爬取夸克热搜排行榜
Python网络爬虫——爬取夸克热搜排行榜
一、 选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10分)
从社会、经济、技术、数据来源等方面进行描述(200字以内)
疫情的爆发使无数的人无法离开家门,那么他们都依靠什么来缓解焦虑呢。阿里巴巴旗下智能搜索APP夸克发布的数据报告显示,我们熟悉的生活却从未走远:有人走进厨房用美食治愈自己,有人关注和萌宠的相处之道,还有人规划起了疫情之后的旅行。
二、主题式网络爬虫设计方案(10分)
1.主题式网络爬虫名称
Python网络爬虫——爬取夸克热搜排行榜
2.主题式网络爬虫爬取的内容与数据特征分析
爬取今日的热搜数据做可视化处理
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
步骤:首先,先确定此次的选题的主题内容,然后爬取夸克热搜排行,设计爬取程序进行爬取(爬取内容时会遇到爬出来的数据为***万人,思考如何将此数据变成数字),将爬取的数据做成xsl表格时(
1. 创建workbook2.创建worsheet3.数据写入sheet4.数据写入sheet5.保存到excel),接着进行可视化处理。最后,保存数据。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
我们所需的网站夸克热搜排行榜(https://quark.sm.cn/sfrom=kkframenew&predict=1&search_id=AAM0gYl%2BOkyU46PzPXUuYxYWwBPQa8ML6I6ZHAjFAA%2Faew%3D%3D_1640440403736&round_id=-1&pdtt=1640440403&uc_param_str=dnntnwvepffrgibijbprsvpidsdichei&q=%E7%83%AD%E6%90%9C%E6%8E%92%E8%A1%8C%E6%A6%9C&hid=72c443e2f1354914d23bba5bb0635f26)从此获取热搜的排名,热搜事件和热度
寻找出我们需要爬取的东西。
2.htmls页面解析
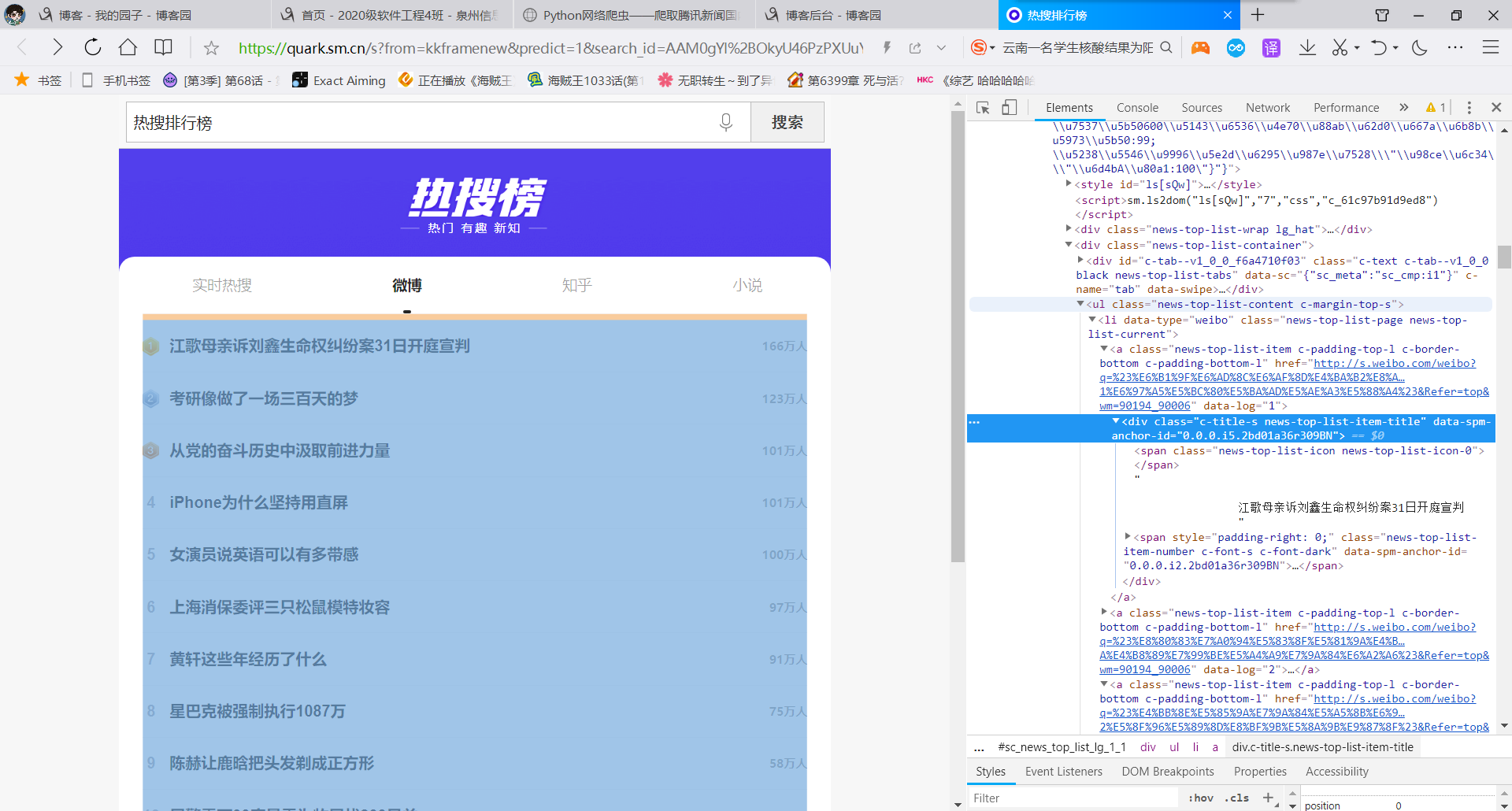
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)

四、网络爬虫程序设计
from bs4 import BeautifulSoup import re import urllib.request,urllib.error import xlwt import sqlite3 def getData(url): datalist = [] html = askURL(url) soup = BeautifulSoup(html,"html.parser") i=1 for item in soup.find_all('a', class_="news-top-list-item c-padding-top-l c-border-bottom c-padding-bottom-l"): data = [] item = str(item) pm = i i=i+1 data.append(pm) #测试print(item) findbt = re.compile(r'</span>(.