集合~面试
| 为什么在面向对象编程时不用数组用集合? |
- 主要原因:数组长度固定,集合长度可变。
- 数组可以存放基本数据类型和引用数据类型,集合存储的元素必须是引用数据类型。

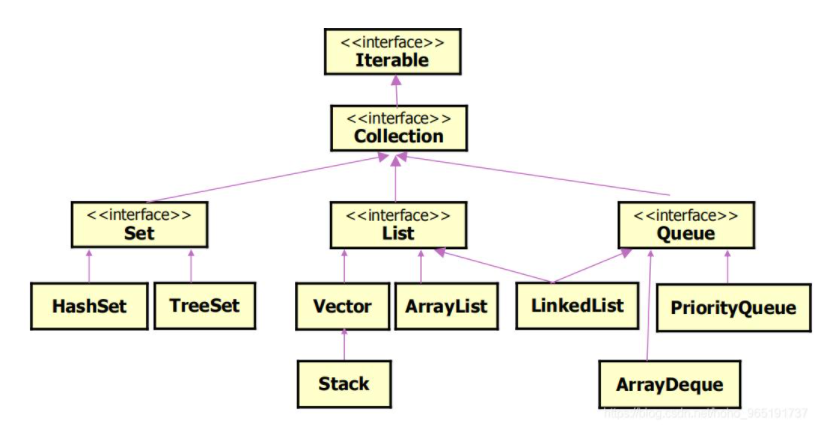
- Java提供了一个集合框架,该框架由 Collection 接口和 Map接口组成,Collection用于存放一组对象,Map存放键值对。
| 数据结构 |
- 堆栈:先进后出
- 队列:先进先出
- 数组:通过索引查找速度快,增删元素慢
- 链表:查找速度慢,增删快
- 哈希表:查找、存储都比较快
| List 接口及实现类 |
- List是Collection的子接口,实现一种线性表的数据结构。
- 所有元素都有下标索引,从0开始,通过索引访问元素。
- 元素有序,可以重复。
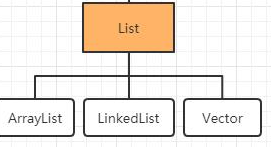
- ArrayList是最常用的集合,是通过数组实现的集合对象,所以它的查找速度快。
- Vector集合数据存储也是数组,但是它是同步的也就是线程安全的,也就比ArrayList查找的速度慢,已经被ArrayList取代。
- LinkedList集合数据存储的结构是链表结构,方便元素增加删除。

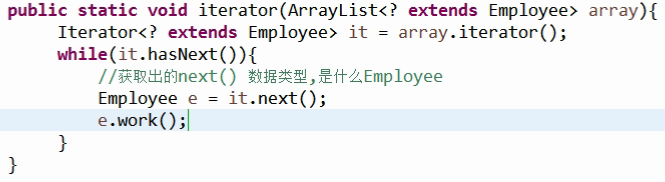
| 泛型:有界类型参数 |
- 通配符 ?
//该方法可以传入任意类型的List对象
public sstatic void printList(List<?> list){
for(Object obj : list){
sout(obj);
}
}
- 有时候需要限制传入参数的类型,例如,要求一个方法只能接收Number类或其子类的实例,这时就需要使用有界类型参数
//上界限定,只能传入Number对象或其子类对象
List<? extend Number> numberList
//下界限定,只能传入Number对象或其父类对象
List<? super Number> numberList
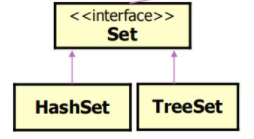
| Set 接口及实现类 |
-
Set接口是Collection接口的子接口,不允许有重复数据
-
HashSet具有最好的存取性能,但元素没有顺序,允许null元素。实际是HashMap实例。
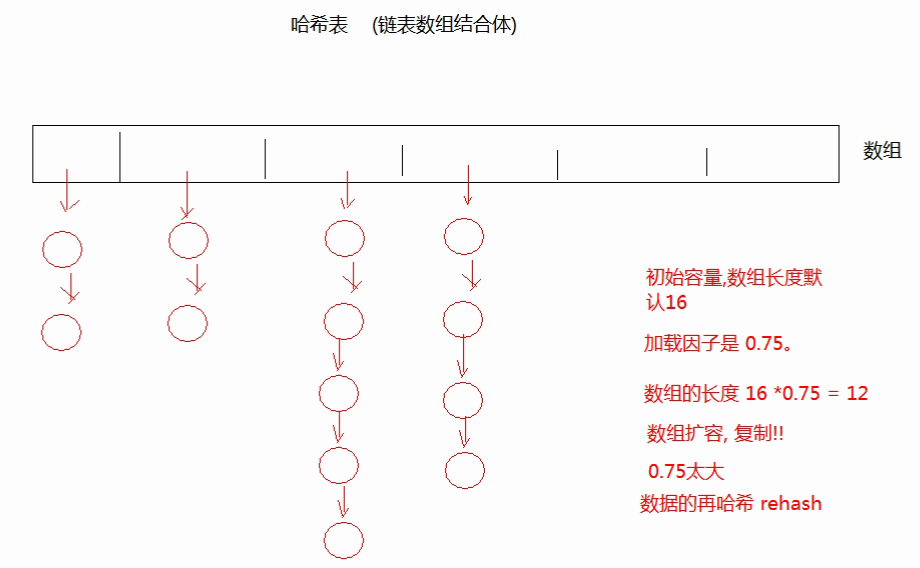
- String重写hashCode()方法

