Hadoop架构: 流水线(PipeLine)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
流水线(PipeLine),简单地理解就是客户端向DataNode传输数据(Packet)和接收DataNode回复(ACK)[Acknowledge]的数据通路。
整条流水线由若干个DataNode串联而成,数据由客户端流向PipeLine,在流水线上,假如DataNode A 比 DataNode B 更接近流水线
那么称A在B的上游(Upstream),称B在A的下游(Downstream)。
流水线上传输数据步骤
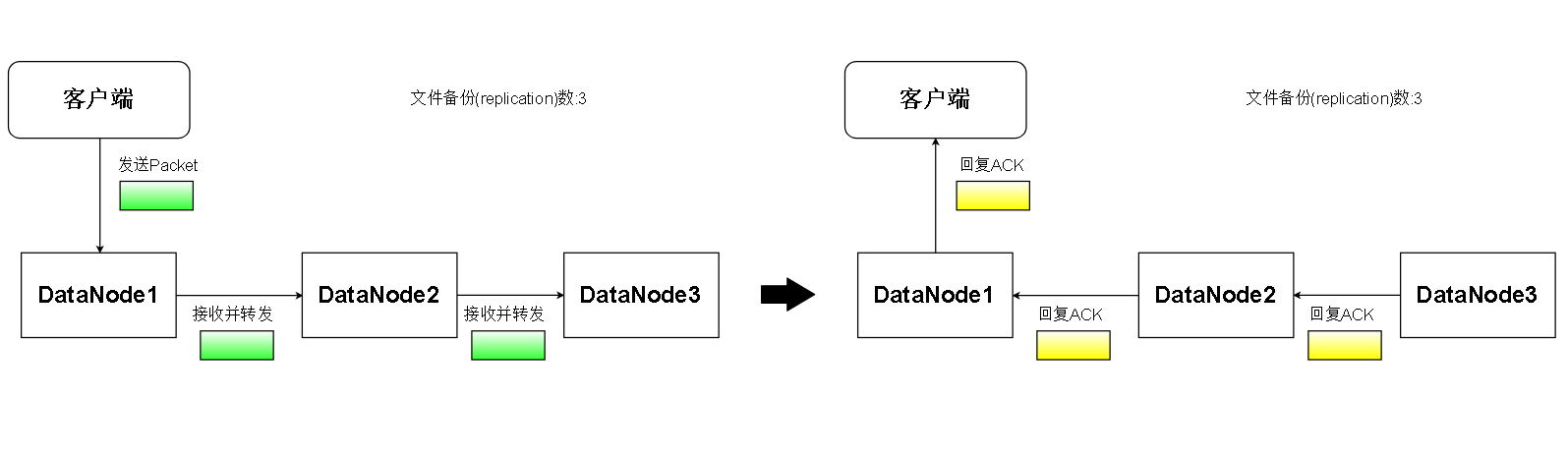
1. 客户端向整条流水线的第一个DataNode发送Packet,第一个DataNode收到Packet就向下个DataNode转发,下游DataNode照做。
2. 接收到Packet的DataNode将Packet数据写入磁盘
3. 流水线上最后一个DataNode接收到Packet后向前一个DataNode发送ACK响应,表示自己已经收到Packet,上游DataNode照做
4. 当客户端收到第一个DataNode的ACK,表明此次Packet的传输成功
一.流水线基础概念
流水线就像一条水管,数据(Packets)从一端流进去,依次经过流水线上的各个DataNode。
回复(ACK)则是相反,ACK从最后一个节点依次向前传递,流回客户端
多么艺术的设计!
