01【MySQL架构、查询缓存】
01【MySQL架构、缓存】
第1章 MySQL安装
1.1 MySQL安装
1)下载安装wget命令
yum -y install wget
2)在线下载mysql安装包
mkdir mysql
cd mysql
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
3)解压mysql安装包:
tar -xvf mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
安装包介绍:
| 安装包名称 | 简介 |
|---|---|
mysql-community-client |
MySQL客户端应用程序和工具 |
mysql-community-common |
服务器和客户端库的通用文件 |
mysql-community-devel |
MySQL数据库客户端应用程序的开发头文件和库 |
mysql-community-embedded-compat |
MySQL服务器作为嵌入式库,与使用库版本18的应用程序兼容 |
mysql-community-libs |
MySQL数据库客户端应用程序的共享库 |
mysql-community-libs-compat |
以前的MySQL安装的共享兼容性库 |
mysql-community-server |
数据库服务器和相关工具 |
mysql-community-server-debug |
调试服务器和插件二进制文件 |
mysql-community-test |
MySQL服务器的测试套件 |
mysql-community |
RPM的源代码看起来类似于mysql-community-8.0.24-1.el7.src.rpm,具体取决于所选的OS |
4)安装mysql服务:
rpm -ivh mysql-community-server-5.7.32-1.el7.x86_64.rpm
出现如下错误:

安装server被其他模块依赖;我们必须安装顺序来安装
5)安装如下顺序进行安装:
rpm -ivh mysql-community-common-5.7.32-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-libs-5.7.32-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-client-5.7.32-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-server-5.7.32-1.el7.x86_64.rpm --nodeps --force
6)启动MySQL
systemctl start mysqld
1.2 MySQL修改密码
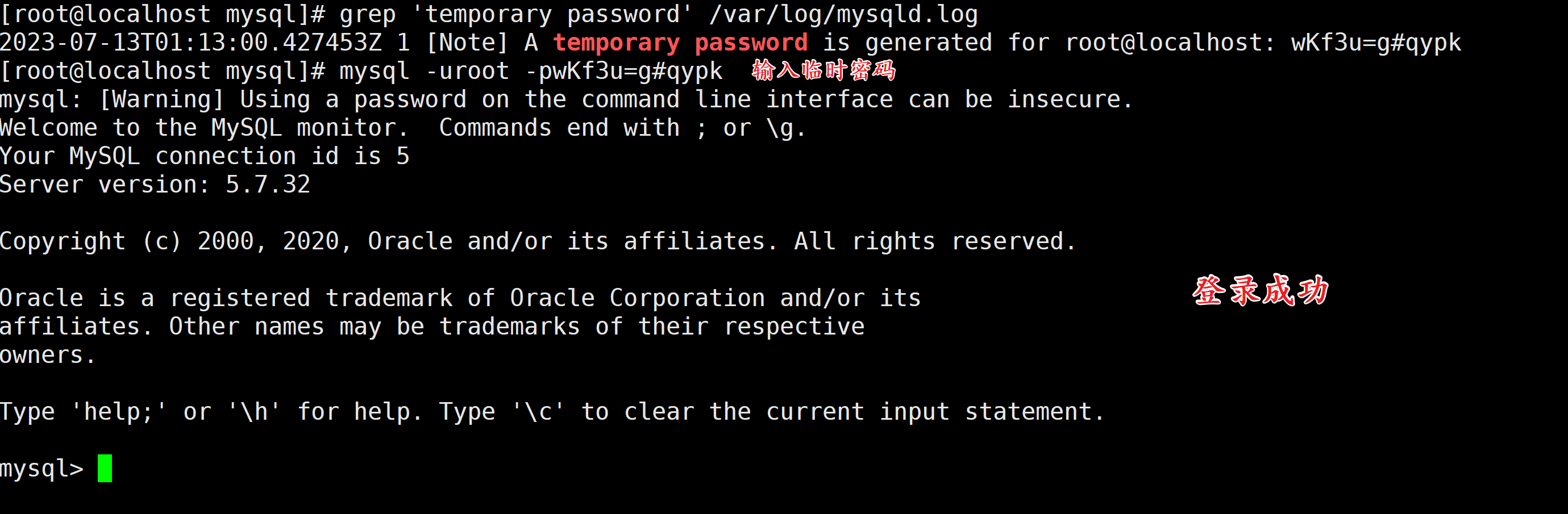
1)获取临时密码
grep 'temporary password' /var/log/mysqld.log

2)登录MySQL
mysql -uroot -pwKf3u=g#qypk
3)将MySQL的密码校验强度改为低风险
set global validate_password_policy=LOW;
4)修改MySQL的密码长度
set global validate_password_length=5;
5)修改MySQL密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'admin';
1.3 允许远程访问
1)首先要关闭Cenots的防火墙
sudo systemctl disable firewalld
2)切换到mysql数据库
use mysql;
3)查看user表
select Host,User from user;
4)发现root用户只运行localhost访问,修改为允许任何地址访问
update user set Host='%' where User='root';
5)刷新权限
flush privileges;
6)使用Navicat连接工具测试
7)设置不区分大小写
Linux版本的MySQL默认是区分大小写了,如果想要使MySQL不区分大小写,可以在MySQL的配置文件(/etc/my.cnf)中设置:
lower_case_table-names=1
8)重启服务器
systemctl restart mysqld
- 创建测试表
CREATE DATABASE `db01` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `db01`;
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
insert into `class`(`id`,`name`) values
(1,'Java'),
(2,'UI'),
(3,'产品');
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`class_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
/*Data for the table `student` */
insert into `student`(`id`,`name`,`class_id`) values
(1,'张三',1),
(2,'李四',1),
(3,'王五',2),
(4,'赵刘',1),
(5,'钱七',3);
第2章 MySQL架构与执行流程
MySQL 数据库是单进程多线程的架构,和 SQL Server 类似,和 Oracle 不一样,Oracle 是多进程架构。
2.1 MySQL组件及架构
MySQL 是一种广泛使用的开源关系型数据库管理系统(RDBMS)。它的架构设计使得它能够高效地处理数据存储、检索和其他数据库操作。下图描述了MySQL的架构及各组件的作用。
MySQL主要有如下组件构成:
- Connectors:连接组件:
- 向外界的其他应用程序提供连接接口,实现外部程序访问MySQL,与MySQL进行交互
- Management Service&Utilities:服务管理与工具组件
- 提供MySQL系统管理、安全管理、权限校验、系统表管理、主从复制、集群等模块功能
- Connection Pool:连接池管理
- 负责外部连接MySQL校验、线程池的维护、线程重用、连接限制等,当一个外部连接成功连接MySQL之后,MySQL将会为其分配一个线程与固定的内存与该客户端进行交互,当此次会话结束后,线程将重回线程池;
