
数据采集与融合技术实践第二次实验
代码放在码云:https://gitee.com/lululusc/crawl_project/tree/master/作业2
第二次作业
作业一
要求:在中国气象网给定城市集的7日天气预报,并保存在数据库。
代码如下:
from bs4 import BeautifulSoup
import requests
import pandas as pd
from sqlalchemy import create_engine
class PDTOMYSQL:#pandas dataframe数据直接加载到mysql中
def __init__(self,host,user,pasword,db,tb,df,port='3306'):
self.host = host
self.user = user
self.port = port
self.db = db
self.password = pasword
self.tb = tb
self.df = df
sql = 'select * from '+self.tb
conn = create_engine('mysql+pymysql://'+self.user+':'+self.password+'@'+self.host+':'+self.port+'/'+self.db)
df.to_sql(self.tb, con=conn, if_exists='replace')
self.pdata = pd.read_sql(sql,conn)
def show(self):#显示数据集
return print(self.pdata)
url="http://www.weather.com.cn/weather/101131406.shtml"
headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36"}
response=requests.get(url)
response.encoding = response.apparent_encoding
data=response.text
# print(data)
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
def get_data(date,weather,temp,count):
return (i,'北京',data,weather,temp)
i=1
d=[]
for li in lis:
try:
date=li.select("h1")[0].text
weather=li.select("p[class='wea']")[0].text
temp=li.select("p[class='tem']")[0].text.strip("\n")
d.append((i,'北京',date,weather,temp))
#print(date,weather," ",temp)
i=i+1
except Exception as err:
print(err)
columns=['序号','地区','日期','天气信息','温度']
df=pd.DataFrame(data=d,columns=columns)
t=PDTOMYSQL(
host='127.0.0.1',
port='3306',
user="root",
pasword="123456",
db="crawl",
tb="test1",
df=df
)
t.show()
结果
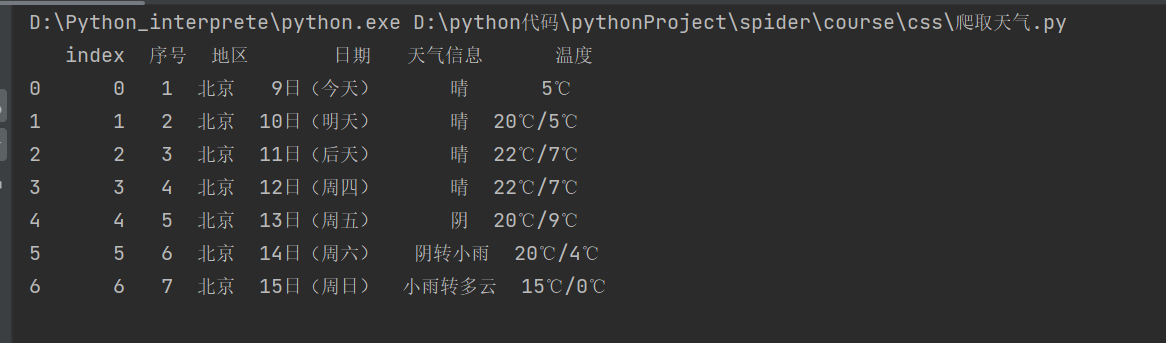
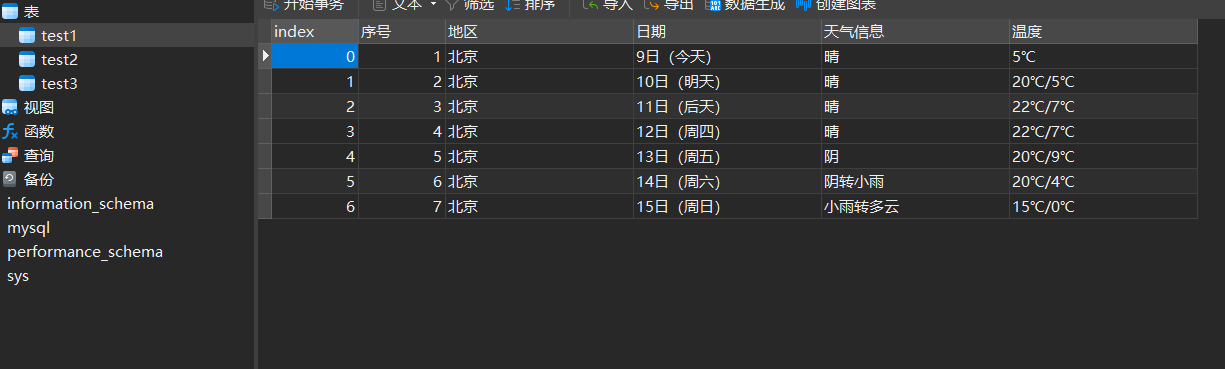
通过数据库可视化工具navicat查看数据库
作业二
要求:
用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/新浪股票:http://finance.sina.com.cn/stock/
输出格式:
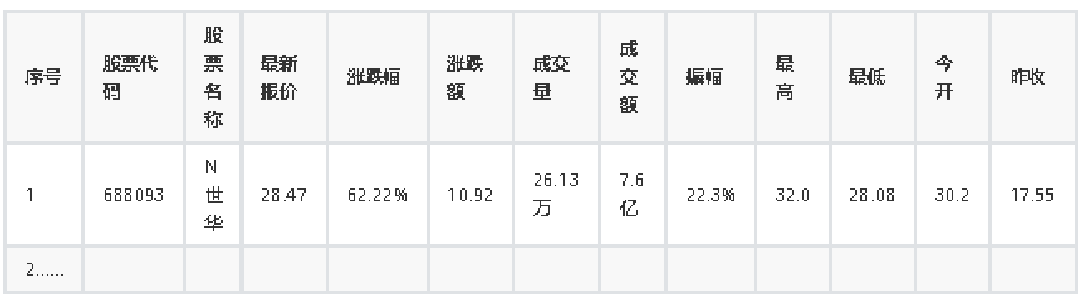
代码如下****:
import bs4
from bs4 import BeautifulSoup
import re
import requests
import pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
import pandas as pd
class PDTOMYSQL:#pandas dataframe数据直接加载到mysql中
def __init__(self,host,user,pasword,db,tb,df,port='3306'):
self.host = host
self.user = user
self.port = port
self.db = db
self.password = pasword
self.tb = tb
self.df = df
sql = 'select * from '+self.tb
conn = create_engine('mysql+pymysql://'+self.user+':'+self.password+'@'+self.host+':'+self.port+'/'+self.db)
df.to_sql(self.tb, con=conn, if_exists='replace')
self.pdata = pd.read_sql(sql,conn)
def show(self):#显示数据集
return print(self.pdata)
def get_df(i,j):
start_url = 'http://30.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405322192635811369_1696661803027&pn='+str(i)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs='+ j +'&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696661803028'
html=requests.get(start_url)
html.encoding=html.apparent_encoding
data=html.text
d=get_data(data)
return d
def get_data(data):
pat = "\"diff\":\[(.*?)\]"
n_data = re.compile(pat, re.S).findall(data)
n_data[0] = n_data[0] + ','
dict_data = []
n = n_data[0].split('},')
n.pop()
for i in range(len(n)):
n[i] = n[i] + '}'
dict_data.append(json.loads(n[i]))
d = []
k = 0
for i in range(len(dict_data)):
dd = []
dd.append(k)
k = k + 1
for j in ["f12", "f14", "f2", "f25", "f4", "f5", "f6", "f7", "f15", "f16", "f17", "f18"]:
dd.append(dict_data[i][j])
d.append(dd)
return d
data=[]
col = {
"沪深京A股":"m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"北证A股":"m:0+t:81+s:2048",
