林汕--第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息,将采集到的评论信息做成词云图 |
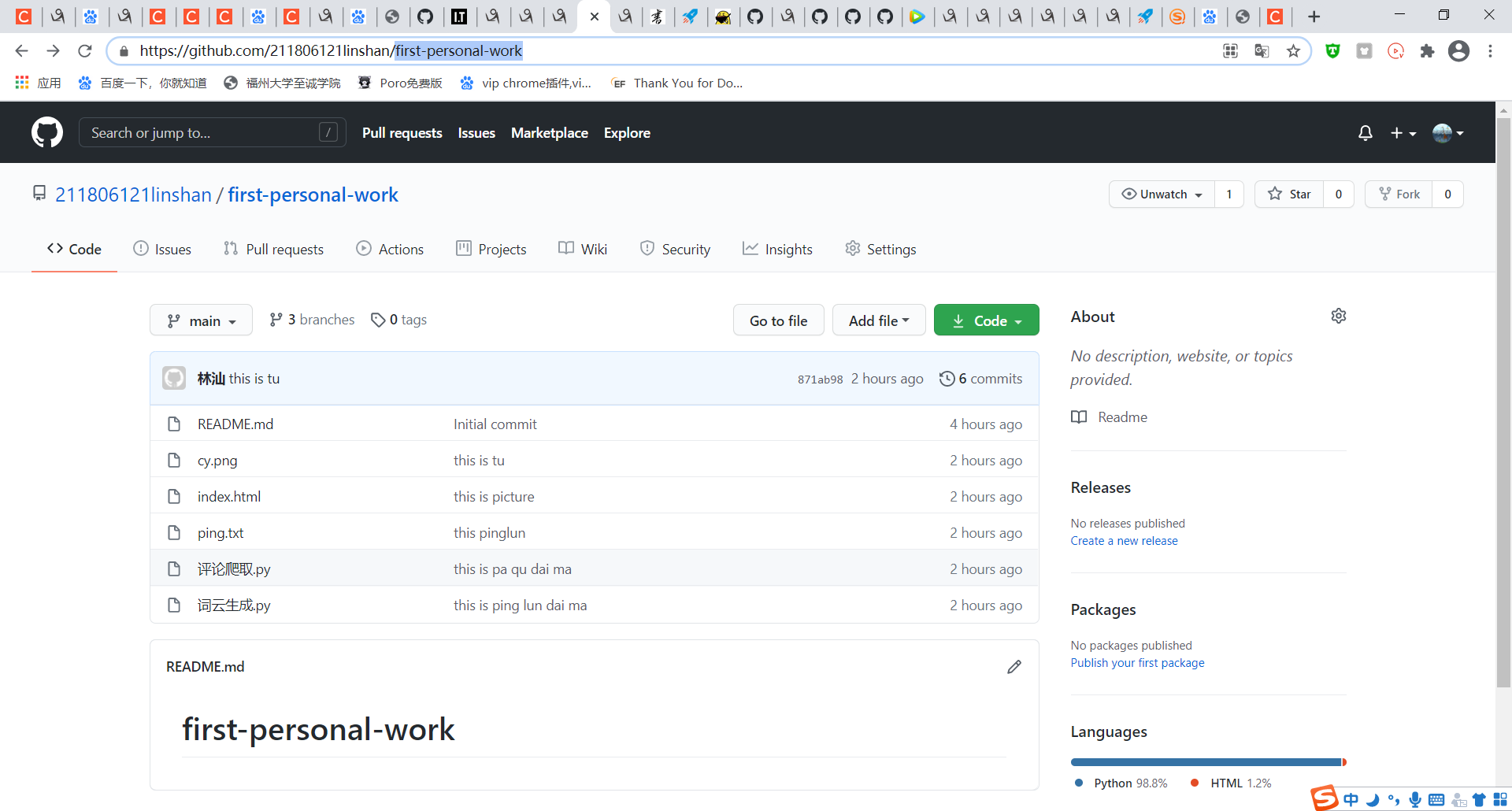
| 作业源代码 | https://github.com/211806121linshan/first-personal-work |
| 学号 | 211806121 |
时间分布
| 步骤 | 耗时 |
|---|---|
| 数据爬取 | 0.5h |
| 数据处理 | 1h |
| 生成词云 | 1h |
| 上传至github | 3h |
爬取评论
打开相应网站,使用谷歌浏览器右键打开检查,注意将鼠标放至评论再右击
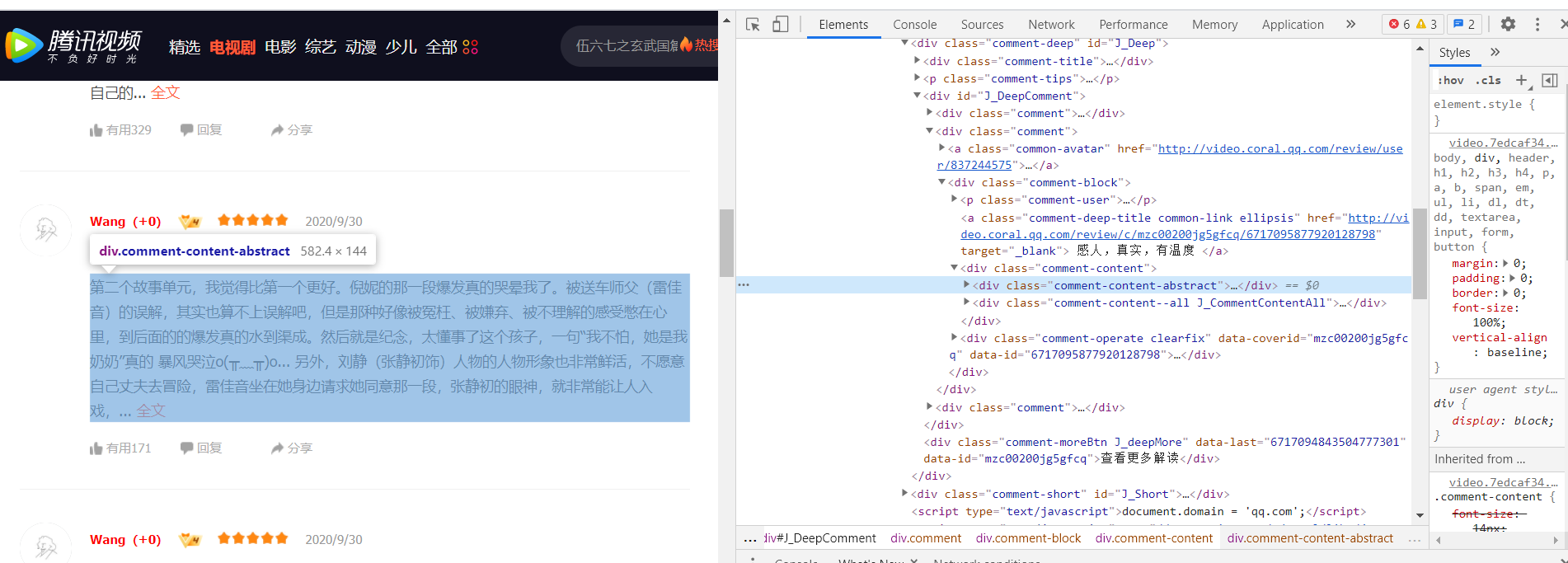
在上图中沿着蓝色方框把标签逐级打开,进行分析,经过分析可知网站用的是异步加载。
