数据采集与融合技术实践第四次作业
数据采集与融合技术实践第四次实验
Gitee:https://gitee.com/lululusc/crawl_project/tree/master/作业4
作业①
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
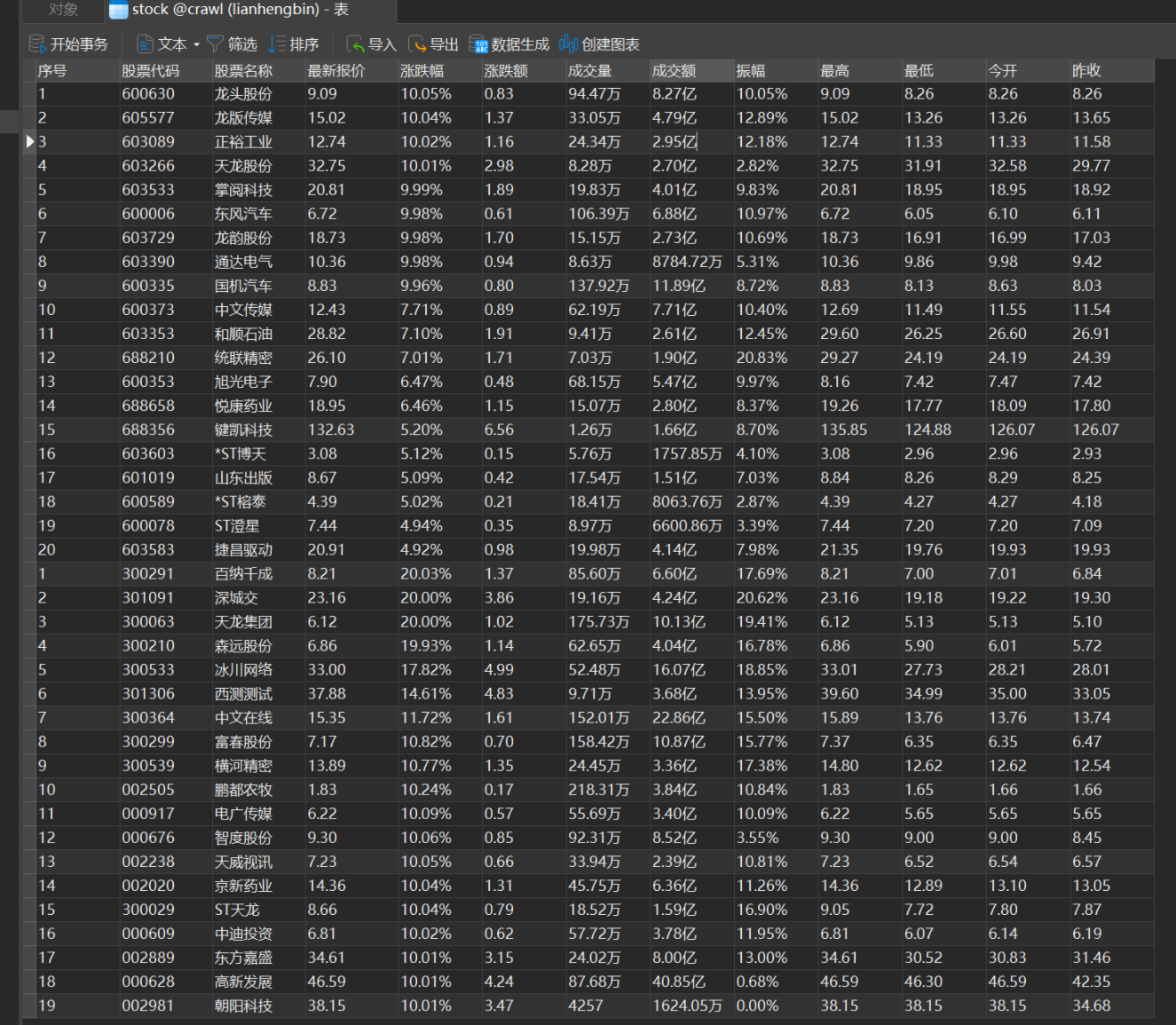
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号 id,股票代码:bStockNo……,由同学们自行定义设计表头:
• Gitee 文件夹链接
输出结果:
代码:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import pymysql
service = ChromeService(path=r"D:\python代码\pythonProject\spider\selenium\chromedriver.exe")
driver = webdriver.Chrome(service=service)
url="http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(url)
mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="crawl"
)
cursor = mydb.cursor()
mydb.commit()
def save_data(i):
stockBotton = driver.find_elements(By.XPATH, "//*[@id=\"tab\"]/ul/li")[i].find_element(By.XPATH,"./a")#换股票
stockBotton.click()#点击股票
driver.refresh()#不刷新会出问题
time.sleep(1)
trs = driver.find_elements(By.XPATH, "//*[@id=\"table_wrapper-table\"]/tbody/tr")
# 1 2 3 4 5 6 7 8 9 10 11 12 13 14
for td in trs:
id = td.find_element(By.XPATH, "./td[1]").text
