6. RDD综合练习:更丰富的操作
集合运算练习
union(), intersection(),subtract(), cartesian()
三、学生课程分数
网盘下载sc.txt文件,通过RDD操作实现以下数据分析:
- 持久化 scm.cache()
scm=sc.textFile("sc.txt").map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])])
scm.cache()
![]()
- 总共有多少学生?map(), distinct(), count()
scm.map(lambda line:line[0]).distinct().count()![]()
- 开设了多少门课程?
scm.map(lambda line:line[1]).distinct().count()![]()
- 每个学生选修了多少门课?map(), countByKey()
scm.map(lambda line:(line[0],(line[1],line[2]))).countByKey()![]()
- 每门课程有多少个学生选?map(), countByValue()
scm.map(lambda line:line[1]).countByValue()![]()
- 多少个100分?
scm.filter(lambda line:line[2]==100).count()![]()






- Tom选修了几门课?每门课多少分?filter(), map() RDD
scm.filter(lambda line:"Tom" in line).collect()
scm.filter(lambda line:"Tom" in line).count()
![]()
- Tom选修了几门课?每门课多少分?map(),lookup() list
scm.map(lambda line:(line[0],(line[1],line[2]))).lookup("Tom")
![]()


- Tom的成绩按分数大小排序。filter(), map(), sortBy()
scm.filter(lambda line:"Tom" in line).sortBy(lambda line:(line[2])).collect()
![]()
- Tom的平均分。map(),lookup(),mean()

arr=scm.map(lambda line:(line[0],line[2])).lookup("Tom") arr np.average([int(x) for x in arr])

- 生成(课程,分数)RDD,观察keys(),values()
lines=sc.textFile("sc.txt") word1=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],line[2])) word1.keys().take(5) word1.values().take(5)![]()
- 每门分数+20分。
- 分别用mapValues(func)和 map(func)实现。
并查看不及格人数的变化。word2=word1.map(lambda line:(line[0],int(line[1]))) word2.mapValues(lambda line:line+20).foreach(print)
![]()
word2=word1.map(lambda line:(line[0],int(line[1])+20)) word2.take(5)
![]()
word1.filter(lambda line:int(line[1])<60).count() word2.filter(lambda line:int(line[1])<60).count()
![]()
求每门课的选修人数及平均分
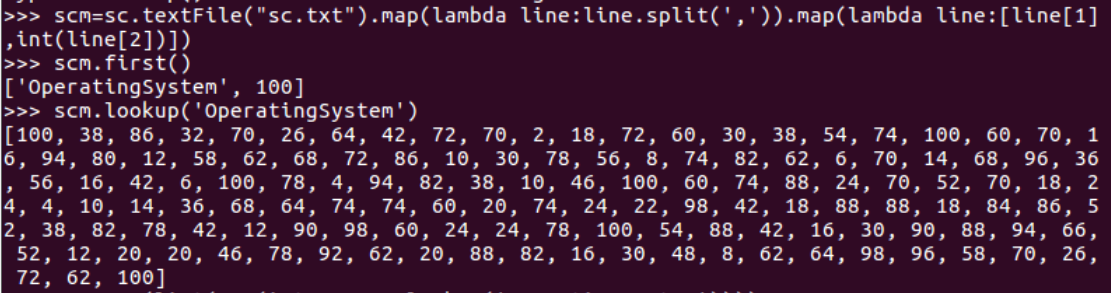
- lookup(),np.mean()实现
scm=sc.textFile("sc.txt").map(lambda line:line.split(',')).map(lambda line:[line[1],int(line[2])]) scm.first() scm.lookup('OperatingSystem') import numpy as np np.mean(list(map(int,scm.lookup('OperatingSystem'))))
![]()
![]()
- reduceByKey()和collectAsMap()实现
scm=sc.textFile("sc.txt").map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])])
words1= scm.map(lambda line:(line[1],(line[2],1)))words2 = course.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).map(lambda c:(c[0],c[1][1],round(c[1][0]/c[1][1]2)))
![]()
![]()
- combineByKey(),map(),round()实现,确到2位小数
courseC=scm.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) courseC.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).sortBy(lambda a:a[2],False).collect()
![]()
![]()
- 比较几种方法的异同 前两种方法都需要多个函数运行才可以得出平均数,并且如果要得出所有科目的平均分需要进行循环运算。第三种方法只需要一个函数就可以得出每门科目的学习人数和总分,更适用于数据量多时使用。第一种与其他两种不同的是可以直接使用numpy.mean()函数算出平均数。
- lookup(),np.mean()实现







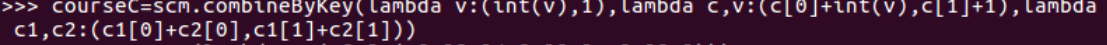


 浙公网安备 33010602011771号
浙公网安备 33010602011771号