15【IO流增强】
15【IO流增强】
一、转换流
1.1 字符编码和字符集
1.1.1 编码与解码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
1.1.2 字符集与编码
字符集(charset):字符集简单来说就是指字符的集合,例如所有的英文字母是一个字符集,所有的汉字是一个字符集,当然,把全世界所有语言的符号都放在一起,也可以称为一个字符集。计算机中的字符包括文字、图形符号、数学符号等;
拿汉字中的“汉”这个字符来说,我们看到的这个“汉”其实是这个字符的一种具体表现形式,是它的图像表现形式,而且它是用中文(而非拼音)书写而成,使用宋体外观;因此同一个字符的表现形式可能有无数种,把每一种的表现形式下的同一个字符都纳入到字符集中,会使得字符集过于庞大;
因此字符集中的字符,都是指唯一存在的抽象字符,而忽略了它的具体表现形式。在给定一个抽象字符集合中的每个字符都分配了一个整数编号之后,这个字符集就有了顺序,就成为了编码字符集。同时,这个编号,可以唯一确定到底指的是哪一个字符(哪一种具体形式)
1.1.3 字符集与编码的关系
字符集与编码的关系图:
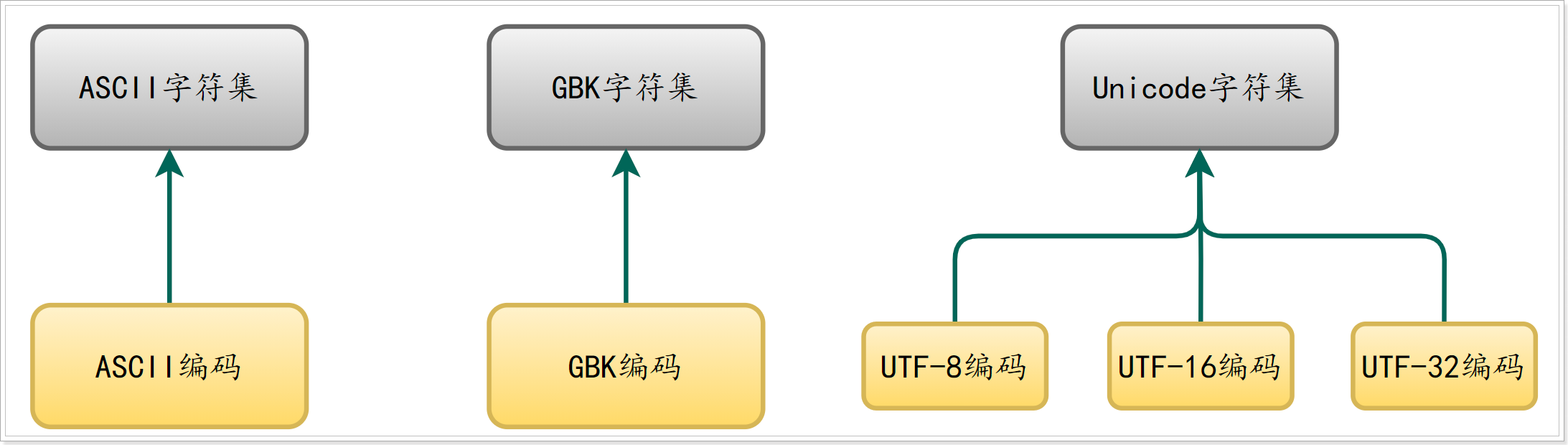
在早期,字符集与编码是一对一的。有很多的字符编码方案,一个字符集只有唯一一个编码实现,两者是一一对应的。比如 GB2312,这种情况,无论你怎么去称呼它们,比如“GB2312编码”,“GB2312字符集”,说来说去其实都是一个东西,可能它本身就没有特意去做什么区分,所以无论怎么说都不会错。
到了 Unicode,变得不一样了,唯一的 Unicode 字符集对应了三种编码:UTF-8,UTF-16,UTF-32。字符集和编码等概念被彻底分离且模块化,其实是 Unicode 时代才得到广泛认同的。
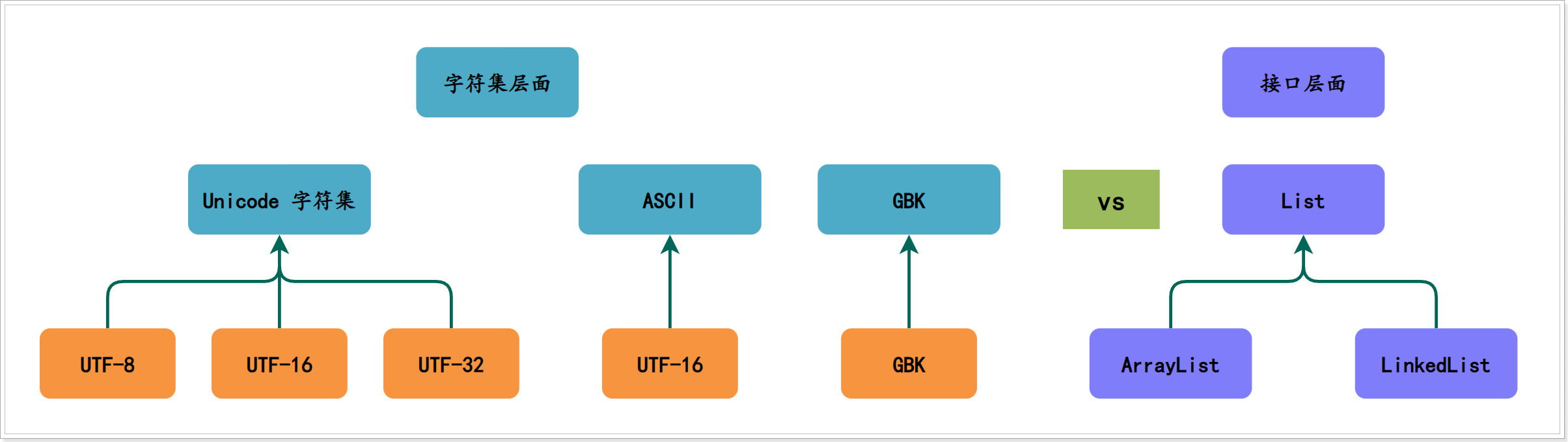
从上图可以很清楚地看到,
1、编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样;
2、一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样。
- 为什么 Unicode 这么特殊?
