14【IO流基础】
一、IO概述
1.1 IO流简介
I(Input)O(Output):中文翻译为输入输出,我们知道计算机的数据不管是软件、视频、音乐、游戏等最终都是存储在硬盘中的,当我们打开后,由CPU将硬盘中的数据读取到内存中来运行。这样一个过程就产生了I/O(输入/输出)
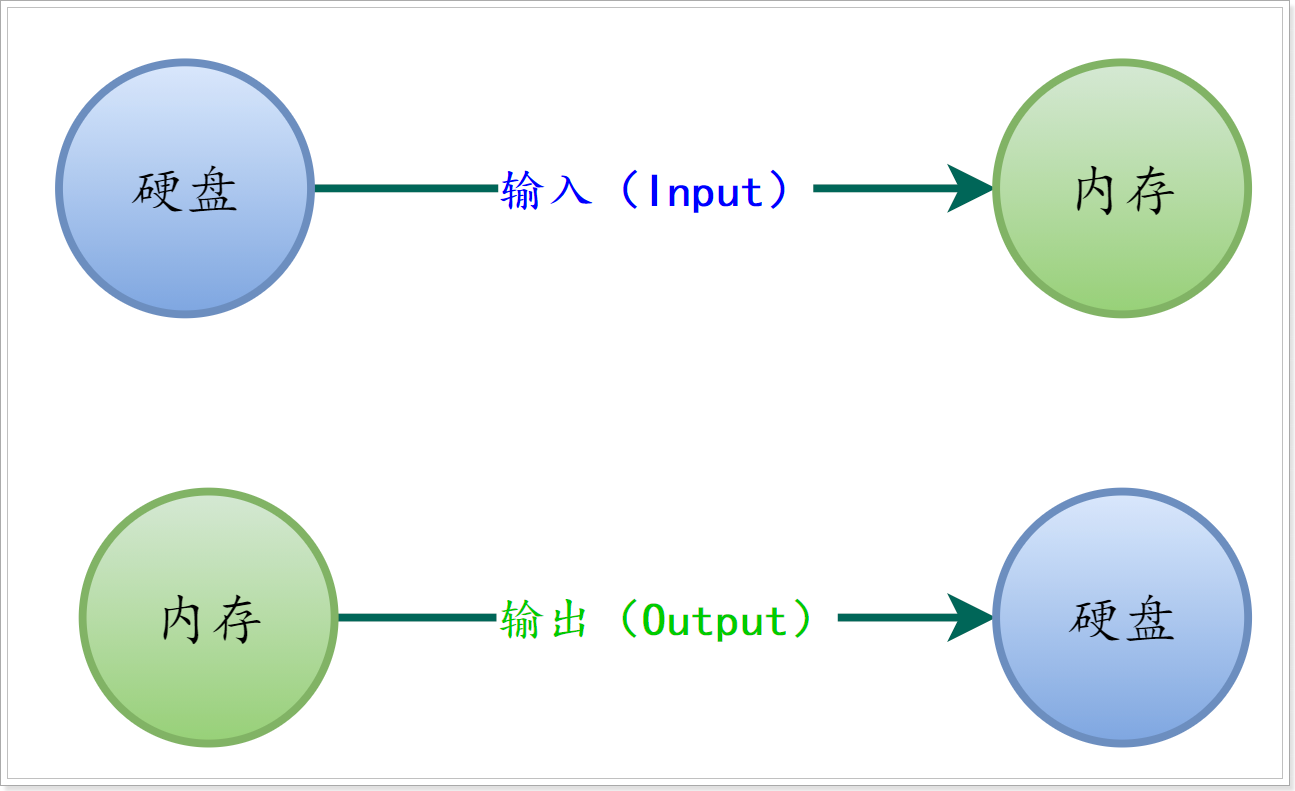
水的流向我们成为水流,数据的流动成为数据流,我们简称为流;数据的流向根据流向的不同,我们分为输入(Input)流和输出(Output)流,简称输入输出流,或称IO流;
1.2 IO流的分类
根据数据的流向分为:输入流和输出流。
- 输入流 :把数据从
输入设备上读取到内存中的流。 - 输出流 :把数据从
内存中写出到输出设备上的流。
根据操作数据单位的不同分为:字节流和字符流。
- 字节流 :以字节为单位,读写数据的流。
- 字符流 :以字符为单位(主要操作文本数据),读写数据的流。
在Java中描述流的底层父类:
| 抽象基类 | 输入流 | 输出流 |
|---|---|---|
| 字节流 | 字节输入流(InputStream) | 字节输出流(OutputStream) |
| 字符流 | 字符输入流(Reader) | 字符输出流(Writer) |
Java的IO流共涉及40多个类,都是从如下4个抽象基类派生的。由这四个类派生出来的子类名称都是以其父类名作为子类名后缀。
二、字节流
字节流有两个顶层接口父类,分别是字节输入流(InputStream)和字节输出流(OuputStream)

2.1 字节输出流
OutputStream是所有字节输出的顶层父类,该父类提供如下公共方法:
public void close():关闭此输出流并释放与此流相关联的任何系统资源。public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。public abstract void write(int b):将指定的字节输出流。
Tips:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
2.1.1 FileOutputStream类
FileOutputStream是OutputStream中一个常用的子类,他可以关联一个文件,用于将数据写出到文件。
FileOutputStream的构造方法如下:
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
Tips:当创建一个流对象时,需要指定一个文件路径,如果该文件以及存在则会清空文件中的数据,如果不存在则创建一个新的文件;
示例代码:
package com.dfbz.demo01_OutputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_FileOutputStream构造方法 {
public static void main(String[] args) throws FileNotFoundException {
// 使用File对象创建流对象
File file = new File("a.txt");
FileOutputStream fos1 = new FileOutputStream(file);
// 使用文件名称创建流对象
FileOutputStream fos2 = new FileOutputStream("b.txt");
}
}
2.1.2 FileOutputStream的使用
1) 常用方法
write(int b):每次可以写出一个字节数据;write(byte[] b):写出一个字节数组的数据;write(byte[] b, int off, int len):从字节数组中的off位置开始写出,写出len个字节;
【示例代码1-写出单个字节】
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_写出单个字节 {
public static void main(String[] args) throws Exception {
OutputStream os = new FileOutputStream("001.txt");
// 写出一个字节!
os.write(97); // 中文的字节 -128~127
os.write(98);
os.write(57); // '9'
os.write(55); // '7'
os.close(); // 文件最终内容为ab97
}
}
Tips:使用字节流向文件写出数据时,首先只会截取一个字节大小,然后根据ASCII码表进行对应字符的转换。
- 示例代码2-写出字节数组:
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_写出一个字节数组 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象(如果有这个文件将清空这个文件的数据)
FileOutputStream fos = new FileOutputStream("000.txt");
// 字符串转换为字节数组
byte[] data = "我是中国人".getBytes();
// 写出字节数组数据
fos.write(data);
// 关闭资源
fos.close();
}
public static void test1(String[] args) throws Exception {
// 使用文件名称创建流对象(如果有这个文件将清空这个文件的数据)
FileOutputStream fos = new FileOutputStream("000.txt");
// 字符串转换为字节数组
byte[] data = "abcdef".getBytes();
// 写出字节数组数据
fos.write(data);
// 关闭资源
fos.close();
}
}
- 代码示例3-按照偏移量来写出数据:
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_按照偏移量来写出字节 {
public static void main(String[] args) throws Exception {
OutputStream os = new FileOutputStream("001.txt");
byte[] data = {97, 98, 99, 100};
os.write(data,2,2); // 99,100(cd)
os.close();
}
}
2) 数据的追加
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能继续添加新数据呢?