- SQL Interface:MySQL对外提供的一系列功能性接口方法,例如我们调用存储过程、创建视图、触发器等都是调用对应的接口来实现对应的功能
- Parser:MySQL语法解析器,将对应的SQL进行解析、生成解析树,并对SQL语句进行语法校验;最后生成预处理报告,交由优化器进行优化
- Optimizer:优化器;我们实际发送的SQL语句并不是MySQL真正执行的SQL语句,优化器会有一系列成本计算方法来帮我们计算出一个最佳效率的SQL语句
- Cache & Buffer:查询缓存以及数据页缓冲模块
- Storage Engine:存储引擎;存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信,不同的存储引擎具有功能不同,MySQL提供了插拔式存储引擎;
- File System:文件系统;主要是将数据存储在运行与裸设备的文件系统之上,并完成与存储引擎的交互。
2.2 SQL语句的执行流程
MySQL的执行流程如图所示:
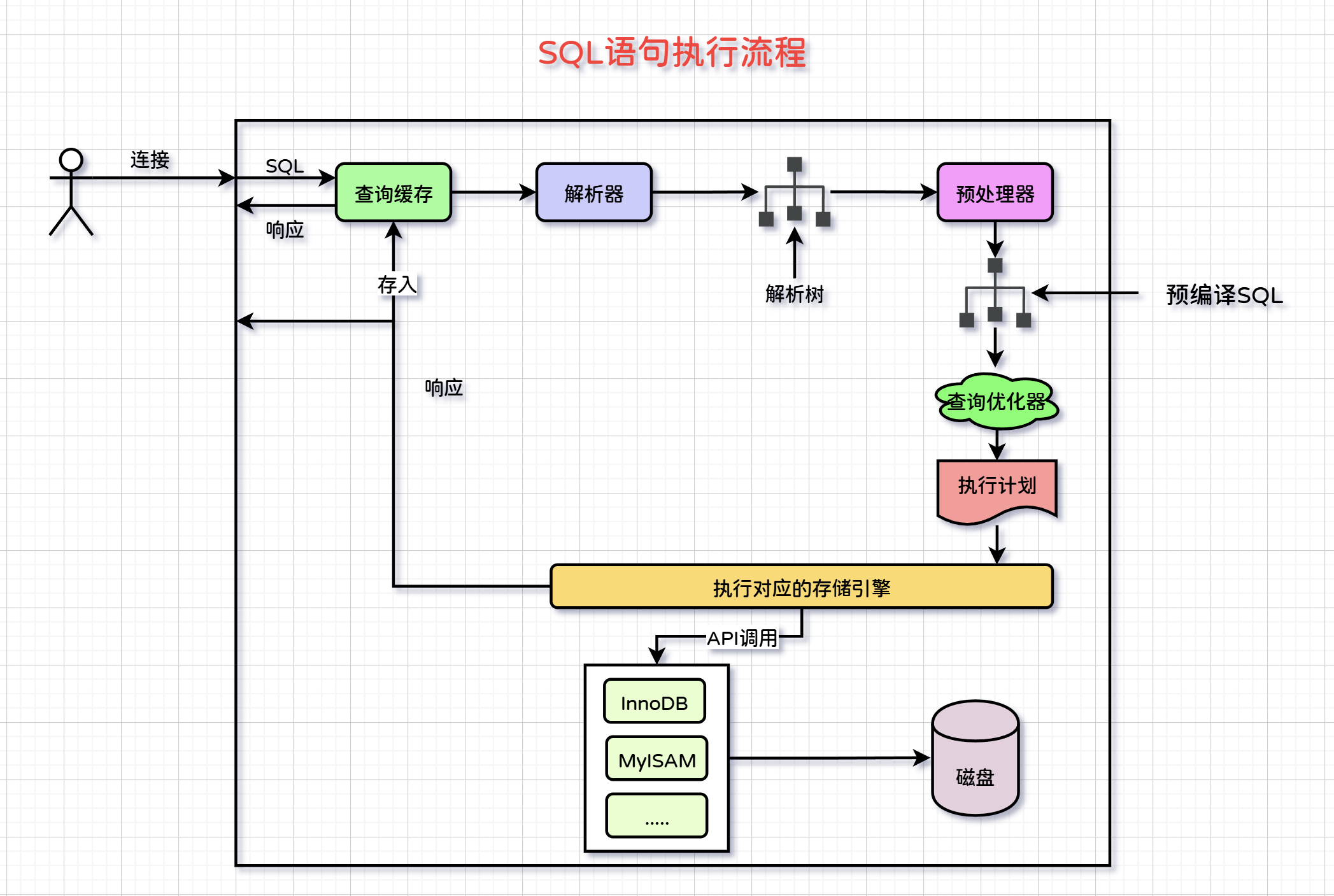
1)用户发送SQL语句来到MySQL服务端,首先查询缓存(Query Cache),如果缓存有数据直接响应,如果没有则进行下一步。
2)然后解析器(Parser)会解析SQL语句的结构并创建一个语法解析树。
3)接着服务器开始对SQL语句进行编译,在这个阶段SQL并没有立即执行,而是为它分配一个预编译句柄。这个句柄可以在后续的操作中用来执行该语句,而无需每次都对同样的SQL语句重新解析和编译。
4)接着优化器会根据一些已有的原则来定制出多个执行计划,这个过程包括表的顺序、索引的选择以及是否使用临时表等。最终选择一个代价最低的方案来执行查询。优化器的优化过程,执行的详细过程将会列在执行计划这个“清单”中。
5)根据优化器制定的执行计划,服务器开始执行查询。如果涉及到多个表,服务器将按照预定的顺序读取这些表的数据。执行过程中,如果有必要,服务器会利用索引来加速数据检索。
6)在执行SQL语句时,服务器会调用对应的存储引擎,这些存储引擎决定了数据的组织结构、排列方式等,由存储引擎调用IO系统从磁盘中读取数据。
2.3 解析器
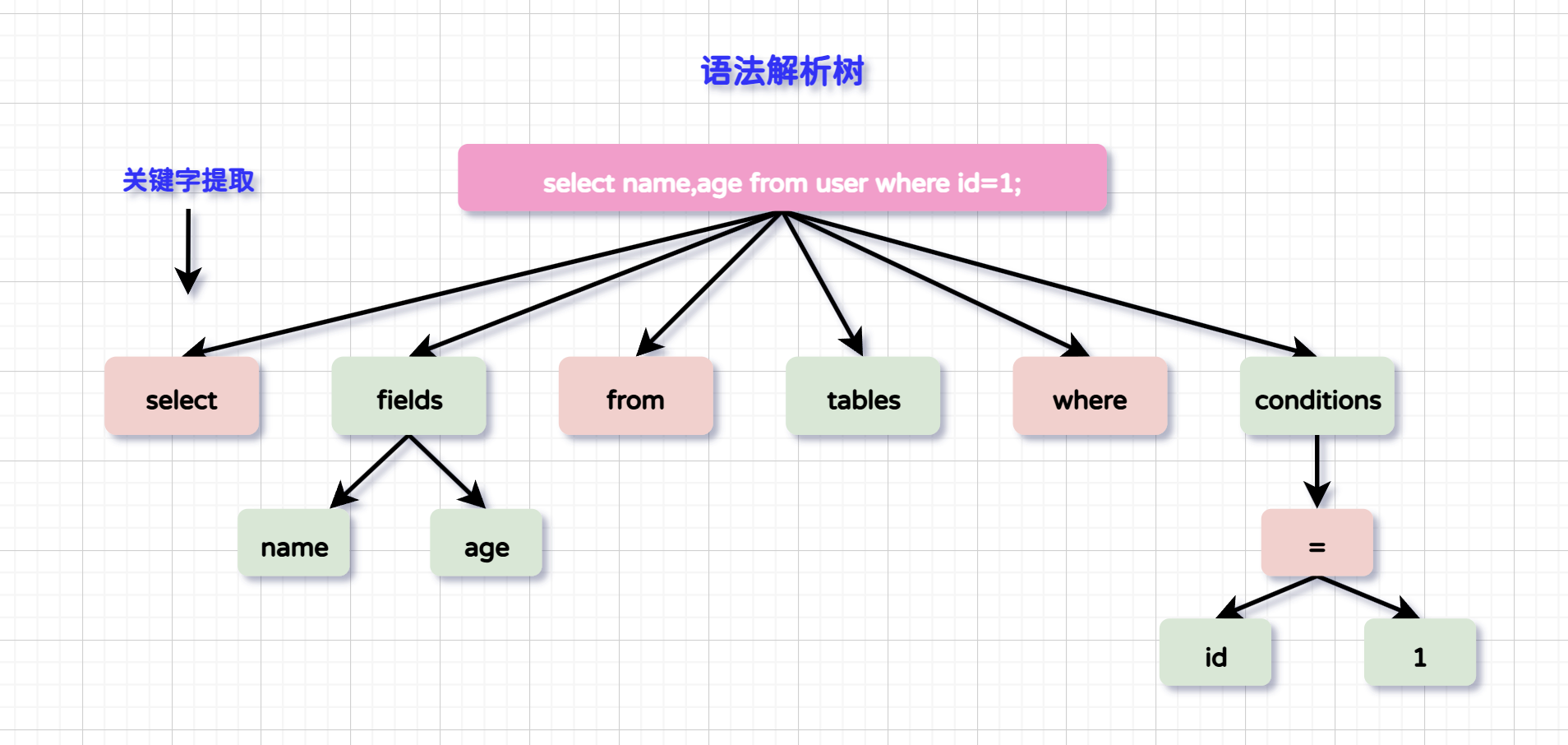
一条SQL来到MySQL服务端如果没有命中缓存则接下来要被解析器(Parser)进行语法的解析,解析器会对SQL进行语法分析、词法分析、语义分析等。最终生成一颗SQL解析树,并将其转换为内部格式,以便MySQL进一步处理。
- 词法分析(Lexical Analysis):将查询字符串分解成一系列的“记号”(tokens),做关键字提取。这些记号包括关键词、表名、列名、运算符、常量等。这个过程利用了一个词法分析器(Lexer),它根据预定义的规则识别出不同类型的记号。
- 语法分析(Syntactic Analysis):经过词法分析后,接下来解析器会根据 SQL 的语法规则,对词法分析得到的记号序列进行语法分析。这一步是通过使用上下文无关文法(CFG)来验证记号的结构是否符合 SQL 语法。解析器会构建一个抽象语法树(AST),这个树结构表示了 SQL 查询的语法结构和逻辑关系。
- 语义分析(Semantic Analysis):在语法分析完成后,解析器会进行语义分析。这一步主要是检查 SQL 查询的逻辑和语义的正确性。例如:表和列的名称是否存在、数据类型是否兼容、权限和访问控制是否正确等。
语法解析树如图所示:
2.4 预编译
预编译是指将 SQL 语句发送到数据库服务器上进行解析和编译,但不立即执行。在这个阶段,数据库服务器会解析 SQL 语句的结构,并为它分配一个预编译句柄。这个句柄可以在后续的操作中用来执行该语句,而无需每次都重新解析和编译。
Tips:预编译语句是一种在数据库中预先编译 SQL 语句的技术,这样可以提高应用程序的性能,并增强安全性,尤其是在处理参数化查询时。
2.4.1 预编译的流程
通常我们发送一条SQL语句给MySQL服务器时,MySQL服务器每次都需要对这条SQL语句进行校验、解析等操作。但是有很多情况下,我们的一条SQL语句可能需要反复的执行,而SQL语句也只可能传递的参数不一样,类似于这样的SQL语句如果每次都需要进行校验、解析等操作,未免太过于浪费性能了,因此MySQL提出了SQL语句的预编译。
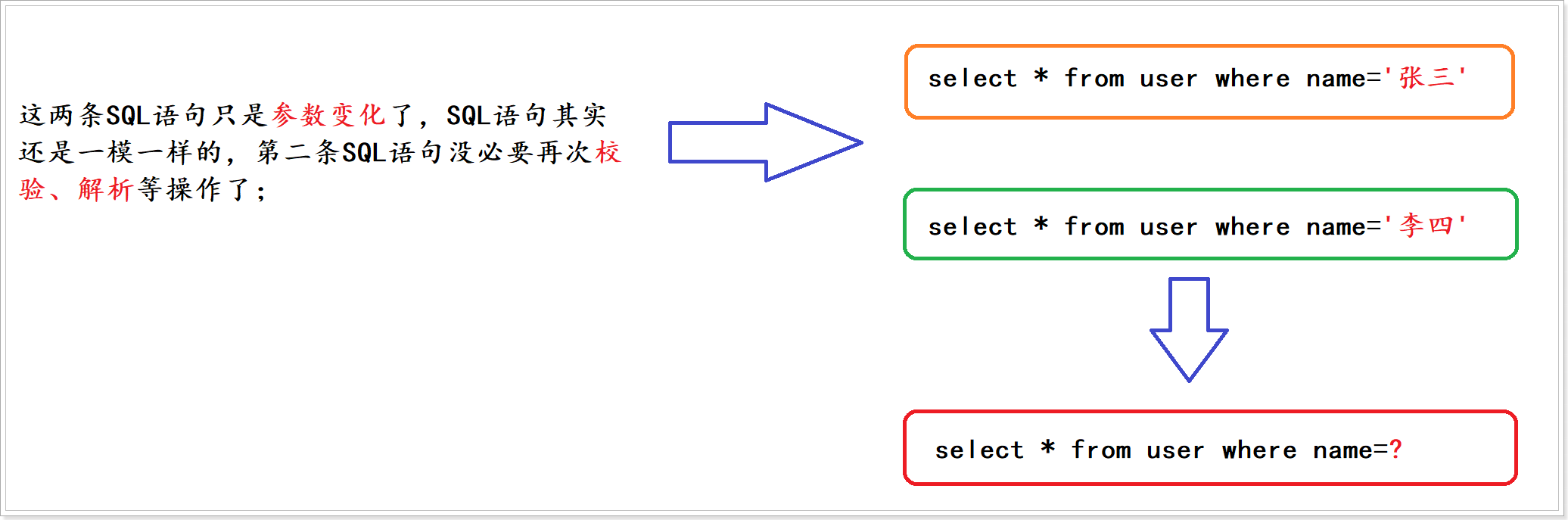
所谓预编译就是将一些灵活的参数值以占位符?的形式给代替掉,我们把参数值给抽取出来,把SQL语句进行模板化。让MySQL服务器执行相同的SQL语句时,不需要在校验、解析SQL语句上面花费重复的时间,因此就是来提高我们的查询速度的;
- 预编译的流程:
1)预编译:首先,SQL 语句被发送到数据库服务器上进行解析和编译。在这个阶段,语句的结构被分析,但具体的值还没有被确定。
2)参数绑定:接着,在客户端,实际的值被绑定到预编译语句中的占位符(通常是问号 ? 或者特定的命名参数)。这些占位符代表了将在服务器上执行时使用的具体值。
3)执行:当所有参数都被绑定后,预编译语句就可以被执行。由于语句已经被编译过,因此再次执行相同的语句时只需要重新绑定参数值即可,而不需要重新解析和编译。
2.4.2 使用预编译
创建一张测试表:
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名称',
`birthday` datetime(0) NULL DEFAULT NULL COMMENT '生日',
`sex` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别',
`address` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `user` VALUES (1, '小灰', '2024-02-27 17:47:08', '男', '湖北武汉');
INSERT INTO `user` VALUES (2, '小蓝', '2024-03-02 15:09:37', '女', '江西南昌');
INSERT INTO `user` VALUES (3, '小绿', '2024-07-04 11:34:34', '女', '河南郑州');
INSERT INTO `user` VALUES (4, '小红', '2024-03-04 12:04:06', '女', '安徽合肥');
INSERT INTO `user` VALUES (5, '小明', '2024-04-08 11:44:00', '男', '湖南长沙');