搞出新的字符集标准,无外乎是旧的字符集里的字符不够用了。Unicode 的目标是统一所有的字符集,囊括所有的字符,因此再去整什么新的字符集就没必要了。
但如果觉得它现有的编码方案不太好呢?在不能弄出新的字符集情况下,只能在编码方面做文章了,于是就有了多个实现,这样一来传统的一一对应关系就打破了。
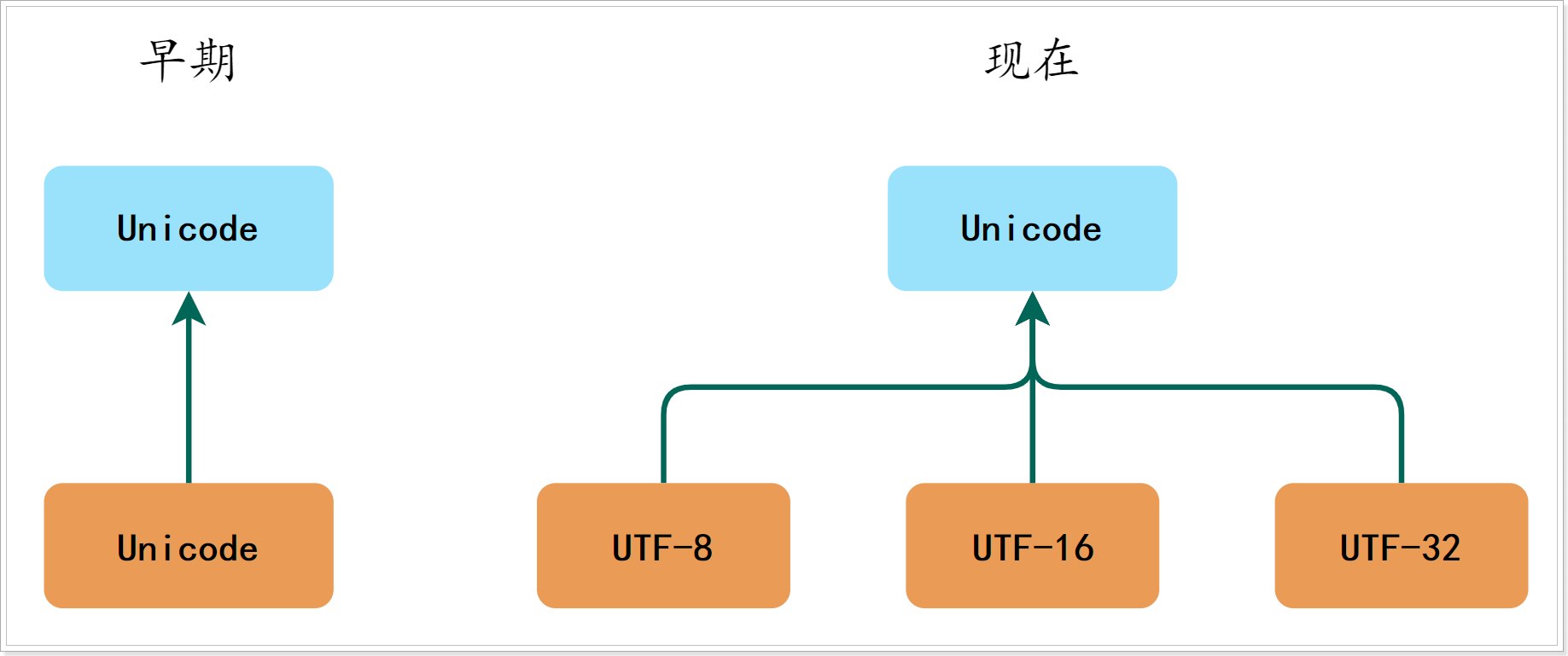
从上图可以看出,由于历史方面的原因,你还会在不少地方看到把 Unicode 和 UTF-8 混在一块的情况,这种情况下的 Unicode 通常就是 UTF-16 或者是更早的 UCS-2 编码。
1.2 编码的问题
当文本写入时的编码与读取时的编码不一致时就会出现乱码的现象;
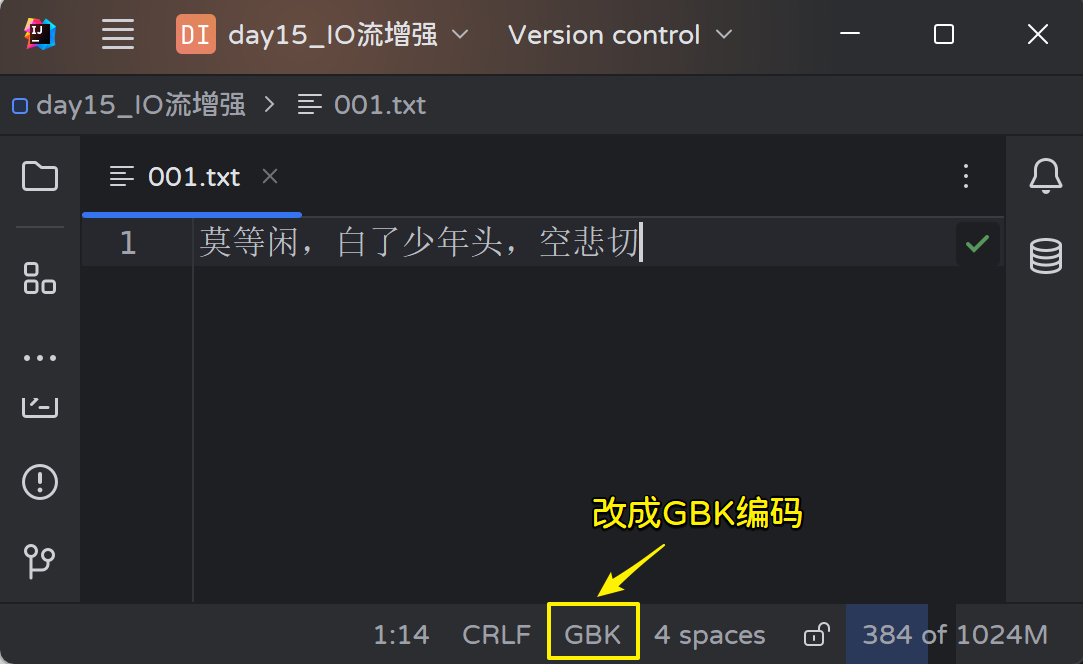
准备两个文件,一个采用GBK编码,一个采用UTF-8编码,使用Notepad++编辑器可编辑:
准备Java代码分别读取两个文件:
package com.dfbz.demo01_转换流;
import java.io.FileReader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_乱码的问题 {
public static void main(String[] args)throws Exception {
// 该文件是采用GBK编码的
FileReader fr = new FileReader("001.txt");
int read;
while ((read = fr.read()) != -1) {
// 打印出现乱码
System.out.print((char)read);
}
fr.close();
}
}
发现在读取GBK时出现中文乱码:
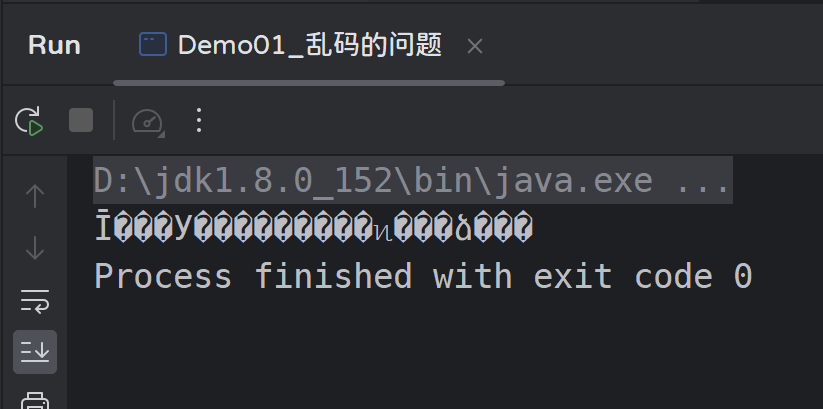
这是因为IDEA默认情况下都是采用UTF-8进行编码与解码,平常我们在操作时感觉不到编码的问题;而我们手动编辑了一个文本文件以GB2312的编码格式保存,此时再使用UTF-8编码进行读取就出现乱码问题;
1.3 转换输入流
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
1.3.1 构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
示例代码:
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
1.3.2 使用转换输入流读取
package com.dfbz.demo01_转换流;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_转换输入流 {
public static void main(String[] args) throws Exception {
// 创建一个字节输入流
FileInputStream fis = new FileInputStream("001.txt");
// 包装成一个装换输入流(按照GBK编码来读取文件内容)
InputStreamReader isr = new InputStreamReader(fis, "GBK");
int data;
while ((data = isr.read()) != -1) {
System.out.print((char) data);
}
isr.close();
}
}
1.4 转换输出流
转换流java.io.OutputStreamWriter ,是Writer的子类,使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
1.4.1 构造方法
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
示例代码:
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");
1.4.2 使用转换输出流写文件
package com.dfbz.demo01_转换流;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_转换输出流 {
public static void main(String[] args) throws Exception{
FileOutputStream fos = new FileOutputStream("02.txt");
// 创建一个转换输出流
OutputStreamWriter osw = new OutputStreamWriter(fos,"GBK");
osw.write("老骥伏枥,志在千里");
osw.write("\r\n");
osw.write("烈士暮年,壮心不已");
osw.close();
}
}
Tips:UTF-8编码表中一个中文汉字占3个字节,GBK则占2个字节;
二、缓冲流
计算机访问外部设备或文件,要比直接访问内存慢的多。如果我们每次调用read()方法或者write()方法访问外部的设备或文件,CPU就要花上最多的时间是在等外部设备响应,而不是数据处理。为此,我们开辟一个内存缓冲区的内存区域,程序每次调用read()方法或write()方法都是读写在这个缓冲区中。当这个缓冲区被装满后,系统才将这个缓冲区的内容一次集中写到外部设备或读取进来给CPU。使用缓冲区可以有效的提高CPU的使用率,能提高整个计算机系统的效率。
