程操作缓慢导致其他SQL线程长期处于等待状态。默认为0,一般不用修改。innodb_purge_batch_size:用来设置每次purge操作需要清理的Undo Log page的数量。innodb_purge_threads:Purge线程的数量(默认为4,最大为32)
第3章 MVCC并发版本控制
3.1 MVCC与LBCC
上面我们说到了InnoDB在RR隔离级别下解决了幻读问题,又保证了高并发的读取(避免了读写串行化),那他到底是如何做的呢?
我们需要解决幻读,即保证前后两次读取的数据条数一致,那么我们就在我们读取的数据的时候加锁,锁定我们需要的数据,不允许其他事务对其修改;这种方案我们叫做基于锁的并发控制 Lock Based Concurrency Control(LBCC)。但很显然,InnoDB没有采用这种方案,我们在查询数据的时候并没有锁定行(没有加锁);
从我们的直观理解上来看,要实现数据库的并发访问控制,最简单的做法就是LBCC,即读的时候不能写(允许多个线程同时读,即共享锁,S锁),写的时候不能读(一次最多只能有一个线程对同一份数据进行写操作,即排它锁,X锁)。这样的加锁访问,其实并不算是真正的并发,或者说它只能实现并发的读,因为它最终实现的是读写串行化,这样就大大降低了数据库的读写性能。是四种隔离级别中级别最高的Serialize隔离级别。为了提出比LBCC更优越的并发性能方法,MVCC便应运而生。
MVCC(Multi-Version Concurrency Control):多版本并发控制。并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
MVCC实现了对数据库的读写并发访问,MVCC主要是为了提高数据库读写并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读;提高了数据库并发读写能力;
Tips:MVCC只会在读已提交(RC)和可重复读(RR)隔离级别下工作,因为读未提交总能读取到最新的行,而串行化隔离级别总是会锁定被读取的行,不存在多版本控制。
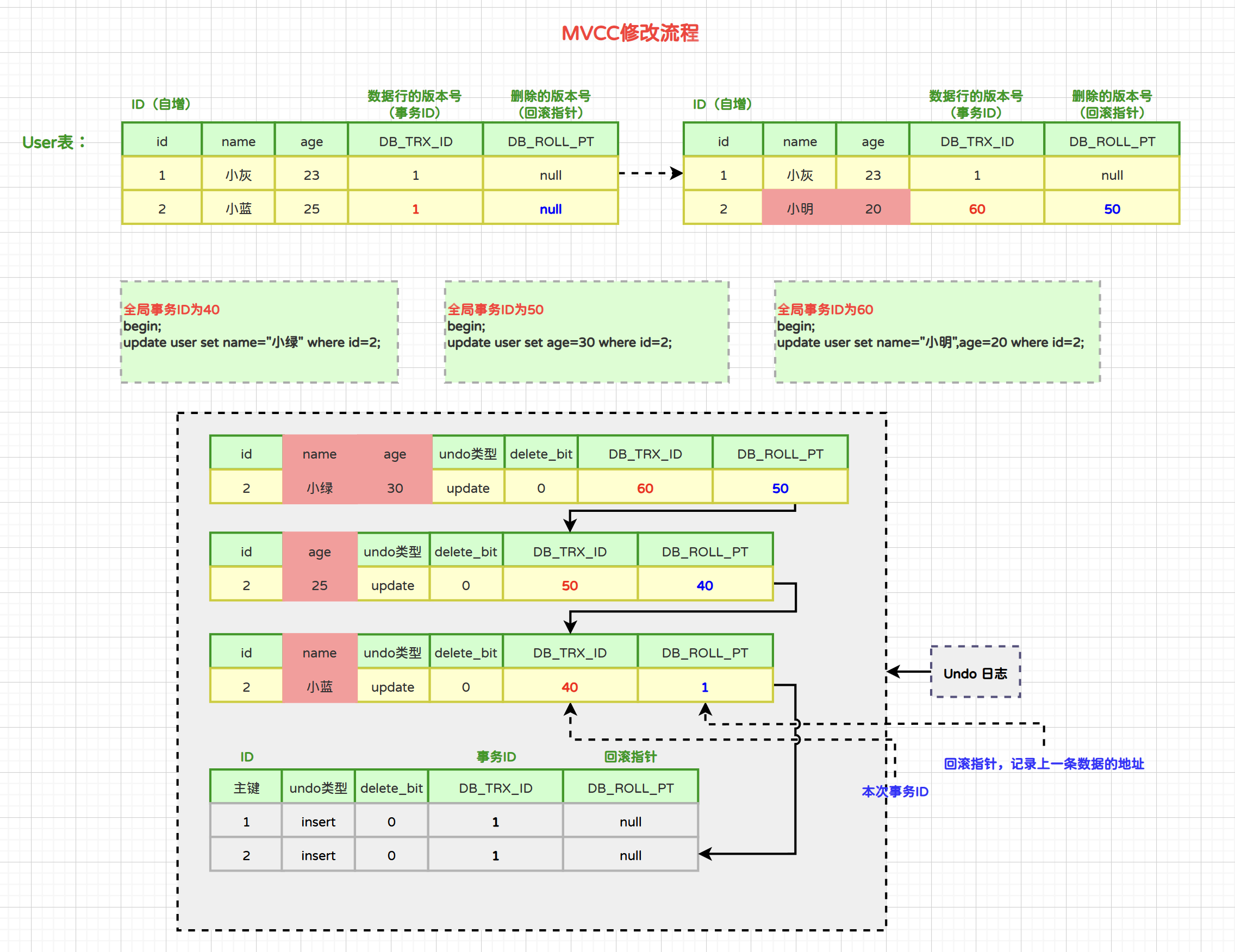
3.2 MVCC增删改流程
MVCC的目的就是实现数据库的并发读取,为了解决读写冲突,它的实现原理主要是依赖记录中的2个隐式字段:DB_TRX_ID(事务ID)和DB_ROLL_PTR(回滚指针)和undo日志 ,Read View(快照)来实现的。
3.2.1 插入流程
当事务开启后,执行的insert语句都会以“insert类型的undo log”记录在undo log日志中,本次事务插入的所有的数据行的版本号字段都为当前事务的ID。
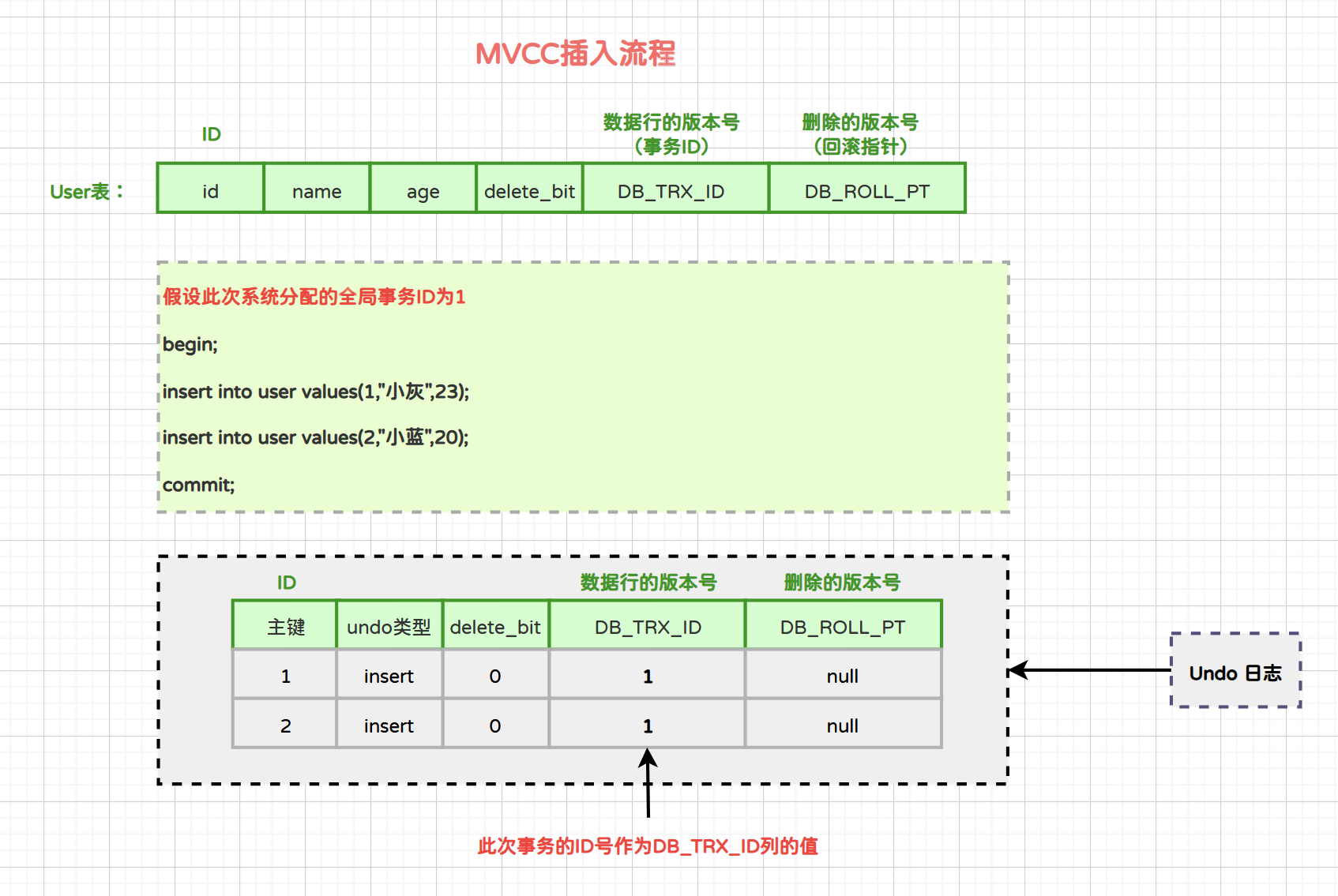
如果需要进行事务回滚,根据undo log中记录的主键进行delete操作即可。
3.2.2 删除流程
- 当事务开启后,InnoDB对于delete语句的流程是:
- 1)将被删除的行以“update类型的undo log”记录到undo log日志中。
