
数据采集与融合技术实践第三次实验
数据采集与融合技术实践第三次实验
Gitee:https://gitee.com/lululusc/crawl_project/tree/master/作业3
作业1
要求
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn/(要求:指定--个网站,爬取这个网站中的所有的所有图片,例如中国气象网)
结果
url信息
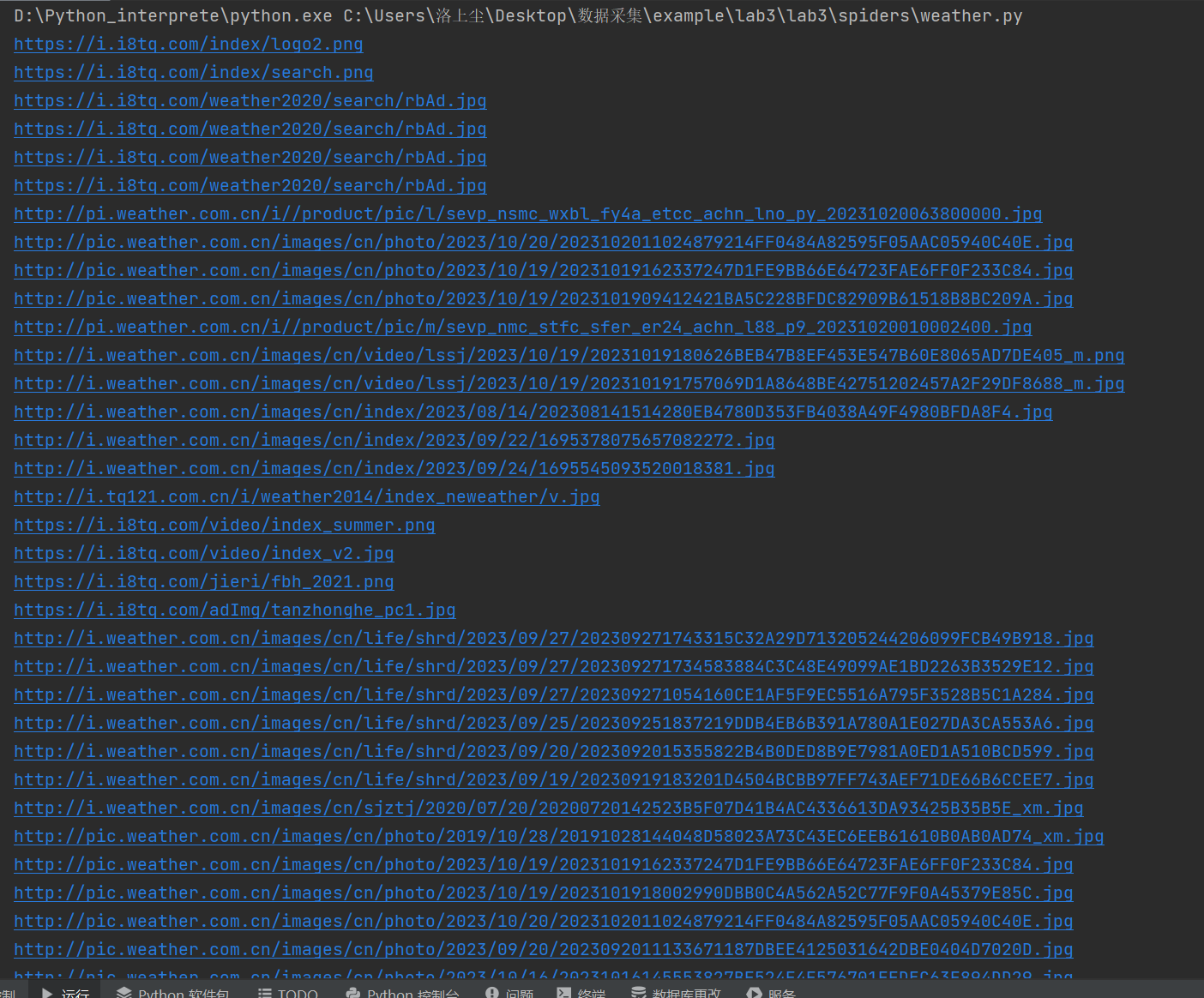
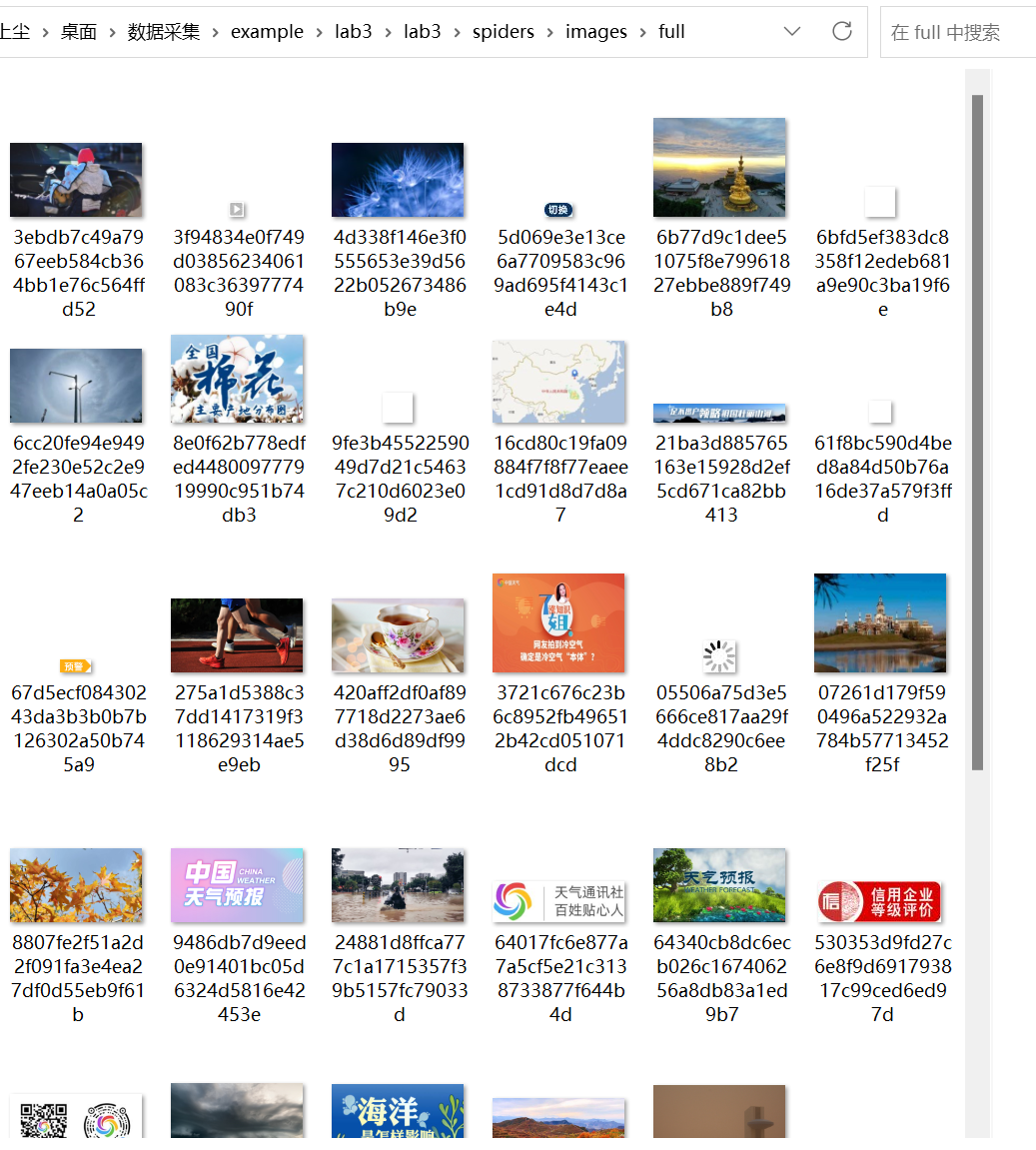
图片信息
代码
单线程爬取
这个代码主要是异步执行提高速度的,在pipeline中,使用yield来提交Request请求。
weather.py
class WeatherSpider(scrapy.Spider):
name = "weather"
allowed_domains = ["www.weather.com.cn"]
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
try:
imags=response.xpath("//img/@src").extract()
for img_url in imags:
weather_img = Lab3Item()
weather_img['Img_url']=img_url
yield weather_img
except Exception as err:
print(err)
cmdline.execute("scrapy crawl weather -s LOG_ENABLED=False".split())
items
class Lab3Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Img_url = scrapy.Field()
pipelines
class Lab3Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
print(item.get('Img_url'))
req_url= item.get('Img_url')
yield Request(req_url)#异步执行
def file_path(self, request, response=None, info=None,item=None):
image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
return f'full/{image_guid}.jpg'