public FileOutputStream(File file, boolean append): 创建文件输出流以写入由指定的 File对象表示的文件。public FileOutputStream(String name, boolean append): 创建文件输出流以指定的名称写入文件。
这两个构造方法,参数中都需要传入一个boolean类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了,代码使用演示:
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_数据的追加 {
public static void main(String[] args) throws Exception {
/*
参数1: 操作的文件名
参数2: 开启追加模式
*/
OutputStream os = new FileOutputStream("001.txt",true);
os.write("大家一起喜洋洋!".getBytes());
os.close();
}
}
3) 写出换行
在Windows操作系统,我们在文本编辑器中,输入一个回车实际上是做了两个动作,第一个动作是回到这一行的开头,第二个动作则是让光标到下一行。这两个动作分别对应着:回车符**\r**和换行符**\n**
- 回车符:回到一行的开头(return),ascii为13。
- 换行符:下一行(newline),ascii为10。
因此在Windows系统中,换行符号是\r\n 。
代码使用演示:
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo06_写出换行 {
public static void main(String[] args)throws Exception{
// 创建输出流
FileOutputStream fos = new FileOutputStream("000.txt");
// 定义字节数组
byte[] words = {97, 98, 99, 100, 101};
// 遍历数组
for (int i = 0; i < words.length; i++) {
// 写出一个字节
fos.write(words[i]);
// 写出一个换行, 换行符号转成数组写出
fos.write("\n".getBytes());
}
// 关闭资源
fos.close();
}
}
运行程序,查看文件内容:
如果只输入\r,那么文件的内容应该是:
edcba
如果只输入\n,那么文件的内容应该是:
a
b
c
d
e
但是多次测试发现,换行只写一个\r或者是\n也能到达上述效果;这是因为市面上大部分的文本编辑工具都做了优化,如果一行的后面只有一个\r或者\n那么文本编辑工具会自动帮我们添上缺少的\n或\r;但是为了规范起见,在windows系统中写出回车符最好还是使用\r\n;
另外,不同的操作系统针对回车符也是不一样的标准:
- Windows系统里,每行结尾是
回车+换行,即\r\n; - Unix系统里,每行结尾只有
换行,即\n; - Mac系统里,每行结尾是
回车,即\r。从 Mac OS X开始与Linux统一。
还好我们可以通过System.getProperty("line.separator")可以获取操作系统的换行符;这样就可以做到跨操作系统了;
2.1.3 字符编码问题
我们字符最终存储到磁盘都是需要经过编码的,而我们在打开一个文件的时候则需要使用对应的编码表进行解码,这一个过程称为编码和解码。
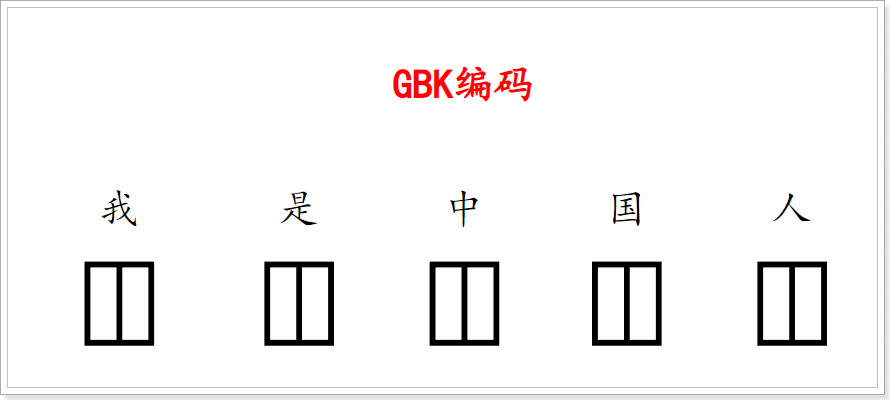
需要注意的是,一个字节是8位。 也就是00000000-11111111,按照 二进制 特性,能表示256不同数据。 英文字母一共只有26个,加上其它的一些符号什么的,也没有超过256种字符。 所以一个字节就能表达所有的字母和符号。
可是对于如汉字,日文,韩文等由字形组成的文字,这样的范围就太小了,而且在不同的编码表中,中文汉字所占用的字节大小可能有所不同,这主要是因为编码方式的不同导致的。
在UTF-8编码下,一个中文占用3个字节,GBK编码下一个中文占用2个字节,因此在使用字节流来精确操作字符数据时将会变得非常麻烦,好在Java提供了一系列的字符流来帮助我们更加便捷的操作字符数据;
【示例代码】
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
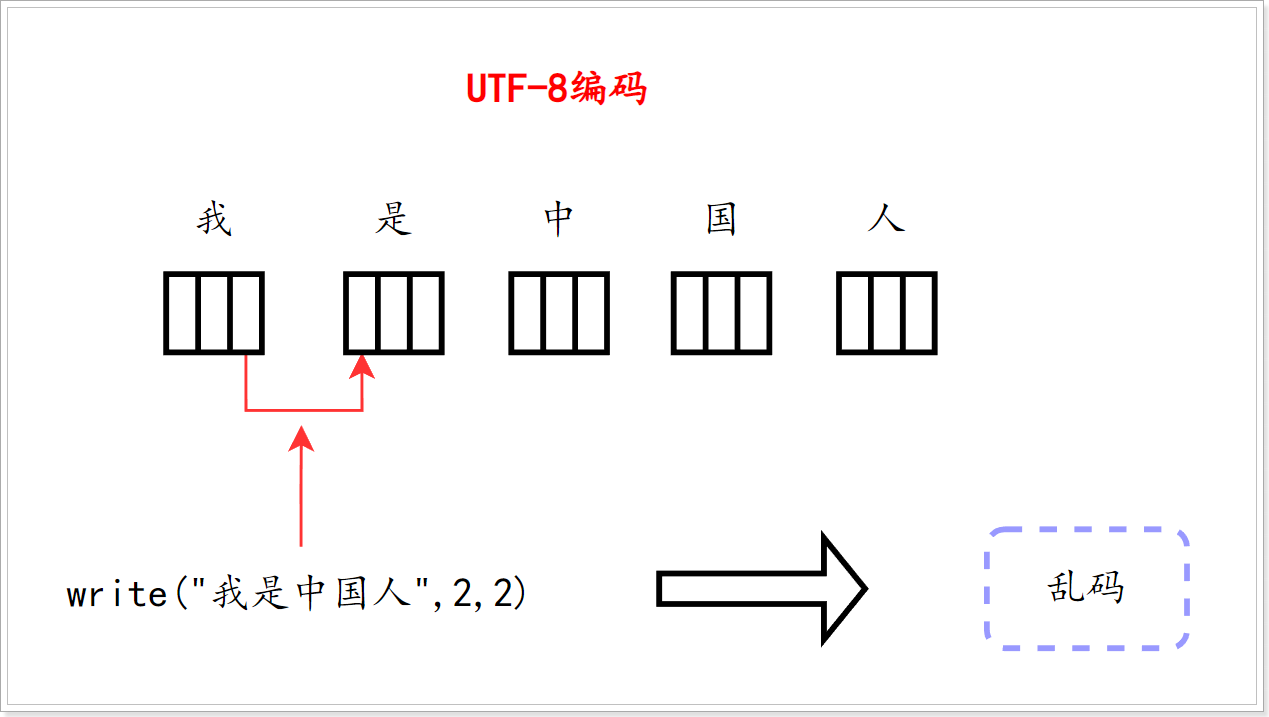
public class Demo07_偏移量写出中文问题 {
public static void main(String[] args) throws Exception {
OutputStream os = new FileOutputStream("001.txt");
String str = "我是中国人";
byte[] data = str.getBytes();
os.write(data,0,2);
os.close();
}
}
图解:
修改写出的位置:
package com.dfbz.demo01;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_字节流写出字符数据 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("000.txt");
// 字符串转换为字节数组
byte[] b = "我是中国人".getBytes();
/*
"我"字占用3个字节,"是"也占用3个字节,写出2下标~4下标位置的数据将会是乱码
0,3-->我
3,3-->是
6,3-->中
9,3-->过
12,3-->人
*/
fos.write(b,6,3);
// 关闭资源
fos.close();
}
}
但是上述代码仅仅是在UTF-8编码环境下才能运行成功,如果文件的编码换成了GBK,那么又会变得乱码,关于字符问题,我们可以使用后面学习的字符流来解决这个问题,让我们操作的单位不再是字节,而是字符!
2.1.4 写出字节问题
FileOutputStream的write方法明明是向文件写出一个字节,为什么参数不是byte而是int呢?一个int数占用4个字节,那么OutputStream写出int数到文件时底层又做了那些操作呢?
我们知道,一个字节的大小是8个位,其最多能表示2^8个数,即256,取值范围为0~255,在Java中byte的取值范围为:-128~127之间刚好是256个数;而使用write方法写出数据时,会根据ASCII码表进行转换,ASCII码表的取值范围为0~127,扩展ASCII码表的最大值取值范围为0~255,因此一个字节有许多字符存储不了(Java的byte取值范围为-128~127),而且Java中整数的默认类型就是int,故write方法中采用int作为参数;
另外,由于int占用的是4个字节,而write写出的时候只能写出一个字节,因此write方法在写出数据时如果超出了一个字节的范围则会做截取动作;
例如,使用write方法写出一个353的int数时,底层将会把353转为二进制并填充满4个字节(8个位):
十进制: 97 二进制: 00000000 00000000 00000000 01100001
十进制: 353 二进制: 00000000 00000000 00000001 01100001
十进制: 609 二进制: 00000000 00000000 00000010 01100001
十进制: 865 二进制: 00000000 00000000 00000011 01100001
write只会截取最后8个位,即:01100001

因此使用write方法写出97、353、609、865等数值时,文件的内容都是一个字符"a"
同理如下:
十进制: 98 二进制: 00000000 00000000 00000000 01100010
十进制: 354 二进制: 00000000 00000000 00000001 01100010
十进制: 610 二进制: 00000000 00000000 00000010 01100010
十进制: 866 二进制: 00000000 00000000 00000011 01100010
write只会截取最后8个位,即:01100010
使用write方法写出98、354、610、866等数值时,文件的内容都是一个字符"b"
- 示例代码:
package com.dfbz.demo01_OutputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_write方法写出单个字节问题探究 {
public static void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("001.txt");
// 00000000 00000000 00000000 01100001->a
fos.write(97);
// 00000000 00000000 00000001 01100001->a
fos.write(353);
// 00000000 00000000 00000010 01100001->a
fos.write(609);
// 00000000 00000000 00000011 01100001->a
fos.write(865);
fos.write("\r\n".getBytes());
// 00000000 00000000 00000000 01100010->b
fos.write(98);
// 00000000 00000000 00000001 01100010->b
fos.write(354);
// 00000000 00000000 00000010 01100010->b
fos.write(610);
// 00000000 00000000 00000011 01100010->b
fos.write(866);
fos.close();
}
}
文件内容如下:
aaaa
bbbb
2.2 字节输入流