INSERT INTO `user` VALUES (6, '小龙', '2024-03-04 12:04:06', '男', '山西太原');
使用预编译:
-- 定义一个预编译语句
prepare user_findById from 'select * from user where id=?';
-- 设置占位符
set @id=1;
-- 执行预编译SQL
execute user_findById using @id;
-- 释放预编译SQL
deallocate prepare user_findById;
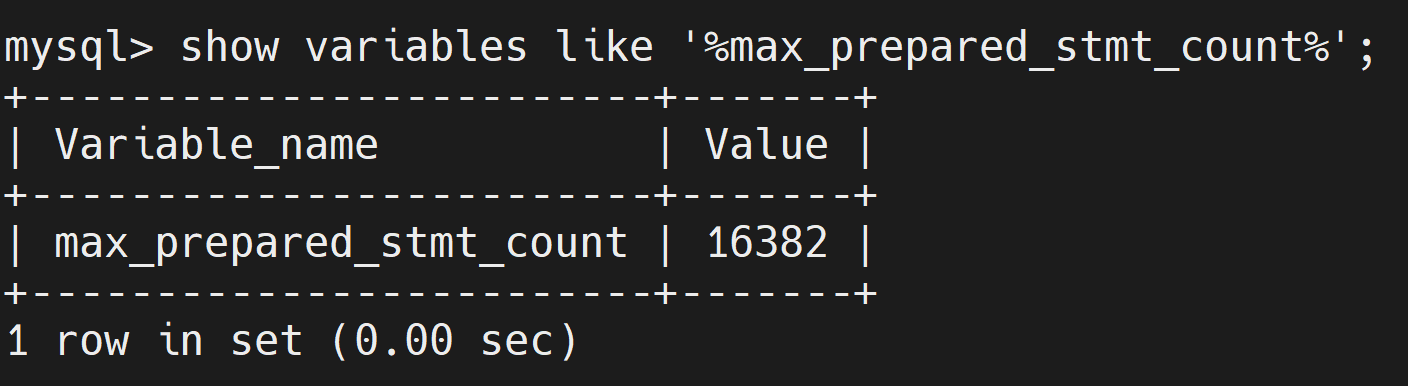
MySQL通过 max_prepared_stmt_count 变量用来控制全局最大存储的预编译语句数。
show variables like '%max_prepared_stmt_count%';
2.4.3 预编译的性能
预编译使得MySQL无需重新对同样的SQL语句重新进行校验、解析等动作,在一定程度上提升了MySQL执行SQL语句的性能。
在JDBC中,PreparedStatement的预编译功能默认是关闭的,要让其生效,必须在JDBC连接的URL设置useServerPrepStmts=true,让其开启预编译功能,,如下:
jdbc:mysql://localhost:3306/test01?&useServerPrepStmts=true
测试代码如下:
@Test
public void test() throws Exception {
System.out.println("开启预编译: ");
// 开启预编译
for (int i = 0; i < 5; i++) {
test1(true);
}
System.out.println("关闭预编译: ");
// 关闭预编译
for (int i = 0; i < 5; i++) {
test1(false);
}
}
/**
* 预编译性能测试
*
* @throws SQLException
*/
public void test1(Boolean flag) throws SQLException {
Connection connection =
DriverManager.getConnection("jdbc:mysql://192.168.166.128:3306/test01?useServerPrepStmts=" + flag, "root", "admin");
long startTime = System.currentTimeMillis();
// 只要预编译一次
PreparedStatement ps = connection.prepareStatement("select * from user where username = ?");
// 循环执行1W次同样的SQL,只有参数发送改变
for (int i = 0; i < 10000; i++) {
// 只需要修改占位符的参数值就行
ps.setString(1, UUID.randomUUID().toString());
// 执行查询
ps.executeQuery();
}
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
ps.close();
}
测试报告如下:
| 次数 | 开启预编译 | 关闭预编译 | 性能提升 |
|---|---|---|---|
| 第一次 | 5240ms | 5543ms | 5.79% |
| 第二次 | 5156ms | 5483ms | 6.34% |
| 第三次 | 5185ms | 5446ms | 5.03% |
| 第四次 | 5151ms | 5483ms | 6.45% |
| 第五次 | 5129ms | 5469ms | 6.63% |
通过上面表格可以看出,开启预编译之后查询性能能够得到一定的提升。
2.4.4 预编译的优缺点
对于频繁使用的语句,使用服务端 “预编译” 还是能够得到提升的。但是对于不频繁使用的语句,服务端预编译本身会增加额外的耗时,还会增加MySQL的使用内存。因此在实际开发中具体是否要开启预编译要根据情况而定。
我们观察如下测试。
@Test
public void test() throws Exception {
System.out.println("开启预编译: ");
// 开启预编译
for (int i = 0; i < 5; i++) {
test2(true);
}
System.out.println("关闭预编译: ");
// 关闭预编译
for (int i = 0; i < 5; i++) {
test2(false);
}
}
public void test2(Boolean flag) throws SQLException {
Connection connection =
DriverManager.getConnection("jdbc:mysql://192.168.166.128:3306/test?useServerPrepStmts=" + flag, "root", "admin");
long startTime = System.currentTimeMillis();
PreparedStatement ps = null;
for (int i = 0; i < 10000; i++) {
// 每次都预编译
ps = connection.prepareStatement("select * from user where username = ?");
ps.setString(1, UUID.randomUUID().toString());
// 执行查询
ps.executeQuery();
}
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
ps.close();
}
测试报告如下:
| 次数 | 开启预编译 | 关闭预编译 |
|---|---|---|
| 第一次 | 11383ms | 5611ms |
| 第二次 | 11055ms | 5533ms |
| 第三次 | 11271ms | 5537ms |
| 第四次 | 11489ms | 5580ms |
| 第五次 | 11609ms | 5557ms |
需要注意的是,上述的测试并不能完全的反应开启预编译后性能下降的具体数值,因为在测试代码中,每次预编译都会产生一个新的PreparedStatement对象,创建该对象也是需要花费一定时间的,因此上述测试仅供参考。