def item_completed(self, results, item, info):
return item
多线程爬取
在settings中设置
CONCURRENT_REQUESTS = 32
心得
熟悉掌握了多线程与单线程爬取数据
作业2
要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。 候选网站:
东方财富网: https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
结果
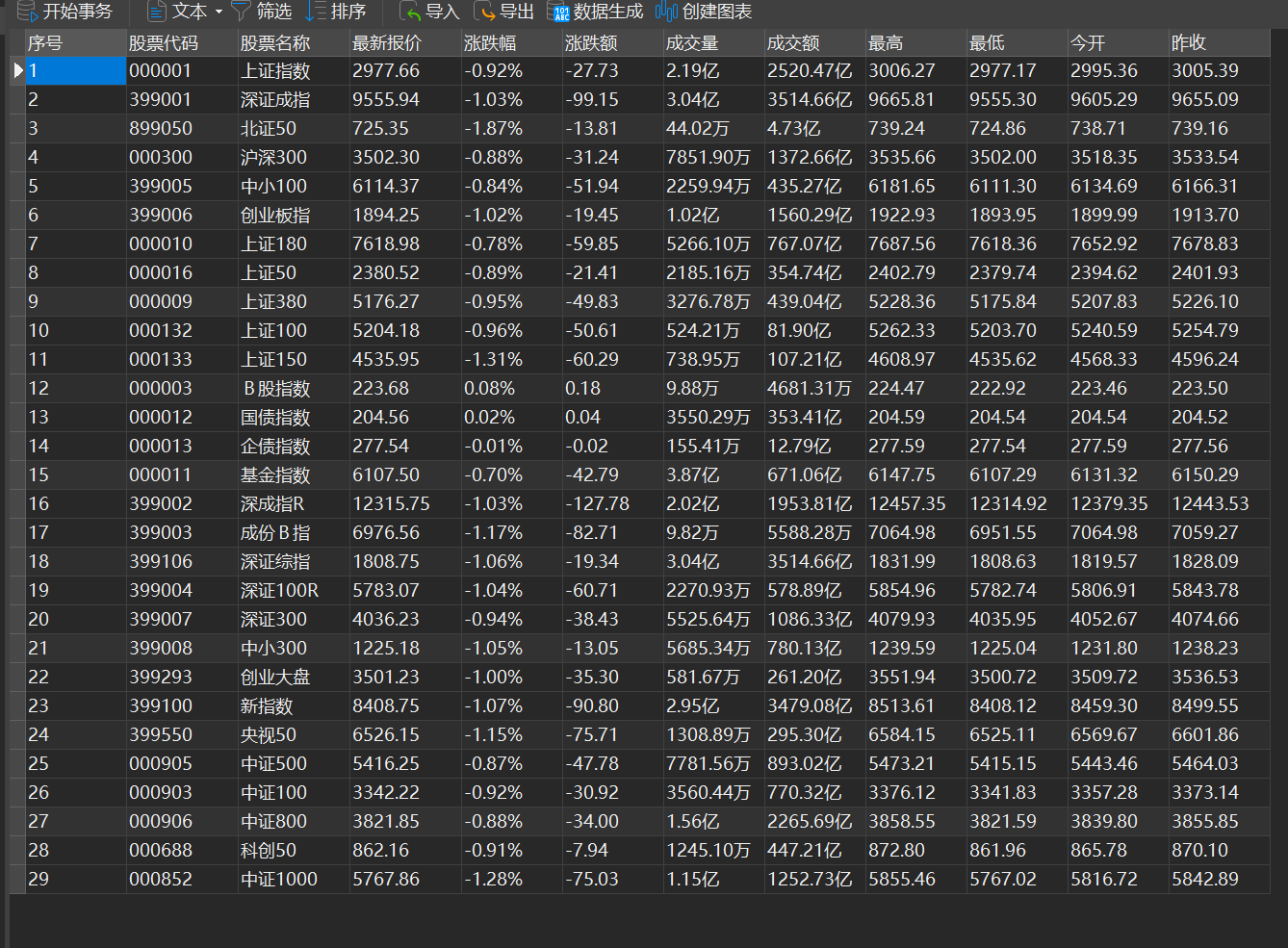
代码
这次代码使用了selenium+scrapy+xpath抓取,因为页面是动态数据,只用scrapy无法获取。
使用selenium主要是修改了middlewares
1.重写了_init__
def __init__(self):
service = ChromeService(executable_path=r'C:\Users\洛上尘\Desktop\数据采集\example\lab3_2\lab3_2\spiders\chromedriver.exe')
self.driver = webdriver.Chrome(service=service)
2.重写process_request
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
self.driver.get(request.url)
body=self.driver.page_source
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return HtmlResponse(url=self.driver.current_url, body=body, encoding='utf-8', request=request)
在stock.py
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["quote.eastmoney.com"]
start_urls = ["https://quote.eastmoney.com/center/hszs.html"]
def parse(self, response,**kwargs):
lines=response.xpath("//table[@id=\"hszs_hszyzs_simple-table\"]/tbody/tr")
item=Lab32Item()
for line in lines:
item['a1']=line.xpath("./td[1]/text()").extract_first()