但是,有一个问题,要知道,若干个Packet才能传输完一个Block,并且多个Block组成一个文件
所以从文件或者Block的角度来看,即使每台机器的效率接近,也可能出现流水线不均匀的情况(接收文件数据量不均匀)
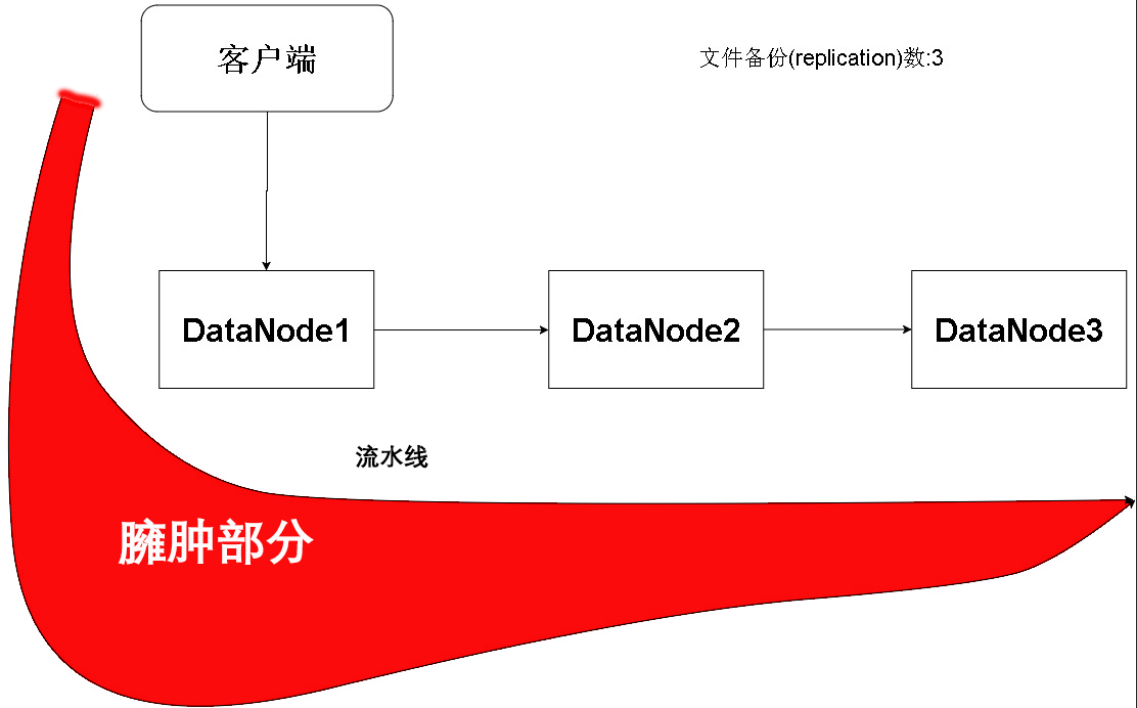
出现的情况往往是第一个节点接收的数据量最多,其后的节点递减,所以我们可以考虑把第一个DataNode选为性能较好的节点,或者是离客户端尽可能近的节点。但实际上,节点的选择是由NameNode根据机架感知等技术实现的。并且客户端的流水线节点选取是由NameNode决定的。
还有一个问题。HDFS是支持一写多读机制的,意味着在流水线上的DataNode(正在被写)允许被其他客户端读取(Reader 以下均称此类读客户端为Reader)。这样就会产生读的不一致性,比如说我在流水线上游的某个DataNode中读到“武汉加油!”这条数据,但是去下游的DataNode读,却读不到。这是因为下游的DataNode可能还没收到数据。

虽然说一般客户端只会读取一个DataNode的信息,但如果被读取的DataNode宕机,那么客户端就要另选DataNode,可能造成前后数据不一致。
或者有多个客户端需要根据对方的数据协调工作,每个客户端读的不是一个DataNode,那么对同一读取目标,读出来的数据不一致。这种水平上的不一致可能也会导致业务出错。
那么,怎么解决呢?