- 2)将该行的事务ID设置为当前事务ID,回滚指针设置为被删除前那条记录的事务ID。
- 3)将删除标记设置为1,表示该记录是被删除掉的记录。
- 4)更改表空间。
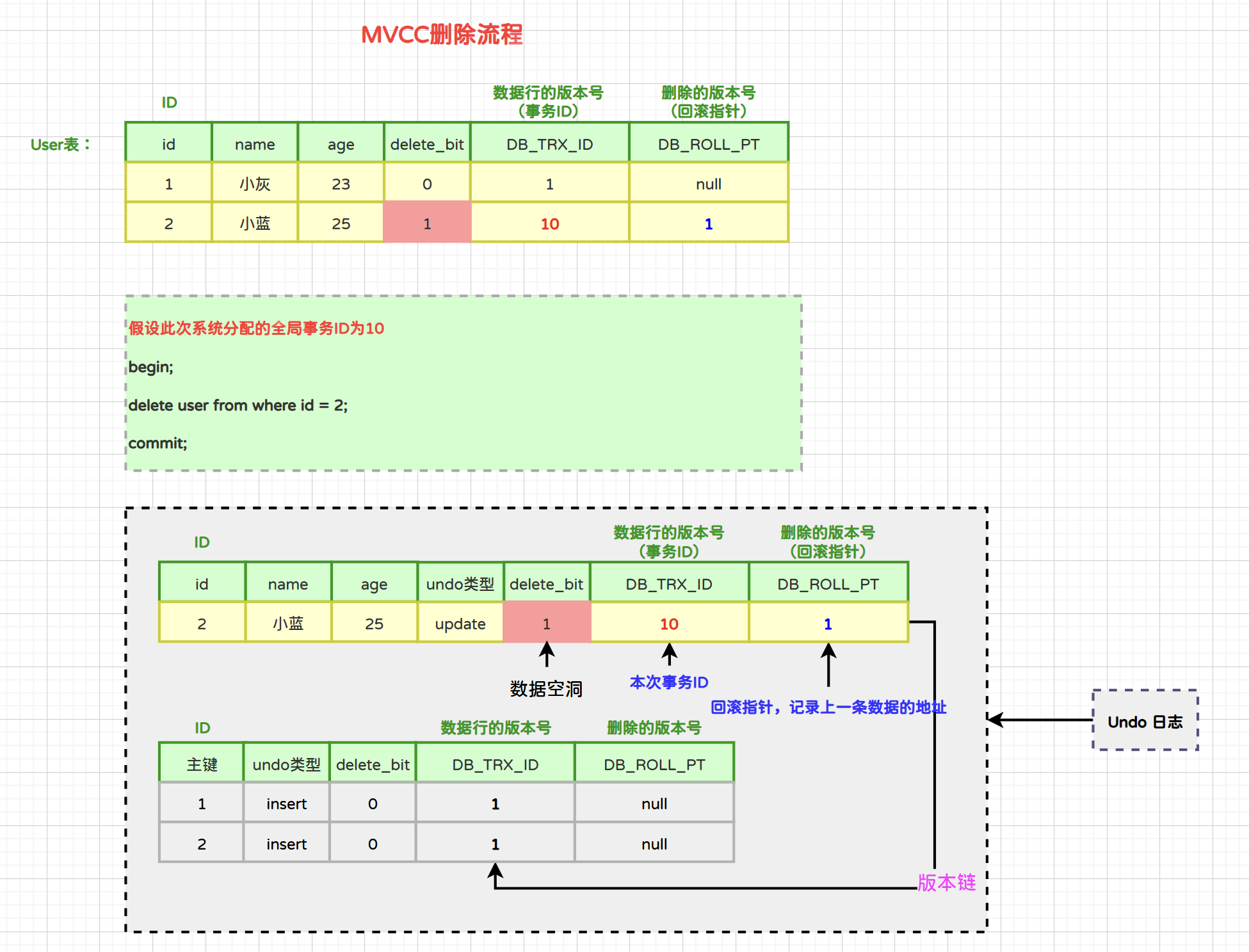
3.2.3 修改流程
- 当事务开启后,InnoDB对于update语句的流程是:
- 1)将被修改的行以“update类型的undo log”记录到undo log日志中。
- 2)将该行的事务ID设置为当前事务ID,回滚指针设置为被删除前那条记录的事务ID。
- 3)更改表空间。
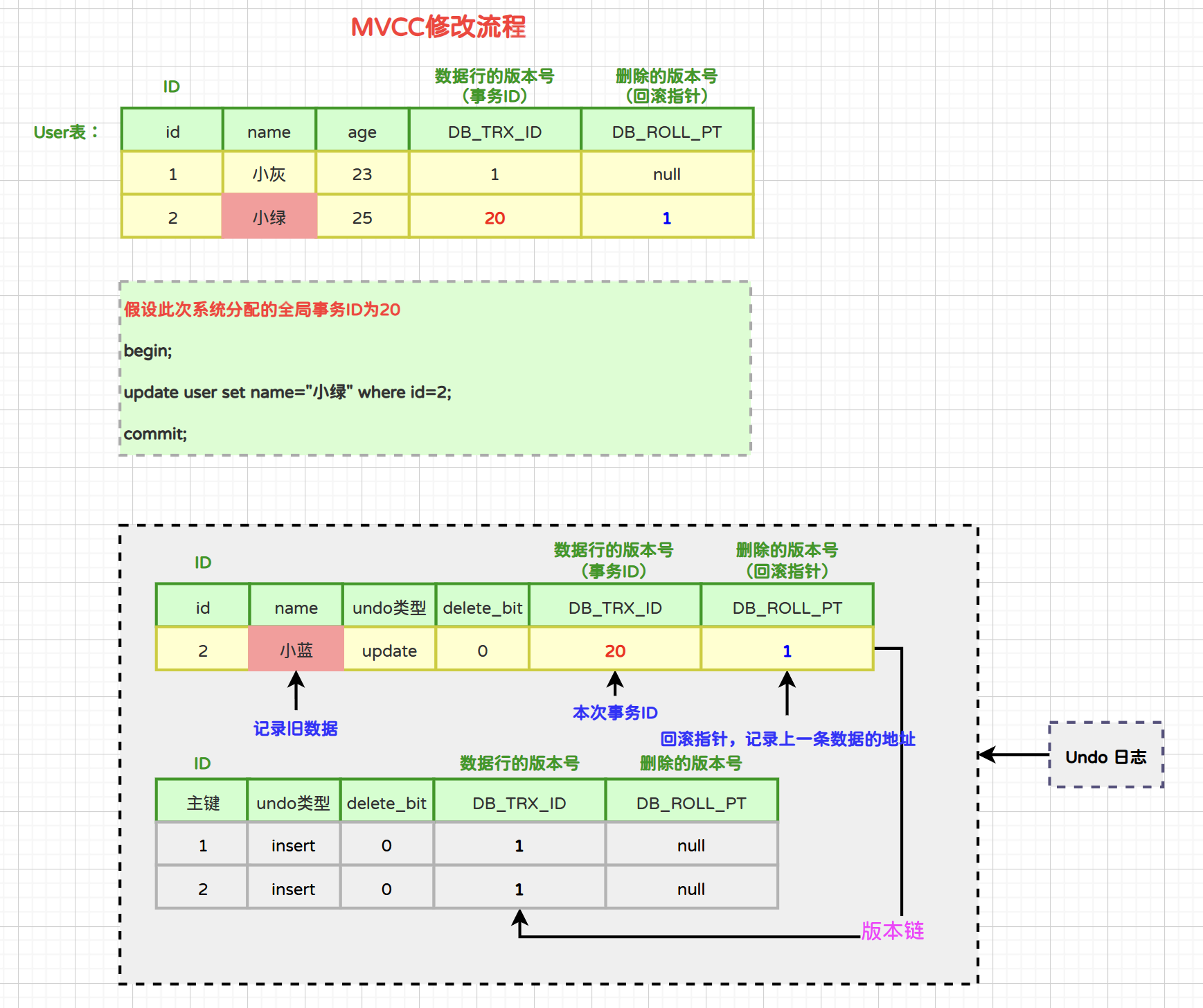
当同一条数据被修改多次,那么通过数据的事务ID和回滚指针能够形成一个非常好的修改链路:
3.3 MVCC查询原理
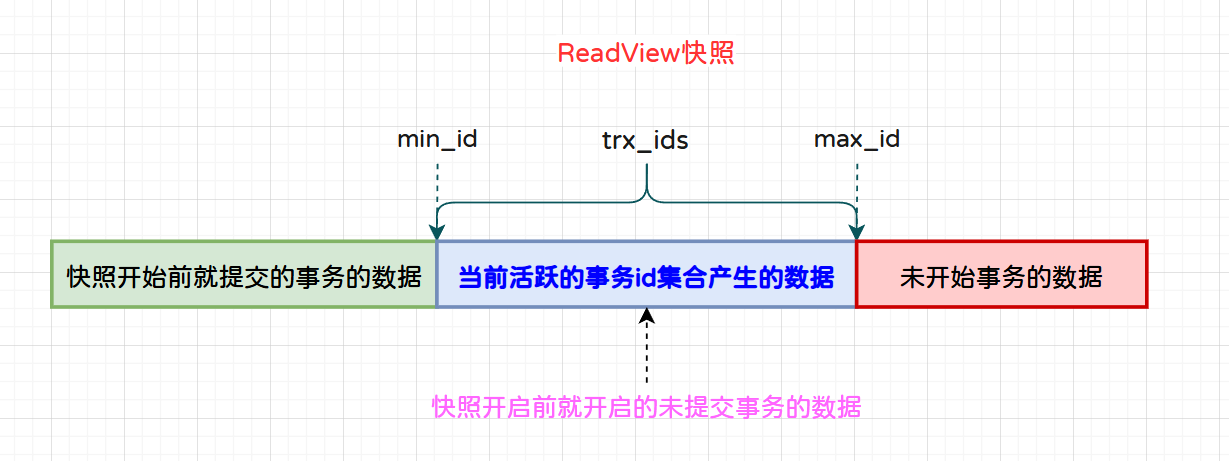
在MVCC中,当执行查询时 InnoDB 会立即生成一个属于该事务的一致性快照(Read View),该一致性快照具备如下属性:
creator_trx_id:当前事务id。trx_ids:当前活跃的事务id集合,即当前快照拍下时所有未提交的事务集合,包含所有未提交的事务id。
和 ReadView 有关的两个特殊的临界值:
min_id:创建 ReadView 时活跃的事务中最小的事务id。max_id:本次快照拍下后的第一个事务id,该事务对本次快照来说是一个未开始的事务。
需要注意的是:一致性快照从拍下那一时刻开始,其中的值就已经确定了,只记录那一瞬间的状态,不会再改变了。其中活跃事务(trx_ids)指的是快照拍下的那一时刻所有未提交事务的id集合,min_id则是该集合中最小的事务id,max_id指的是本次快照拍下后的第一个事务。
Tips:在InnoDB中,MVCC只在RR和RC两个隔离级别下工作,因为RU隔离级别总是会读取最新的行,而不是符合当前事务版本的数据行。而Serializable则会对所有读取的行都加锁。
3.3.2 RR环境下MVCC查询流程
- 1)被查询的行记录中的trx_id等于当前的事务id(id=creator_trx_id):这部分数据能够被当前事务访问(说明自己创建的)。
- 2)被查询的行记录中的trx_id小于min_id(id<min_id):说明该记录为快照开启之前就已经提交的数据,能够被当前事务访问(图中绿色部分)。
- 3)被查询的行记录中的trx_id大于等于min_id小于max_id(min_id<=id<max_id):说明该记录为拍下快照后还未提交的事务,对当前快照来说属于活跃事务,不能被当前事务访问(蓝色部分)。
- 4)被查询的行记录中的trx_id大于max_id(id>=max_id):说明该记录是当前快照开启之后才插入的数据行,这部分数据对当前快照来说是未知的,所以这部分数据不能被当前事务访问(红色部分)。
测试表:
create table user(
id int primary key auto_increment,
name varchar(30),
age int
);
