
20241417 实验四《Python程序设计》实验报告
20241417 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2414
姓名: 罗若元
学号:20241417
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
一.实验内容
-
基于 Selenium 的京东商品信息爬虫工具,主要功能是爬取指定商品的销量排名信息
-
部分功能:1.运行后打印出Excel表格,方便后续查看;2.打包成了exe程序,方便使用;3.设计有简单的GUI界面,清晰直观...
-
最开始是花了几个晚上的时间研究各个电商平台商品价格的爬虫,想借着618做一下各种优惠力度的对比(一直对百亿补贴和国补的优惠力度感兴趣),但中道崩殂了,原因就是这几个平台的反爬机制都太复杂了,查阅了CSDN和使用了各种大模型唯一一个相对方便点的就是通过模拟浏览器 + 反检测免登录查看价格,但是这样的的限制又太多了,达不到我期望的效果,于是我转变观念,爬取同种商品在同一平台下的各类数据(基于多方考虑,最终本次实验决定选取京东平台作为爬取对象),最终成果如下:
![]()
源代码:https://gitee.com/luo-ruoyuan/python/blob/master/PythonProject5/shiyan4.py
二. 实验过程
(一)前置条件
- 首先得导入第三方库:
import os
import time
import random
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
import threading
import sys
from openpyxl import Workbook
from openpyxl.styles import Font, Alignment, PatternFill
from openpyxl.utils.dataframe import dataframe_to_rows
主要需要安装的外部库有以下几个:
- selenium:驱动浏览器自动化操作(如登录、翻页、抓取动态数据)
指令:pip install selenium - pandas:用于数据处理与分析,将爬取结果转换为结构化表格
指令:pip install pandas - openpyxl:生成并美化Excel文件(设置字体、对齐、背景色等)
指令:pip install openpyxl
PS:完整指令:pip install selenium pandas openpyxl
![]()
- 下载与浏览器版本匹配的驱动(我这里用的是windows自带的Edge浏览器,但听说谷歌浏览器更稳定,以下说明均为Edge浏览器版本)
- 首先在浏览器地址栏输入以下代码查看当前浏览器版本:edge://settings/help
![]()
- 然后到官网下载对应版本浏览器驱动(下载稳定通道的x64版本即可):
官网下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH#downloads
![]()
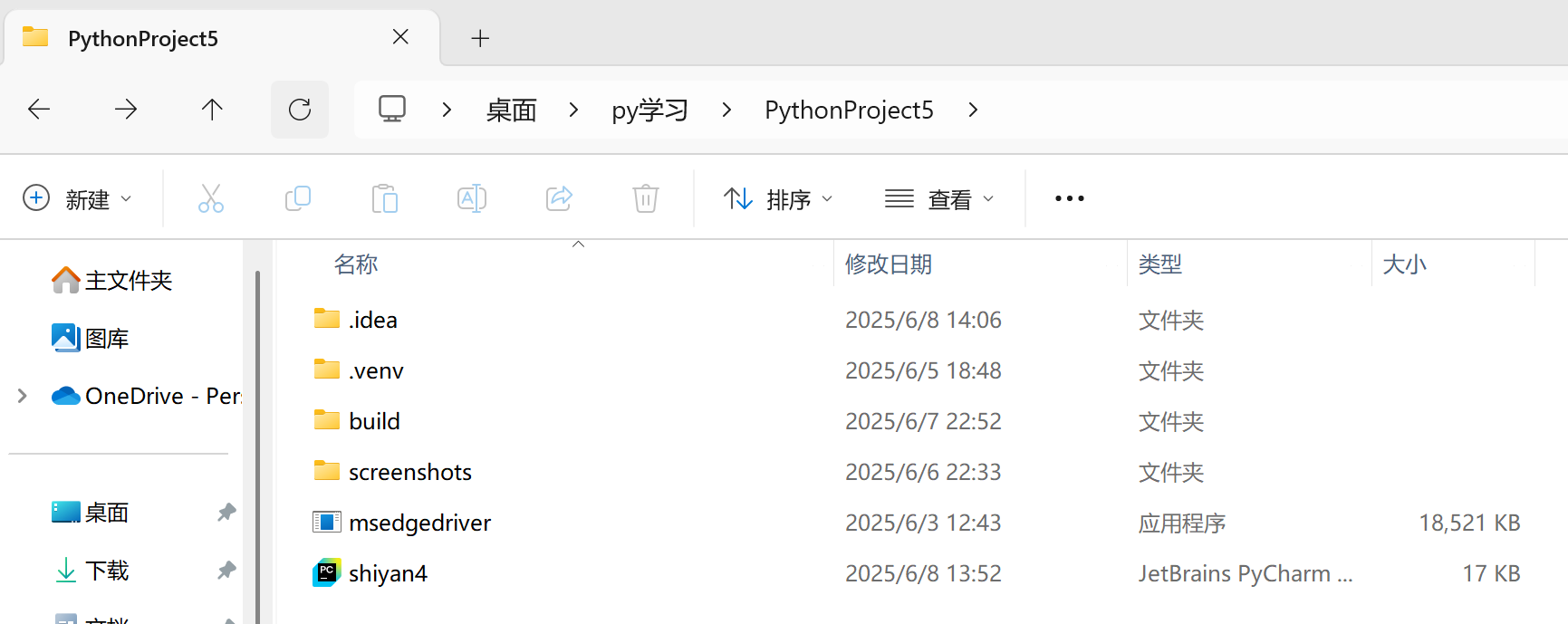
- 下载解压后得到一个名为msedgedriver的exe应用程序,记得一定要把它移至和代码文件的相同目录下,以我的为例:
![]()
(二)代码编写
- 完成上述准备工作后,正式开始代码编写,因为我的爬虫需要借助浏览器来实现,首当其冲的就是配置浏览器(setup_driver)
- 初始化 Edge
edge_options = Options()
- 稳定性参数配置:这是我在无数次使浏览器崩溃后,上网搜寻的几个常用的防报错配置,但不是每一个都会用到,有总比没有强
edge_options.add_argument("--no-sandbox")
edge_options.add_argument("--disable-dev-shm-usage")
edge_options.add_argument("--remote-debugging-port=9222")
edge_options.add_argument("--disable-extensions")