二.流水线读一致性设计
我们先来定义一下概念
首先提出问题,在流水线中的某个DataNode,怎么样判断自己的数据是否可以给Reader读取。
就比如上面那张图,不能一致性读的原因是下游的DataNode3没有接收到DataNode1已经接收的Packet。那么如果DataNode1确定DataNode3已经接收到Packet了,那不就能放心地把Packet的数据给Reader了吗?就算Reader再去DataNode3读,也会读到同样的数据,而不会出现数据找不到或者数据不一致的情况。
于是有了定义:对于一个数据块,一个DataNode接收到的数据为DR(Data Received),根据下游收到的ACK,已被下游确认接收的数据为DA(Data Acknowledged)
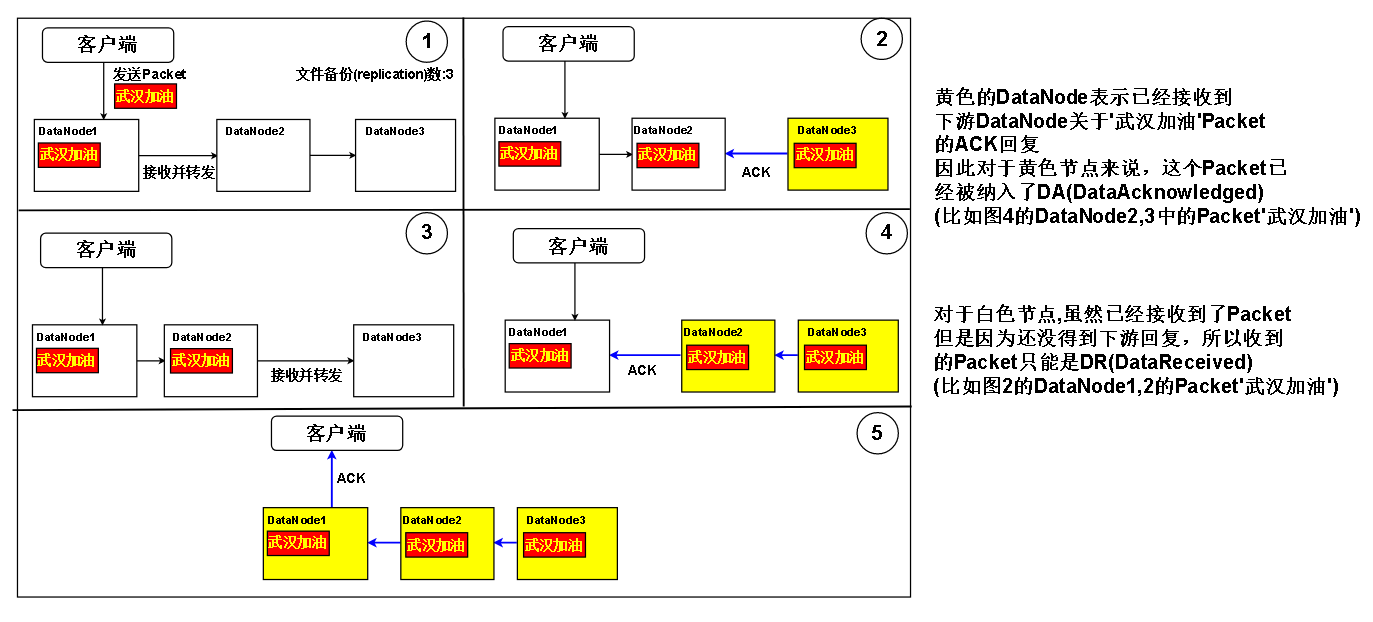
顺便定义:对于 i 节点的DA是DAi , DR是DRi , 对于客户端,客户端发出去的数据为CS(Clent Send) ,而客户端确认的数据为CA(Client Acknowlege)
DA和DR其实是一个增量的概念,并且针对的是一个Block。下图是一个DataNode中的Replica(Block在DataNode中称为Replica,强调是Block的副本)在逐渐被写满的过程

我们可以分析一下,整个流水线上,各个节点的DR和DA的走势
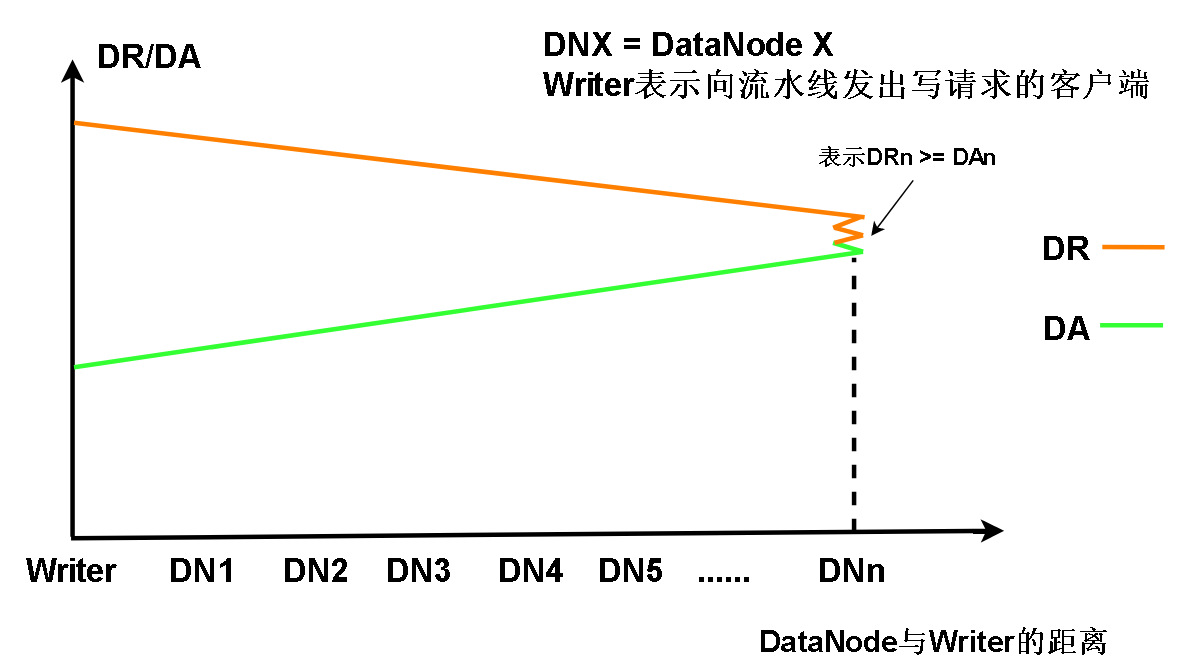
以及从图形上看,DR和DA在一来一回的流水线上的分布情况
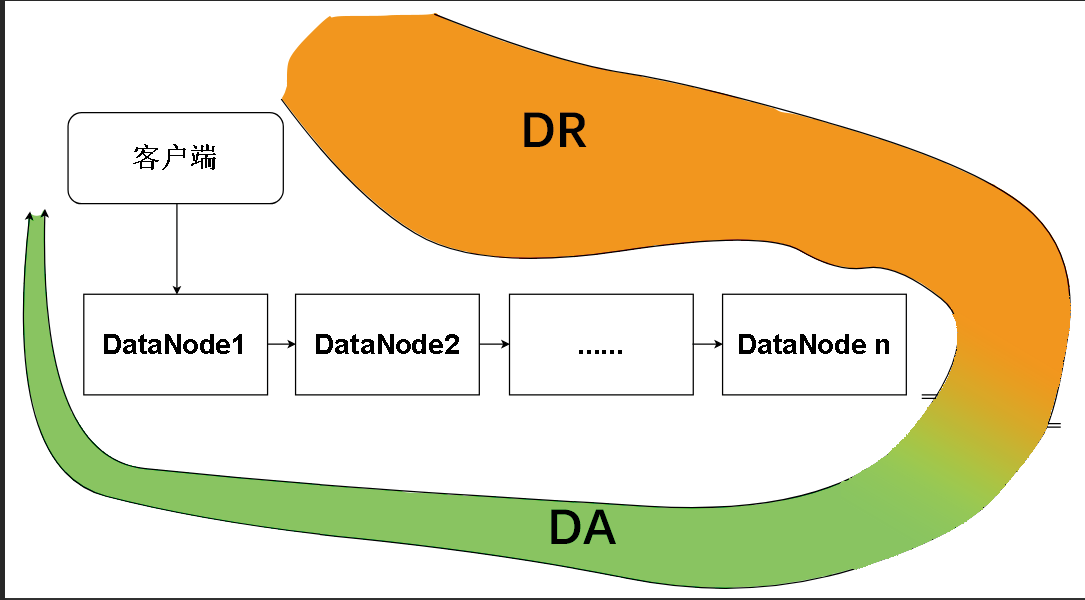