然后我通过搜索找到类似的代码,将代码进行稍微的修改爬取对应的评论,并且保存为txt文件。
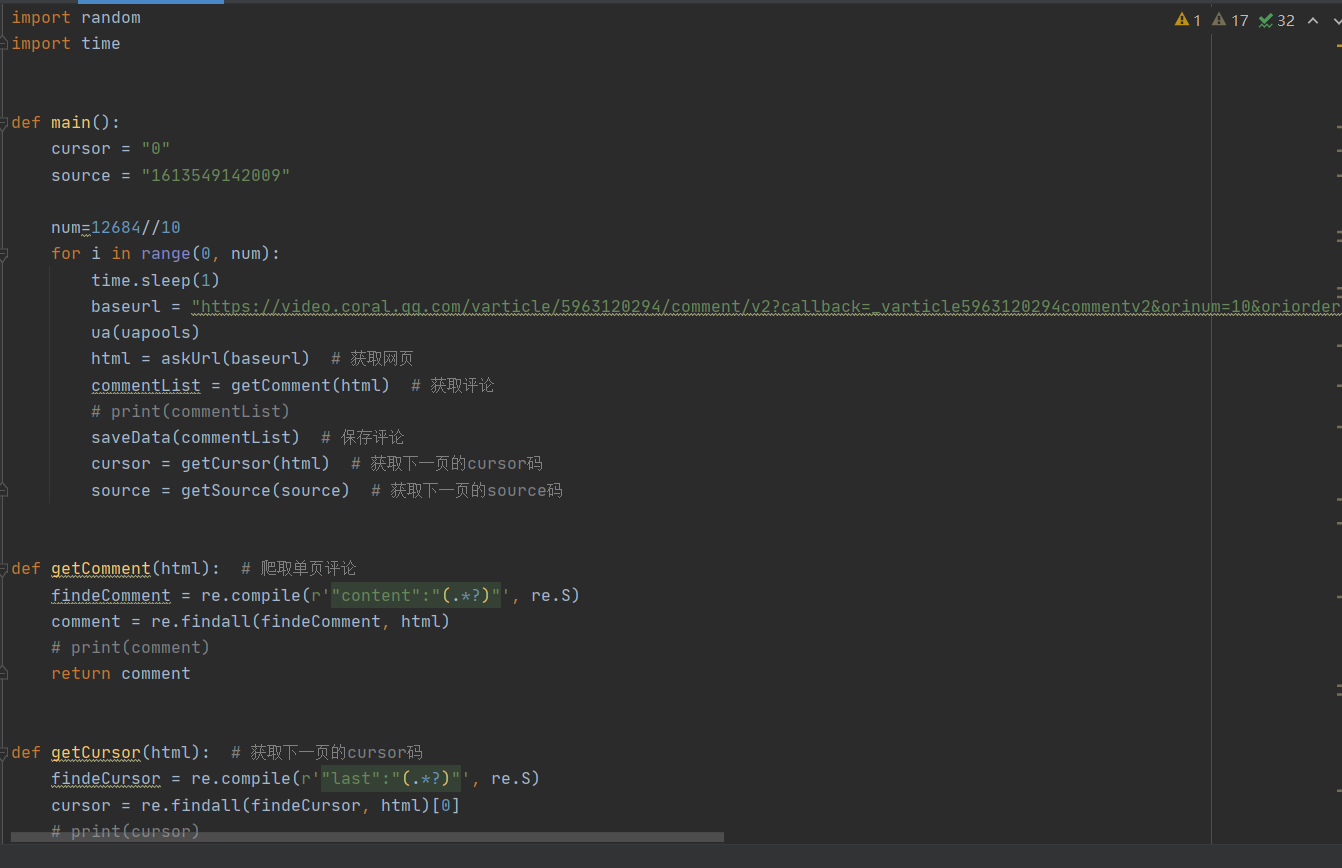
至此评论爬取工作就做完了,接下来就是要对得到的数据进行处理。
数据处理
通过对刚才爬取到的评论进行分词,jieba进行词频统计,再调用numpy进行词云的生成
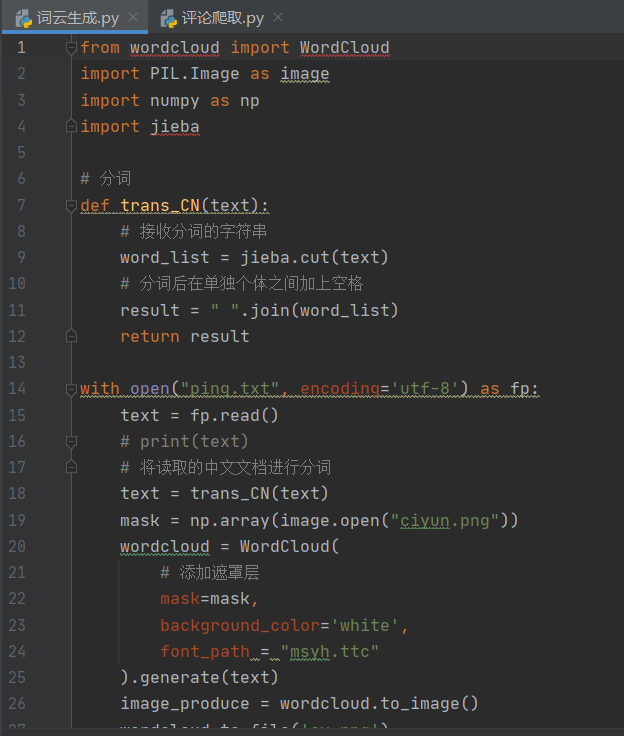
生成词云
得到的词云如下图

上传至github
先在github上面创建仓库first-personal-work
然后在本地打开git-bash,输入git init

把仓库克隆到本地
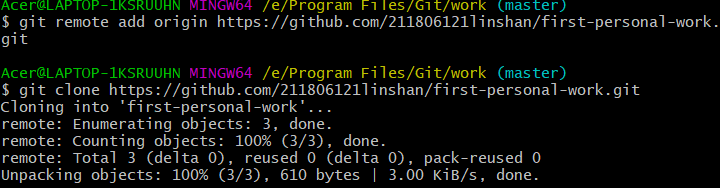
进入first-personal-work
建立crawl和chart两个分支
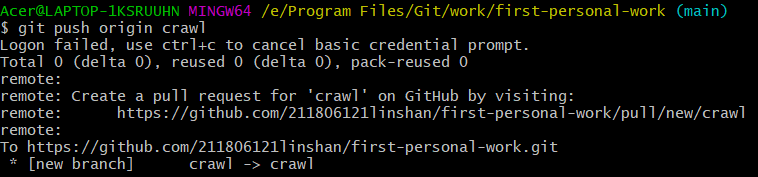