item['a2']= line.xpath("./td[2]/a/text()").extract_first()
item['a3']= line.xpath("./td[3]/a/text()").extract_first()
item['a4']= line.xpath("./td[4]/span/text()").extract_first()
item['a5']= line.xpath("./td[5]/span/text()").extract_first()
item['a6']= line.xpath("./td[6]/span/text()").extract_first()
item['a7']= line.xpath("./td[7]/text()").extract_first()
item['a8']= line.xpath("./td[8]/text()").extract_first()
item['a9']= line.xpath("./td[9]/text()").extract_first()
item['a10']= line.xpath("./td[10]/span/text()").extract_first()
item['a11']= line.xpath("./td[11]/span/text()").extract_first()
item['a12']= line.xpath("./td[12]/span/text()").extract_first()
yield item
cmdline.execute("scrapy crawl stock -s LOG_ENABLED=True".split())
items
class Lab32Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
a1 =scrapy.Field()
a2 =scrapy.Field()
a3 =scrapy.Field()
a4 =scrapy.Field()
a5 =scrapy.Field()
a6 =scrapy.Field()
a7=scrapy.Field()
a8=scrapy.Field()
a9 =scrapy.Field()
a10 =scrapy.Field()
a11=scrapy.Field()
a12=scrapy.Field()
pipelines
class Lab32Pipeline:
def open_spider(self,spider):
print("*******************************************")
print("opened_爬取1")