insert into user values(1,'小灰',18);
【案例-01】
| session-01 |
|---|
| begin; version:10 |
| select * from user; |
| insert into user values(2,"小蓝",20); |
| select * from user; -- 能否查询到小蓝? |
| update user set age=100 where id=2; |
| select * from user; -- 能否查询到age=100的修改? |
| rollback; |
Tips:小蓝记录的
DB_TRX_ID为10,修改过后的id=1的记录DB_TRX_ID也为10,id=creator_trx_id,因此能够查询到。
【案例-02】
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| select * from user; -- 能否查询到小蓝记录? | |
| rollback; |
Tips:小蓝这条记录属于快照拍下之前就提交的事务(id<min_id),可以查询到。
【案例-03】
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from user; -- 拍下了快照 | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| select * from user; -- 能否查询到小蓝? | |
| rollback; |
Tips:小蓝这条记录属于快照拍下后才存在的数据(id>=max_id),该记录对于快照来说属于未知事务的数据,因此查询不到。
【案例-04】
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| insert into user values(2,"小蓝",20); | |
| select * from user; --能否查询到小蓝? | |
| commit; | |
| rollback; |
Tips:小蓝这条记录属于快照拍下之前就存在的事务,但还未提交,属于活跃事务id集合(trx_ids)中的事务的数据,因此查询不到。
【案例-05】
| session-01 | session-02 |
|---|---|
| begin; | |
| select * from user; | |
| begin; | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| select * from user; -- 能否查询到小蓝? | |
| rollback; |
Tips:小蓝这条记录属于快照拍下后才存在的数据(id>=max_id),该记录对于快照来说属于未知事务的数据,因此查询不到。
3.3.3 RC环境下MVCC查询流程