"上证A股票":"m:1+t:2,m:1+t:23"
}#用三个举个例子
cool=input("输入想要爬取的股票:")
for i in range(1,30):#爬取的页面
data=data+get_df(i,col[cool])
df=pd.DataFrame(data)
columns = {0:"序号",1:"代码",2:'名称',3:"最新价格",4:"涨跌幅",5:"涨跌额",6:"成交量",7:"成交额",8:"振幅",9:"最高",10:"最低",11:"今开",12:"昨收"}
df.rename(columns = columns,inplace=True)
t=PDTOMYSQL(
host='127.0.0.1',
port='3306',
user="root",
pasword="123456",
db="crawl",
tb="test2",
df=df
)
t.show()
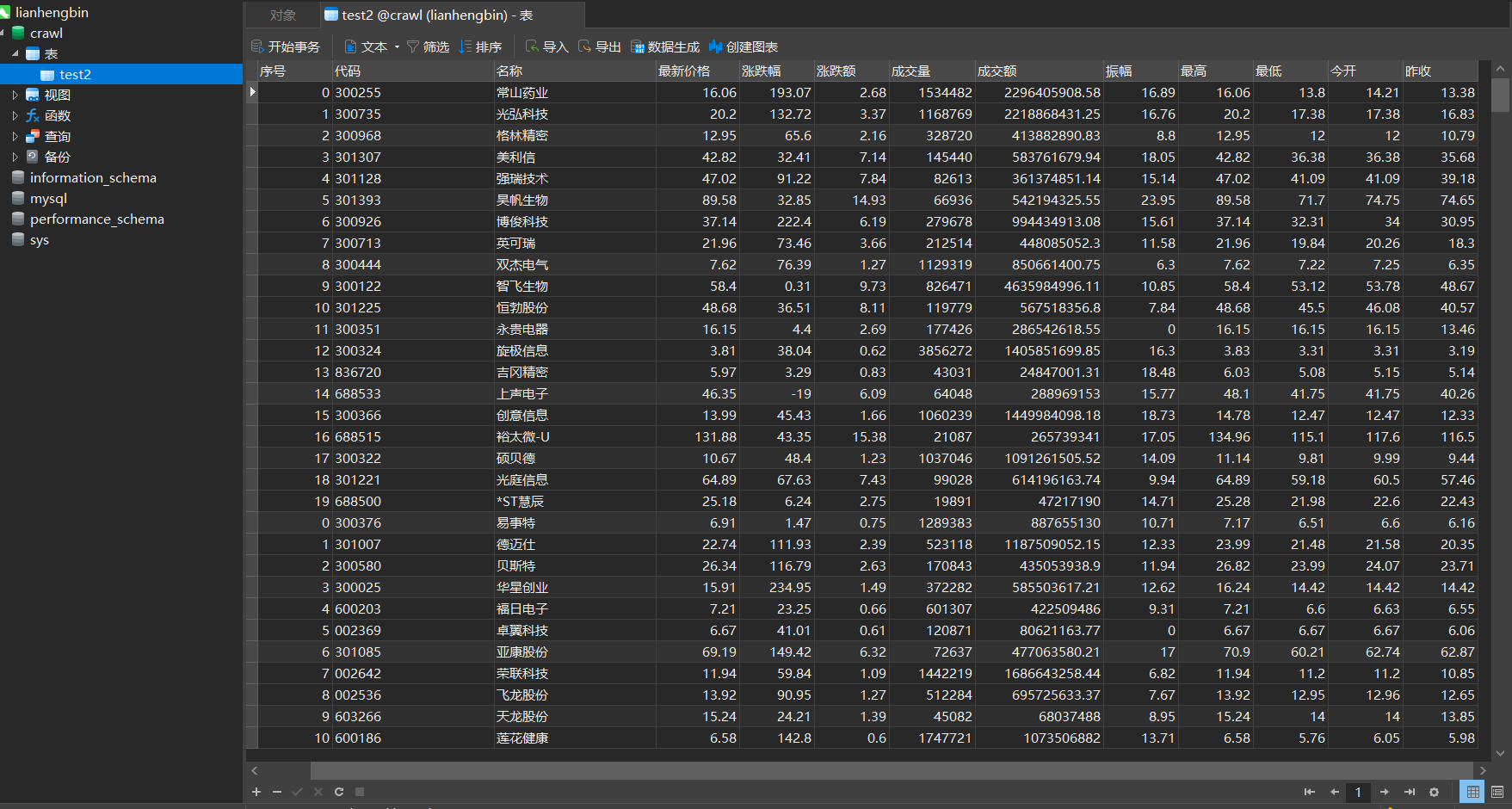
结果:
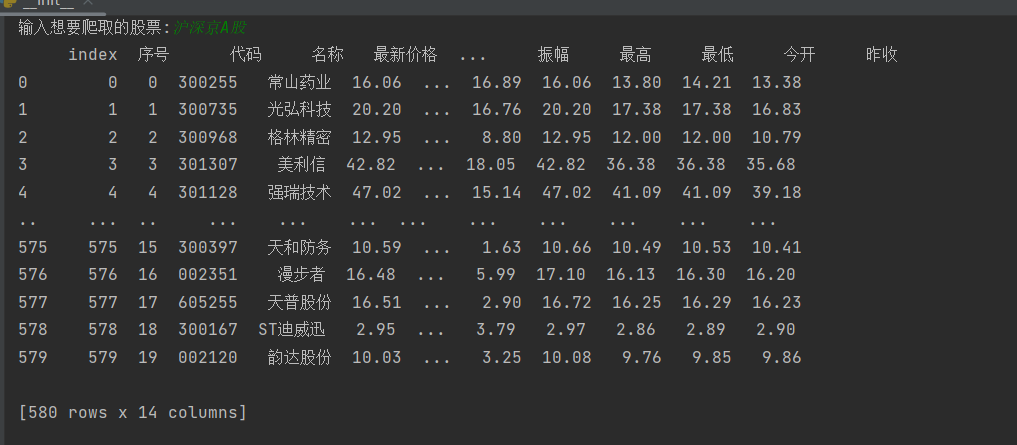
通过数据库可视化工具navicat查看数据库
作业三
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。技巧:分析该网站的发包情况,分析获取数据的api
输出格式:

gif动图分析

代码如下:
本次代码存入数据库部分直接调用了自己写的类,可以参考前两题
import json
import requests
import pandas as pd
import re
from PDTONYSQL import PDTOMYSQL
start_url='https://www.shanghairanking.cn/_nuxt/static/1695811954/rankings/bcur/2021/payload.js'
rep=requests.get(start_url)
rep.encoding=rep.apparent_encoding
js=rep.text
function='a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,_,$,aa,ab,ac,ad,ae,af,ag,ah,ai,aj,ak,al,am,an,ao,ap,aq,ar,as,at,au,av,aw,ax,ay,az,aA,aB,aC,aD,aE,aF,aG,aH,aI,aJ,aK,aL,aM,aN,aO,aP,aQ,aR,aS,aT,aU,aV,aW,aX,aY,aZ,a_,a$,ba,bb,bc,bd,be,bf,bg,bh,bi,bj,bk,bl,bm,bn,bo,bp,bq,br,bs,bt,bu,bv,bw,bx,by,bz,bA,bB,bC,bD,bE,bF,bG,bH,bI,bJ,bK,bL,bM,bN,bO,bP,bQ,bR,bS,bT,bU,bV,bW,bX,bY,bZ,b_,b$,ca,cb,cc,cd,ce,cf,cg,ch,ci,cj,ck,cl,cm,cn,co,cp,cq,cr,cs,ct,cu,cv,cw,cx,cy,cz,cA,cB,cC,cD,cE,cF,cG,cH,cI,cJ,cK,cL,cM,cN,cO,cP,cQ,cR,cS,cT,cU,cV,cW,cX,cY,cZ,c_,c$,da,db,dc,dd,de,df,dg,dh,di,dj,dk,dl,dm,dn,do0,dp,dq,dr,ds,dt,du,dv,dw,dx,dy,dz,dA,dB,dC,dD,dE,dF,dG,dH,dI,dJ,dK,dL,dM,dN,dO,dP,dQ,dR,dS,dT,dU,dV,dW,dX,dY,dZ,d_,d$,ea,eb,ec,ed,ee,