stock_id = td.find_element(By.XPATH, "./td[2]").text
stock_name = td.find_element(By.XPATH, "./td[3]").text
last_price = td.find_element(By.XPATH, "./td[5]/span").text
rise = td.find_element(By.XPATH, "./td[6]/span").text
rise_extend = td.find_element(By.XPATH, "./td[7]/span").text
exchange = td.find_element(By.XPATH, "./td[8]").text
exchange_extend = td.find_element(By.XPATH, "./td[9]").text
dang = td.find_element(By.XPATH, "./td[10]").text
top = td.find_element(By.XPATH, "./td[11]/span").text
bottom = td.find_element(By.XPATH, "./td[12]/span").text
today = td.find_element(By.XPATH, "./td[13]/span").text
yesday = td.find_element(By.XPATH, "./td[14]").text
cursor.execute("INSERT INTO stock VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (
id, stock_id, stock_name, last_price, rise, rise_extend, exchange, exchange_extend, dang, top, bottom, today,yesday))
mydb.commit()
for i in range(1,5):
save_data(i)
实验心得
复盘了selenium的使用方法,和mysql的连接过程。
作业②:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国 mooc 网:https://www.icourse163.org
o 输出信息:MYSQL 数据库存储和输出格式
•Gitee 文件夹链接:
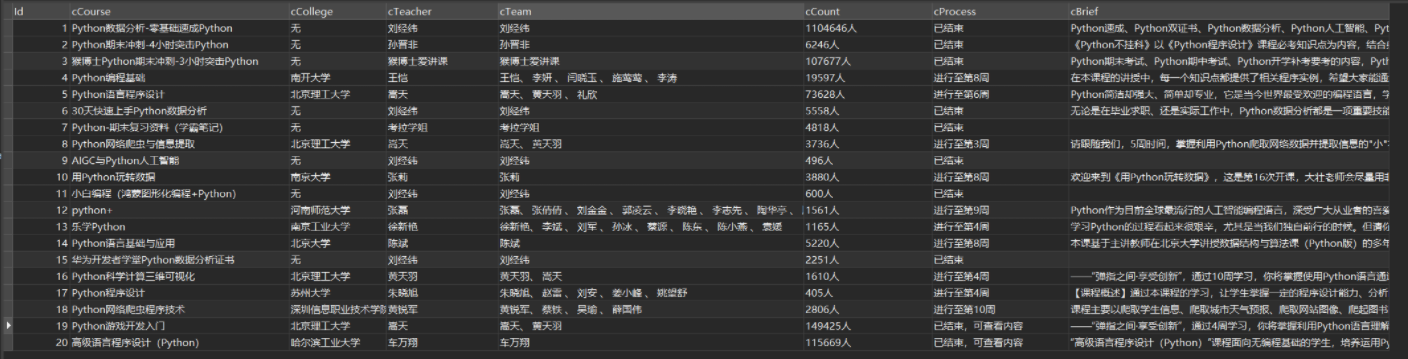
结果
控制台输出结果

Navicat查看结果
代码
连接数据库
from selenium.webdriver.chrome.service import Service as ChromeService
service = ChromeService(path=r"D:\python代码\pythonProject\spider\selenium\chromedriver.exe")
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pymysql
mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="crawl"
)
cursor = mydb.cursor()
登录账号
driver = webdriver.Chrome(service=service)
url = 'https://www.icourse163.org/'
driver.get(url)
time.sleep(3)
sign=driver.find_element(By.XPATH,'//div[@class="_3uWA6"]')#登录按钮
sign.click()
time.sleep(5)
driver.switch_to.frame(driver.find_elements(By.TAG_NAME,'iframe')[0])#转换到内层
time.sleep(5)
phone=driver.find_element(By.XPATH,'//input[@id="phoneipt"]')#登录框
phone.clear()
phone.send_keys("输入自己的账号")
time.sleep(3)
password=driver.find_element(By.XPATH,'//input[@placeholder="请输入密码"]')
password.clear()
password.send_keys("输入自己的密码")
deng=driver.find_element(By.XPATH,'//*[@id="submitBtn"]')