RC的查询流程和RR的是一样的。RC与RR唯一的不同点在于ReadView生成的次数,RR只在事务开始时生成一次,RC则是在每次select语句时都生成一次;也就是说在RC的隔离级别下,每次select的时候trx_ids都是在变化的(前提是有新的事务开启了)。
修改隔离级别:
-- 将隔离级别设置为提已提交(会话级别)
set session transaction isolation level read committed;
【案例-01】
| session-01 |
|---|
| begin; version:10 |
| select * from user; |
| insert into user values(2,"小蓝",20); |
| select * from user; -- 能否查询到小蓝? |
| update user set age=100 where id=2; |
| select * from user; -- 能否查询到age=100的修改? |
| rollback; |
Tips:小蓝记录的
DB_TRX_ID为10,修改过后的id=1的记录DB_TRX_ID也为10,id=creator_trx_id,因此能够查询到。
【案例-02】
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| select * from user; -- 能否查询到小蓝记录? | |
| rollback; |
Tips:小蓝这条记录属于快照拍下之前就提交的事务(id<min_id),可以查询到。
【案例-03】
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from user; -- 拍下了快照 | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| -- 对于RC来说,这是重新拍下了快照 select * from user; -- 能否查询到小蓝? | |
| rollback; |
Tips:在新的快照中,小蓝这条记录属于拍照拍下前就已经提交的数据(id<min_id),可以被查询到。
【案例-04】
| session-01 | session-02 |
|---|---|
| begin; | |
| select * from user; | |
| begin; | |
| insert into user values(2,"小蓝",20); | |
| commit; | |
| -- 对于RC来说,这是重新拍下了快照 select * from user; -- 能否查询到小蓝? | |
| rollback; |
Tips:在新的快照中,小蓝这条记录属于拍照拍下前就已经提交的数据(id<min_id),可以被查询到。
测试完毕将隔离级别修改回来:
set session transaction isolation level repeatable read;
3.4 MVCC原理与事务ID