- 无头模式核心配置:使爬取时浏览器不显示(类似于后台)
edge_options.add_argument("--headless") # 无界面运行
edge_options.add_argument("--disable-gpu") # 禁用GPU加速
- 通用优化参数:优化浏览器,减少干扰(如禁用弹窗)
edge_options.add_argument("--log-level=3")
edge_options.add_argument("--disable-infobars")
edge_options.add_argument("--disable-notifications")
edge_options.add_argument("--disable-popup-blocking")
- 用户数据目录:保留登陆数据,避免重复登陆(京东首次需登录,找了好久也没找到解决方法,只能退而求其次了)
edge_options.add_argument(f"--user-data-dir={self.cookies_path}")
- 随机化 User-Agent:随机选取用户地址,防止单一地址重复访问被认定为爬虫
user_agents = [...] # 原有UA列表
edge_options.add_argument(f"--user-agent={random.choice(user_agents)}")
- 驱动路径配置:对应前面把msedgedriver.exe放到当前目录下的步骤,如果放到其他地方,就得你手动输入地址了
if getattr(sys, 'frozen', False):
driver_path = os.path.join(os.path.dirname(sys.executable), 'msedgedriver.exe')
else:
driver_path = os.path.join(os.getcwd(), 'msedgedriver.exe')
- 驱动初始化
service = Service(driver_path)
self.driver = webdriver.Edge(service=service, options=edge_options)
self.driver.set_page_load_timeout(60)
- 最好添加一个异常处理:
try:
# 上述代码
except Exception as e:
print(f"驱动设置失败: {str(e)}")
return None
- 登录状态检测(is_logged_in)和登录流程(login_jd):京东平台的数据爬取需要登陆了个人账号才能实现,所以就多了这两个步骤
- 登录状态检测(is_logged_in):刚开始我搜索网络上的判断方法都是看HTLM网络源代码中有没有“我的京东”元素来判断是否登录,但是实操后发现登不登陆都有“我的京东”,于是,我在反复观察下发现“切换账号”元素能够更为准确的判断出是否登陆京东
def is_logged_in(self):
"""检查是否已登录京东(通过检查是否存在'切换账号'元素)"""
try:
self.driver.get("https://www.jd.com")
time.sleep(1)
# 尝试查找"切换账号"元素
try:
# 使用XPath查找包含"切换账号"文本的元素
switch_account = self.driver.find_element(By.XPATH, "//*[contains(text(), '切换账号')]")
if switch_account.is_displayed():
return True
except NoSuchElementException:
pass
except Exception as e:
print(f"未登录: {str(e)}")
return False
- 登录流程(login_jd):首次登陆或身份过期会跳转这串代码,然后会在有头模式(浏览器前台显示)下给用户扫码登陆
def login_jd(self):
"""手动登录京东"""
self.update_status("请在打开的浏览器中手动登录京东(等待时间5分钟)...")