2.1 缓冲流的分类
缓冲流是针对4个顶层父类的流的增强,分为:
| 输入缓冲流 | 输出缓冲流 | |
|---|---|---|
| 字节缓冲流 | BufferedInputStream | BufferedOutputStream |
| 字符缓冲流 | BufferedReader | BufferedWriter |
缓冲流在读取/写出数据时,内置有一个默认大小为8192字节/字符的缓冲区数组,当发生一次IO时读满8192个字节再进行操作,从而提高读写的效率。
2.2 字节缓冲流
2.2.1 构造方法
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
示例代码:
// 创建字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));
// 创建字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));
2.2.2 使用字节缓冲流
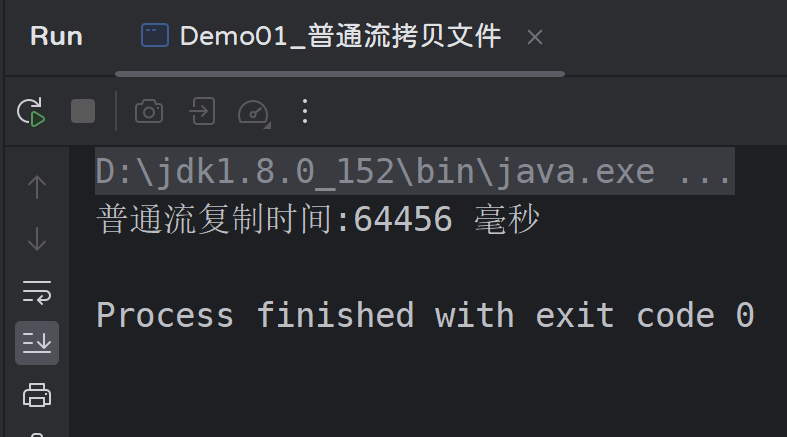
我们分别使用普通流和缓冲流对一个大小为10.4MB的文件进行拷贝,查看两种方案所花费的时间;
- 使用普通流:
package com.dfbz.demo01_缓存字节流;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_普通流拷贝文件 {
public static void main(String[] args) {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
FileInputStream fis = new FileInputStream("D:\\apache-tomcat-8.0.43.zip");
FileOutputStream fos = new FileOutputStream("D:\\apache-tomcat-8.0.43_bak.zip")
) {
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:" + (end - start) + " 毫秒");
}
}
运行结果:
- 使用缓冲流拷贝:
package com.dfbz.demo01_缓存字节流;
import java.io.*;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_缓存字节流拷贝文件 {
public static void main(String[] args) throws Exception {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D:\\apache-tomcat-8.0.43.zip"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D:\\apache-tomcat-8.0.43_bak.zip"));
) {
// 读写数据
int data;
while ((data = bis.read()) != -1) {
bos.write(data);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:" + (end - start) + " 毫秒");
}
}
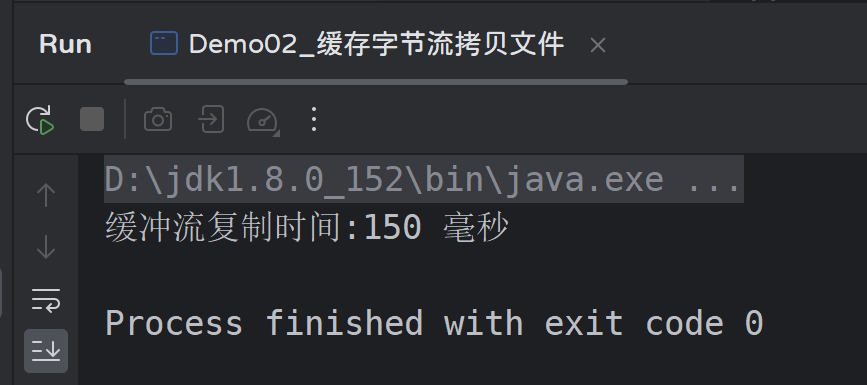
可以看出,缓冲流拷贝文件的效率比普通流高太多太多,因此我们在做大文件拷贝时应该尽量选用缓冲流;
2.2.3 自定义缓冲区
缓冲区内置有8192个字节大小的缓冲区,读写效率比普通的流要高效非常多,但我们也可以自定义字节缓存来进行文件的读写;
- 示例代码:
package com.dfbz.demo01_缓存字节流;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_自定义字节数组拷贝 {
public static void main(String[] args) throws Exception {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
FileInputStream fis = new FileInputStream("D:\\apache-tomcat-8.0.43.zip");
FileOutputStream fos = new FileOutputStream("D:\\apache-tomcat-8.0.43_bak.zip")
) {
// 读写数据
byte[] data = new byte[8192];
int len;
while ((len = fis.read(data)) != -1) {
fos.write(data, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("自定义缓冲区复制时间:" + (end - start) + " 毫秒");
}
}
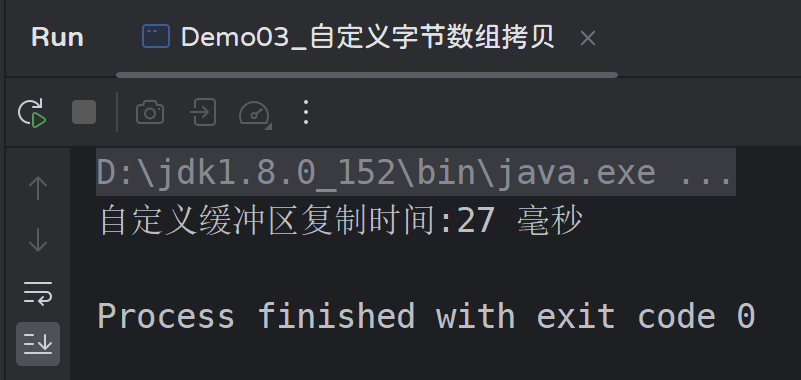
2.2.4 自定义缓冲区高效的原因
可以发现,我们自定义的缓冲区比缓冲流的速度还要快,这是为什么呢?