在InnoDB存储引擎中,事务ID(Transaction ID,通常缩写为TRX ID)是用于标识每个事务的一个唯一标识符。事务ID是时由InnoDB存储引擎自动分配的,并且每个新的事务都会获得一个唯一的事务ID,事务ID分配呈向上增长趋势,即后分配的事务ID总是比前面分配的事务ID要大。事务ID主要用于InnoDB内部的行级锁定机制以及多版本并发控制(MVCC)中,以确保数据的一致性和隔离性。
事务ID并非在开启事务时分配,而是在执行SQL语句时分配,一旦分配了事务ID,它在整个事务期间保持不变。但并非所有的SQL语句都会导致分配事务ID。通常来说,只有执行那些会修改数据库状态的语句(如INSERT、UPDATE、DELETE等)才会分配事务ID。但是当一个事务中只存在查询语句时,InnoDB会将当前事务定义为“只读事务”,并且为当前的只读事务分配一个只读事务id。这个事务id的值比一般的非只读事务的id要大很多,可以很好的与修改事务id作区分。在information_schema数据库的innodb_trx表中存储着活跃事务的id。
测试表:
drop table if exists user;
create table user(
id int primary key auto_increment,
name varchar(30),
age int
);
insert into user values(1,'小灰',18);
示例代码:
begin;
-- 此时查询事务id为空(事务id还未分配)
select trx_id from information_schema.innodb_trx;
-- 执行查询(分配只读事务id)
select * from user;
-- 事务id:421940713278176
select trx_id from information_schema.innodb_trx;
-- 执行insert语句,分配非只读事务id
insert into user values(2,"小蓝",20);
-- 事务id:1808
select trx_id from information_schema.innodb_trx;
-- 回滚事务,事务id销毁
rollback;
-- 查询事务id为空
select trx_id from information_schema.innodb_trx;
【事务id案例-01】
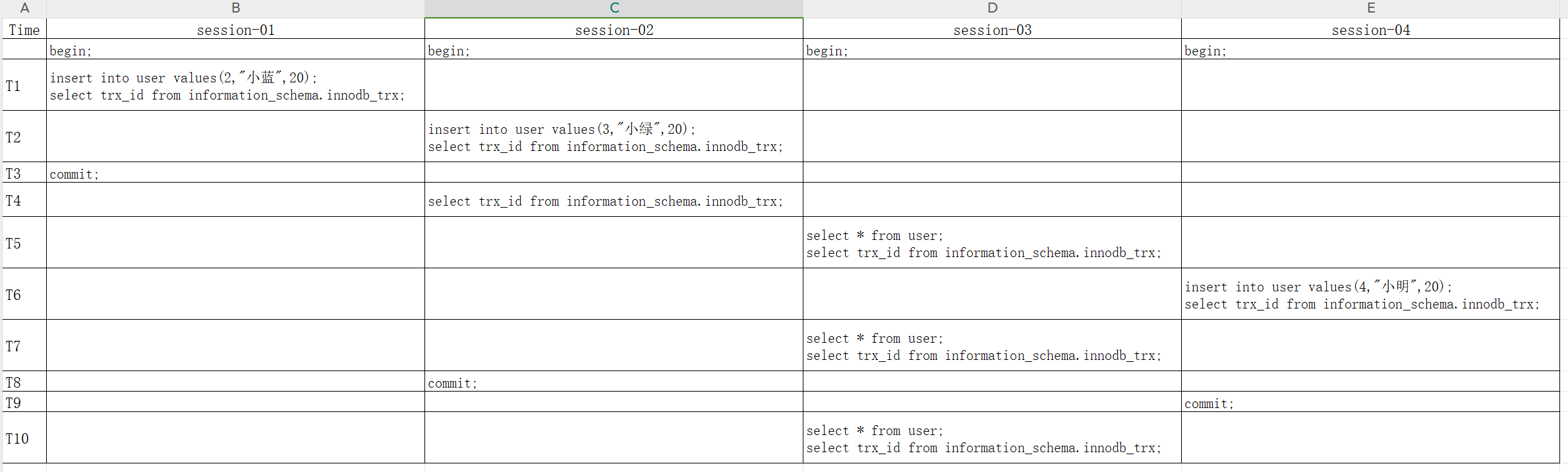
| Time | session-01 | session-02 | session-03 |
|---|---|---|---|
| -- 开启事务不涉及到事务ID,事务开启顺序不影响测试 begin; | begin; | begin; | |
| T1 | -- 执行insert,分配非只读事务id insert into user values(2,"小蓝",20); -- 查询事务id select trx_id from information_schema.innodb_trx; | ||
| T2 | -- 执行查询,分配只读事务id select * from user; -- 查询事务id select trx_id from information_schema.innodb_trx; | ||