try:
self.driver.get("https://passport.jd.com/new/login.aspx")
# 等待登录成功标志
WebDriverWait(self.driver, 300).until(
lambda driver: self.is_logged_in()
)
self.update_status("京东登录成功")
time.sleep(2)
return True
except Exception as e:
self.update_status(f"京东登录超时: {str(e)}")
return False
- 商品数据抓取 (get_jd_info):这串代码是实现京东商品爬虫最核心的部分
- 登录状态检测promax:有别于上面通过网页元素判断登陆情况的方法,这串代码通过检查用户数据目录是否存在来判断(这是后期通过b站视频启发加上去的,原来的检测方法也不想删了,于是就二者结合着用了)
# 检查用户数据目录是否存在
user_data_dir_exists = os.path.exists(self.cookies_path)
# 情况1:用户数据目录存在(非首次使用)
if user_data_dir_exists:
# 无头模式启动浏览器
if not self.setup_driver(): return None
# 检查登录状态
if self.is_logged_in():
... # 已登录则继续
else:
# 切换有头模式登录
self.driver.quit()
edge_options = Options()
edge_options.add_argument(f"--user-data-dir={self.cookies_path}")
... # 启动有头浏览器
if not self.login_jd(): return None
# 重新无头模式启动
self.driver.quit()
if not self.setup_driver(): return None
# 情况2:首次使用(无用户数据目录)
else:
... # 启动有头浏览器并登录
- 商品搜索与排序:
# 按销量降序排序
url = f"https://search.jd.com/Search?keyword={product_name}&sort=sort_totalsales15_desc"
self.driver.get(url)
# 显式等待商品加载
WebDriverWait(self.driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.gl-item'))
)
time.sleep(1) # 额外缓冲
- 商品数据解析:考虑到正品有品质保障,我在用代码解析数据时给官方认证的京东自营店和旗舰店标上了*,然后页面的解析用了CSS选择器定位,避免页面微调的影响
items = self.driver.find_elements(By.CSS_SELECTOR, '.gl-item')
for item in items:
try:
# 店铺信息(标记自营/旗舰店)
shop = item.find_element(By.CSS_SELECTOR, '.p-shop a').text.strip()
if "京东自营" in shop or "旗舰店" in shop:
shop = f"{shop} *"
# 价格提取
price = float(item.find_element(
By.CSS_SELECTOR, '.p-price strong i').text)
# 评价数处理(异常捕获)
try:
comment_num = item.find_element(
By.CSS_SELECTOR, '.p-commit strong a').text.strip()
except:
comment_num = "未知"
results.append({'店铺名字':shop, '价格':price, '累计评价数':comment_num})
except Exception:
continue # 单条商品解析失败时继续
- 同样是最好加上异常处理机制:
except (TimeoutException, NoSuchElementException) as e:
self.update_status(f"京东爬取出错: {str(e)}")
return None
except Exception as e:
self.update_status(f"京东爬取发生未知错误: {str(e)}")
return None
- 数据的爬取与输出:爬取了数据,肯定得做一个Excel表格来存放这些数据,于是有了以下代码
- 数据的格式化保存(save_to_excel):将爬取的商品数据保存为格式化的 Excel 文件,包含数据存储、格式美化和路径处理
def save_to_excel(self, df):
# 1. 数据校验
if df is None or df.empty:
return False
try:
# 2. 创建Excel工作簿
wb = Workbook()
ws = wb.active
ws.title = "京东商品信息"
# 3. 添加表头
ws.append(["店铺名字", "价格", "累计评价数"])
# 4. 添加数据行(仅保留三列关键数据)
for row in dataframe_to_rows(df[['店铺名字', '价格', '累计评价数']], index=False, header=False):
ws.append(row)
# 5. 设置表头样式
header_fill = PatternFill(start_color="1E88E5", end_color="1E88E5", fill_type="solid")
header_font = Font(bold=True, color="FFFFFF")
for cell in ws[1]:
cell.font = header_font
cell.fill = header_fill
cell.alignment = Alignment(horizontal="center")
# 6. 自动调整列宽(基于内容长度)
for col in ws.columns:
max_length = 0
column = col[0].column_letter # 获取列字母标识(A,B,C...)