1) 普通流拷贝文件流程
- 普通流拷贝文件流程:
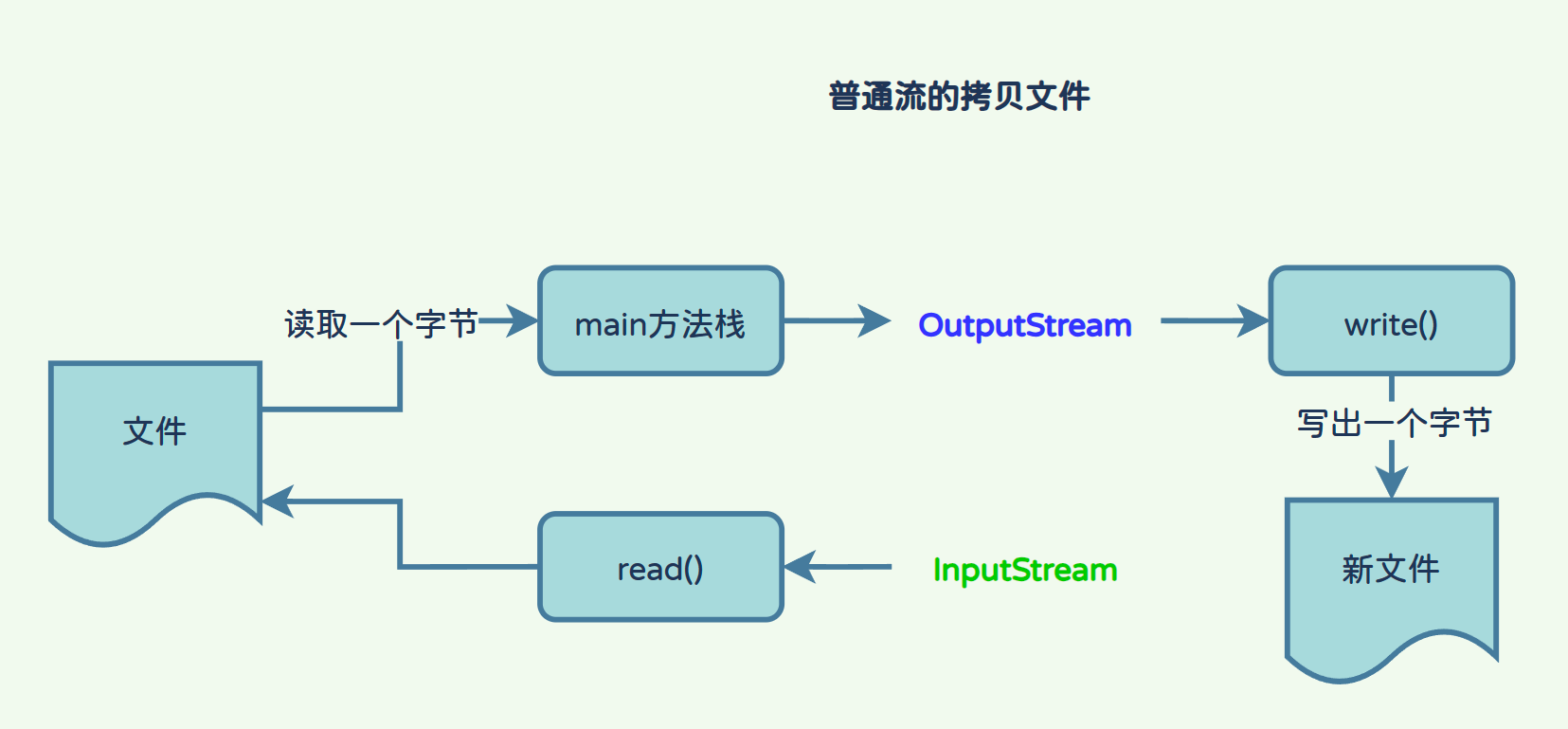
首先InputStream调用read方法从文件中读取一个字节,然后赋值给main方法中的一个变量,这一步相当于从磁盘中读取数据到内存(栈内存),然后使用OutputStream将变量保存的值写出到磁盘中。文件有多少个字节就需要读写多少次,效率非常低;
2) 缓冲流拷贝文件流程
- 缓存流拷贝文件流程:
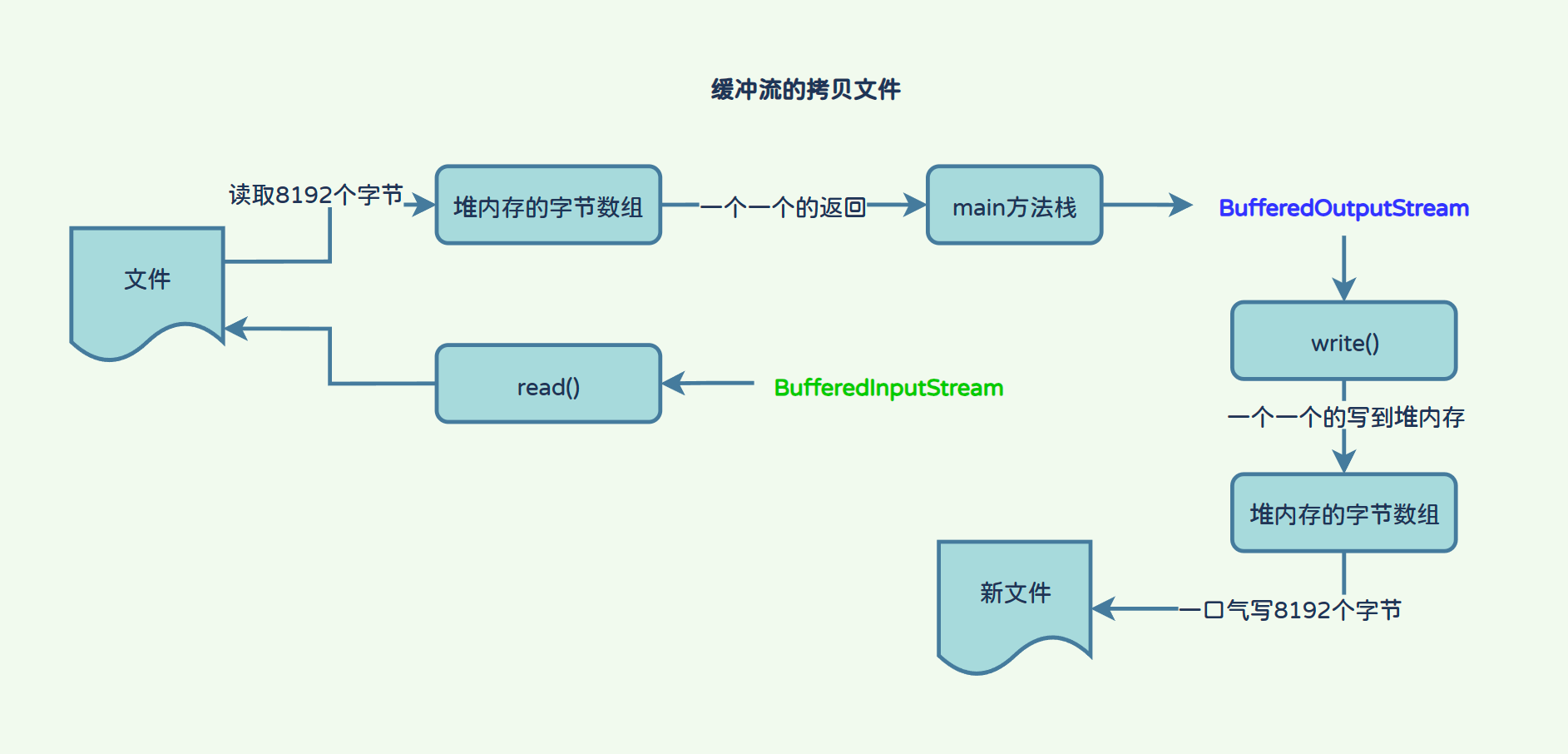
使用BufferedInputStream调用read方法从文件中读取8192个字节到BufferedInputStream类内置的字节数组中(堆内存),然后一个字节一个字节的返回到mian方法栈中(时间消耗),最终调用BufferedOutputStream将main方法中的一个字节写入到BufferedOutputStream内置的字节数组中,等到累计满了8192个字节时一口气全部写入新文件;
3) 自定义缓冲区拷贝文件流程
- 自定义缓冲区拷贝文件流程:
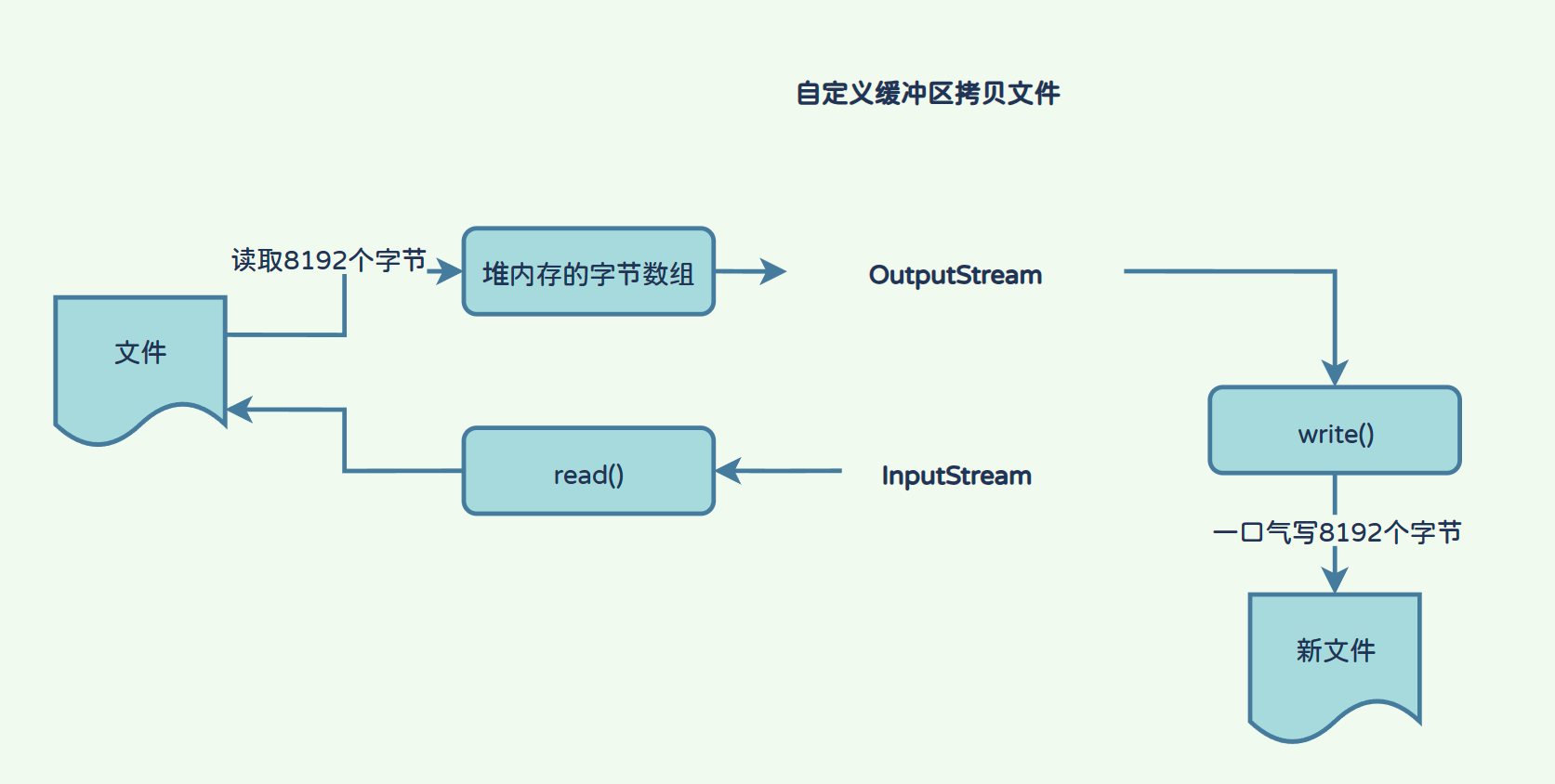
使用BufferedInputStream调用read方法从文件中读取8192个字节到自定义的字节数组中(堆内存),然后使用OutputStream直接将自定义的字节数组中的数据全部写入文件(效率高)
2.3 字符缓冲流
在字节缓冲流中,内部维护了一个8192大小的一个字节数组,字符流则是内部维护了一个8192大小的字符数组;在一次IO时读取8192个字符,提升读取/写入性能。另外,字符缓冲流在普通流的基础上添加了一些独特的方法,让我们读取/写出字符更加方便;
2.3.1 构造方法
public BufferedReader(Reader in):创建一个 新的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
示例代码:
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("br.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("bw.txt"));
2.3.2 常用方法
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
- BufferedReader:
public String readLine(): 读一行文字。 - BufferedWriter:
public void newLine(): 写一行行分隔符,由系统属性定义符号。
newLine方法示例代码如下:
package com.dfbz.demo02_缓存字符流;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_BufferedWriter {
public static void main(String[] args) throws Exception{
// 缓存字符输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("001.txt"));
bw.write("海内存知己");
// 写出换行
bw.newLine();
bw.write("天涯若比邻");
bw.close();
}
}
readLine方法示例代码如下:
准备一篇文章:
豫章故郡,洪都新府。星分翼轸,地接衡庐。襟三江而带五湖,控蛮荆而引瓯越。物华天宝,龙光射牛斗之墟;人杰地灵,徐孺下陈蕃之榻。雄州雾列,俊采星驰。台隍枕夷夏之交,宾主尽东南之美。都督阎公之雅望,棨戟遥临;宇文新州之懿范,襜帷暂驻。十旬休假,胜友如云;千里逢迎,高朋满座。腾蛟起凤,孟学士之词宗;紫电青霜,王将军之武库。家君作宰,路出名区;童子何知,躬逢胜饯。(豫章故郡 一作:南昌故郡;青霜 一作:清霜)
时维九月,序属三秋。潦水尽而寒潭清,烟光凝而暮山紫。俨骖騑于上路,访风景于崇阿。临帝子之长洲,得天人之旧馆。层峦耸翠,上出重霄;飞阁流丹,下临无地。鹤汀凫渚,穷岛屿之萦回;桂殿兰宫,即冈峦之体势。(天人 一作:仙人;层峦 一作:层台;即冈 一作:列冈;飞阁流丹 一作:飞阁翔丹)
披绣闼,俯雕甍,山原旷其盈视,川泽纡其骇瞩。闾阎扑地,钟鸣鼎食之家;舸舰弥津,青雀黄龙之舳。云销雨霁,彩彻区明。落霞与孤鹜齐飞,秋水共长天一色。渔舟唱晚,响穷彭蠡之滨,雁阵惊寒,声断衡阳之浦。(轴 通:舳;迷津 一作:弥津;云销雨霁,彩彻区明 一作:虹销雨霁,彩彻云衢)
遥襟甫畅,逸兴遄飞。爽籁发而清风生,纤歌凝而白云遏。睢园绿竹,气凌彭泽之樽;邺水朱华,光照临川之笔。四美具,二难并。穷睇眄于中天,极娱游于暇日。天高地迥,觉宇宙之无穷;兴尽悲来,识盈虚之有数。望长安于日下,目吴会于云间。地势极而南溟深,天柱高而北辰远。关山难越,谁悲失路之人;萍水相逢,尽是他乡之客。怀帝阍而不见,奉宣室以何年?(遥襟甫畅 一作:遥吟俯畅)
嗟乎!时运不齐,命途多舛。冯唐易老,李广难封。屈贾谊于长沙,非无圣主;窜梁鸿于海曲,岂乏明时?所赖君子见机,达人知命。老当益壮,宁移白首之心?穷且益坚,不坠青云之志。酌贪泉而觉爽,处涸辙以犹欢。北海虽赊,扶摇可接;东隅已逝,桑榆非晚。孟尝高洁,空余报国之情;阮籍猖狂,岂效穷途之哭!(见机 一作:安贫;以犹欢 一作:而相欢)
勃,三尺微命,一介书生。无路请缨,等终军之弱冠;有怀投笔,慕宗悫之长风。舍簪笏于百龄,奉晨昏于万里。非谢家之宝树,接孟氏之芳邻。他日趋庭,叨陪鲤对;今兹捧袂,喜托龙门。杨意不逢,抚凌云而自惜;钟期既遇,奏流水以何惭?