| T3 | -- 事务提交,事务ID销毁 commit; | ||
| T4 | -- 查询事务id select trx_id from information_schema.innodb_trx; | ||
| T5 | -- 执行insert,分配非只读事务id insert into user values(3,"小绿",20); -- 查询事务id select trx_id from information_schema.innodb_trx; | ||
| T6 | select * from user; | ||
| T7 | commit; | ||
| T8 | select * from user; |
T1时刻的事务ID:
58126(小蓝的事务id)
T2时刻的事务ID:
58126(小蓝的事务id)
283929123990168(只读事务ID)
T4时刻的事务ID:
283929123990168(只读事务ID)
T5时刻的事务ID:
58131(小绿的事务id)
283929123990168(只读事务ID)
结合MVCC的分析:
在T1时刻执行了insert语句,分配了事务ID为58126(小蓝的事务ID)。
在T2时刻执行了查询,拍下了一致性快照ReadView,当前快照中把小蓝的事务ID定义为活跃事务id,即存储在trx_ids集合中。
在T3时刻将小蓝这条数据提交,事务ID销毁,但并不影响T2时刻拍下的一致性快照。所以小蓝这条数据对于T2时刻拍下的快照仍然是不可见的,除非当前事务能够重新拍一次快照(RC隔离级别)。
在T4时刻查询事务ID能够发现已提交的事务ID被回收。
在T5时刻执行了insert,分配了事务ID为58131(小绿的事务ID),这条数据对于之前拍下的快照是不可知的。
在T6时刻执行查询,查询的是之前在T2时刻拍下的快照,即无法查询到小蓝也无法查询到小绿。
在T7时刻将小绿这条数据提交,事务ID销毁,仍然不影响在T2时刻就拍下的快照,所以小绿这条数据仍然对于T2时刻拍下的快照是不可见的。
在T8时刻执行查询,查询的是之前在T2时刻拍下的快照,即无法查询到小蓝也无法查询到小绿。
【事务ID案例-02】
事务ID分析:
| Time | session-01 | session-02 | session-03 | session-04 |
|---|---|---|---|---|
| begin; | begin; | begin; | begin; | |
| T1 | 58163(小蓝) | |||
| T2 | 58168(小绿) 58163(小蓝) | |||
| T3 | -- 提交事务,事务ID销毁 commit; | |||
| T4 | 58168(小绿) | |||
| T5 | -- 拍下快照 58168(小绿) 283929123991912(只读事务ID) | |||
| T6 | 58169(小明) 58168(小绿) 283929123991912(只读事务ID) | |||