我们发现Writer发送数据(第一个DataNode的DR)最多,但是确认了的数据DA最少,原因是Packet和ACK在流水线一来一回需要路程时间
Reader直接访问一个DataNode中Replica的数据时,需要提供四个数据<BlockId,BGS(Block Generation Stamp 可以理解成Block的版本号) , offset, len>
BlockId 和 BGS 用来识别一个Block,当DataNode中不存在指定BlockId的Replica或者Replica的BGS比Reader给出的BGS旧,那么DataNode将拒绝这次读请求
offset 表示Reader将从哪里开始读取数据,len表示欲读取的数据长度,因为DA是线性增长的,所以只要保证 offset + len <= DA ,DataNode就允许这次读请求(当然offset 和 len 都大于0)
具体怎么做才能实现呢?有两种做法。
做法一,当其他应用请求一个Reader客户端读取数据的时候,Reader会向将要读的DataNode发送请求,询问DataNode的DA。如果应用请求的数据规模(offset + len)大于DA,那么将抛出异常
否则,Reader将获取DataNode的Min(DR, offset + len)长度数据放到缓存Q中,并且安全地返回 off + len 数据给应用,随后Reader监听这个DataNode的DA的变化,直到应用放弃对文件的读取。如果DA增加,表示Reader能从缓存Q中读到的最大数据量增加,也就是offset + len能达到更大的值。