

elasticsearch-分片思想
elasticsearch的分片思路:
最好的情况是,我们能知道自己对单个分片的要求,比如单个分片对用户的响应时间不能长于哪个值,测试的方法是使用历史数据,压入到一个测试的分片中
知道这个分片的响应速度使我们无法忍受,这时候的数据量就是单个分片的最大容量。最最好的情况下,我们有自己的最大数据目标,也就是业务的数据量天花板
用这个天花板 除以 单个分片的最大容量,也就是我们业务发展到天花板之后需要的最大物理机数量。但是实际上,我们的业务数据的天花板是不可估摸的
确定物理机数量就是个难题,当然不是说一开始就需要那么多物理机。毕竟业务也是由小到大发展,机器集群也是由小到大发展。
elasticsearch官方给出 对于分片的声明是:
分片不应该分裂,而是一开始就存在,之后的水平扩展中只是简单地将分片复制到另一台物理机上。

比如上图,一开始就确定了业务只有两个主分片,之后向集群添加物理机 (或者虚拟机)NODE 2 之后,主分片P1只是简单地复制到 NODE2 上
为什么不是使用分裂呢?如下图 P0 容量达到某个上限之后 将 P0分裂成两个分片,P00 和 P01 分别存入 NODE1 和 NODE2
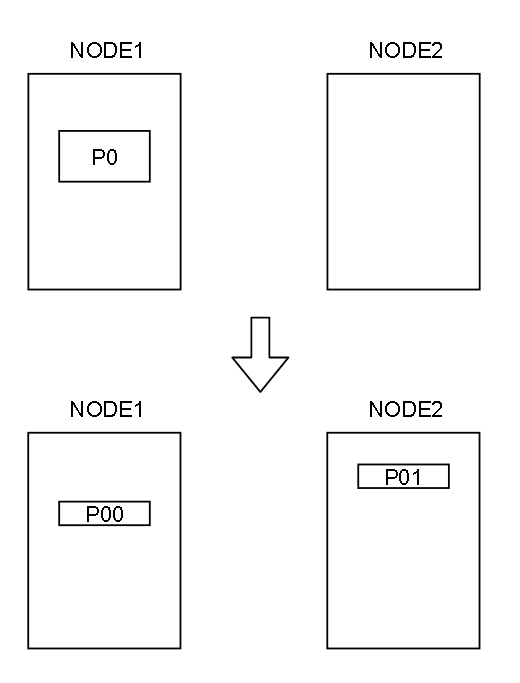
需要注意的是,如果分裂分片,需要对正排索引 和 倒排索引 进行分裂。
正排索引还好说,因为类似与关系型数据库,可以采用分表的思想分出去,但是倒排索引的内容可能关乎整个分片
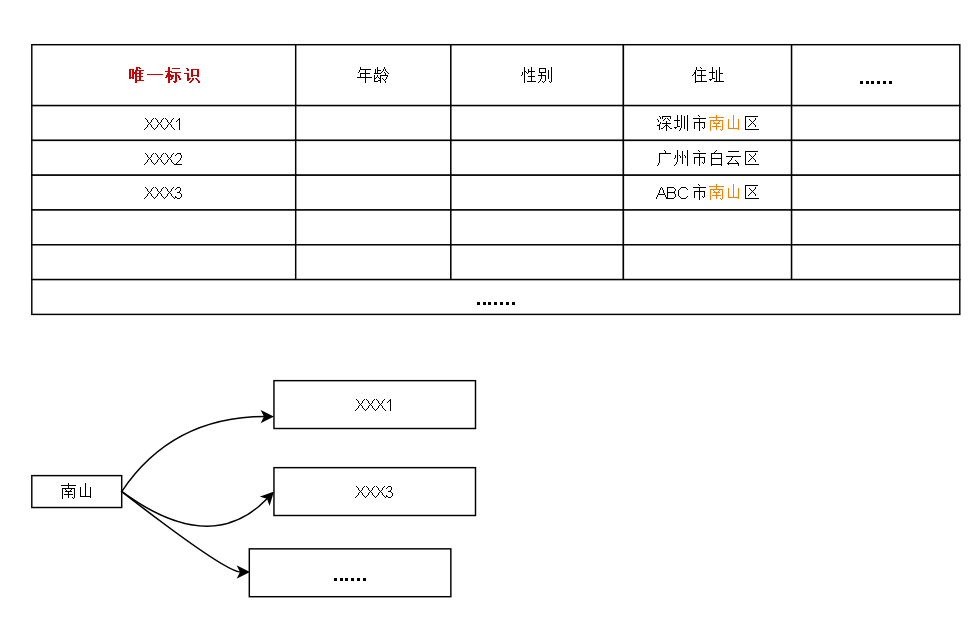
拿上一篇的图来距离,“南山” 这个 term 可能会联系到 正排索引中 任意一行,如果要分裂正排索引,那么需要根据分裂后的正排索引重新构建倒排索引
然而,日积月累存下来的数据要一次性全部重新构建倒排索引,可想而知对硬件消耗之大!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号