for cell in col:
try:
# 计算本列最长内容
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
# 设置列宽 = 内容最大长度 + 2个字符的缓冲
adjusted_width = (max_length + 2)
ws.column_dimensions[column].width = adjusted_width
# 7. 确定保存路径(兼容打包环境)
if getattr(sys, 'frozen', False): # 判断是否打包成exe
save_path = os.path.join(os.path.dirname(sys.executable), f"{self.product_name}_京东商品信息.xlsx")
else:
save_path = os.path.join(os.getcwd(), f"{self.product_name}_京东商品信息.xlsx")
# 8. 保存文件并返回路径
wb.save(save_path)
return save_path
# 9. 异常处理
except Exception as e:
messagebox.showerror("保存错误", f"保存Excel文件时出错: {str(e)}")
return None
- 爬虫入口(start_spider):启动爬虫任务的入口方法,处理用户输入并初始化爬取线程
def start_spider(self):
# 1. 获取商品名称输入
product_name = self.entry.get().strip()
# 2. 输入验证
if not product_name:
messagebox.showwarning("输入错误", "请输入商品名称")
return
# 3. 初始化UI状态
self.progress_var.set(0) # 进度条归零
self.result_text.delete(1.0, tk.END) # 清空结果文本框
self.spider_button.config(state=tk.DISABLED) # 禁用开始按钮
self.status_label.config(text="开始爬取...") # 更新状态标签