*?)<span class="news-top-list-item-number') bt = re.findall(findbt, item)[0] data.append(bt) findrs = re.compile(r'dark">(.*?)<i class="news-top-list-item-trend') rs = re.findall(findrs, item)[0].replace("万人", "0000") data.append(rs) datalist.append(data) print(data) return datalist def askURL(url): head = { "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" } request = urllib.request.Request(url, headers=head) html = "" try: response = urllib.request.urlopen(request) html = response.read().decode("utf-8") except urllib.error.URLError as e: if hasattr(e, "code"): print(e.code) if hasattr(e, "reason"): print(e.reason) return html #askURL("https://quark.sm.cn/s?from=kkframenew&predict=1&search_id=AAM0gYl%2BOkyU46PzPXUuYxYWwBPQa8ML6I6ZHAjFAA%2Faew%3D%3D_1640440403736&round_id=-1&pdtt=1640440403&uc_param_str=dnntnwvepffrgibijbprsvpidsdichei&q=%E7%83%AD%E6%90%9C%E6%8E%92%E8%A1%8C%E6%A6%9C&hid=72c443e2f1354914d23bba5bb0635f26") url = ("https://quark.sm.cn/s?from=kkframenew&predict=1&search_id=AAM0gYl%2BOkyU46PzPXUuYxYWwBPQa8ML6I6ZHAjFAA%2Faew%3D%3D_1640440403736&round_id=-1&pdtt=1640440403&uc_param_str=dnntnwvepffrgibijbprsvpidsdichei&q=%E7%83%AD%E6%90%9C%E6%8E%92%E8%A1%8C%E6%A6%9C&hid=72c443e2f1354914d23bba5bb0635f26") html=askURL(url) datalist = getData(url) print(datalist) print("爬取完毕!")