| T7 | -- 查询之前的快照 58168(小绿) 283929123991912(只读事务ID) | |||
| T8 | -- 提交事务,事务ID销毁 commit; | |||
| T9 | -- 提交事务,事务ID销毁 commit; | |||
| T10 | -- 查询之前的快照 58168(小绿) 283929123991912(只读事务ID) |
结合MVCC的分析:
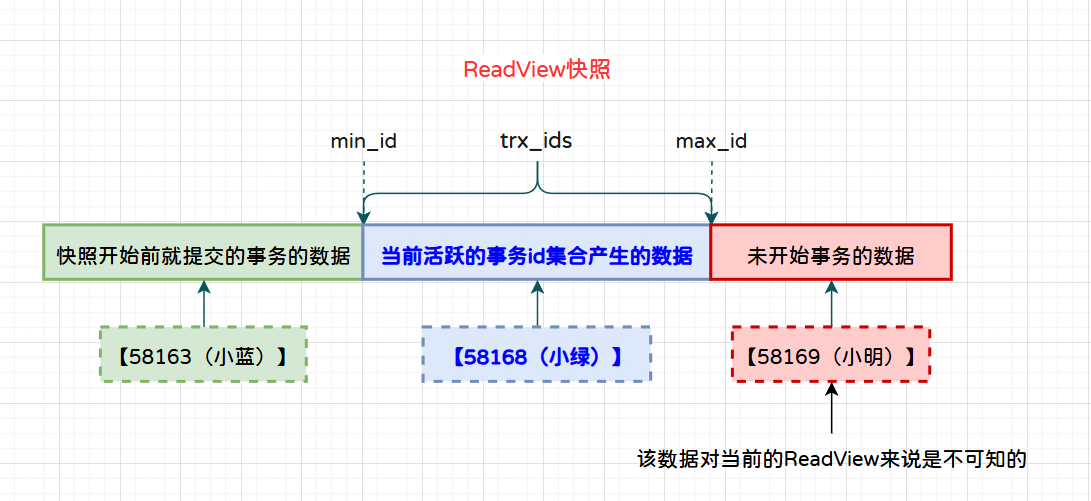
T1:执行了insert语句,分配了事务ID为58163(小蓝的事务ID)。
T2:执行了insert语句,分配了事务ID为58168(小绿的事务ID)。
T3:提交了事务,事务ID58163(小蓝)销毁。
T4:查询当前所有的事务ID,只有58168(小绿)。
T5:拍下一致性快照,当前的快照中将58168(小绿)定义为活跃事务id,并且58163(小蓝)则不在trx_ids集合中,属于快照拍下前就提交的事务产生的数据,这条数据(小蓝)对于当前快照来说是可见的。
T6:执行了insert语句,分配了事务ID为58169(小明的事务ID)。
T7:执行查询,查询的还是T5时刻拍下的快照,能查询到小蓝,但不能查询到小绿和小明。
T8:提交了事务,事务ID58168(小绿)销毁。
T9:提交了事务,事务ID58169(小明)销毁。
T10:执行查询,查询的还是T5时刻拍下的快照,能查询到小蓝,但不能查询到小绿和小明。
3.5 快照读和当前读
我们根据Undo日志的工作原理可以分析,当一个事务对表的任何的更新操作都会事先记录到Undo日志,当另一个事务查询的上一个事务的操作的那条数据时,返回的是当前事务的快照,也就是Undo日志中的记录;我们把这种读取也称之为快照读取;
当前读:即读的必须是当前最新的数据,当前读在每次读取都加上了锁,例如S锁(lock in share mode)、X锁(for update)等,当前读用于读取的是数据最新的版本,但当前读会对记录加锁,在事务并发访问情况下,如果其他事务对该记录加上了排它锁,那么当前读进入阻塞状态;同样的如果使用当前读读取数据,该数据也不能被其他事务加上排它锁;
快照读:在InnoDB事务中默认的读取方式就是快照读,即:select * from user [where xxx];这些操作默认都不会加锁的,这些操作读的都是数据的快照;快照读的出现极大的提升了InnoDB在并发读写能力上的提升;但由于快照读所读取的数据都是快照(旧版本数据),所以说快照读取并不一定是最新版本的数据;
我们来看一个案例:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from user where id=1; -- age=18 (快照读) | |
| update user set age=20 where id=1; | |
| select * from user where id=1; -- age=18(快照读,保证读已提交) | |
| commit; | |
| select * from user where id=1; -- age=18(快照读,保证可重复读) | |