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public void close():关闭此输入流并释放与此流相关联的任何系统资源。public int read(): 从输入流中读取一个字节数据,将读取到的数据返回;读取到文件的末尾返回-1public int read(byte[] buf): 从输入流中读取一个字节数组的数据,返回实际读取到的有效字节数量;读取到文件的末尾返回-1public int read(byte[] buf, int off, int len):从输入流中读取len个字节,然后将读取到的字节从off位置开始放置到字节数组中,len不可以超出字节数组的长度;读取到文件的末尾返回-1public int available():返回输入流中剩余的有效字节个数,如果没有有效字节(读取到末尾)则返回0public long skip(long n):跳过输入流的n个字节public void mark(int readlimit):对当前的位置进行标记,在字节流中传递的readlimit参数是无意义的;public void reset():将此流重新定位到最后一次对此输入流调用mark方法时的位置public boolean markSupported():测试这个输入流是否支持mark和reset方法。 FileInputStream的markSupported方法返回false。
2.2.1 FileInputStream类
java.io.FileInputStream类是文件输入流,从文件中读取字节。
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
Tips:当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出
FileNotFoundException。
【示例代码】
package com.dfbz.demo02_InputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.InputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_FileInputStream构造方法 {
public static void main(String[] args) throws Exception{
InputStream is=new FileInputStream("001.txt");
InputStream is2=new FileInputStream(new File("001.txt"));
is.close();
is2.close();
}
}
2.2.2 FileOutputStream的使用
1) 常用方法
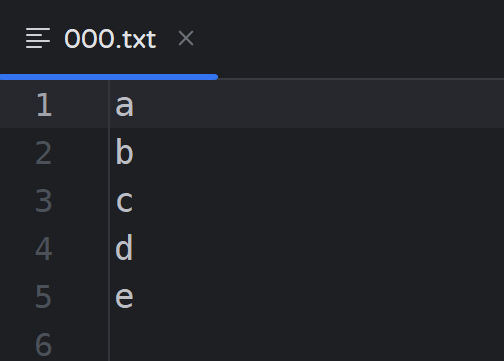
将000.txt文件的内容改为abcde
【示例代码-读取单个字节】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_读取单个字符 {
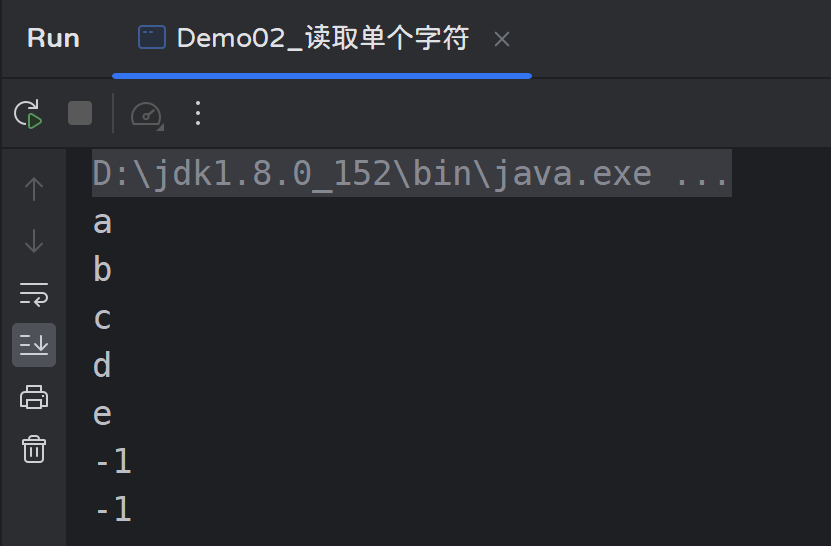
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("000.txt");
// 读取数据,返回一个字节
int read = fis.read();
System.out.println((char) read); // a
read = fis.read();
System.out.println((char) read); // b
read = fis.read();
System.out.println((char) read); // c
read = fis.read();
System.out.println((char) read); // d
read = fis.read();
System.out.println((char) read); // e
// 读取到末尾,返回-1(-1不要转成字符,会出现乱码)
read = fis.read();
System.out.println(read); // -1
// 再读还是-1
read = fis.read();
System.out.println(read); // -1
// 关闭资源
fis.close();
}
}
运行结果:
【示例代码-循环改进读取方式】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_循环读取单个字符 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("000.txt");
// 接收我们读取的数据
int data;
while ((data = is.read()) != -1) {
// 代表读取到了有效的数据(没有读取到末尾)
System.out.println((char)data);
}
is.close();
}
}
Tips:虽然读取了一个字节,但是会自动提升为int类型。
【示例代码-读取一个字节数组】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Arrays;
/**
* @author lscl
* @version 1.0
* @intro:
*/
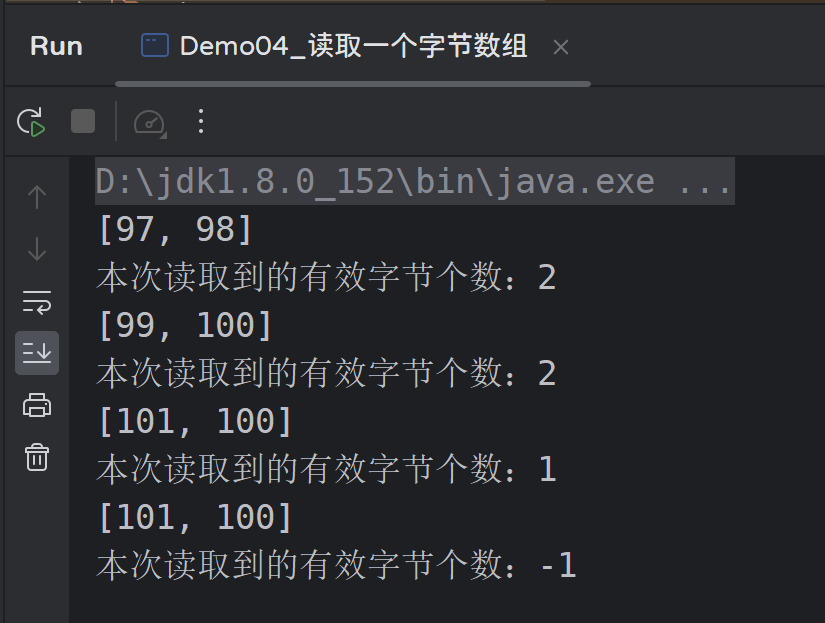
public class Demo04_读取一个字节数组 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("000.txt");
byte[] data = new byte[2];
int len = is.read(data);
System.out.println(Arrays.toString(data)); // ab
System.out.println("本次读取到的有效字节个数:" + len); // 2
len = is.read(data);
System.out.println(Arrays.toString(data)); // cd
System.out.println("本次读取到的有效字节个数:" + len); // 2
len = is.read(data);
System.out.println(Arrays.toString(data)); // e(101) d(100)
System.out.println("本次读取到的有效字节个数:" + len); // 1
len = is.read(data);
System.out.println(Arrays.toString(data)); // e(101) d(100)
System.out.println("本次读取到的有效字节个数:" + len); // -1
is.close();
}
}
运行结果:
【示例代码-使用循环改进读取方式】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Arrays;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_循环使用字节数组读取 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("000.txt");
byte[] data = new byte[2];
int len;
while ((len = is.read(data)) != -1) {
System.out.println(new String(data));
}
is.close();
}
}
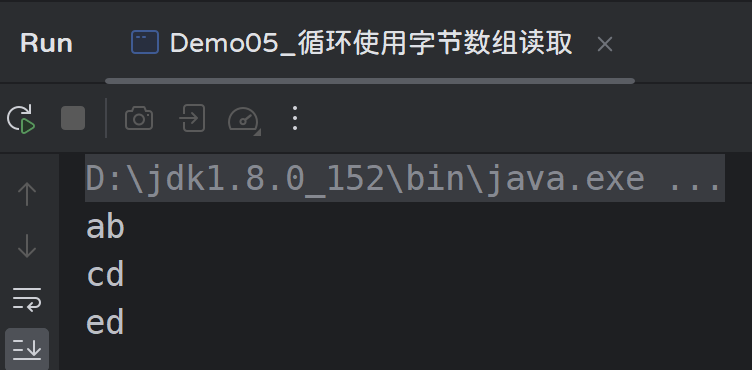
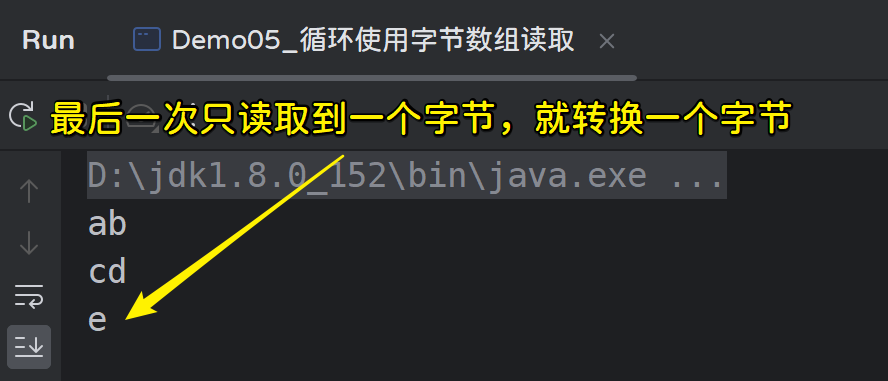
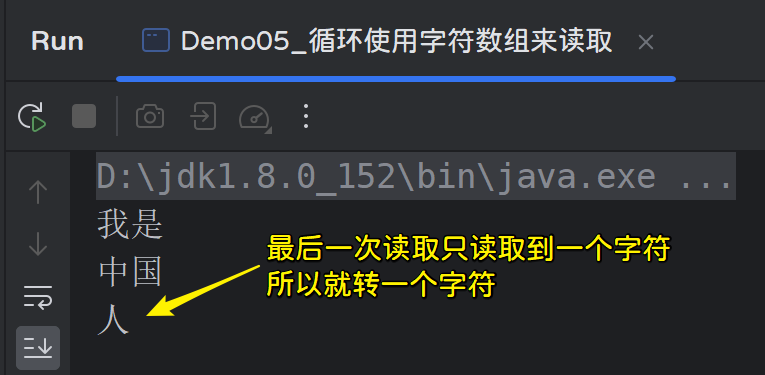
发现d出现了两次,这是由于最后一次读取时,只读取到了一个有效字节“e”,替换了原数组的0下标的“c”,图解分析如下:
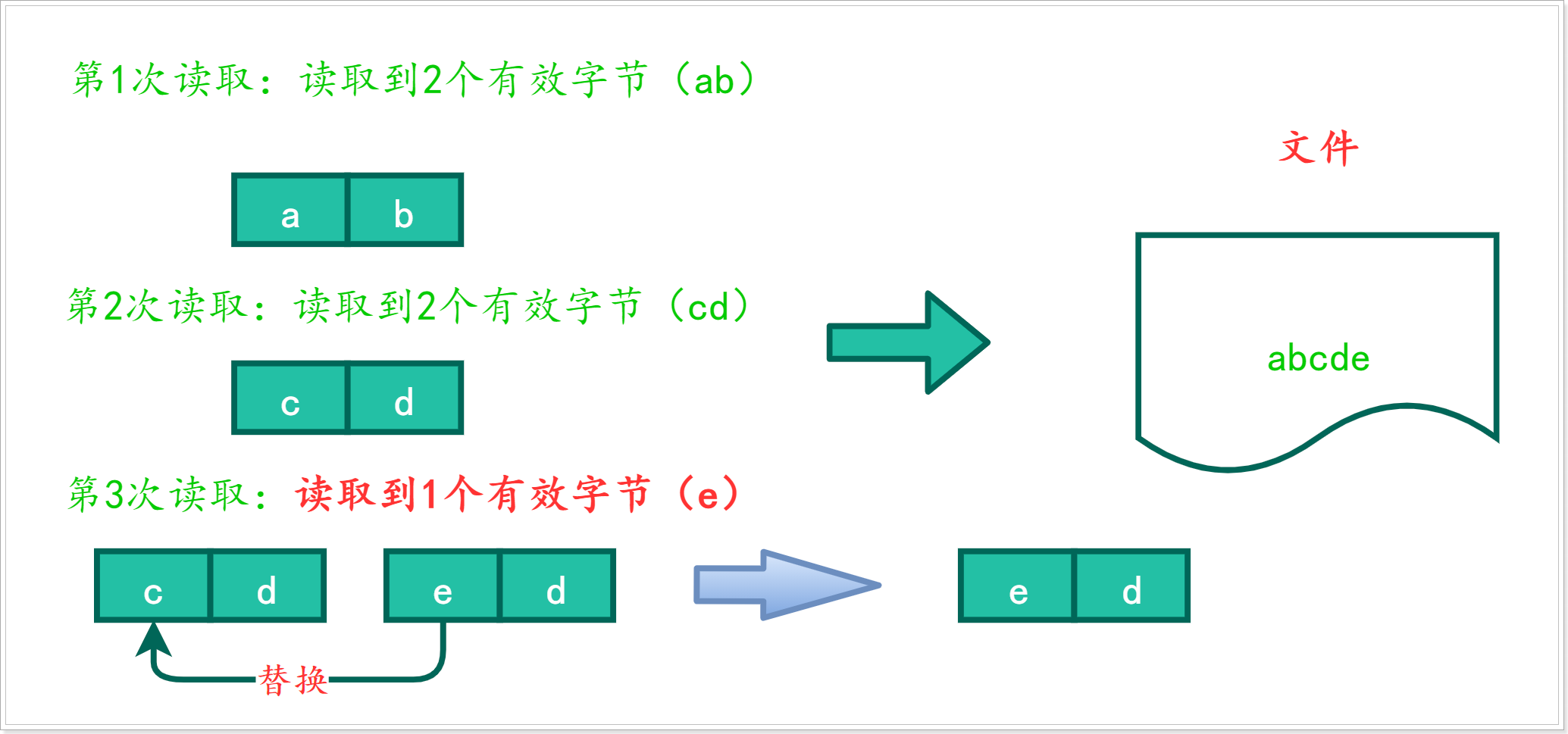
我们在转换的时候不能全部转换,而是只转换有效的字节,所以要通过len(实际读取到的字节个数) ,获取有效的字节,来决定到底转换多少个字节;
我们可以把每次读取到的有效字节个数打印出来:
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Arrays;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_循环使用字节数组读取 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("000.txt");
byte[] data = new byte[2];
int len;
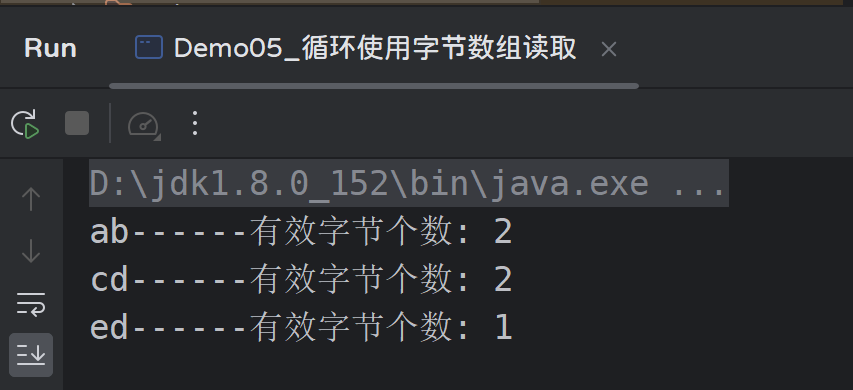
while ((len = is.read(data)) != -1) {
System.out.println(new String(data) + "------有效字节个数: " + len);
// System.out.println(new String(data));
}
is.close();
}
}
最后一次只读取到了一个有效字节,因此在最后一次我们可以只转换1个字节:
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Arrays;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_循环使用字节数组读取 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("000.txt");
byte[] data = new byte[2];
int len;
while ((len = is.read(data)) != -1) {
// System.out.println(new String(data) + "------有效字节个数: " + len);
// System.out.println(new String(data));
System.out.println(new String(data, 0, len));
}
is.close();
}
}
2) 按照偏移量来读取
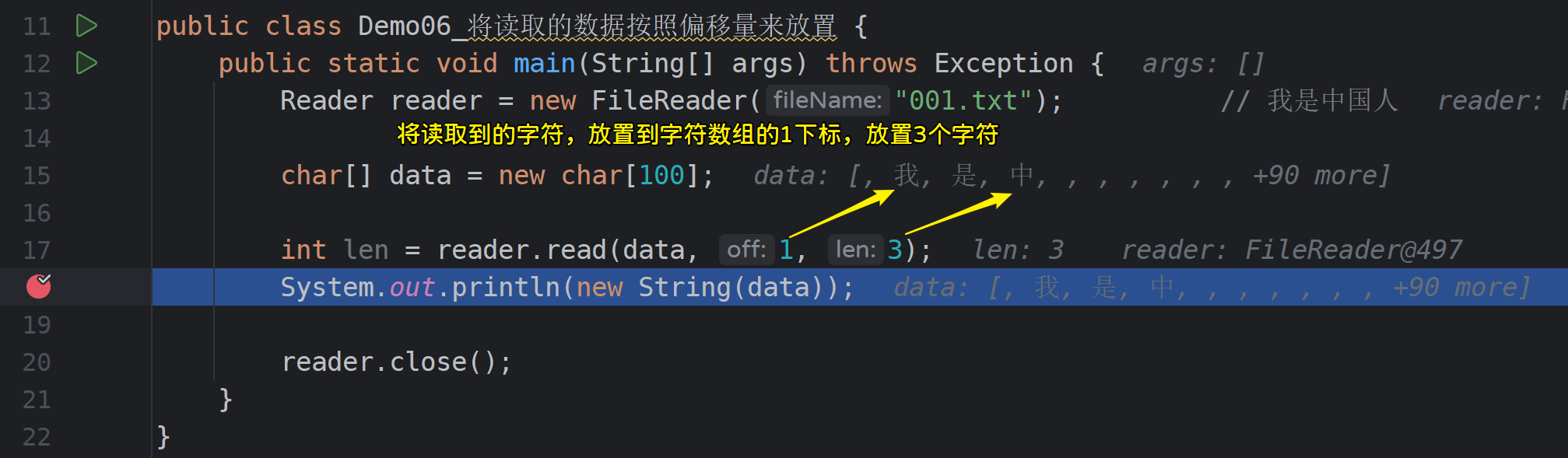
- 示例代码3-将从字节流中读取到的数据按位置排列到字节数组中
package com.dfbz.demo02_字节输入流;
import java.io.FileInputStream;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