呜呼!胜地不常,盛筵难再;兰亭已矣,梓泽丘墟。临别赠言,幸承恩于伟饯;登高作赋,是所望于群公。敢竭鄙怀,恭疏短引;一言均赋,四韵俱成。请洒潘江,各倾陆海云尔。
滕王高阁临江渚,佩玉鸣鸾罢歌舞。
画栋朝飞南浦云,珠帘暮卷西山雨。
闲云潭影日悠悠,物换星移几度秋。
阁中帝子今何在?槛外长江空自流。
package com.dfbz.demo02_缓存字符流;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_BufferedReader {
public static void main(String[] args) throws Exception {
// 缓存字符输入流
BufferedReader br = new BufferedReader(new FileReader("text.txt"));
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
public static void test(String[] args) throws Exception {
// 缓存字符输入流
BufferedReader br = new BufferedReader(new FileReader("text.txt"));
// 读取一行,读到文件末尾返回null
String line = br.readLine();
System.out.println(line);
line = br.readLine();
System.out.println(line);
line = br.readLine();
System.out.println(line);
line = br.readLine();
System.out.println(line);
line = br.readLine();
System.out.println(line);
br.close();
}
}
三、序列化流
3.1 序列化概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。看图理解序列化:

3.2 对象输出流
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
3.2.1 构造方法
public ObjectOutputStream(OutputStream out): 创建一个指定OutputStream的ObjectOutputStream。
示例代码:
FileOutputStream fileOut = new FileOutputStream("goods.txt");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
3.2.2 对象的序列化
一个对象要想序列化,必须满足两个条件:
- 1)该类必须实现
java.io.Serializable接口,Serializable是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException。 - 2)该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。
写出对象方法:
public final void writeObject(Object obj): 将指定的对象写出。
准备一个对象:
package com.dfbz.demo01;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Goods implements Serializable {
// 标题
private String title;
// 价格
private Double price;
// 库存
private transient Integer store; // transient修饰的成员不会被序列化
// 省略构造方法/get/set/toString...
}
测试代码:
package com.dfbz.demo01_序列化流的使用;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_ObjectOutputStream {
public static void main(String[] args)throws Exception {
Goods goods = new Goods("神舟战神笔记本", 6899.0D, 2);
System.out.println(goods);
// 创建一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("oos.ser")); // 文件名随意
// 将对象写入到文件中(序列化)
oos.writeObject(goods);
oos.close();
}
}
3.3 对象输入流
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
3.3.1 构造方法
public ObjectInputStream(InputStream in): 创建一个指定InputStream的ObjectInputStream。
3.3.2 对象的反序列化
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用ObjectInputStream读取对象的方法:
public final Object readObject(): 读取一个对象。
package com.dfbz.demo01_序列化流的使用;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_ObjectInputStream {
public static void main(String[] args) throws Exception{
// 创建一个对象输出流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("oos.ser"));
// 从文件中读取对象(反序列化)
Goods goods = (Goods) ois.readObject();
System.out.println(goods); // Goods{title='神舟战神笔记本', price=6899.0, brand='null', store=null}
ois.close();
}
}
3.3.3 序列化版本号
当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个**InvalidClassException**异常。原因是:该类的序列版本号与从流中读取的类描述符的版本号不匹配;
例如我们在Goods类中,新增一个成员变量brand:
package com.dfbz.demo01_序列化流的使用;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Goods implements Serializable {
// 标题
private String title;
// 价格
private Double price;
// 品牌
private String brand;
// 库存
private transient Integer store; // 瞬态变量(不会被序列化的变量)
// 省略构造方法/get/set/toString...
}
再次使用对象输入流读取文件,发现出现如下错误:
Exception in thread "main" java.io.InvalidClassException: com.dfbz.demo01_序列化流的使用.Goods; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 7905992613359845956
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:687)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1880)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1746)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2037)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1568)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:428)
at com.dfbz.demo01_序列化流的使用.Demo02_ObjectInputStream.main(Demo02_ObjectInputStream.java:17)
原因是每一个类都有一个版本号,每次使用对象输出流写出对象到文件时都会将这个类的版本号写入到文件中,在使用对象输入流读取文件的内容时会与当前类进行对比,如果一致则可以读取成功,如果不一致则抛出java.io.InvalidClassException异常;
而每次对类进行修改都会导致类的版本号变更,因此只要类发生变更后,再使用对象输入流读取之前版本写入的数据就会发生异常;
对于这种情况,我们可以在类中锁定一个版本号,让版本号不随着类的变更而变更,这样即使类已经修改过也没有关系;
package com.dfbz.demo01_序列化流的使用;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Goods implements Serializable {
// 锁定版本号
private static final long serialVersionUID = 1L;
// 标题
private String title;
// 价格
private Double price;
// 品牌
private String brand;
// 库存
private transient Integer store; // 瞬态变量(不会被序列化的变量)
// 省略构造方法/get/set/toString...
}
Tips:序列化变量名固定为
serialVersionUID,并且一定要被static final修饰,权限修饰符和变量的值无所谓;
再次写入到文件中,然后尝试更改类,再读取文件中的对象,发现不会出现异常;
3.4 序列化案例
- 将存有多个自定义对象的集合序列化操作,保存到
list.txt文件中。 - 反序列化
list.txt,并遍历集合,打印对象信息。
3.4.1 案例分析
- 把若干学生对象 ,保存到集合中。
- 把集合序列化。
- 反序列化读取时,只需要读取一次,转换为集合类型。
- 遍历集合,可以打印所有的学生信息
3.4.2 案例实现
【准备一个Book类】
package com.dfbz.demo01_序列化流的使用;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
class Book implements Serializable { // 实现序列化接口
private String name;
private String author;
// 省略构造方法/get/set/toString...
}
【测试代码】
package com.dfbz.demo01_序列化流的使用;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_序列化与反序列化案例 {
// 反序列化
public static void main(String[] args) throws Exception {
// 准备一个对象输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("books.ser"));
// 从流里面读取对象
List<Book> books = (List<Book>) ois.readObject();
for (Book book : books) {
System.out.println(book);
}
ois.close();
}
// 序列化
public static void test() throws Exception {
// 创建一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("books.ser"));
ArrayList<Book> books = new ArrayList<>();
books.add(new Book("西游记", "吴承恩"));
books.add(new Book("红楼梦", "曹雪芹"));
books.add(new Book("水浒传", "施耐庵"));
books.add(new Book("三国演义", "罗贯中"));
// 将对象写入到文件中
oos.writeObject(books);
oos.close();
}
}
3.5 序列流注意事项
在使用序列流序列化对象时,除了被transient关键字修饰的成员变量不会被序列化到文件之外,被stastic修饰的成员也不会被序列化到文件中。
