
druid.io使用技术简介: Hyperloglog
druid.io 使用Hyperloglog 估计基数
参照如下连接
http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-part-i.html
http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-part-ii.html
http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-part-iii.html
http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-part-iv.html
基数估计算法就是使用准确性换取空间。为了说明这一点,我们用三种不同的计算方法统计所有莎士比亚作品中不同单词的数量。请注意,我们的输入数据集增加了额外的数据以致比问题的参考基数更高。这三种技术是:Java HashSet、Linear Probabilistic Counter以及一个Hyper LogLog Counter。结果如下:
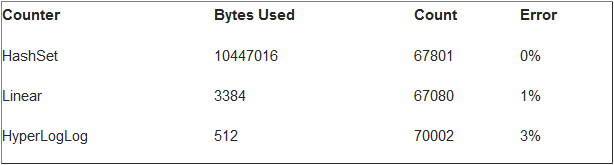
该表显示,我们统计这些单词只用了512 bytes,而误差在3%以内。相比之下,HashMap的计数准确度最高,但需要近10MB的空间,你可以很容易地看到为什么基数估计是有用的。在实际应用中准确性并不是很重要的,这是事实,在大多数网络规模和网络计算的情况下,用概率计数器会节省巨大的空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号