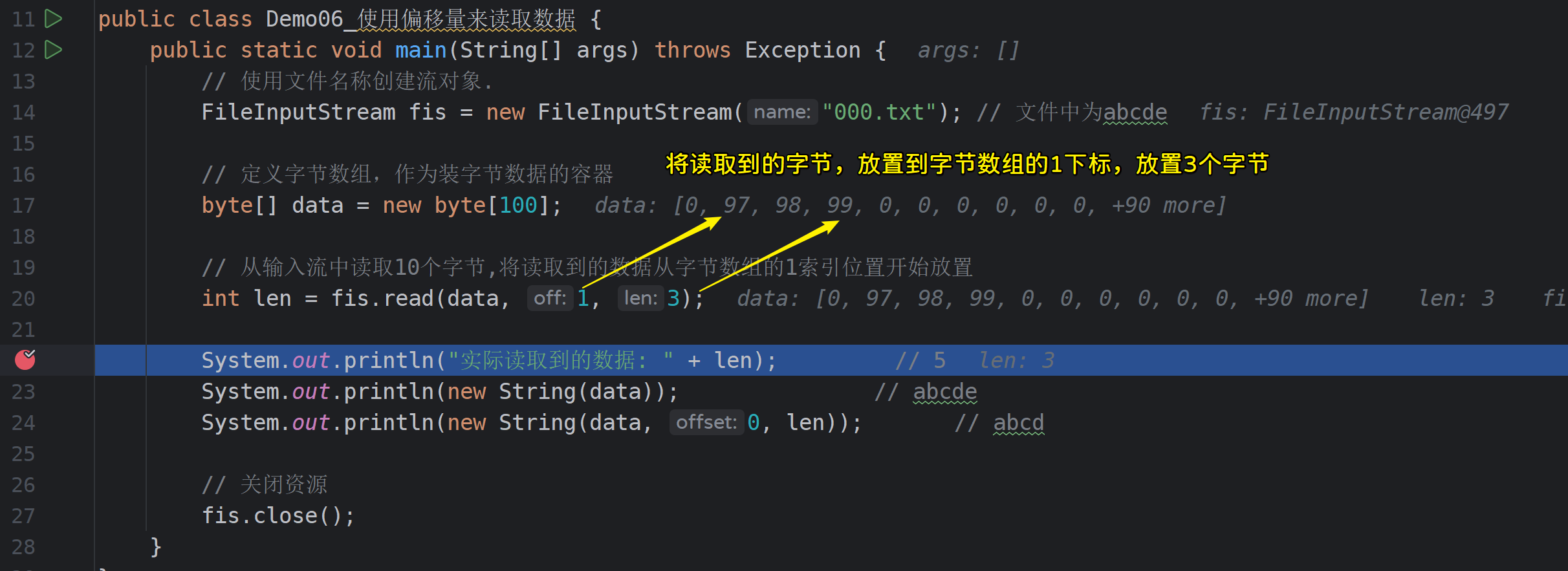
public class Demo06_使用len来读取数据 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("000.txt"); // 文件中为abcde
// 定义字节数组,作为装字节数据的容器
byte[] data = new byte[100];
// 从输入流中读取10个字节,将读取到的数据从字节数组的1索引位置开始放置
int len = fis.read(data, 1, 10);
System.out.println("实际读取到的数据: " + len); // 5
System.out.println(new String(data)); // abcde
System.out.println(new String(data, 0, len)); // abcd
// 关闭资源
fis.close();
}
}
运行示例:
2.2.3 FileInputStream其他方法
public int available():返回输入流中剩余的有效字节个数,如果没有有效字节(读取到末尾)则返回0public long skip(long n):跳过输入流的n个字节public void mark(int readlimit):对当前的位置进行标记,在字节流中传递的readlimit参数是无意义的;public void reset():将此流重新定位到最后一次对此输入流调用mark方法时的位置public boolean markSupported():测试这个输入流是否支持mark和reset方法。FileInputStream的markSupported方法返回false。
【示例代码-01】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
/**
* @author lscl
* @version 1.0
* @intro: InputStream的mark/reset方法是留给其他子类的,FileInputStream并不支持这两个方法,因此会出现异常:
* Exception in thread "main" java.io.IOException: mark/reset not supported
*/
public class Demo07_输入流的其他用法_mark_rest {
public static void main(String[] args) throws Exception {
FileInputStream is = new FileInputStream("001.txt"); // 文件内容abcde
if (!is.markSupported()) {
is.close();
System.out.println("对不起,您的流不支持mark操作");
System.exit(0);
}
System.out.println((char) is.read()); // a
System.out.println((char) is.read()); // b
/*
参数是没有意义的,传递什么都行
在当前指针的位置做个标记
*/
is.mark(1);
System.out.println((char) is.read()); // c
System.out.println((char) is.read()); // d
// 回到之前做的标记那里
is.reset();
System.out.println((char) is.read()); // c
System.out.println((char) is.read()); // d
is.close();
}
}
【示例代码-02】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
import java.io.InputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_输入流的其他用法_skip {
public static void main(String[] args) throws Exception{
InputStream is=new FileInputStream("001.txt"); // abcde
System.out.println((char)is.read()); // a
System.out.println((char)is.read()); // b
is.skip(2);
System.out.println((char)is.read()); // e
System.out.println(is.read()); // -1
is.close();
}
}
【示例代码-03】
package com.dfbz.demo02_InputStream;
import java.io.FileInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo09_输入流的其他用法_available {
public static void main(String[] args) throws Exception{
FileInputStream fis = new FileInputStream("002.txt"); // 文件中为ab
System.out.println(fis.available()); // 2
System.out.println(fis.read()); // 97
System.out.println(fis.available()); // 1
System.out.println(fis.read()); // 98
System.out.println(fis.available()); // 0
System.out.println(fis.read()); // -1
System.out.println(fis.available()); // 0
System.out.println(fis.read()); // -1
// 关闭资源
fis.close();
}
}
2.3 字节流练习
FileOutputStream 主要按照字节方式写文件,例如:我们做文件的复制,首先读取文件,读取后在将该文件另写一份保存到磁盘上,这就完成了备份
【示例代码-01】
package com.dfbz.demo03_文件的拷贝;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_文件的复制_单个字节拷贝 {
public static void main(String[] args) throws Exception {
long startTime = System.currentTimeMillis();
// 文件输入流,用于读取文件(将磁盘的数据----->内存)
FileInputStream fis = new FileInputStream("D:/001/geek.exe");
// 文件输出流,用于写出数据(将内存的数据----->磁盘)
FileOutputStream fos = new FileOutputStream("D:/aa.exe");
int data;
while ((data = fis.read()) != -1) {
fos.write(data);
}
fis.close();
fos.close();
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
}
}
拷贝一个6MB的文件,耗时:36104毫秒
【示例代码-02】
package com.dfbz.demo03_文件的拷贝;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_文件的复制_定义字节数组拷贝 {
public static void main(String[] args) throws Exception{
long startTime = System.currentTimeMillis();
// 文件输入流,用于读取文件(将磁盘的数据----->内存)
FileInputStream fis = new FileInputStream("D:/apache-tomcat-8.0.43-feedback.zip");
// 文件输出流,用于写出数据(将内存的数据----->磁盘)
FileOutputStream fos = new FileOutputStream("D:/aa.zip");
byte[] data = new byte[8192];
int len;
while ((len = fis.read(data)) != -1) {
fos.write(data,0,len);
}
fis.close();
fos.close();
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
}
}
拷贝一个87.3MB的文件,耗时270毫秒
三、字符流
计算机都是按照字节进行存储的,我们之前学习过编码表,通过编码表可以将字节转换为对应的字符,但是世界上有非常多的编码表,不同的编码表规定的单个字符所占用的字节可能都不一样,例如在GBK编码表中一个中文占2个字节,UTF8编码表则占3个字节;且一个中文字符都是由多个字节组成的,为此我们不能再基于字节的操作单位来操作文本文件了,因为这样太过麻烦,我们希望基于字符来操作文件,一次操作读取一个“字符”而不是一个“字节”,这样在操作文本文件时非常便捷;
3.1 字符输入流
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public void close():关闭此流并释放与此流相关联的任何系统资源。public int read():每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回-1public int read(char[] buf): 每次读取一个字符数组的数据读取到buf中,返回读取到的有效字符个数,读取到末尾时,返回-1public int read(char buf[], int off, int len):从输入流中读取len个字符,然后将读取到的字符从字符数组的off位置开始放置,len不可以超出字符数组的长度;读取到文件末尾返回-1
