
hadoop fs -mkdir -p /lpptext
hdfs dfs -put /opt/soft/hivetext.txt /text
在hive中创建数据库
create database lppdata;
创建数据库后根据自己的数据字段进行创建外部表
create external table ods_data(
name string,
id int,
addr string,
type string,
rank string,
acaddr string
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/dwd/dwd_data' ;
从hadoop本地文件传输到hive中
load data local inpath '/opt/soft/x.txt' overwrite into table ods_data;
inpath后写的是hadoop本地文件的路径
中文乱码的解决办法
-
ALTER TABLE ods_data SET SERDEPROPERTIES (‘serialization.encoding’=‘GBK’);
-
利用工具将文件的格式转化为utf-8格式
FAILED: 执行hql语句时产生 Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask问题
-
查看yarn日志
-
我是从网上百度筛选出对我有用的一个解决办法
-
执行hadoop classpath,在yarn-site.xml中加如下内容
-
<property> <name>yarn.application.classpath</name>
<value>classpath(刚才显示的classpath的内容)</value></property>
编写shell脚本
-
对本次的数据分析由于我得到的数据如下:
-
我想统计出各区的有评级的数据并进行数量的统计
![]()
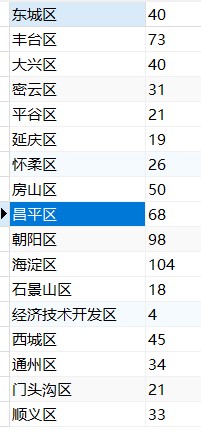
具体的是实现过程如下:
-
ods表(原先的数据)
-
dwd(经过空数据处理,以及剔除不需要的信息的字段、筛选出已经评级的医院信息)
-
ads(将生成的已评级的医院数量进行统计,并且进行对应各区相应数量)
-
dwd层先进行创表
create external table dwd_data(
name string,
addr string,
rank string,
acaddr string
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/dwd/dwd_data' ;
create external table dwd1_data(
name string,
addr string,
rank string,
acaddr string
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/dwd/dwd1_data' ;
-
编写脚本
#!/bin/bash
hive_db=lppdata
hive=/opt/module/hive/bin/hive
sql="
insert overwrite table "$hive_db".dwd_data
select * from "$hive_db".ods_data
where name !='none'
and id !='none'
and addr !='none'
and type !='none'
and rank!='none'
and addr!='none'
"
$hive -e "$sql"
保存为ods_data.sh 在当前脚本的目录下赋予该执行权限:chmod +x ods_data.sh 然后进行执行
-
脚本二 剔除未评级的数据
#!/bin/bash
hive_db=lppdata
hive=/opt/module/hive/bin/hive
sql="
insert overwrite table "$hive_db".dwd1_data
select * from "$hive_db".dwd_data
and rank!='\u672a\u8bc4\u7ea7'
"
$hive -e "$sql"
-
ads层:主要思路是创建两个表,一个表统计数字,一个表统计区名,再进行表连接生成到一个新的表中
create external table ads1_data(
addr string
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/ads/ads1_data' ;
create external table ads2_data(
sum int
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/ads/ads2_data' ;
create external table ads3_data(
addr string,
sum int
)
row format delimited fields terminated by '\t'
location '/warehouse/lppdata/ads/ads3_data';
-
脚本编写
#!/bin/bash
hive_db=lppdata
hive=/opt/module/hive/bin/hive
sql="
insert overwrite table "$hive_db".ads1_data
select distinct addr from "$hive_db".dwd1_data
"
$hive -e "$sql"
#!/bin/bash
hive_db=lppdata
hive=/opt/module/hive/bin/hive
sql="
insert into table "$hive_db".ads2_data
select count(addr) from "$hive_db".dwd1_data group by addr
"
$hive -e "$sql"
#!/bin/bash
hive_db=lppdata
hive=/opt/module/hive/bin/hive
sql="
insert overwrite table "$hive_db".ads_data
select * from "$hive_db".ads1_data left join "$hive_db".ads2_data on "$hive_db".ads1_data
"
$hive -e "$sql"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号