deng.click()
time.sleep(15)
driver.switch_to.default_content()
#driver.refresh()
获取数据
# #搜索
select_course=driver.find_element(By.XPATH,'//*[@name="search"]')
select_course.send_keys("python")
dianji=driver.find_element(By.XPATH,'//span[@data-track="首页-点击搜索框-w"]')
dianji.click()
time.sleep(3)
# driver.refresh()不要这步!
rows = driver.find_elements(By.XPATH,"//div[@class='m-course-list']/div/div")
print(rows)
Id=0
time.sleep(5)
for row in rows:
Id=Id+1
cCourse= row.find_element(By.XPATH,".//span[@class=\" u-course-name f-thide\"]").text
# course_string="".join(course)
all_college_teather_team=row.find_element(By.XPATH,".//div[@class=\"t2 f-fc3 f-nowrp f-f0\"]")#集合体
try:
cCollege=all_college_teather_team.find_element(By.XPATH,"./a[@class='t21 f-fc9']").text
except:
cCollege="无"
cTeacher=all_college_teather_team.find_element(By.XPATH,".//a[@class='f-fc9']").text
try:
cTeam = all_college_teather_team.find_element(By.XPATH,"./span[@class=\"f-fc9\"]").text
cTeam=cTeacher+cTeam
except:
cTeam=cTeacher