3.1.1 FileReader类
java.io.FileReader类是读取字符文件的便利类,使用系统默认的字符编码来读取字符,并且内置1024大小的字符缓冲区;
Tips:Windows系统的中文编码默认是GBK编码表。idea中默认是UTF-8
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于FileInputStream 。
package com.dfbz.demo01_字符输出流;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_FileReader构造方法 {
public static void main(String[] args) throws FileNotFoundException {
// 使用File对象创建流对象
File file = new File("a.txt");
FileReader fr = new FileReader(file);
// 使用文件名称创建流对象
FileReader fr2 = new FileReader("b.txt");
}
}
3.1.2 FileReader的使用
1) 常用方法
public int read():每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回-1public int read(char buf[]):每次读取一个字符数组的数据读取到buf中,返回读取到的有效字符个数,读取到末尾时,返回-1public int read(char cbuf[], int offset, int length):从输入流中读取len个字符,然后将读取到的字符从字符数组的off位置开始放置,len不可以超出字符数组的长度;读取到文件末尾返回-1
【示例代码-01-读取单个字符】
package com.dfbz.demo01_Reader;
import java.io.FileReader;
import java.io.Reader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_读取单个字符 {
public static void test(String[] args) throws Exception {
// 创建一个字符输入流
Reader reader = new FileReader("001.txt"); // 文件内容我是中国人
System.out.println((char) reader.read()); // 我
System.out.println((char) reader.read()); // 是
System.out.println((char) reader.read()); // 中
System.out.println((char) reader.read()); // 国
System.out.println((char) reader.read()); // 人
System.out.println(reader.read()); // -1
System.out.println(reader.read()); // -1
System.out.println(reader.read()); // -1
reader.close();
}
}
输出结果:
我
是
中
国
人
Tips:虽然读取了一个字符,但是会自动提升为int类型,输出时注意转换为char。
【示例代码-循环读取数组】
package com.dfbz.demo01_Reader;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_循环读取字符 {
public static void main(String[] args) throws IOException {
Reader reader = new FileReader("001.txt");
// 定义一个变量来接收读取到的字符
int data;
// 如果读取到的内容不是-1,代表读取的是有效字符
while ((data = reader.read()) != -1) {
System.out.print((char)data);
}
reader.close();
}
}
【示例代码-读取字符数组】
package com.dfbz.demo01_Reader;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.InputStream;
import java.io.Reader;
import java.util.Arrays;
/**
* @author lscl
* @version 1.0
* @intro:
*/
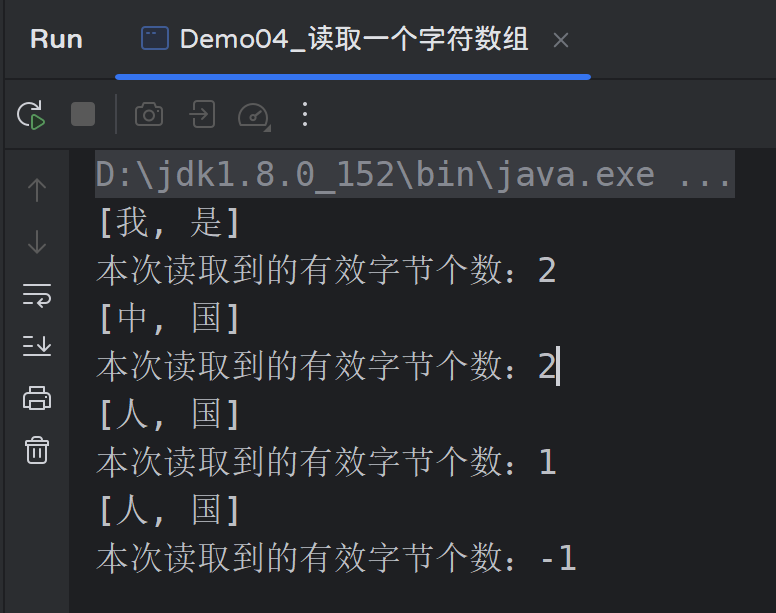
public class Demo04_读取一个字符数组 {
public static void main(String[] args) throws Exception{
Reader reader = new FileReader("001.txt"); // 文件内容: 我是中国人
char[] data = new char[2];
int len = reader.read(data);
System.out.println(Arrays.toString(data)); // [我, 是]
System.out.println("本次读取到的有效字节个数:" + len); // 2
len = reader.read(data);
System.out.println(Arrays.toString(data)); // [中, 国]
System.out.println("本次读取到的有效字节个数:" + len); // 2
len = reader.read(data);
System.out.println(Arrays.toString(data)); // [人, 国]
System.out.println("本次读取到的有效字节个数:" + len); // 1
len = reader.read(data);
System.out.println(Arrays.toString(data)); // [人, 国]
System.out.println("本次读取到的有效字节个数:" + len); // -1
reader.close();
}
}
输出结果:
【示例代码-获取有效的字符改进】
package com.dfbz.demo01_Reader;
import java.io.FileReader;
import java.io.Reader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_循环使用字符数组来读取 {
public static void main(String[] args) throws Exception{
Reader reader = new FileReader("001.txt");
char[] data = new char[2];
int len;
while ((len = reader.read(data))!=-1){
// 读到了多少个有效字符就转多少个
System.out.println(new String(data,0,len));
}
reader.close();
}
}
输出结果:
2) 按照偏移量来读取
package com.dfbz.demo01_字符输出流;
import java.io.FileReader;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_使用len来读取数据 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("001.txt");
// 准备一个字符数组来接收字符流读取的数据l
char[] buf = new char[100];
// 从输入流中读取10个字符,将读取到的数据从字符数组的3索引位置开始放置数据
int len = fr.read(buf, 3, 10);
System.out.println("读取到的有效字符: " + len); // 5
System.out.println(new String(buf)); // 我是中国人
System.out.println(new String(buf, 0, len)); // 我是
// 关闭资源
fr.close();
}
}
运行程序,查看效果:
3) 乱码问题
字符流只是操作的数据单位变为了字符而已,在读取文本文件时依旧要指定文本的编码(默认使用的是idea所使用的编码表),并非使用了字符流就一定不会出现乱码问题,字符流默认使用的是开发工具的默认编码,如果文件编码和开发工具的编码不一致,一样会出现乱码问题;
- idea默认的编码表:
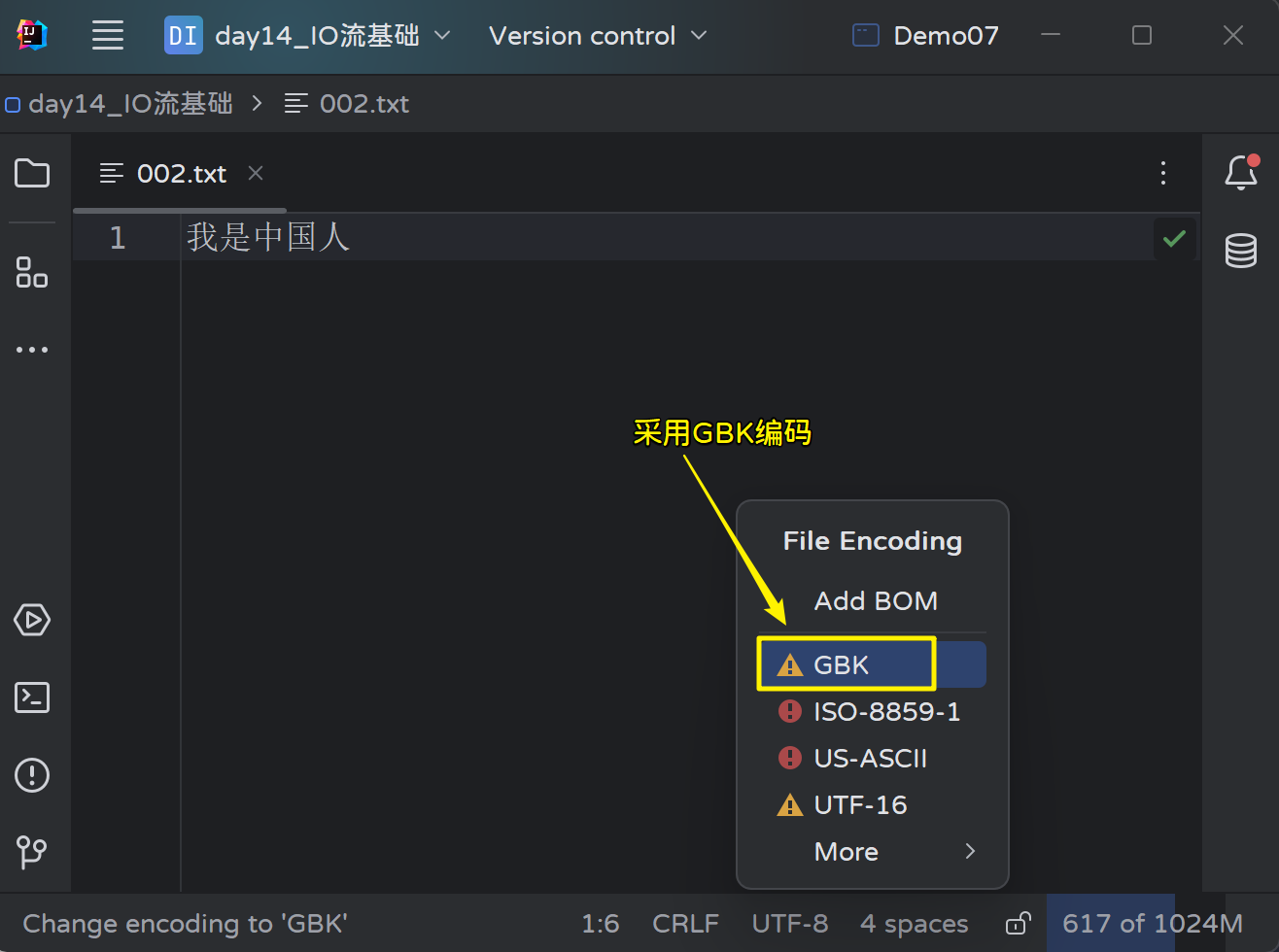
使用idea创建一个文本,并采用GBK进行编码:
- 示例代码:
package com.dfbz.demo01_Reader;
import java.io.FileReader;
import java.io.Reader;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_字符流乱码问题 {
public static void main(String[] args) throws Exception {
Reader reader = new FileReader("002.txt"); // 我是中国人
char[] data = new char[5];
int len = reader.read(data); // 读取5个字符
System.out.println(new String(data,0,len));
reader.close();
}
}
运行效果:
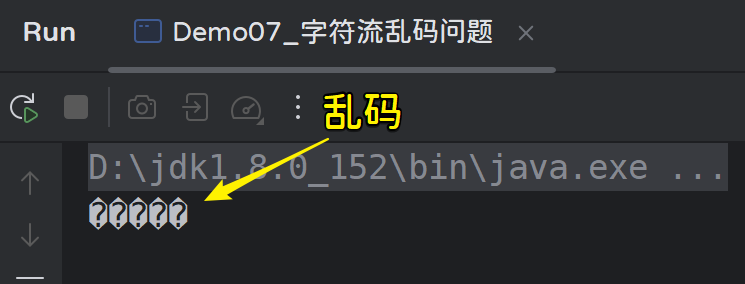
我们可以把文本的编码改为UTF-8,或者把idea的编码改为GBK,都可以使文本读取正常;
Tips:项目内容已经存在了再更改项目的编码是不能改变那些Java文件编码的,测试的时候需要新建立一个项目,将项目的编码改为GBK,然后再执行上述代码,可以发现能够正常读取GBK文件;
3.2 字符输出流
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