输出结果图:

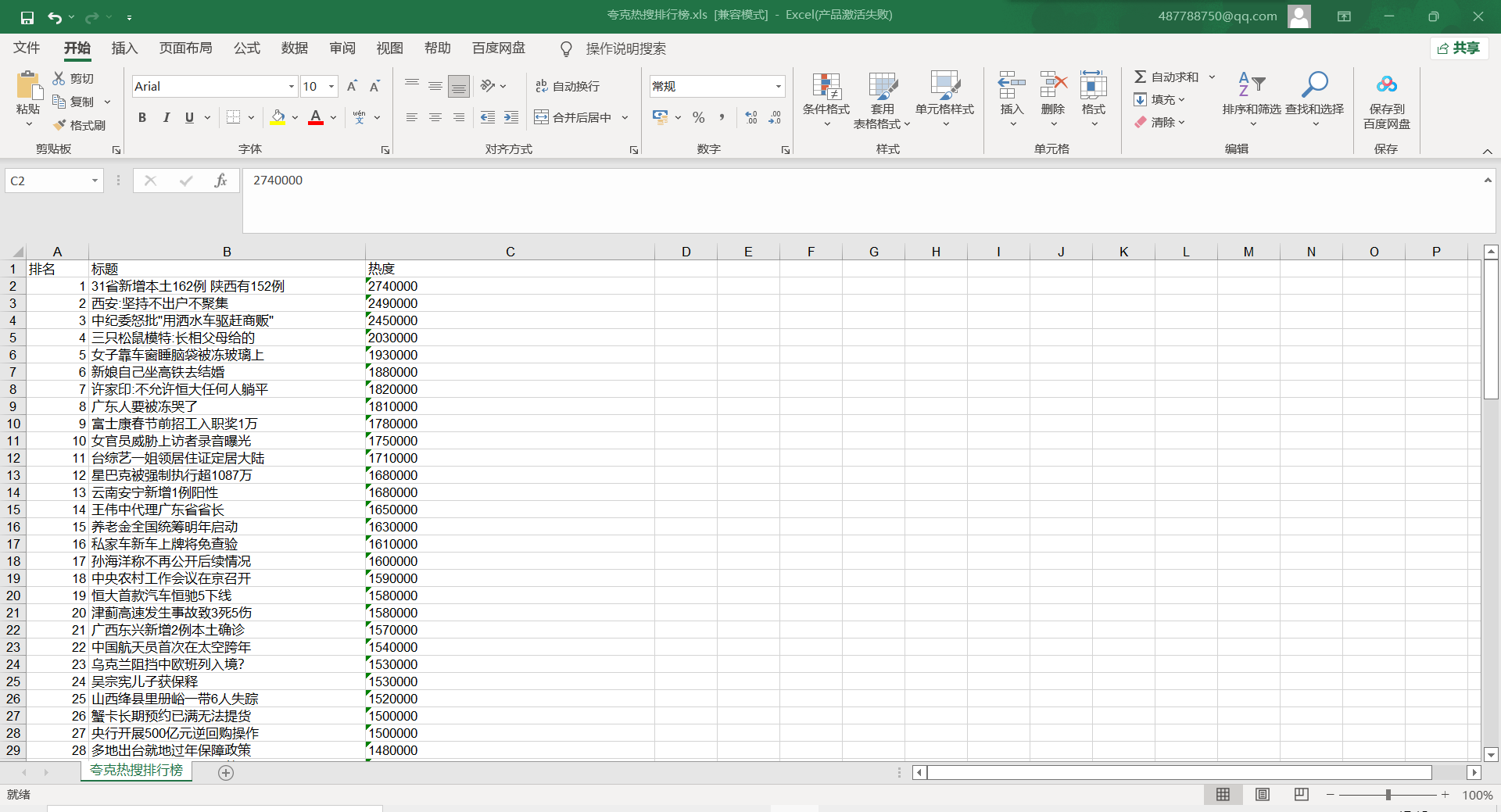
将爬取的数据输入excle
savepath = ".\\夸克热搜排行榜.xls"
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
#创建workbook对象
sheet = book.add_sheet('夸克热搜排行榜',cell_overwrite_ok=True)
#创建工作表
col = ("排名","标题","热度")
for i in range(0,3):
sheet.write(0,i,col[i]) #列名
for i in range(0,100):
#测试 print("第%d条" %(i+1))
data = datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
#数据
book.save(savepath)
print('已输出表格!')