2.5 优化器
在很多场景下,MySQL优化器能够帮我们做出一些实质性的优化,例如子查询优化、JOIN优化和查询重写策略等。通过这些策略,优化器能够处理复杂的查询并优化性能。
2.5.1 优化器的工作流程
SQL语句在经过解析器得到语法树之后,MySQL内部提供有优化器对SQL语句进行优化处理。其工作流程如下:
1)优化器首先从表或索引中提取统计信息,如行数、数据分布、索引基数等。然后根据查询语句和统计信息等生成不同的执行计划。每个计划描述了数据如何被检索、连接以及排序,包括是否使用索引、使用哪个索引、表的扫描方式(全表扫描或索引扫描)等,执行计划是我们SQL调优的一个重要参考信息。
2)优化器为每个执行计划估算成本,这些成本由I/O、CPU、内存消耗等因素决定,优化器通过这些代价评估来判断执行计划的效率。在多个候选计划中,优化器最终会选择成本最低的计划作为最终执行计划,这个选择过程基于MySQL内部的成本模型。
3)在确定执行计划的过程中,优化器可能会对查询进行进一步优化,例如选择合适的连接顺序,评估是否适合使用索引或临时表,以及是否可以简化查询操作。
Tips:在我们执行SQL语句时并不是我写什么SQL语句MySQL就真正执行什么SQL语句,因为MySQL内部有优化器对其进行优化,可能最终执行的不是我们原来的SQL语句,但不管怎么优化,SQL语句最终查询的结果肯定是一致的;
2.5.2 SQL优化
查询优化器能够自动地将某些子查询转换为等效的连接查询或其他更高效的查询形式。这种优化通常在以下情况下发生:
1)IN 子查询优化
如果子查询返回一个列表,优化器可能会将IN子查询转换为连接查询。
例如:
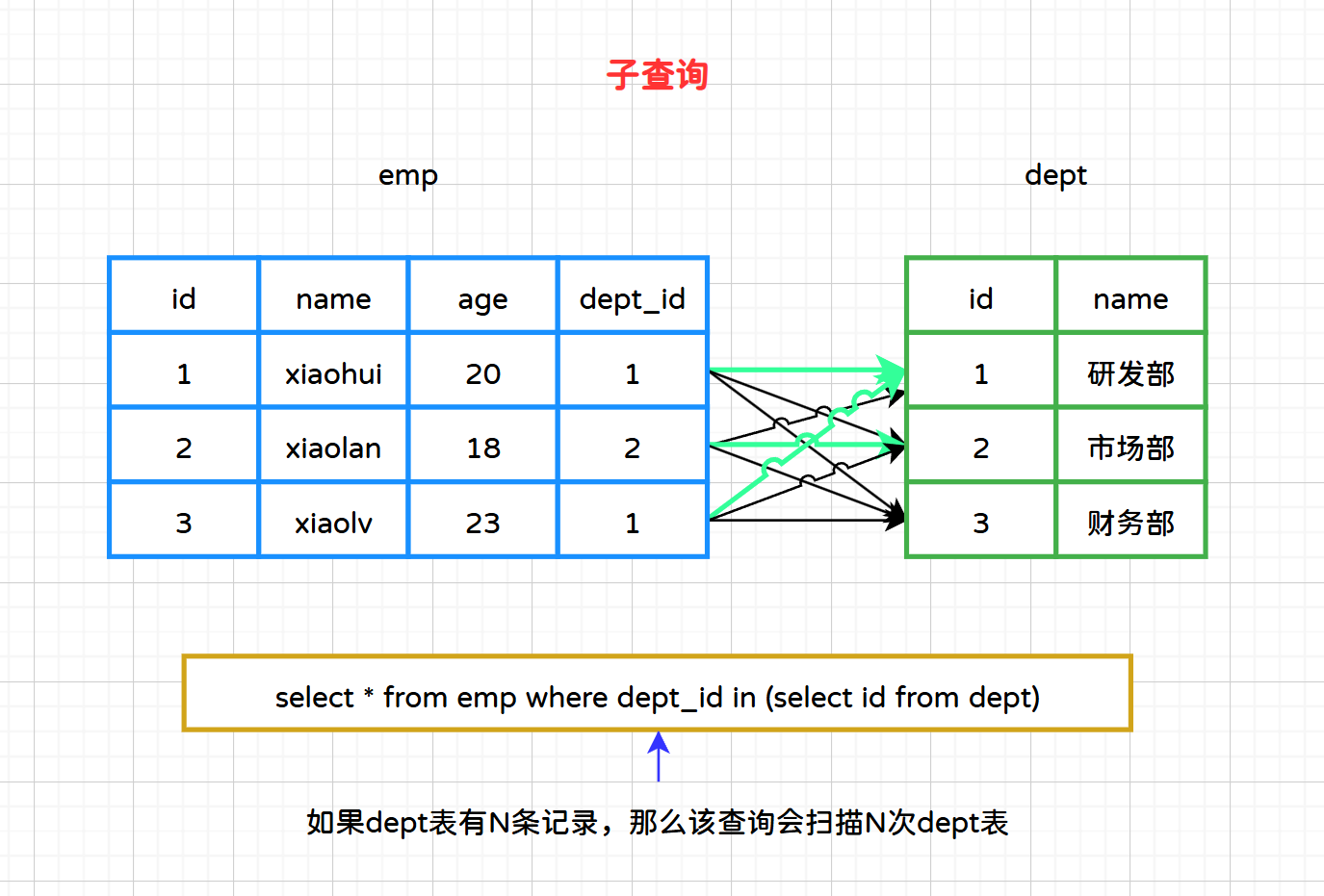
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept)
可能会被优化为
SELECT * FROM emp JOIN dept ON user.dept_id = dept.id。
- 1)子查询:对于每一个
user表中的记录,它都会检查dept_id是否存在于dept表中。如果dept表的数据量很大,那么这种查询可能会导致全表扫描,尤其是当没有合适的索引时。此外,某些数据库系统可能不会很好地优化这种形式的子查询,导致性能不佳。
子查询如图所示:
模拟算法如下:
// 先遍历外表
FOR each row e IN employees
// 外表的每一条记录都遍历一次内表
FOR each row d IN departments
// 符合条件的筛选
IF e.department_id == d.id THEN
OUTPUT (e.name, d.name)
在本查询中,外表的每条记录将会与内表每条记录进行匹配,查询性能低,而且索引优化空间小,存在索引优化局限性。
- 2)关联查询:它将
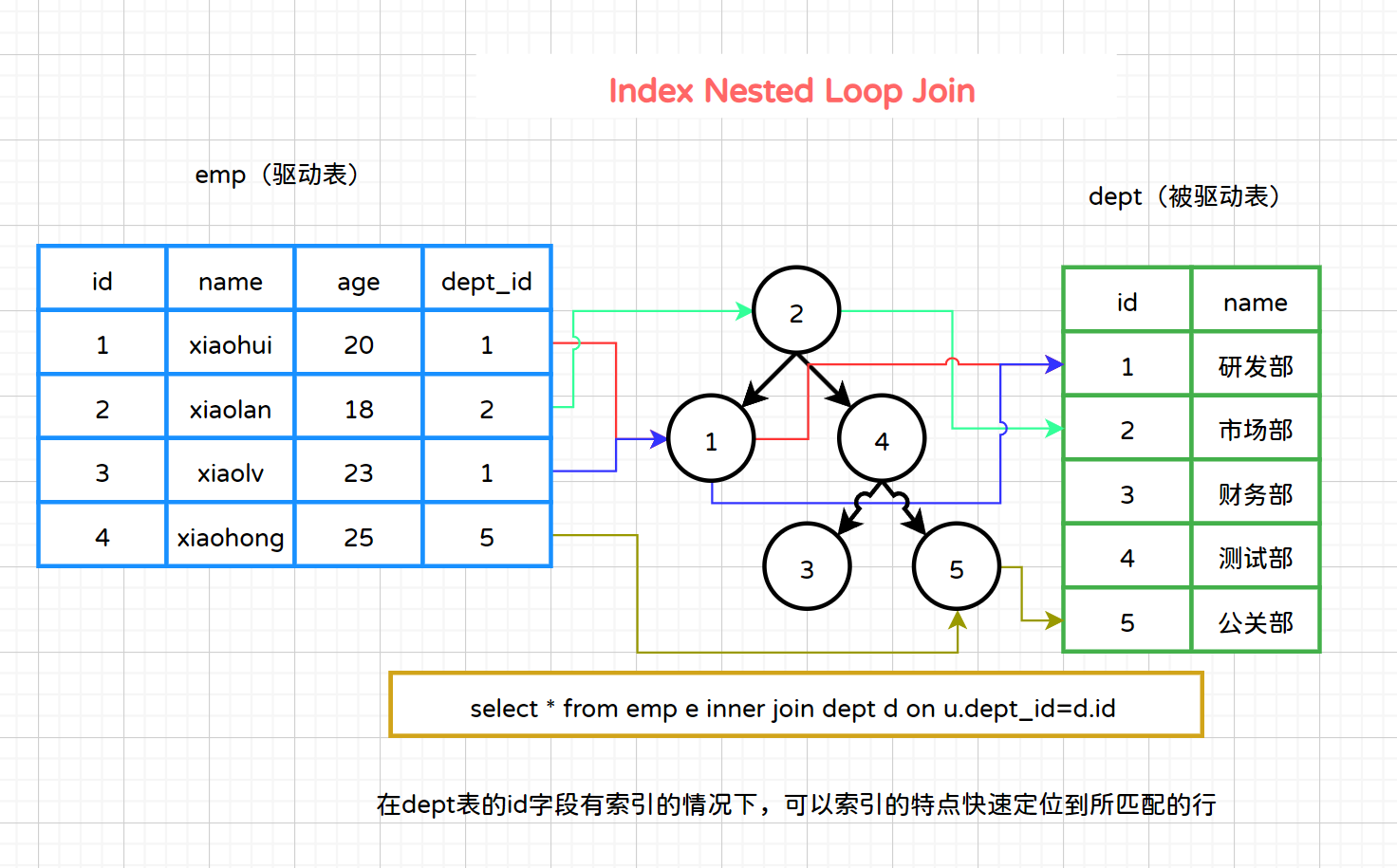
user表与dept表基于dept_id和id进行匹配。现代数据库系统通常对JOIN操作有很好的优化,且提供多种Join算法来优化Join操作,如NLJ、BNLJ、INLJ、IMLJ等等....这些算法可以在一定场景中改善Join操作的性能,并且可以利用索引来加速查找过程。JOIN操作通常会比IN子查询更高效,尤其是在处理较大的数据集时。
以Join算法中的INL为例,执行SELECT * FROM emp JOIN dept ON user.dept_id = dept.id语句时,当dept表的id字段建立索引时,可以利用dept表上的索引来快速查找匹配的记录。
INL算法如图所示:
模拟算法如下:
CREATE INDEX idx_department ON departments(id); // 假设已经存在这个索引
FOR each row e IN employees // 外层循环遍历左表
LOOKUP rows FROM departments USING idx_department WHERE id = e.department_id // 使用索引查找
FOR each matching row d // 遍历匹配的结果
OUTPUT (e.name, d.name)
2)EXISTS 子查询优化
如果子查询用于检查某个条件的存在性,优化器可能会将EXISTS子查询转换为连接查询。
当MySQL遇到EXISTS子查询时,它不会试图计算出所有可能的结果行,而是在找到第一个满足条件的行后就立即返回结果。这是因为EXISTS表达式只关心是否存在至少一行满足条件的数据,而不是关心具体有多少行或这些行的具体内容。
例如:
SELECT * FROM emp WHERE EXISTS (SELECT 1 FROM dept WHERE emp.dept_id = dept.id)
可能会被优化为
SELECT * FROM emp JOIN dept ON emp.dept_id = dept.id
EXISTS 查询模拟算法如下:
-- 假设我们有一个父表 `parent` 和一个子表 `child`
-- 我们想找出所有在 `child` 表中拥有相关记录的 `parent` 表中的记录
SELECT p.*
FROM parent p
WHERE EXISTS (
SELECT 1
FROM child c
WHERE c.parent_id = p.id
);
-- 伪代码表示MySQL优化器可能采取的步骤:
optimized_exists_query(parent_record):
-- 假设 'parent_id' 在 'child' 表上有一个索引
-- 使用索引来查找与当前父记录相关的子记录
index_lookup_result = use_index_to_find_child_records(parent_record.id)
-- 如果找到了至少一条记录,则立即返回true,结束搜索
if not empty(index_lookup_result):
return true
-- 如果没有找到任何记录,返回false
return false
-- 类似于之前的IN子查询的操作,先遍历外层循环,再遍历内存循环
for each parent_record in parent:
if optimized_exists_query(parent_record):
output parent_record
3)单行比较子查询优化
如果子查询返回单行数据,并且用于比较操作,优化器可能会将子查询转换为连接查询。
例如:
