爬虫 1 requests 、beautifulsoup
1.requests
1.method
提交方式:post、get、put、delete、options、head、patch
2.url
访问地址
3.params
在url中传递的参数,GET
params = {'k1':'v1','k2':'v2'} params = ‘k1=v1&k2=v2’ params = [('k1','v1'),('k2,'v2')]
4.data
在请求体内传递的参数
data = {'k1':'v1','k2':'v2'} data = ‘k1=v1&k2=v2’ data = [('k1','v1'),('k2,'v2')] data = open('file','rb')
5.json
在请求体内传递的参数
JSON serializable Python object
参数经过序列化,意味着可以传递字典内嵌套字典等
6.headers
请求头
headers = { 'referer':上次浏览的页面
'user-agent':用户使用的客户端类型
...
}
7.cookies
即cookie
字典类型或CookieJar object类型,在请求头中传递
8.files
文件
files = {'file1':open('file','rb')} files = ('file1',open('file','rb')) === ('filename', fileobj, 'content_type') 或 ('filename', fileobj, 'content_type', custom_headers)
9.auth
用户名、密码加密 auth = HTTPBasicAuto(username,pwd)
10.timeout
请求和响应的超时
11.allow_redirects
是否允许重定向
12.proxies
代理
13.verify
是否忽略证书
14.stream
下载方式 类型为布尔值 True,则下载能下多少下多少
15.cert
针对https,证书文件
16.session
requests.session 可以免去写cookies
2.beautifulsoup
1.markup
将一个字符串或者文件序列化(url,文件路径等)
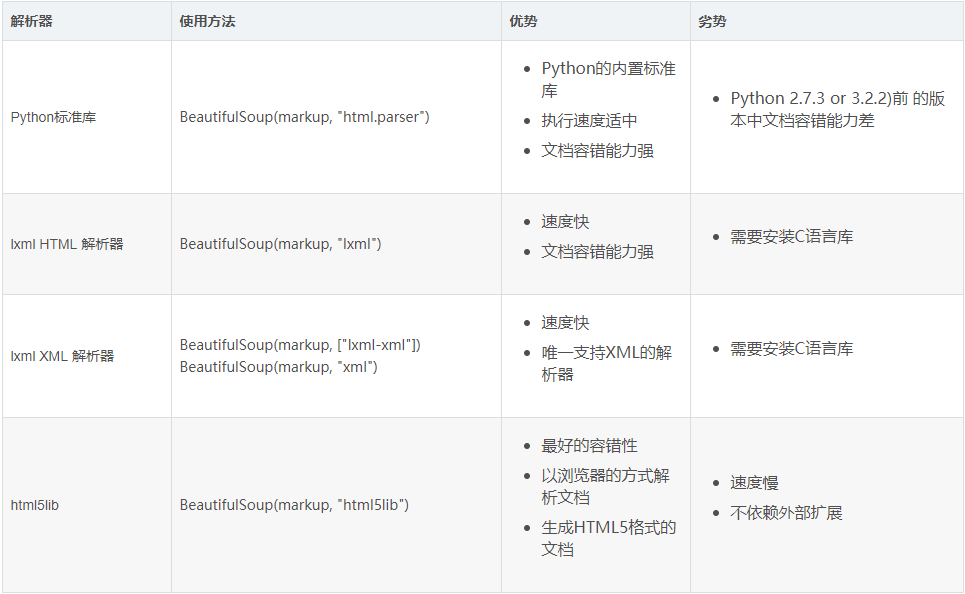
2.features
解析器类型
基本应用
1.tag
1)name


from bs4 import BeautifulSoup soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') tag = soup.b print(tag.name)
通过可以通过该属性来修改标签,如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档。
from bs4 import BeautifulSoup soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') tag.name = 'a' print(tag)
2)Attributes
一个tag可能有很多个属性. tag <b class="boldest"> 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同
from bs4 import BeautifulSoup soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') print(tag['class'])
也可以使用attrs可以以字典形式返回标签的所有属性
from bs4 import BeautifulSoup soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') print(tag.attrs)
tag的属性可以被添加,删除或修改.
tag['class'] = 'verybold' tag['id'] = 1 del tag['class'] del tag['id'] tag['class'] print(tag.get('class'))
3)children
所有子标签
4)clear
将标签的所有子标签全部清空(保留标签名)
tag = soup.find('body') tag.clear() print(soup)
5)decompose
递归的删除所有的标签
body = soup.find('body') body.decompose() print(soup)
6)extract
递归的删除所有的标签,并获取删除的标签
body = soup.find('body') v = body.extract() print(soup)
7)decode 和 encode
decode转换为字符串(含当前标签);decode_contents(不含当前标签)
encode转换为字节(含当前标签);encode_contents(不含当前标签)
body = soup.find('body') v = body.decode() v = body.decode_contents() print(v)
body = soup.find('body') v = body.encode() v = body.encode_contents() print(v)
8)find 和 find_all
查找第一个和查找所有,源码中find的实现基于find_all,取[0]
tag = soup.find('a') print(tag) tag = soup.find(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie') tag = soup.find(name='a', class_='sister', recursive=True, text='Lacie') print(tag)
tags = soup.find_all('a') print(tags) tags = soup.find_all('a',limit=1) print(tags) tags = soup.find_all(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie') tags = soup.find(name='a', class_='sister', recursive=True, text='Lacie') print(tags) ####### 列表 ####### v = soup.find_all(name=['a','div']) print(v) v = soup.find_all(class_=['sister0', 'sister']) print(v) v = soup.find_all(text=['Tillie']) print(v, type(v[0])) v = soup.find_all(id=['link1','link2']) print(v) v = soup.find_all(href=['link1','link2']) print(v) ####### 正则 ####### import re rep = re.compile('p') rep = re.compile('^p') v = soup.find_all(name=rep) print(v) rep = re.compile('sister.*') v = soup.find_all(class_=rep) print(v) rep = re.compile('http://www.oldboy.com/static/.*') v = soup.find_all(href=rep) print(v) ####### 方法筛选 ####### def func(tag): return tag.has_attr('class') and tag.has_attr('id') v = soup.find_all(name=func) print(v) ## get,获取标签属性 tag = soup.find('a') v = tag.get('id') print(v)
9)has_attr
检查标签是否具有该属性
10)get_text
获取标签内部文本内容
11)index
检查标签在某标签中的索引位置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号