# 4. 启动后台线程执行爬取任务
threading.Thread(
target=self.run_spider, # 目标函数
args=(product_name,), # 参数:商品名称
daemon=True # 守护线程(主程序退出时自动结束)
).start() # 启动线程
- 执行爬取、展示和保存(run_spider):线程执行的实际爬取任务,包含完整爬取流程和结果展示
def run_spider(self, product_name):
try:
# 1. 保存商品名称(用于文件命名)
self.product_name = product_name
# 2. 初始化浏览器驱动
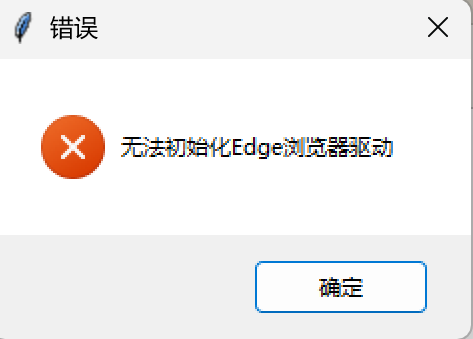
if not self.setup_driver():
messagebox.showerror("错误", "无法初始化Edge浏览器驱动")
return
# 3. 执行爬取任务
results = self.get_jd_info(product_name)
# 4. 处理结果
if results:
# 4.1 转换为DataFrame
df = pd.DataFrame(results)
# 4.2 数据准备(仅保留三列关键数据)
display_df = df[['店铺名字', '价格', '累计评价数']]
# 4.3 格式化输出到文本框
# 标题
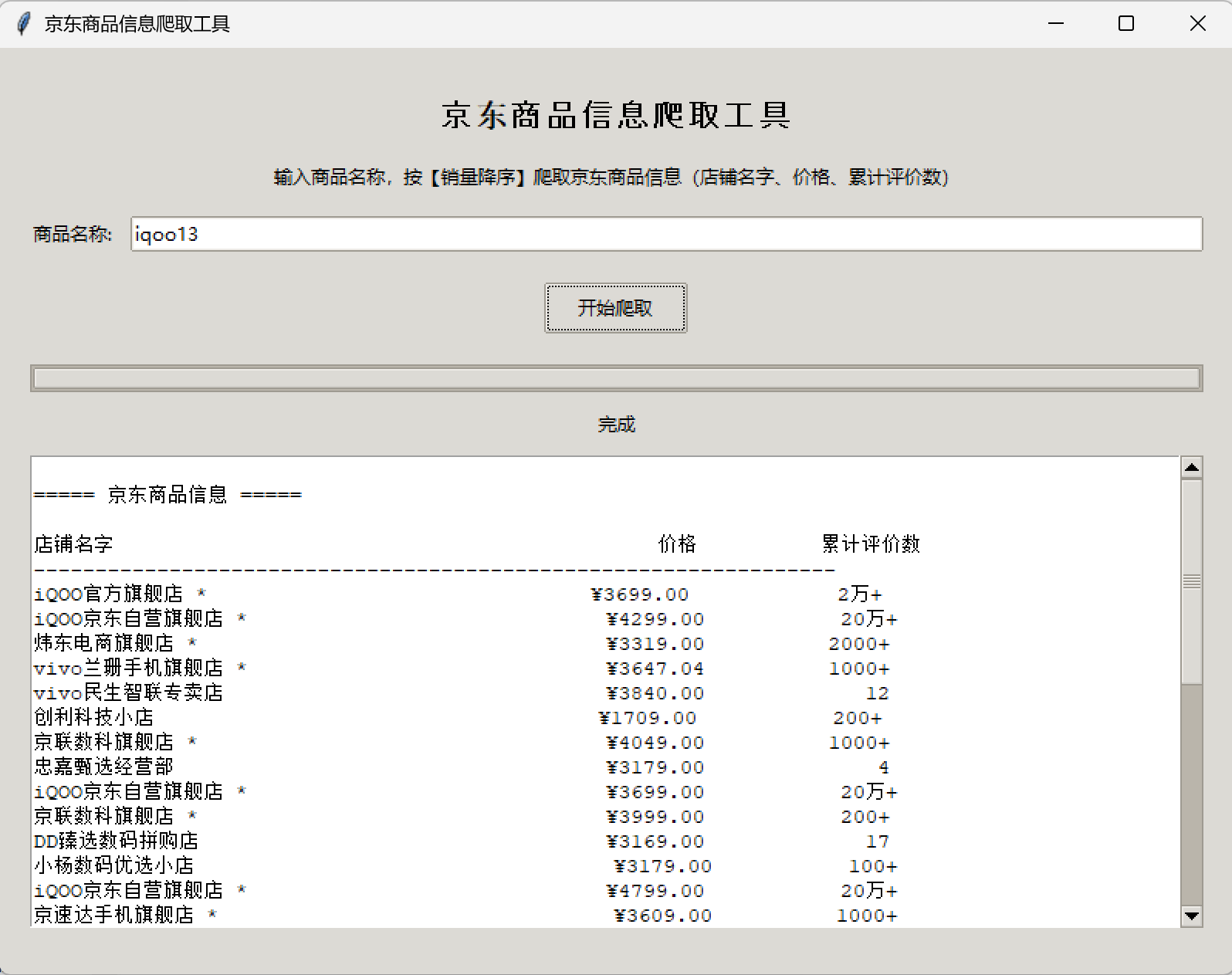
self.result_text.insert(tk.END, "\n===== 京东商品信息 =====\n\n")
# 表头(使用等宽字体实现对齐)
self.result_text.insert(tk.END, f"{'店铺名字'.ljust(40)}{'价格'.rjust(10)}{'累计评价数'.rjust(15)}\n")
self.result_text.insert(tk.END, "-" * 65 + "\n")
# 数据行
for _, row in display_df.iterrows():
# 处理店铺名称过长
shop = row['店铺名字']
if len(shop) > 38:
shop = shop[:35] + "..." # 截断并添加省略号
# 格式化价格(添加货币符号)
price = f"¥{row['价格']:.2f}"
# 添加对齐的数据行(左对齐店铺,右对齐价格和评价数)
self.result_text.insert(tk.END,
f"{shop.ljust(40)}{price.rjust(10)}{str(row['累计评价数']).rjust(15)}\n")
# 尾部信息
self.result_text.insert(tk.END, "\n" + "=" * 65 + "\n")
self.result_text.insert(tk.END, f"共找到 {len(display_df)} 条商品信息\n")
# 4.4 保存到Excel
save_path = self.save_to_excel(df)
if save_path:
self.result_text.insert(tk.END, f"\n结果已保存到: {save_path}\n")
# 5. 更新进度状态
self.progress_var.set(100)
self.status_label.config(text="完成")
# 6. 异常处理
except Exception as e:
messagebox.showerror("错误", f"发生未预期错误: {str(e)}")
import traceback
traceback.print_exc() # 打印完整错误堆栈(调试用)
# 7. 资源清理(无论成功与否)
finally:
# 7.1 恢复按钮状态
self.spider_button.config(state=tk.NORMAL)
# 7.2 关闭浏览器驱动(如果存在)
if self.driver:
self.driver.quit()
self.driver = None
- GUI界面设计 (create_gui):为了让代码的呈现更为直观,设计了一个简易的GUI界面
def create_gui(self):
# 主窗口设置
self.root.geometry("800x600")
self.root.title("京东商品信息爬取工具")
# 响应式布局
input_frame = ttk.Frame(main_frame)