ef,eg,eh,ei,ej,ek,el,em,en,eo,ep,eq,er,es,et,eu,ev,ew,ex,ey,ez,eA,eB,eC,eD,eE,eF,eG,eH,eI,eJ,eK,eL,eM,eN,eO,eP,eQ,eR,eS,eT,eU,eV,eW,eX,eY,eZ,e_,e$,fa,fb,fc,fd,fe,ff,fg,fh,fi,fj,fk,fl,fm,fn,fo,fp,fq,fr,fs,ft,fu,fv,fw,fx,fy,fz,fA,fB,fC,fD,fE,fF,fG,fH,fI,fJ,fK,fL,fM,fN,fO,fP,fQ,fR,fS,fT,fU,fV,fW,fX,fY,fZ,f_,f$,ga,gb,gc,gd,ge,gf,gg,gh,gi,gj,gk,gl,gm,gn,go,gp,gq,gr,gs,gt,gu,gv,gw,gx,gy,gz,gA,gB,gC,gD,gE,gF,gG,gH,gI,gJ,gK,gL,gM,gN,gO,gP,gQ,gR,gS,gT,gU,gV,gW,gX,gY,gZ,g_,g$,ha,hb,hc,hd,he,hf,hg,hh,hi,hj,hk,hl,hm,hn,ho,hp,hq,hr,hs,ht,hu,hv,hw,hx,hy,hz,hA,hB,hC,hD,hE,hF,hG,hH,hI,hJ,hK,hL,hM,hN,hO,hP,hQ,hR,hS,hT,hU,hV,hW,hX,hY,hZ,h_,h$,ia,ib,ic,id,ie,if0,ig,ih,ii,ij,ik,il,im,in0,io,ip,iq,ir,is,it,iu,iv,iw,ix,iy,iz,iA,iB,iC,iD,iE,iF,iG,iH,iI,iJ,iK,iL,iM,iN,iO,iP,iQ,iR,iS,iT,iU,iV,iW,iX,iY,iZ,i_,i$,ja,jb,jc,jd,je,jf,jg,jh,ji,jj,jk,jl,jm,jn,jo,jp,jq,jr,js,jt,ju,jv,jw,jx,jy,jz,jA,jB,jC,jD,jE,jF,jG,jH,jI,jJ,jK,jL,jM,jN,jO,jP,jQ,jR,jS,jT,jU,jV,jW,jX,jY,jZ,j_,j$,ka,kb,kc,kd,ke,kf,kg,kh,ki,kj,kk,kl,km,kn,ko,kp,kq,kr,ks,kt,ku,kv,kw,kx,ky,kz,kA,kB,kC,kD,kE,kF,kG,kH,kI,kJ,kK,kL,kM,kN,kO,kP,kQ,kR,kS,kT,kU,kV,kW,kX,kY,kZ,k_,k$,la,lb,lc,ld,le,lf,lg,lh,li,lj,lk,ll,lm,ln,lo,lp,lq,lr,ls,lt,lu,lv,lw,lx,ly,lz,lA,lB,lC,lD,lE,lF,lG,lH,lI,lJ,lK,lL,lM,lN,lO,lP,lQ,lR,lS,lT,lU,lV,lW,lX,lY,lZ,l_,l$,ma,mb,mc,md,me,mf,mg,mh,mi,mj,mk,ml,mm,mn,mo,mp,mq,mr,ms,mt,mu,mv,mw,mx,my,mz,mA,mB,mC,mD,mE,mF,mG,mH,mI,mJ,mK,mL,mM,mN,mO,mP,mQ,mR,mS,mT,mU,mV,mW,mX,mY,mZ,m_,m$,na,nb,nc,nd,ne,nf,ng,nh,ni,nj,nk,nl,nm,nn,no,np,nq,nr,ns,nt,nu,nv,nw,nx,ny,nz,nA,nB,nC,nD,nE,nF,nG,nH,nI,nJ,nK,nL,nM,nN,nO,nP,nQ,nR,nS,nT,nU,nV,nW,nX,nY,nZ,n_,n$,oa,ob,oc,od,oe,of,og,oh,oi,oj,ok,ol,om,on,oo,op,oq,or,os,ot,ou,ov,ow,ox,oy,oz,oA,oB,oC,oD,oE,oF,oG,oH,oI,oJ,oK,oL,oM,oN,oO,oP,oQ,oR,oS,oT,oU,oV,oW,oX,oY,oZ,o_,o$,pa,pb,pc,pd,pe,pf,pg,ph,pi,pj,pk,pl,pm,pn,po,pp,pq,pr,ps,pt,pu,pv,pw,px,py,pz,pA,pB,pC'