指定chart分支,可以看到main变成chart

开始上传文件,上传一次commit一次,剩下的文件按照如下步骤逐次上传,传完为止
剩下文件部分操作步骤
将两个分支分别合并到主分支
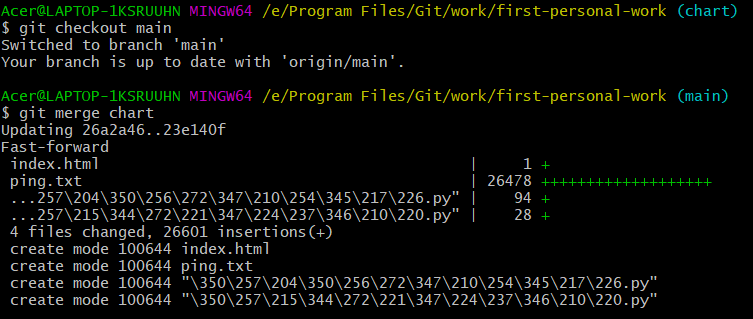
将文件上传

遇到的问题
从开始的爬取代码就是通过网站上学习拿来使用的
词云的也是,过程中要用的插件,这些都是根据网络学习做出来的
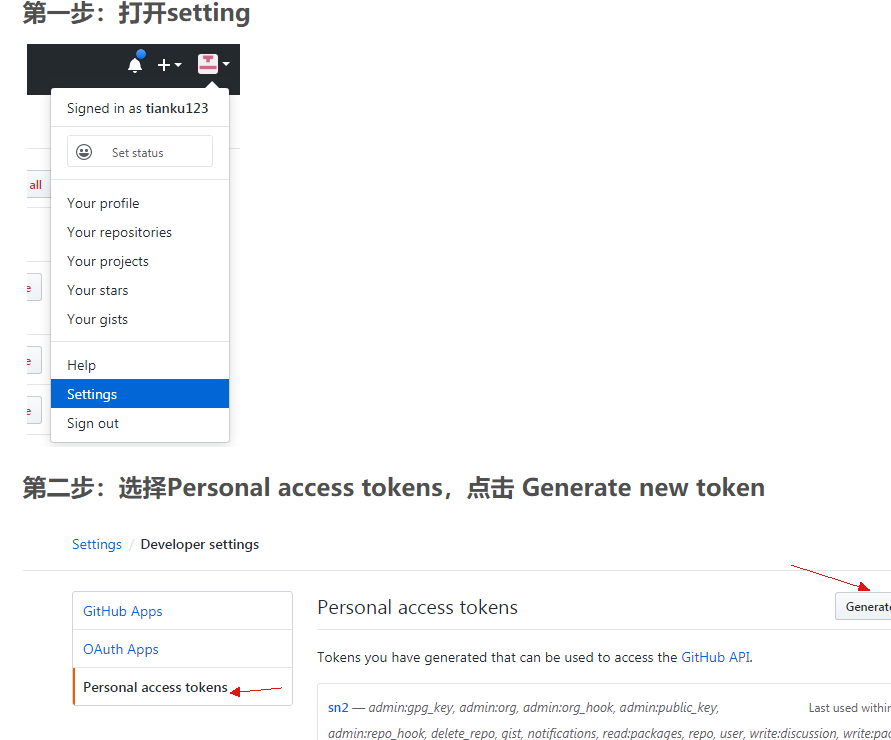
本次对我来说最困难的文件上传,以前并没有接触过,有的时候很简单的yige问题都会困我好久,例如要与github仓库建立连接时出现报错
通过Generate new token解决了登陆问题

最后的上传结果
参考资料
https://www.liaoxuefeng.com/wiki/896043488029600
https://blog.csdn.net/zx1245773445/article/details/100894576
https://blog.csdn.net/ruanhao1203/article/details/91948837
https://www.cnblogs.com/longshiyVip/p/5640987.html
https://www.cnblogs.com/xiaowenshu/p/9916735.html
https://www.cnblogs.com/litchi666/p/12703836.html
http://www.ruanyifeng.com/blog/2016/01/commit_message_change_log.html
https://blog.csdn.net/heyuexianzi/article/details/76851377

 浙公网安备 33010602011771号
浙公网安备 33010602011771号