SELECT * FROM user WHERE dept_id = (SELECT id FROM dept WHERE name = '研发部')
可能会被优化为
SELECT * FROM user JOIN dept ON user.dept_id = dept.id AND dept.name = '研发部'
第3章 MySQL缓存
在MySQL的架构组件中存在一个查询缓存组件(Query Cache),它缓存了查询结果,KV形式保存在服务器内存中。如果运行相同的SQL,服务器直接从缓存中去获取结果,而不需要重新执行查询,查询缓存可以显著提高读密集型应用程序的性能。
然而,MySQL的查询缓存数据非常容易失效,如果这个表修改了(有修改的数据),那么使用这个表中的所有缓存将不再有效,查询缓存值得相关条目将被清空。表中得任何改变是指表中任何数据或者是结构的改变,包括insert、update、delete、truncate、alter table、drop table或者是drop database 等。显然,对于频繁更新的表,查询缓存不合适,对于一些不变的数据且有大量相同sql查询的表,查询缓存会节省很大的性能。
3.1 查询缓存的工作流程
缓存是有命中条件的,并不是所有的SQL语句都会进入缓存查找。
缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key。在判断命中前,mysql不会解析SQL,而是使用SQL去查询缓存,SQL上的任何字符的不同,如空格,注释,都会导致缓存不命中。如果查询有不确定的数据current_date(),那么查询完成后结果者不会被缓存,包含不确定的数的是不会放置到缓存中。
查询缓存的工作流程如下:
1)服务器接收SQL,以SQL和一些其他条件为key查找缓存。
2)如果找到了缓存,则直接返回缓存。
3)如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等。
4)执行完SQL查询结果以后,将SQL查询结果放入查询缓存。
3.2 查询缓存的配置
3.2.1 开启查询缓存
MySQL默认是将查询缓存关闭的,我们需要在配置文件中打开。
查询当前数据库缓存是否开启:
mysql> select @@query_cache_type;
+--------------------+
| @@query_cache_type |
+--------------------+
| OFF |
+--------------------+
1 row in set, 1 warning (0.00 sec)
修改配置文件:linux的是/etc/my.cnf,Windows的是C:\ProgramData\MySQL\MySQL Server 5.7\my.ini
在mysqld组下面增加:
query_cache_type=1
重启MySQL服务:
systemctl restart mysqld
再次查看:
mysql> select @@query_cache_type;
+--------------------+
| @@query_cache_type |
+--------------------+
| on |
+--------------------+
1 row in set, 1 warning (0.00 sec)
3.2.2 缓存参数
输入如下命令查询缓存相关参数
show variables like "%query_cache%";
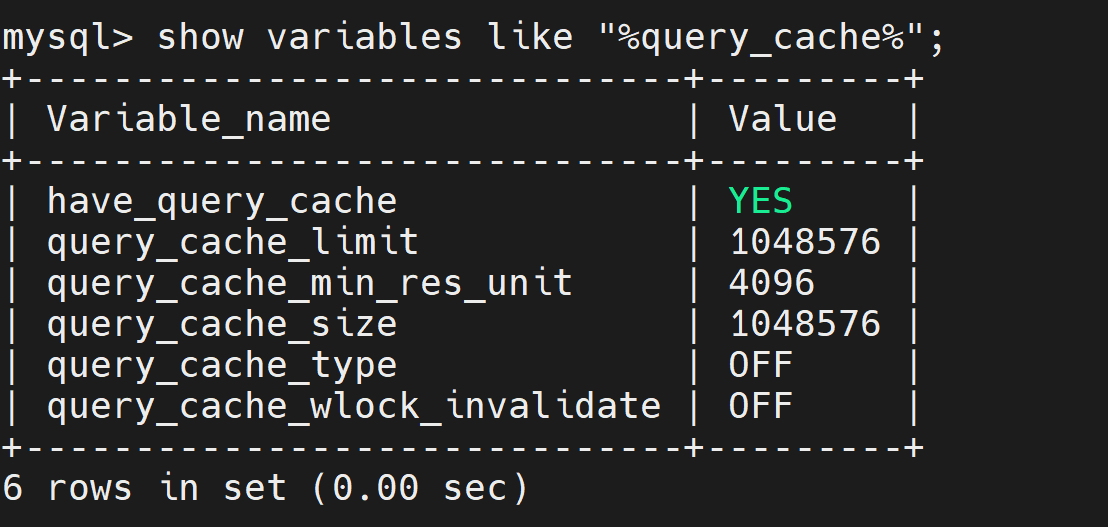
- have_query_cache:当前数据库版本是否支持缓存 NO:不支持 YES:支持
- query_cache_limit:查询缓存能缓存单个SQL语句的最大容量,单位:B
- query_cache_size:缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同
- query_cache_min_res_unit:分配内存块时的最小单位大小
- MySQL并不是一下子分配
query_cache_size大小的内存作为缓存,而且将整个查询缓存的大小分成了若干个内存块,query_cache_min_res_unit正是决定这些块的大小,需要注意的是,即使缓存的数据没有达到一个缓存块大小也需要占用一个缓存块大小的空间。如果超出单个缓存块,那么需要申请多个缓存块,当查询完发现有缓存块内存多余,造成缓存碎片。
- MySQL并不是一下子分配
- query_cache_type:是否打开缓存
select SQL_CACHE * from t_goods; -- 将查询结果放入缓存(前提缓存是开启的)
select SQL_NO_CACHE * from t_goods; -- 不缓存查询结果
- OFF(0):关闭缓存(默认值)
- ON(1):开启缓存(任意的select语句的结果集都会被缓存)
- DEMAND:只有明确写了SQL_CACHE的查询才会写入缓存
- query_cache_wlock_invalidate:如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回。
3.2.3 全局缓存状态
输入如下命令查询全局缓存状态:
show global status like '%Qcache%';
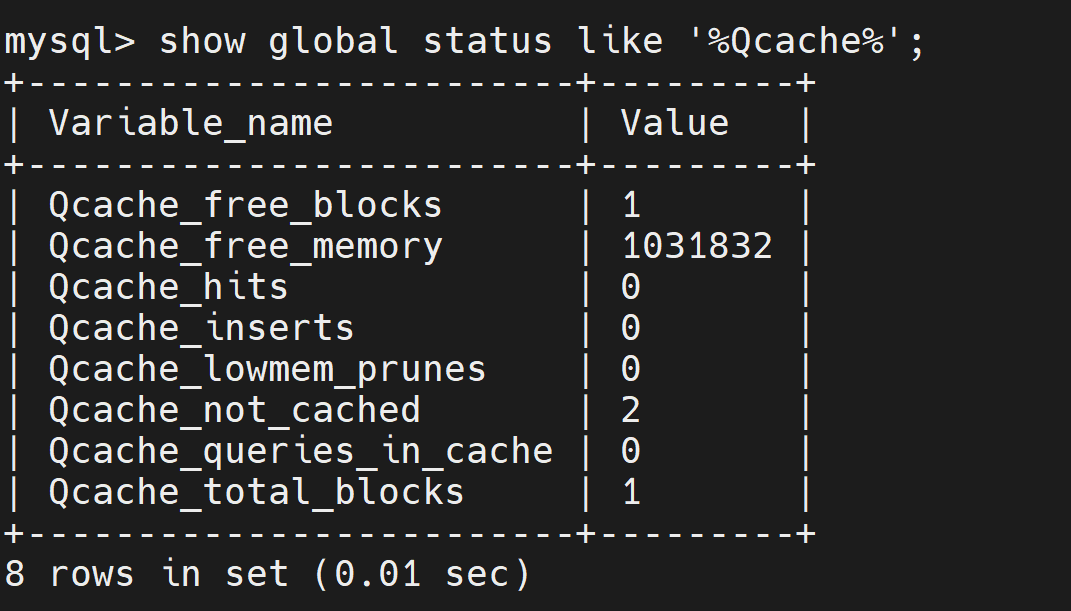
- Qcache_free_blocks:缓存池中空闲块的个数
- Qcache_free_memory:缓存中空闲内存量
- Qcache_hits:缓存命中次数
- Qcache_inserts:缓存写入次数
- Qcache_lowmen_prunes:因内存不足删除缓存次数
- Qcache_not_cached:查询未被缓存次数,例如查询结果超出缓存块大小,查询中包含可变函数等,或者未查询到数据的行、或者SQL语句中使用了
SQL_NO_CACHE等。 - Qcache_queries_in_cache:当前缓存中缓存的SQL数量
- Qcache_total_blocks:缓存总block数
3.3 缓存的使用
3.3.1 缓存命中测试
- 创建数据库:
create database test;
use test;
- 创建一张测试表:
CREATE TABLE `goods` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`price` decimal(10, 2) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