input_frame.pack(fill=tk.X, pady=10)
# 组件创建
self.entry = ttk.Entry(input_frame, width=50)
self.spider_button = ttk.Button(text="开始爬取", command=self.start_spider)
# 结果显示区(等宽字体保证对齐)
self.result_text = tk.Text(font=("Courier New", 10))
# 进度指示
self.progress_var = tk.IntVar()
ttk.Progressbar(variable=self.progress_var)
# 状态栏
self.status_label = ttk.Label(text="准备就绪")
(三)打包成exe程序(使用PyInstaller)
-
安装PyInstaller
指令:pip install pyinstaller
![]()
-
基础打包(生成单个 EXE 文件):不同于一般的点在于将msedgedriver.exe驱动文件包含进打包结果,并放在.exe同目录
指令:pyinstaller --onefile --noconsole --add-data "msedgedriver.exe;." shiyan4.py
PS:这里的shiyan4.py是源代码实际的文件名
![]()

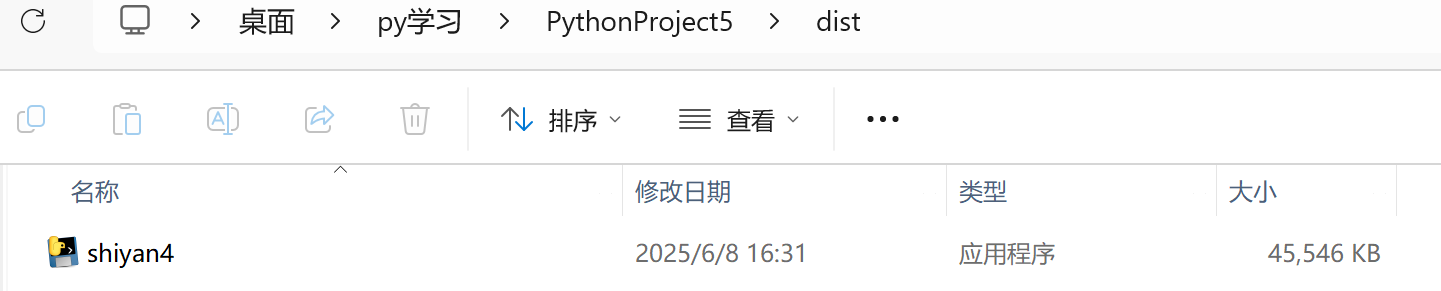
- 出现下面这行说明打包成功,打包到了当前路径的dist文件夹下
![]()
![]()

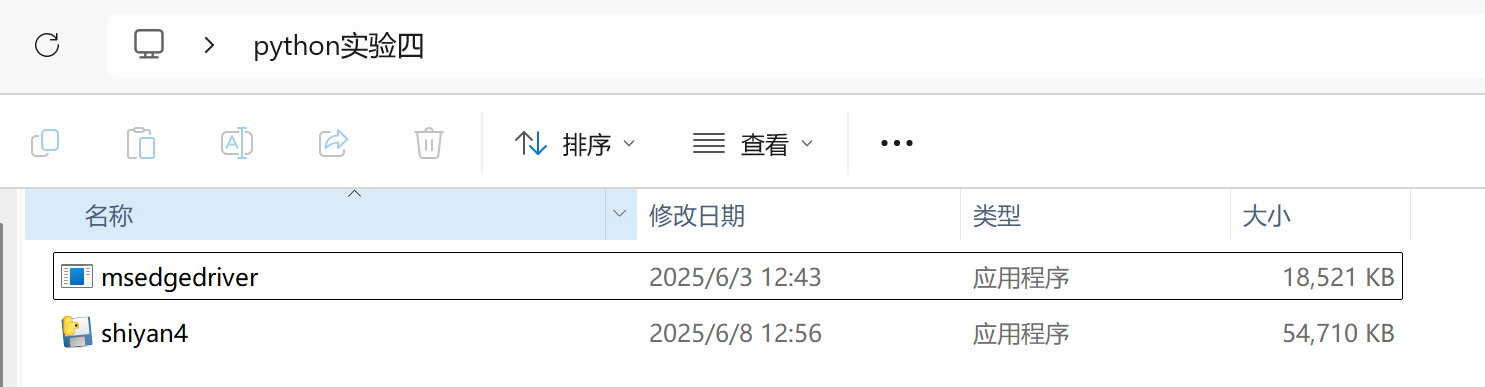
- 我为了方便操作,把打包好的程序移动到了桌面,并复制了一份浏览器驱动msedgedriver.exe到同一文件夹下(一定要记得,不然会无法配置)
![]()
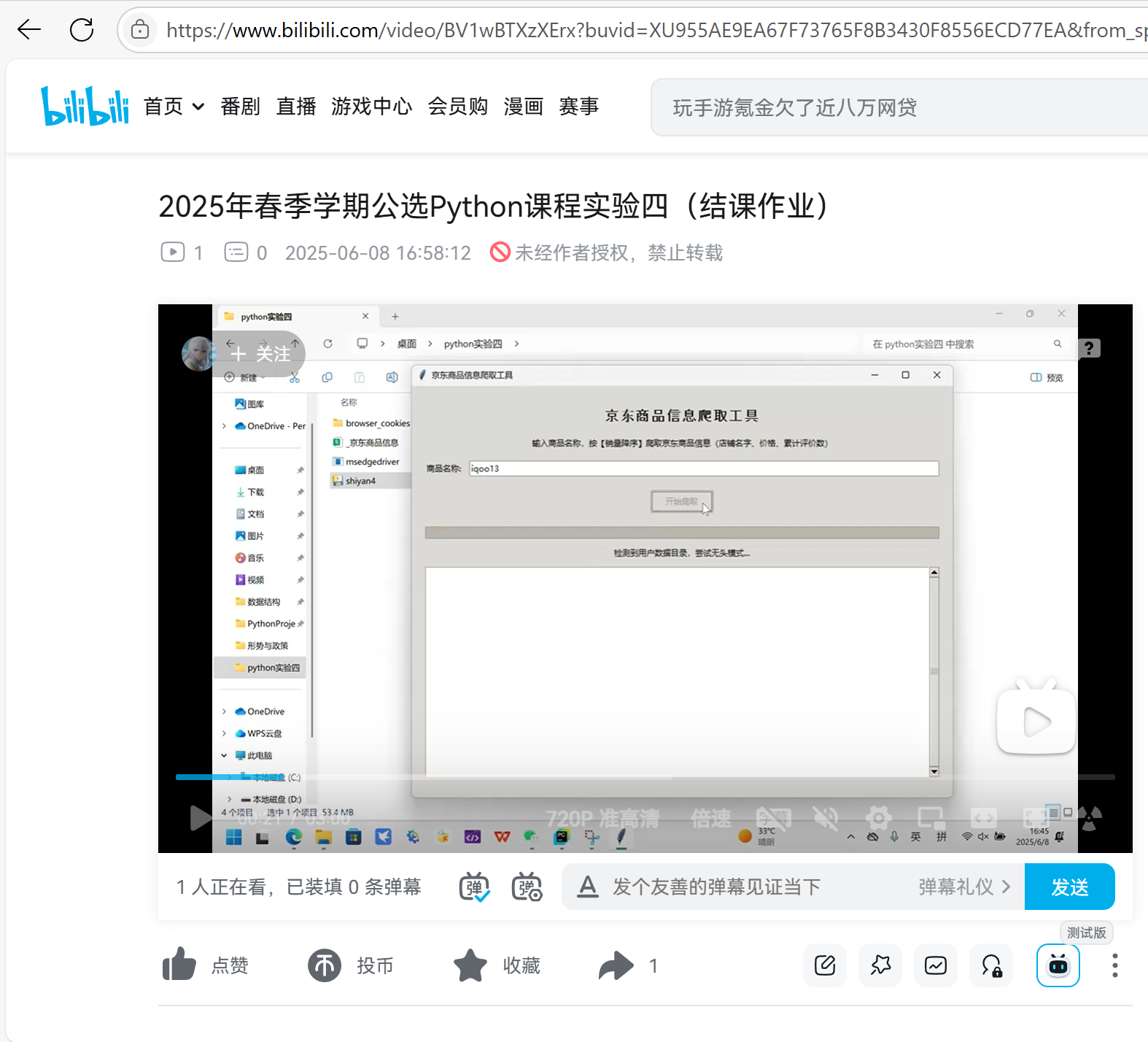
- 最后双击shiyan4.exe文件即可运行(注意首次使用需登录京东,按流程进行即可)
- 运行结果:
【2025年春季学期公选Python课程实验四(结课作业)-哔哩哔哩】 https://b23.tv/IS32VHH