functions=function.split(",")
province_category='"",false,null,0,"理工","综合",true,"师范","双一流","211","江苏","985","农业","山东","河南","河北","北京","辽宁","陕西","四川","广东","湖北","湖南","浙江","安徽","江西","黑龙江","吉林","上海","福建","山西","云南","广西",2,"贵州","甘肃","内蒙古","重庆","天津","新疆","2023-01-05T00:00:00+08:00","467","496",1,"2023,2022,2021,2020","林业","5.8","533","23.1","7.3","海南","37.9","28.0","4.3","12.1","16.8","11.7","3.7","4.6","297","397","21.8","32.2","16.6","37.6","24.6","13.6","13.9","3.3","5.2","8.1","3.9","5.1","5.6","5.4","2.6","162",93.5,89.4,11,14,10,13,"宁夏","青海","西藏","11.3","35.2","9.5","35.0","32.7","23.7","33.2","9.2","30.6","8.5","22.7","26.3","8.0","10.9","26.0","3.2","6.8","5.7","13.8","6.5","5.5","5.0","13.2","13.3","15.6","18.3","3.0","21.3","12.0","22.8","3.6","3.4","3.5","95","109","117","129","138","147","159","185","191","193","196","213","232","237","240","267","275","301","309","314","318","332","334","339","341","354","365","371","378","384","388","403","416","418","420","423","430","438","444","449","452","457","461","465","474","477","485","487","491","501","508","513","518","522","528",83.4,"538","555",2021,5,"12.8","42.9","18.8","36.6","4.8","40.0","37.7","11.9","45.2","31.8","10.4","40.3","11.2","30.9","37.8","16.1","19.7","11.1","23.8","29.1","0.2","24.0","27.3","24.9","39.5","20.5","23.4","9.0","4.1","25.6","12.9","6.4","18.0","24.2","7.4","29.7","26.5","22.6","29.9","28.6","10.1","16.2","19.4","19.5","18.6","27.4","17.1","16.0","27.6","7.9","28.7","19.3","29.5","38.2","8.9","