- 插入测试数据:
INSERT INTO `goods` VALUES (1, '华为4G全面屏游戏手机', '华为手机', 5299.00);
INSERT INTO `goods` VALUES (2, '神舟战神游戏本', '神舟笔记本', 4599.00);
INSERT INTO `goods` VALUES (3, '小米5G全面屏手机', '小米手机', 2899.00);
INSERT INTO `goods` VALUES (4, '小米4G游戏全面屏拍照手机', '小米手机', 1899.00);
- 查询当前缓存使用情况:
-- 首先执行一次查询语句
select * from goods;
-- 查看是否有写入到缓存
show global status like '%Qcache%';
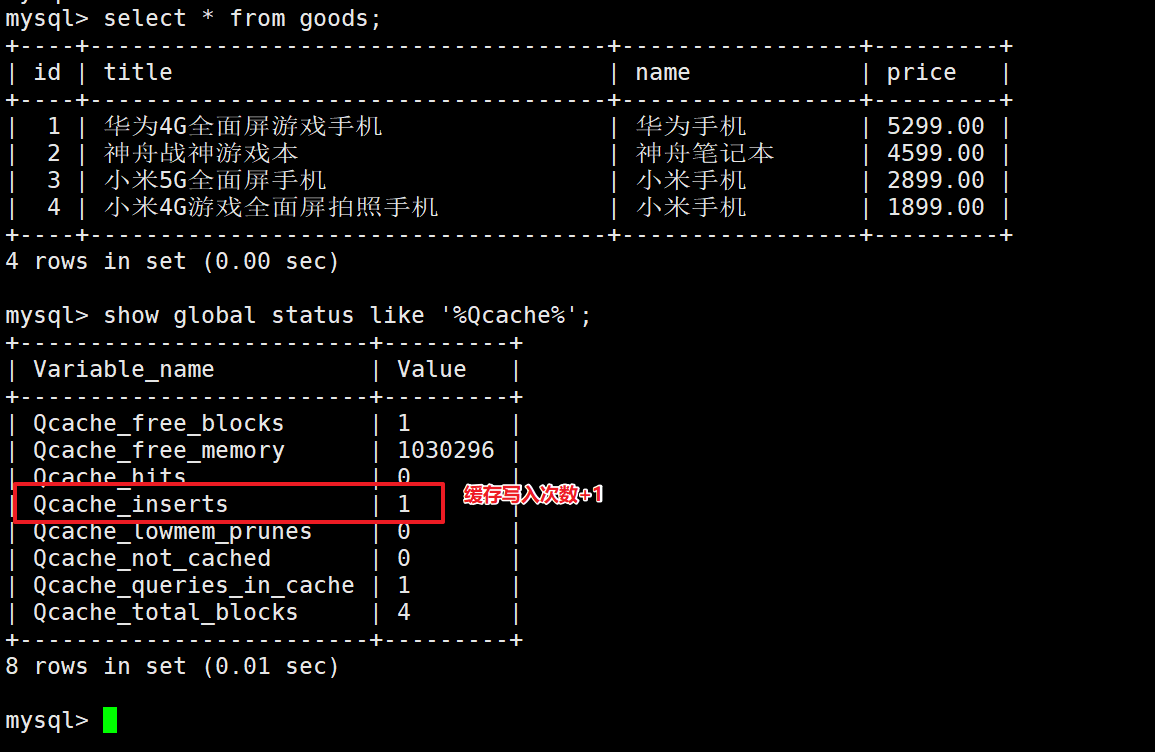
发现缓存写入次数+1
我们再次执行SQL语句,查看缓存使用情况:
select * from goods;
show global status like '%Qcache%';

缓存命中次数+1
- 我们执行多次SQL语句,查看缓存插入和命中情况:
-- 写入缓存+1
select * from goods g; -- 注意仔细看SQL语句(取了个别名)
-- 写入缓存+1
select * from goods where id=1;
-- 写入缓存+1
select * from goods where id=2;
-- 写入缓存+1
select * from goods g where id=1;
-- 命中缓存+1
select * from goods g;
-- 命中缓存+1
select * from goods where id=1;
-- 命中缓存+1
select * from goods where id=2;
我们先计算一遍:
缓存写入数(Qcache_inserts)为1(原来的一次)+4=5
缓存命中数(Qcache_hits)为1(原来的一次)+3=4
- 查看缓存写入和命中情况:
show global status like '%Qcache%';
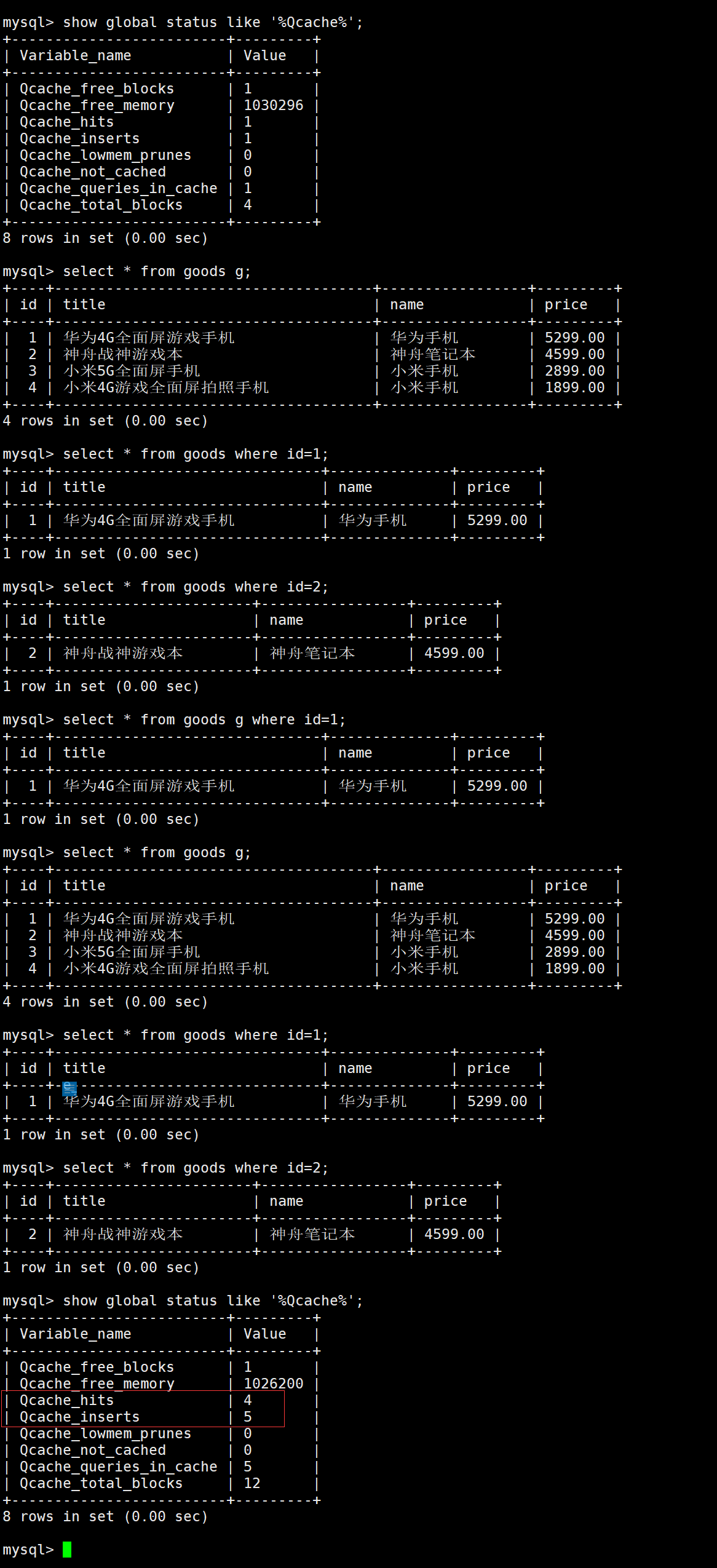
- 这里要注意一点,即使有的SQL查询不出来结果,也是会写入缓存的
-- 即使查询不到结果集,也会写入缓存
select * from goods where id=10;
-- 即使查询不到结果集也会命中缓存
select * from goods where id=10;
show global status like '%Qcache%';
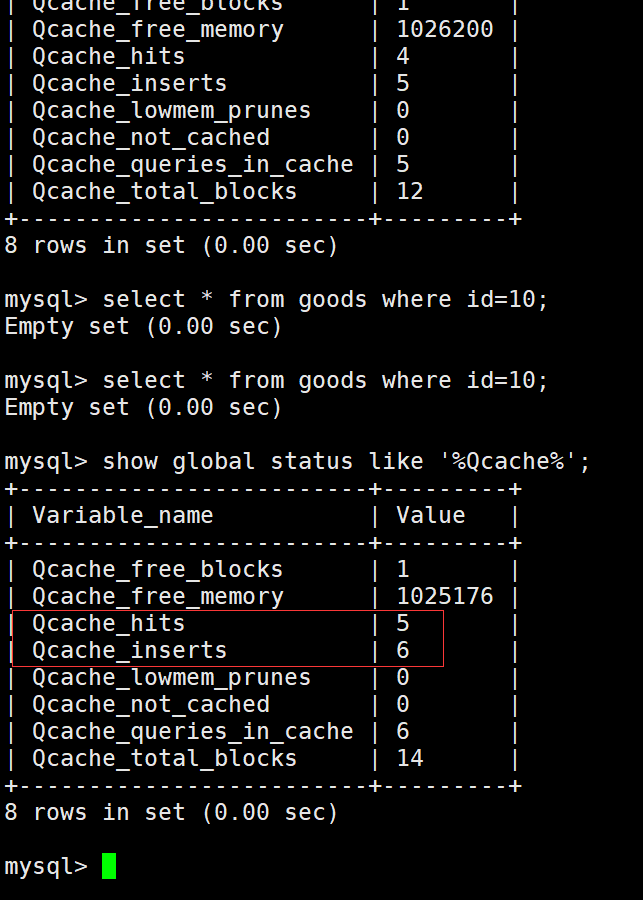
Tips:发现即使有的SQL没有查询到结果集,也会写入缓存,并且再次查询也会命中缓存
3.3.2 缓存清空测试
我们上提到过,对表的任何DML操作都会导致缓存清空,包括insert,update,delete,truncate,alter table,drop table等。
为了方便测试,我重启MySQL服务器(缓存信息全部清空):
systemctl restart mysqld
- 执行SQL语句观察缓存命中变化
mysql> use test
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from goods where id=1; # 写入缓存
+----+-------------------------------+--------------+---------+
| id | title | name | price |
+----+-------------------------------+--------------+---------+
| 1 | 华为4G全面屏游戏手机 | 华为手机 | 5399.00 |
+----+-------------------------------+--------------+---------+
1 row in set (0.00 sec)
mysql> show global status like '%Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1030296 |
| Qcache_hits | 0 |
| Qcache_inserts | 1 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2 |
| Qcache_queries_in_cache | 1 | # 当前缓存了一条SQL
| Qcache_total_blocks | 4 |
+-------------------------+---------+
8 rows in set (0.00 sec)
mysql> select * from goods where id=1; # 命中缓存
+----+-------------------------------+--------------+---------+
| id | title | name | price |
+----+-------------------------------+--------------+---------+
| 1 | 华为4G全面屏游戏手机 | 华为手机 | 5399.00 |
+----+-------------------------------+--------------+---------+
1 row in set (0.00 sec)
mysql> show global status like '%Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1030296 |
| Qcache_hits | 1 |
| Qcache_inserts | 1 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2 |
| Qcache_queries_in_cache | 1 | # 当前缓存了一条SQL
| Qcache_total_blocks | 4 |
+-------------------------+---------+
8 rows in set (0.00 sec)
mysql> update goods set price=8999 where id=1; # 清空缓存