void write(int c)写入单个字符。void write(char[] cbuf)写入字符数组。abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串。void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()刷新该流的缓冲。void close()关闭此流,但要先刷新它。
3.2.1 FileWriter类
java.io.FileWriter类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。
- 构造举例,代码如下:
package com.dfbz.demo02_Writer;
import java.io.File;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_FileWriter的构造方法 {
public static void main(String[] args) throws Exception {
// 使用File对象创建流对象
File file = new File("a.txt");
FileWriter fw = new FileWriter(file);
// 使用文件名称创建流对象
FileWriter fw2 = new FileWriter("b.txt");
}
}
1) 写出字符数据
- 示例代码1-写出单个字符数据:
package com.dfbz.demo02_字符输入流;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_写出单个字符数据 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("002.txt");
// 写出数据
fw.write(97); // 写出第1个字符
fw.write('b'); // 写出第2个字符
fw.write('C'); // 写出第3个字符
fw.write(22909); // 写出第4个字符,中文编码表中22909对应一个汉字"好"。
/*
【注意】关闭资源时,与FileOutputStream不同。
如果不关闭,数据只是保存到缓冲区,并未保存到文件。
*/
fw.close();
}
}
Tips:未调用close方法,数据只是保存到了缓冲区,并未写出到文件中。
- 示例代码2-写出字符数组:
package com.dfbz.demo02_Writer;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_写出字符数组 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("002.txt");
// 字符串转换为字节数组
char[] data = "我是中国人".toCharArray();
// 写出字符数组
fw.write(data); // 我是中国人
// 写出从索引2开始,2个字节。索引2是'中',两个字节,也就是'中国'。
fw.write(data,2,2); // 中国
// 关闭资源
fw.close();
}
}
文件内容:
我是中国人中国
2) 续写和换行
操作类似于FileOutputStream。
package com.dfbz.demo02_Writer;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_续写和换行 {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("002.txt", true);
// 写出字符串
fw.write("我是");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("中国人");
// 关闭资源
fw.close();
}
}
3) 关闭和刷新
因为字符输出流内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush 方法了。
flush:刷新缓冲区,流对象可以继续使用。close:先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
代码使用演示:
package com.dfbz.demo02_Writer;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_flush_close方法 {
public static void main(String[] args) throws Exception {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("002.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功
fw.flush();
// 写出数据,通过close
fw.write('关'); // 写出第1个字符
fw.close();
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();
}
}
Tips:即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
3.3 拷贝文件问题
3.3.1 字符流拷贝文件
字符流只能操作文本文件,不能操作图片,视频等非文本文件。当我们单纯读或者写文本文件时可以使用字符流,其他情况使用字节流;
准备一个text.txt文档:
先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。
将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
今当远离,临表涕零,不知所言。
1)字符流拷贝文本文件:
package com.dfbz.demo03_拷贝案例;
import java.io.FileReader;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_字符流拷贝文本 {
public static void main(String[] args) throws Exception{
FileReader fr = new FileReader("text.txt");
FileWriter fw = new FileWriter("text_copy.txt");
// 准备一个字符数组接收字符数据
char[] data = new char[1024];
int len;
while ((len = fr.read(data)) != -1) {
fw.write(data,0,len);
}
fr.close();
fw.close();
}
}
打开text_copy.txt文件发现内容正常;
2)字符流拷贝非文本文件:
package com.dfbz.demo03_拷贝案例;
import java.io.FileReader;
import java.io.FileWriter;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_字符流拷贝非文本 {
public static void main(String[] args) throws Exception{
FileReader fr = new FileReader("100.png");
FileWriter fw = new FileWriter("100_copy.png");
// 准备一个字符数组接收字符数据
char[] data = new char[1024];
int len;
while ((len = fr.read(data)) != -1) {
fw.write(data,0,len);
}
fr.close();
fw.close();
}
}
打开100_copy.png发现文件损坏;
- 得出结论:字符流可以拷贝文本文件,但不可以拷贝非文本文件
- 原因:因为字符流在拷贝文件过程中,就先会将读取到的数据转换为字符,而非文本文件内容本质上并不是一个字符,因此要转换为对应的字符会出现乱码,而最终将乱码写入到新的文件中,造成新的文件损坏;
3.3.2 字节流拷贝文件
由于拷贝文件时不需要将文本转换为对应的字符,而是直接基于字节的搬运,因此字节流既可以拷贝文本文件,又可以拷贝非文本文件
1)字节流拷贝文本文件
package com.dfbz.demo03_拷贝案例;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_字节流拷贝文本文件 {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("text.txt");
FileOutputStream fos = new FileOutputStream("text2.txt");
int len;
byte[] data = new byte[1024];
while ((len = fis.read(data)) != -1) {
fos.write(data,0,len);
}
fis.close();
fos.close();
}
}
2)字节流拷贝非文本文件
package com.dfbz.demo03_拷贝案例;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_字节流拷贝非文本文件 {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("100.png");
FileOutputStream fos = new FileOutputStream("101.png");
int len;
byte[] data = new byte[1024];
while ((len = fis.read(data)) != -1) {
fos.write(data,0,len);
}
fis.close();
fos.close();
}
}
3)字节流读取字符
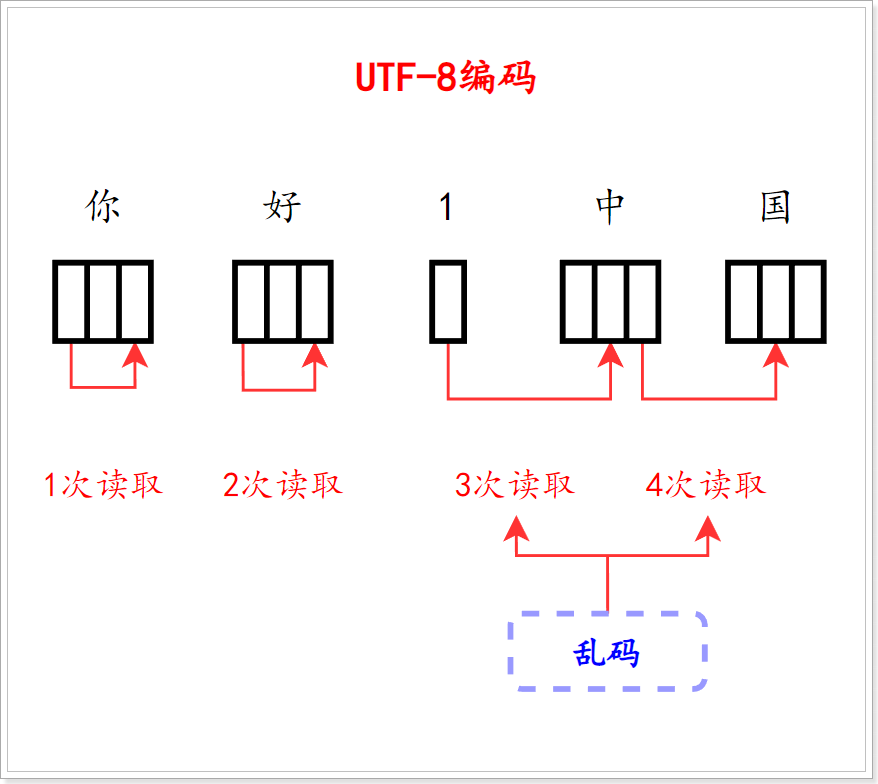
我们指定UTF-8的字符占用3个字节,GBK的字符占用2个字节,那么固定编码表的情况下(假设为UTF8),我们将字节数组大小定义为3来读取,是不是就可以很完美的读取所有的字符呢?