3.8","15.7","13.5","1.7","16.9","33.4","132.7","15.2","8.7","20.3","5.3","0.3","4.0","17.4","2.7","160","161","164","165","166","167","168",130.6,105.5,4,2023,15,"中国大学排名(主榜)",12,"全部","1","88.0","2","36.1","25.9","3","34.3",6,"4","35.5","21.6","39.2","5","10.8","4.9","30.4","6","46.2","7","0.8","42.1","8","32.1","22.9","31.3","9","43.0","25.7","10","34.5","10.0","26.2","46.5","11","47.0","33.5","35.8","25.8","12","46.7","13.7","31.4","33.3","13","34.8","42.3","13.4","29.4","14","30.7","15","42.6","26.7","16","12.5","17","12.4","44.5","44.8","18","10.3","15.8","19","32.3","19.2","20","21","28.8","9.6","22","45.0","23","30.8","16.7","16.3","24","25","32.4","26","9.4","27","33.7","18.5","21.9","28","30.2","31.0","16.4","29","34.4","41.2","2.9","30","38.4","6.6","31","4.4","17.0","32","26.4","33","6.1","34","38.8","17.7","35","36","38.1","11.5","14.9","37","14.3","18.9","38","13.0","39","27.8","33.8","3.1","40","41","28.9","42","28.5","38.0","34.0","1.5","43","15.1","44","31.2","120.0","14.4","45","149.8","7.5","46","47","38.6","48","49","25.2","50","19.8","51","5.9","6.7","52","4.2","53","1.6","54","55","20.0","56","39.8","18.1","57","35.6","58","10.5","14.1","59","8.2","60","140.8","12.6","61","62","17.6","63","64","1.1","65","20.9","66","67","68","2.1","69","123.9","27.1","70","25.5","37.4","71","72","73","74","75","76","27.9","7.0","77","78","79","80","81","82","83","84","1.4","85","86","87","88","89","90","91","92","93","109.0","94",235.7,"97","98","99","100","101","102","103","104","105","106","107","108",223.8,"111","112","113","114","115","116",215.5,"119","120","121","122","123","124","125","126","127","128",206.7,"131","132","133","134","135","