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> show global status like '%Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1031832 |
| Qcache_hits | 1 |
| Qcache_inserts | 1 | # 注意:这里显示的是你当前写入了多少次缓存
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2 |
| Qcache_queries_in_cache | 0 | # 当前缓存了0条SQL
| Qcache_total_blocks | 1 |
+-------------------------+---------+
8 rows in set (0.01 sec)
mysql> select * from goods where id=1; # 写入缓存
+----+-------------------------------+--------------+---------+
| id | title | name | price |
+----+-------------------------------+--------------+---------+
| 1 | 华为4G全面屏游戏手机 | 华为手机 | 8999.00 |
+----+-------------------------------+--------------+---------+
1 row in set (0.00 sec)
mysql> show global status like '%Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1030296 |
| Qcache_hits | 1 |
| Qcache_inserts | 2 | # 发现缓存写入次数增加
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2 |
| Qcache_queries_in_cache | 1 | # 当前缓存了一条SQL
| Qcache_total_blocks | 4 |
+-------------------------+---------+
8 rows in set (0.00 sec)
mysql>
通过观察Qcache_queries_in_cache参数可以发现,执行完update语句之后,有关于这张表的缓存全部清空,当再次执行SQL语句的时候,会重新写入缓存。
对MySQL表的任意DML操作都会导致有关于这张表的所有缓存全部清空。
3.3.3 使用SQL Hint选择缓存
我们知道MySQL的查询缓存一旦开启,会将本次SQL语句的结果集全部放入缓存中,这样其实是非常不友好的,因为我们知道,对于表的任何DML操作都会导致这张表的缓存全部清空。因此我们可以指定哪些SQL语句存入缓存,哪些不存。
SQL_CACHE:将此次SQL语句的结果集存入缓存(前提是当前MySQL服务器时开启缓存的)SQL_NO_CACHE:此次SQL语句的结果集不存入缓存
执行如下SQL语句,分析缓存执行情况:
-- 缓存写入次数0
show global status like '%Qcache%';
-- 存入缓存
select * from goods;
-- 缓存写入次数1
show global status like '%Qcache%';
-- 不存入缓存
select SQL_NO_CACHE * from goods g; -- 注意:取了个别名
-- 缓存写入次数还是1
show global status like '%Qcache%';
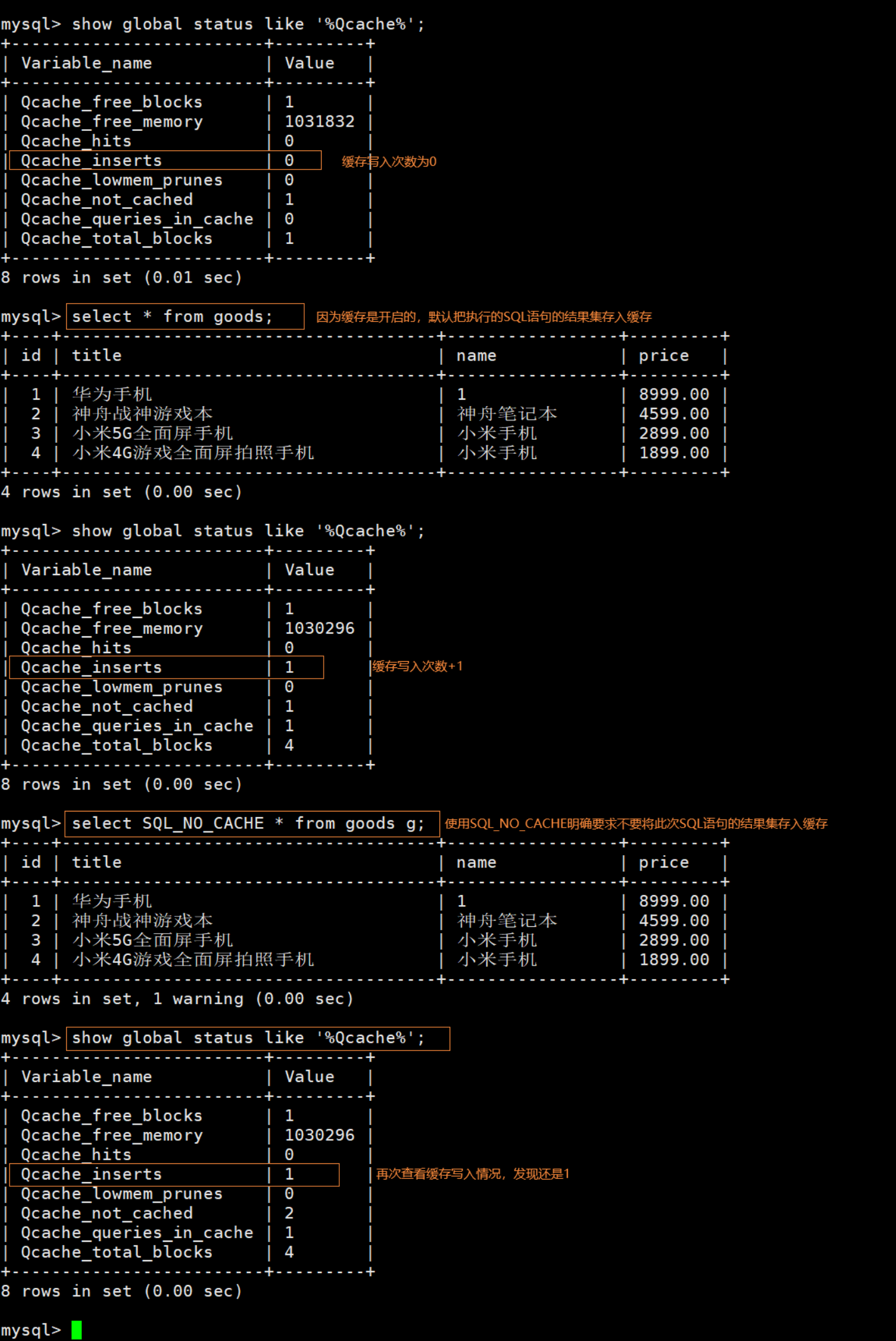
3.4 大数据量缓存性能测试
3.4.1 导入300W数据
我们已经明白缓存何时写入、何时清空,何时命中,接下来我们插入300W数据,来执行SQL语句,体验缓存给我们带来性能上的提升。
- 创建测试表:
CREATE TABLE `userinfo` (
`id` int(10) NOT NULL COMMENT '用户id',
`username` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '用户名',
`age` int(3) NULL DEFAULT NULL COMMENT '年龄',
`phone` varchar(15) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '手机号',
`gender` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别: ‘0’-男 ‘1’-女',
`desc` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '自我介绍',
`register_time` datetime(0) NULL DEFAULT NULL COMMENT '注册时间',
`login_time` datetime(0) NULL DEFAULT NULL COMMENT '上一次登录时间',
`pic` varchar(250) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '头像地址',
`look` int(10) NULL DEFAULT NULL COMMENT '查看数',
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
- 编写存储过程
create procedure test_insert(count int)
begin
declare i int default 1;
while i<=count do
INSERT INTO userinfo values(
i, -- id
uuid(), -- username
CEILING(RAND()*90+10), -- age
FLOOR(RAND()*100000000000), -- phone
round(FORMAT(rand(),1)), -- gender
uuid(), -- desc
now(), -- register_time
now(), -- login_time
uuid(), -- pic
CEILING(RAND()*90+10) -- look
);
set i=i+1;