![]()
- 将代码上传至码云
三. 实验过程中遇到的问题和解决过程(说实话遇到的问题太多了,导致我根本无从说起,挑几个简要的说吧)
- 问题1:刚开始参考网上的代码一直用的是无头模式运行浏览器,修改了好几回都还是反复报错,后来把无头注释掉使浏览器可视化才发现是京东等平台要求登录,不然就会一直卡在那个界面,无法进行下一步
- 问题1解决方案:用#把无头参数注释掉
![]()
- 问题2:打包为exe程序后是无法独立运行的,要把浏览器驱动和它一起放在一个文件夹下,不然就会出现以下情况,无法配置浏览器:
![]()
- 问题2解决方案:将程序与浏览器驱动放于一个文件夹下
![]()
- 问题3:刚开始时GUI界面的生成结果排列得杂乱无章,观感十分不好:
![]()
- 问题3解决方案:询问大模型了解到几种方法:对齐,等宽字体,分隔线等,然后编写代码实现:
![]()
![]()




其他(感悟、思考等)
- 感悟:相较于前几次实验,这最后一次实验是我花费心思最多的了,不同与前几次有明确的目标,最后一次实验可谓是五花八门,爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全...开始我并不知道要做什么,直到DDL的日渐临近让我有了莫大的危机感,开始了解实验的有关内容,发现同学们大多都是各种有趣的小游戏,本人没有那么多有趣的细胞,于是决定循规蹈矩,进行对电商平台的爬虫。爬虫说简单也不复杂,说难又能耗费你几天光阴,让你整日坐在方寸屏幕间与平台的反爬机制殊死搏斗。不过,当密密麻麻的数据呈现于GUI界面上时,那一刻,柳暗花明。感谢王志强老师带领我踏入python这座巍峨的大山,这学期的学习只是初窥门径,我相信,python的学习不只有代码,还有诗和远方
- 思考:这次的实验算是完成了,却仍然有很多不足之处,说难听点,这个程序还是个半成品,比如首次登陆时,我要把程序关闭后重新打开才能继续查询,研究了几天也没有对应的解决方法;又好比爬虫只能爬第一页,如何翻页也是个难题...除此之外我还想完成最初的想法————三个电商平台的价格对比,事到如今我也只成功了京东的,其他两个都各有难点需要突破

 浙公网安备 33010602011771号
浙公网安备 33010602011771号