excle输出结果图:
4.数据分析与可视化
#柱形图 import matplotlib.pyplot as plt import pandas as pd import numpy as np kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') data=np.array(zhihu_df['热度'][0:10]) #索引 index=np.arange(1,11) #用来正常显示中文标签 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #用来正常显示负号 plt.rcParams['axes.unicode_minus']=False #修改x轴字体大小为12 plt.xticks(fontsize=12) #修改y轴字体大小为12 plt.yticks(fontsize=12) print(data) print(index) #x标签 plt.xlabel('排名') #y标签 plt.ylabel('热度') s = pd.Series(data, index) s.plot(kind='bar',color='g') plt.grid() plt.show()
输出结果

5.散点图
#散点图、折线图 kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') plt.rcParams['font.sans-serif']=['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False plt.xticks(fontsize=12) plt.yticks(fontsize=12) #散点 plt.scatter(kuake_df.排名, kuake_df.热度,color='b') #折线 plt.plot(kuake_df.排名, kuake_df.热度,color='r') #x标签 plt.xlabel('paiming') #y标签 plt.ylabel('redu') plt.show()

线性回归方程
from sklearn.linear_model import LinearRegression zhihu_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') predict_model=LinearRegression() X=kuake_df[["排名"]] Y=kuake_df["热度"] predict_model.fit(X,Y) print("回归方程系数为{}".format( predict_model.coef_)) print("回归方程截距:{0:2f}".format( predict_model.intercept_))

import matplotlib.pyplot as plt import matplotlib import numpy as np import scipy.optimize as opt kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') x0=np.array(kuake_df['排名'][0:10]) y0=np.array(kuake_df['热度'][0:10]) def func(x,c0): a,b,c=c0 return a*x**2+b*x+c def errfc(c0,x,y): return y-func(x,c0) c0=[0,2,3] c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] a,b,c=c1 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') plt.plot(x0,y0,"ob",label="样本数据") plt.plot(x0,func(x0,c1),"r",label="拟合曲线") plt.legend(loc=3,prop=chinese) plt.show()

7、总代码
1 from bs4 import BeautifulSoup 2 #进行网页解析 3 import re 4 #进行文字匹配 5 import urllib.request,urllib.error 6 #制定URL,获取网页数据 7 import xlwt 8 #进行excel操作 9 import sqlite3 10 #进行SQLite数据库操作 11 12 13 14 def getData(url): 15 datalist = [] 16 html = askURL(url) 17 soup = BeautifulSoup(html,"html.parser") 18 i=1 19 for item in soup.find_all('a', class_="news-top-list-item c-padding-top-l c-border-bottom c-padding-bottom-l"): 20 data = [] 21 item = str(item) 22 23 #测试print(item) 24 25 pm = i 26 i=i+1 27 data.append(pm) 28 29 findbt = re.compile(r'</span>(.*?)<span class="news-top-list-item-number') 30 # 事件名称 31 bt = re.findall(findbt, item)[0] 32 data.append(bt) 33 findrs = re.compile(r'dark">(.*?)<i class="news-top-list-item-trend') 34 #热度人数 35 rs = re.findall(findrs, item)[0].replace("万人", "0000") 36 data.append(rs) 37 datalist.append(data) 38 print(data) 39 #把处理好的信息放入datalist并返回 40 return datalist 41 42 #得到指定的一个URL的网页内容 43 def askURL(url): 44 #模拟浏览器头部信息 45 head = { 46 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 47 } 48 request = urllib.request.Request(url, headers=head) 49 #携带着这个包含着我的设备型号的头部信息去访问这个url 50 51 html = "" 52 #用字符串对它进行存储 53 try: 54 #可能会发生的错误,比如说404等 55 response = urllib.request.urlopen(request) 56 html = response.read().decode("utf-8") 57 except urllib.error.URLError as e: 58 if hasattr(e, "code"): 59 print(e.code) 60 61 if hasattr(e, "reason"): 62 print(e.reason) 63 64 #测试 print(html) 65 return html 66 67 #askURL("https://quark.sm.cn/s?from=kkframenew&predict=1&search_id=AAM0gYl%2BOkyU46PzPXUuYxYWwBPQa8ML6I6ZHAjFAA%2Faew%3D%3D_1640440403736&round_id=-1&pdtt=1640440403&uc_param_str=dnntnwvepffrgibijbprsvpidsdichei&q=%E7%83%AD%E6%90%9C%E6%8E%92%E8%A1%8C%E6%A6%9C&hid=72c443e2f1354914d23bba5bb0635f26") 68 url = ("https://quark.sm.cn/s?from=kkframenew&predict=1&search_id=AAM0gYl%2BOkyU46PzPXUuYxYWwBPQa8ML6I6ZHAjFAA%2Faew%3D%3D_1640440403736&round_id=-1&pdtt=1640440403&uc_param_str=dnntnwvepffrgibijbprsvpidsdichei&q=%E7%83%AD%E6%90%9C%E6%8E%92%E8%A1%8C%E6%A6%9C&hid=72c443e2f1354914d23bba5bb0635f26") 69 html=askURL(url) 70 datalist = getData(url) 71 print(datalist) 72 print("爬取完毕!") 73 savepath = ".