- 示例代码:
package com.dfbz.demo03_拷贝案例;
import java.io.FileInputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_字节流读取文本 {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("text.txt");
int len;
byte[] data = new byte[3]; //定义一个大小为3的字节数组
while ((len = fis.read(data)) != -1) {
/*
一次读取三个字节,刚好是一个汉字.可以解决中文乱码问题,这种方法是能解决此问题
但如果中间含有一个字节的符号。例如,1+回车符等等...就会出现乱码问题
字节流不适用于读取文本文件
*/
System.out.print(new String(data, 0, len));
}
fis.close();
}
}
运行代码,查看控制台:
先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
����������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������
���������������������������������������������
发现还是出现乱码问题;画图分析:
四、IO异常的处理
4.1 JDK7前处理
之前的入门练习,我们一直把异常抛出,而实际开发中并不能这样处理,建议使用try...catch...finally 代码块,处理异常部分,代码使用演示:
package com.dfbz.demo01_异常的标准处理方式;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_JDK7之前的异常处理方式 {
public static void main(String[] args) {
// 声明变量
FileWriter fw = null;
try {
//创建流对象
fw = new FileWriter("fw.txt");
// 写出数据
fw.write("我是中国人"); //我是中国人
} catch (IOException e) {
e.printStackTrace();
} finally {
// 不管是否出现异常都需要关闭流,释放资源
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4.2 JDK7的处理
4.2.1 JDK7处理异常的方式
Java7提供的try-with-resources语句,是异常处理的一大利器。该语句确保了每个资源在语句结束时关闭。所谓的资源(resource)是指在程序完成后,必须关闭的对象。
格式:
try (创建流对象语句,如果多个,使用';'隔开) {
// 读写数据
} catch (IOException e) {
e.printStackTrace();
}
- 示例代码:
package com.dfbz.demo01_异常的标准处理方式;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_JDK7的标准处理异常方式 {
public static void main(String[] args) {
/*
写在try()中的流,在try{}代码块执行完毕后,会自动关流,
而且即使是出现异常了也会帮我们自动关流,
如果是创建流的时候就出现异常了,流对象创建失败,则不会调用这个流的close方法(调用了就空指针了)
*/
try (
InputStream is = new FileInputStream("001.txt");
OutputStream os = new FileOutputStream("001.txt");
) {
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.2.2 AutoCloseable接口
在JDK7中,声明在try()中的类必须实现AutoCloseable接口,在资源处理完毕时,将自动的调用AutoCloseable接口中的close方法,如果没有实现AutoCloseable接口的类将不能写在try()中;
public interface AutoCloseable {
void close() throws Exception;
}
【定义AutoCloseable接口子类】
package com.dfbz.demo02_AutoCloseable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class TestAutoCloseable implements AutoCloseable {
public TestAutoCloseable() {
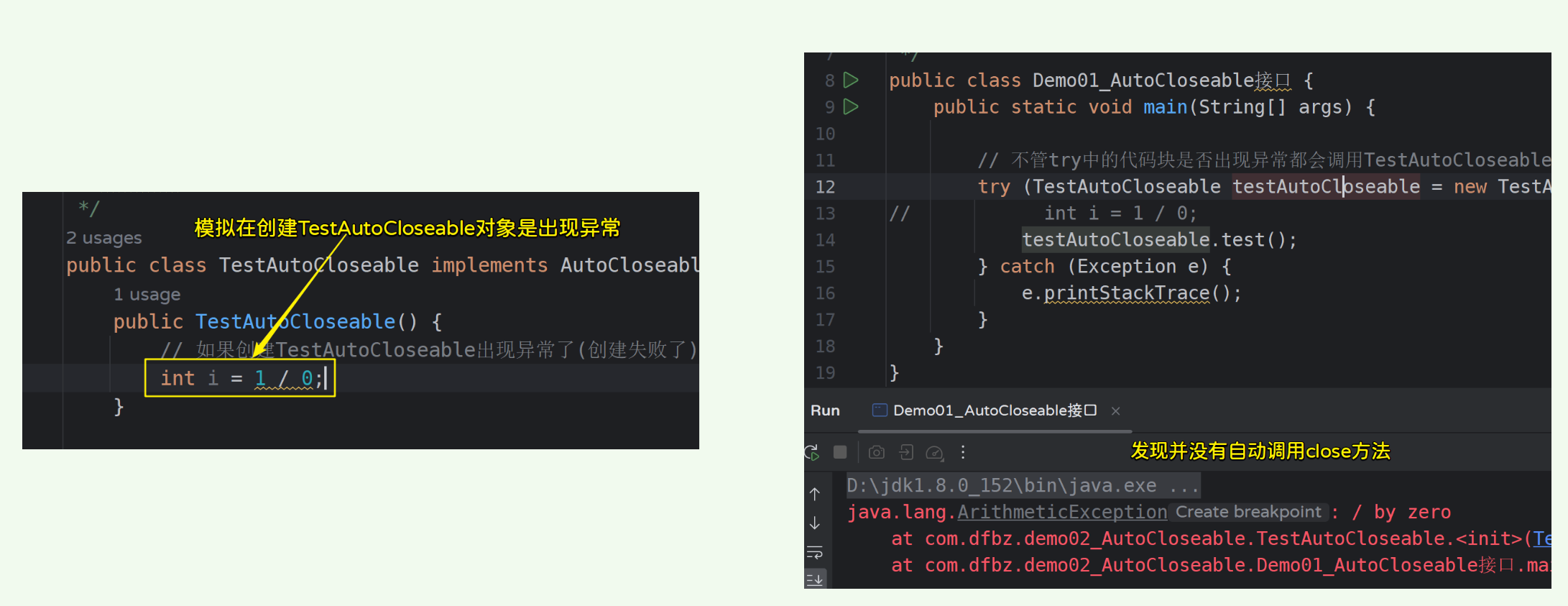
// 如果创建TestAutoCloseable出现异常了(创建失败了),则不会调用close方法
// int i = 1 / 0;
}
public void test() {
System.out.println("测试方法");
}
@Override
public void close() throws Exception {
System.out.println("close方法调用啦!");
}
}
测试AutoClouseable:
package com.dfbz.demo02_AutoCloseable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_AutoCloseable接口 {
public static void main(String[] args) {
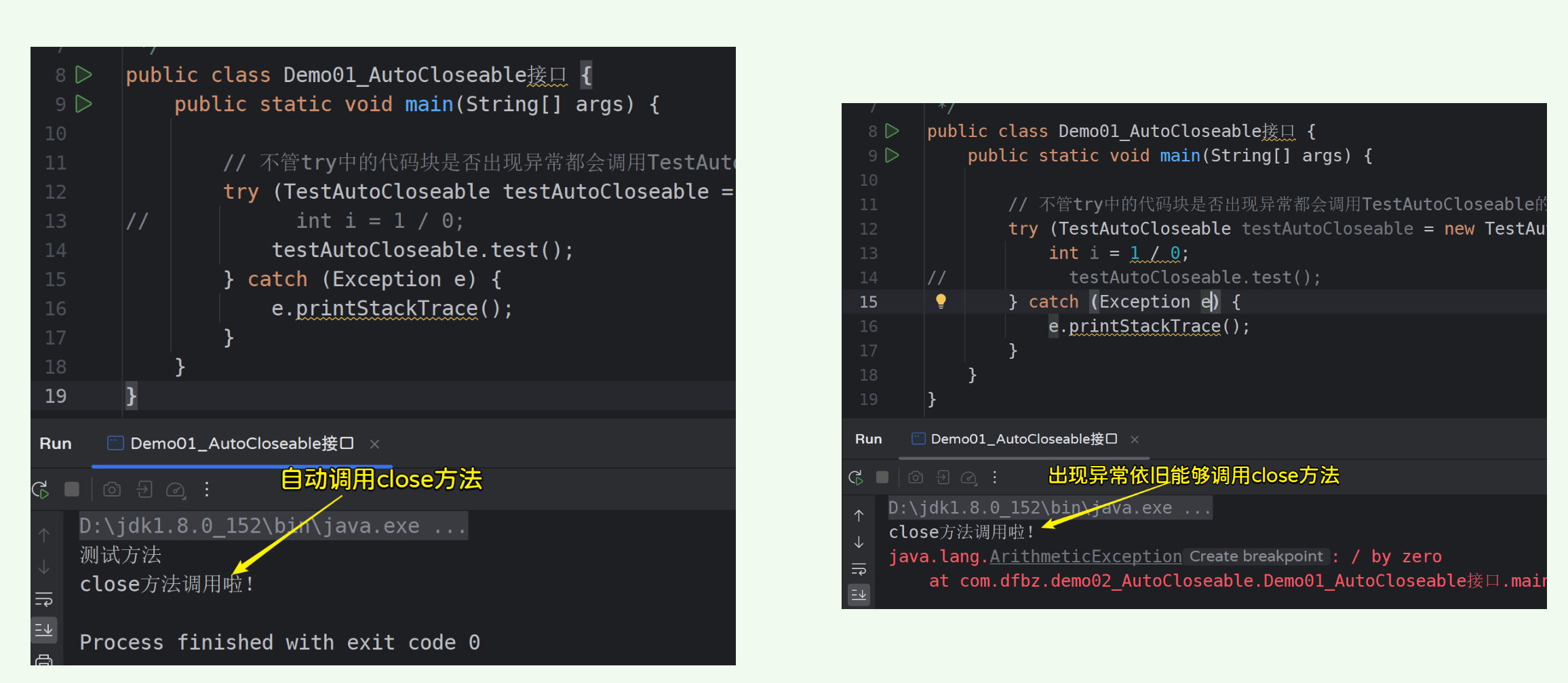
// 不管try中的代码块是否出现异常都会调用TestAutoCloseable的close方法,除非TestAutoCloseable创建的时候出现异常了(创建失败了)
try (TestAutoCloseable testAutoCloseable = new TestAutoCloseable();) {
// int i = 1 / 0;
testAutoCloseable.test();