136","137",201,"140","141","142","143","144","145","146",194.6,"149","150","151","152","153","154","155","156","157","158",183.3,"169","170","171","172","173","174","175","176","177","178","179","180","181","182","183","184",169.6,"187","188","189","190",168.1,167,"195",165.5,"198","199","200","201","202","203","204","205","206","207","208","209","210","212",160.5,"215","216","217","218","219","220","221","222","223","224","225","226","227","228","229","230","231",153.3,"234","235","236",150.8,"239",149.9,"242","243","244","245","246","247","248","249","250","251","252","253","254","255","256","257","258","259","260","261","262","263","264","265","266",139.7,"269","270","271","272","273","274",137,"277","278","279","280","281","282","283","284","285","286","287","288","289","290","291","292","293","294","295","296","300",130.2,"303","304","305","306","307","308",128.4,"311","312","313",125.9,"316","317",124.9,"320","321","Wuyi University","322","323","324","325","326","327","328","329","330","331",120.9,120.8,"Taizhou University","336","337","338",119.9,119.7,"343","344","345","346","347","348","349","350","351","352","353",115.4,"356","357","358","359","360","361","362","363","364",112.6,"367","368","369","370",111,"373","374","375","376","377",109.4,"380","381","382","383",107.6,"386","387",107.1,"390","391","392","393","394","395","396","400","401","402",104.7,"405","406","407","408","409","410","411","412","413","414","415",101.2,101.1,100.9,"422",100.3,"425","426","427","428","429",99,"432","433","434","435","436","437",97.6,"440","441","442","443",96.5,"446","447","448",95.8,"451",95.2,"454","455","456",94.8,"459","460",94.3,"463","464",93.6,"