- 哈希表:保证 Set 集合没有重复元素。
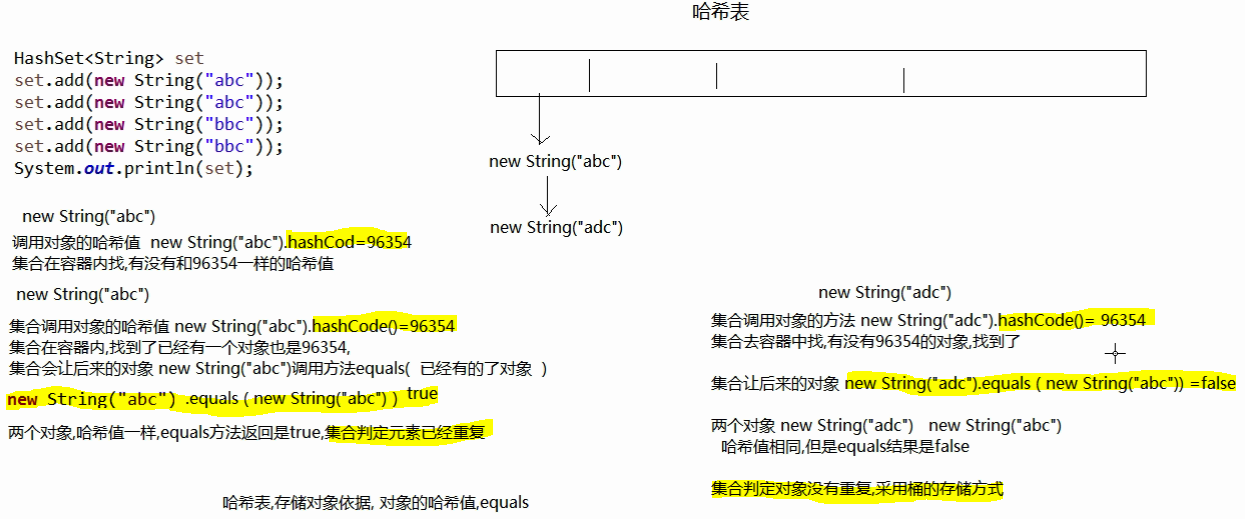
- hashCode协定

- String重写hashCode()方法
-
LinkedHashSet是HashSet的子类,元素有顺序
-
TreeSet实现一种树集合,使用红黑树为元素排序,元素必须可比较。
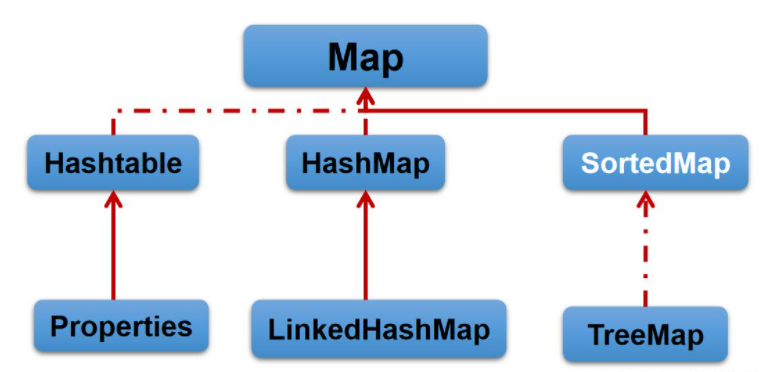
| Map 接口及实现类 |
-
将键映射到值的对象,关键字和值都必须是对象,键唯一,值可以重复。
-
常用实现类HashMap,子类LinkedHashMap。
- 实现原理:
- JDK7:new HashMap() 底层创建长度16的Entry[]数组。计算 key 的哈希值,找到存储位置,位置上没有元素则添加成功;有元素,比较哈希值是否相等,不等添加成功,相等则调用equals()方法,不相等添加成功,相等则覆盖。
- JDK8:new HashMap() 底层创建Node[]数组,使用put()方法时指定长度16,底层结构:数组+链表+红黑树,当数组某一索引上链表元素>8且数组长度>64,此索引上数据使用红黑树存储
- 实现原理:
-
TreeMap类保证键值对按关键字升序排序
-
HashTable已经被HashMap取代,HashMap线程不安全,键值都可以为null,但是HashTable的子类Properties集合还在使用,经常和“流”结合使用
-
遍历方法keySet(),返回键的Set集合;也可以使用entrySet()方法返回Set<Map.Entry<K,V>>集合,Map.Entry<K,V>的方法getKey()、getValue()。
作 者:凑数的园丁
出 处:https://www.cnblogs.com/lq-404/
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主: 如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号