

[已完善]pytorch实现简单的径向基网络
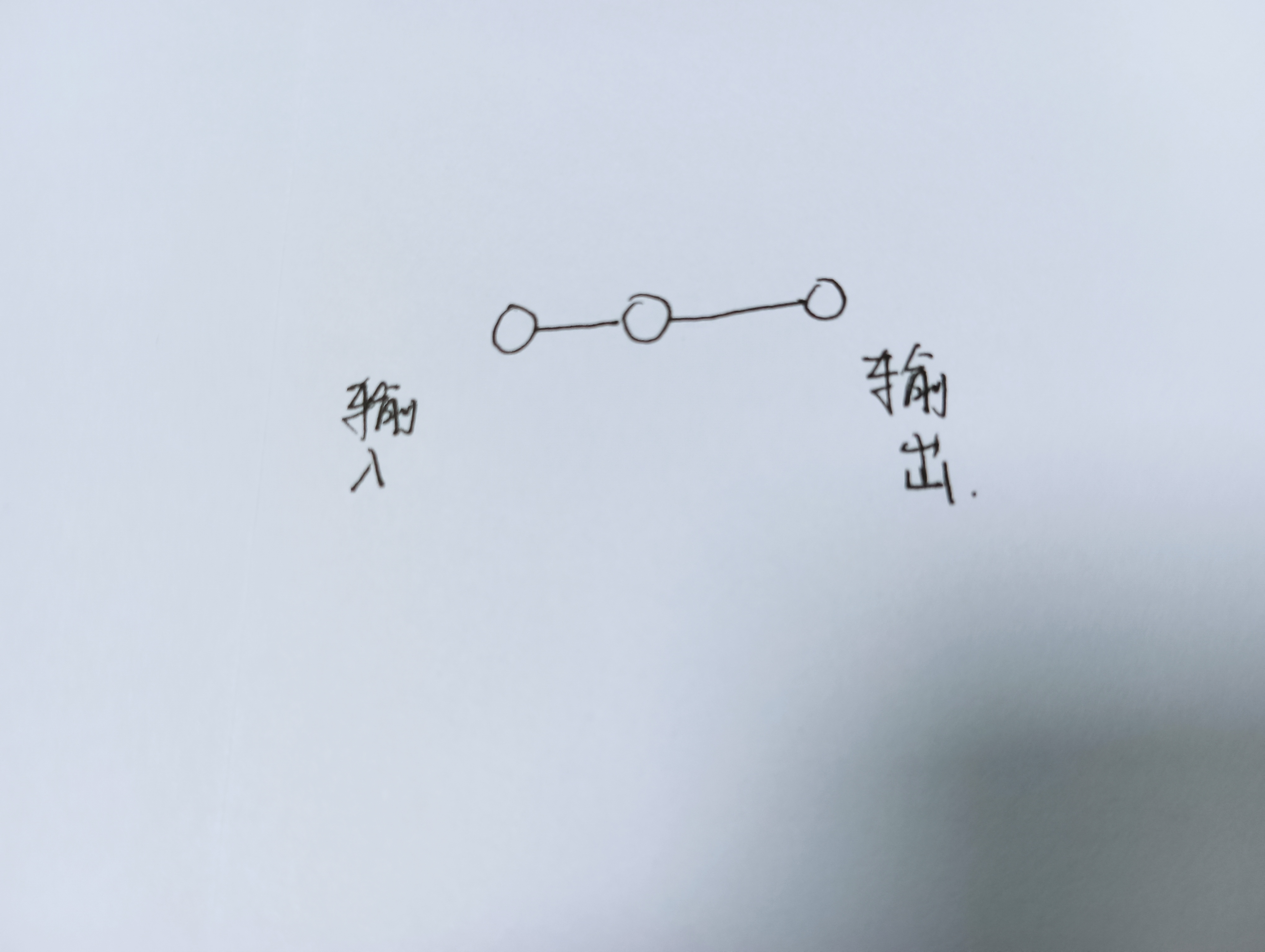
网络只有三个节点,如下图
用来拟合一个函数,如下图
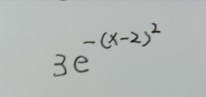
数据如下
x为[[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12],[13],[14],[15]]
y为[[1.103638323514327], [3.0], [1.103638323514327], [0.054946916666202536], [0.0003702294122600387], [3.3760552415777734e-07], [4.166383159489206e-11], [6.958568490730709e-16], [1.5728656990090393e-21], [4.811432671645914e-28], [1.9919031598742206e-35], [1.1160227928062509e-43], [8.462310265380405e-53], [8.683920934944901e-63], [1.2060180647230065e-73]]
这些数据用这个代码生成:
import math a = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] b = [] def yunsuan(a,b): for i in range(len(a)): b.append(math.exp(-(a[i]-2)**2)*3) return b print(yunsuan(a,b))
搭建及训练网络的代码参考网址:https://www.pythonheidong.com/blog/article/608644/9530a7202e0ab840d104/
如下:
#1,导入包 import torch, random import torch.nn as nn import torch.optim as optim #2,设置随机数种子 torch.manual_seed(42) #3,搭建神经网络类 class RBFN(nn.Module): """ 以高斯核作为径向基函数 """ def __init__(self, centers, n_out=1): """ :param centers: shape=[center_num,data_dim] :param n_out: """ super(RBFN, self).__init__() self.n_out = n_out #这个是输出维度?? self.num_centers = 1#centers.size(0) # 隐层节点的个数 self.dim_centure = 1#centers.size(1) # 这个centers是隐藏层?,num是节点的话,dim是该节点处的维度吗? self.centers = nn.Parameter(centers) #nn.parameter的作用是设置网络参数??,centers变成了模型的一部分 self.beta = torch.ones(1, self.num_centers) #生成一行有八个值为10的张量 #self.beta = nn.Parameter(self.beta) # 对线性层的输入节点数目进行了修改 self.linear = nn.Linear(self.num_centers, self.n_out, bias=True) #不懂这里为什么输入不是num self.initialize_weights()# 创建对象时自动执行,初始化权重 def kernel_fun(self, batches): n_input = batches.size(0) # number of inputs,0代表行数 A = self.centers.view(self.num_centers, -1).repeat(n_input, 1, 1) #view成num_centers行,然后再重复n_input次 B = batches.view(n_input, -1).unsqueeze(1).repeat(1, self.num_centers, 1) #A是中心,B是数据 #把batches展开成n_input行, #unsqueeze添加一个维度 C = torch.exp(-self.beta.mul((A - B).pow(2).sum(1, keepdim=False))) #pow是2次方, #sum(2, keepdim=False),False不保存原来的维度,2是按照第二维度进行求和后用false去掉多余维度 return C def forward(self, batches): radial_val = self.kernel_fun(batches) class_score = self.linear((radial_val)) #linear这一行,是只定义输入?? return class_score def initialize_weights(self, ): """ 网络权重初始化 :return: """ for m in self.modules(): #modules负责返回所有的modules if isinstance(m, nn.Conv2d): #isinstance是一个内置函数,用于判断一个对象是否是一个已知的类型 m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.ConvTranspose2d): #转置卷积 m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.Linear): #线性 m.weight.data.normal_(0, 0.02) m.bias.data.zero_() def print_network(self): num_params = 0 for param in self.parameters(): num_params += param.numel() #numel统计模型参数量,tensor里的每个元素算一个 print(self) print('Total number of parameters: %d' % num_params) if __name__ =="__main__": #4,数据 data1 = torch.tensor([0.25], dtype=torch.float32) data = torch.tensor([[1],[2],[3],[4],[5], [6],[7],[8],[9],[10],[11],[12],[13],[14],[15]], dtype=torch.float32) label = torch.tensor([[1.103638323514327], [3.0], [1.103638323514327], [0.054946916666202536], [0.0003702294122600387], [3.3760552415777734e-07], [4.166383159489206e-11], [6.958568490730709e-16], [1.5728656990090393e-21], [4.811432671645914e-28], [1.9919031598742206e-35], [1.1160227928062509e-43], [8.462310265380405e-53], [8.683920934944901e-63], [1.2060180647230065e-73]], dtype=torch.float32) #5,设置网络 centers = data1 #data1就是中心参数 rbf = RBFN(centers,1) #设置中心参数 params = rbf.parameters() loss_fn = torch.nn.MSELoss() optimizer = torch.optim.SGD(params,lr=0.1,momentum=0.9) #6,训练网络 for i in range(10000): optimizer.zero_grad() #1,梯度归零 y = rbf.forward(data) #2,前向传播 loss = loss_fn(y,label) #3,求损失函数 loss.backward() #4,反向传播 optimizer.step() #5,对参数进行更新 print(i,"\t",loss.data) # 7,加载使用 y = rbf.forward(data) print("预测值") print(y.data) print("真实值") print(label.data) print("网络的参数") print(rbf.state_dict())
最后计算出的网络的参数如下:
网络的参数
OrderedDict([('centers', tensor([2.])), ('linear.weight', tensor([[3.]])), ('linear.bias', tensor([-1.9980e-08]))])
比较符合原函数。
注意:这个代码不是通用的,用它去拟合其他函数就会有些问题,比如网络的输出全为Nan,或者与原函数的参数不太一样。具体原因我也不是很清楚。
比如用来拟合这个函数就会有问题
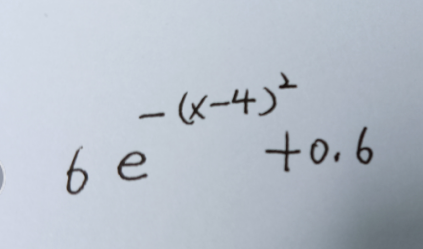
把beta变成参数再拟合其他的一些函数也会有问题,如下面两个函数
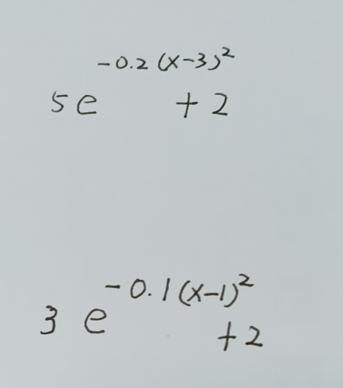
################
问题解决了,学习率调小就可以了,我真是个小傻子。
学习率调成0.01就可以了,如果还不行,就调成0.001,管用得很。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号