当读取任意一个DataNode P,假设他的DA是m,如果这个DataNode刚好宕机,1. Reader转而访问上游的DataNode,上游DataNode的DR比下游的DR大,随着时间的推迟,上游DataNode会把整个DR暴露给Reader,其中包含下游DR的数据,下游的数据在上游仍然能访问。2.Reader转而访问下游的DataNode,下游的DataNode的DA比P的要大,所以在P读到的数据在下游中仍然找得到。一致性读达成。
这种做法的缺点是客户端的代码和算法实现复杂,要时刻监听DA的变化。
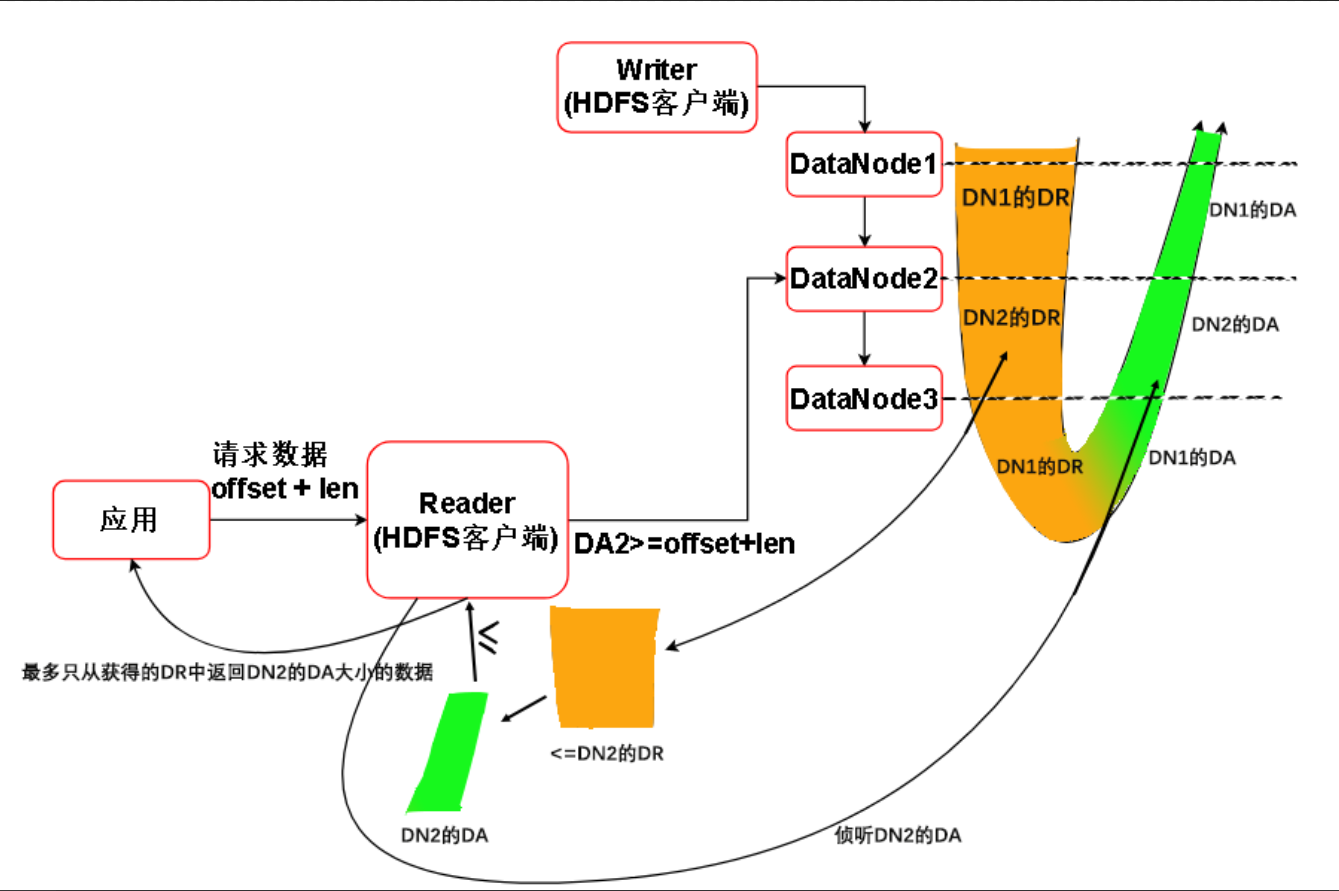
做法二,为了更清楚地描述,分一下步骤
1.Reader向DataNode a发出<BlockId,BGS(Block Generation Stamp 可以理解成Block的版本号) , offset, len>,DataNode a的DA必须大于等于offset + len
2.读取的请求不是发给DataNode a,而是将请求发给另外一个DataNode b
3.如果
1.offset + len <= DAb,那么可以安全地返回数据
2.如果offset + len > DAb ,因为DAa >= offset + len > DAb。所以DAa > DAb,所以b在a的上游,所以DRb > DRa,所以在b上有a已经ACK了的数据。所以b也可以安全地返回offset + len的数据给Reader
3.如果offset + len > DRb,那么将抛出异常。
虽然上述步骤2访问了DR,但是DR中被访问的数据已经在下游被ACK了,只是Reader自己移动到了上游去找数据。