self.mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="crawl",
charset="utf8"
)
self.cursor = self.mydb.cursor()
def process_item(self, item, spider):
sql="insert into stock values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item.get("a1"),item.get("a2"),item.get("a3"),item.get("a4"),item.get("a6"),item.get("a5"),item.get("a7"),item.get("a8"),item.get("a11"),item.get("a12"),item.get("a10"),item.get("a9")))
self.mydb.commit()
return item
def close_spider(self,spider):
self.mydb.close()
心得
学会了如何将selenium与scrapy结合起来爬取数据,收获颇多
作业3
要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:https://www.boc.cn/sourcedb/whpj/
结果
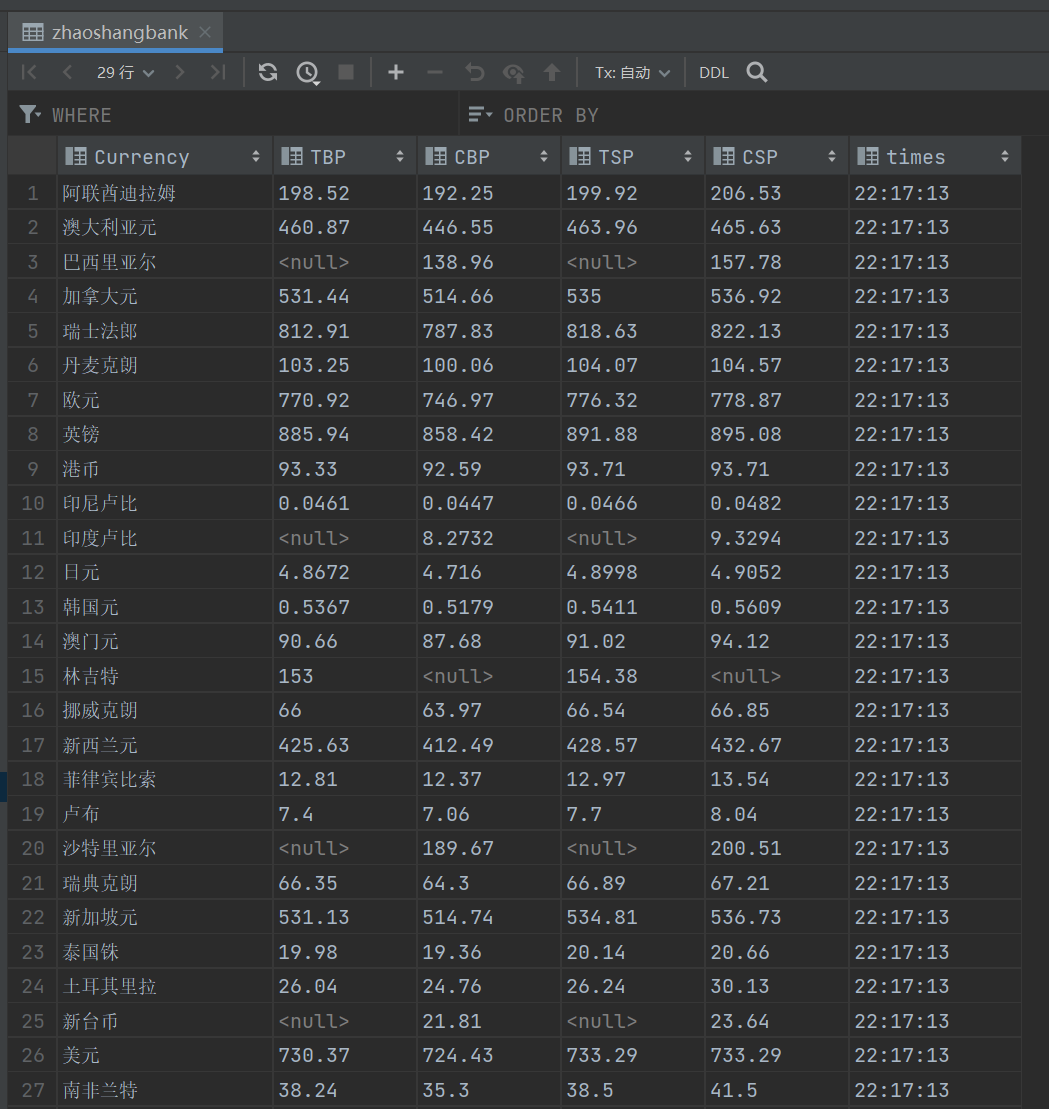
代码
在zhaoshangbank(myspider)里
class ZhaoshangbankSpider(scrapy.Spider):
name = "zhaoshangbank"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
trs=response.xpath("//tr")
trs=trs[2:]
item=Lab33Item()
for tr in trs:
item['name']=tr.xpath("./td[1]/text()").extract_first()
item['tsp']= tr.xpath("./td[2]/text()").extract_first()
item['csp']= tr.xpath("./td[3]/text()").extract_first()
item['tbp']= tr.xpath("./td[4]/text() ").extract_first()
item['cbp']= tr.xpath("./td[5]/text()").extract_first()