} catch (Exception e) {
e.printStackTrace();
}
}
}
查看控制台运行:
如果创建TestAutoCloseable时失败了,则并不会调用close方法:
我们可以看到四个父接口都继承了AutoCloseable,也就是说Java中的所有流都实现了AutoCloseable接口:

五、属性集
5.1 概述
java.util.Properties 继承于Hashtable ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。该类也被许多Java类使用,比如获取系统属性时,System.getProperties 方法就是返回一个Properties对象。
5.2 Properties类
5.2.1 构造方法
public Properties():创建一个空的属性列表。
5.2.2 基本的存储方法
public Object setProperty(String key, String value): 保存一对属性。public String getProperty(String key):使用此属性列表中指定的键搜索属性值。public Set<String> stringPropertyNames():所有键的名称的集合。
package com.dfbz.demo01_Properties的用法;
import java.util.Properties;
import java.util.Set;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_Properties的基本用法 {
public static void main(String[] args) {
Properties prop = new Properties();
prop.setProperty("username","root");
prop.setProperty("password","123");
prop.setProperty("email","root@admin.com");
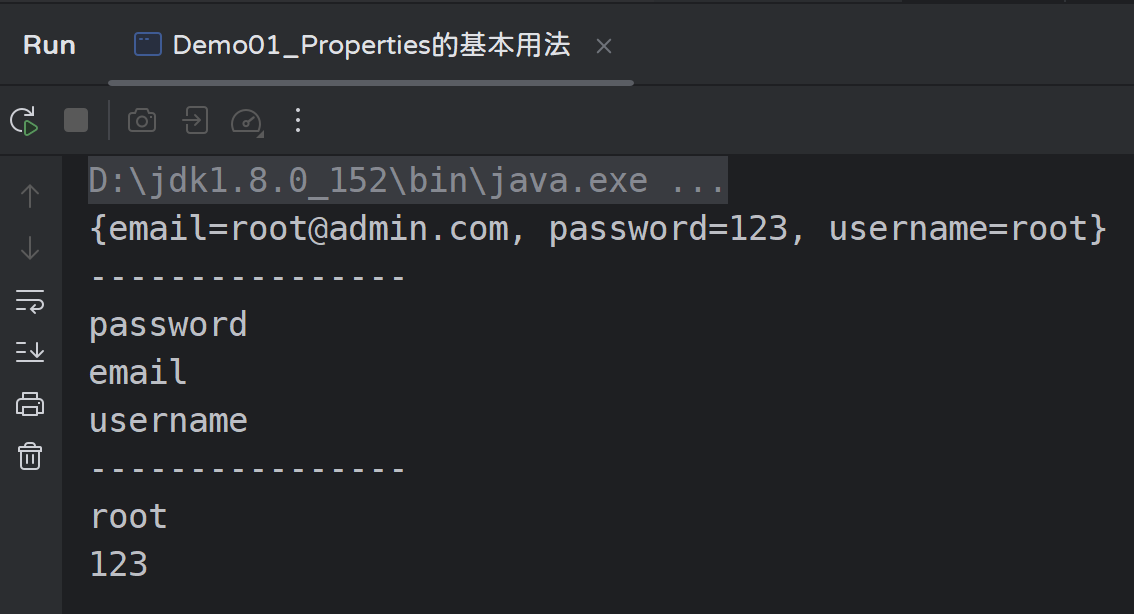
System.out.println(prop);
System.out.println("----------------");
// 获取所有key
Set<String> keys = prop.stringPropertyNames();
for (String key : keys) {
System.out.println(key);
}
System.out.println("----------------");
System.out.println(prop.getProperty("username")); // root
System.out.println(prop.getProperty("password")); // 123
}
}
运行效果:
5.3 操作属性集
5.3.1 读取流
public void load(InputStream inStream): 从字节输入流中读取键值对。
参数中使用了字节输入流,通过流对象,可以关联到某文件上,这样就能够加载文本中的数据了。文本数据格式:
username=root
password=123
加载代码演示:
package com.dfbz.demo01_Properties的用法;
import java.io.FileInputStream;
import java.io.FileReader;
import java.util.Properties;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_Properties加载配置文件 {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("config.properties");
FileReader fr = new FileReader("config.properties");
// 属性集
Properties prop = new Properties();
// 可以加载字符流也可以加载字节流
prop.load(fis);
// prop.load(fr);
System.out.println(prop); // {password=123, username=root}
}
}
Tips:文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。
5.3.2 写出流
public void store(Writer writer, String comments):将Properties中的属性集写出到一个输出流中,并指定注释信息;
【示例代码】
package com.dfbz.demo01_Properties的用法;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.util.Properties;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_Properties写出配置 {
public static void main(String[] args) throws Exception {
// 属性集
Properties prop = new Properties();
prop.setProperty("id", "001");
prop.setProperty("name", "南昌拌粉");
prop.setProperty("price", "3.5");
prop.setProperty("origin", "南昌");
// 将属性集中的配置写到输出流中
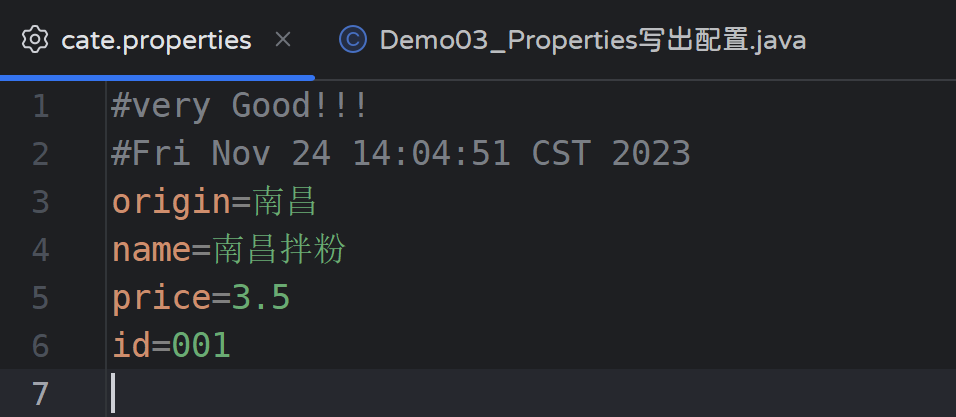
prop.store(new FileWriter("cate.properties"), "very Good!!!");
}
}
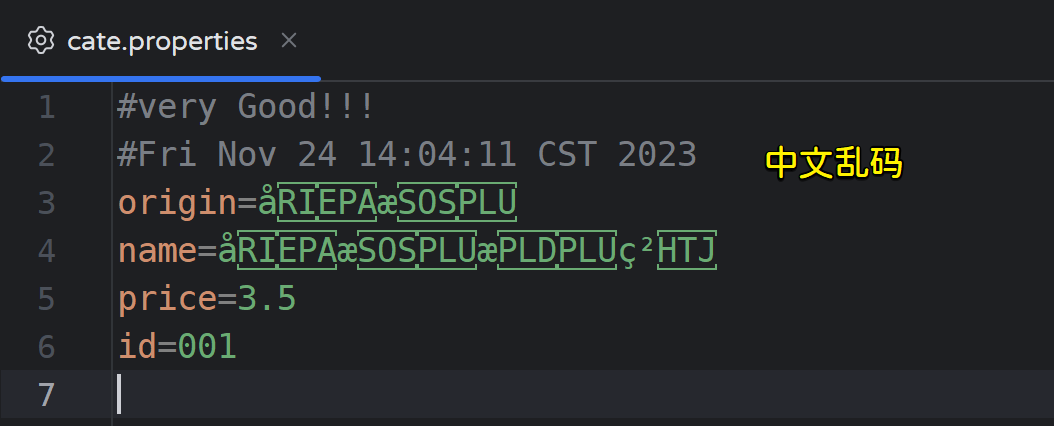
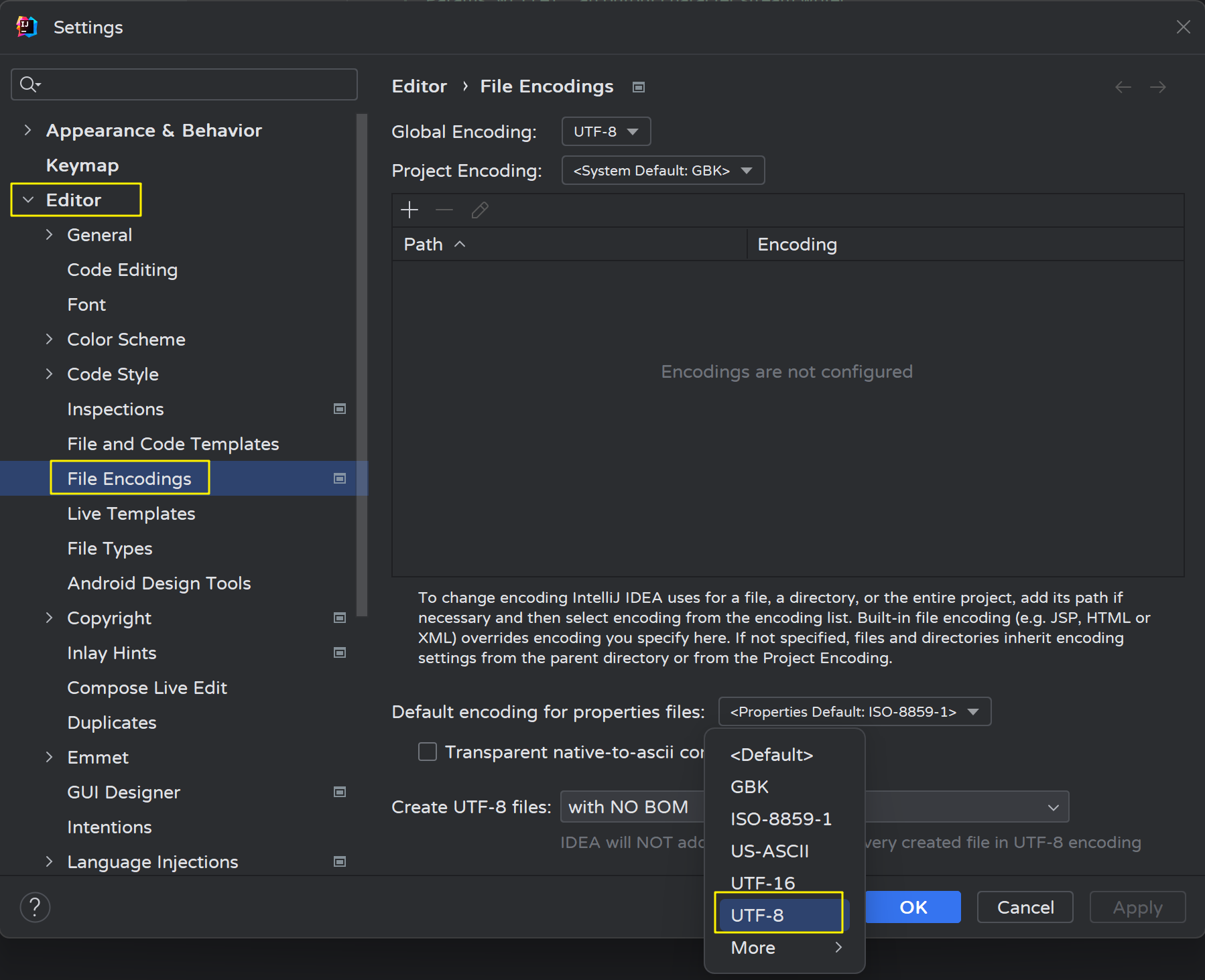
修改编码:
再次运行:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号