end while;
end;
- 执行脚本,批量插入300W数据:
-- 关闭唯一性校验,提高批量插入速度
set unique_checks=0;
-- 控制在一个事务,避免频繁开启/提交事务
start transaction;
call test_insert(3000000); -- 模拟300W的数据
commit;
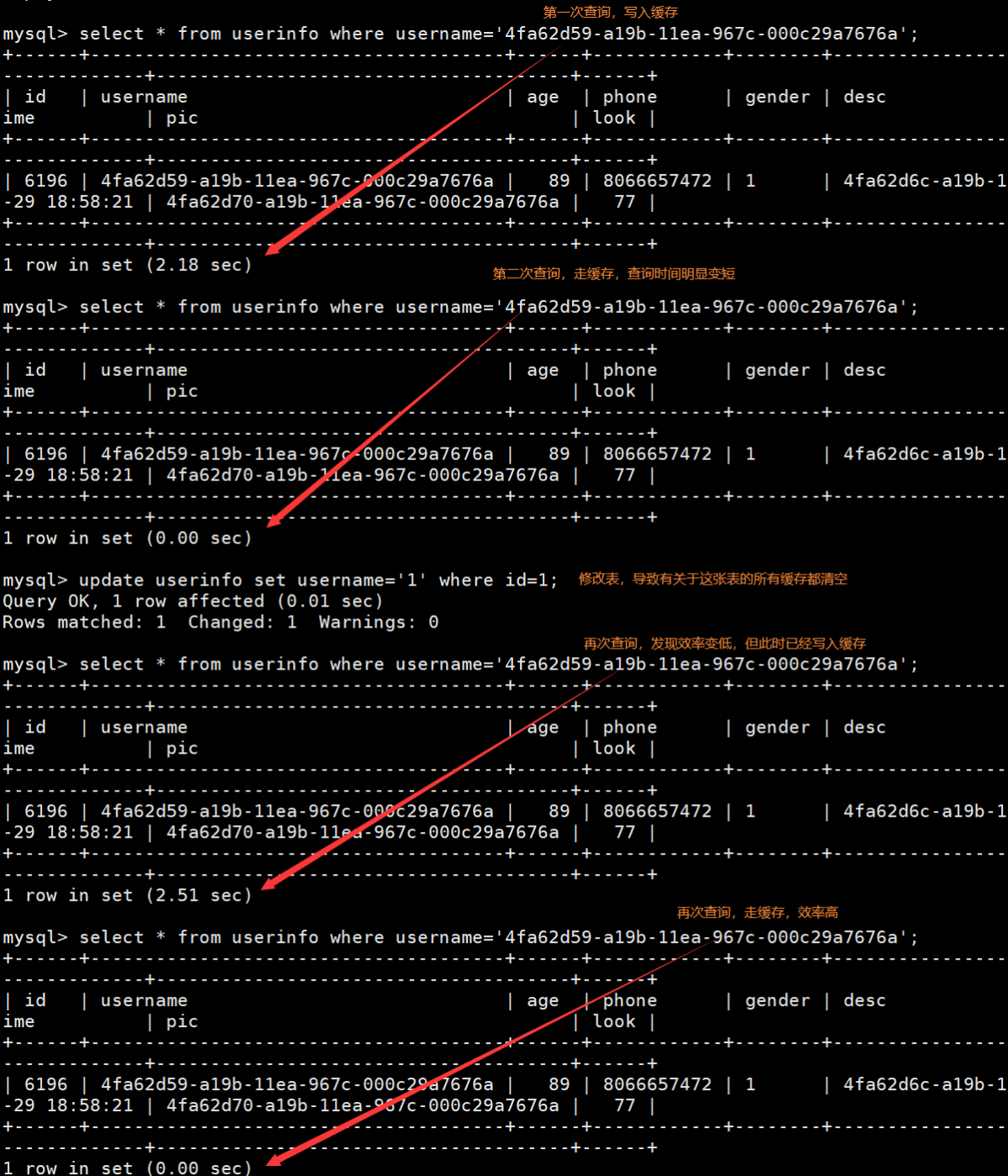
- 执行如下SQL测试缓存效率:
-- 第一次查询,将结果存入缓存(2.18)
select * from userinfo where username='4fa62d59-a19b-11ea-967c-000c29a7676a';
-- 走缓存,效率快(0.00s)
select * from userinfo where username='4fa62d59-a19b-11ea-967c-000c29a7676a';
-- 对表进行修改,关于这张表的缓存全部清空
update userinfo set username='1' where id=1;
-- 再次查询,发现效率低,但又存入缓存了(2.51s)
select * from userinfo where username='4fa62d59-a19b-11ea-967c-000c29a7676a';
-- 再次查询,走缓存,效率高(0.00s)
select * from userinfo where username='4fa62d59-a19b-11ea-967c-000c29a7676a';
再进行多次测试:
-- 写入缓存(2.45s)
select * from userinfo where age=1;
-- 命中缓存(0.00s)
select * from userinfo where age=1;
-- 写入缓存(2.25s)
select * from userinfo where phone='1';
-- 命中缓存(0.00s)
select * from userinfo where phone='1';
-- 命中缓存(0.00s)
select * from userinfo where phone='1';
-- 写入缓存(1.99s)
select * from userinfo where look=1;
-- 命中缓存(0.00s)
select * from userinfo where look=1;
-- 命中缓存(0.00s)
select * from userinfo where look=1;
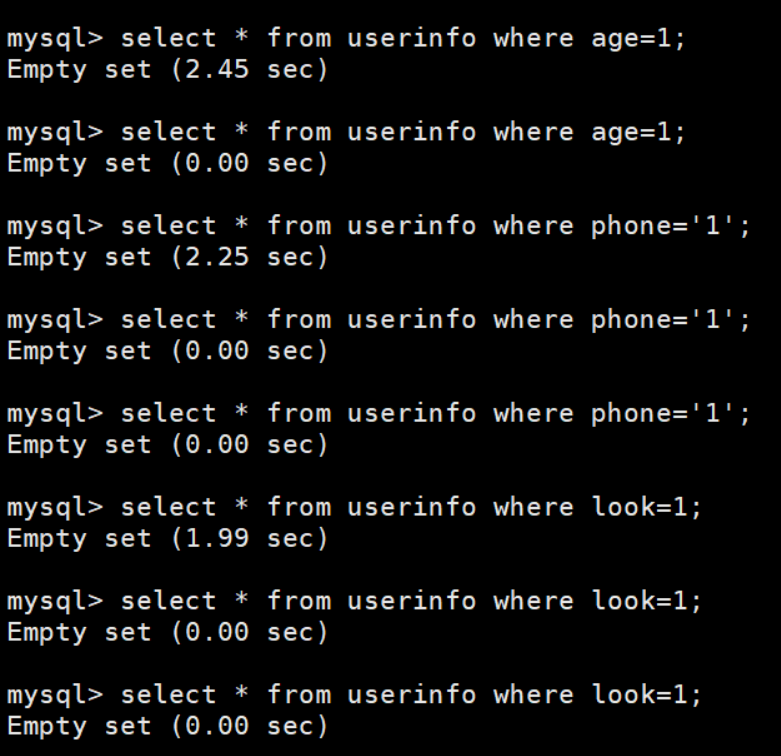
发现命中缓存确实比没有命中缓存查询效率高多了。
3.4.2 什么SQL语句适合放入缓存
场景举例:
select * from xxx age > 18 and age <25;
-- 在大量数据中,筛选出几条数据(这样的SQL语句最适合存入查询缓存)
select * from xxx hobby in (1,2,3,4);
select * from xxx limit 1000000,100;
-- 在大量数据中,做分组操作(这样的SQL语句最适合存入查询缓存)
select avg(age) from xxx group dept_id;
尽量缓存结果集不会太大的SQL语句(建立缓存时间短,就算缓存失效对我影响也不大),但是表中数据量大(表中数据量大,意味着查询速度慢),这样的SQL语句下次查询缓存速度上就能得到明显的提升。
什么情况下不适合使用查询缓存?
场景举例:
-- 整表缓存
select SQL_NO_CACHE * from xxx;
-- 多表缓存
select SQL_NO_CACHE * from xxx x1 inner join xxx x2 on x1.x=x2.x;
-- 大范围缓存
select SQL_NO_CACHE * from xxx where age>18;
3.5 缓存的其他特性
3.5.1 缓存失败的情况
- 1)缓存碎片、内存不足、数据修改都会造缓存失败。如果配置了足够的缓存空间,而且
query_cache_min_res_unit的大小也设置的合理。那么缓存失效应该主要是数据修改导致的。可以通过Qcache_not_cached参数来查看有多少次失效是由于内存不足导致的。 - 2)当某个表正在写入数据,则这个表的缓存(命中缓存,缓存写入等)将会处于失效状态(默认状态)
- 3)在Innodb中,如果某个事务修改了这张表,则这个表的缓存在事务提交/回滚前都会处于失效状态,在这个事务提交/回滚前,这个表的相关查询都无法被缓存。
3.5.2 缓存整理
- 1)清空缓存
如果当前的MySQL缓存了过多的SQL语句没有及时清除,我们可以使用命令将缓存清空,来是否缓存:
reset query cache;
- 2)减少缓存碎片
我们在分析缓存参的时候知道,MySQL并不是一下子分配query_cache_size内存作为缓存,而是将内存分为若干个query_cache_min_res_unit小内存,即使本次缓存没有达到一个缓存块大小也需要占用一个缓存块大小。但query_cache_min_res_unit也不能设置太小,设置太小会造成MySQL不断的分配很多个内存块来缓存本次SQL语句的结果集。
- 3)使用
FLUSH QUERY CACHE命令整理缓存碎片,来释放碎片占用的空间,但需要注意的是这个命令在整理缓存期间,会导致其他连接无法使用查询缓存。
3.5.3 缓存的弊端
- 1)查询缓存的失效非常频繁,只要有对一个表的更新,这个表上的所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。因此读写非常频繁的业务场景,缓存开启还不如关闭效率高。除非你的业务有一张静态表,很长时间更新一次,比如系统配置表,那么这张表的查询才适合做查询缓存。
- 2)缓存和数据耦合在了一起,我们在开发中,缓存和数据应该是独立分开的,这样的话有利于单独进行扩容;比如缓存的配置需要更好的,数据库服务器的配置一般就行了;
- 3)不支持持久化、不支持可视化等;
- 4)大多数情况下,我们都是采用市面上比较成熟的软件来进行缓存,如redis、memcache等,这些软件不管是性能、功能、操作上都比MySQL缓存要强大的多,而且利于我们进行性能扩容(如搭建缓存集群)。
Tips:MySQL官网上已经说明,在MySQL8.0及以上版本,MySQL的缓存功能已经被删除了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号