| -- age=20(当前读,读的是最新的版本) select * from user where id=1 lock in share mode; | |
| commit/rollback; |
当前读读的是最新的数据,但与此同时,id=1的这行记录已经被加上S锁了,其他事务要对其update(加X锁)就会被其阻塞,并发能力差;
需要注意的是,快照读的前提是隔离级别不是串行化级别,串行化级别下的快照读会进化成当前读;另外,读未提交和串行化的隔离级别是没有MVCC快照的。
快照读(Snapshot Read),这种一致性不加锁的读(Consistent Nonlocking Read),就是 InnoDB 并发如此之高的核心原因。
3.6 InnoDB与隔离级别
在InnoDB存储引擎中,不同的事务隔离级别对性能有着直接的影响。这是因为不同的隔离级别在并发控制上的强度不同,这会影响到锁的使用方式以及多版本并发控制(MVCC)的应用。以下是四种主要的事务隔离级别及其对性能的潜在影响:
- 读未提交(Read Uncommitted, RU):
- 这个隔离级别下的性能最高,因为它几乎不使用任何锁,也不需要维护很多版本信息,性能是最佳的(例如隐藏字段)。
- 但由于缺乏隔离性,它可能导致脏读(读取到了未提交的数据),这在某些应用场景中可能是不可接受的。
- 读已提交(Read Committed, RC):
- 每个事务只读取已经提交的数据,这比RU提供了更好的数据一致性。
- 虽然RC比RU有更多的锁,但这些锁通常只是针对单行的共享锁(S锁),因此性能仍然较好。
- RC级别下的并发性能相对RR较高,但由于缺乏可重复读特性,可能导致幻读现象(同一查询返回不同的结果集)。
- 可重复读(Repeatable Read, RR):
- 这是InnoDB默认的隔离级别,它提供了一个很好的平衡点,在保证一定隔离性的同时也尽量减少了锁的竞争。
- 使用MVCC来实现读取操作不阻塞写入操作,同时保证了事务内的可重复读。
- 由于MVCC的使用,RR级别下的读操作通常不会阻塞写操作,这有助于提高并发性能。
- 但是,为了维护版本信息,RR级别会保留更多的旧版本数据,这可能会增加存储空间的使用。
- 序列化(Serializable):
- 提供最强的隔离性,但也是最保守的并发控制策略。
- 在SERIALIZABLE隔离级别下,读操作可能会被写操作阻塞,直到写操作完成或回滚。
- 由于严格的锁机制,这种隔离级别可能会导致较多的锁竞争,从而降低并发性能。
选择哪个隔离级别应该基于应用程序的具体需求。如果应用程序能够容忍较低的隔离性并且需要尽可能高的并发性能,那么可以选择较低的隔离级别如RU或RC。相反,如果应用程序需要较高的数据一致性和隔离性,那么应该选择较高的隔离级别如RR或SERIALIZABLE,尽管这样可能会牺牲一些性能。在实际应用中,通常会在RR和RC之间做出选择,前者提供了较好的隔离性,而后者则提供了更好的并发性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号