# team_string=",".join(team)
cCount = row.find_element(By.XPATH,".//span[@class='hot']").text.replace("参加","")
try:
cProcess = row.find_element(By.XPATH,".//span[@class='txt']").text
except:
cProcess="已结束"
try:
cBrief=row.find_element(By.XPATH,".//span[@class='p5 brief f-ib f-f0 f-cb']").text
except:
cBrief="无"
# jianjie_string=",".join(jianjie)
print(Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
cursor.execute("INSERT INTO mooc VALUES (%s,%s,%s,%s,%s,%s,%s,%s)", (Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief))
mydb.commit()
mydb.close()
driver.quit()
实验心得
知道了在登录的时候还有个iframe,要先转到内层,然后再抓。
作业 ③ :
o 要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
• 环境搭建:
·任务一:开通 MapReduce 服务
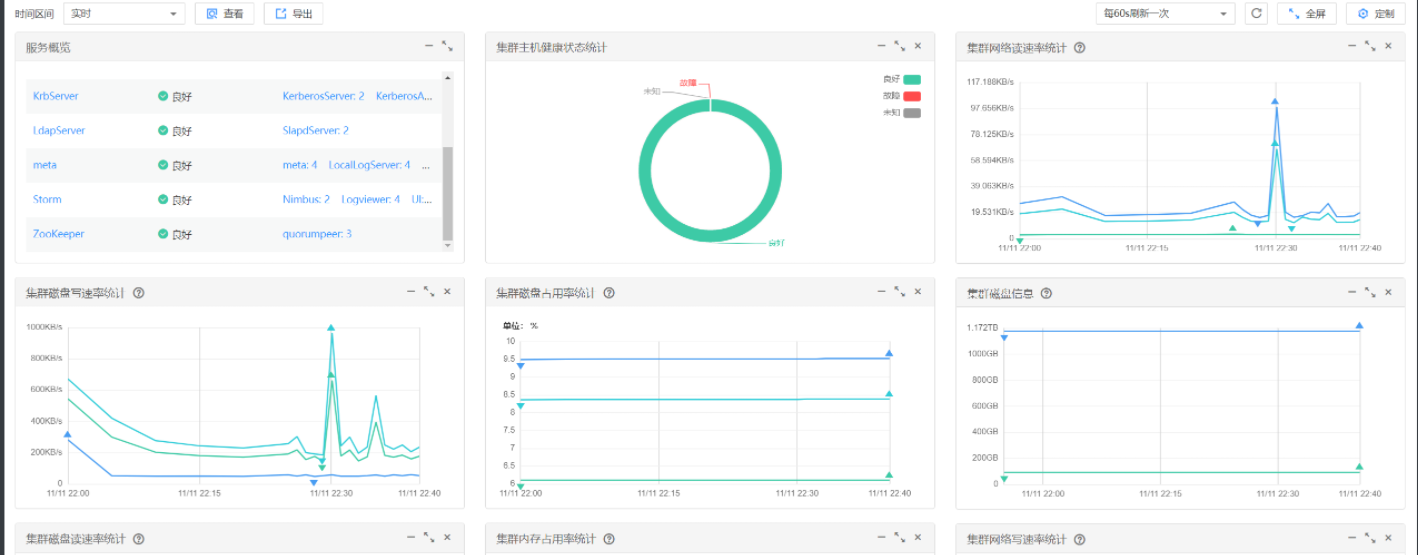
• 实时分析开发实战****:
·任务一:Python 脚本生成测试数据
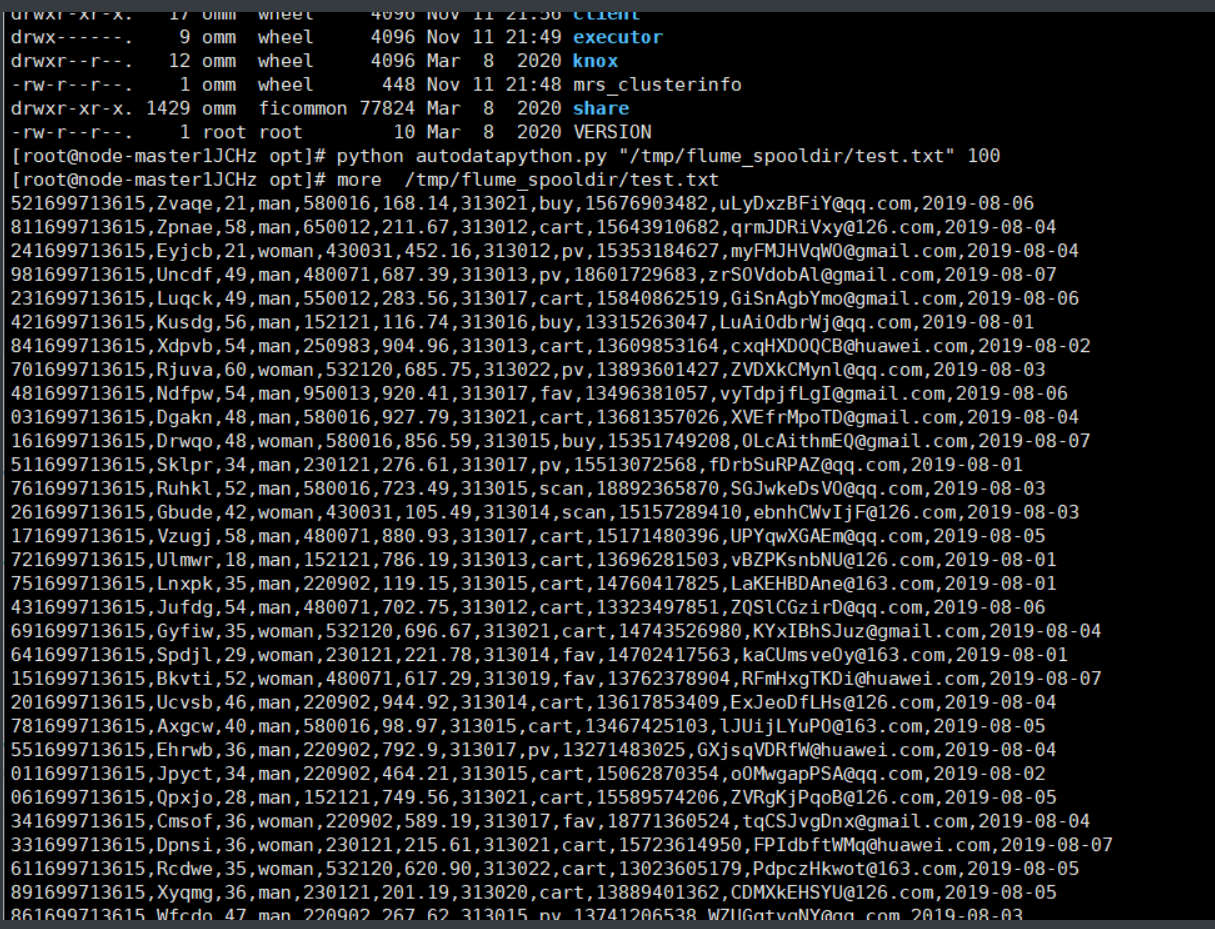
·任务二:配置 Kafka
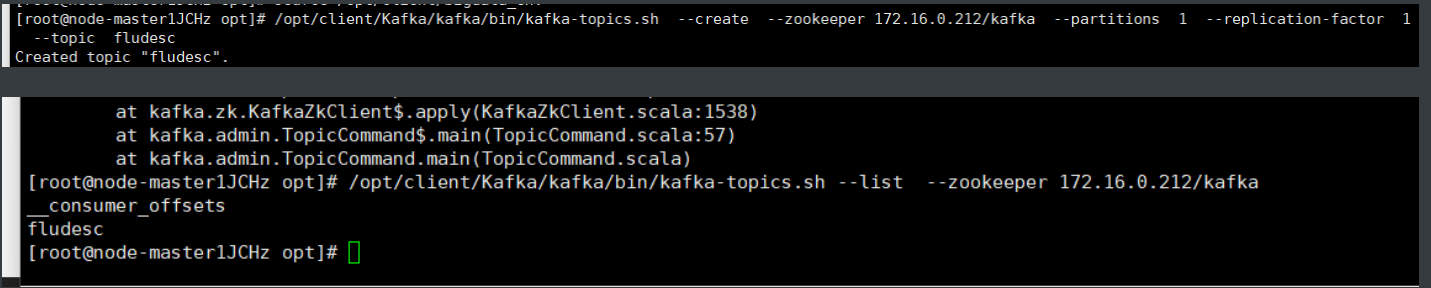
三: 安装 Flume 客户端
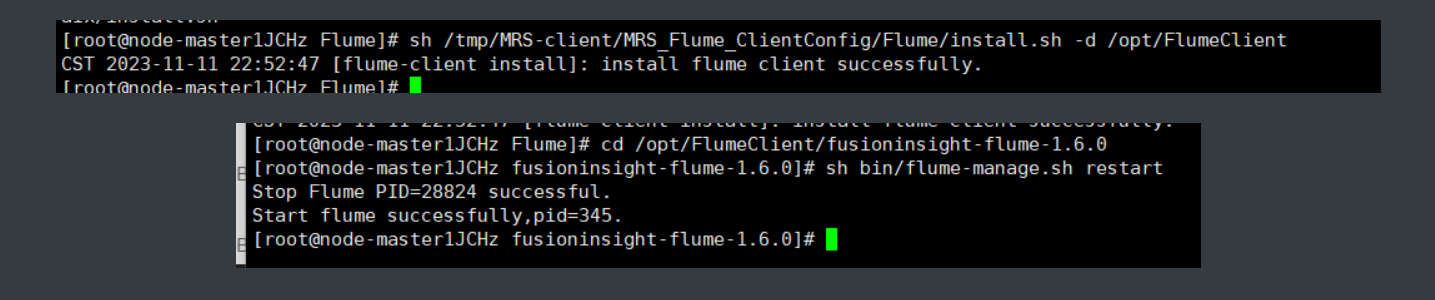
·任务四:配置 Flume 采集数据

实验心得:
了解到了华为云服务器配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号