KNN算法实验
1.knn算法概述
KNN算法是机器学习算法中最基础,最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想就是对输入的特征向量对应特征空间的一个点,输出为该特征向量所对应的类别标签或者预测值。
KNN算法是一种特别的机器学习算法,没有一般意义上的学习的过程。工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型,存在一个样本数据集合,称作训练样本集,并且训练集的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
一般我们只取样本数据集中前K个最相似的数据,就是KNN算法中K的含义。通常K是不大于20的整数。
2.KNN算法介绍
KNN算法,是有监督学习的分类算法,可以用于解决分类问题或者回归问题,但是通常用作分类算法。
3.KNN的核心思想
KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。KNN 的原理是:当预测一个新样本的类别时,根据它距离最近的 K 个样本点是什么类别来判断该新样本属于哪个类别(多数投票)。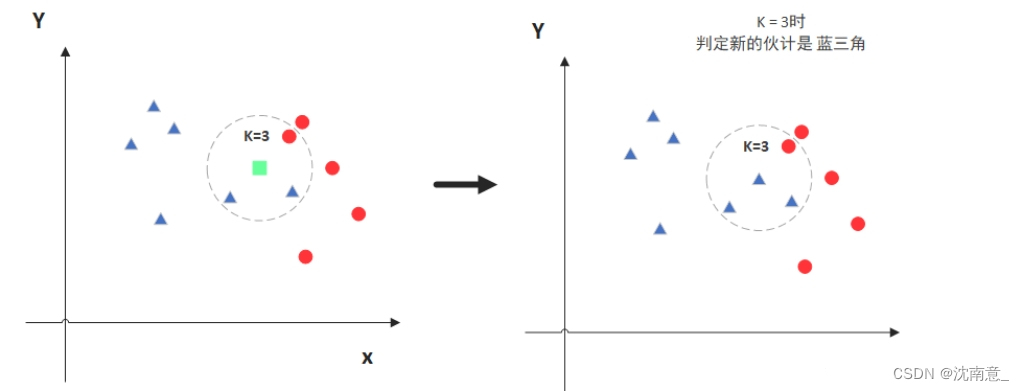
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
4.k值的选择
我们可以使用交叉验证的方式进行K值的选择,从选取一个较小的K值开始不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
5.KNN算法的优劣介绍
优点:
1.简单易用
2.模型训练时间快
3.预测效果好
4.对异常值不敏感
缺点:
1.对内存要求高,需要存储所有训练数据
2.预测阶段可能较慢
6.KNN回归算法
上面讲到的KNN主要用于分类算法,事实上KNN也可以用于回归预测。
KNN算法用于回归预测的时候寻找K个近邻,将K个样本对的目标值取均值即可作为新样本的预测值。
7.KNN算法中的距离指标公式
曼哈顿距离L1(xi,xj)=∑nl=1|x(l)i−x(l)j|
欧式距离L2(xi,xj)=(∑nl=1|x(l)i−x(l)j|2)12
8.总结KNN⼯作流程
1.计算待分类物体与其他物体之间的距离;
2.统计距离最近的 K 个邻居;
3.对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪⼀类。
9.基于K邻近算法的实验实现
我写的是一个鸢尾花分类案例,数据集内置于sklearn库中,可以直接导入使用。
`from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
1.获取数据集
iris = load_iris()
数据集特征名称
print(iris.feature_names)
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
2.数据预处理
2.1 数据分割
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=2)
2.2 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
3.模型训练
3.1 实例化分类器
estimator = KNeighborsClassifier(n_neighbors=9)
3.2 使用交叉验证网格搜索
estimator-->分类器
param_grid-->指定的数据
cv=5-->5折交叉验证
params_grid = {"n_neighbors":[1,3,5,7,9,11]}
estimator = GridSearchCV(estimator,param_grid=params_grid,cv=5)
3.3 模型训练
estimator.fit(x_train,y_train)
4.模型评估
4.1 传入测试集数据 预测出来的结果跟实际的测试集结果和真实结果
y_pre = estimator.predict(x_test)
print(y_pre)
print(y_test)
4.2 输出准确率 注意:X-->测试集特征 y-->测试集真实结果
ret = estimator.score(x_test,y_test)
print("准确率:",ret)
print('最好的模型:',estimator.best_estimator_)
print('最好的得分:',estimator.best_score_)
print('最好的结果:',estimator.cv_results_)
实验结果如下

实验总结:
数据预处理问题:标准化处理时使用了错误的方法,应该使用transform而不是fit_transform,因为在测试集上需要使用相同的标准化参数,而不是重新拟合。
超参数选择问题:在实验中使用了交叉验证网格搜索来选择最优的邻居数,但是可能存在超参数选择不当的情况,导致模型性能不佳。
模型评估问题:虽然计算了模型的准确率,但仅仅依靠准确率可能不足以全面评估模型性能,还可以考虑其他指标如精确度、召回率、F1值等。
通过交叉验证和网格搜索得到了最优的超参数配置,即最优的邻居数。
输出了模型在测试集上的预测结果和实际结果,以及模型的准确率。
输出了最优模型的参数配置和得分,以及交叉验证的结果,可以帮助进一步分析模型的性能和稳定性。
可以进一步分析模型在不同类别上的预测性能,比如混淆矩阵等评估指标,以更全面地了解模型的性能。
综上所述,KNN算法实验中可能遇到的问题主要涉及数据预处理、超参数选择和模型评估等方面,通过输出模型的预测结果和性能指标可以帮助总结实验结果,进一步分析模型的性能和稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号