
数据采集与容融合技术实践作业一
实验内容
- 作业①:用requests和BeautifulSoup库方法定向爬取给定网址
- 作业②:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 作业③:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
作业①
o要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码如下:
import urllib.request
import bs4
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr.find_all("a")
tds = tr.find_all("td")
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
def printUnivList(ulist1, num):
# 格式化输出
tplt = "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
uinfo = []
html = urllib.request.urlopen(url)
fillUnivList(uinfo, html)
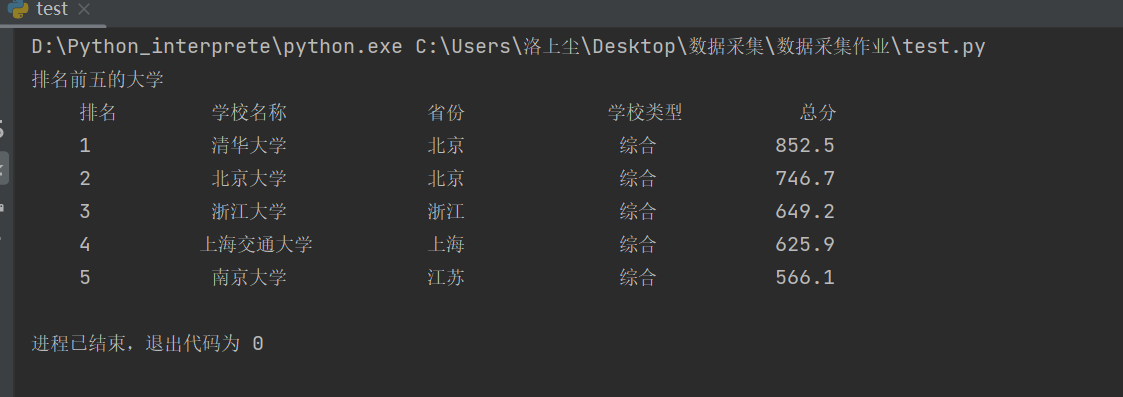
print("排名前五的大学")
printUnivList(uinfo, 5)
结果
心得体会
在这个作业中,使用BeautifulSoup库可以方便地解析网页内容,并使用CSS选择器或XPath定位和提取所需的数据。理解网页结构和标签的层次关系对于准确提取数据很重要。
作业②
o要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码如下
from bs4 import BeautifulSoup
import urllib.parse
import urllib.request
import pandas as pd
def fit(n,m,url):
for i in range(n,m+1):
print("--------------正在爬取第{}页面的书包数据------------------".format(i))
page = {
"page_index": i
}
page = urllib.parse.urlencode(page)
url = url + page
res = urllib.request.urlopen(url)
data = res.read().decode('gb2312')
# print(data)
soup = BeautifulSoup(data, 'lxml')
# print(soup)
goods = soup.select('p[class = "name"] > a[title]')
price = soup.select('span[class="price_n"]')
g=[]
p=[]
for i in range(len(goods)):
g.append(goods[i].text)
p.append(float((price[i].text).split('¥')[1]))
return g,p
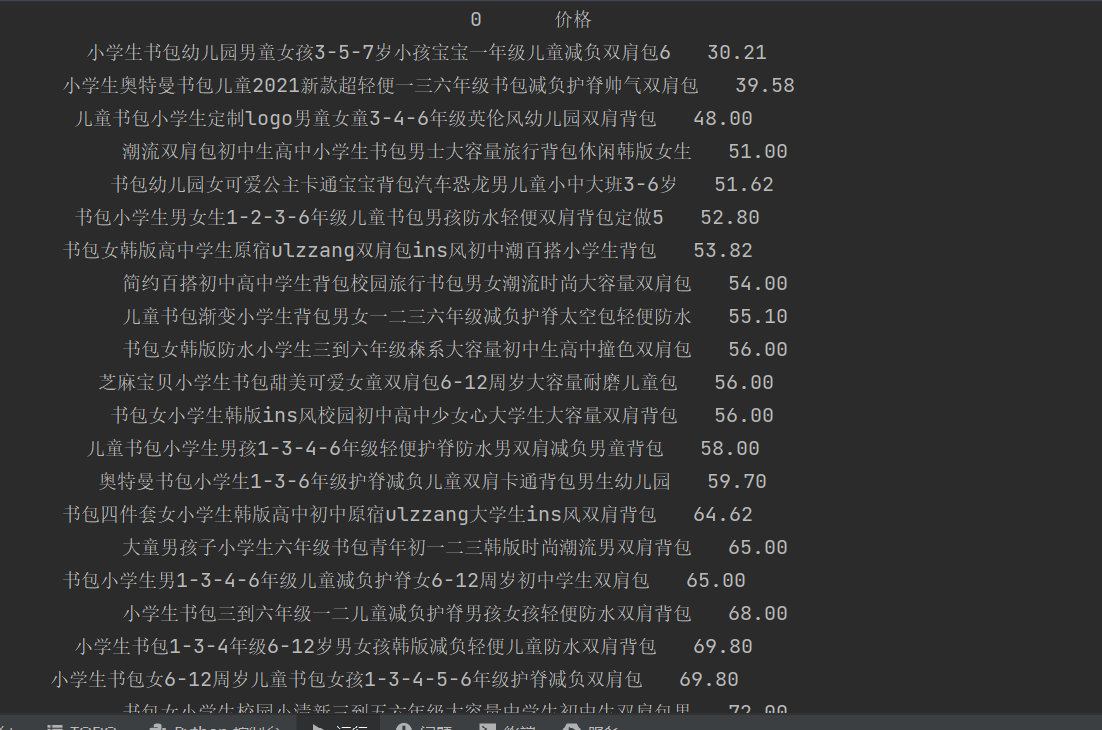
def printHTML(goods,price):
df=pd.DataFrame(goods)
df1=pd.DataFrame(price)
df['价格']=df1
df_ = df.sort_values('价格')
print(df_)
url = 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&'
n = int(input("请输入想要爬取的起始页面:"))
m = int(input("请输入想要爬取的最后页面:"))
goods,price=fit(n,m,url)
printHTML(goods,price)
结果
心得体会
通过这个作业,我学习和熟悉了使用requests和BeautifulSoup库。这两个库提供了丰富的功能和方法,能够方便地发送请求、解析网页内容和提取所需数据
作业③
o要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
代码如下
import urllib.request
from bs4 import BeautifulSoup
import urllib.parse
import os
url='https://xcb.fzu.edu.cn/info/1071/4481.htm'
headers={'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36'}
rep=urllib.request.Request(url=url,headers=headers)
doc=urllib.request.urlopen(rep)
data1=doc.read().decode()
soup=BeautifulSoup(data1,'lxml')
def myFilter(tag):
return (tag.name=="img" and tag.has_attr("src"))
tags=soup.find_all(myFilter)
for tag in tags:
print(tag)
path='D:\python代码\pythonProject\spider'
x=1
for tag in tags:
tag1=str(tag)
tag2=tag1.split('"')[1]
tag2=tag2.split('?')[0]
#print(tag2)
Ur="https://xcb.fzu.edu.cn"+tag2
urllib.request.urlretrieve(Ur,'{}{}.jpg'.format(path,x))
x=x+1
结果

心得体会
这个作业将之前学习得爬虫知识融合实践,更好的熟悉掌握了知识,巩固基础,也学会了存储文件的一些方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号