因为被static修饰的属性是所有类共享的,如果可以序列化,当我们序列化某个类的一个对象到某个文件后,这个文件中的对象的那个被static修饰的属性值会固定下来,当另外一个普通的的对象修改了该static属性后,我们再去反序列化那个文件中的对象,就会得到和后面的对象不同的static属性值,这显然违背了static关键字诞生的初衷。
- 测试实体类:
package com.dfbz.demo01_序列化流的使用;
import java.io.Serializable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Person implements Serializable {
String name = "小灰";
static String sex = "男";
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
"sex='" + sex + '\'' +
'}';
}
public Person(String sex , String name) {
this.name = name;
this.sex = sex;
}
}
- 测试序列化:
package com.dfbz.demo01_序列化流的使用;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_被static修饰的变量不会被序列化 {
public static void main(String[] args) throws Exception{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"));
oos.writeObject(new Person("女","小灰"));
oos.close();
// 修改sex的值
Person.sex = "男";
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser"));
Person obj = (Person) ois.readObject();
System.out.println(obj); // Person{name='小灰'sex='女'}
}
}
四、打印流
4.1 打印流概述
打印流java.io.PrintStream类是OutputStream的一个子类,因此也是属于字节输出流。打印流的功能主要是将数据打印(输出)到控制台,方便我们输出的;
我们平时向控制台输出内容都是借助打印流来完成的:
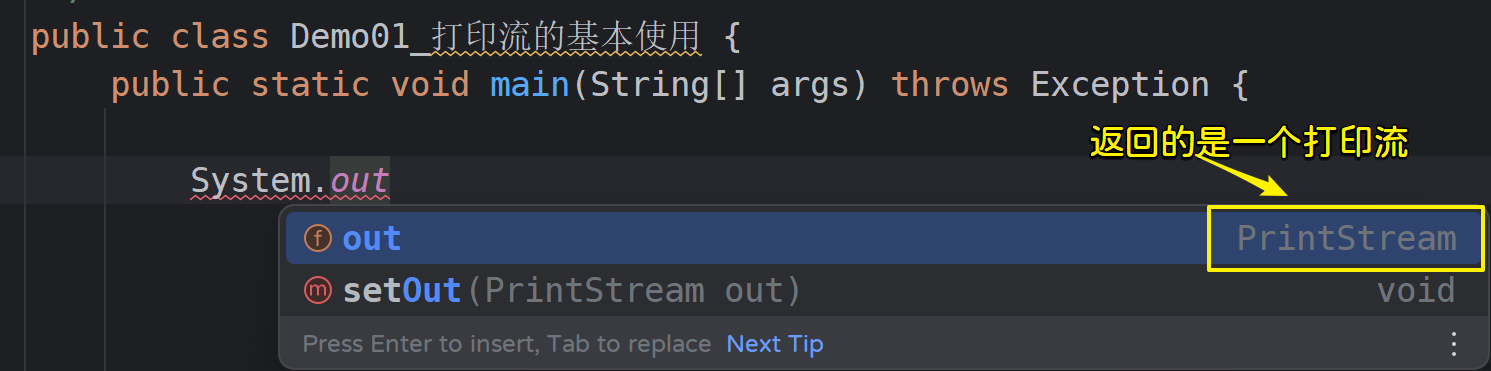
4.2 打印流的使用
4.2.1 构造方法
public PrintStream(String fileName): 使用指定的文件名创建一个新的打印流。
示例代码:
PrintStream ps = new PrintStream("ps.txt");
4.2.2 打印流输出内容
public void println(String x):将指定的字符串输出public void println(int x):将指定的整形输出
Tips:我们之前通过
System.out获取到的就是一个打印流,因此打印流的方法不多赘述;
示例代码:
package com.dfbz.demo01_打印流;
import java.io.PrintStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_打印流的基本使用 {
public static void main(String[] args) throws Exception {
PrintStream ps = new PrintStream("001.txt");
// 打印并换行
ps.println("云南");
// 打印不换行
ps.print("贵州");
// 打印并换行
ps.println("四川");
ps.close();
}
}
4.3 标准输入输出流
4.3.1 标准输入流
标准输入流是一个缓冲字节输入流(BufferedInputStream),他默认指向的是控制台(键盘),通过System.in获取;
我们之前在用Scanner的时候,构造方法如下:
System.in获取的就是标准输入流(指向键盘),因此Scanner总是接受我们键盘输入的数据,我们可以更改Scanner读取的流对象:
package com.dfbz.demo01_打印流;
import java.io.FileInputStream;
import java.util.Scanner;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_标准输入流 {
public static void main(String[] args) throws Exception {
// 更改标准输入流的指向
System.setIn(new FileInputStream("text.txt"));
Scanner scanner = new Scanner(System.in);
String str = scanner.nextLine();
System.out.println(str);
}
}
4.3.2 标准输出流
标准输出流是一个打印流(PrintStream),他默认指向的是控制台,通过System.out获取标准输出流,因此我们之前总是使用System.out.println往控制台输出内容;
我们也可以更改标准输出流,让其不在输出到控制台,而是输出到我们制定的地方:
package com.dfbz.demo01_打印流;
import java.io.PrintStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_标准输出流 {
public static void main(String[] args) throws Exception{
// 更改标准输出流
System.setOut(new PrintStream("001.txt"));
System.out.println("清汤");
System.out.println("水饺");
System.out.println("混沌");
System.out.println("抄手");
}
}
五、其他流
5.1 字节数组流
我们之前的所有流最终的流向(指向)都是文件,通过FileInputStream/FileOutputStream关联一个文件,从文件进行读取/写入;但有些情况下我们可以将流直接指向内存,对内存的某块区域进行读写操作;
Java中提供有ByteArrayInputStream和ByteArrayOutputStream,分别是字节数组输入流和字节数组输出流;
Tips:对于字节数组输入/输出流,关闭该流无效,关闭此流后依旧可以正常读写
5.1.1 ByteArrayInputStream
- ByteArrayInputStream:内置一个字节数组缓冲区,调用read方法对其缓冲区进行读取
【测试代码】
package com.dfbz.demo01_其他流;
import java.io.ByteArrayInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_字节数组输入流 {
public static void main(String[] args) throws Exception {
// 创建一个内存字节输入流(从内存中读取数据)
ByteArrayInputStream bis = new ByteArrayInputStream("abc".getBytes());
// 读取一个字节
int b = bis.read();
System.out.println((char) b); // a
bis.close(); // 内存字节流不需要关闭,即使关闭了依旧可以继续使用
byte[] data = new byte[1024];
int len = bis.read(data, 0, 2);
System.out.println(new String(data, 0, len)); // bc
}
}
5.1.2 ByteArrayOutputStream
- ByteArrayOutputStream:该类实现了将数据写入字节数组的输出流。并内置缓冲区,当数据写入缓冲区时,缓冲区会自动增长。
- 相关成员变量:
**buf[]**:内置的缓冲区,默认大小32**count**:缓冲区中有效字节数
- 相关方法:
**write(int b)**:将指定的字节写入此字节数组输出流。**write(byte[] b, int off, int len)**:从指定的字节数组写入 len字节,从偏移量为 off开始,输出到这个字节数组输出流。**public void reset()**:将此字节数组输出流的count字段重置为零,以便丢弃输出流中当前累积的所有输出。 可以再次使用输出流,重用已经分配的缓冲区空间。**public int size()**:返回缓冲区的当前大小。**public String toString()**:使用平台的默认字符集将缓冲区内容转换为字符串解码字节。**public String toString(String charsetName)**:通过使用命名的charset解码字节将缓冲区的内容转换为字符串。**public byte[] toByteArray()**:创建一个新分配的字节数组。 其大小是此输出流的当前大小,缓冲区的有效内容已被复制到其中。**public void writeTo(OutputStream out)**:将此字节数组输出流的完整内容写入指定的输出流参数
- 相关成员变量:
【测试代码】
package com.dfbz.demo01_其他流;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_字节数组输出流 {
public static void main(String[] args) throws Exception{
// 创建字节数组输出流
ByteArrayOutputStream bos = new ByteArrayOutputStream(1024); // 内置一个大小为1024的byte[]缓冲区,默认大小为32
// 写出一个字节到缓冲区
bos.write(97);
// 写出一个字节数组
bos.write("你好".getBytes());
// 根据偏移量来写出数据
bos.write("abcd".getBytes(), 0, 2); // 写出ab
// 获取缓冲区中的数据(0~count的数据)
byte[] data = bos.toByteArray(); // a你好ab
System.out.println(new String(data)); // a你好ab
// 将0~count之间的数据转换为字符串
System.out.println(bos.toString()); // 根据平台默认的编码表将字节转换为字符串
System.out.println(bos.toString("UTF-8")); // 指定编码表将字节数据转换为字符串
bos.reset(); // 将count置为0
System.out.println(bos.toString()); // count已经变为0,因此输出空
// 重新写入数据到内置的字节数组
bos.write("大家好".getBytes());
bos.writeTo(new FileOutputStream("00.txt")); // 将缓冲区中的内容写入到指定文件
}
}
5.2 数据流
5.2.1 数据流概述
文本格式的数据对于人类而言显得很方便,但是它并不像以二进制格式传递数据那样高效。数据流能更精确的操作Java中的数据类型并以适当的方式将Java基本数据类型输出或输入,数据流提供了存取所有Java基本数据类的方法;
由于IO操作数据的时候,操作的都是字节,即使写出的是一个int数,但真正写出的却截取之后的字节,数据流能很好的指定写出的数据类型,由于写出的是Java的数据类型,所以在文件上写出的是乱码,但程序能读懂
Tips:数据输入流允许应用程序从底层输入流读取原始Java数据类型。
- 使用普通字节流的问题:
package com.dfbz.demo01_其他流;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_普通流写出int数问题 {
public static void main(String[] args)throws Exception {
FileOutputStream fos=new FileOutputStream("01.txt");
// 向文件写出一个字节
fos.write(865);
fos.close();
/*
由于write写出的时候默认转成字节(二进制)
int为4个字节 前面会补0 最后写出的时候只会写出一个字节,即最后面8位
800的二进制是: 00000000 00000000 00000011 01100001
最后将 01100001 保存到了文件,01100001对应的ASCII字符为a
*/
FileInputStream fis=new FileInputStream("01.txt");
// 将读取到的字节转换为int数
int x=fis.read();
System.out.println(x); // 打印 01100001 的十进制 97
}
}
在针对精确数据类型的操作时,普通流将会变得非常不方便;
5.2.2 数据流的使用