\\夸克热搜排行榜.xls" 74 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 75 #创建workbook对象 76 sheet = book.add_sheet('夸克热搜排行榜',cell_overwrite_ok=True) 77 78 #创建工作表 79 col = ("排名","标题","热度") 80 81 for i in range(0,3): 82 sheet.write(0,i,col[i]) #列名 83 84 for i in range(0,100): 85 86 #测试 print("第%d条" %(i+1)) 87 88 data = datalist[i] 89 for j in range(0,3): 90 sheet.write(i+1,j,data[j]) 91 #数据 92 93 book.save(savepath) 94 95 print('已输出表格!') 96 97 98 99 100 101 #柱形图 102 import matplotlib.pyplot as plt 103 104 import pandas as pd 105 106 import numpy as np 107 108 kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') 109 data=np.array(kuake_df['热度'][0:10]) 110 111 #索引 112 index=np.arange(1,11) 113 114 #用来正常显示中文标签 115 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 116 117 #用来正常显示负号 118 plt.rcParams['axes.unicode_minus']=False 119 120 #修改x轴字体大小为12 121 plt.xticks(fontsize=12) 122 123 #修改y轴字体大小为12 124 plt.yticks(fontsize=12) 125 print(data) 126 print(index) 127 128 #x标签 129 plt.xlabel('排名') 130 131 #y标签 132 plt.ylabel('热度') 133 s = pd.Series(data, index) 134 s.plot(kind='bar',color='g') 135 plt.grid() 136 plt.show() 137 138 139 140 141 #散点图、折线图 142 kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') 143 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 144 plt.rcParams['axes.unicode_minus']=False 145 plt.xticks(fontsize=12) 146 plt.yticks(fontsize=12) 147 #散点 148 plt.scatter(kuake_df.排名, kuake_df.热度,color='b') 149 #折线 150 plt.plot(kuake_df.排名, kuake_df.热度,color='r') 151 #x标签 152 plt.xlabel('paiming') 153 #y标签 154 plt.ylabel('redu') 155 plt.show() 156 157 158 from sklearn.linear_model import LinearRegression 159 zhihu_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') 160 predict_model=LinearRegression() 161 X=kuake_df[["排名"]] 162 Y=kuake_df["热度"] 163 predict_model.fit(X,Y) 164 print("回归方程系数为{}".format( predict_model.coef_)) 165 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 166 167 import matplotlib.pyplot as plt 168 import matplotlib 169 import numpy as np 170 import scipy.optimize as opt 171 kuake_df=pd.read_excel(r'C:\Users\86198\夸克热搜排行榜.xls') 172 x0=np.array(kuake_df['排名'][0:10]) 173 y0=np.array(kuake_df['热度'][0:10]) 174 def func(x,c0): 175 a,b,c=c0 176 return a*x**2+b*x+c 177 def errfc(c0,x,y): 178 return y-func(x,c0) 179 c0=[0,2,3] 180 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 181 a,b,c=c1 182 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 183 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 184 plt.plot(x0,y0,"ob",label="样本数据") 185 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 186 plt.legend(loc=3,prop=chinese) 187 plt.show()
五、总结(10分)
1、经过对夸克热搜的数据分析与可视化,我们可以得到大部分人的兴趣爱好是什么,可以得知人们对什么事情感兴趣,大众的关注点是什么,经过俩天的爬取我发现每一天的热搜排行都有着十分大的变化,可能仅仅几个小时的时间就可能会出来一条上百万的热搜新闻。可以达到预期的目标,观测出人们的兴趣爱好,从而帮助那些因为疫情待在家中无聊的人们寻找一些乐趣,以及一些重要的国家大事
2、在完成此设计过程中,我了解到了网络爬虫的一些重要意义,可以帮助我们获取网站中我们所需的内容。对于爬取还是太过于生疏了,并且还有许多网站不会爬,在未来的日子学习更多的知识去扩大自己的知识面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号