当前访问的DataNode a如果宕机
1.向下游读,下游的DA大于上游,故在上游的数据一般能在下游找得到,经过步骤1将数据返回
2.向上游读,因为之前已经规定好,只能访问offset + len范围的数据,并且上游的BR总是包含DAa,所以 offset + len 长度的数据总是能在上游找到。
一致性读解决
做法二虽然简单但是要访问两个节点。网络上的切换的开销不小。
具体HDFS实现了哪一个,需要看版本决定,笔者暂时还没有找到官方给定哪些版本实现哪种方案和研究源码,日后填坑。
三.流水线的生命周期
1.流水线被建立(Setup) : 客户端Writer通告NameNode获得Block信息,通知信息里locations(Replica所在)包含的DataNode,告知这些DataNode将要创建一条流水线,DataNode收到后会回复。
2.数据传输(DataStream) : 当Writer在步骤1接收到如数的DataNode的回应后,流水线正式创建,Writer能够在流水线上以Packet为单位传输数据。
3.恢复(Recovery) : 恢复分三种情况 : 1.流水线创建时失败 2.流水线传输过程失败 3.流水线关闭失败
4.关闭(Close) : 当一个块被写满,Writer将通知DataNode流水线关闭,DataNode可以将块的状态设置为FINALIZED并且DataNode向NameNode汇报
四.流水线的建立
流水线建立的时机:
1.客户端请求新建一个Block,需要新建流水线,以便将新Block的数据写入到DataNode的Replica里