item['time']= tr.xpath("./td[8]/text()").extract_first()
print(item.get("name"))
#yield item
cmdline.execute("scrapy crawl zhaoshangbank -s LOG_ENABLED=False".split())
items
class Lab33Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name=scrapy.Field()
tsp=scrapy.Field()
csp=scrapy.Field()
tbp=scrapy.Field()
cbp=scrapy.Field()
time=scrapy.Field()
pipelines
class Lab33Pipeline:
def open_spider(self,spider):
self.mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="crawl",
charset='utf8'
)
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS zhaoshangbank
(Currency VARCHAR(256),
TBP VARCHAR(256),
CBP VARCHAR(256),
TSP VARCHAR(256),
CSP VARCHAR(256),
times VARCHAR(256)
)''')
self.mydb.commit()
def process_item(self, item, spider):
print(item.get("name"))
sql="INSERT INTO zhaoshangbank (Currency,TBP,CBP,TSP,CSP,times) VALUES (%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item.get("name"),item.get("tsp"),item.get("csp"),item.get("tbp"),item.get("cbp"),item.get("time")))
self.mydb.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.mydb.close()
心得
这次实验让我懂得了如何利用scrapy+mysql存储数据,更加熟练得操作了mysql,也知道了xpath绝对定位有时候会出错,最好使用迷糊匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号