472","473",92.3,"476",91.7,"479","480","481","482","483","484",90.7,90.6,"489","490",90.2,"493","494","495",89.3,"503","504","505","506","507",87.4,"510","511","512",86.8,"515","516","517",86.2,"520","521",85.8,"524","525","526","527",84.6,"530","531","532","537",82.8,"540","541","542","543","544","545","546","547","548","549","550","551","552","553","554",78.1,"557","558","559","560","561","562","563","564","565","566","567","568","569","570","571","572","573","574","575","576","577","578","579","580","581","582",7,9,"logo\\u002Fannual\\u002Fbcur\\u002F2023.png",2022,2020,2019,2018,2017,2016,2015,"logo\\u002FindAnalysis\\u002Fbcur.png","中国大学排名","国内","大学"'
province_categorys=province_category.split(",")
dictionary = dict(zip(functions, province_categorys))
name = re.findall(r'univNameCn:"(.*?)",',js)
score = re.findall(r',score:(.*?),',js)
pro=re.findall(r'province:(.*?),',js)
category=re.findall(r'univCategory:(.*?),',js)
length=len(pro)
for i in range(length):
pro[i]=dictionary[pro[i]]
category[i]=dictionary[category[i]]
df = pd.DataFrame(columns=['排名', '学校', '省市', '类型', '总分'])
num = [i + 1 for i in range(582)]
nnum = pd.Series(num)
sname = pd.Series(name)
sprovince = pd.Series(pro)
scategory = pd.Series(category)
sscore = pd.Series(score)
df['排名'] = nnum
df['学校'] = sname
df['总分'] = sscore
df['省市'] = sprovince
df['类型'] = scategory
t=PDTOMYSQL(
host='127.0.0.1',
port='3306',
user="root",
pasword="123456",
db="crawl",
tb="test3",
df=df
)
t.show()
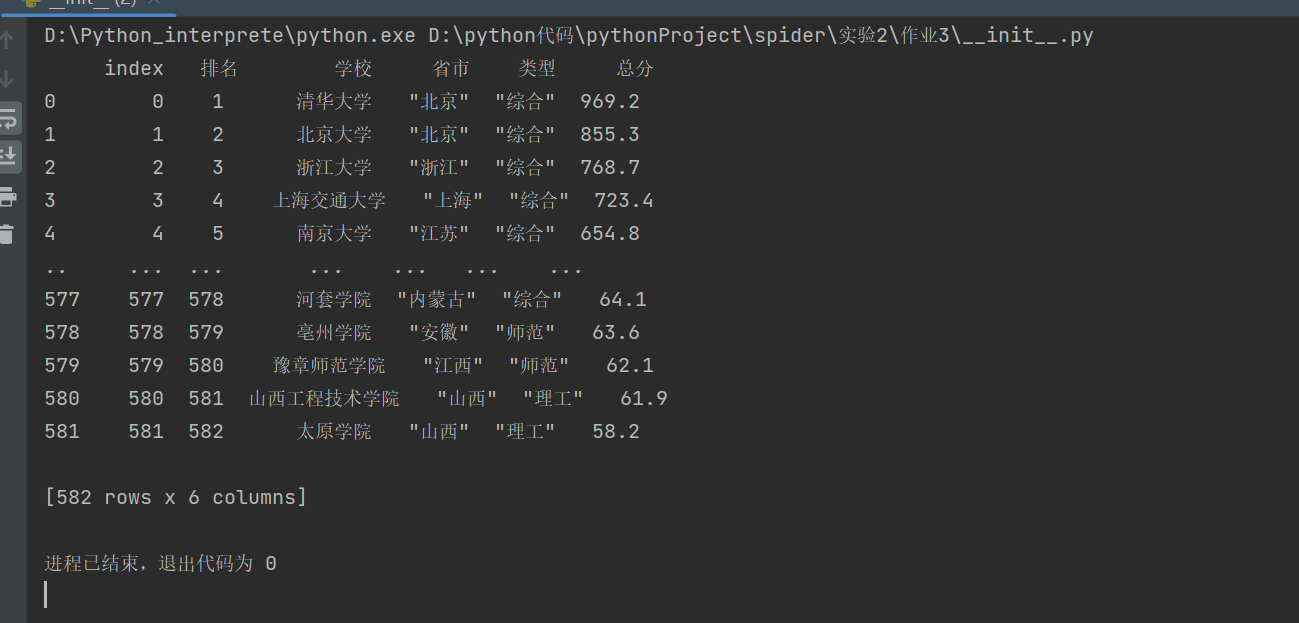
结果:
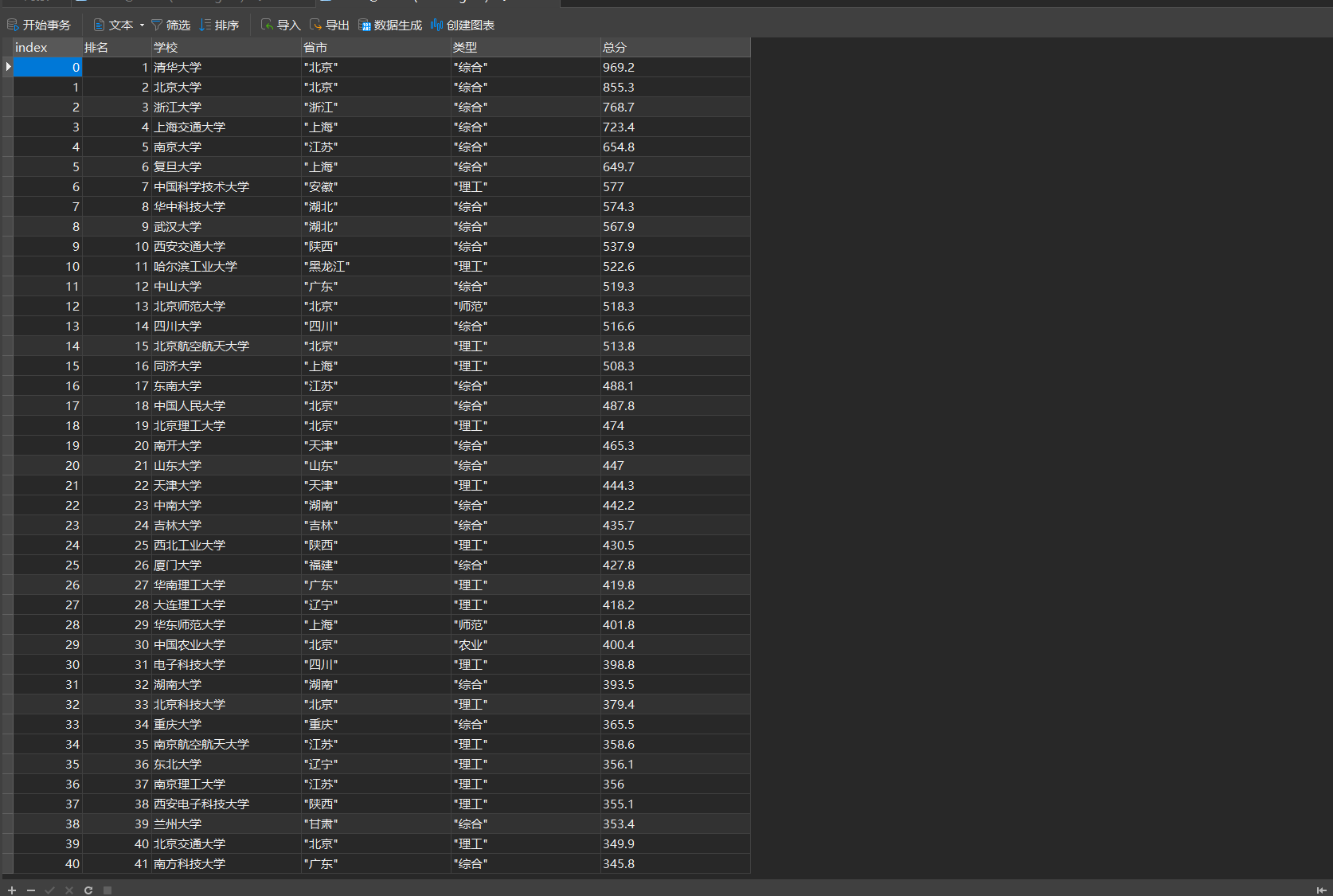
通过数据库可视化工具navicat查看数据库
心得体会
学会了用js抓包爬取数据,学会了如何用python连接数据库,存入mysql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号