2.客户端请求打开一个文件并且对这个文件进行append操作,这个文件末尾的最后一个块如果没有满,那么所有拥有这个Block的Replica的DataNode将被连起来成为一条流水线,以便对这些没写满的Replica进行追加,(其实是对Block进行追加)
3.在恢复过程中需要建立流水线
流水线建立流程:
客户端的行为:
1.客户端首先需要询问NameNode相关信息,比如对应Block的Replica在哪,Block的BGS和ID等信息。如果流水线的建立的是为了恢复流水线,或者文件被打开用来append,那么客户端还会为Block向NameNode申请新的BGS。
2.根据1中获取的信息,客户端试图和流水线的第一个DataNode通过Socket建立连接。
3.客户端将1中获得的信息发布到流水线上,告知线上的DataNode,该Block对应的Replica需要被操作。
发送的信息具体按流水线的用途分为:
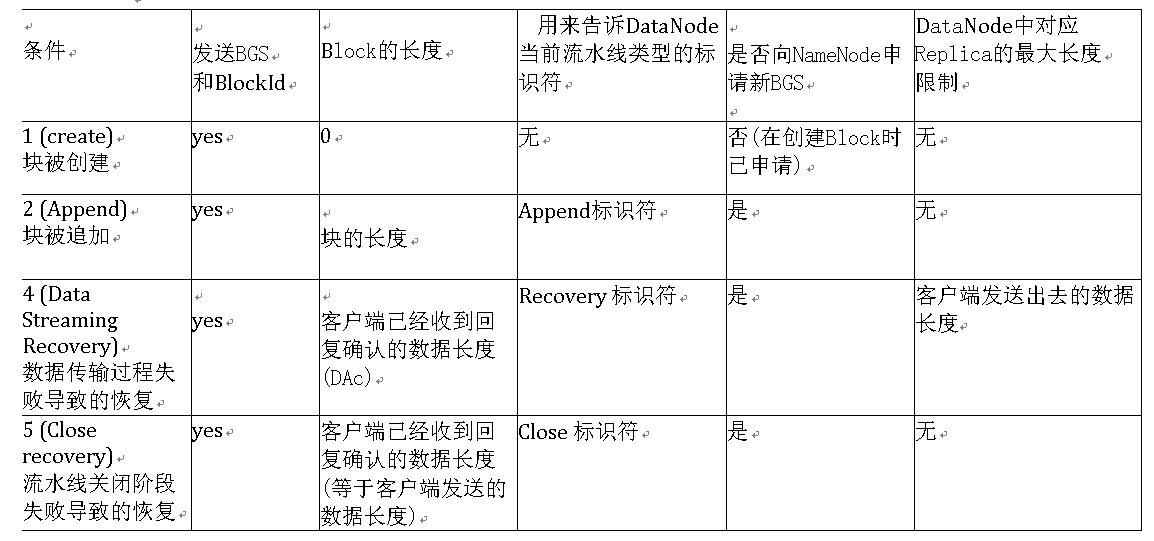
DataNode行为:
.1.当DataNode从3中得知信息后,将按情况进行如下操作
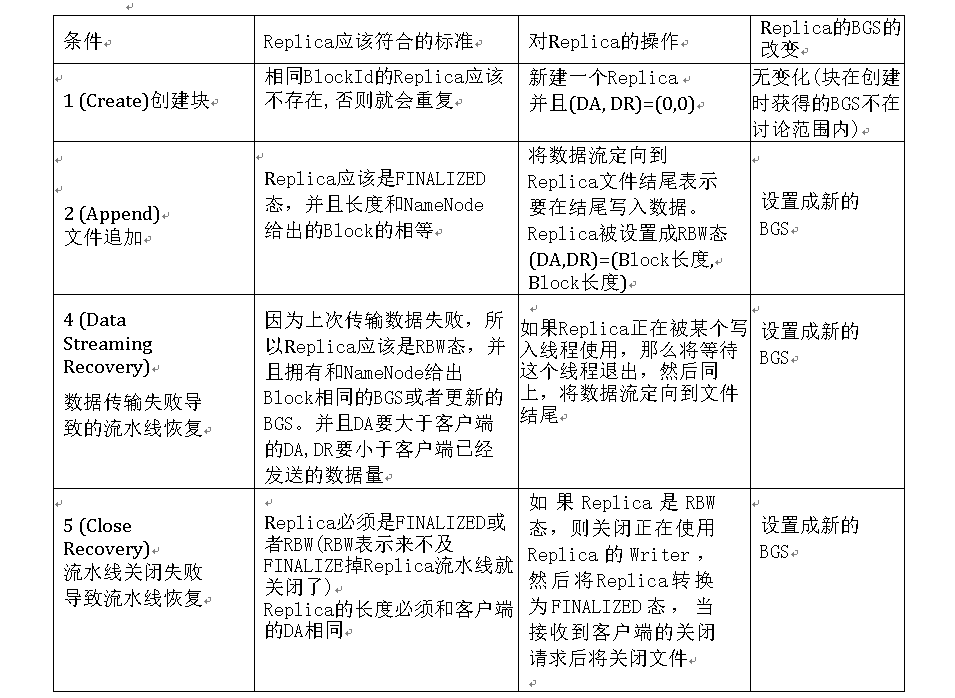
最后一步:
如果建立的流水线是用来恢复或者Append的,那么将会通知NameNode,流水线完成,告知NameNode更新流水线信息(块的位置等)。
重新架构流水线:
如果上述所有步骤不成功,则会重新建立流水线(进行流水线恢复)。
五:流水线的恢复
请见:Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号