Java中数据流分为数据输入流和数据输出流,分别对应DataInputStream和DataOutputStream;数据流能很好的针对精确的数据进行读取或写出;
DataInputStream类中提供有如下方法:
public boolean readBoolean():从输入流中读取一个布尔值public byte readByte():从输入流中读取一个Byte值public short readShort():从输入流中读取一个Byte值public char readChar():从输入流中读取一个Char值public int readInt():从输入流中读取一个Integer值public long readLong():从输入流中读取一个Long值public float readFloat():从输入流中读取一个Float值public double readDouble():从输入流中读取一个Double值
【数据流测试】
package com.dfbz.demo01_其他流;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_数据流 {
public static void main(String[] args) throws Exception{
// 创建一个数据输出流
DataOutputStream dos = new DataOutputStream(new FileOutputStream("001.txt"));
/*
* writeInt方法写出的是一个int数 为4个字节
* 此时存到文件上的还是乱码 但是程序能读的懂
*/
dos.writeInt(865);
dos.close();
// 创建一个数据输入流
DataInputStream dis = new DataInputStream(new FileInputStream("001.txt"));
int number = dis.readInt();
System.out.println(number); // 865
dis.close();
}
}
5.3 序列流
序列流(SequenceInputStream ):序列流用于关联多个输入流,它从一个有序的输入流集合开始,从第一个读取到文件的结尾,然后从第二个文件读取,依此类推,直到最后一个输入流达到文件的结尾。
比如现在有三个文件【1.txt】、【2.txt】、【3.txt】;现在要把这三个文件按照1、2、3的顺序合并成一个文件输出到 【all.txt】文件中。如果不知道有这个流,大家可能都是自己一个一个文件的去读,自己合并到一个文件中。有了这个流,我们操作起来,代码更加优雅。
- 测试代码:
package com.dfbz.demo01_其他流;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.SequenceInputStream;
import java.util.Enumeration;
import java.util.Vector;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_序列流 {
public static void main(String[] args) throws Exception {
FileInputStream fis_01 = new FileInputStream("01.txt");
FileInputStream fis_02 = new FileInputStream("02.txt");
FileInputStream fis_03 = new FileInputStream("03.txt");
// 准备一个Vector集合,存放多个输入流
Vector<FileInputStream> vector = new Vector<>();
vector.add(fis_01);
vector.add(fis_02);
vector.add(fis_03);
// 获取枚举
Enumeration<FileInputStream> elements = vector.elements();
// 通过枚举来构建序列流
SequenceInputStream sis = new SequenceInputStream(elements);
FileOutputStream fos = new FileOutputStream("menus.txt");
// 按照枚举中的顺序挨个写出到文件中
int data;
while ((data = sis.read()) != -1) {
fos.write(data);
}
sis.close();
fos.close();
}
}
5.4 回退流
- 回退流(PushbackInputStream):在JAVA IO中所有的数据都是采用顺序的读取方式,即对于一个输入流来讲都是采用从头到尾的顺序读取的,如果在输入流中某个不需要的内容被读取进来,我们就要采取办法把不需要的数据处理掉,为了解决这样的处理问题,在JAVA中提供了一种回退输入流(PushbackInputStream),可以把读取进来的某些数据重新回退到输入流的缓冲区之中。
回退流中提供的方法如下:
构造方法:
public PushbackInputStream(InputStream in):将输入流放入到回退流之中。
普通方法:
public int read() throws IOException:读取数据。public int read(byte[] b,int off,int len) throws IOException:普通方法 读取指定范围的数据。public void unread(int b) throws IOException:回退一个数据到缓冲区前面。public void unread(byte[] b) throws IOException:回退一组数据到缓冲区前面。public void unread(byte[] b,int off,int len) throws IOException:回退指定范围的一组数据到缓冲区前面。
回退流测试:
package com.dfbz.demo01_其他流;
import java.io.FileInputStream;
import java.io.PushbackInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo06_回退流 {
public static void main(String[] args) throws Exception {
PushbackInputStream pis = new PushbackInputStream(new FileInputStream("001.txt"));
System.out.println((char) pis.read()); // a
System.out.println((char) pis.read()); // b
pis.unread('-');
System.out.println((char) pis.read()); // -
System.out.println((char) pis.read()); // c
System.out.println((char) pis.read()); // d
pis.unread('-');
System.out.println((char) pis.read()); // -
System.out.println((char) pis.read()); // e
pis.close();
}
}
- 回退流小案例:
需求:在一段数字中截取手机号(11位)
package com.dfbz.demo01_其他流;
import java.io.ByteArrayInputStream;
import java.io.PushbackInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo07_回退流的小案例 {
public static void main(String[] args)throws Exception {
String str = "13079016067131350454961897434920916552444009";
// 从内存中读取数据
PushbackInputStream push = new PushbackInputStream(new ByteArrayInputStream(str.getBytes()));
System.out.println("读取之后的数据为:");
int data;
int count = 1;
while ((data = push.read()) != -1) { // 读取内容
System.out.print((char) data);
if (count % 11 == 0) { // 读完了一个手机号
push.unread("-".getBytes()); // 放回到缓冲区之中
data = push.read(); // 再读一遍
System.out.print((char) data); // 13079016067-131350454
}
count++;
}
System.out.println();
}
}
5.5 管道流
管道输入与输出实际上使用的是一个循环缓冲数组来实现,这个数组默认大小为1024字节。输入流(PipedInputStream)从这个缓冲数组中读数据,输出流(PipedOutputStream)往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组首次为空的时候,输入流PipedInputStream所在的线程将阻塞。
管道流测试:
package com.dfbz.demo01_其他流;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_管道流测试 {
public static void main(String[] args) throws Exception {
// 管道输出流
PipedOutputStream pos = new PipedOutputStream();
// 管道输入流
PipedInputStream pis = new PipedInputStream();
// 连接管道输入流和管道输出流
pis.connect(pos);
pos.write("Hello".getBytes()); // 向管道里面写出数据
byte[] data = new byte[1024];
int len = pis.read(data); // 从管道中读取数据
System.out.println("接收到管道流的数据【" + new String(data, 0, len) + "】");
pos.write("你好".getBytes()); // 向管道里面写出数据
len = pis.read(data); // 从管道里面读取数据
System.out.println("接收到管道流的数据【" + new String(data, 0, len) + "】");
pos.close();
pis.close();
}
}
- 管道流小案例:
package com.dfbz.demo01_其他流;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Scanner;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo09_管道流小案例 {
public static void main(String[] args) throws Exception {
// 管道输出流
PipedOutputStream pos = new PipedOutputStream();
// 管道输入流
PipedInputStream pis = new PipedInputStream();
pis.connect(pos);
// 开启两个线程
// 一个线程负责读
new Thread() {
@Override
public void run() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
byte[] data = new byte[1024];
while (true) {
// 从管道输入流里面读取数据
int len = pis.read(data);
System.out.println("管道输出流来数据啦【" + new String(data, 0, len) + "】时间为:" + sdf.format(new Date()));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
// 一个线程负责写
new Thread() {
@Override
public void run() {
try {
Scanner scanner = new Scanner(System.in);
while (true) {
String str = scanner.nextLine();
// 将数据写入到管道输出流(管道输出流一旦有了数据之后,管道输入流就可以读取到)
pos.write(str.getBytes());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号